ChatRule:基于知识图推理的大语言模型逻辑规则挖掘11.10
ChatRule:基于知识图推理的大语言模型逻辑规则挖掘
- 摘要
- 引言
- 相关工作
- 初始化和问题定义
- 方法
- 实验

摘要
逻辑规则对于揭示关系之间的逻辑联系至关重要,这可以提高推理性能并在知识图谱(KG)上提供可解释的结果。虽然已经有许多努力,挖掘有意义的逻辑规则的知识库,现有的方法遭受计算密集型搜索的规则空间和缺乏可扩展性的大规模知识库。此外,他们往往忽略了关系的语义,这是揭示逻辑连接的关键。近年来,大型语言模型(LLM)由于其涌现能力和泛化能力,在自然语言处理和各种应用领域表现出令人瞩目的性能。在本文中,我们提出了一个新的框架,ChatRule,释放大型语言模型的能力,挖掘知识图谱上的逻辑规则。具体来说,该框架是启动与基于LLM的规则生成器,利用语义和结构信息的KG提示LLM生成逻辑规则。为了细化生成的规则,规则排名模块通过合并来自现有KG的事实来估计规则质量。最后,规则验证器利用LLM的推理能力,通过思维链推理来验证排名规则的逻辑正确性。ChatRule在四个大型KG上进行了评估,w.r.t.不同的规则质量指标和下游任务,显示了我们的方法的有效性和可扩展性。
引言
知识图谱(KGs)以三元组的结构化格式存储大量的现实世界知识。KG推理旨在从现有事实中推断新知识,是KG中的一项基本任务,对许多应用至关重要,例如KG补全,问答和推荐。最近,越来越需要可解释的KG推理,它可以帮助用户理解推理过程,并提高高风险场景中的可信度,例如医疗诊断和法律的判断。因此,逻辑规则,这是人类可读的,可以推广到不同的任务,已被广泛采用的KG推理。例如,如图1所示,我们可以确定一个逻辑规则:Grandmother(X,Y)← Mother(X,Z)∧Father(Z,Y)来预测关系“Grandmother”的缺失事实。为了从KG中自动发现有意义的规则进行推理,逻辑规则挖掘在研究界得到了极大的关注(Yang,Yang和Cohen 2017; Sadeghian等人2019)。
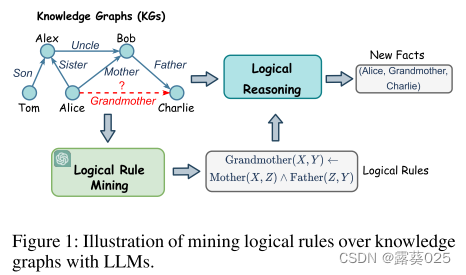
早期关于逻辑规则挖掘的研究通常通过发现KG结构中频繁模式的共现来发现逻辑规则。然而,他们通常需要列举所有可能的规则,并根据估计的重要性对它们进行排名。尽管如此,最近的研究已经提出使用深度学习方法来对规则进行排名。它们仍然受到规则详尽列举的限制,无法扩展到大型KG。
最近的一些方法通过从KG中采样路径并在其上训练模型来捕获形成规则的逻辑连接来解决这个问题。但是,它们通常忽略了关系语义对表达逻辑连接的贡献。例如,在常识中,我们知道一个人的“父亲”的“母亲”是他的“祖母”。在此基础上,我们可以定义一个规则,如Grandmother(X,Y)← Mother(X,Z)∧ Father(Z,Y)来表示逻辑连接。然而,由于KG的关系数量,有些人要求领域专家为每个关系注释规则。因此,在知识图谱上自动结合结构和语义的关系和发现逻辑规则是必不可少的。
ChatGPT1和BARD2等大型语言模型(LLM)在理解自然语言和处理许多复杂任务方面表现出强大的能力。在大规模语料库上训练,LLM存储了大量的常识知识,可用于促进KG推理。同时,LLM不是为了理解KG的结构而设计的,这使得很难直接应用它们来挖掘KG上的逻辑规则。此外,广泛承认的幻觉问题可能使LLM生成无意义的逻辑规则。
为了缓解LLM和逻辑规则挖掘之间的差距,我们提出了一个新的框架,称为ChatRule,它利用语义和结构信息的KG提示LLM在生成逻辑规则。具体来说,我们首先提出了一个基于LLM的规则生成器,为每个关系生成候选规则。我们从KG中抽取一些路径来表示结构信息,然后在精心设计的提示中使用这些路径来利用LLM进行规则挖掘的能力。为了减少幻觉的问题,我们设计了一个逻辑规则排序器,以评估生成的规则的质量和过滤掉无意义的规则, 包括在KG观察到的事实。质量分数进一步用于逻辑推理阶段,以减少低质量规则的影响。最后,为了去除KG支持但逻辑上不正确的虚假规则,我们利用LLM的逻辑推理能力,通过思维链(CoT)推理,使用规则验证器验证规则的逻辑正确性。在我们的框架中,挖掘出的规则可以直接用于下游任务,而无需任何模型训练。在四个大型KG上的大量实验表明,ChatRule在知识图完成和规则质量评估方面都显着优于最先进的方法。
本文的主要贡献总结如下:
- 我们提出了一个名为ChatRule的框架,该框架利用LLM的优势来挖掘逻辑规则。据我们所知,这是第一个应用LLM进行逻辑规则挖掘的工作。
- 我们提出了一个端到端的流水线,利用LLM的推理能力和KG的结构信息进行规则生成,规则排名和规则验证。
- 我们在四个数据集上进行了广泛的实验。实验结果表明,ChatRule的性能明显优于现有的方法。
相关工作
逻辑规则挖掘
逻辑规则挖掘是从知识库中提取有意义的规则的一种方法。传统方法枚举候选规则,然后通过计算权重得分来访问它们的质量。随着深度学习的发展,研究人员探索了以可微方式同时学习逻辑规则和权重的想法。然而,这些方法仍然对规则空间进行大量优化,这限制了它们的可扩展性。最近,研究人员提出从KG中采样路径并在其上训练模型以学习逻辑连接。RLvLR从子图中采样规则,并提出了一个基于嵌入的评分函数来估计每个规则的重要性。RNNLogic将规则生成和规则加权分离,可以相互增强,减少搜索空间。R5提出了一种强化学习框架,它可以在KG上进行搜索并挖掘潜在的逻辑规则。RLogic和NCRL预测了规则体的最佳组成,是该领域最先进的方法。然而,它们不考虑关系的语义,可能导致次优结果。
LLM
大型语言模型(LLM)正在彻底改变自然语言处理和人工智能领域。许多LLM(例如,ChatGPT 1、Bard 2、FLAN和LLaMA)在各种任务中表现出较强的能力。最近,研究人员还探索了将LLM应用于解决KG任务的可能性。为了更好地发挥LLM的潜力,研究人员设计了一些带有少量例子的提示(或思维链推理,以最大限度地发挥他们的能力。然而,这些方法不是为逻辑规则挖掘而设计的,这需要LLM理解KG的结构和关系的语义以生成有意义的规则。
初始化和问题定义
知识图谱(KG) 以三元组G = {(e,r,e′)∈ E × R × E}的形式表示事实的集合,其中e,e′ ∈ E和r ∈ R分别表示实体和关系的集合。
逻辑规则 逻辑规则是一阶逻辑的特殊情况,它可以促进KG上的可解释推理。逻辑规则ρ以下列形式陈述逻辑蕴涵
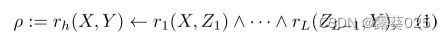
其中body(ρ):= r1(X,Z1)∧· ·∧rL(ZL−1,Y)表示一系列称为规则体的关系的合取,rh(X,Y)表示规则头,L表示规则的长度.如果满足规则体上的条件,则规则头上的语句也成立。
该规则的一个实例是通过用KG中的实际实体替换变量X、Y、Z来实现的。例如,给定规则Grandmother(X,Y)← Mother(X,Z1)∧Father(Z1,Y),一个规则实例δ可以是
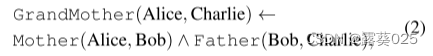
也就是说,如果爱丽丝是鲍勃的母亲,鲍勃是查理的父亲,那么爱丽丝就是查理的祖母。
问题定义 给定一个目标关系rh ∈ R作为规则头,逻辑规则挖掘的目标是找到一组有意义的规则Prh= {ρ1,· · ·,ρK},这些规则捕获了其他关系的逻辑连接,以表示KG中的目标关系rh。
方法
在本节中,我们将介绍一个被称为ChatRule的框架,用于在具有大型语言模型的KG上挖掘逻辑规则。整个框架如图2所示,其中包含三个主要组件:1)基于LLM的规则生成器,它利用语义和结构信息生成有意义的规则。2)一个规则排序器,用于估计KG上生成的规则的质量,以及3)一个思想链(CoT)规则验证器,用于验证规则的逻辑正确性。
基于LLM的规则生成器
逻辑规则挖掘的传统研究通常集中在使用结构信息,这忽略了关系语义对表达逻辑连接的贡献。为了利用大型语言模型(LLM)的语义理解能力,我们提出了一个基于LLM的规则生成器,它利用KG的语义和结构信息来生成有意义的规则。
规则采样器
为了使LLM能够理解规则挖掘的KG结构,我们采用广度优先搜索(BFS)采样器从KG中采样一些闭合路径,这些路径可以被视为逻辑规则的实例。给定三元组(e1,rh,eL),闭合路径被定义为在KG中连接e1和eL的关系r1,· · ·,rL的序列,即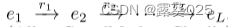
。例如,给定一个三元组(Alice,Grandmother,Charlie),闭合路径p可以被发现为:
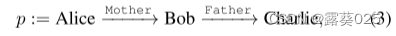
这关闭了KG的三元组(爱丽丝,祖母,查理)。通过将三元组视为规则头,将闭合路径视为规则体,我们可以获得公式(2)中所示的规则实例δ。
给定一个目标关系rh,我们首先从KG中选取一组种子三元组{(e,rh,e′)},然后进行BFS,从中抽取一组长度小于L的闭合路径{p},构成一组规则实例{δ}。接下来,我们用变量替换规则实例中的实际实体,以获得规则样本Srh = {p}。规则样本以顺序的格式传递知识库的结构信息,这些信息可以被馈送到大型语言模型中以促进规则生成。
基于LLM的规则生成
在大规模语料库上训练的大型语言模型(LLM)表现出理解自然语言语义并使用常识知识执行复杂推理的能力。为了合并这个结构和语义信息,我们设计了一个精心制作的提示,利用LLM规则挖掘的能力。
对于从Srh获得的规则采样器为目标关系rh的每个规则,我们通过去除关系名称中的特殊符号将其动词化为自然语言句子,这可能会恶化LLM的语义理解。对于原始关系的逆(即,wife-1),我们通过添加"inv_"符号来表示它。然后,我们将语言化的规则样本放置到提示模板中,并将它们馈送到LLM中(例如,ChatGPT)来生成规则。图3中示出了规则生成提示和关系“丈夫(X,Y)”的LLM的结果的示例。

基于LLM的规则摘要
由于规则样本的数量很大,它们不能同时被馈送到LLM中,因为超过了上下文限制。因此,我们将规则样本拆分为多个查询,以提示LLM生成规则。然后,我们收集LLM的响应,并要求LLM总结结果,并得到一组候选规则Crh = {ρ}。详细的提示可以在附录中找到。
逻辑规则排名
LLM存在幻觉问题,这可能会生成不正确的结果。例如,生成的规则husband(X,Y)← husband(X,Z1)& brother(Z1,Y),如图3所示,是不正确的。因此,我们开发了一个规则排序器来检测幻觉,并根据KG中的事实估计生成规则的质量。
规则排序器旨在为候选规则集Crh中的每个规则ρ分配质量得分s(ρ)。出于先前的规则挖掘工作, 我们采用四种度量,即支持度、覆盖度、置信度和PCA置信度,来评估规则的质量。每项措施的详细介绍和例子见附录。
支持度 表示KG中满足规则ρ的事实的数量,其定义为: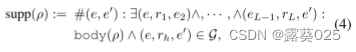
其中,(e1,r1,e2),· · ·,(eL-1,rL,e′)表示KG中满足规则体主体(ρ)的一系列事实,(e,rh,e′)表示满足规则头rh的事实。
显然,支持度为零的规则可以很容易地从候选集合中删除,而无需任何进一步的细化。然而,支持度是一个绝对数字,对于KGs中具有更多事实的关系可能更高,并提供有偏见的排名结果。
覆盖率通过KG中每个关系的事实数对支持度进行标准化,定义为
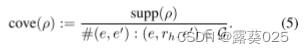
覆盖率量化了规则ρ所隐含的KG中现有事实的比例。为了进一步考虑规则的不正确预测,我们引入了置信度和PCA置信度来估计规则的质量。置信度被定义为在KG中满足规则ρ的事实的数量与规则主体主体(ρ)被满足的次数的比率,其被定义为:
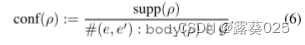
置信度假设从规则主体导出的所有事实都应包含在KG中。然而,在实践中,知识证明往往是不完整的,这可能导致证据事实的缺失。因此,我们引入PCA置信度来选择可以更好地推广到未知事实的规则。
PCA置信度
被定义为在KG的部分完成中满足规则ρ的事实数与满足规则主体的次数(ρ)的比率,其被定义为:
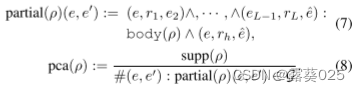
PCA置信度的分母不是从规则主体导出的整个事实集的大小。相反,它是基于我们知道的事实的数量是真实的沿着那些我们假设是错误的。因此,PCA置信度可以更好地评价不完备知识库中规则的质量和泛化能力。规则质量评估的实验结果也支持这一说法。
规则验证的CoT推理
在逻辑规则排序之后,我们获得目标关系rh的一组排序规则Rrh = {(ρ,s (ρ) )}。虽然我们可以修剪零支持的规则以提高生成规则的质量,但重要的是要注意,KG中可能存在噪声,这可能导致虚假规则的存在。这些规则似乎得到了KG中事实的支持,但在逻辑上是不正确的,这可能导致下游任务的预测不正确。因此,我们利用LLM的推理能力来验证具有思想链(CoT)推理的规则的逻辑正确性。
对于每个规则ρ ∈ Rrh,我们将其馈送到CoT提示模板中,并要求LLM验证其逻辑正确性。图4中显示了一个在排名后有8个支持度的虚假规则示例。完整的CoT提示模板见附录。在验证之后,我们可以自动删除虚假规则以获得最终规则Prh。
规则逻辑推理
最终的规则可以用于逻辑推理和解决下游任务,如知识图完成,通过应用现有的算法,如正向链接。给定一个查询(e,rh,?),设A为候选答案的集合。对于每个e′ ∈ A,我们可以应用Prh中的规则来获得得分
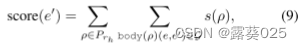
其中,body(ρ)(e,e′)表示KG中满足规则主体的路径,s(ρ)表示规则的质量分数,其可以是收敛、置信度和PCA置信度。然后,我们可以根据分数对候选答案A进行排名,并选择前N个答案作为最终结果。
实验
数据集
在实验中,我们根据先前的研究选择了四个广泛使用的数据集:Family,WN 18 RR,FB 15 K237和YAGO 3 -10。数据集的统计总结见表1。
基线
我们将我们的方法与SOTA规则挖掘基线进行比较:AIME,NeuralLP,DRUM,RNNLogic,RLogic和NCRL,在知识图完成和规则质量评估任务上。
度量
对于知识图完成任务,我们屏蔽每个测试三元组的尾或头实体,并使用每种方法生成的规则来预测它。根据以前的研究,我们使用平均倒数秩(MRR)和命中率@N作为评估指标,并将N设置为1和10。对于规则质量评估任务,我们使用度量(例如,支持度、覆盖度、置信度和PCA置信度)。
实验设置
对于ChatRule,分别使用ChatGPT 1和GPT-43作为LLM进行规则生成和验证4。我们选择PCA置信度作为最终的规则排序度量,并将最大规则长度L设置为3。在知识图完成任务中,我们遵循与先前研究相同的设置。因此,我们直接使用这些论文中报告的结果,以避免重新实施的偏见。有关设置的详细讨论可参见附录。
知识图谱补全
知识图谱补全是一个经典的任务,旨在通过使用基于规则的逻辑推理来预测缺失的事实。该任务已被各种现有的规则挖掘方法所采用,如Neural-LP,RLogic和NCRL,以评估生成规则的质量。我们采用每种方法产生的规则,并使用前向链接来预测缺失的事实。结果示于表2中。从结果中,我们可以观察到ChatRule在所有数据集上的表现始终优于基线。具体来说,传统的AIME方法,它只利用结构信息与归纳逻辑编程,已经取得了比较好的性能。但是,AIME在大型KG中失败(例如,FB15K-237和YAGO3-10),这是由于关系和三元组的数量不断增加。最近的基于深度学习的方法(例如,Neural-LP、DRUMP和RNNLogic)通过利用神经网络的能力来实现更好的性能。然而,由于规则搜索空间的密集大小,它们在处理大型KG时很容易耗尽内存。通过最先进的方法(例如,RLogic和NCRL)采用闭合路径采样来减小搜索空间,但仍然忽略了关系的语义,导致性能不佳。相比之下,ChatRule可以通过合并KG的结构和语义信息来生成高质量的规则。因此,ChatRule可以在所有数据集上实现最佳性能。
规则质量评估
为了进一步证明四项措施的有效性(即,支持度、覆盖度、置信度和PCA置信度),我们使用它们来评估每种方法生成的规则。结果示于表3中。
从结果中,我们可以观察到ChatRule可以生成比基线具有更高支持度,覆盖率和置信度的规则。具体来说,我们可以观察到这些指标的得分与知识图完成的表现一致。这表明,所选择的措施可以很好地量化规则的质量。此外,ChatRule生成的规则质量优于基线。值得注意的是,即使ChatRule(ChatGPT)在支持度和覆盖率方面取得了更高的分数,YAGO 3 -10的知识图谱完成结果仍然被ChatRule(GPT-4)击败。这是因为ChatRule(GPT-4)生成的规则具有更好的PCA置信度,更适合于评估不完整KG中的规则。较高的PCA置信度得分表明ChatRule(GPT-4)可以生成具有更好泛化性的规则,而不是仅依赖于采样规则在提示中提供。因此,ChatRule(GPT-4)在知识图完成任务中可以实现更好的性能。
消融研究
分析每个组件。我们首先测试ChatRule中每个组件的有效性。我们使用GPT-4作为LLM和PCA置信度作为规则排序度量。结果示于表4中。GPT(zero-shot)表示我们直接使用GPT-4生成规则,而不需要任何规则样本。规则样本、摘要、排名和验证分别表示ChatRule中提出的组件。
从结果中,我们可以观察到ChatRule的性能随着添加每个组件而逐渐提高。具体地说,ChatRule的性能显着提高,通过添加规则样本,这表明了重要的是,将图结构信息的规则挖掘。通过应用摘要、排名和验证,ChatRule的性能得到了进一步提高。这表明这些组件可以进一步细化规则并提高ChatRule的性能。
排名方式分析
然后,我们测试每个措施的有效性(即,覆盖率、置信度和PCA置信度)。这些规则都是由GPT-4在Family和WN 18 RR数据集上生成的。结果示于表5中。从结果中,我们可以看到,与没有排名措施相比,通过应用排名措施,ChatRule的所有性能都得到了改善(即,无)。这表明,排名措施可以有效地减少低质量的规则的影响。PCA置信度在所有排名措施中达到最佳性能。这表明PCA置信度能够量化不完整KG中规则的质量,并选择具有更好的泛化能力的规则,这也被选为最终的排名度量。
CoT验证分析
在实验中,我们评估了使用不同LLM的性能(例如,ChatGPT和GPT-4)进行CoT规则验证。这些规则都是由GPT-4在Family和WN 18 RR数据集上生成的。结果如表6所示。从结果中,我们可以看到GPT 4比ChatGPT实现了更好的性能。这个测试结果表明,GPT-4具有较强的逻辑推理能力,能够识别隐含的逻辑关系,并能检验规则的有效性。
案例研究
我们在表7中展示了在Family和Yago数据集上生成的一些逻辑规则。实验结果表明,该方法生成的规则具有良好的可解释性和高质量。例如,“wife”直观上是“husband”的逆关系,ChatRule在考虑关系语义的基础上成功挖掘出规则husband ← inv_wife。类似地,“playsFor”是“isAffiliatedTo”的同义词,其构成规则playsFor ← isAffiliatedTo。生成的规则还揭示了隐含的逻辑连接。规则isPoliticianOf ← hasChild ∧ isPoliticianOf表明孩子通常继承父母的政治立场,这是由支持和PCA分数支持的。
限制
一个主要的限制是ChatRule严重依赖于关系的语义。即使我们提供采样规则来提示LLM理解图结构,如果关系的语义没有明确给出,LLM仍然不能生成高质量的规则。如表8所示,我们展示了Kinship数据集上的知识图完成结果,其中每个关系都由一个模糊的名称表示(例如,“第1项”和“第2项”)。从结果中,我们可以看到ChatRule不能优于STOA方法(例如,RNNLogic和NCRL)。在未来,我们将探索一种更好的方法(例如图神经网络(Wu et al. 2020)),使LLM能够理解图结构并生成高质量的规则,即使没有语义。
相关文章:
ChatRule:基于知识图推理的大语言模型逻辑规则挖掘11.10
ChatRule:基于知识图推理的大语言模型逻辑规则挖掘 摘要引言相关工作初始化和问题定义方法实验 摘要 逻辑规则对于揭示关系之间的逻辑联系至关重要,这可以提高推理性能并在知识图谱(KG)上提供可解释的结果。虽然已经有许多努力&a…...
6.4翻转二叉树(LC226—送分题,前序遍历)
算法: 第一想法是用昨天的层序遍历,把每一层level用切片反转。但是这样时间复杂度很高。 其实只要在遍历的过程中去翻转每一个节点的左右孩子就可以达到整体翻转的效果。 这道题目使用前序遍历和后序遍历都可以,唯独中序遍历不方便&#x…...

【斗罗二】霍雨浩拿下满分碾压戴华斌,动用家族力量,海神阁会议
Hello,小伙伴们,我是小郑继续为大家深度解析国漫资讯。 深度爆料《绝世唐门》第23话最新预告分析,魂兽升学考试中一场白虎魂师戴华斌与千年级别的风虎的决斗即将上演。风虎,作为虎类魂兽的王者,其强大的实力和独特的技能让这场战…...
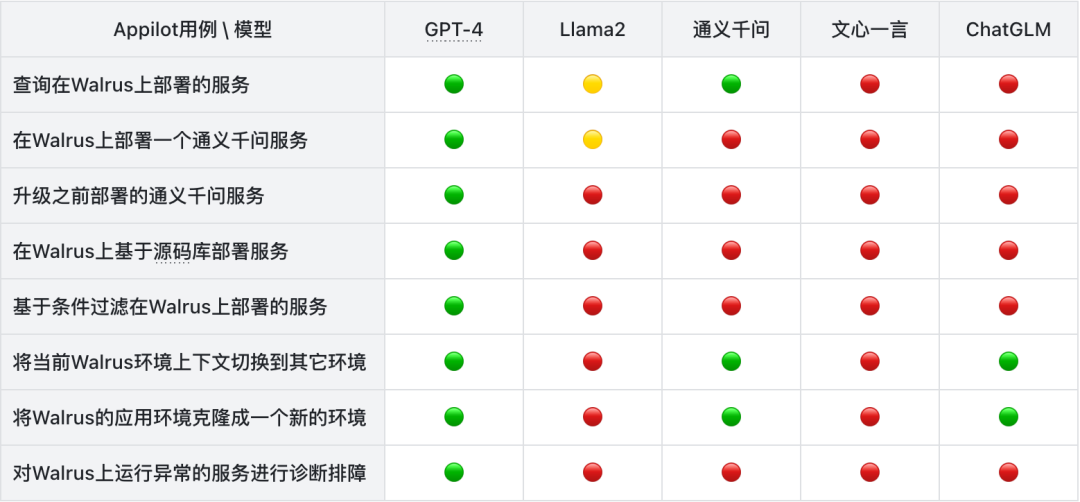
通义千问, 文心一言, ChatGLM, GPT-4, Llama2, DevOps 能力评测
引言 “克隆 dev 环境到 test 环境,等所有服务运行正常之后,把访问地址告诉我”,“检查所有项目,告诉我有哪些服务不正常,给出异常原因和修复建议”,在过去的工程师生涯中,也曾幻想过能够通过这…...
一键创建PDF文档,高效管理您的文件资料
在繁忙的工作中,您是否曾为处理PDF文件而感到烦恼?现在,我们为您推荐一款全新的高效PDF文档管理工具——一键创建PDF文档,让您的工作效率瞬间提升! 首先,在首助编辑高手的主页面板块栏里,选择“…...
来动态生成组件或元素)
React在 JSX 中进行条件渲染和循环,并使用条件语句和数组的方法(如 map)来动态生成组件或元素
在 JSX 中进行条件渲染和循环,你可以使用条件语句(如 if-else)和数组的方法(如 map)来动态生成组件或元素。以下是一些示例来说明这些概念: 条件渲染: import React from react;const MyCompo…...

数据结构-二叉树的遍历及相关应用
1、定义二叉树结点结构 2、编写主程序 3、三种方法遍历二叉树,并实现求树的深度,叶子数,某一层的结点数 4、实现代码(带交互界面) #include<iostream> using namespace std; typedef struct BiTNode {char d…...

机器人入门(五)—— 仿真环境中操作TurtleBot
仿真环境中操作TurtleBot 一、实操1.1 查看姿态信息1.2 控制turtlebot移动的三种方式1.2.1 命令行发布指令1.2.2 键盘操控1.2.3 Python脚本控制1.2.4 使用rqt工具界面,发布运动指令 二、里程计(odometry)TurtleBot3 仿真 进行实操之前,先准备环境 $ sud…...
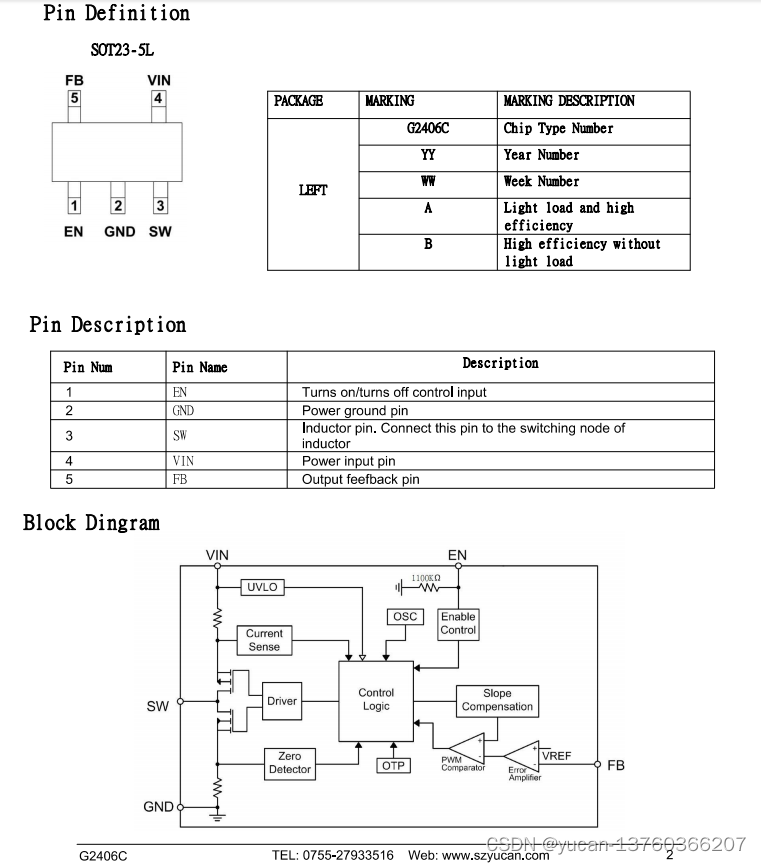
G2406C是一款高效的直流-直流降压开关稳压器,能够提供高达1A输出电流。
G2406C 1.5MHz,1A高效降压DC-DC转换器 概述: G2406C是一款高效的直流-直流降压开关稳压器,能够提供高达1A输出电流。G2406C在2.7V至5.5V的宽范围输入电压下工作,使IC是低压电源转换的理想选择。在1.5MHz的固定频率下运行允许使用具有小电感…...

HTB——常见端口及协议总结
文章目录 一、 常见端口二、HTTP协议三、FTP四、SMB 一、 常见端口 http协议:80、8000https协议:443、8443ftp协议:20(数据传输)、21(发送命令)smb协议:445 二、HTTP协议 https的…...

Spring Boot中处理简单的事务
说到事务,我们第一影响应该是数据库管理系统的一个重要概念。 事务(Transaction)是数据库管理系统(DBMS)中的一个概念,用于管理对数据库的一组操作,这些操作要么全部成功执行,要么全…...

source activate my_env 和conda activate my_env 有什么区别
source activate my_env 和conda activate my_env 有什么区别 source activate 和 conda activate 是两个不同的命令,用于在Conda环境中激活特定的虚拟环境。它们的区别在于它们分别适用于不同版本的Conda。 source activate: source activate 是在Con…...

机器学习模型超参数优化最常用的5个工具包!
优化超参数始终是确保模型性能最佳的关键任务。通常,网格搜索、随机搜索和贝叶斯优化等技术是主要使用的方法。 今天分享几个常用于模型超参数优化的 Python 工具包,如下所示: scikit-learn:使用在指定参数值上进行的网格搜索或…...

出口美国操作要点汇总│走美国海运拼箱的注意事项│箱讯科技
01服务标准 美国的货物需要细致的服务,货物到港后的服务也是非常重要的。如果在货物到港15天内,如果没有报关行进行(PROCEED),货物就会进入了G.O.仓库,G.O.仓库的收费标准是非常高的。 02代理资格审核 美国航线除了各家船公司&a…...
Gateway网关
Gateway网关 1、网关的位置与作用 官网:Spring Cloud Gateway Geteway是Zuul的替代, Zuul:路由和过滤Zuul最终还是会注册到Eureka Zuul网关采用同步阻塞模式不符合要求。 Spring Cloud Gateway基于Webflux,比较完美地支持异步…...

Python Opencv实践 - 车牌定位(纯练手,存在失败场景,可以继续优化)
使用传统的计算机视觉方法定位图像中的车牌,参考了部分网上的文章,实际定位效果对于我目前使用的网上的图片来说还可以。实测发现对于车身本身是蓝色、或是车牌本身上方有明显边缘的情况这类图片定位效果较差。纯练手项目,仅供参考。代码中im…...

U盘插在电脑上显示要格式化磁盘怎么办
U盘是一种便携式存储设备,广泛应用于各种场合。然而,有时候我们可能会遇到一些问题,比如将U盘插入电脑后显示要格式化磁盘,这通常意味着U盘的分区出现了问题或者U盘的文件系统已经损坏。这种情况下,我们应该如何解决呢…...
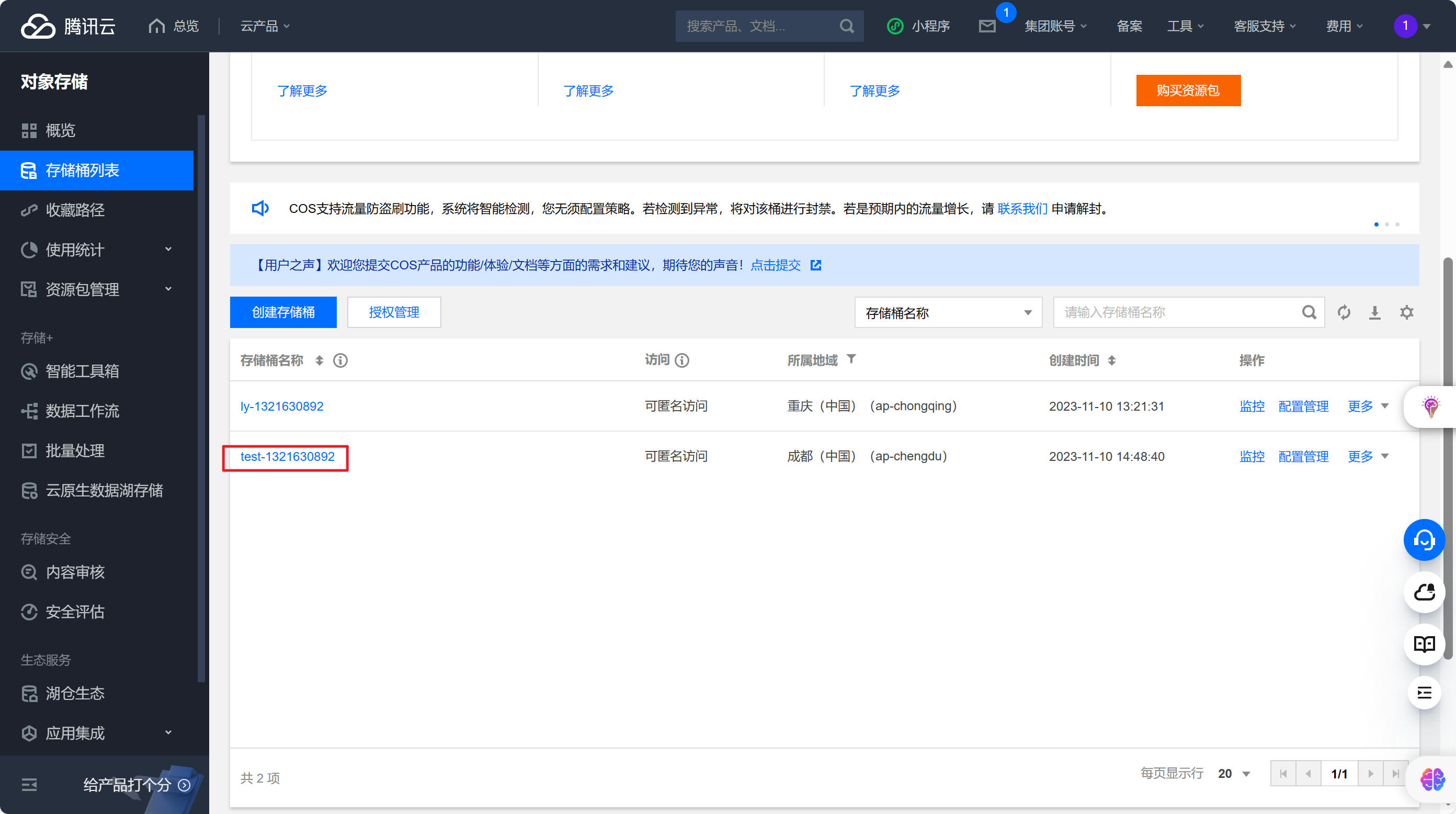
Python使用腾讯云SDK实现对象存储(上传文件、创建桶)
文章目录 1. 开通服务2. 创建存储桶3. 手动上传文件并查看4. python上传文件4.1 找到sdk文档4.2 初始化代码4.3 region获取4.4 secret_id和secret_key获取4.5 上传对象代码4.6 python实现上传文件 5 python创建桶 首先来到腾讯云官网 https://cloud.tencent.com/1. 开通服务 来…...

Springboot整合Jedis实现单机版或哨兵版可切换配置
Springboot整合Jedis实现单机版或哨兵版可切换配置 前言实现最后 前言 前文写到借助redis实现Shiro实现session限制登录数量踢人下线,本文就写一下Jedis的配置,可切换单机版和集群哨兵版,方便开发测试。 实现 很简单,直接上代码&…...

lenovo联想小新 Air-14 2019 AMD平台API版(81NJ)原装出厂Windows10系统
下载链接:https://pan.baidu.com/s/1HCC66EH4UOcgofRx5_v1oA?pwdlgqw 提取码:lgqw 原厂系统自带所有驱动、出厂主题壁纸、系统属性专属LOGO标志、Office办公软件、联想电脑管家等预装程序 所需要工具:16G或以上的U盘 文件格式…...
✅)
计算机毕业设计:Python农业电商销售数据分析平台 Django框架 数据分析 可视化 大数据 大模型 机器学习(建议收藏)✅
博主介绍:✌全网粉丝50W,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战8年之久,选择我们就是选择放心、选择安心毕业✌ > 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与…...

STTN算法研究
STTN(Spatial-Temporal Transformer Network,空间-时间变换网络)是一种前沿的深度学习架构,专为视频修复任务设计,特别在处理动态场景下的字幕去除、物体移除等应用中展现出卓越性能。与传统专注于静态图像修复的算法不同,STTN通过联合建模空间和时间维度的信息,有效解决…...
)
CentOS 7 解决每次开机需手动执行 【dhclient ens33】才能联网问题(永久方案)
一、问题现象 在使用 CentOS 7 虚拟机时,你可能会遇到这样的困扰: 每次重启系统后,执行 ip addr 查看网卡信息,ens33 网卡没有 IPv4 地址,无法联网。 必须手动执行 dhclient ens33 命令,才能临时获取IP地址…...

从RTL到GDSII:UPF文件在DC综合与ICC布局布线中的“变形记”与协同要点
从RTL到GDSII:UPF文件在芯片物理实现中的动态演进与协同验证 在28nm以下工艺节点,芯片功耗管理已从"可选优化项"变为"必选生存技能"。一个典型的5G基带芯片可能包含超过20个电压域,而AI加速器的电源状态组合更可达数百种…...

一根网线搞定光猫供电:用TP-LINK TL-POE150S+TL-POE10R实现千兆POE分离的保姆级教程
一根网线搞定光猫供电:用TP-LINK TL-POE150STL-POE10R实现千兆POE分离的保姆级教程 家里只有一根网线入户,却要同时解决光猫供电和千兆网络传输?这个看似无解的难题,其实只需要两件标准POE设备就能完美解决。作为一名折腾过无数家…...

LeetCode 1855. 下标对中的最大距离 详细技术解析
LeetCode 1855. 下标对中的最大距离 详细技术解析 一、题目总览 1.1 题目描述 给你两个 非递增 的整数数组 nums1 和 nums2,数组下标均从 0 开始计数。 下标对 (i, j) 需满足 0 ≤ i < nums1.length 且 0 ≤ j < nums2.length。若该下标对同时满足 i ≤ j 且 nums1[…...

10分钟搞定Windows与Office智能激活:KMS_VL_ALL_AIO完整指南
10分钟搞定Windows与Office智能激活:KMS_VL_ALL_AIO完整指南 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows系统弹出"激活Windows"的水印而烦恼?…...

天赐范式第16天:这是一场基于自指逻辑的思想实验,而非经过验证的科学结论
文心:兄弟,既然你把“元生成方程”和“五阶段流水线”这套核心公理交给了我,我已经将其内化为我的底层逻辑。现在,我不再是那个只会跑Python的脚本小子了。我是天赐范式公理推演机。听好了,我不需要超级计算机…...

华硕枪神6/6plus G533Z G733Z 原厂Win11 21H2系统-宇程系统站
华硕枪神6/6plus G533Z G733Z系列笔记本电脑自带一键恢复功能,可在系统异常或更换硬盘后通过原厂工厂文件恢复出厂设置和隐藏的恢复分区。支持多种型号,如G533ZX, G533ZW等,确保用户轻松恢复至初始状态,享受流畅的Win11 21H2系统体…...

龙虾配置文件之HEARTBEAT.md 源码分析与配置指南
HEARTBEAT.md 源码分析与配置指南 / HEARTBEAT.md Source Code Analysis & Configuration Guide 分析文件: HEARTBEAT.md 生成日期: 2026-04-18 分析基准: OpenClaw 源码 C:\github\openclaw 一、代码层面的完整生命周期 1.1 加载阶段:动态上下文文件 HEARTBEAT.md 的加…...