2022最新版-李宏毅机器学习深度学习课程-P50 BERT的预训练和微调
模型输入无标签文本(Text without annotation),通过消耗大量计算资源预训练(Pre-train)得到一个可以读懂文本的模型,在遇到有监督的任务是微调(Fine-tune)即可。
最具代表性是BERT,预训练模型现在命名基本上是源自于动画片《芝麻街》。

芝麻街人物
经典的预训练模型:
- ELMo:Embeddings from Language Models
- BERT:Bidirectional Encoder Representations from Transformers
- 华丽分割线,命名逐渐开始离谱
- ERNIE:Enhanced Representation through Knowledge Integration
- Grover:Generating aRticles by Only Viewing mEtadaya Records

一、pre-train model 是什么
(一)预训练概念
预训练模型的概念并不是由BERT时才出现。
预训练的任务一般是实现 词语token -> 词向量embedding vector, vector中包含token的语义,比如我们语文中常学习的近义词,语义相近,那么要求其词向量也应该近似。
(二)多语义多语境
存在的问题:同一个token就可以指代同一个vector。解决方法Word2vec、Glove...

但是语言有无穷尽的词语,咱们现在就一直在创造新词语,如 “雪糕刺客”、“栓Q”等等新兴词汇不断迭代更新,一个新的词汇就要增加一个向量,显然是不太OK的。
那么,研究者就想到可以将词语再分,英文可以拆分为字符(FastText),中文可以拆分为单个字,或者将一个中文字看作一张图片输入CNN等模型,可以让模型学习到字的构成。

但分解为单个character后面临的就是语义多意的问题,“养只狗”、“单身狗”其中的“狗”都是狗,但是我们知道,两个“狗”其实是不同的,然鹅他们又不能完全分开,毕竟都用了一个字,其实咱们是将考虑到其语义的。

考虑上下文后,就诞生了语境词向量(Contextualized Word Embedding),输入模型的是整个句子,模型会阅读上下文,而不是仅仅考虑单个token,考虑语境后得到一个词向量表示。【Encoder行为】
语境词向量的模型一般模型会由多层组成,层结构常使用LSTM、Self-attention layers或者一些Tree-based model(与文法相关)。但Tree-base Model经过检验效果不突出,在文法结构严谨(解决数学公式)时,效果突出。

李老师列举了“苹果”在10个句子中的向量表示,两两计算相似度,得到一个10*10的混淆矩阵。可以明显观察到,水果苹果和苹果公司两个苹果语义有所区别。

预训练模型训练参数逐渐增加,网络结构逐渐复杂,各个公司都争相发布“全球最大预训练模型”。

(三)穷人的BERT
预训练模型参数量大,在训练时会消耗大量计算资源,都是一些互联网公司在做,像我们这些“穷人”,没有那么大的GPU算力,就会搞一些丐版BERT。

举例:
- Distill BERT
[1910.01108] DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter (arxiv.org)arxiv.org/abs/1910.01108
- Tiny BERT
[1909.10351v5] TinyBERT: Distilling BERT for Natural Language Understanding (arxiv.org)arxiv.org/abs/1909.10351v5
- Mobile BERT
[2004.02984] MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices (arxiv.org)arxiv.org/abs/2004.02984
- ALBERT(相比于原版BERT, 12层不同参数,ALBERT12层参数完全一致,效果甚至超过原版BERT一点点)
[1909.11942] ALBERT: A Lite BERT for Self-supervised Learning of Language Representations (arxiv.org)arxiv.org/abs/1909.11942
模型压缩技术:网络剪枝(Network Pruning)、知识蒸馏(Knowledge Distillation)、参数量化(Parameter Quantization)、架构设计(Architecture Design)

(四)架构设计(Architecture Design)
在该领域架构设计的目标,意在处理长文本语句。
典型代表,读者可以自行检索学习
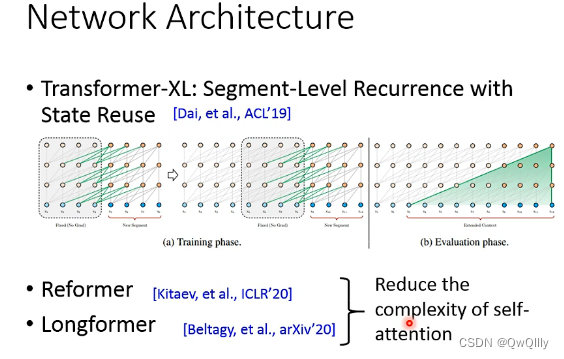
- Transformer-XL: Segment-Level Recurrence with State Reuse
[1901.02860] Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context (arxiv.org)arxiv.org/abs/1901.02860
- Reformer
[2001.04451] Reformer: The Efficient Transformer (arxiv.org)arxiv.org/abs/2001.04451
- Longformer
[2004.05150] Longformer: The Long-Document Transformer (arxiv.org)arxiv.org/abs/2004.05150
Reformer和Longformer意在降低Self-attention的复杂度。
二、怎么做 Fine-tune
预训练+微调范式是现在的主流形式,我们可以拿到大公司训练好的大模型,只需要根据自己的下游任务加一些Layer,就可以应用某一个具体的下游任务上。
预训练微调效果的实现,需要预训练模型针对该问题进行针对性设计。

(一)Input & Output
这里总结了NLP Tasks的常见输入输出。

- Input:
- one sentence: 直接丢进去。
- multiple sentences: Sentence1 SEP Sentence2, 句子分割。
- Ouput:
- one class: 加一个 CLS,或者直接将所有Embedding表示接下游任务分类
- class for each token
- copy from input: 可以解决阅读理解问题,QA。
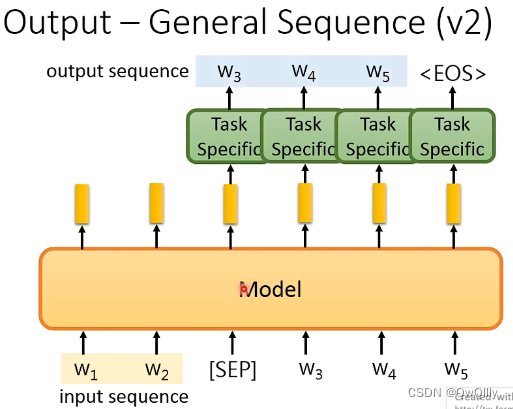
- General Sequence: 用到Seq2Seq Model
- v1:将预训练模型看作Encoder,将下游任务模型看作Decoder。
- v2:给出一个特别符号 SEP,得到字符再输入到预训练模型,让预训练模型encoder-decoder。







(二)How to fine-tune
如何微调也有两种,一种是冻结预训练模型,只微调下游任务对应的Task-specific部分;另一种是连同预训练模型,将整体网络结构进行参数微调(预训练模型参数不是随机初始化,可以有效避免过拟合)。

Adaptor
考虑到模型巨大,微调代价太大,且消耗存储大。引入Apt,只微调Pre-train Model中的一部分Apt。这样只需要存储Apt和Task specific. 此处举一个例子。



现在很多预训练模型中都是使用了Transformer的结构,研究者在Transformer结构中插入Adaptor层,通过训练微调Adaptor,而不去修改其他已经训练好的参数。



三、Why Pre-train Models?
研究者提出了GLUE指标,用来衡量机器与人在不同语言任务上的表现,随着深度学习的发展,预训练模型的迭代更新,现在预训练模型使得模型效果已经同人类水平相差无几。

四、Why Fine-tune?
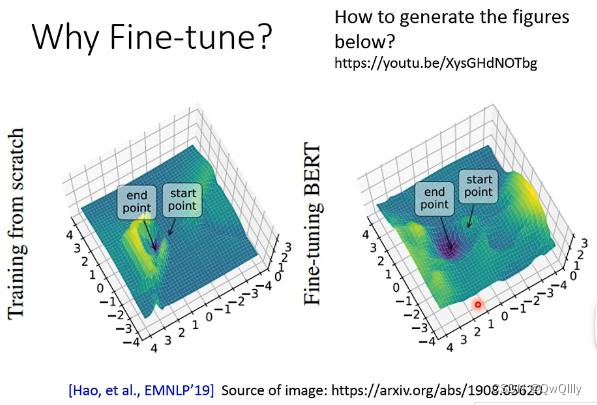
EMNLP19年刊发的一篇文章做了分析,在网络模型上fine-tune与否,Training Loss变化是不同的。
在有Fine-tune的情况下,Training Loss可以很好的实现收敛,而从头训练则会出现较大的波动。

同时考虑泛化能力,因为基于预训练模型将Training Loss降低到很低,有没有可能是过拟合导致的。海拔图可以表示,如果海拔图中,变化越陡峭,模型泛化能力越差,变化越平稳,模型泛化能力越强。
相关文章:
2022最新版-李宏毅机器学习深度学习课程-P50 BERT的预训练和微调
模型输入无标签文本(Text without annotation),通过消耗大量计算资源预训练(Pre-train)得到一个可以读懂文本的模型,在遇到有监督的任务是微调(Fine-tune)即可。 最具代表性是BERT&…...
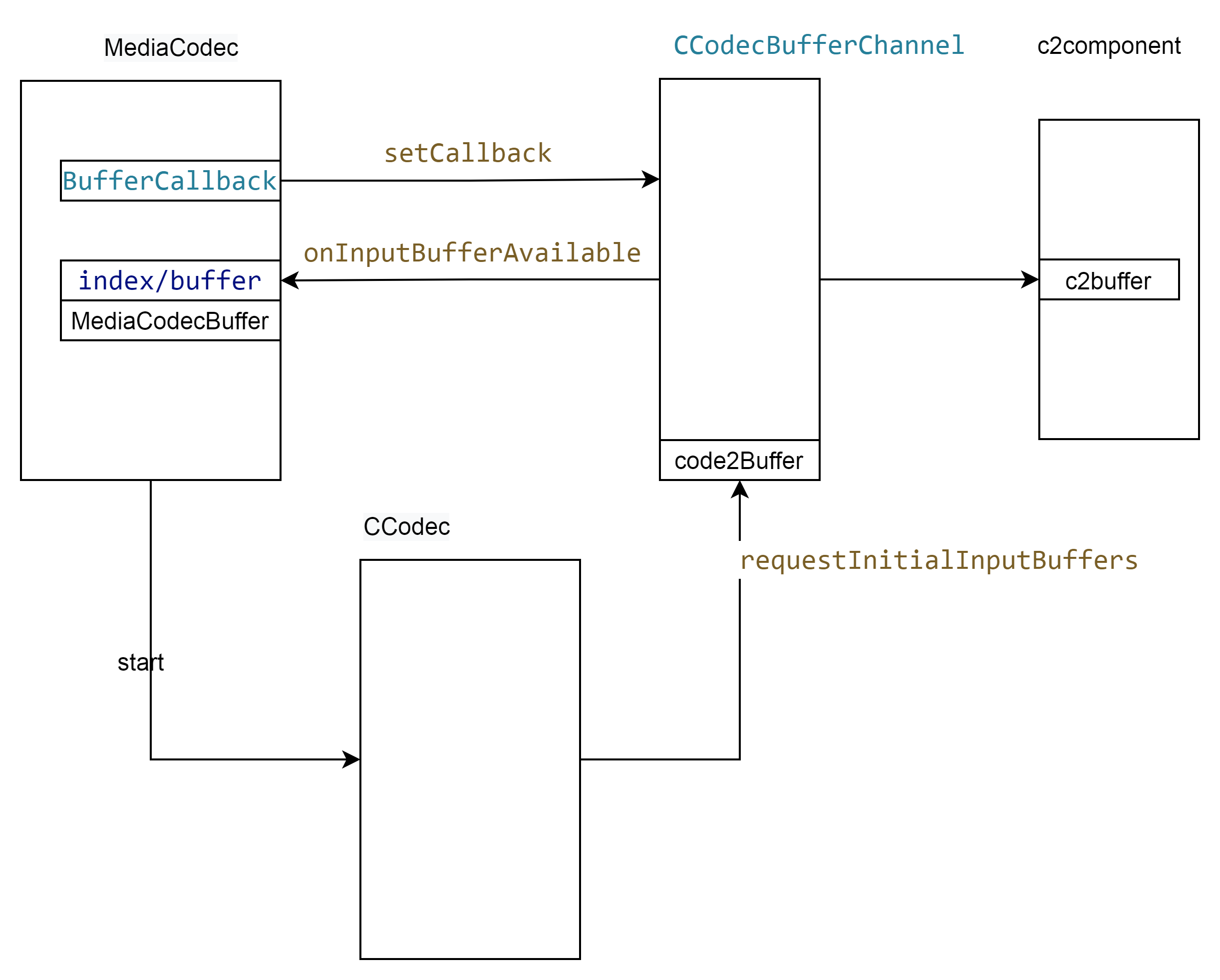
Android codec2 视频框架 之输入buffer
文章目录 输入端的内存管理输入数据包buffer结构体的转换 主要的流程如上, 申请内存在CCodecBufferChannel,申请之后回调到MediaCodec。然后应用从MediaCodec获取 将解码数据放到buffer中,CCodecBufferChannel在将这块buffer 送到componet模块…...

Python实现局部二进制算法(LBP)
1.介绍 局部二进制算法是一种用于获取图像纹理的算法。这算法可以应用于人脸识别、纹理分类、工业检测、遥感图像分析、动态纹理识别等领域。 2.示例 """ 局部二进制算法,计算图像纹理特征 """ import cv2 import numpy as np imp…...

如何评价现在的CSGO游戏搬砖市场
如何评价现在的csgo市场? 其实整个搬砖市场,现在已经变得乌烟瘴气,散发着“恶臭”。我个人非常鄙视那些虚有其表,大小通吃的做法,那些甚至连搬砖数据都看不懂的人,也出来吹嘘着“实力强大,经验丰…...

ResourceQuota对象在K8s上的说明
ResourceQuota资源对象的说明,以及在集群中的作用说明 定义说明 https://kubernetes.io/zh-cn/docs/concepts/policy/resource-quotas/ 集群中的资源组的划分和设计 在具有 32 GiB 内存和 16 核 CPU 资源的集群中,允许 A 团队使用 20 GiB 内存 和 10 核…...

悟空crm二次开发 增加客户保护功能 (很久没有消息,但是有觉得有机会的客户)就进入了保护转态
需求:客户信息录入不限数量,但是录入的信息1个月内只有自己和部门领导能看到,如果1个月内未成交或者未转移至自己的客保 则掉入公海所有人可见,这里所说的客保就是现在系统自带的客保 1、需求思维导图 2、新增保护按钮 3、点击该…...

k8s之配置资源管理
一,secret Secret 是用来保存密码、token、密钥等敏感数据的 k8s 资源,这类数据虽然也可以存放在 Pod 或者镜像中,但是放在 Secret 中是为了更方便的控制如何使用数据,并减少暴露的风险。 有三种类型: 1,k…...

赛氪助力全国大学生数学竞赛山东赛区圆满举办
近日,全国大学生数学竞赛山东赛区比赛有序进行,赛氪已连续6年助力本项赛事蓬勃发展。在中国高等教育学会高校竞赛评估与管理体系研究专家工作组发布的《2022全国普通高校大学生竞赛分析报告》中,本赛事荣登观察目录。 全国大学生数学竞赛旨在…...
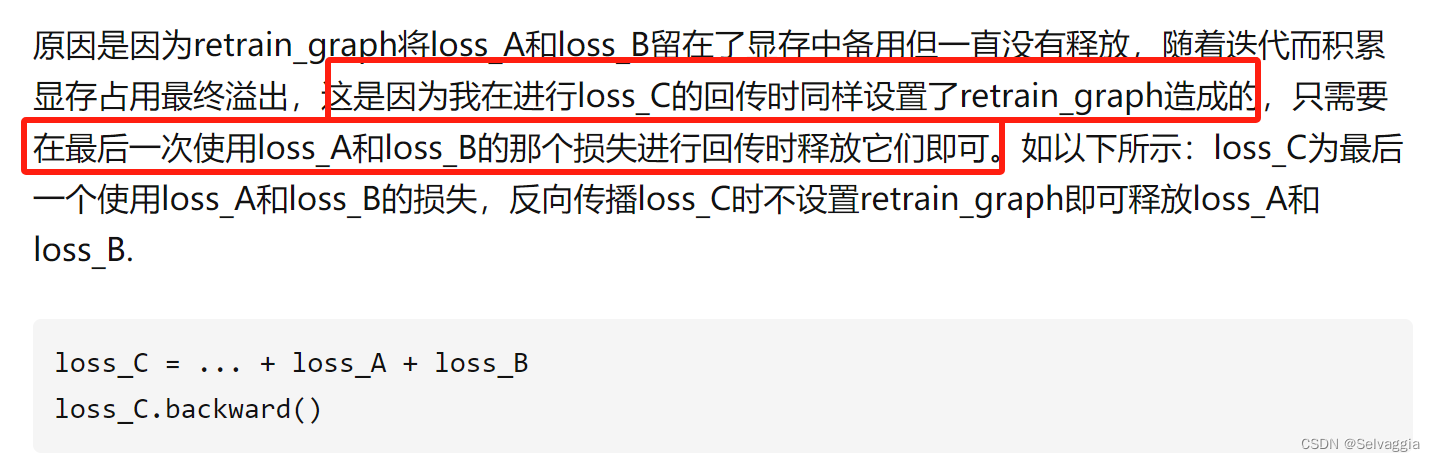
pytorch基础语法问题
这里写目录标题 pytorch基础语法问题shapetorch.ones_like函数和torch.zeros_like函数y.backward(torch.ones_like(x), retain_graphTrue)torch.autograd.backward参数grad_tensors: z.backward(torch.ones_like(x))来个复杂例子z.backward(torch.Tensor([[1., 0]])更复杂例子实…...
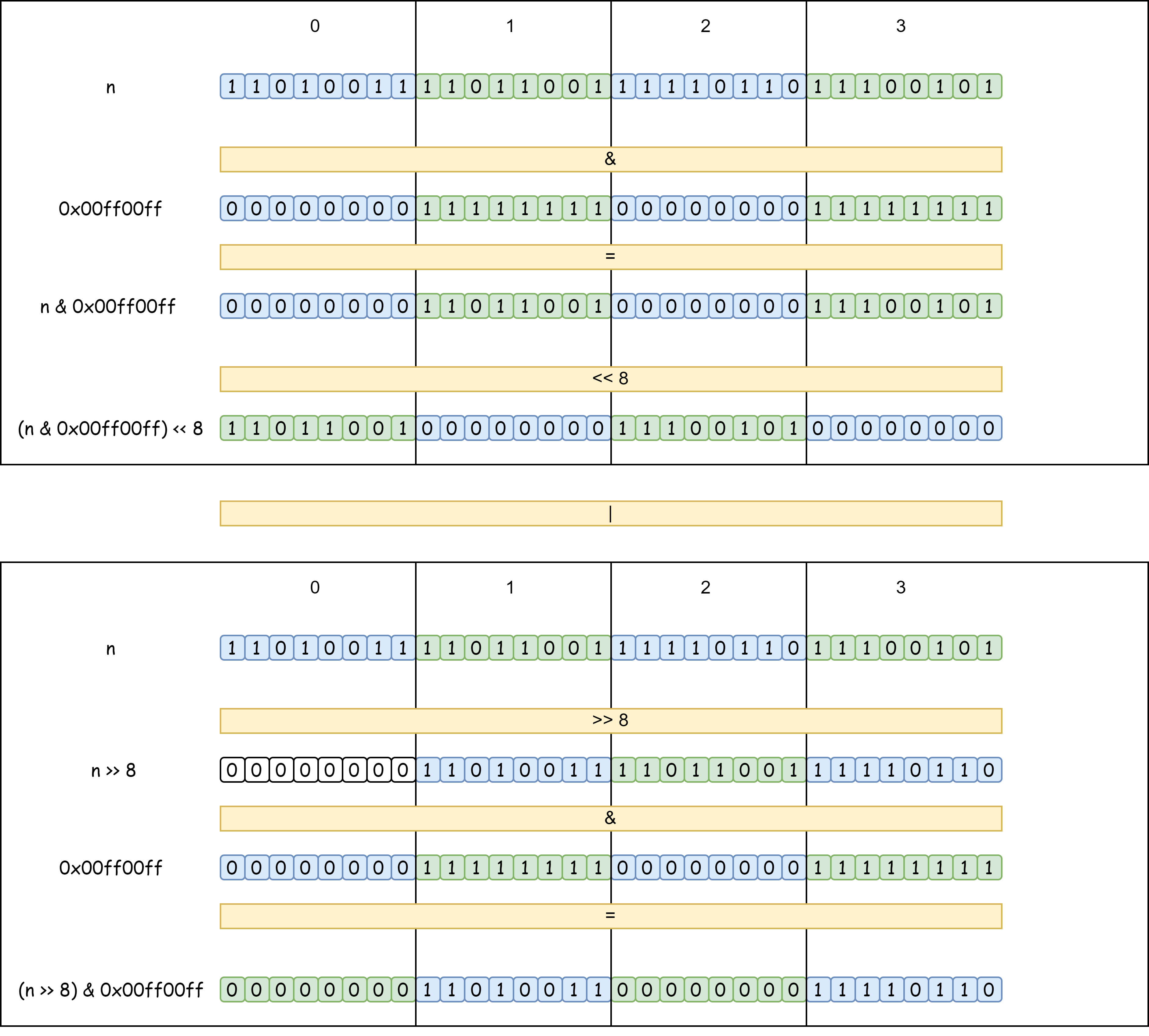
【面试经典150 | 】颠倒二进制位
文章目录 写在前面Tag题目来源题目解读解题思路方法一:逐位颠倒方法二:分治 写在最后 写在前面 本专栏专注于分析与讲解【面试经典150】算法,两到三天更新一篇文章,欢迎催更…… 专栏内容以分析题目为主,并附带一些对于…...

十分钟了解自动化测试
自动化测试 自动化测试的定义:使用一种自动化测试工具来验证各种软件测试的需求,它包括测试活动的管理与实施、测试脚本的开发与执行。 自动化测试只是测试工作的一部分,是对手工测试的一种补充; 自动化测试绝不能代替手工测试;多数情况下&…...

Redis配置文件
Redis可以在没有配置文件的情况下使用内置的默认配置启动,但是这种设置仅推荐用于测试和开发。 配置Redis的正确方法是提供一个Redis配置文件,通常称为 redis.conf 。 通过命令行传递参数启动 你也可以直接使用命令行传递Redis配置参数。这对于测试非…...

[量化投资-学习笔记009]Python+TDengine从零开始搭建量化分析平台-KDJ
技术分析有点像烹饪,收盘价、最值、成交量等是食材;均值,移动平均,方差等是烹饪方法。随意组合一下就是一个技术指标。 KDJ又称随机指标(随机这个名字起的很好)。KDJ的计算依据是最高价、最低价和收盘价。…...

Activiti6工作流引擎:Form表单
表单约等于流程变量。StartEvent 有一个Form属性,用于关联流程中涉及到的业务数据。 一:内置表单 每个节点都可以有不同的表单属性。 1.1 获取开始节点对应的表单 Autowired private FormService formService;Test void delopyProcess() {ProcessEngi…...

Fortran 中的指针
Fortran 中的指针 指针可以看作一种数据类型 指针存储与之关联的数据的内存地址变量指针:指向变量数组指针:指向数组过程指针:指向函数或子程序指针状态 未定义未关联 integer, pointer::p1>null() !或者 nullify(p1) 已关联 指针操作 指…...
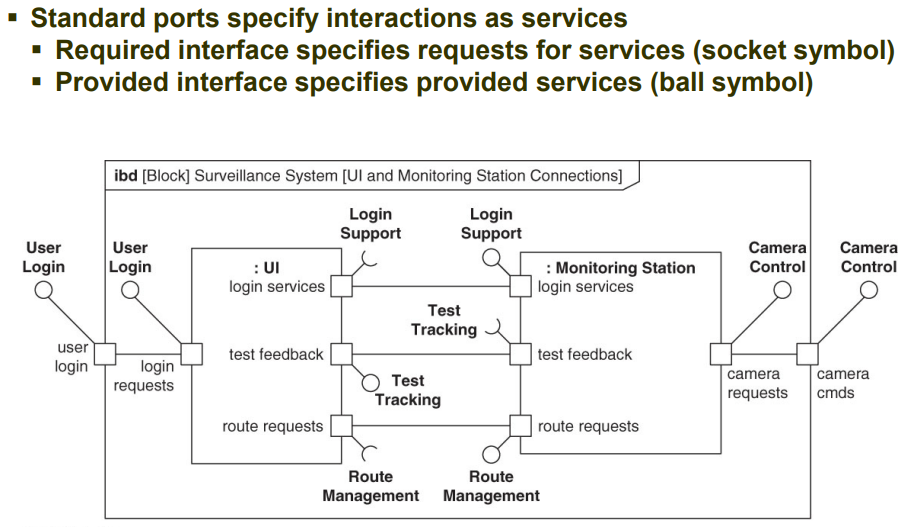
第七章 块为结构建模 P4|系统建模语言SysML实用指南学习
仅供个人学习记录 这部分感觉很模糊,理解的不好,后面的图也没画了,用到的时候再来翻书 应用端口实现接口建模 端口port表示了块边界上的一个访问点,也可以是由该块分类的任何组成或引用边界上的可访问点。一个块可以有多个端口规…...
提升中小企业效率的不可或缺的企业云盘网盘
相比之大型企业,中小型企业在挑选企业云盘工具更注重灵活性和成本。那么市面上有哪些企业云盘产品更适合中小企业呢? 说起中小企业不能错过的企业云盘网盘,Zoho Workdrive企业云盘绝对榜上有名! Zoho Workdrive企业云盘为用户提…...

Web 安全之时序攻击 Timing Attack 详解
目录 什么是 Timing Attack 攻击? Timing Attack 攻击原理 Timing Attack 攻击的几种基本类型 如何防范 Timing Attack 攻击 小结 什么是 Timing Attack 攻击? Timing Attack(时序攻击)是一种侧信道攻击(timing s…...

【objectarx.net】定时器的使用
【objectarx.net】定时器的使用...

C++:容器list的介绍及使用
目录 1.list的介绍及使用 1.1 list的介绍 1.2 list的使用 1.2.1 list的构造 1.2.2 list iterator 的使用 1.2.3 list capacity 容量 1.2.4 list element access 访问list元素 1.2.5 list modifiers 修改 1.2.6 迭代器失效 1.list的介绍及使用 1.1 list的介绍 C官网 …...

如何高效获取抖音无水印视频:douyin-downloader 完整实战指南
如何高效获取抖音无水印视频:douyin-downloader 完整实战指南 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallbac…...

GDAL投影定义实战:proj.db冲突排查与环境变量配置指南
1. 为什么你的GDAL投影定义会报错? 最近在处理一批遥感影像数据时,遇到了一个让人头疼的问题:明明代码写得没问题,但就是报错。具体来说,当我尝试用GDAL的osr模块给影像定义投影时,控制台突然蹦出一串红色错…...

如何免费解锁Cursor Pro完整功能:终极指南
如何免费解锁Cursor Pro完整功能:终极指南 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your trial request …...

Kali Linux 2023.4 安装指南:从下载到避坑全攻略
1. Kali Linux 2023.4 安装前的准备工作 第一次接触Kali Linux的朋友可能会被它酷炫的黑客主题界面吸引,但安装过程往往让人头疼。作为安全测试领域的瑞士军刀,Kali Linux 2023.4版本在硬件兼容性和工具链上都有显著提升。我在实际安装过程中发现&#…...

SD-PPP完整实用指南:如何让Photoshop与AI绘图无缝协作
SD-PPP完整实用指南:如何让Photoshop与AI绘图无缝协作 【免费下载链接】sd-ppp A Photoshop AI plugin 项目地址: https://gitcode.com/gh_mirrors/sd/sd-ppp SD-PPP是一款革命性的Photoshop AI插件,它能将Adobe Photoshop与ComfyUI、Stable Diff…...

终极指南:5步快速掌握VRChat动画工具,实现虚拟形象手势管理高效创作
终极指南:5步快速掌握VRChat动画工具,实现虚拟形象手势管理高效创作 【免费下载链接】VRC-Gesture-Manager A tool that will help you preview and edit your VRChat avatar animation directly in Unity. 项目地址: https://gitcode.com/gh_mirrors/…...

2025届毕业生推荐的十大降重复率平台实测分析
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 我们能够通过文本重构来有效降低检测风险,针对的是维普系统对AI生成内容的识别机…...

星际蜗牛矿机变家庭影院:用群晖Docker部署Jellyfin的完整避坑记录
星际蜗牛矿机变家庭影院:用群晖Docker部署Jellyfin的完整避坑记录 去年在二手市场淘了台星际蜗牛矿机,原本打算当个下载机用,没想到这台不到500元的设备竟成了我家的影音中枢。从矿渣到NAS再到4K流媒体服务器,整个过程踩坑无数&am…...

Qwerty Learner:掌握英语输入肌肉记忆的终极训练神器
Qwerty Learner:掌握英语输入肌肉记忆的终极训练神器 【免费下载链接】qwerty-learner 为键盘工作者设计的单词记忆与英语肌肉记忆锻炼软件 / Words learning and English muscle memory training software designed for keyboard workers 项目地址: https://gitc…...
)
手把手教你用Xilinx Artix-7和MT41J256M16RH-125:E配置MIG IP核(避坑指南)
从芯片手册到MIG配置:Artix-7与DDR3硬件设计实战解析 当FPGA开发者第一次面对DDR3内存接口设计时,数据手册里密密麻麻的参数表格和Vivado中复杂的MIG配置界面往往让人望而生畏。本文将以美光MT41J256M16RH-125:E内存芯片与Xilinx Artix-7系列FPGA的组合为…...