多级缓存之实现多级缓存
多级缓存的实现离不开Nginx编程,而Nginx编程又离不开OpenResty。
1. OpenResty快速入门
我们希望达到的多级缓存架构如图:

其中:
-
windows上的nginx用来做反向代理服务,将前端的查询商品的ajax请求代理到OpenResty集群 -
OpenResty集群用来编写多级缓存业务
1.1. 反向代理流程
现在,商品详情页使用的是假的商品数据。不过在浏览器中,可以看到页面有发起ajax请求查询真实商品数据。
这个请求如下:

请求地址是localhost,端口是80,就被windows上安装的Nginx服务给接收到了。然后代理给了OpenResty集群:

我们需要在OpenResty中编写业务,查询商品数据并返回到浏览器。
但是这次,我们先在OpenResty接收请求,返回假的商品数据。
1.2. OpenResty监听请求
OpenResty的很多功能都依赖于其目录下的Lua库,需要在nginx.conf中指定依赖库的目录,并导入依赖:
1)添加对OpenResty的Lua模块的加载
修改/usr/local/openresty/nginx/conf/nginx.conf文件,在其中的http下面,添加下面代码:
#lua 模块
lua_package_path "/usr/local/openresty/lualib/?.lua;;";
#c模块
lua_package_cpath "/usr/local/openresty/lualib/?.so;;";
2)监听/api/item路径
修改/usr/local/openresty/nginx/conf/nginx.conf文件,在nginx.conf的server下面,添加对/api/item这个路径的监听:
location /api/item {# 默认的响应类型default_type application/json;# 响应结果由lua/item.lua文件来决定content_by_lua_file lua/item.lua;
}
这个监听,就类似于SpringMVC中的@GetMapping("/api/item")做路径映射。
而content_by_lua_file lua/item.lua则相当于调用item.lua这个文件,执行其中的业务,把结果返回给用户。相当于java中调用service。
1.3. 编写item.lua
1)在/usr/loca/openresty/nginx目录创建文件夹:lua

2)在/usr/loca/openresty/nginx/lua文件夹下,新建文件:item.lua

3)编写item.lua,返回假数据
item.lua中,利用ngx.say()函数返回数据到Response中
ngx.say('{"id":10001,"name":"SALSA AIR","title":"RIMOWA 21寸托运箱拉杆箱 SALSA AIR系列果绿色 820.70.36.4","price":17900,"image":"https://m.360buyimg.com/mobilecms/s720x720_jfs/t6934/364/1195375010/84676/e9f2c55f/597ece38N0ddcbc77.jpg!q70.jpg.webp","category":"拉杆箱","brand":"RIMOWA","spec":"","status":1,"createTime":"2019-04-30T16:00:00.000+00:00","updateTime":"2019-04-30T16:00:00.000+00:00","stock":2999,"sold":31290}')
4)重新加载配置
nginx -s reload
刷新商品页面:http://localhost/item.html?id=1001,即可看到效果:

2. 请求参数处理
我们在OpenResty接收前端请求,但是返回的是假数据。
要返回真实数据,必须根据前端传递来的商品id,查询商品信息才可以。
那么如何获取前端传递的商品参数呢?
2.1. 获取参数的API
OpenResty中提供了一些API用来获取不同类型的前端请求参数:

2.2. 获取参数并返回
在前端发起的ajax请求如图:

可以看到商品id是以路径占位符方式传递的,因此可以利用正则表达式匹配的方式来获取ID
1)获取商品id
修改/usr/loca/openresty/nginx/nginx.conf文件中监听/api/item的代码,利用正则表达式获取ID:
location ~ /api/item/(\d+) {# 默认的响应类型default_type application/json;# 响应结果由lua/item.lua文件来决定content_by_lua_file lua/item.lua;
}
2)拼接ID并返回
修改/usr/loca/openresty/nginx/lua/item.lua文件,获取id并拼接到结果中返回:
-- 获取商品id
local id = ngx.var[1]
-- 拼接并返回
ngx.say('{"id":' .. id .. ',"name":"SALSA AIR","title":"RIMOWA 21寸托运箱拉杆箱 SALSA AIR系列果绿色 820.70.36.4","price":17900,"image":"https://m.360buyimg.com/mobilecms/s720x720_jfs/t6934/364/1195375010/84676/e9f2c55f/597ece38N0ddcbc77.jpg!q70.jpg.webp","category":"拉杆箱","brand":"RIMOWA","spec":"","status":1,"createTime":"2019-04-30T16:00:00.000+00:00","updateTime":"2019-04-30T16:00:00.000+00:00","stock":2999,"sold":31290}')
3)重新加载并测试
运行命令以重新加载OpenResty配置:
nginx -s reload
刷新页面可以看到结果中已经带上了ID:

3. 查询Tomcat
拿到商品ID后,本应去缓存中查询商品信息,不过目前我们还未建立nginx、redis缓存。因此,这里我们先根据商品id去tomcat查询商品信息。我们实现如图部分:

需要注意的是,我们的OpenResty是在虚拟机,Tomcat是在Windows电脑上。两者IP一定不要搞错了。

3.1. 发送http请求的API
nginx提供了内部API用以发送http请求:
local resp = ngx.location.capture("/path",{method = ngx.HTTP_GET, -- 请求方式args = {a=1,b=2}, -- get方式传参数
})
返回的响应内容包括:
resp.status:响应状态码resp.header:响应头,是一个tableresp.body:响应体,就是响应数据
注意:这里的path是路径,并不包含IP和端口。这个请求会被nginx内部的server监听并处理。
但是我们希望这个请求发送到Tomcat服务器,所以还需要编写一个server来对这个路径做反向代理:
location /path {# 这里是windows电脑的ip和Java服务端口,需要确保windows防火墙处于关闭状态proxy_pass http://192.168.150.1:8081; }
原理如图:

3.2. 封装http工具
下面,我们封装一个发送Http请求的工具,基于ngx.location.capture来实现查询tomcat。
1)添加反向代理,到windows的Java服务
因为item-service中的接口都是/item开头,所以我们监听/item路径,代理到windows上的tomcat服务。
修改 /usr/local/openresty/nginx/conf/nginx.conf文件,添加一个location:
location /item {proxy_pass http://192.168.150.1:8081;
}
以后,只要我们调用ngx.location.capture("/item"),就一定能发送请求到windows的tomcat服务。
2)封装工具类
之前我们说过,OpenResty启动时会加载以下两个目录中的工具文件:

所以,自定义的http工具也需要放到这个目录下。
在/usr/local/openresty/lualib目录下,新建一个common.lua文件:
vi /usr/local/openresty/lualib/common.lua
内容如下:
-- 封装函数,发送http请求,并解析响应
local function read_http(path, params)local resp = ngx.location.capture(path,{method = ngx.HTTP_GET,args = params,})if not resp then-- 记录错误信息,返回404ngx.log(ngx.ERR, "http请求查询失败, path: ", path , ", args: ", args)ngx.exit(404)endreturn resp.body
end
-- 将方法导出
local _M = { read_http = read_http
}
return _M
这个工具将read_http函数封装到_M这个table类型的变量中,并且返回,这类似于导出。
使用的时候,可以利用require('common')来导入该函数库,这里的common是函数库的文件名。
3)实现商品查询
最后,我们修改/usr/local/openresty/lua/item.lua文件,利用刚刚封装的函数库实现对tomcat的查询:
-- 引入自定义common工具模块,返回值是common中返回的 _M
local common = require("common")
-- 从 common中获取read_http这个函数
local read_http = common.read_http
-- 获取路径参数
local id = ngx.var[1]
-- 根据id查询商品
local itemJSON = read_http("/item/".. id, nil)
-- 根据id查询商品库存
local itemStockJSON = read_http("/item/stock/".. id, nil)
这里查询到的结果是json字符串,并且包含商品、库存两个json字符串,页面最终需要的是把两个json拼接为一个json:

这就需要我们先把JSON变为lua的table,完成数据整合后,再转为JSON。
3.3. CJSON工具类
OpenResty提供了一个cjson的模块用来处理JSON的序列化和反序列化。
官方地址: https://github.com/openresty/lua-cjson/
1)引入cjson模块:
local cjson = require "cjson"
2)序列化:
local obj = {name = 'jack',age = 21
}
-- 把 table 序列化为 json
local json = cjson.encode(obj)
3)反序列化:
local json = '{"name": "jack", "age": 21}'
-- 反序列化 json为 table
local obj = cjson.decode(json);
print(obj.name)
3.4. 实现Tomcat查询
下面,我们修改之前的item.lua中的业务,添加json处理功能:
-- 导入common函数库
local common = require('common')
local read_http = common.read_http
-- 导入cjson库
local cjson = require('cjson')-- 获取路径参数
local id = ngx.var[1]
-- 根据id查询商品
local itemJSON = read_http("/item/".. id, nil)
-- 根据id查询商品库存
local itemStockJSON = read_http("/item/stock/".. id, nil)-- JSON转化为lua的table
local item = cjson.decode(itemJSON)
local stock = cjson.decode(stockJSON)-- 组合数据
item.stock = stock.stock
item.sold = stock.sold-- 把item序列化为json 返回结果
ngx.say(cjson.encode(item))
3.5. 基于ID负载均衡
刚才的代码中,我们的tomcat是单机部署。而实际开发中,tomcat一定是集群模式:

因此,OpenResty需要对tomcat集群做负载均衡。
而默认的负载均衡规则是轮询模式,当我们查询/item/10001时:
- 第一次会访问8081端口的
tomcat服务,在该服务内部就形成了JVM进程缓存 - 第二次会访问8082端口的
tomcat服务,该服务内部没有JVM缓存(因为JVM缓存无法共享),会查询数据库 - …
你看,因为轮询的原因,第一次查询8081形成的JVM缓存并未生效,直到下一次再次访问到8081时才可以生效,缓存命中率太低了。
怎么办?
如果能让同一个商品,每次查询时都访问同一个tomcat服务,那么JVM缓存就一定能生效了。
也就是说,我们需要根据商品id做负载均衡,而不是轮询。
1)原理
nginx提供了基于请求路径做负载均衡的算法:
nginx根据请求路径做hash运算,把得到的数值对tomcat服务的数量取余,余数是几,就访问第几个服务,实现负载均衡。
例如:
- 我们的请求路径是
/item/10001 tomcat总数为2台(8081、8082)- 对请求路径
/item/1001做hash运算求余的结果为1 - 则访问第一个
tomcat服务,也就是8081
只要id不变,每次hash运算结果也不会变,那就可以保证同一个商品,一直访问同一个tomcat服务,确保JVM缓存生效。
2)实现
修改/usr/local/openresty/nginx/conf/nginx.conf文件,实现基于ID做负载均衡。
首先,定义tomcat集群,并设置基于路径做负载均衡:
upstream tomcat-cluster {hash $request_uri;server 192.168.150.1:8081;server 192.168.150.1:8082;
}
然后,修改对tomcat服务的反向代理,目标指向tomcat集群:
location /item {proxy_pass http://tomcat-cluster;
}
重新加载OpenResty
nginx -s reload
3)测试
启动两台tomcat服务:

同时启动:

清空日志后,再次访问页面,可以看到不同id的商品,访问到了不同的tomcat服务:


4. Redis缓存预热
Redis缓存会面临冷启动问题:
冷启动:服务刚刚启动时,Redis中并没有缓存,如果所有商品数据都在第一次查询时添加缓存,可能会给数据库带来较大压力。
缓存预热:在实际开发中,我们可以利用大数据统计用户访问的热点数据,在项目启动时将这些热点数据提前查询并保存到Redis中。
我们数据量较少,并且没有数据统计相关功能,目前可以在启动时将所有数据都放入缓存中。
1)利用Docker安装Redis
docker run --name redis -p 6379:6379 -d redis redis-server --appendonly yes
2)在item-service服务中引入Redis依赖
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
3)配置Redis地址
spring:redis:host: 192.168.150.101
4)编写初始化类
缓存预热需要在项目启动时完成,并且必须是拿到RedisTemplate之后。
这里我们利用InitializingBean接口来实现,因为InitializingBean可以在对象被Spring创建并且成员变量全部注入后执行。
package com.dcxuexi.item.config;import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.dcxuexi.item.pojo.Item;
import com.dcxuexi.item.pojo.ItemStock;
import com.dcxuexi.item.service.IItemService;
import com.dcxuexi.item.service.IItemStockService;
import org.springframework.beans.factory.InitializingBean;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.stereotype.Component;import java.util.List;@Component
public class RedisHandler implements InitializingBean {@Autowiredprivate StringRedisTemplate redisTemplate;@Autowiredprivate IItemService itemService;@Autowiredprivate IItemStockService stockService;private static final ObjectMapper MAPPER = new ObjectMapper();@Overridepublic void afterPropertiesSet() throws Exception {// 初始化缓存// 1.查询商品信息List<Item> itemList = itemService.list();// 2.放入缓存for (Item item : itemList) {// 2.1.item序列化为JSONString json = MAPPER.writeValueAsString(item);// 2.2.存入redisredisTemplate.opsForValue().set("item:id:" + item.getId(), json);}// 3.查询商品库存信息List<ItemStock> stockList = stockService.list();// 4.放入缓存for (ItemStock stock : stockList) {// 2.1.item序列化为JSONString json = MAPPER.writeValueAsString(stock);// 2.2.存入redisredisTemplate.opsForValue().set("item:stock:id:" + stock.getId(), json);}}
}
5. 查询Redis缓存
现在,Redis缓存已经准备就绪,我们可以再OpenResty中实现查询Redis的逻辑了。如下图红框所示:

当请求进入OpenResty之后:
- 优先查询
Redis缓存 - 如果
Redis缓存未命中,再查询Tomcat
5.1. 封装Redis工具
OpenResty提供了操作Redis的模块,我们只要引入该模块就能直接使用。但是为了方便,我们将Redis操作封装到之前的common.lua工具库中。
修改/usr/local/openresty/lualib/common.lua文件:
1)引入Redis模块,并初始化Redis对象
-- 导入redis
local redis = require('resty.redis')
-- 初始化redis
local red = redis:new()
red:set_timeouts(1000, 1000, 1000)
2)封装函数,用来释放Redis连接,其实是放入连接池
-- 关闭redis连接的工具方法,其实是放入连接池
local function close_redis(red)local pool_max_idle_time = 10000 -- 连接的空闲时间,单位是毫秒local pool_size = 100 --连接池大小local ok, err = red:set_keepalive(pool_max_idle_time, pool_size)if not ok thenngx.log(ngx.ERR, "放入redis连接池失败: ", err)end
end
3)封装函数,根据key查询Redis数据
-- 查询redis的方法 ip和port是redis地址,key是查询的key
local function read_redis(ip, port, key)-- 获取一个连接local ok, err = red:connect(ip, port)if not ok thenngx.log(ngx.ERR, "连接redis失败 : ", err)return nilend-- 查询redislocal resp, err = red:get(key)-- 查询失败处理if not resp thenngx.log(ngx.ERR, "查询Redis失败: ", err, ", key = " , key)end--得到的数据为空处理if resp == ngx.null thenresp = nilngx.log(ngx.ERR, "查询Redis数据为空, key = ", key)endclose_redis(red)return resp
end
4)导出
-- 将方法导出
local _M = { read_http = read_http,read_redis = read_redis
}
return _M
完整的common.lua:
-- 导入redis
local redis = require('resty.redis')
-- 初始化redis
local red = redis:new()
red:set_timeouts(1000, 1000, 1000)-- 关闭redis连接的工具方法,其实是放入连接池
local function close_redis(red)local pool_max_idle_time = 10000 -- 连接的空闲时间,单位是毫秒local pool_size = 100 --连接池大小local ok, err = red:set_keepalive(pool_max_idle_time, pool_size)if not ok thenngx.log(ngx.ERR, "放入redis连接池失败: ", err)end
end-- 查询redis的方法 ip和port是redis地址,key是查询的key
local function read_redis(ip, port, key)-- 获取一个连接local ok, err = red:connect(ip, port)if not ok thenngx.log(ngx.ERR, "连接redis失败 : ", err)return nilend-- 查询redislocal resp, err = red:get(key)-- 查询失败处理if not resp thenngx.log(ngx.ERR, "查询Redis失败: ", err, ", key = " , key)end--得到的数据为空处理if resp == ngx.null thenresp = nilngx.log(ngx.ERR, "查询Redis数据为空, key = ", key)endclose_redis(red)return resp
end-- 封装函数,发送http请求,并解析响应
local function read_http(path, params)local resp = ngx.location.capture(path,{method = ngx.HTTP_GET,args = params,})if not resp then-- 记录错误信息,返回404ngx.log(ngx.ERR, "http查询失败, path: ", path , ", args: ", args)ngx.exit(404)endreturn resp.body
end
-- 将方法导出
local _M = { read_http = read_http,read_redis = read_redis
}
return _M
5.2. 实现Redis查询
接下来,我们就可以去修改item.lua文件,实现对Redis的查询了。
查询逻辑是:
- 根据
id查询Redis - 如果查询失败则继续查询
Tomcat - 将查询结果返回
1)修改/usr/local/openresty/lua/item.lua文件,添加一个查询函数:
-- 导入common函数库
local common = require('common')
local read_http = common.read_http
local read_redis = common.read_redis
-- 封装查询函数
function read_data(key, path, params)-- 查询本地缓存local val = read_redis("127.0.0.1", 6379, key)-- 判断查询结果if not val thenngx.log(ngx.ERR, "redis查询失败,尝试查询http, key: ", key)-- redis查询失败,去查询httpval = read_http(path, params)end-- 返回数据return val
end
2)而后修改商品查询、库存查询的业务:

3)完整的item.lua代码:
-- 导入common函数库
local common = require('common')
local read_http = common.read_http
local read_redis = common.read_redis
-- 导入cjson库
local cjson = require('cjson')-- 封装查询函数
function read_data(key, path, params)-- 查询本地缓存local val = read_redis("127.0.0.1", 6379, key)-- 判断查询结果if not val thenngx.log(ngx.ERR, "redis查询失败,尝试查询http, key: ", key)-- redis查询失败,去查询httpval = read_http(path, params)end-- 返回数据return val
end-- 获取路径参数
local id = ngx.var[1]-- 查询商品信息
local itemJSON = read_data("item:id:" .. id, "/item/" .. id, nil)
-- 查询库存信息
local stockJSON = read_data("item:stock:id:" .. id, "/item/stock/" .. id, nil)-- JSON转化为lua的table
local item = cjson.decode(itemJSON)
local stock = cjson.decode(stockJSON)
-- 组合数据
item.stock = stock.stock
item.sold = stock.sold-- 把item序列化为json 返回结果
ngx.say(cjson.encode(item))
6. Nginx本地缓存
现在,整个多级缓存中只差最后一环,也就是nginx的本地缓存了。如图:
6.1. 本地缓存API
OpenResty为Nginx提供了 shard dict 的功能,可以在nginx的多个worker之间共享数据,实现缓存功能。
1)开启共享字典,在nginx.conf的http下添加配置:
# 共享字典,也就是本地缓存,名称叫做:item_cache,大小150mlua_shared_dict item_cache 150m;
2)操作共享字典:
-- 获取本地缓存对象
local item_cache = ngx.shared.item_cache
-- 存储, 指定key、value、过期时间,单位s,默认为0代表永不过期
item_cache:set('key', 'value', 1000)
-- 读取
local val = item_cache:get('key')
6.2. 实现本地缓存查询
1)修改/usr/local/openresty/lua/item.lua文件,修改read_data查询函数,添加本地缓存逻辑:
-- 导入共享词典,本地缓存
local item_cache = ngx.shared.item_cache-- 封装查询函数
function read_data(key, expire, path, params)-- 查询本地缓存local val = item_cache:get(key)if not val thenngx.log(ngx.ERR, "本地缓存查询失败,尝试查询Redis, key: ", key)-- 查询redisval = read_redis("127.0.0.1", 6379, key)-- 判断查询结果if not val thenngx.log(ngx.ERR, "redis查询失败,尝试查询http, key: ", key)-- redis查询失败,去查询httpval = read_http(path, params)endend-- 查询成功,把数据写入本地缓存item_cache:set(key, val, expire)-- 返回数据return val
end
2)修改item.lua中查询商品和库存的业务,实现最新的read_data函数:

其实就是多了缓存时间参数,过期后nginx缓存会自动删除,下次访问即可更新缓存。
这里给商品基本信息设置超时时间为30分钟,库存为1分钟。
因为库存更新频率较高,如果缓存时间过长,可能与数据库差异较大。
3)完整的item.lua文件:
-- 导入common函数库
local common = require('common')
local read_http = common.read_http
local read_redis = common.read_redis
-- 导入cjson库
local cjson = require('cjson')
-- 导入共享词典,本地缓存
local item_cache = ngx.shared.item_cache-- 封装查询函数
function read_data(key, expire, path, params)-- 查询本地缓存local val = item_cache:get(key)if not val thenngx.log(ngx.ERR, "本地缓存查询失败,尝试查询Redis, key: ", key)-- 查询redisval = read_redis("127.0.0.1", 6379, key)-- 判断查询结果if not val thenngx.log(ngx.ERR, "redis查询失败,尝试查询http, key: ", key)-- redis查询失败,去查询httpval = read_http(path, params)endend-- 查询成功,把数据写入本地缓存item_cache:set(key, val, expire)-- 返回数据return val
end-- 获取路径参数
local id = ngx.var[1]-- 查询商品信息
local itemJSON = read_data("item:id:" .. id, 1800, "/item/" .. id, nil)
-- 查询库存信息
local stockJSON = read_data("item:stock:id:" .. id, 60, "/item/stock/" .. id, nil)-- JSON转化为lua的table
local item = cjson.decode(itemJSON)
local stock = cjson.decode(stockJSON)
-- 组合数据
item.stock = stock.stock
item.sold = stock.sold-- 把item序列化为json 返回结果
ngx.say(cjson.encode(item))
相关文章:
多级缓存之实现多级缓存
多级缓存的实现离不开Nginx编程,而Nginx编程又离不开OpenResty。 1. OpenResty快速入门 我们希望达到的多级缓存架构如图: 其中: windows上的nginx用来做反向代理服务,将前端的查询商品的ajax请求代理到OpenResty集群 OpenRest…...

React【axios、全局处理、 antd UI库、更改主题、使用css module的情况下修改第三方库的样式、支持sass less】(十三)
文件目录 Proxying in Development http-proxy-middleware fetch_get fetch 是否成功 axios 全局处理 antd UI库 更改主题 使用css module的情况下修改第三方库的样式 支持sass & less Proxying in Development 在开发模式下,如果客户端所在服务器跟后…...
在gitlab中指定自定义 CI/CD 配置文件
文章目录 1. 介绍2. 配置操作3. 配置场景3.1 CI/CD 配置文件在当前项目step1:在当前项目中创建目录,编写流水线文件存放在该目录中step2:在当前项目中配置step3:运行流水线测试 3.2 CI/CD 配置文件位于外部站点上step1:…...
(论文阅读22/100)Learning a Deep Compact Image Representation for Visual Tracking
文献阅读笔记 简介 题目 Learning a Deep Compact Image Representation for Visual Tracking 作者 N Wang, DY Yeung 原文链接 Learning a Deep Compact Image Representation for Visual Tracking (neurips.cc) 关键词 Object tracking、DLT、SDAE 研究问题 track…...

浅谈设计模式
文章目录 一、单例模式 1.饿汉模式 2.懒汉模式 二、工厂模式 三、建造者模式 四、代理模式 设计模式是前辈们对代码开发的总结,是解决特定问题的一系列套路。它不是语法规定,而是一套用来提高代码可复用性、可维护性、可读性、稳健性以及安全性的解…...

企业年会/年终活动如何邀请媒体记者报道?
媒体邀约是企业或组织进行宣传的重要手段之一。通过邀请媒体参加活动,可以增加活动的曝光度和知名度,吸引更多的关注和参与。同时,媒体报道还可以提高企业或组织的权威性和可信度,从而让公众更容易接受其传达的信息。 企业年会或…...

C语言如何执行HTTP GET请求
在现代互联网时代,网络数据的获取和分析变得越来越重要。无论是为了研究市场趋势,还是为了收集信息进行数据分析,编写一个网络爬虫可以帮助我们自动化这一过程。在这篇文章中,我们将使用C语言和libcurl库来编写一个简单的网络爬虫…...

.Net 6 Nacos日志控制台疯狂发输出+Log4Net日志过滤
我们的项目配置了Log4Net 作为日志输出工具,在引入Nacos后,控制台和日志里疯狂输出nacos心跳日志和其他相关信息,导致自己记录的信息被淹没了,找了很多解决办法: 1、提高nacos日志级别,然后再屏蔽相应级别…...
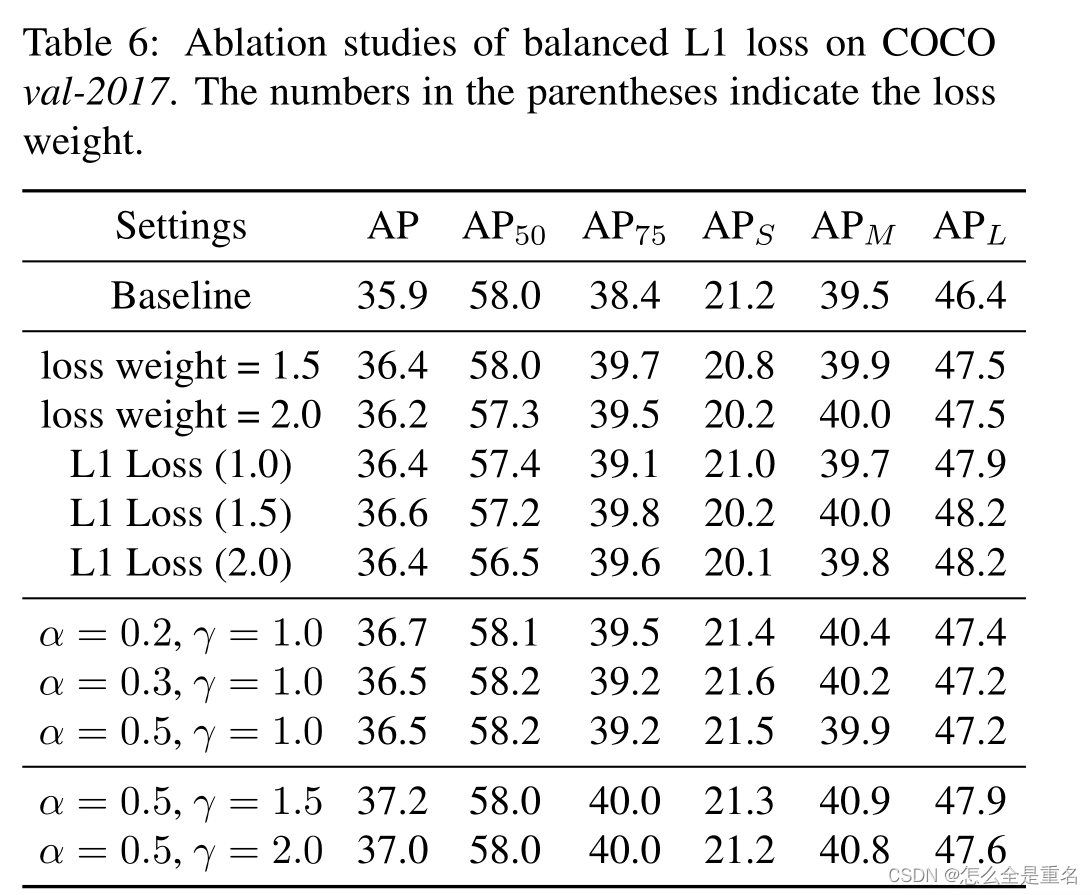
Libra R-CNN: Towards Balanced Learning for Object Detection(2019.4)
文章目录 AbstractIntroduction引入问题1) Sample level imbalance2) Feature level imbalance3) Objective level imbalance进行解决贡献 Related Work(他人的work,捎带与我们的对比)Model architectures for object detection&a…...
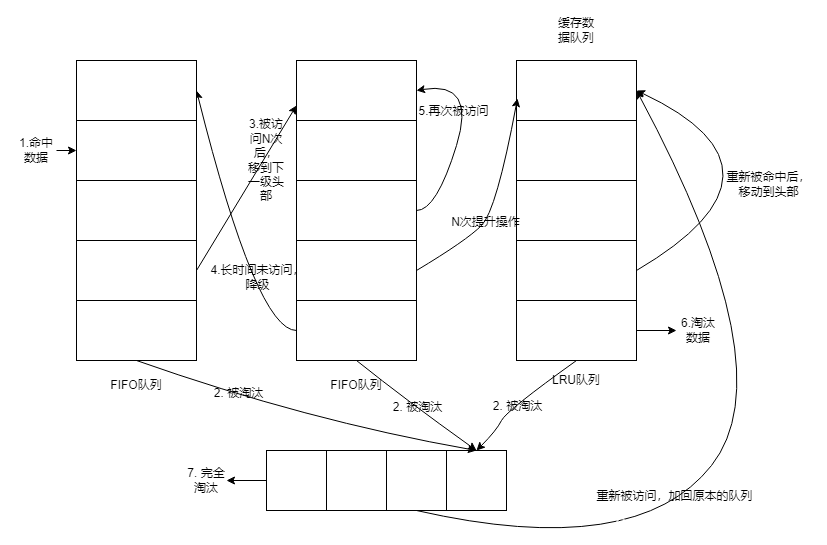
Redis的内存淘汰策略分析
概念 LRU 是按访问时间排序,发生淘汰的时候,把访问时间最久的淘汰掉。LFU 是按频次排序,一个数据被访问过,把它的频次 1,发生淘汰的时候,把频次低的淘汰掉。 几种LRU策略 以下集中LRU测率网上有很多&am…...

git命令之遭遇 ignore罕见问题解决
我先来讲讲背景 我的一些文件在ignore了,不会被提交到远程仓库,这时候我的远程仓库中是没有这几个文件的,这时候我如果使用 git reset 的话这时候除了那几个 ignore 的文件以外都被更新的,但是如果我不需要这几个被 ignore 的文件…...

torch DDP多卡训练教程记录
参考 简明教程看这里 --> pytorch分布式训练 和这篇: [PyTorch]> DDP系列第一篇:入门教程 --》 详细解答了pipeline DDP原理篇 --> DDP系列第二篇:实现原理与源代码解析 --》 主要讲 all_reduce 和 sample 的实现 减少GPU占用看这里…...
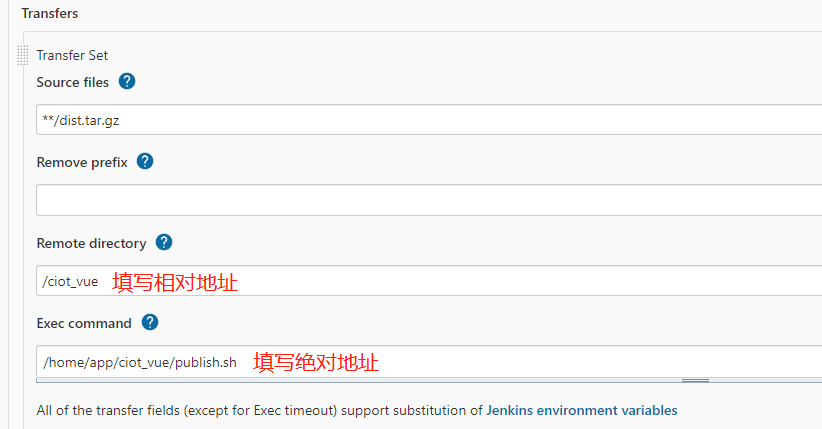
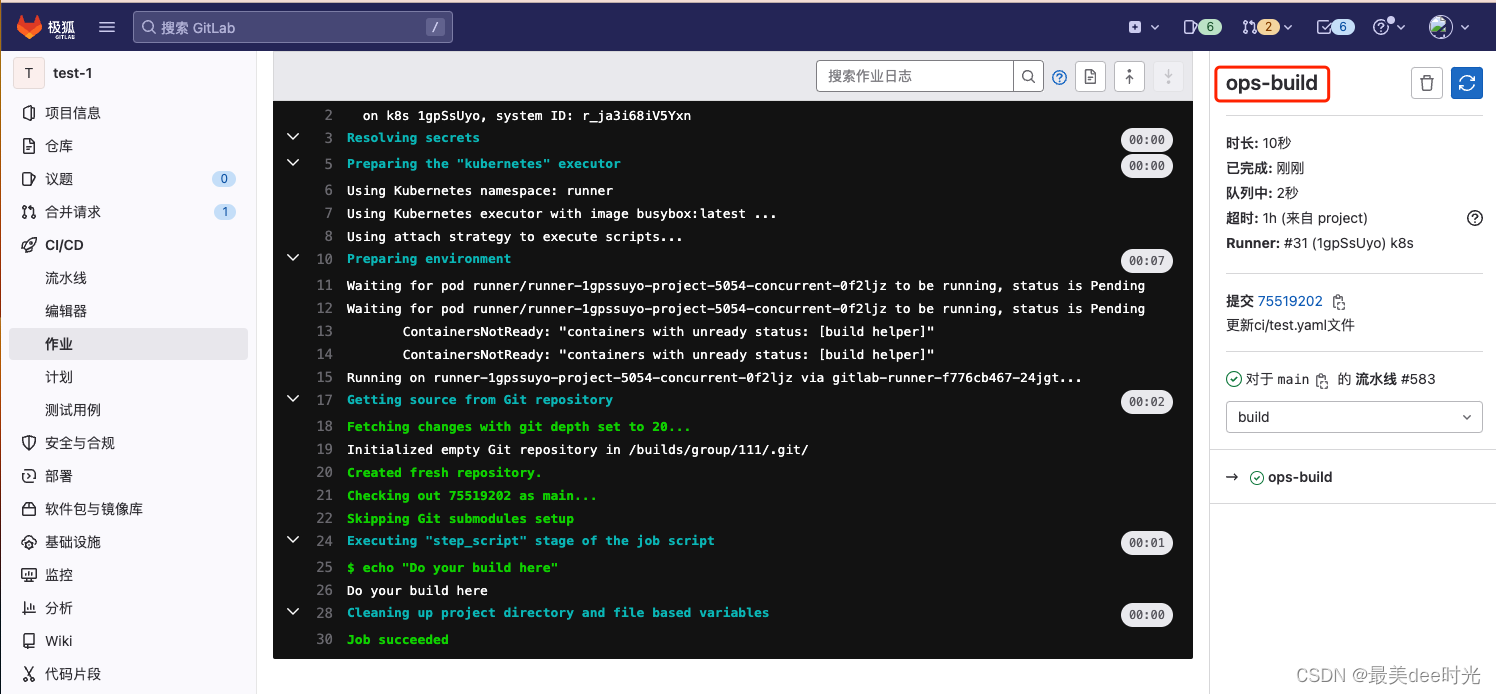
Jenkins CICD过程常见异常
1 Status [126] Exception when publishing, exception message [Exec exit status not zero. Status [126] 1.1 报错日志 SSH: EXEC: STDOUT/STDERR from command [/app/***/publish.sh] ... bash: /app/***/publish.sh: Permission denied SSH: EXEC: completed after 200…...

Java11新增特性
前言 在前面的文章中,我们已经介绍了 Java9的新增特性 和 Java10的新增特性 ,下面我们书接上文,来介绍一下Java11的新增特性 版本简介 Java 11 是 Java 平台的最新版本,于2018年9月25日发布。这个版本是自Java 8以来最重要的更新之一&…...
)
安卓常见设计模式13------过滤器模式(Kotlin版)
W1 是什么,什么是过滤器模式? 过滤器模式(Filter Pattern)是一种常用的结构型设计模式,用于根据特定条件过滤和筛选数据。 2. W2 为什么,为什么需要使用过滤器模式,能给我们编码带来什么好处…...

使用spark进行递归的可行方案
在实际工作中会遇到,最近有需求将产品炸开bom到底层,但是ERP中bom数据在一张表中递归存储的,不循环展开,是无法知道最底层原材料是什么。 在ERP中使用pl/sql甚至sql是可以进行炸BOM的,但是怎么使用spark展开࿰…...
Spring -Spring之依赖注入源码解析(下)--实践(流程图)
IOC依赖注入流程图 注入的顺序及优先级:type-->Qualifier-->Primary-->PriOriry-->name...

前端设计模式之【单例模式】
文章目录 前言介绍实现单例模式优缺点?后言 前言 hello world欢迎来到前端的新世界 😜当前文章系列专栏:前端设计模式 🐱👓博主在前端领域还有很多知识和技术需要掌握,正在不断努力填补技术短板。(如果出…...

设备零部件更换ar远程指导系统加强培训效果
随着科技的发展,AR技术已经成为了一种广泛应用的新型技术。AR远程指导系统作为AR技术的一种应用,具有非常广泛的应用前景。 一、应用场景 气象监测AR教学软件适用于多个领域,包括气象、环境、地理等。在教学过程中,软件可以帮助学…...

文本生成高精准3D模型,北京智源AI研究院等出品—3D-GPT
北京智源AI研究院、牛津大学、澳大利亚国立大学联合发布了一项研究—3D-GPT,通过文本问答方式就能创建高精准3D模型。 据悉,3D-GPT使用了大语言模型的多任务推理能力,通过任务调度代理、概念化代理和建模代理三大模块,简化了3D建模的开发流程…...

XueQiuSuperSpider扩展开发教程:从零开始构建自定义Mapper组件
XueQiuSuperSpider扩展开发教程:从零开始构建自定义Mapper组件 【免费下载链接】XueQiuSuperSpider 雪球股票信息超级爬虫 项目地址: https://gitcode.com/gh_mirrors/xu/XueQiuSuperSpider XueQiuSuperSpider是一款功能强大的雪球股票信息超级爬虫ÿ…...
)
手把手教你用Keil MDK5和STM32F103ZET6给LVGL v7.1.0安个家(附DMA加速技巧)
STM32F103ZET6实战:Keil MDK5环境下的LVGL v7.1.0移植与DMA加速全解析 当一块800480的LCD屏幕遇上仅有64KB RAM的STM32F103ZET6,图形界面开发似乎成了不可能的任务。这正是LVGL(Light and Versatile Graphics Library)展现魔力的…...

【微软内部验证通过】:C# 14 原生 AOT 部署 Dify 客户端的5步黄金流程,从本地构建到K8s Pod就绪仅需83秒
第一章:C# 14 原生 AOT 部署 Dify 客户端生产环境部署总览C# 14 原生 AOT(Ahead-of-Time)编译能力显著提升了 .NET 应用在边缘与云原生场景下的启动性能与资源占用表现。当用于封装 Dify 的 RESTful 客户端时,AOT 可将 C# 客户端代…...

Rust 并发模型中的所有权转移
Rust 并发模型中的所有权转移 在并发编程中,数据竞争和内存安全问题一直是困扰开发者的难题。Rust 语言通过独特的所有权机制,为并发编程提供了高效且安全的解决方案。所有权转移是 Rust 并发模型的核心之一,它确保数据在多线程环境下安全传…...

宗格替尼Zongertinib说明书深度解析:HER2突变非小细胞肺癌的靶向新星与腹泻、皮疹分级管理
在非小细胞肺癌(NSCLC)的治疗领域,HER2突变型肺癌一直是一块难啃的“硬骨头”。这类患者约占所有NSCLC的2%-4%,其肿瘤往往进展迅速、侵袭性强,且对传统化疗和免疫治疗反应不佳。然而,随着靶向治疗的发展&am…...
)
STM32CubeMX LL库串口通信避坑指南:从配置到中断处理的完整流程(基于STM32F103)
STM32CubeMX LL库串口通信避坑指南:从配置到中断处理的完整流程(基于STM32F103) 当你第一次用STM32CubeMX生成LL库串口通信代码时,是否遇到过这样的场景:代码编译一切正常,下载到板子后却发现串口死活不工作…...

别再混淆了!光学检测中PV、RMS、标准差到底怎么算?手把手教你用Excel验证Zemax结果
光学检测核心指标实战指南:从Excel验证到Zemax结果解析 在光学元件加工与检测领域,面形误差的量化评估直接关系到成像系统的最终性能。当我们拿到一份检测报告或仿真数据时,那些看似简单的PV、RMS数值背后,其实隐藏着复杂的计算逻…...
)
SEO老鸟的避坑指南:从‘降权’到‘索引暴跌’,我踩过的10个坑和补救方法(附真实案例)
SEO老鸟的避坑指南:从‘降权’到‘索引暴跌’,我踩过的10个坑和补救方法 在SEO这个看似简单实则暗藏玄机的领域里,每个从业者都像在走钢丝——一边是算法的不断更新,一边是老板对排名的执着追求。记得2018年我接手一个电商项目时&…...

终极PrivateGPT批量部署指南:多实例管理与资源分配的完整方案
终极PrivateGPT批量部署指南:多实例管理与资源分配的完整方案 【免费下载链接】privateGPT Interact with your documents using the power of GPT, 100% privately, no data leaks 项目地址: https://gitcode.com/GitHub_Trending/pr/privateGPT PrivateGPT…...

如何快速掌握HiveWE:魔兽地图编辑的完整创作指南
如何快速掌握HiveWE:魔兽地图编辑的完整创作指南 【免费下载链接】HiveWE A Warcraft III world editor. 项目地址: https://gitcode.com/gh_mirrors/hi/HiveWE 还在为魔兽争霸III地图制作而烦恼吗?HiveWE作为一款专注于速度和易用性的魔兽争霸II…...