Hive 知识点八股文记录 ——(二)优化
函数
UDF:用户定义函数
UDAF:用户定义聚集函数
UDTF:用户定义表生成函数
建表优化
分区建桶
- 创建表时指定分区字段
PARTITIONED BY (date string) - 指定分桶字段和数量 ·CLUSTERED BY (id) INTO 10 BUCKETS·
- 插入数据按分区、分桶字段插入
提高查询速度(查询范围减少),数据聚集性增强,减少连接操作数据流传输
Union
Union
- 去重
- 排序
- 性能较低
Union all - 不去重
- 不排序
优化
压缩
- map阶段压缩(orcfile/parquet算法)
set hive.exec.compress.intermediate=true
set mapred.map.output.compression.codec= org.apache.hadoop.io.compress.SnappyCodec
set mapred.map.output.compression.codec=com.hadoop.compression.lzo.LzoCodec;- 输出结果压缩(snappy)
set hive.exec.compress.output=true
set mapred.output.compression.codec=org.apache.hadoop.io.compress.SnappyCodec
- 建表时候压缩
环境参数
参数优化
// 让可以不走mapreduce任务的,就不走mapreduce任务
hive> set hive.fetch.task.conversion=more;// 开启任务并行执行set hive.exec.parallel=true;
// 解释:当一个sql中有多个job时候,且这多个job之间没有依赖,则可以让顺序执行变为并行执行(一般为用到union all的时候)// 同一个sql允许并行任务的最大线程数
set hive.exec.parallel.thread.number=8;// 设置jvm重用
// JVM重用对hive的性能具有非常大的 影响,特别是对于很难避免小文件的场景或者task特别多的场景,这类场景大多数执行时间都很短。jvm的启动过程可能会造成相当大的开销,尤其是执行的job包含有成千上万个task任务的情况。
set mapred.job.reuse.jvm.num.tasks=10; // 合理设置reduce的数目
// 方法1:调整每个reduce所接受的数据量大小
set hive.exec.reducers.bytes.per.reducer=500000000; (500M)
// 方法2:直接设置reduce数量
set mapred.reduce.tasks = 20// map端聚合,降低传给reduce的数据量set hive.map.aggr=true
// 开启hive内置的数倾优化机制set hive.groupby.skewindata=truesql
where
where条件优化,join的过程中,对小表先进行where操作(where条件在map端执行),再与另一个表join,而非先join再where
# 优化前
select m.cid,u.id from order m join customer u on( m.cid =u.id )where m.dt='20180808';
# 优化后
select m.cid,u.id from (select * from order where dt='20180818') m join customer u on( m.cid =u.id)
union
少用union,多用union all+group by组合
count distinc
调整为
count(1) from (select col group by col)
in
只需要查询单个列是否出现在别的表的情况
in代替join
select a from t1 where a in (select a in t2)
子查询
group by, count(distinct) max, min可减少job数量
数据倾斜
任务进度长时间维持在99%(或100%),部分reduce子任务处理数据对比其他reduce数据过大。
key本身分布不均匀
- 字段较为集中, 使用随机值打散,
create table small_table as
select a.key
,sum(a.Cnt) as Cnt
from(select key,count(1) as Cntfrom table_namegroup by key,case when key = "较为集中的字段" then Hash(rand()) % 50else keyend
) a
group by a.key;
字段较为集中也可能出现在小表join大表情况,可以将小表存入内存再对达标进行map操作(小表存入内存是hive自己根据表大小确定的)
set hive.auto.convert.join=true; //设置 MapJoin 优化自动开启
set hive.mapjoin.smalltable.filesize=25000000 //设置小表不超过多大时开启 mapjoin 优化
空值
# 筛选出不为空值的参与关联
select * from log a join user b on a.user_id is not null and a.user_id = b.user_id
union all
select * from log c where c.user_id is null
#给空值赋值
select
*
from log a
left outer join user b
on
case when a.user_id is null then concat('hive',rand()) else a.user_id end = b.user_id;
第二个方法更好
还有一种情况是对空值聚类,这时候可以先筛选出来。1.count distinct时,将值为空的情况单独处理,如果是计算count distinct,可以不用处理,直接过滤,在最后结果中加1。 2.如果还有其他计算,需要进行group by,可以先将值为空的记录单独处理,再和其他计算结果进行union;
select
cast(count(distinct(user_id))+1 as bigint) as user_cnt
from tab_a
where user_id is not null and user_id <> ''
不同数据类型关联
产生数据倾斜(如id同时使用string和int,对id进行join操作)
方法:cast将int转换为字符串
大大表关联
先将大表分为小表再map join
select /*+mapjoin(x)*/*
from log a
left outer join (select /*+mapjoin(c)*/ d.*from ( select distinct user_id from log ) c join users d on c.user_id = d.user_id) x
on a.user_id = x.user_id;大表log使用distinct 减少user_id值,得到第一个小表。小表和user连接,得到第二个“小表”,/+mapjoin©/提示hive将c存入内存,以此类推
group by
set hive.map.aggr = true
# 配置代表开启map端聚合;
#万用参数:
set hive.groupby.skewindata=true
#本质:将一个mapreduce拆分为两个MR
第一个MR,M结果随机分布到reduce,可能相同的key分布到不同的reduce
第二个MR根据预处理数据结果,groupby key分不到reduce
多个distinct
Select day,count(distinct session_id),count(distinct user_id) from log a group by day
空间换时间,union后再用判断来统计,否则distinct会重复计算两次全表且产生数据偏移
SELECTday,COUNT(CASE WHEN type = 'session' THEN 1 ELSE NULL END) AS session_cnt,COUNT(CASE WHEN type = 'user' THEN 1 ELSE NULL END) AS user_cnt
FROM (SELECTday,session_id,'session' AS typeFROMlogUNION ALLSELECTday,user_id,'user' AS typeFROMlog
) t1
GROUP BYday;
合并小文件
map输入输出和reduce输出会产生小文件
可以设置如下内容设置map输入
set mapred.max.split.size=256000000;
//一个节点上split的至少的大小(这个值决定了多个DataNode上的文件是否需要合并)
set mapred.min.split.size.per.node=100000000;
//一个交换机下split的至少的大小(这个值决定了多个交换机上的文件是否需要合并)
set mapred.min.split.size.per.rack=100000000;
//执行Map前进行小文件合并
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
map输出和reduce输出合并
//设置map端输出进行合并,默认为true
set hive.merge.mapfiles = true
//设置reduce端输出进行合并,默认为false
set hive.merge.mapredfiles = true
//设置合并文件的大小
set hive.merge.size.per.task = 256*1000*1000
//当输出文件的平均大小小于该值时,启动一个独立的MapReduce任务进行文件merge。
set hive.merge.smallfiles.avgsize=16000000
查看sql的执行计划
explain sql
EXPLAIN [EXTENDED|CBO|AST|DEPENDENCY|AUTHORIZATION|LOCKS|VECTORIZATION|ANALYZE] query
后面可以跟以下可选参数,但不是所有版本都支持
- EXTENDED:加上 extended 可以输出有关计划的额外信息。这通常是物理信息,例如文件名。这些额外信息对我们用处不大
- CBO:输出由Calcite优化器生成的计划。CBO 从 hive 4.0.0 版本开始支持
- AST:输出查询的抽象语法树。AST 在hive 2.1.0 版本删除了,存在bug,转储AST可能会导致OOM错误,将在4.0.0版本修复
- DEPENDENCY:dependency在EXPLAIN语句中使用会产生有关计划中输入的额外信息。它显示了输入的各种属性
- AUTHORIZATION:显示所有的实体需要被授权执行(如果存在)的查询和授权失败
- LOCKS:这对于了解系统将获得哪些锁以运行指定的查询很有用。LOCKS 从 hive 3.2.0 开始支持
- VECTORIZATION:将详细信息添加到EXPLAIN输出中,以显示为什么未对Map和Reduce进行矢量化。从 Hive 2.3.0 开始支持
相关文章:
优化)
Hive 知识点八股文记录 ——(二)优化
函数 UDF:用户定义函数 UDAF:用户定义聚集函数 UDTF:用户定义表生成函数 建表优化 分区建桶 创建表时指定分区字段 PARTITIONED BY (date string)指定分桶字段和数量 CLUSTERED BY (id) INTO 10 BUCKETS插入数据按分区、分桶字段插入 …...
计算机技术专业CSIT883系统分析与项目管理介绍
文章目录 前言一、学科学习成果二、使用步骤三、最低出勤要求四、讲座时间表五、项目管理 前言 本课程介绍了信息系统开发中的技术和技术,以及与管理信息技术项目的任务相关的方法和过程。 它研究了系统分析师、客户和用户在系统开发生命周期中的互补角色。 它涵盖…...

gitlab安装地址
镜像地址: Index of /gitlab-ce/yum/el7/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror wget Index of /gitlab-ce/yum/el7/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror rpm -i gitlab-ce-15.9.1-ce.0.el7.x86_64.rpm 一直提示 &#x…...

Spark处理方法_提取文件名中的时间
需求描述 通过读取目录下的类似文件的datapath路径的文件名及文件内容,需要将读取的每一个文件的文件名日期解析出来,并作为读取当前文件内容递归读取当前文件一个df列,列名为“时间”;后面就是读一个文件,解析一下时间…...

技术分享 | 测试平台开发-前端开发之数据展示与分析
测试平台的数据展示与分析,我们主要使用开源工具ECharts来进行数据的展示与分析。 ECharts简介与安装 ECharts是一款基于JavaScript的数据可视化图表库,提供直观,生动,可交互,可个性化定制的数据可视化图表ÿ…...

NZ系列工具NZ06:VBA创建PDF文件说明
我的教程一共九套及VBA汉英手册一部,分为初级、中级、高级三大部分。是对VBA的系统讲解,从简单的入门,到数据库,到字典,到高级的网抓及类的应用。大家在学习的过程中可能会存在困惑,这么多知识点该如何组织…...

redis-cli 连接 sentinel架构的redis服务
之前一直用gui连接redis,今天在服务器连接发现redis-cli无法直接连接到redis-sentinel服务器,研究后发现多了几个步骤,如下: 假设有三个redis节点127.0.0.1,127.0.0.2,127.0.0.3,端口为9696先连接任意一个节点: redis-cli -h 12…...
使用github copilot
现在的大模型的应用太广了,作为程序员我们当然野可以借助大模型来帮我们敲代码。 下面是自己注册使用github copilot的过程。 一、注册github copilot 1. 需要拥有github账号 ,登录github之后,点右侧自己的头像位置,下面会出现…...
)
1438 绝对差不超过限制的最长连续子数组(单调队列)
题目 绝对差不超过限制的最长连续子数组 给你一个整数数组 nums ,和一个表示限制的整数 limit,请你返回最长连续子数组的长度,该子数组中的任意两个元素之间的绝对差必须小于或者等于 limit 。 如果不存在满足条件的子数组,则返…...

OpenCV入门9:图像增强和图像滤波
图像增强是一种通过对图像进行处理以改善其质量、对比度、清晰度等方面的技术。在OpenCV中,有多种图像增强的方法和函数可用。下面简要介绍一些常见的图像增强方法及其在OpenCV中的实现方式。 直方图均衡化(Histogram Equalization)ÿ…...

Pycharm常用快捷键和替换正则表达式
原生快捷键的使用: 1.CtrlF:查找 2.CtrlZ:返回上一步 3.Alt 鼠标左键选择:多行同时编辑(上、下、左、右键能够移动光标) 按住Ctrl,左键点击,定位光标 编辑过程 URL常用的替换正则表达式&am…...

C#,数值计算——函数计算,Epsalg的计算方法与源程序
1 文本格式 using System; namespace Legalsoft.Truffer { /// <summary> /// Convergence acceleration of a sequence by the algorithm.Initialize by /// calling the constructor with arguments nmax, an upper bound on the /// number of term…...

Delphi 12 重返雅典 (RAD Studio 12)
RAD Studio 12 的新功能: 以最新的平台版本为目标! RAD Studio 12 提供对 iOS 17(仅适用于 Delphi)、Android 14 和 macOS Sonoma 的官方支持。RAD Studio 12 还支持 Ubuntu 22 LTS 和 Windows Server 2022。 Delphi 源代码的多…...

手写链表C++
目录 一、链表基本概念以及注意事项 1.1 构造函数与析构函数 1.2 插入元素 1.3 重载运算符 二、小结 一、链表基本概念以及注意事项 在工作中,链表是一种常见的数据结构,可以用于解决很多实际问题。在学习中,掌握链表可以提高编程能力和…...

为什么我一直是机器视觉调机仔,为什么一定要学一门高级语言编程?
为什么我是机器视觉调机仔,为什么一定要学一门高级语言编程,以后好不好就业,待遇高不高,都是跟这项技术没关系,是跟这个技术背后的行业发展有关系。 你可以选择离机器视觉行业,也可以选择与高级语言相关…...
)
MongoDB单实例安装(Linux)
实战环境 centos7系统、64位 iptables和selinux关闭 mongodb简介 mongodb是个非关系型数据库,但操作跟关系型数据最类似。mysql是关系型数据库 mongodb是面向文档存储的非关系型数据库,数据以json的格式进行存储 mongodb可用来永久存储,也可用…...

各种业务场景调用API代理的API接口教程(附带电商平台api接口商品详情数据接入示例)
API代理的API接口在各种业务场景中具有广泛的应用,本文将介绍哪些业务场景可以使用API代理的API接口,并提供详细的调用教程和代码演示,同时,我们还将讨论在不同场景下使用API代理的API接口所带来的好处。 哪些业务场景可以使用API…...

React-hooks有哪些 包括用法是什么?
React Hooks是React 16.8版本引入的功能,它允许你在函数组件中使用状态(state)和其他React特性,而无需编写类组件。以下是一些常用的React Hooks及其用法: 1:useState:用于在函数组件中添加状态…...
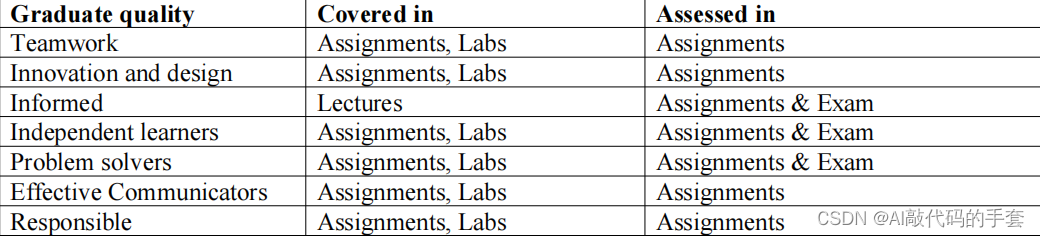
根据DataFrame指定的列该列中如果有n个不同元素则将其转化为n行显示explode()
【小白从小学Python、C、Java】 【计算机等考500强证书考研】 【Python-数据分析】 根据DataFrame指定的列 该列中如果有n个不同元素 则将其转化为n行显示 explode() 选择题 以下代码两次输出结果分别为几行? import pandas as pd df pd.DataFrame({种类:[蔬菜,水…...
《持续交付:发布可靠软件的系统方法》- 读书笔记(十三)
持续交付:发布可靠软件的系统方法(十三) 第 13 章 组件和依赖管理13.1 引言13.2 保持应用程序可发布13.2.1 将新功能隐蔽起来,直到它完成为止13.2.2 所有修改都是增量式的13.2.3 通过抽象来模拟分支 13.3 依赖13.3.1 依赖地狱13.3…...

如何在Windows上运行iOS应用:ipasim模拟器完整使用指南
如何在Windows上运行iOS应用:ipasim模拟器完整使用指南 【免费下载链接】ipasim iOS emulator for Windows 项目地址: https://gitcode.com/gh_mirrors/ip/ipasim 你是否曾经想过在Windows电脑上直接运行iOS应用?ipasim作为一款专为Windows平台设…...

HunterPie完整指南:怪物猎人世界终极叠加层工具配置与优化
HunterPie完整指南:怪物猎人世界终极叠加层工具配置与优化 【免费下载链接】HunterPie-legacy A complete, modern and clean overlay with Discord Rich Presence integration for Monster Hunter: World. 项目地址: https://gitcode.com/gh_mirrors/hu/HunterPi…...
)
从‘模糊’到‘精确’:手把手教你用频域分析搞定高斯滤波参数(附MATLAB/Python对比)
从频域视角解密高斯滤波:用频谱分析精准调参的实战指南 第一次接触高斯滤波时,你可能和我一样困惑——为什么调整那个叫"标准差"的σ参数,图像就会变得模糊?空域中那个神秘的钟形卷积核,到底是如何影响像素的…...

5分钟搞定Windows Defender永久禁用:开源工具完全指南
5分钟搞定Windows Defender永久禁用:开源工具完全指南 【免费下载链接】defender-control An open-source windows defender manager. Now you can disable windows defender permanently. 项目地址: https://gitcode.com/gh_mirrors/de/defender-control 你…...

如何用Go语言构建跨平台漫画下载工具:comics-downloader核心技术解析
如何用Go语言构建跨平台漫画下载工具:comics-downloader核心技术解析 【免费下载链接】comics-downloader tool to download comics and manga in pdf/epub/cbr/cbz from a website 项目地址: https://gitcode.com/gh_mirrors/co/comics-downloader 在数字漫…...

HY-Motion 1.0在VR开发中的应用:手势交互与动作捕捉替代方案
HY-Motion 1.0在VR开发中的应用:手势交互与动作捕捉替代方案 1. 引言 想象一下,你正在开发一款VR游戏,需要让虚拟角色做出"挥手打招呼"的动作。传统方式可能需要昂贵的动作捕捉设备,专业的动捕演员,以及数…...

解放双手的终极指南:如何用MAA自动化助手轻松管理《明日方舟》日常任务
解放双手的终极指南:如何用MAA自动化助手轻松管理《明日方舟》日常任务 【免费下载链接】MaaAssistantArknights 《明日方舟》小助手,全日常一键长草!| A one-click tool for the daily tasks of Arknights, supporting all clients. 项目地…...

别让LaTeX投稿坑了你:BSPC、BMC等期刊的隐藏规则与文件提交全解析
别让LaTeX投稿坑了你:BSPC、BMC等期刊的隐藏规则与文件提交全解析 当你熬夜修改完论文最后一处公式,满心欢喜点击投稿按钮时,系统却弹出一连串编译错误——这可能是每个LaTeX用户都经历过的噩梦。不同于Word投稿的"所见即所得"&…...

Nano Banana MCP 集成指南
MCP (Model Context Protocol) 是由 Anthropic 推出的模型上下文协议,它允许 AI 模型(如 Claude、GPT 等)通过标准化接口调用外部工具。借助 AceData Cloud 提供的 Nano Banana MCP 服务器,您可以直接在 Claude Desktop、VS Code、…...

SDMatte效果深度评测:复杂人像与发丝级抠图的惊艳表现
SDMatte效果深度评测:复杂人像与发丝级抠图的惊艳表现 1. 开篇:重新定义图像抠图标准 当你在电商平台看到完美无瑕的商品展示图,或者在电影中看到主角与虚拟场景无缝融合时,背后都离不开一项关键技术——图像抠图。传统抠图工具…...