手写链表C++
目录
一、链表基本概念以及注意事项
1.1 构造函数与析构函数
1.2 插入元素
1.3 重载运算符
二、小结
一、链表基本概念以及注意事项
在工作中,链表是一种常见的数据结构,可以用于解决很多实际问题。在学习中,掌握链表可以提高编程能力和算法思维能力。在面试中,手写链表是一个常考的知识点,能够考察应聘者的编程水平和代码实现能力。因此,掌握手写C++链表对于程序员来说是非常重要的。
C++链表,一种重要的数据结构,由一系列节点构成,每个节点包含两部分:数据和指向下一个节点的指针。链表是一种物理存储单元上非连续、非顺序的存储结构,数据结构的逻辑顺序是通过链表中的指针链接次序实现的。链表的最简单形式是单向链表,它只包含一个信息域和一个指针域。链表的优点是可以动态地分配内存空间,实现高效的数据操作。在C++中,链表的每个节点都是通过指针链接在一起,从而形成一个连续的链式结构。
使用纯C/C++实现List链表。在编写函数之前,请务必注意以下三点:
- 输入的指针、各类容器可能是空的
- 输入的容器可能只有一个元素
- 输入的容器可能有多个元素,这个是最常见的情况。
所以,为了代码安全,该加的判断都要加上。完整代码:
#include<iostream>
using namespace std;class Node
{
public:int data_;//数据阈Node* next_;//指针阈
public:Node() :data_(-1), next_(nullptr) {}
};
class List
{
public:List(){this->head_ = new Node();// 不分配空间,下面赋值是不合理的!//this->head_->data_ = 0;//多余?this->head_->next_ = nullptr;this->size_ = 0;};void insert(int pos, int value);void remove(int pos);int get_reverse_element(int reverse_pos);//链表中倒数第k个节点void reverse();int operator[](int i);void print();~List();
public:Node* head_;int size_;//维护一个size
};
//在第pos个元素前一个位置插入(创建、找到位置、入链表)
void List::insert(int pos, int value)
{if (pos < 0 || pos > size_)return;//创建新的节点接受数据Node* newnode = new Node();newnode->data_ = value;//cout << "newnode->data_ = " << *newnode->data_ << endl;newnode->next_ = nullptr;//利用辅助指针找到pos前一个节点// 其实这里不断next,无非就是希望p_curr = nullptr// 然后56行 让newnode->next_ = nullptr(这个nullptr是从head_->next 传过来的);也就是尾部插入嘛// 而循环链表 同理 让newnode->next_ = &(head_)(这个 &(head_) 是从head_->next 传过来的);Node* p_curr = head_;for (int i = 0; i < pos; i++) //这个for循环本质上是head_->next_->next_......{p_curr = p_curr->next_;}//现在p_curr就是pos前一个节点的指针阈//新节点入链表newnode->next_ = p_curr->next_;//右边p_curr->next_ = newnode;//左边size_++;
}
void List::remove(int pos)
{if (pos < 0 || pos > size_){return;}Node* p_curr = head_;for (int i = 0; i < pos; i++)// 3{p_curr = p_curr->next_;}p_curr->next_ = p_curr->next_->next_;size_--;
}//链表中倒数第k个节点
int List::get_reverse_element(int reverse_pos)
{int pos = size_ - reverse_pos;Node* p_curr = head_;for (int i = 0; i < pos; i++){p_curr = p_curr->next_;}return p_curr->data_;
}//反转链表
void List::reverse()
{// head -> 1 -> 2 -> 3 -> 4 -> nullptr//nullptr <- 1 <- 2 <- 3 <- 4Node* p_curr = head_->next_;Node* p_prev = nullptr;while (p_curr != nullptr){Node* p_next = p_curr->next_;if (p_next == nullptr)if (p_curr->next_ == nullptr){head_->next_ = p_curr;}p_curr->next_ = p_prev;p_prev = p_curr;p_curr = p_next;}
}
int List::operator[](int i)
{Node* p_curr = head_;int count = 0;while (count <= i){p_curr = p_curr->next_;count++;}return p_curr->data_;
}
void List::print()
{if (size_ == 0){cout << "size = 0" << endl;return;}//遍历Node* p_curr = head_->next_;//【注意这里next】while (p_curr != nullptr){cout << p_curr->data_ << " ";p_curr = p_curr->next_;}cout << endl;
}
List::~List()
{while (size_ != 0){Node* p_curr = head_;for (int i = 0; i < (size_ - 1); i++)// 012345 i < 5{p_curr = p_curr->next_;//for循环执行完,p_curr指向4}delete p_curr->next_;//删除最后一个元素p_curr->next_ = nullptr;//末尾元素 空指针size_--;print();}delete head_; //【这个容易忘记!】cout << "delete!" << endl;
}//合并两个排序链表
void mergeLists(List& list3, List& list4, List& list34)
{Node* p_curr3 = list3.head_->next_;Node* p_curr4 = list4.head_->next_;Node* p_curr34 = list34.head_->next_;int location = 0;while ((p_curr3 != nullptr) || (p_curr4 != nullptr)){if ((p_curr3 != nullptr) && (p_curr4 != nullptr)){if (p_curr3->data_ < p_curr4->data_){list34.insert(location, p_curr3->data_);location++;list34.insert(location, p_curr4->data_);location++;}else{list34.insert(location, p_curr4->data_);location++;list34.insert(location, p_curr3->data_);location++;}p_curr3 = p_curr3->next_;p_curr4 = p_curr4->next_;}else if ((p_curr3 != nullptr) && (p_curr4 == nullptr)){list34.insert(location, p_curr3->data_);location++;p_curr3 = p_curr3->next_;}else if ((p_curr3 == nullptr) && (p_curr4 != nullptr)){list34.insert(location, p_curr4->data_);location++;p_curr4 = p_curr4->next_;}}
}
int main()
{List list1;//插入for (int i = 0; i < 15; i++){list1.insert(i, i);}//删除list1.remove(10);list1.remove(5);//打印list1.print();list1.reverse();list1.print();//访问倒数元素for (int i = 1; i < 4; i++){cout << "倒数第" << i << "个元素是:" << list1.get_reverse_element(i) << endl;}list1.insert(2, 9999);//重载符[]for (int i = list1.size_ - 1; i >= 0; i--){cout << list1[i] << " ";}cout << endl;List list2;list2.insert(0, 10);list2.insert(1, 20);list2.insert(2, 30);list2.print();int size2 = list2.size_;//合并两个排序链表List list3, list4;for (int i = 0; i < 5; i++){list3.insert(i, 2 * i);list4.insert(i, 2 * i + 1);}list4.insert(5, 12);list4.insert(6, 21);list3.print();list4.print();List list34;mergeLists(list3, list4, list34);list34.print();return 1;
}1.1 构造函数与析构函数
链表由多个Node节点组成 ,每个节点由数据和指针构成。其中,指针是下一个连接节点的地址。其中Node初始化数据一定要做,如下。
class Node
{
public:int data_;//数据阈Node* next_;//指针阈
public:Node():data_(-1), next_(nullptr){}
};List的构造函数实现,这里给头节点申请内存,size_参数初始化为0,后续每插入一个元素,就+1。
List()
{this->head_ = new Node();// 分配空间this->size_ = 0;
};整个链表,实现任何功能,我们都要维护一个头节点和size_。析构函数如下,必须是串行的方式析构每一个节点,不然可能造成内存泄漏。
List::~List()
{while (size_ != 0){Node* p_curr = head_;for (int i = 0; i < (size_ - 1); i++)// 012345 i < 5{p_curr = p_curr->next_;//for循环执行完,p_curr指向4}delete p_curr->next_;//删除最后一个元素p_curr->next_ = nullptr;//末尾元素 空指针size_--;print();}delete head_; //cout << "delete!" << endl;
}在保证不断链的前提下;释放整个链表,似乎只能从后面开始delete。循环当中,每次遍历到 待删除节点前一个p_curr, 然后delete p_curr->next_
1.2 插入元素
//在第pos个元素前一个位置插入(创建、找到位置、入链表)
void List::insert(int pos, int value)
{if (pos < 0 || pos > size_)return;//创建新的节点接受数据Node* newnode = new Node();newnode->data_ = value;Node* p_curr = head_;for (int i = 0; i < pos; i++){p_curr = p_curr->next_;}//新节点入链表newnode->next_ = p_curr->next_;p_curr->next_ = newnode;size_++;
}18行、19行代码很好诠释了插入过程;其中18行代码:将当前节点的指针域指向 对象的地址 赋给 newnode->next_;保证了新数据与链表中后面连接;
19行代码:当前节点指针域指向 新的节点。例如: 1 2 3 4 5 要在 4 和 5 之间插入 一个 666,步骤如下:
- 遍历至节点4; 1 2 3 4 5
- 将666 指向5:; 1 2 3 4 666 5
- 再将 4 指向 666; 1 2 3 4 666 5
1.3 重载运算符
C++ STL中的List是不能通过[ ]来访问元素的,只有vector可以。本文这里给自定义的List重载一个 [ ],实现类似:arr[2]来访问元素的方法。
int List::operator[](int i)
{Node* p_curr = head_;int count = 0;while (count <= i){p_curr = p_curr->next_;count++;}return p_curr->data_;
}二、小结
本文我们将实现最基础的List。List是一个常见的数据结构,用于存储有序的元素集合。在C++中,我们可以使用类和指针来实现List。
下一篇文章将带来《C++ 实现List的反转、删除、合并》。这些操作在面试中经常被问到,因为它们是List的基本操作之一。通过反转、删除和合并List,我们可以更加深入地了解List的实现方式和应用场景。同时,这些操作也是许多算法的基础,例如排序、查找等。因此,掌握这些操作对于面试和实际应用都非常重要。
在接下来的文章中,我们将介绍如何实现List的反转、删除和合并。如果您对这些操作感兴趣,敬请关注我们的下一篇文章!
相关文章:

手写链表C++
目录 一、链表基本概念以及注意事项 1.1 构造函数与析构函数 1.2 插入元素 1.3 重载运算符 二、小结 一、链表基本概念以及注意事项 在工作中,链表是一种常见的数据结构,可以用于解决很多实际问题。在学习中,掌握链表可以提高编程能力和…...

为什么我一直是机器视觉调机仔,为什么一定要学一门高级语言编程?
为什么我是机器视觉调机仔,为什么一定要学一门高级语言编程,以后好不好就业,待遇高不高,都是跟这项技术没关系,是跟这个技术背后的行业发展有关系。 你可以选择离机器视觉行业,也可以选择与高级语言相关…...
)
MongoDB单实例安装(Linux)
实战环境 centos7系统、64位 iptables和selinux关闭 mongodb简介 mongodb是个非关系型数据库,但操作跟关系型数据最类似。mysql是关系型数据库 mongodb是面向文档存储的非关系型数据库,数据以json的格式进行存储 mongodb可用来永久存储,也可用…...

各种业务场景调用API代理的API接口教程(附带电商平台api接口商品详情数据接入示例)
API代理的API接口在各种业务场景中具有广泛的应用,本文将介绍哪些业务场景可以使用API代理的API接口,并提供详细的调用教程和代码演示,同时,我们还将讨论在不同场景下使用API代理的API接口所带来的好处。 哪些业务场景可以使用API…...

React-hooks有哪些 包括用法是什么?
React Hooks是React 16.8版本引入的功能,它允许你在函数组件中使用状态(state)和其他React特性,而无需编写类组件。以下是一些常用的React Hooks及其用法: 1:useState:用于在函数组件中添加状态…...
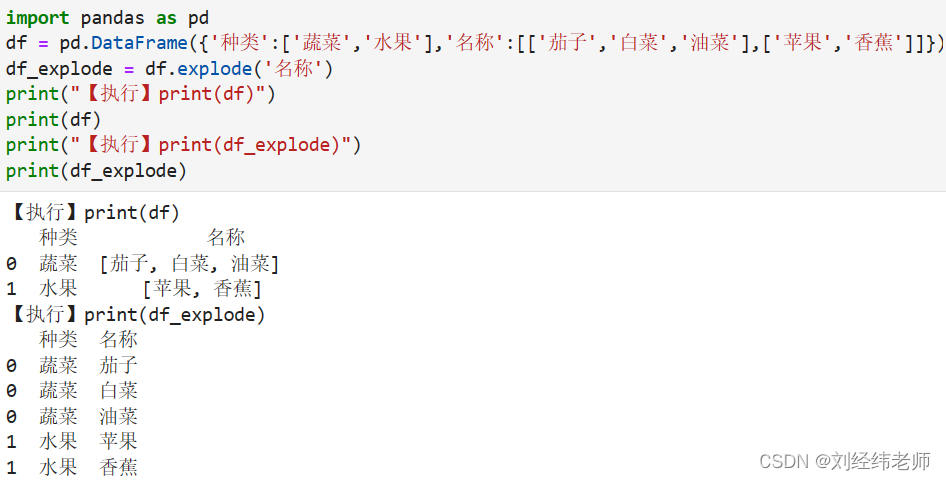
根据DataFrame指定的列该列中如果有n个不同元素则将其转化为n行显示explode()
【小白从小学Python、C、Java】 【计算机等考500强证书考研】 【Python-数据分析】 根据DataFrame指定的列 该列中如果有n个不同元素 则将其转化为n行显示 explode() 选择题 以下代码两次输出结果分别为几行? import pandas as pd df pd.DataFrame({种类:[蔬菜,水…...
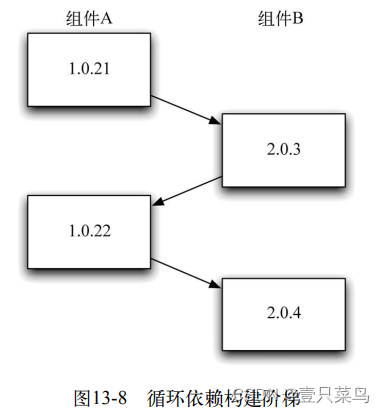
《持续交付:发布可靠软件的系统方法》- 读书笔记(十三)
持续交付:发布可靠软件的系统方法(十三) 第 13 章 组件和依赖管理13.1 引言13.2 保持应用程序可发布13.2.1 将新功能隐蔽起来,直到它完成为止13.2.2 所有修改都是增量式的13.2.3 通过抽象来模拟分支 13.3 依赖13.3.1 依赖地狱13.3…...
【Copilot】登录报错 Extension activation failed: “No auth flow succeeded.“(VSCode)
问题描述 Visual Studio Code 登录 GitHub Copilot 插件报错。 在浏览器中成功授权 GitHub 账户,返回 VSCode 后仍然报错。 [ERROR] [default] [2023-11-06T12:34:56.185Z] Extension activation failed: "No auth flow succeeded."原因分析 网络环境问…...

uboot - 驱动开发 - dw watchdog
说明 公司SOC使用的watchdog模块是新思(Synopsys)的IP。 需求 用户有时会在uboot/kernel中做些开发,新增一些功能(OTA升级等),可能会出现uboot/kernel启动崩溃甚至设备死机等问题,需要在uboo…...

【系统架构设计】架构核心知识: 2.5 软件测试、系统转换计划、系统维护
目录 一 软件测试 1 静态测试 2 动态测试 3 测试 4 集成测试的策略 二...

EXPLAIN详解(MySQL)
EXPLAIN概述 EXPLAIN语句提供MySQL如何执行语句的信息。EXPLAIN与SELECT, DELETE, INSERT, REPLACE和UPDATE语句一起工作。 EXPLAIN返回SELECT语句中使用的每个表的一行信息。它按照MySQL在处理语句时读取表的顺序列出了输出中的表。MySQL使用嵌套循环连接方法解析所有连接。…...
[PyTorch][chapter 61][强化学习-免模型学习 off-policy]
前言: 蒙特卡罗的学习基本流程: Policy Evaluation : 生成动作-状态轨迹,完成价值函数的估计。 Policy Improvement: 通过价值函数估计来优化policy。 同策略(one-policy):产生 采样轨迹的策略 和要改…...

【服务器学习】 iomanager IO协程调度模块
iomanager IO协程调度模块 以下是从sylar服务器中学的,对其的复习; 参考资料 继承自协程调度器,封装了epoll,支持为socket fd注册读写事件回调函数 IO协程调度还解决了调度器在idle状态下忙等待导致CPU占用率高的问题。IO协程调…...

前端设计模式之【迭代器模式】
文章目录 前言介绍实现接口优缺点应用场景后言 前言 hello world欢迎来到前端的新世界 😜当前文章系列专栏:前端设计模式 🐱👓博主在前端领域还有很多知识和技术需要掌握,正在不断努力填补技术短板。(如果出现错误&a…...

Linux-用户与用户组,权限
1.用户组管理(以下命令需root用户执行) ①创建用户组 groupadd 用户组名 ②删除用户组 groupdel 用户组名 2.用户管理(以下命令需root用户执行) ①创建用户 useradd [-g -d] 用户名 >-g:指定用户的组,不…...

使用nvm-windows在Windows下轻松管理多个Node.js版本
Node.js是一个非常流行的JavaScript运行时环境,许多开发者在开发过程中可能需要在不同的Node.js版本之间进行切换。在Windows操作系统下,我们可以使用nvm-windows来轻松管理多个Node.js版本。本文将详细介绍如何安装和使用nvm-windows。 什么是nvm-wind…...

2023.11.10 hadoop,hive框架概念,基础组件
目录 分布式和集群的概念: hadoop架构的三大组件:Hdfs,MapReduce,Yarn 1.hdfs 分布式文件存储系统 Hadoop Distributed File System 2.MapReduce 分布式计算框架 3.Yarn 资源调度管理框架 三个组件的依赖关系是: hive数据仓库处理工具 hive的大体流程: Apache hive的…...
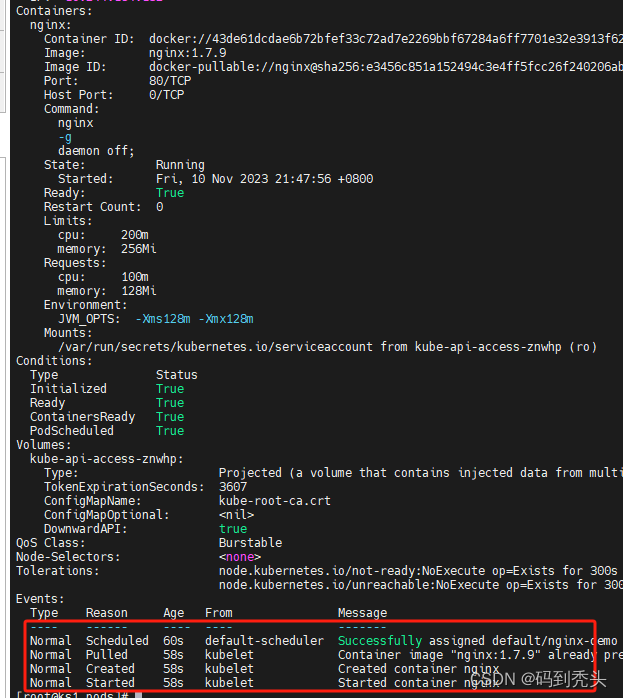
Kubernetes 创建pod的yaml文件-简单版-nginx
apiVersion: v1 #api文档版本 kind: Pod # 资源类型 Deployment,StatefulSet之类 metadata: #pod元数据 描述信息 name: nginx-demo labels: type: app #自定义标签 version: 1.0.0 # 自定义pod版本 namespace: default spec: #期望Pod按照这里的描述创建 cont…...
Git的进阶操作,在idea中部署gie
🏅我是默,一个在CSDN分享笔记的博主。📚📚 🌟在这里,我要推荐给大家我的专栏《git》。🎯🎯 🚀无论你是编程小白,还是有一定基础的程序员,这…...
)
设计模式-迭代器模式(Iterator)
设计模式-迭代器模式(Iterator) 一、迭代器模式概述1.1 什么是迭代器模式1.2 简单实现迭代器模式1.3 使用迭代器模式的注意事项 二、迭代器模式的用途三、迭代器模式实现方式3.1 使用Iterator接口实现迭代器模式3.2 使用Iterable接口和Iterator接口实现迭…...

react-native-shared-element 性能优化技巧:避免闪烁和提升动画流畅度
react-native-shared-element 性能优化技巧:避免闪烁和提升动画流畅度 【免费下载链接】react-native-shared-element Native shared element transition "primitives" for react-native 💫 项目地址: https://gitcode.com/gh_mirrors/re/re…...

终极指南:Snap.Hutao - 让原神玩家效率翻倍的Windows桌面工具箱
终极指南:Snap.Hutao - 让原神玩家效率翻倍的Windows桌面工具箱 【免费下载链接】Snap.Hutao 实用的开源多功能原神工具箱 🧰 / Multifunctional Open-Source Genshin Impact Toolkit 🧰 项目地址: https://gitcode.com/GitHub_Trending/sn…...

LVGL滚动卡住了?可能是你没搞懂Tile View的`lv_tileview_add_element`用法
LVGL滚动卡住了?可能是你没搞懂Tile View的lv_tileview_add_element用法 在嵌入式GUI开发中,LVGL的Tile View控件是一个非常实用的组件,它允许用户通过滑动在不同的"瓦片"之间导航。然而,很多开发者在初次使用Tile View…...

如何实现Amlogic S9XXX设备内核版本迁移:从5.15到6.6的平滑升级指南
如何实现Amlogic S9XXX设备内核版本迁移:从5.15到6.6的平滑升级指南 【免费下载链接】amlogic-s9xxx-armbian Supports running Armbian on Amlogic, Allwinner, and Rockchip devices. Support a311d, s922x, s905x3, s905x2, s912, s905d, s905x, s905w, s905, s9…...
)
新手避坑指南:用PHPStudy在Windows上快速搭建Pikachu靶场(附常见错误解决)
新手避坑指南:用PHPStudy在Windows上快速搭建Pikachu靶场(附常见错误解决) 在网络安全学习的过程中,搭建本地靶场环境是每个初学者必须掌握的技能。Pikachu靶场作为一个专为Web安全学习设计的漏洞演示平台,包含了SQL注…...
)
别再手动示教了!用RobotStudio的Offs函数搞定ABB机器人复杂码垛(附完整RAPID代码)
告别示教噩梦:用RobotStudio的Offs函数实现ABB机器人智能码垛 在工业自动化领域,码垛作业是最常见也最耗时的任务之一。传统的手动示教方式需要工程师逐个点位进行示教,不仅效率低下,而且容易出错。想象一下,面对一个3…...

SpringBoot+MyBatis项目实战复盘:我如何用一周时间搞定一个旅行社管理后台?
SpringBootMyBatis项目实战复盘:一周交付旅行社管理后台的六个关键决策 当产品经理在周一晨会上抛出"两周内上线旅行社管理系统"的需求时,我意识到这不仅是技术挑战,更是效率优化的绝佳实验场。作为经历过传统SSH框架折磨的开发者&…...

如何快速备份微信聊天记录:终极完整导出指南
如何快速备份微信聊天记录:终极完整导出指南 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 你是否曾因为手机丢失或更换设备,而遗憾地丢失了重要…...

RexUniNLU在客户服务工单自动分类中的实战应用
RexUniNLU在客户服务工单自动分类中的实战应用 客户服务工单处理效率直接影响用户体验和企业运营成本,传统人工分类方式面临效率低、准确率不稳定等痛点 在现代客户服务体系中,工单处理是第一道也是最重要的环节之一。每天,客服团队需要处理大…...

SQL和NOSQL数据库对比
SQL 与 NoSQL 数据库详细对比 SQL(关系型数据库)和 NoSQL(非关系型数据库)是当前数据存储领域的两大类解决方案。它们在数据模型、查询语言、事务支持、扩展方式和适用场景上存在根本差异。以下从多个维度进行全面对比。 一、定义与核心特征 SQL 数据库(关系型) 数据模…...