机器学习模型超参数优化最常用的5个工具包!
优化超参数始终是确保模型性能最佳的关键任务。通常,网格搜索、随机搜索和贝叶斯优化等技术是主要使用的方法。
今天分享几个常用于模型超参数优化的 Python 工具包,如下所示:
- scikit-learn:使用在指定参数值上进行的网格搜索或随机搜索。
- HyperparameterHunter:构建在scikit-learn之上,以使其更易于使用。
- Optuna:使用随机搜索、Parzen估计器(TPE)和基于群体的训练。
- Hyperopt:使用随机搜索和TPE。
- Talos:构建在Keras之上,以使其更易于使用。
技术交流
技术要学会分享、交流,不建议闭门造车。一个人可以走的很快、一堆人可以走的更远。
本文由粉丝群小伙伴总结与分享,如果你也想学习交流,资料获取,均可加交流群获取,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。
方式①、添加微信号:dkl88194,备注:来自CSDN + 加群
方式②、微信搜索公众号:Python学习与数据挖掘,后台回复:加群
现在,让我们看一些使用这些库进行自动编码器模型超参数优化的Python代码示例:
from keras.layers import Input, Dense
from keras.models import Model# define the Autoencoder
input_layer = Input(shape=(784,))
encoded = Dense(32, activation='relu')(input_layer)
decoded = Dense(784, activation='sigmoid')(encoded)
autoencoder = Model(input_layer, decoded)
autoencoder.compile(optimizer='adam', loss='binary_crossentropy')
autoencoder.fit(X_train, X_train, epochs=100, batch_size=256, validation_data=(X_test, X_test))
scikit-learn
from sklearn.model_selection import GridSearchCV# define the parameter values that should be searched
param_grid = {'batch_size': [64, 128, 256], 'epochs': [50, 100, 150]}# create a KFold cross-validator
kfold = KFold(n_splits=10, random_state=7)# create the grid search object
grid = GridSearchCV(estimator=autoencoder, param_grid=param_grid, cv=kfold)# fit the grid search object to the training data
grid_result = grid.fit(X_train, X_train)# print the best parameters and the corresponding score
print(f'Best parameters: {grid_result.best_params_}')
print(f'Best score: {grid_result.best_score_}')
HyperparameterHunter
import HyperparameterHunter as hh# create a HyperparameterHunter object
hunter = hh.HyperparameterHunter(input_data=X_train, output_data=X_train, model_wrapper=hh.ModelWrapper(autoencoder))# define the hyperparameter search space
hunter.setup(objective='val_loss', metric='val_loss', optimization_mode='minimize', max_trials=100)
hunter.add_experiment(parameters=hh.Real(0.1, 1, name='learning_rate', digits=3, rounding=4))
hunter.add_experiment(parameters=hh.Real(0.1, 1, name='decay', digits=3, rounding=4))# perform the hyperparameter search
hunter.hunt(n_jobs=1, gpu_id='0')# print the best hyperparameters and the corresponding score
print(f'Best hyperparameters: {hunter.best_params}')
print(f'Best score: {hunter.best_score}')
Hyperopt
from hyperopt import fmin, tpe, hp# define the parameter space
param_space = {'batch_size': hp.quniform('batch_size', 64, 256, 1), 'epochs': hp.quniform('epochs', 50, 150, 1)}# define the objective function
def objective(params):autoencoder.compile(optimizer='adam', loss='binary_crossentropy')autoencoder.fit(X_train, X_train, batch_size=params['batch_size'], epochs=params['epochs'], verbose=0)scores = autoencoder.evaluate(X_test, X_test, verbose=0)return {'loss': scores, 'status': STATUS_OK}# perform the optimization
best = fmin(objective, param_space, algo=tpe.suggest, max_evals=100)# print the best parameters and the corresponding score
print(f'Best parameters: {best}')
print(f'Best score: {objective(best)}')
Optuna
import optuna# define the objective function
def objective(trial):batch_size = trial.suggest_int('batch_size', 64, 256)epochs = trial.suggest_int('epochs', 50, 150)autoencoder.compile(optimizer='adam', loss='binary_crossentropy')autoencoder.fit(X_train, X_train, batch_size=batch_size, epochs=epochs, verbose=0)score = autoencoder.evaluate(X_test, X_test, verbose=0)return score# create the Optuna study
study = optuna.create_study()# optimize the hyperparameters
study.optimize(objective, n_trials=100)# print the best parameters and the corresponding score
print(f'Best parameters: {study.best_params}')
print(f'Best score: {study.best_value}')
Talos
import talos# define the parameter space
param_space = {'learning_rate': [0.1, 0.01, 0.001], 'decay': [0.1, 0.01, 0.001]}# define the objective function
def objective(params):autoencoder.compile(optimizer='adam', loss='binary_crossentropy', lr=params['learning_rate'], decay=params['decay'])history = autoencoder.fit(X_train, X_train, epochs=100, batch_size=256, validation_data=(X_test, X_test), verbose=0)score = history.history['val_loss'][-1]return score# perform the optimization
best = talos.Scan(X_train, X_train, params=param_space, model=autoencoder, experiment_name='autoencoder').best_params(objective, n_trials=100)# print the best parameters and the corresponding score
print(f'Best parameters: {best}')
print(f'Best score: {objective(best)}')
相关文章:

机器学习模型超参数优化最常用的5个工具包!
优化超参数始终是确保模型性能最佳的关键任务。通常,网格搜索、随机搜索和贝叶斯优化等技术是主要使用的方法。 今天分享几个常用于模型超参数优化的 Python 工具包,如下所示: scikit-learn:使用在指定参数值上进行的网格搜索或…...

出口美国操作要点汇总│走美国海运拼箱的注意事项│箱讯科技
01服务标准 美国的货物需要细致的服务,货物到港后的服务也是非常重要的。如果在货物到港15天内,如果没有报关行进行(PROCEED),货物就会进入了G.O.仓库,G.O.仓库的收费标准是非常高的。 02代理资格审核 美国航线除了各家船公司&a…...
Gateway网关
Gateway网关 1、网关的位置与作用 官网:Spring Cloud Gateway Geteway是Zuul的替代, Zuul:路由和过滤Zuul最终还是会注册到Eureka Zuul网关采用同步阻塞模式不符合要求。 Spring Cloud Gateway基于Webflux,比较完美地支持异步…...

Python Opencv实践 - 车牌定位(纯练手,存在失败场景,可以继续优化)
使用传统的计算机视觉方法定位图像中的车牌,参考了部分网上的文章,实际定位效果对于我目前使用的网上的图片来说还可以。实测发现对于车身本身是蓝色、或是车牌本身上方有明显边缘的情况这类图片定位效果较差。纯练手项目,仅供参考。代码中im…...

U盘插在电脑上显示要格式化磁盘怎么办
U盘是一种便携式存储设备,广泛应用于各种场合。然而,有时候我们可能会遇到一些问题,比如将U盘插入电脑后显示要格式化磁盘,这通常意味着U盘的分区出现了问题或者U盘的文件系统已经损坏。这种情况下,我们应该如何解决呢…...
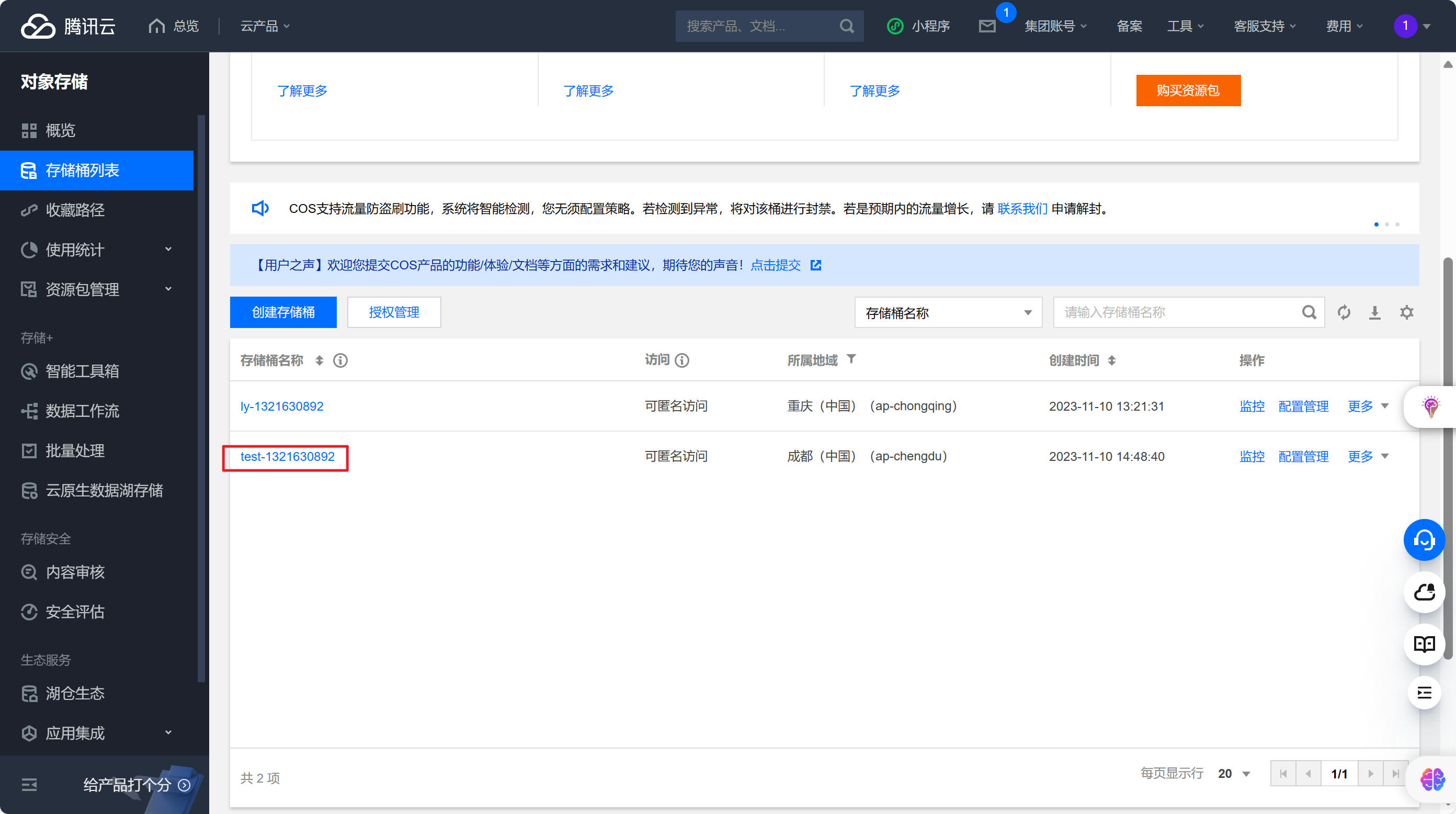
Python使用腾讯云SDK实现对象存储(上传文件、创建桶)
文章目录 1. 开通服务2. 创建存储桶3. 手动上传文件并查看4. python上传文件4.1 找到sdk文档4.2 初始化代码4.3 region获取4.4 secret_id和secret_key获取4.5 上传对象代码4.6 python实现上传文件 5 python创建桶 首先来到腾讯云官网 https://cloud.tencent.com/1. 开通服务 来…...

Springboot整合Jedis实现单机版或哨兵版可切换配置
Springboot整合Jedis实现单机版或哨兵版可切换配置 前言实现最后 前言 前文写到借助redis实现Shiro实现session限制登录数量踢人下线,本文就写一下Jedis的配置,可切换单机版和集群哨兵版,方便开发测试。 实现 很简单,直接上代码&…...

lenovo联想小新 Air-14 2019 AMD平台API版(81NJ)原装出厂Windows10系统
下载链接:https://pan.baidu.com/s/1HCC66EH4UOcgofRx5_v1oA?pwdlgqw 提取码:lgqw 原厂系统自带所有驱动、出厂主题壁纸、系统属性专属LOGO标志、Office办公软件、联想电脑管家等预装程序 所需要工具:16G或以上的U盘 文件格式…...
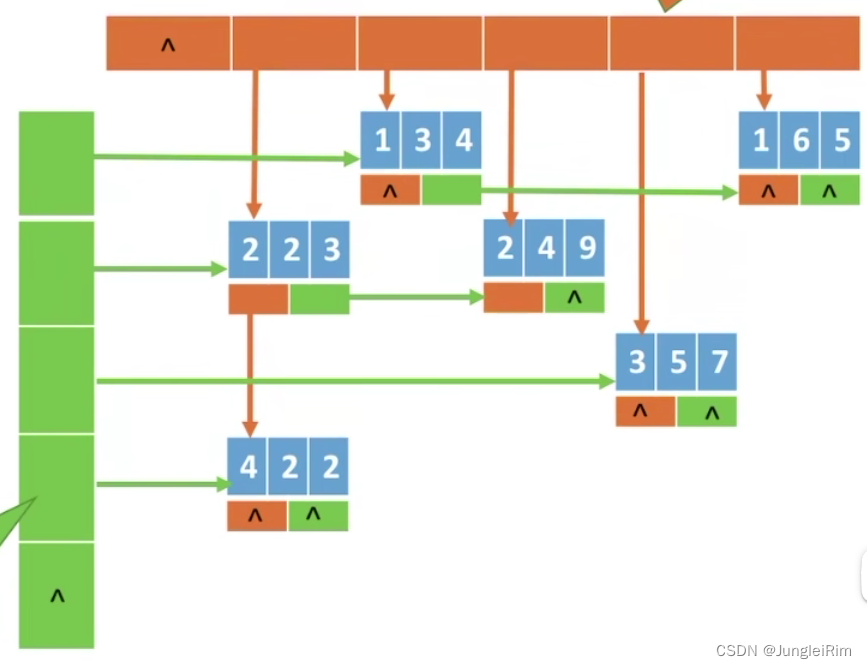
特殊矩阵的压缩存储(对称矩阵,三角矩阵,三对角矩阵,稀疏矩阵)
目录 1.数组的存储结构1.—维数组2.二维数组1.行优先存储2.列优先存储 2.特殊矩阵1.对称矩阵1.行优先存储 2.三角矩阵1.上三角矩阵2.下三角矩阵 3.三对角矩阵(带状矩阵)4.稀疏矩阵 1.数组的存储结构 1.—维数组 各数组元素大小相同,且物理上…...

DDU框架学习之路
目录 MVVM对比 DDU 数据消费者UI 数据的转换者:Domain Layer 数据图生产者/提供者 DataLayer 遵循原理: 单一数据流: Android官方推荐架构:DDU MVVM对比 M:Model 网络层 用于获取远端数据 VM:ViewModel 中间转…...
进阶课6——基于Seq2Seq的开放域生成型聊天机器人的设计和开发流程
情感聊天机器人通常属于开放领域,用户可以与机器人进行各种话题的互动。例如,微软小冰和早期的AnswerBus就是这种类型的聊天机器人。基于检索的开放领域聊天机器人需要大量的语料数据,其开发流程与基于任务型的聊天机器人相似,而基…...

Java面试题04
1.Array 和 ArrayList 有何区别? Array是固定长度的,元素类型可以是基本类型,创建后大小不可改变;ArrayList是可变长 度的,只能存储对象,可以动态添加和删除元素。 区别1: 存储类型不同 …...
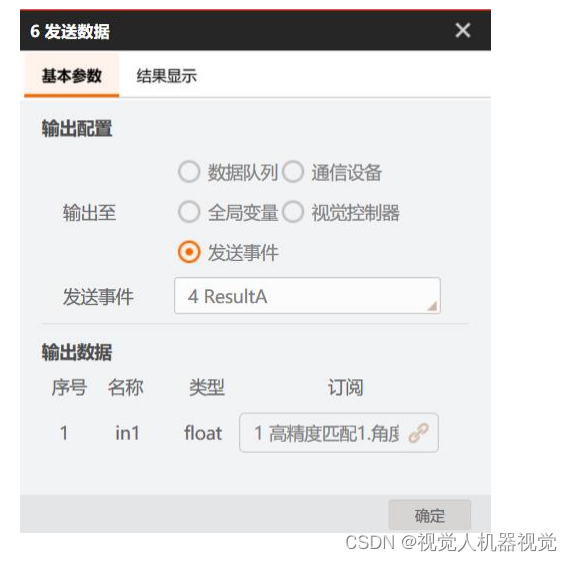
海康Visionmaster-通讯管理:使用 Modbus TCP 通讯 协议与流程交互
使用 Modbus TCP 通讯协议与视觉通讯,当地址为 0000 的保持型寄存器(4x 寄存器)变为 1 时,触发视觉流程执行一次,同时视觉将地址为 0000 的寄存器复位(也即写为 0),视觉流程执行完成后,将结果数…...

assimp中如何判断矩阵是否是单位矩阵
对于一个矩阵元素为浮点型的矩阵,你是否还在使每个元素跟1.0f或0.0f进行比较,如果这样,只能说你的结果不一定正确,那我们看看assimp中是如何做的。 template <typename TReal> AI_FORCE_INLINE bool aiMatrix4x4t<TReal…...

大数据Doris(二十):数据导入(Broker Load)介绍
文章目录 数据导入(Broker Load)介绍 一、适用场景...

Docker快速安装kafka
创建zk docker run -d --name zookeeper-server \-e ALLOW_ANONYMOUS_LOGINyes \bitnami/zookeeper:latest创建kafka docker run -d --name kafka-server \-p 9092:9092 \-e ALLOW_PLAINTEXT_LISTENERyes \-e KAFKA_CFG_ZOOKEEPER_CONNECTzookeeper-server:2181 \-e KAFKA_CF…...
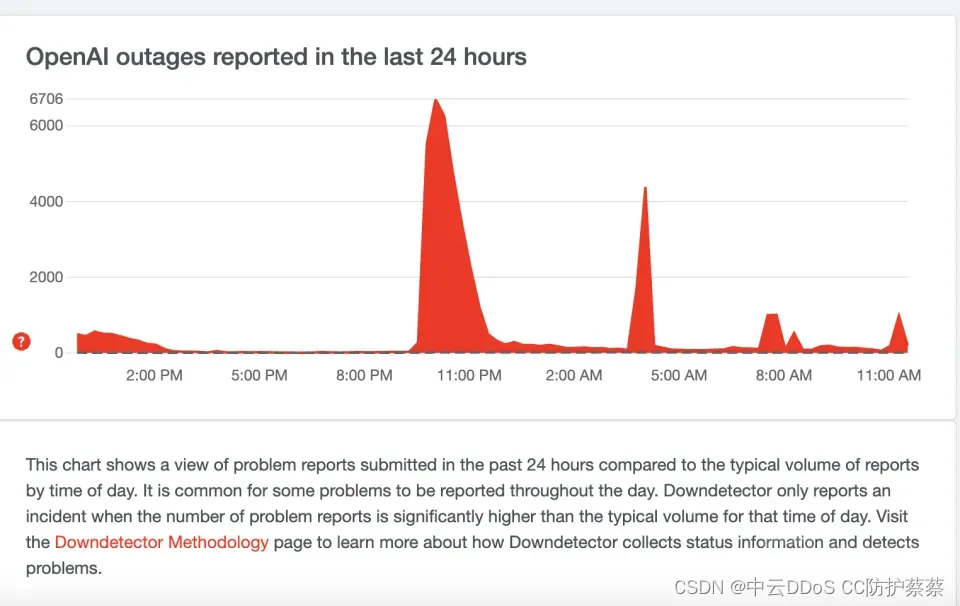
ChatGPT是什么?黑客试图淹没其服务
上线2个月,月活跃用户破亿,媒体人用它编辑文案,学生用它写作业,程序员用它编辑代码, 它是谁呢? 它就是火爆全网(chatgpt),chatgpt是什么呢,chatgpt是美国研发的一款人工…...

【Java 进阶篇】Java Web 开发之 Listener 篇:ServletContextListener 使用详解
欢迎大家来到 Java Web 开发的学习之旅!在前面的博客中,我们已经学习了 Servlet、JSP、Filter 等重要的概念和技术。今天,我们将深入探讨 Java Web 开发中另一个重要的组成部分——Listener(监听器),具体来…...

[C/C++]数据结构 链表OJ题:环形链表(如何判断链表是否有环)
题目描述: 给你一个链表的头节点 head ,判断链表中是否有环。 如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数 pos 来表示链表尾连接到链表中的位置&…...

c#流程控制
c#分支语句 namespace ConsoleApp1 {internal class Program{static void Main(string[] args){Console.WriteLine("请输入学生成绩");string sConsole.ReadLine();int aint.Parse(s);//将字符类型强制转换为int类型if (a > 90){ Console.WriteLine("成绩优…...

OpenUserJS.org 新手快速上手指南:轻松搭建用户脚本平台
OpenUserJS.org 新手快速上手指南:轻松搭建用户脚本平台 【免费下载链接】OpenUserJS.org The home of FOSS user scripts. 项目地址: https://gitcode.com/gh_mirrors/op/OpenUserJS.org OpenUserJS.org 是一个开源的用户脚本托管平台,为开发者提…...

AGI与量子计算融合的7个致命断层:2026奇点大会未公开技术白皮书首曝
第一章:AGI与量子计算融合的范式危机与奇点临界态 2026奇点智能技术大会(https://ml-summit.org) 当通用人工智能(AGI)的推理架构遭遇量子叠加态的本征坍缩机制,传统冯诺依曼—图灵范式正经历不可逆的结构性失稳。实验表明&#…...

CSS如何引入CSS暗黑模式配置_通过媒体特性实现主题自动化
直接用 media (prefers-color-scheme: dark) 媒体查询响应系统主题,支持 Chrome 76 等现代浏览器;需配合 no-preference 回退规则,并与 JS 主题控制协同:媒体查询管首次加载默认态,JS 管后续手动切换,避免冲…...

Less如何构建CSS样式库_通过继承机制优化组件化开发
Less 中 extend 用于编译时合并选择器以减少 CSS 体积,需加 all 才继承嵌套规则;不支持跨文件、参数化及深层嵌套,易导致选择器爆炸;适用样式身份固定场景,动态或差异化需求应选 mixins;大型项目须收敛入口…...

3步解锁旧Mac潜能:OpenCore Legacy Patcher完整使用指南
3步解锁旧Mac潜能:OpenCore Legacy Patcher完整使用指南 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher OpenCore Legacy Patcher是一款强大的开源…...

Android 12+ 上 NetworkStatsManager 统计应用流量,为什么你的 queryDetailsForUid 总返回0?
Android 12 流量统计实战:破解 NetworkStatsManager.queryDetailsForUid 返回0的迷局 在开发流量监控类应用时,许多开发者都会遇到一个令人抓狂的问题:明明按照官方文档调用了 queryDetailsForUid 方法,却总是得到0值返回。这就像…...

ytDownloader:如何一站式解决全网视频下载难题
ytDownloader:如何一站式解决全网视频下载难题 【免费下载链接】ytDownloader Desktop App for downloading Videos and Audios from hundreds of sites 项目地址: https://gitcode.com/GitHub_Trending/yt/ytDownloader 在当今数字时代,视频内容…...

终极百度网盘直链解析教程:免费实现10倍下载速度
终极百度网盘直链解析教程:免费实现10倍下载速度 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 厌倦了百度网盘非会员的龟速下载?想要摆脱百度网盘客户…...

异步电机控制进阶:从标量到矢量,解锁高性能工业驱动的核心
1. 异步电机控制技术演进:从基础调速到高精度驱动 第一次接触变频器时,我被操作面板上密密麻麻的参数搞懵了——为什么同样是调节电机转速,有的模式叫V/F控制,有的却标注着SVC、FOC这些英文缩写?后来在调试水泥厂风机系…...
)
Jetson Orin Nano无头模式实战:用XRDP远程桌面告别显示器(Ubuntu 22.04 + GNOME)
Jetson Orin Nano无头模式实战:XRDP远程桌面全流程配置指南 当你把Jetson Orin Nano塞进机器人底盘或者嵌入到某个工业设备中时,物理显示器往往成了最不实用的配件。但调试时盯着SSH黑窗口操作图形界面?这就像用螺丝刀吃牛排——不是不行&…...