Java Stream:List分组成Map或LinkedHashMap
在Java中,使用Stream API可以轻松地对集合进行操作,包括将List转换为Map或LinkedHashMap。本篇博客将演示如何利用Java Stream实现这两种转换,同时假设List中的元素是User对象。
1. 数据准备
List<User> list = new ArrayList<>();
list.add(new User(1, "张三", "我是张三01"));
list.add(new User(2, "张三", "我是张三02"));
list.add(new User(3, "李四", "我是李四01"));
list.add(new User(4, "李四", "我是李四02"));
list.add(new User(5, "王五", "我是王五01"));
list.add(new User(6, "王五", "我是王五02"));
2. List转Map(无序-默认)
List转Map有两种Map格式,分别是 Map<String, User>和 Map<String, List>,下面我将分别展示:
2.1 List转Map<String, User>
转换成Map<String, User>我们需要使用到Collectors.toMap方法:
//通过名字进行分组,如果名字重复的话只取第一个:List转Map<String, User>
Map<String, User> map01 = list.stream().collect(Collectors.toMap(User::getName, Function.identity(), (u1, u2) -> u1));
System.out.println(map01);
执行结果:
{
李四=User(id=3, name=李四, note=我是李四01),
张三=User(id=1, name=张三, note=我是张三01),
王五=User(id=5, name=王五, note=我是王五01)
}
2.2 List转Map<String, List<User>>
转换成Map<String, List<User>>我们需要使用到Collectors.groupingBy方法:
//通过名字进行分组,如果名字重复的话就分组成List:List转Map<String, List<User>>
Map<String, List<User>> map02 = list.stream().collect(Collectors.groupingBy(User::getName));
System.out.println(map02);
执行结果:
{
李四=[User(id=3, name=李四, note=我是李四01), User(id=4, name=李四, note=我是李四02)],
张三=[User(id=1, name=张三, note=我是张三01), User(id=2, name=张三, note=我是张三02)],
王五=[User(id=5, name=王五, note=我是王五01), User(id=6, name=王五, note=我是王五02)]
}
我们可以看到:map中打印出来的执行结果并没有按照List中添加的顺序打印的
3. List转LinkedHashMap(有序)
List转LinkedHashMap也有两种Map格式,分别是 LinkedHashMap<String, User>和 LinkedHashMap<String, List>,下面我将分别展示:
3.1 List转LinkedHashMap<String, User>
转换成LinkedHashMap<String, User>我们需要使用到Collectors.toMap方法:
//通过名字进行分组,如果名字重复的话只取第一个:List转LinkedHashMap<String, User>
Map<String, User> map03 = list.stream().collect(Collectors.toMap(User::getName, Function.identity(), (u1, u2) -> u1, LinkedHashMap::new));
System.out.println(map03);
执行结果:
{
张三=User(id=1, name=张三, note=我是张三01),
李四=User(id=3, name=李四, note=我是李四01),
王五=User(id=5, name=王五, note=我是王五01)
}
3.2 List转LinkedHashMap<String, List<User>>
转换成LinkedHashMap<String, List<User>>我们需要使用到Collectors.groupingBy方法:
//通过名字进行分组,如果名字重复的话就分组成List:List转LinkedHashMap<String, List<User>>
Map<String, List<User>> map04 = list.stream().collect(Collectors.groupingBy(User::getName, LinkedHashMap::new, Collectors.toList()));
System.out.println(map04);
执行结果:
{
张三=[User(id=1, name=张三, note=我是张三01), User(id=2, name=张三, note=我是张三02)],
李四=[User(id=3, name=李四, note=我是李四01), User(id=4, name=李四, note=我是李四02)],
王五=[User(id=5, name=王五, note=我是王五01), User(id=6, name=王五, note=我是王五02)]
}
我们可以看到:map中打印出来的执行结果是按照List中添加的顺序打印的
4. 总结
在List转Map的过程中:
如果我们对Map中的顺序没要求,我们可以通过stream流将List转换为默认的HMap即可
如果我们对Map中的顺序有要求,我们可以通过stream流将List转换为LinkedHashMap才行
5. 全部代码
public static void test1() {List<User> list = new ArrayList<>();list.add(new User(1, "张三", "我是张三01"));list.add(new User(2, "张三", "我是张三02"));list.add(new User(3, "李四", "我是李四01"));list.add(new User(4, "李四", "我是李四02"));list.add(new User(5, "王五", "我是王五01"));list.add(new User(6, "王五", "我是王五02"));//通过名字进行分组,如果名字重复的话只取第一个:List转Map<String, User>Map<String, User> map01 = list.stream().collect(Collectors.toMap(User::getName, Function.identity(), (u1, u2) -> u1));System.out.println(map01);//通过名字进行分组,如果名字重复的话就分组成List:List转Map<String, List<User>>Map<String, List<User>> map02 = list.stream().collect(Collectors.groupingBy(User::getName));System.out.println(map02);//通过名字进行分组,如果名字重复的话只取第一个:List转LinkedHashMap<String, User>Map<String, User> map03 = list.stream().collect(Collectors.toMap(User::getName, Function.identity(), (u1, u2) -> u1, LinkedHashMap::new));System.out.println(map03);//通过名字进行分组,如果名字重复的话就分组成List:List转LinkedHashMap<String, List<User>>Map<String, List<User>> map04 = list.stream().collect(Collectors.groupingBy(User::getName, LinkedHashMap::new, Collectors.toList()));System.out.println(map04);
}
public class User {private Integer id;private String name;private String note;
}
相关文章:

Java Stream:List分组成Map或LinkedHashMap
在Java中,使用Stream API可以轻松地对集合进行操作,包括将List转换为Map或LinkedHashMap。本篇博客将演示如何利用Java Stream实现这两种转换,同时假设List中的元素是User对象。 1. 数据准备 List<User> list new ArrayList<>(…...
vue2+elementui使用MessageBox 弹框$msgbox自定义VNode内容:实现radio
虽说实现下面的效果,用el-dialog很轻松就能搞定。但是这种简单的交互,我更喜欢使用MessageBox。 话不多说,直接上代码~ <el-button type"primary" size"mini" click"handleApply()" >处理申请</el-b…...

OC 实现手指滑动拖动View
RPReplay_Final1699613924 实现手指滑动拖动View 支持手势移动的控件 支持 Masonry frame 布局 使用富文本 也支持自动高度 核心代码 - (void)handlePanGesture:(UIPanGestureRecognizer *)p {CGPoint panPoint [p locationInView:self.view];CGPoint currentViewPoint _dr…...

多级缓存之实现多级缓存
多级缓存的实现离不开Nginx编程,而Nginx编程又离不开OpenResty。 1. OpenResty快速入门 我们希望达到的多级缓存架构如图: 其中: windows上的nginx用来做反向代理服务,将前端的查询商品的ajax请求代理到OpenResty集群 OpenRest…...

React【axios、全局处理、 antd UI库、更改主题、使用css module的情况下修改第三方库的样式、支持sass less】(十三)
文件目录 Proxying in Development http-proxy-middleware fetch_get fetch 是否成功 axios 全局处理 antd UI库 更改主题 使用css module的情况下修改第三方库的样式 支持sass & less Proxying in Development 在开发模式下,如果客户端所在服务器跟后…...
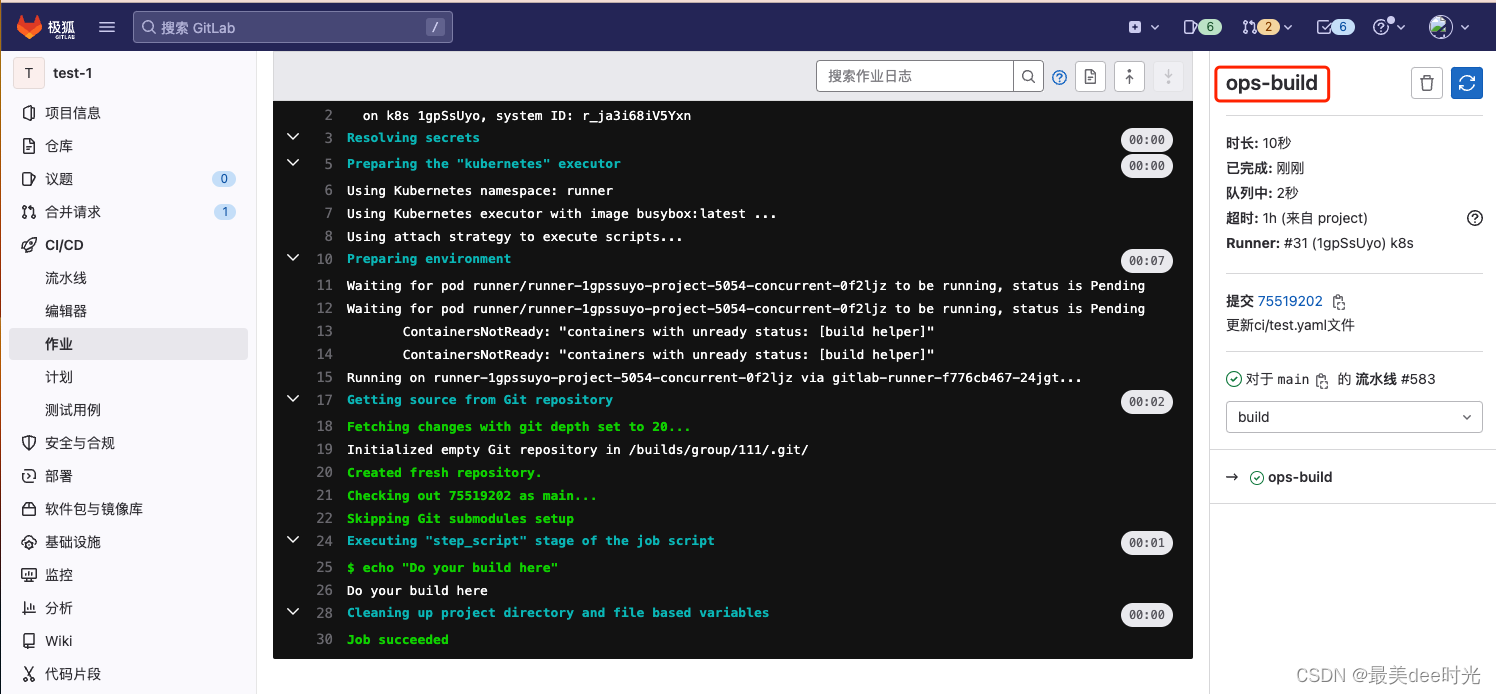
在gitlab中指定自定义 CI/CD 配置文件
文章目录 1. 介绍2. 配置操作3. 配置场景3.1 CI/CD 配置文件在当前项目step1:在当前项目中创建目录,编写流水线文件存放在该目录中step2:在当前项目中配置step3:运行流水线测试 3.2 CI/CD 配置文件位于外部站点上step1:…...
(论文阅读22/100)Learning a Deep Compact Image Representation for Visual Tracking
文献阅读笔记 简介 题目 Learning a Deep Compact Image Representation for Visual Tracking 作者 N Wang, DY Yeung 原文链接 Learning a Deep Compact Image Representation for Visual Tracking (neurips.cc) 关键词 Object tracking、DLT、SDAE 研究问题 track…...

浅谈设计模式
文章目录 一、单例模式 1.饿汉模式 2.懒汉模式 二、工厂模式 三、建造者模式 四、代理模式 设计模式是前辈们对代码开发的总结,是解决特定问题的一系列套路。它不是语法规定,而是一套用来提高代码可复用性、可维护性、可读性、稳健性以及安全性的解…...

企业年会/年终活动如何邀请媒体记者报道?
媒体邀约是企业或组织进行宣传的重要手段之一。通过邀请媒体参加活动,可以增加活动的曝光度和知名度,吸引更多的关注和参与。同时,媒体报道还可以提高企业或组织的权威性和可信度,从而让公众更容易接受其传达的信息。 企业年会或…...

C语言如何执行HTTP GET请求
在现代互联网时代,网络数据的获取和分析变得越来越重要。无论是为了研究市场趋势,还是为了收集信息进行数据分析,编写一个网络爬虫可以帮助我们自动化这一过程。在这篇文章中,我们将使用C语言和libcurl库来编写一个简单的网络爬虫…...

.Net 6 Nacos日志控制台疯狂发输出+Log4Net日志过滤
我们的项目配置了Log4Net 作为日志输出工具,在引入Nacos后,控制台和日志里疯狂输出nacos心跳日志和其他相关信息,导致自己记录的信息被淹没了,找了很多解决办法: 1、提高nacos日志级别,然后再屏蔽相应级别…...
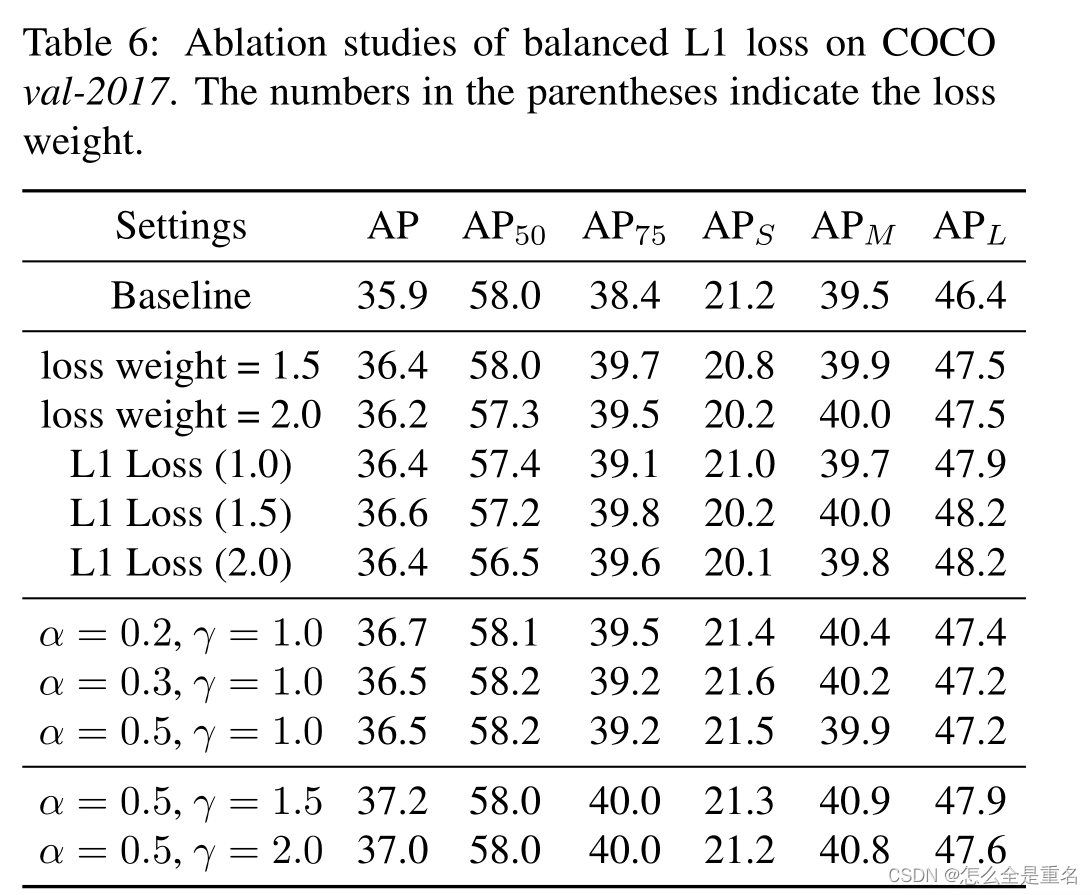
Libra R-CNN: Towards Balanced Learning for Object Detection(2019.4)
文章目录 AbstractIntroduction引入问题1) Sample level imbalance2) Feature level imbalance3) Objective level imbalance进行解决贡献 Related Work(他人的work,捎带与我们的对比)Model architectures for object detection&a…...
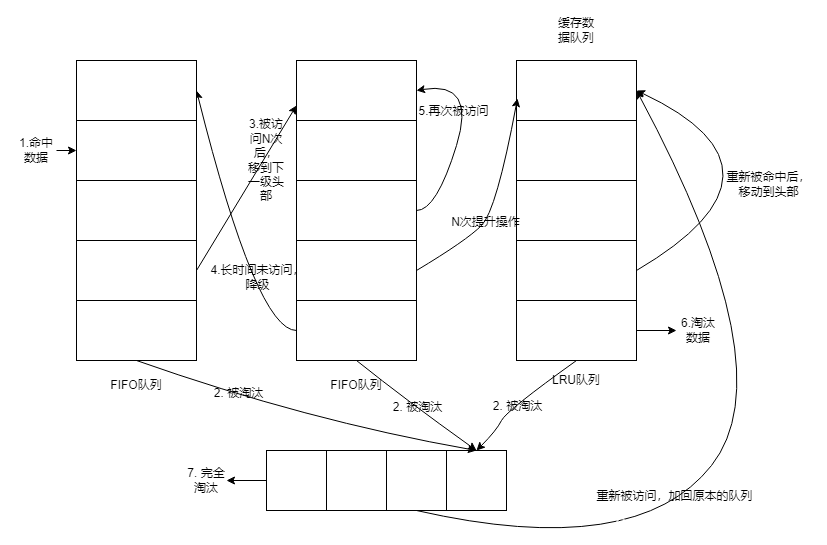
Redis的内存淘汰策略分析
概念 LRU 是按访问时间排序,发生淘汰的时候,把访问时间最久的淘汰掉。LFU 是按频次排序,一个数据被访问过,把它的频次 1,发生淘汰的时候,把频次低的淘汰掉。 几种LRU策略 以下集中LRU测率网上有很多&am…...

git命令之遭遇 ignore罕见问题解决
我先来讲讲背景 我的一些文件在ignore了,不会被提交到远程仓库,这时候我的远程仓库中是没有这几个文件的,这时候我如果使用 git reset 的话这时候除了那几个 ignore 的文件以外都被更新的,但是如果我不需要这几个被 ignore 的文件…...

torch DDP多卡训练教程记录
参考 简明教程看这里 --> pytorch分布式训练 和这篇: [PyTorch]> DDP系列第一篇:入门教程 --》 详细解答了pipeline DDP原理篇 --> DDP系列第二篇:实现原理与源代码解析 --》 主要讲 all_reduce 和 sample 的实现 减少GPU占用看这里…...
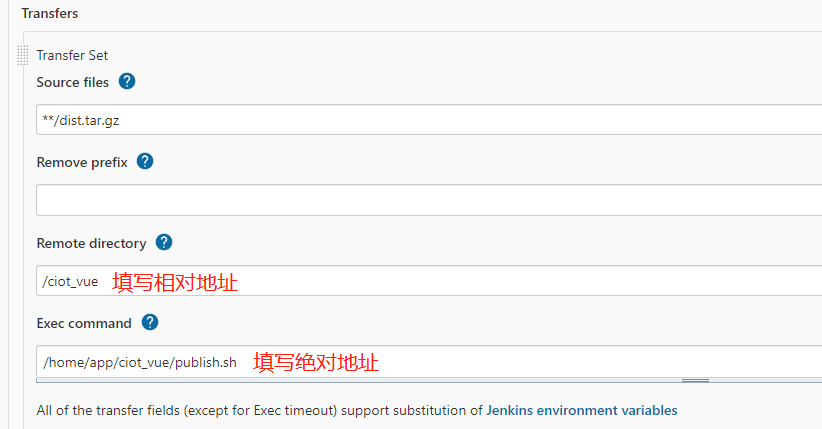
Jenkins CICD过程常见异常
1 Status [126] Exception when publishing, exception message [Exec exit status not zero. Status [126] 1.1 报错日志 SSH: EXEC: STDOUT/STDERR from command [/app/***/publish.sh] ... bash: /app/***/publish.sh: Permission denied SSH: EXEC: completed after 200…...

Java11新增特性
前言 在前面的文章中,我们已经介绍了 Java9的新增特性 和 Java10的新增特性 ,下面我们书接上文,来介绍一下Java11的新增特性 版本简介 Java 11 是 Java 平台的最新版本,于2018年9月25日发布。这个版本是自Java 8以来最重要的更新之一&…...
)
安卓常见设计模式13------过滤器模式(Kotlin版)
W1 是什么,什么是过滤器模式? 过滤器模式(Filter Pattern)是一种常用的结构型设计模式,用于根据特定条件过滤和筛选数据。 2. W2 为什么,为什么需要使用过滤器模式,能给我们编码带来什么好处…...

使用spark进行递归的可行方案
在实际工作中会遇到,最近有需求将产品炸开bom到底层,但是ERP中bom数据在一张表中递归存储的,不循环展开,是无法知道最底层原材料是什么。 在ERP中使用pl/sql甚至sql是可以进行炸BOM的,但是怎么使用spark展开࿰…...
Spring -Spring之依赖注入源码解析(下)--实践(流程图)
IOC依赖注入流程图 注入的顺序及优先级:type-->Qualifier-->Primary-->PriOriry-->name...

5分钟掌握GHelper:华硕笔记本轻量控制工具的实战指南
5分钟掌握GHelper:华硕笔记本轻量控制工具的实战指南 【免费下载链接】g-helper Lightweight, open-source control tool for ASUS laptops and ROG Ally. Manage performance modes, fans, GPU, battery, and RGB lighting across Zephyrus, Flow, TUF, Strix, Sca…...

5G手机信号安全背后的秘密:PDCP层如何用4把密钥守护你的通话与上网
5G手机信号安全背后的秘密:PDCP层如何用4把密钥守护你的通话与上网 每次用5G手机发消息、刷视频时,你可能从未想过——那些在屏幕上跳动的文字和画面,正被一套精密的"数字锁具"严密保护着。这套系统就像银行金库的四重门禁…...

中国重名人数最多的前20个姓名
...

NoMachine vs. 其他远程工具:实测Ubuntu到Win10的延迟与画质,附分辨率自适应设置
NoMachine远程桌面性能深度评测:Ubuntu与Windows跨平台实战指南 远程办公和跨平台协作已成为现代工作流的重要组成部分。在众多远程桌面解决方案中,NoMachine以其独特的NX协议技术脱颖而出,尤其在处理高延迟网络环境时表现卓越。本文将深入评…...

3步快速上手VTube Studio API:打造专属虚拟主播互动插件
3步快速上手VTube Studio API:打造专属虚拟主播互动插件 【免费下载链接】VTubeStudio VTube Studio API Development Page 项目地址: https://gitcode.com/gh_mirrors/vt/VTubeStudio 你是否想让虚拟主播根据弹幕做出反应?或者让模型跟随音乐节奏…...

如何用Arduino库实现PZEM-004T v3.0电能监测?完整指南解析
如何用Arduino库实现PZEM-004T v3.0电能监测?完整指南解析 【免费下载链接】PZEM-004T-v30 Arduino library for the Updated PZEM-004T v3.0 Power and Energy meter 项目地址: https://gitcode.com/gh_mirrors/pz/PZEM-004T-v30 PZEM-004T v3.0电能监测仪A…...

Degrees of Lewdity汉化版完整指南:5分钟完成中文游戏配置
Degrees of Lewdity汉化版完整指南:5分钟完成中文游戏配置 【免费下载链接】Degrees-of-Lewdity-Chinese-Localization Degrees of Lewdity 游戏的授权中文社区本地化版本 项目地址: https://gitcode.com/gh_mirrors/de/Degrees-of-Lewdity-Chinese-Localization …...
)
告别手动转换!用MyBatis TypeHandler优雅处理MySQL 8.0的JSON字段(附完整Spring Boot配置)
告别手动转换!用MyBatis TypeHandler优雅处理MySQL 8.0的JSON字段(附完整Spring Boot配置) 在Spring Boot项目中处理MySQL的JSON字段时,开发者常常陷入手动序列化/反序列化的繁琐操作中。本文将带你彻底摆脱这种低效模式…...

Axios拦截器里的小秘密:如何自动处理POST请求的JSON/FormData格式转换?
Axios拦截器实战:智能切换JSON与FormData的工程化解决方案 在前后端分离架构中,数据格式的差异常常成为联调阶段的痛点。当某个接口要求application/json而另一个却需要multipart/form-data时,开发者往往需要手动处理这些细节。这不仅增加了代…...

YaeAchievement:一站式自动化成就管理解决方案
YaeAchievement:一站式自动化成就管理解决方案 【免费下载链接】YaeAchievement 更快、更准的原神数据导出工具 项目地址: https://gitcode.com/gh_mirrors/ya/YaeAchievement 还在为数百项《原神》成就的手动整理而头疼吗?你是否曾花费数小时在多…...