LeetCode146.LRU缓存
写了一个小时,终于把示例跑过了,没想到啊提交之后第19/22个测试用例没过

我把测试用例的输出复制在word上看看和我的有什么不同,没想到有18页的word,然后我一直检查终于找出了问题,而且这个bug真的太活该了,感觉只有傻屌才能写出这种bug,以下是我之前的代码:
class LRUCache {HashMap<Integer,Integer> map;int cap;int useIndex;HashMap<Integer,Integer> lastUseMap;public LRUCache(int capacity) {map = new HashMap<Integer,Integer>();lastUseMap = new HashMap<Integer,Integer>();cap = capacity;useIndex =0;}public int get(int key) {if(map.containsKey(key)){lastUseMap.put(key,useIndex);useIndex++;return map.get(key);}else{return -1;}}public void put(int key, int value) {if(!map.containsKey(key)){if(map.size() == cap){int min = 10000;int delKey = -1;Set<Map.Entry<Integer, Integer>> entrySet = lastUseMap.entrySet();for (Map.Entry<Integer,Integer> entry : entrySet) {if(entry.getValue() < min){min = entry.getValue();delKey = entry.getKey();}}map.remove(delKey);lastUseMap.remove(delKey);}}map.put(key,value);lastUseMap.put(key,useIndex);useIndex++;}
}我想讲我的算法思想,最后再讲里面的那个bug。
我的想法是,用hashmap来进行put和get操作,这样就不用自己写真正put和get的代码了(其实一开始看到题目写put和get算法复杂度是O1我用的是数组,写了很久没写出来,直接换成了hashmap,因为一开始我以为hashmap的算法复杂度大于1,但其实不是的,因为hashmap是数组--->数组+链表 ---->数组+红黑树,最简单的情况是用hash函数直接算出数组下标,算法复杂度是O1,如果数组的这个位置上是个链表,那么还要用O(n)遍历链表,如数组的这个位置上是个红黑树,那么还要用O(nlogn)遍历红黑树,但大多数情况还是O(1))
那么put和get操作解决了,只需要解决过期淘汰就可以了,我是用一个
HashMap<Integer,Integer> map;进行正真的putget缓存操作,然后用一个
int useIndex;来记录每次get和put操作的序号(从0开始,每次自增,如果get失败就不自增),然后再用一个map
HashMap<Integer,Integer> lastUseMap;
来记录map中的每个元素的最新一次的操作序号。
构造函数就不用说了,把这几个属性初始化以下就行。
先讲get方法,如果map中没有这个key返回-1,如果有这个key,把lastUseMap中的这个key的value更新为本次操作的序号,再把序号加一,再把map中这个key的value返回。
再讲讲put方法,先对size进行判断,如果达到最大容量cap那么就要删除掉map中的一个最久未使用的元素,要找出最久未使用的元素只需要对lastUseMapz进行一次遍历即可,这个就属于基操了,先定义个较大数min,然后把遍历出来的value和min进行比较,如果小于min就把min更新为这个value,找到了这个最久没用的元素后再map和lastUseMap中把这个元素删除就可以了,然后是进行put操作,除了把key和value put进map以外还要记得把key和当前操作序号put进lastUseMap,然后操作序号自增。
需要注意的一点是,在尽心put操作之前先看看map里面有没有这个key,如果有直接put就行不用删除,这是个坑,有个测试用例就是这个。
最后讲讲那个傻逼bug,就是min的初值,我当时也没想到操作次数会达到18页word啊,就直接给了10000,所以在第19个测试用例报错了,只要把min的初值赋为Integer.MAX_VALUE就可以了。
再看看官方题解吧:
题解用的是hsahMap+双向链表的做法,并且它并没有用封装好的LinkedList,而是自己写一个简介的链表,以下是题解代码:
public class LRUCache {class DLinkedNode {int key;int value;DLinkedNode prev;DLinkedNode next;public DLinkedNode() {}public DLinkedNode(int _key, int _value) {key = _key; value = _value;}}private Map<Integer, DLinkedNode> cache = new HashMap<Integer, DLinkedNode>();private int size;private int capacity;private DLinkedNode head, tail;public LRUCache(int capacity) {this.size = 0;this.capacity = capacity;// 使用伪头部和伪尾部节点head = new DLinkedNode();tail = new DLinkedNode();head.next = tail;tail.prev = head;}public int get(int key) {DLinkedNode node = cache.get(key);if (node == null) {return -1;}// 如果 key 存在,先通过哈希表定位,再移到头部moveToHead(node);return node.value;}public void put(int key, int value) {DLinkedNode node = cache.get(key);if (node == null) {// 如果 key 不存在,创建一个新的节点DLinkedNode newNode = new DLinkedNode(key, value);// 添加进哈希表cache.put(key, newNode);// 添加至双向链表的头部addToHead(newNode);++size;if (size > capacity) {// 如果超出容量,删除双向链表的尾部节点DLinkedNode tail = removeTail();// 删除哈希表中对应的项cache.remove(tail.key);--size;}}else {// 如果 key 存在,先通过哈希表定位,再修改 value,并移到头部node.value = value;moveToHead(node);}}private void addToHead(DLinkedNode node) {node.prev = head;node.next = head.next;head.next.prev = node;head.next = node;}private void removeNode(DLinkedNode node) {node.prev.next = node.next;node.next.prev = node.prev;}private void moveToHead(DLinkedNode node) {removeNode(node);addToHead(node);}private DLinkedNode removeTail() {DLinkedNode res = tail.prev;removeNode(res);return res;}
}hashMap的key是key,value是链表的节点。链表中越头部的节点是越新的节点,越再尾部的节点是越久未使用的节点。
get方法只需要通过key拿到node节点,如果为null直接返回-1,否则返回node.val,并且需要把这个node移到链表的最前面。
put方法也是通过key拿到node节点,如果node不存在就创建一个node,然后把key和这个node放进hashMap,把这个node放到链表的头部,然后size++,如果这个时候size>最大容量了那么就把尾部节点删除,并且再map中删除这个key,size--;如果node存在直接把node的value改成参数value然后把node移到链表头部,剩下的方法都是关于双向链表的操作了。
相关文章:
LeetCode146.LRU缓存
写了一个小时,终于把示例跑过了,没想到啊提交之后第19/22个测试用例没过 我把测试用例的输出复制在word上看看和我的有什么不同,没想到有18页的word,然后我一直检查终于找出了问题,而且这个bug真的太活该了,…...

5-7 使用函数求余弦函数的近似
实现一个函数,用下列公式求cos(x)的近似值,精确到最后一项的绝对值小于e:…...
Kotlin HashMap entries.filter过滤forEach
Kotlin HashMap entries.filter过滤forEach fun main(args: Array<String>) {val hashMap HashMap<String, Int>()hashMap["a"] 1hashMap["b"] 2hashMap["c"] 3println(hashMap)hashMap.entries.filter {println("filter $…...

css的预处理
CSS的预处理器是一种CSS的扩展,可以让开发者使用更加高效、灵活的方式来编写CSS代码。 常用的CSS预处理器包括: Sass:基于Ruby的CSS预处理器,提供了大量的函数和变量等扩展功能。 Less:基于JavaScript的CSS预处理器&…...

[云原生案例2.2 ] Kubernetes的部署安装 【单master集群架构 ---- (二进制安装部署)】网络插件部分
文章目录 1. Kubernetes的网络类别2. Kubernetes的接口类型3. CNI网络插件 ---- Flannel的介绍及部署3.1 简介3.2 flannel的三种模式3.3 flannel的UDP模式工作原理3.4 flannel的VXLAN模式工作原理3.5 Flannel CNI 网络插件部署3.5.1 上传flannel镜像文件和插件包到node节点3.5.…...

Go开发基础环境搭建
前面,我们写了下关于GO的入门简介,今天我们打算实操,在实操之前需要准备下基础环境。 IDE开发工具 GoLand 是一款由捷克软件开发公司 JetBrains 专为 Go 开发的跨平台商业 IDE。Goland 具有 Strong Code Insight、Navigation & Search、…...
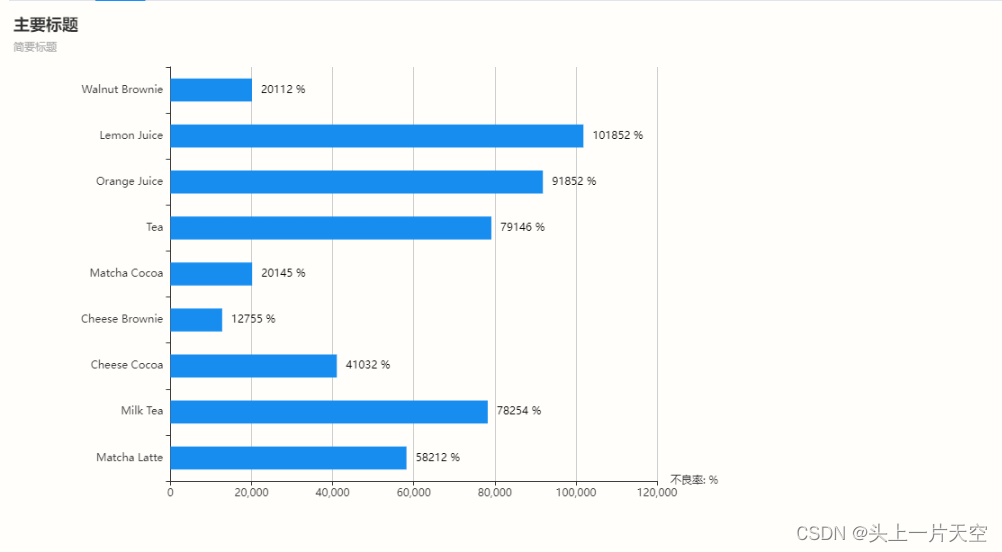
Vue简单使用Echart图表柱形图 vue使用柱形图 vue使用 echart图表柱形图 vue使用柱形图
Vue简单使用Echart图表柱形图 vue使用柱形图 vue使用 echart图表柱形图 vue使用柱形图 1、安装依赖2、页面Demo使用3、效果图 1、安装依赖 官方文档:https://echarts.apache.org/zh/option.html#title 官方在线示例:https://echarts.apache.org/exampl…...
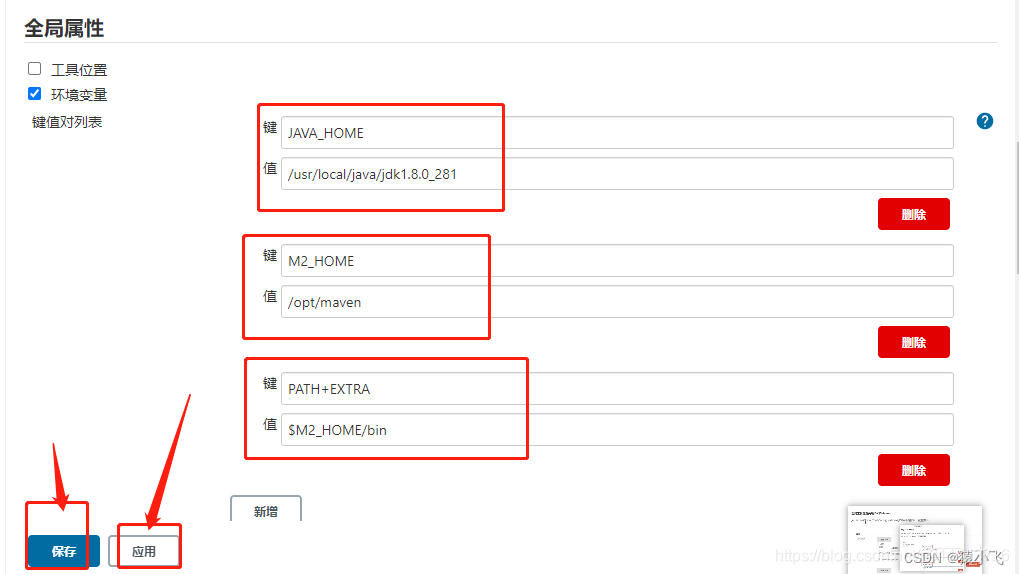
centos 7.9系统安装老版本jenkins,并解决插件问题
1.初衷 因为jenkins随着时间推移,其版本也越来越新,支持它运行的JDK也越来越新。基于不折腾的目标,我们安装一个老的固定版本就行。以前安装新版本,经常碰到的问题就是插件安装不兼容的问题。现在这个问题,可以把以前…...

BMVC 23丨多模态CLIP:用于3D场景问答任务的对比视觉语言预训练
来源:投稿 作者:橡皮 编辑:学姐 论文链接:https://arxiv.org/abs/2306.02329 摘要: 训练模型将常识性语言知识和视觉概念从 2D 图像应用到 3D 场景理解是研究人员最近才开始探索的一个有前景的方向。然而,…...

《嵌入式虚拟化技术与应用》:深入浅出阐述嵌入式虚拟机原理,实现“小而能”嵌入式虚拟机!
目录 关于博主前言专家推荐本书适合谁?内容简介书本目录权威作者团队其他 关于博主 🚀Python爬虫项目实战系列文章!! ⭐⭐欢迎订阅⭐⭐ 【Python爬虫项目实战一】获取Chatgpt3.5免费接口文末付代码(过Authorization认…...

【Java开发】之获取客户端真实 IP 地址
一、应用场景 在投票系统开发中,为了防止刷票,我们需要限制每个 IP 地址只能投票一次;当网站受到诸如 DDoS(Distributed Denial of Service,分布式拒绝服务攻击)等攻击时,我们需要快速定位攻击者…...
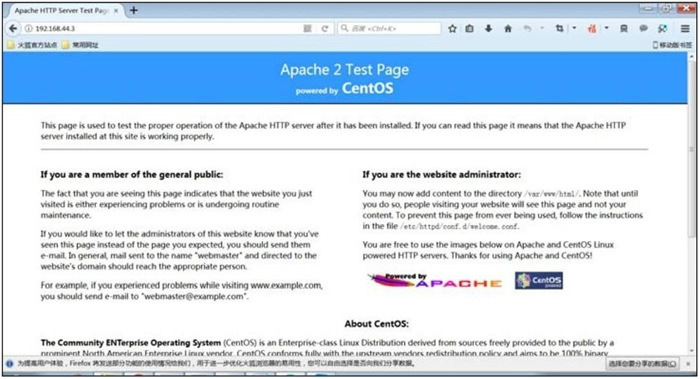
Linux RPM包安装、卸载和升级
我们以安装 apache 程序为例。因为后续章节还会介绍使用源码包的方式安装 apache 程序,读者可以直观地感受到源码包和 RPM 包的区别。 RPM包默认安装路径 通常情况下,RPM 包采用系统默认的安装路径,所有安装文件会按照类别分散安装到表 1 所…...
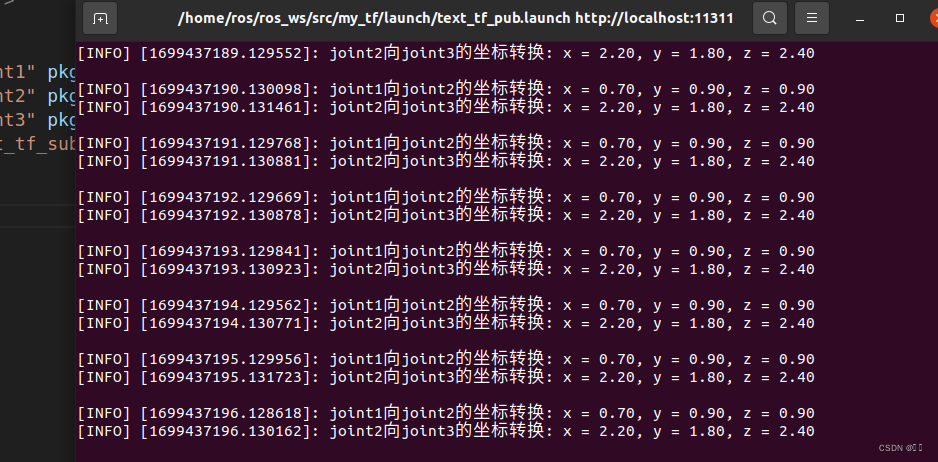
ROS 多级tf坐标转换
题目 现有一移动机器人,该机器人的基坐标系为“base_link”,机器人包含3个子坐标系分别为“joint1”,“joint2”,“joint3”。 要求:利用多坐标转换,实现joint1下的坐标向joint2下的坐标转换,…...

ceph rados对象存储索引残留问题排查与处理
问题现象 对象存储存储桶无法删除,检查发现生命周期过期后存储桶中有文件残留,未完全删除,但实际访问文件时为404,通过s3cmd无法删除对象,且无报错。 问题定位 检查bucket当前状态,发现桶内有大量object…...

十年测试工龄,揭露软件测试痛点以及分析
做软件测试的同学们,你在平时的测试工作中有哪些困惑或困扰呢?你可以自行简单思考一下。下面我梳理一下,大家可以看看自己是不是也有如此的感受。 从测试整体角度分析: 第一个痛点是入门容易深入难。 很多人认为软件测试也就那么…...
 组件)
【星海出品】flask(三) 组件
Flask是一个基于Python开发并且依赖jinja2模板和Werkzeug WSGI服务的一个微型框架 wsgiref 因为我们不希望接触到TCP连接、HTTP原始请求和响应格式,所以,需要一个统一的接口协议来实现这样的服务器软件,让我们专心用Python编写Web业务。 这个…...
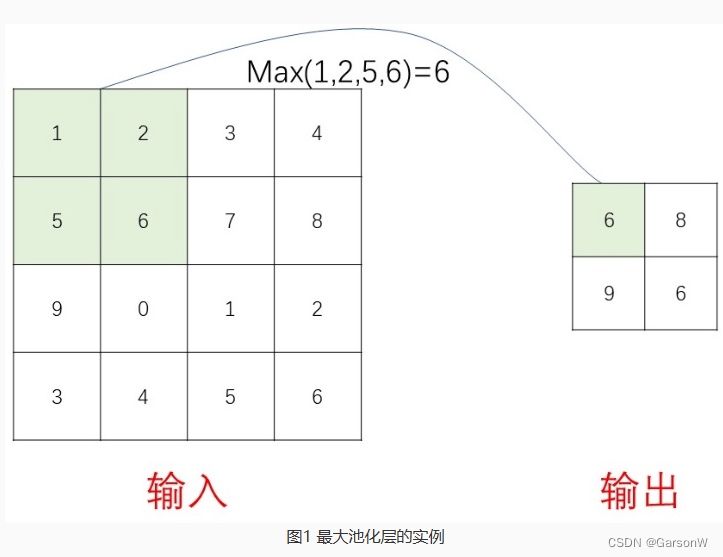
关于卷积神经网络的池化层(pooling)
了解池化层 池化层又称“下采样层”或“子采样层”,池化层可以大大降低特征的维度,减少计算量,同时可以避免过拟合问题。 顾名思义,最大池化层就是从输入的矩阵中某一范围内,选择最大的元素进行保留;平均池…...
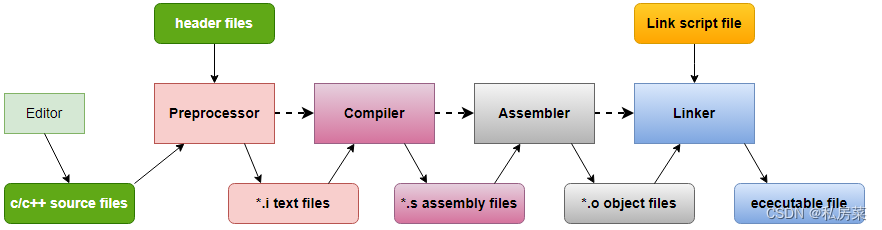
GNU链接脚本详解
0. 前言 每一个链接都是由链接脚本控制的,链接脚本是用链接命令语言编写的脚本。链接都会用到一个链接脚本,如果你没有指定自己的脚本,就会使用默认的链接脚本。可以用 "--verbose" 命令行选项显示默认的连接脚本。指定命令行参数…...
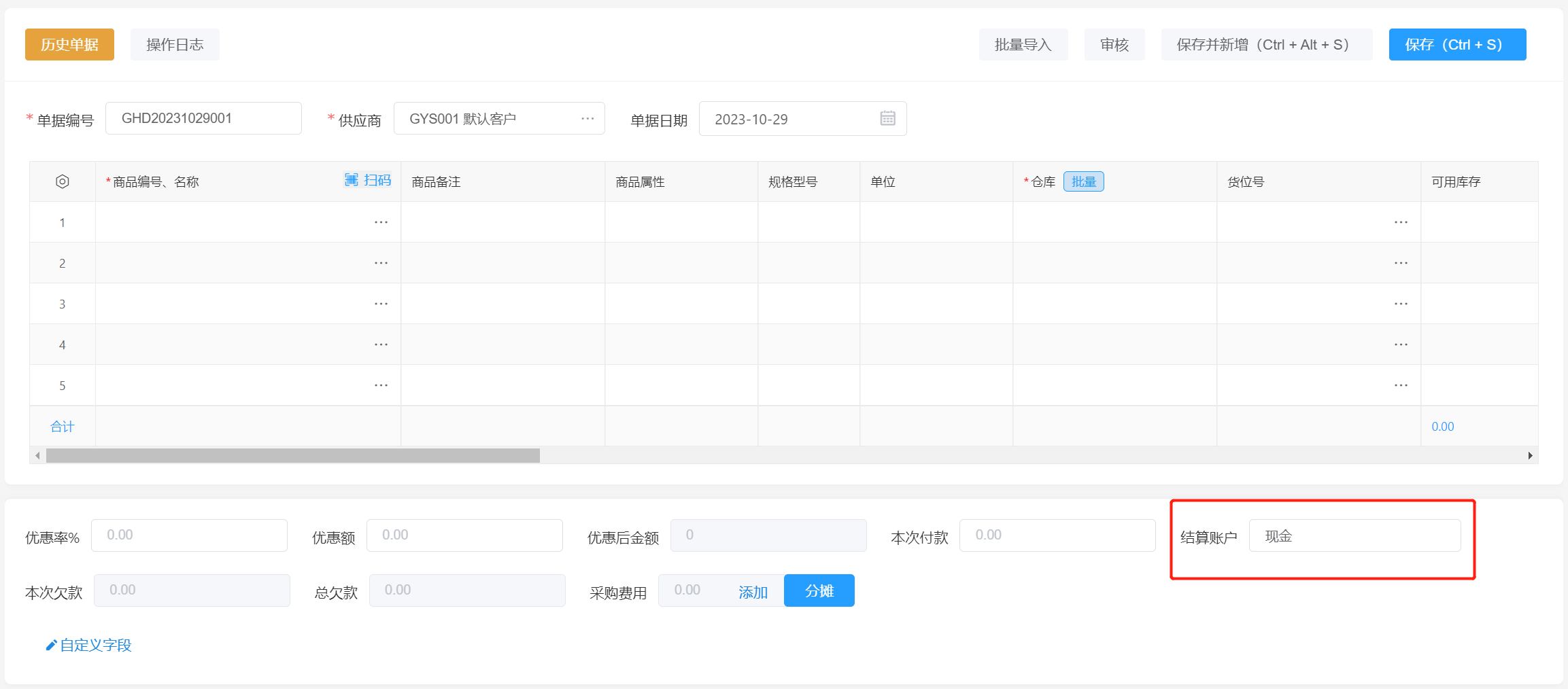
酷柚易汛ERP-账户管理操作指南
1、应用场景 对账户进行管理,可设置账户当前余额、期初余额和设置是否为默认账户。 2、主要操作 2.1 新增支付账户 打开【资料】-【账款管理】,点击【新增】添加账户类别,输入相关信息并保存,账户编号和名称为必录项。&#x…...
函数的连续性
函数在某一点极限存在,不一定连续 函数的左极限 函数的右极限 函数在某点连续需要满足三个条件 1、左右极限存在 2、左右极限相等 3、函数在该点的极限值等于在该点的函数值 满足1、2两个条件函数在该点极限存在。...

深入解析XDG_RUNTIME_DIR:从Linux桌面到Docker容器的环境变量配置实战
1. 理解XDG_RUNTIME_DIR的前世今生 第一次在终端里看到"XDG_RUNTIME_DIR not set"的警告时,我盯着这行字发了五分钟呆。这个看起来像乱码的变量名,其实是Linux桌面环境中一个至关重要的配置项。让我们从一个真实案例说起:上周同事在…...
)
STM32F407实战避坑指南(一)
1. GPIO配置中的那些"坑" 第一次用STM32F407点灯的时候,我信心满满地照着手册写好了GPIO配置代码,结果灯死活不亮。后来才发现,原来GPIO的时钟使能位写错了位置。这种低级错误在新手阶段特别常见,今天就和大家分享几个G…...

移相全桥变换器原理及优缺点
一、引言在中大功率 DC-DC 变换领域(100W~10kW),移相全桥(Phase-Shifted Full-Bridge, PSFB)变换器凭借软开关特性、高效率、高功率密度、低电磁干扰等优势,成为当之无愧的主流拓扑。它完美解决了硬开关全桥…...

职业院校智慧校园采购怎样才算明智?聊聊性价比与易用性的那些事
✅作者简介:合肥自友科技 📌核心产品:智慧校园平台(包括教工管理、学工管理、教务管理、考务管理、后勤管理、德育管理、资产管理、公寓管理、实习管理、就业管理、离校管理、科研平台、档案管理、学生平台等26个子平台) 。公司所有人员均有多…...

Windows更新故障的终极解决方案:Reset Windows Update Tool深度技术解析
Windows更新故障的终极解决方案:Reset Windows Update Tool深度技术解析 【免费下载链接】Reset-Windows-Update-Tool Troubleshooting Tool with Windows Updates (Developed in Dev-C). 项目地址: https://gitcode.com/gh_mirrors/re/Reset-Windows-Update-Tool…...

LX Music桌面版:三大痛点解决方案,让你的音乐体验焕然一新
LX Music桌面版:三大痛点解决方案,让你的音乐体验焕然一新 【免费下载链接】lx-music-desktop 一个基于 Electron 的音乐软件 项目地址: https://gitcode.com/GitHub_Trending/lx/lx-music-desktop 你是否厌倦了音乐平台的会员限制?是…...

从自动驾驶到AI医生:拆解5个真实案例,看多模态融合如何解决行业难题
从自动驾驶到AI医生:拆解5个真实案例,看多模态融合如何解决行业难题 当一辆自动驾驶汽车在暴雨中行驶时,摄像头被雨水模糊,激光雷达却依然能清晰识别障碍物;当医生面对复杂的肺部CT影像时,结合患者的电子病…...

从色温窗口到增益系数:一种硬件友好的实时白平衡方案
1. 为什么我们需要硬件友好的白平衡方案 每次用手机拍出来的照片颜色不对劲,你是不是总觉得是手机摄像头不行?其实很多时候问题出在白平衡上。白平衡就像是给照片戴了一副"有色眼镜",它的任务是消除光源色温对颜色的影响࿰…...

避开二轴机械臂动力学建模的坑:摩擦、噪声与激励轨迹设计实战
二轴机械臂动力学建模实战:从摩擦处理到激励轨迹设计的工程精要 在工业自动化与协作机器人快速发展的今天,精确的动力学建模已成为实现高精度控制的基础。不同于教科书中的理想化推导,真实机械臂建模过程中工程师们常会遇到三大"拦路虎&…...

Symfony Polyfill PHP73 性能优化:hrtime高精度时间函数的底层实现
Symfony Polyfill PHP73 性能优化:hrtime高精度时间函数的底层实现 【免费下载链接】polyfill-php73 This component provides functions unavailable in releases prior to PHP 7.3. 项目地址: https://gitcode.com/gh_mirrors/po/polyfill-php73 Symfony P…...