[NLP] 使用Llama.cpp和LangChain在CPU上使用大模型
一 准备工作
下面是构建这个应用程序时将使用的软件工具:
1.Llama-cpp-python
下载llama-cpp, llama-cpp-python
[NLP] Llama2模型运行在Mac机器-CSDN博客
2、LangChain
LangChain是一个提供了一组广泛的集成和数据连接器,允许我们链接和编排不同的模块。可以常见聊天机器人、数据分析和文档问答等应用。
3、sentence-transformer
sentence-transformer提供了简单的方法来计算句子、文本和图像的嵌入。它能够计算100多种语言的嵌入。我们将在这个项目中使用开源的all-MiniLM-L6-v2模型。
4、FAISS
Facebook AI相似度搜索(FAISS)是一个为高效相似度搜索和密集向量聚类而设计的库。
给定一组嵌入,我们可以使用FAISS对它们进行索引,然后利用其强大的语义搜索算法在索引中搜索最相似的向量。
虽然它不是传统意义上的成熟的向量存储(如数据库管理系统),但它以一种优化的方式处理向量的存储,以实现有效的最近邻搜索。
二 LLM应用架构:以文档Q&A为例
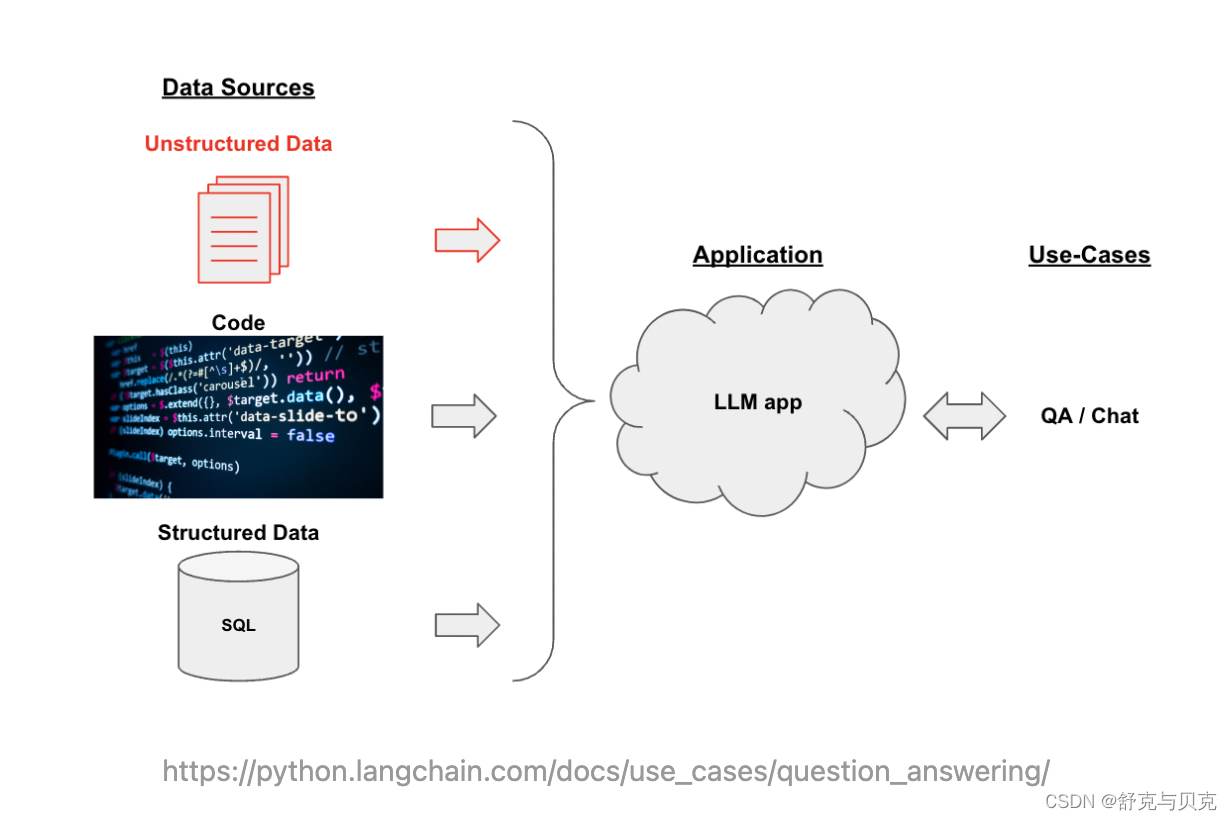
假设我们想基于自己部署的Llama2模型,构建一个用于回答针对特定文档内容提问的聊天机器人。文档的内容可能属于特定领域或者特定组织内的文档,因此不属于任何Llama2进行预训练和微调的数据集。一个直觉的做法是in-context-learning:将文档作为Prompt提供给模型,从而模型能够根据所提供的Context进行回答。直接将文档作为Context可能遇到的问题是:
- 文档的长度超出了模型的Context长度限制,原版Llama2的Context长度为4096个Tokens。
- 对于较长的Context,模型可能会Lost in the Middle,无法准确从Context中获取关键信息。
因此,我们希望在构建Prompt时,只输入与用户的问题最相关的文档内容。
以下是构建文档Q&A应用的常用架构:
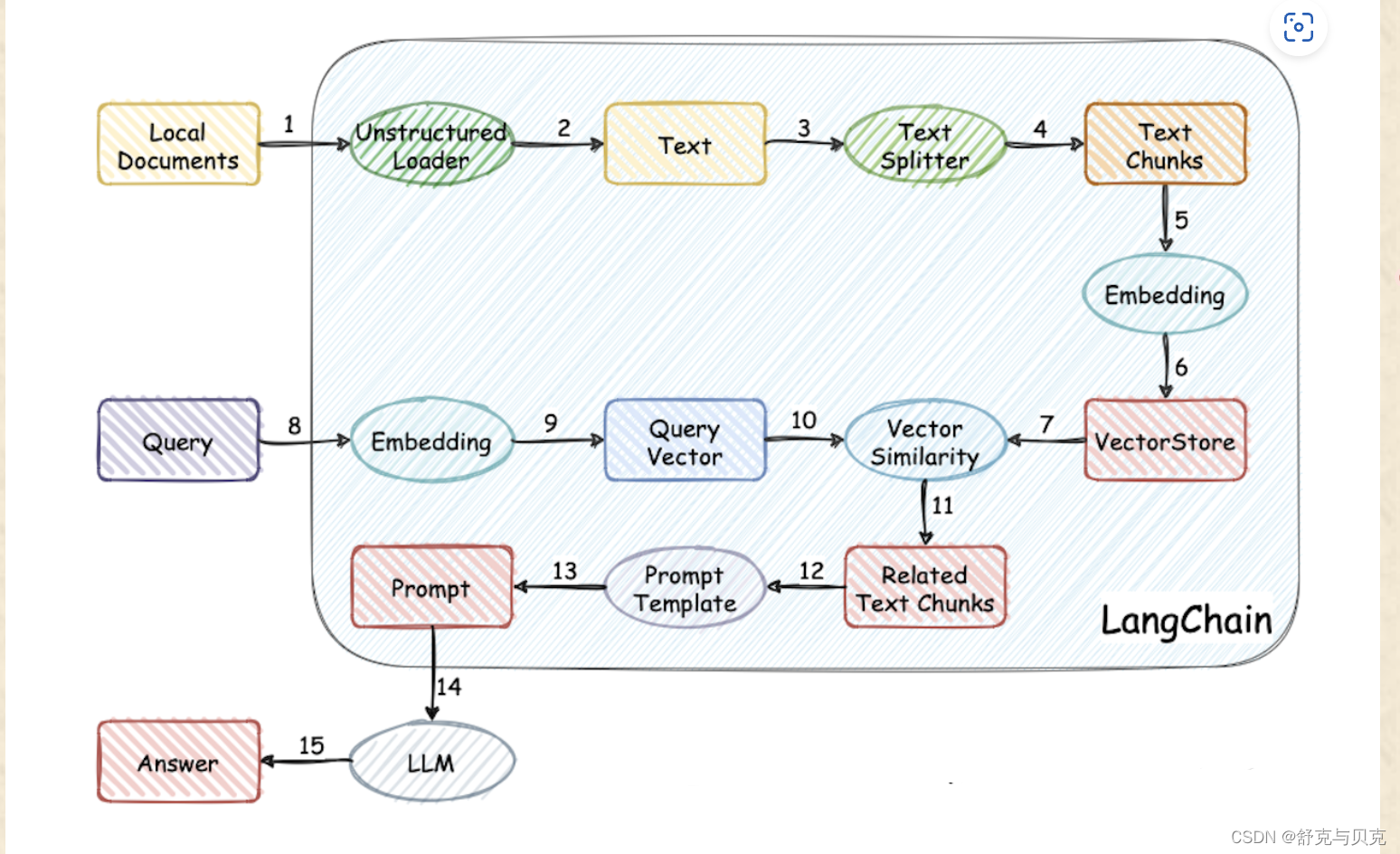
- 文档处理与存储:将原始文本进行分块 (Splitting),并使用语言模型对每块文本进行embedding,得到文本的向量表示,最后将文本向量存储在支持相似性搜索的向量数据库中。
- 用户询问和Prompt构建:根据用户输入的询问,使用相似性搜索在向量数据库中提取出与询问最相关的一些文档分块,并将用户询问+文档一起构建Prompt,随后输入LLM并得到回答。
三 实际使用
LangChain
在上节中描述了以文档Q&A为例的LLM应用Pipeline架构。LangChain是构建该类大模型应用的框架,其提供了模块化组件(例如上文图中的Document loader, Text splitter, Vector storage)的抽象和实现,并支持集成第三方的实现(例如可以使用不同第三方提供的Vector Storage服务)。通过LangChain可以将大模型与自定义的数据源结合起来构建Pipeline。
https://github.com/langchain-ai/langchaingithub.com/langchain-ai/langchain
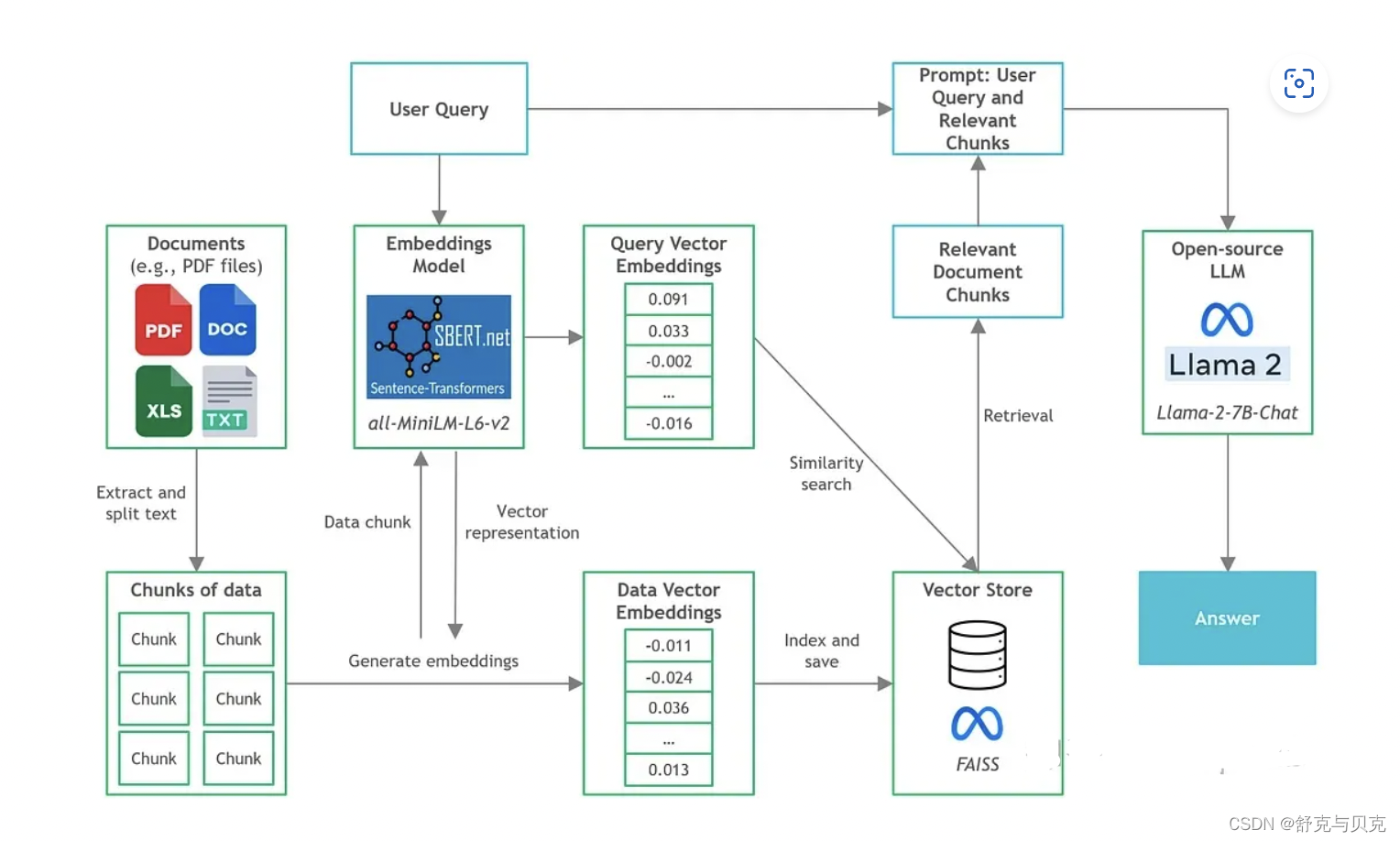
构建步骤
我们已经了解了各种组件,接下来让逐步介绍如何构建文档问答应用程序。
由于已经有许多教程了,所以我们不会深入到复杂和一般的文档问答组件的细节(例如,文本分块,矢量存储设置)。在本文中,我们将把重点放在开源LLM和CPU推理方面。
使用llama-cpp-python启动llama2 api服务
python3 -m llama_cpp.server --model TheBloke--Chinese-Alpaca-2-7B-GGUF/chinese-alpaca-2-7b.Q4_K_M.gguf --n_gpu_layers 1INFO: Started server process [63148]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://localhost:8000 (Press CTRL+C to quit)使用LangChain调用本地部署的Llama2
下面的示例将使用LangChain的API调用本地部署的Llama2模型。
from langchain.chat_models import ChatOpenAIchat_model = ChatOpenAI(openai_api_key = "EMPTY", openai_api_base = "http://localhost:8000/v1", max_tokens=256)- 由于本地部署的llama-cpp-python提供了类OpenAI的API,因此可以直接使用
ChatOpenAI接口,这将调用/v1/chat/completionsAPI。 - 由于并没有使用真正的OpenAI API,因此
open_ai_key可以任意提供。openai_pi_base为模型API的Base URL。max_tokens限制了模型回答的长度。
from langchain.chat_models import ChatOpenAIchat_model = ChatOpenAI(openai_api_key = "EMPTY", openai_api_base = "http://localhost:8000/v1", max_tokens=256)from langchain.schema import AIMessage, HumanMessage, SystemMessagesystem_text = "You are a helpful assistant."
human_text1 = "What is the capital of France?"
assistant_text = "Paris."
human_text2 = "How about England?"messages = [SystemMessage(content=system_text), HumanMessage(content=human_text1), AIMessage(content=assistant_text), HumanMessage(content=human_text2)]chat_model.predict_messages(messages)
这里将演示如何使用LangChain构建一个简单的文档Q&A应用Pipeline:
- Document Loading + Text Splitting
- Text Embeddings + Vector Storage
- Text Retrieval + Query LLM
1 数据加载与处理 Document Loading + Text Splitting
本实验使用llama.cpp的README.md作为我们需要进行询问的文档。LangChain提供了一系列不同格式文档的Loader,包括用于加载Markdown文档的UnstructuredMarkdownLoader:
UnstructuredMarkdownLoader默认会将文档中的不同Elements(各级标题,正文等)组合起来,去掉了#等字符。
RecursiveCharacterTextSplitter是对常见文本进行Split的推荐选择:
RecursiveCharacterTextSplitter递归地在文本中寻找能够进行分割的字符(默认为["\n\n", "\n", " ", ""])。这将尽可能地保留完整的段落,句子和单词。
chunk_size: 文本进行Split后每个分块的最大长度,所有分块将在这个限制以内chunk_overlap: 前后分块overlap的长度,overlap是为了保持前后两个分块之间的语义连续性length_function: 度量文本长度的方法
from langchain.document_loaders import UnstructuredMarkdownLoaderloader = UnstructuredMarkdownLoader("./README.md")
text = loader.load()from langchain.text_splitter import RecursiveCharacterTextSplittertext_splitter = RecursiveCharacterTextSplitter(chunk_size = 2000,chunk_overlap = 400,length_function = len,is_separator_regex = False
)
all_splits = text_splitter.split_documents(text)

2.矢量存储 Text Embeddings + Vector Storage
这一步的任务是:将文本分割成块,加载嵌入模型,然后通过FAISS 进行向量的存储
Vector Storage
这里以FAISS向量数据库作为示例, FAISS基于Facebook AI Similarity Search(Faiss)库 。
pip install faiss-cpufrom langchain.embeddings import HuggingFaceEmbeddings
# Load embeddings model
embeddings = HuggingFaceEmbeddings(model_name='sentence-transformers/all-MiniLM-L6-v2', model_kwargs={'device': 'cpu'}) from langchain.vectorstores import FAISS
vectorstore = FAISS.from_documents(all_splits, embeddings)
vectorstore.save_local('vectorstore/db_faiss')#question = "How to run the program in interactive mode?"
#docs = vectorstore.similarity_search(question, k=1)

运行上面的Python脚本后,向量存储将被生成并保存在名为'vectorstore/db_faiss'的本地目录中,并为语义搜索和检索做好准备。
3.文本检索与LLM查询 Text Retrieval + Query LLM
from langchain.llms import OpenAI
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQAchat_model = ChatOpenAI(openai_api_key = "EMPTY", openai_api_base = "http://localhost:8000/v1", max_tokens=256)qa_chain = RetrievalQA.from_chain_type(chat_model, retriever=vectorstore.as_retriever(search_kwargs={"k": 1}))
qa_chain({"query": "How to run the program in interactive mode?"})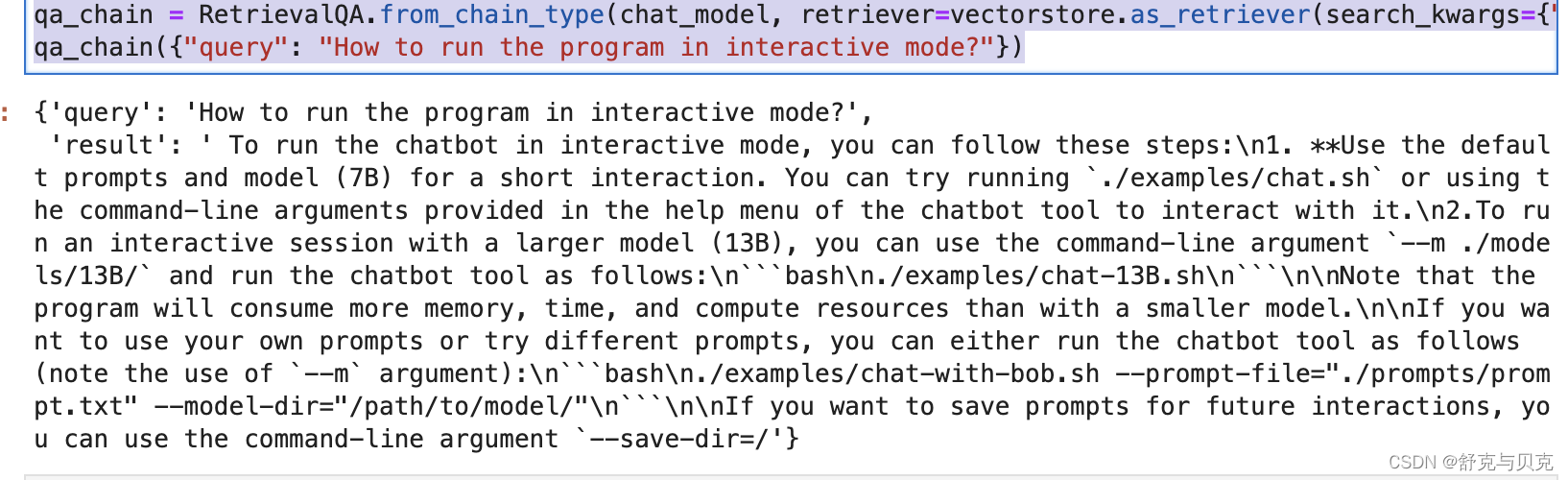
构造RetrievalQA需要提供一个LLM的实例,我们提供基于本地部署的Llama2构造的ChatOpenAI;还需要提供一个文本的Retriever,我们提供FAISS向量数据库作为一个Retriever,参数search_kwargs={"k":1}设置了Retriever提取的文档分块的数量,决定了最终Prompt包含的文档内容的数量,在这里我们设置为1。 向Chain中传入询问,即可得到LLM根据Retriever提取的文档做出的回答。
自定义RetrievalQA的Prompt:
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplatetemplate = """Use the following pieces of context to answer the question at the end.
If you don't know the answer, just say that you don't know, don't try to make up an answer.
Use three sentences maximum and keep the answer as concise as possible.
Always say "thanks for asking!" at the end of the answer.
{context}
Question: {question}
Helpful Answer:"""
QA_CHAIN_PROMPT = PromptTemplate.from_template(template)qa_chain = RetrievalQA.from_chain_type(chat_model,retriever=vectorstore.as_retriever(search_kwargs={"k": 1}),chain_type_kwargs={"prompt": QA_CHAIN_PROMPT}
)
qa_chain({"query": "What is --interactive option used for?"})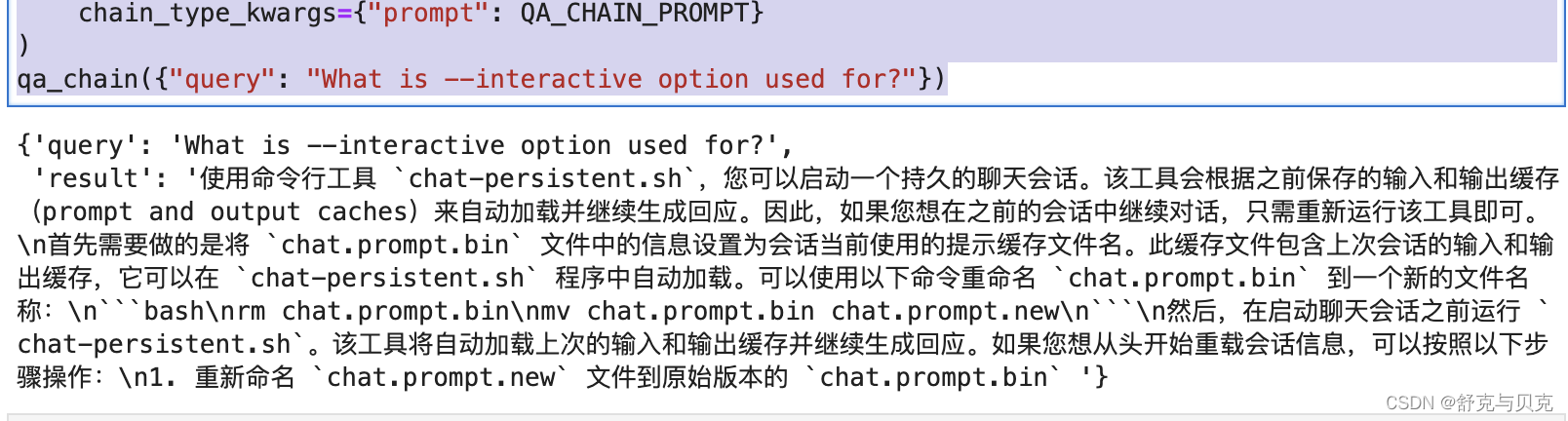
结论
本文介绍了如何在MacBook Pro本地环境使用llama.cpp部署ggml量化格式的Llama2语言模型,并演示如何使用LangChain简单构造了一个文档Q&A应用。
References
[1] https://github.com/ggerganov/llama.cpp
[2] QA over Documents | ️ Langchain
在MacBook Pro部署Llama2语言模型并基于LangChain构建LLM应用 - 知乎 (zhihu.com)
使用GGML和LangChain在CPU上运行量化的llama2 - 知乎 (zhihu.com)
相关文章:
[NLP] 使用Llama.cpp和LangChain在CPU上使用大模型
一 准备工作 下面是构建这个应用程序时将使用的软件工具: 1.Llama-cpp-python 下载llama-cpp, llama-cpp-python [NLP] Llama2模型运行在Mac机器-CSDN博客 2、LangChain LangChain是一个提供了一组广泛的集成和数据连接器,允许我们链接和编排不同的模块。可以常…...

开发知识点-Ant-Design-Vue
Ant-Design-Vue a-input a-input Vue组件 a-spin 加载中的效果 data字段 mounted钩子函数 Ant Design Vue 组件库 list-type“picture-card” 上传的图片作为卡片展示 name show-upload-list action :beforeUpload“handleBeforeUpload” :headers“customHeaders” :disabl…...
2022最新版-李宏毅机器学习深度学习课程-P50 BERT的预训练和微调
模型输入无标签文本(Text without annotation),通过消耗大量计算资源预训练(Pre-train)得到一个可以读懂文本的模型,在遇到有监督的任务是微调(Fine-tune)即可。 最具代表性是BERT&…...
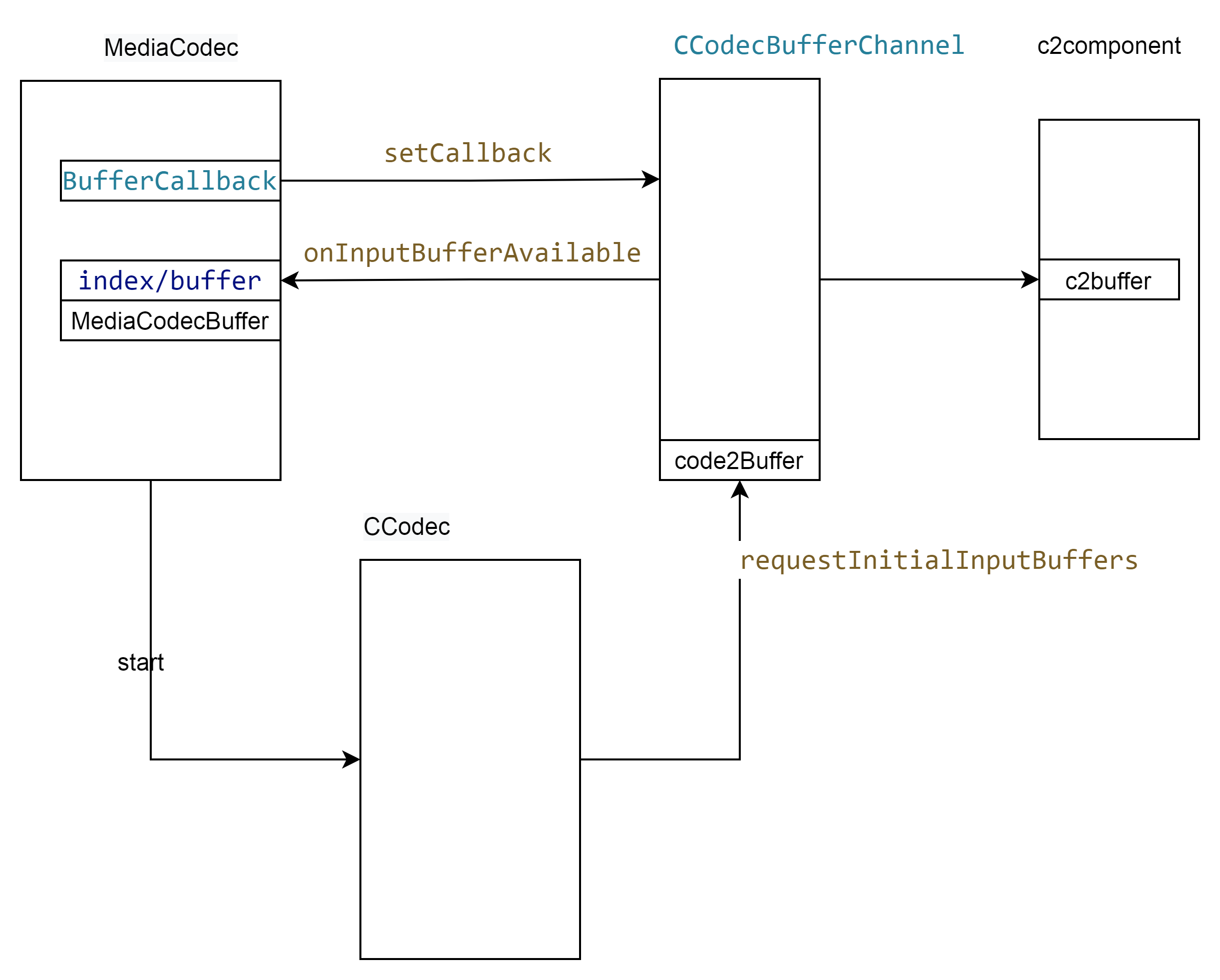
Android codec2 视频框架 之输入buffer
文章目录 输入端的内存管理输入数据包buffer结构体的转换 主要的流程如上, 申请内存在CCodecBufferChannel,申请之后回调到MediaCodec。然后应用从MediaCodec获取 将解码数据放到buffer中,CCodecBufferChannel在将这块buffer 送到componet模块…...

Python实现局部二进制算法(LBP)
1.介绍 局部二进制算法是一种用于获取图像纹理的算法。这算法可以应用于人脸识别、纹理分类、工业检测、遥感图像分析、动态纹理识别等领域。 2.示例 """ 局部二进制算法,计算图像纹理特征 """ import cv2 import numpy as np imp…...

如何评价现在的CSGO游戏搬砖市场
如何评价现在的csgo市场? 其实整个搬砖市场,现在已经变得乌烟瘴气,散发着“恶臭”。我个人非常鄙视那些虚有其表,大小通吃的做法,那些甚至连搬砖数据都看不懂的人,也出来吹嘘着“实力强大,经验丰…...

ResourceQuota对象在K8s上的说明
ResourceQuota资源对象的说明,以及在集群中的作用说明 定义说明 https://kubernetes.io/zh-cn/docs/concepts/policy/resource-quotas/ 集群中的资源组的划分和设计 在具有 32 GiB 内存和 16 核 CPU 资源的集群中,允许 A 团队使用 20 GiB 内存 和 10 核…...

悟空crm二次开发 增加客户保护功能 (很久没有消息,但是有觉得有机会的客户)就进入了保护转态
需求:客户信息录入不限数量,但是录入的信息1个月内只有自己和部门领导能看到,如果1个月内未成交或者未转移至自己的客保 则掉入公海所有人可见,这里所说的客保就是现在系统自带的客保 1、需求思维导图 2、新增保护按钮 3、点击该…...

k8s之配置资源管理
一,secret Secret 是用来保存密码、token、密钥等敏感数据的 k8s 资源,这类数据虽然也可以存放在 Pod 或者镜像中,但是放在 Secret 中是为了更方便的控制如何使用数据,并减少暴露的风险。 有三种类型: 1,k…...

赛氪助力全国大学生数学竞赛山东赛区圆满举办
近日,全国大学生数学竞赛山东赛区比赛有序进行,赛氪已连续6年助力本项赛事蓬勃发展。在中国高等教育学会高校竞赛评估与管理体系研究专家工作组发布的《2022全国普通高校大学生竞赛分析报告》中,本赛事荣登观察目录。 全国大学生数学竞赛旨在…...
pytorch基础语法问题
这里写目录标题 pytorch基础语法问题shapetorch.ones_like函数和torch.zeros_like函数y.backward(torch.ones_like(x), retain_graphTrue)torch.autograd.backward参数grad_tensors: z.backward(torch.ones_like(x))来个复杂例子z.backward(torch.Tensor([[1., 0]])更复杂例子实…...
【面试经典150 | 】颠倒二进制位
文章目录 写在前面Tag题目来源题目解读解题思路方法一:逐位颠倒方法二:分治 写在最后 写在前面 本专栏专注于分析与讲解【面试经典150】算法,两到三天更新一篇文章,欢迎催更…… 专栏内容以分析题目为主,并附带一些对于…...

十分钟了解自动化测试
自动化测试 自动化测试的定义:使用一种自动化测试工具来验证各种软件测试的需求,它包括测试活动的管理与实施、测试脚本的开发与执行。 自动化测试只是测试工作的一部分,是对手工测试的一种补充; 自动化测试绝不能代替手工测试;多数情况下&…...

Redis配置文件
Redis可以在没有配置文件的情况下使用内置的默认配置启动,但是这种设置仅推荐用于测试和开发。 配置Redis的正确方法是提供一个Redis配置文件,通常称为 redis.conf 。 通过命令行传递参数启动 你也可以直接使用命令行传递Redis配置参数。这对于测试非…...

[量化投资-学习笔记009]Python+TDengine从零开始搭建量化分析平台-KDJ
技术分析有点像烹饪,收盘价、最值、成交量等是食材;均值,移动平均,方差等是烹饪方法。随意组合一下就是一个技术指标。 KDJ又称随机指标(随机这个名字起的很好)。KDJ的计算依据是最高价、最低价和收盘价。…...

Activiti6工作流引擎:Form表单
表单约等于流程变量。StartEvent 有一个Form属性,用于关联流程中涉及到的业务数据。 一:内置表单 每个节点都可以有不同的表单属性。 1.1 获取开始节点对应的表单 Autowired private FormService formService;Test void delopyProcess() {ProcessEngi…...

Fortran 中的指针
Fortran 中的指针 指针可以看作一种数据类型 指针存储与之关联的数据的内存地址变量指针:指向变量数组指针:指向数组过程指针:指向函数或子程序指针状态 未定义未关联 integer, pointer::p1>null() !或者 nullify(p1) 已关联 指针操作 指…...
第七章 块为结构建模 P4|系统建模语言SysML实用指南学习
仅供个人学习记录 这部分感觉很模糊,理解的不好,后面的图也没画了,用到的时候再来翻书 应用端口实现接口建模 端口port表示了块边界上的一个访问点,也可以是由该块分类的任何组成或引用边界上的可访问点。一个块可以有多个端口规…...
提升中小企业效率的不可或缺的企业云盘网盘
相比之大型企业,中小型企业在挑选企业云盘工具更注重灵活性和成本。那么市面上有哪些企业云盘产品更适合中小企业呢? 说起中小企业不能错过的企业云盘网盘,Zoho Workdrive企业云盘绝对榜上有名! Zoho Workdrive企业云盘为用户提…...

Web 安全之时序攻击 Timing Attack 详解
目录 什么是 Timing Attack 攻击? Timing Attack 攻击原理 Timing Attack 攻击的几种基本类型 如何防范 Timing Attack 攻击 小结 什么是 Timing Attack 攻击? Timing Attack(时序攻击)是一种侧信道攻击(timing s…...

从刚体动力学到生物力学:MuJoCo肌腱系统的技术演进与工程实践
从刚体动力学到生物力学:MuJoCo肌腱系统的技术演进与工程实践 【免费下载链接】mujoco Multi-Joint dynamics with Contact. A general purpose physics simulator. 项目地址: https://gitcode.com/GitHub_Trending/mu/mujoco 在物理仿真领域,从传…...

告别追番焦虑:Mikan Project 一站式动漫管理解决方案
告别追番焦虑:Mikan Project 一站式动漫管理解决方案 【免费下载链接】mikan_flutter 蜜柑计划( https://mikanani.me ),🚧 持续开发中... 项目地址: https://gitcode.com/gh_mirrors/mi/mikan_flutter 你是否曾…...

一键下载30+文档平台:kill-doc让你轻松保存网页内容
一键下载30文档平台:kill-doc让你轻松保存网页内容 【免费下载链接】kill-doc 看到经常有小伙伴们需要下载一些免费文档,但是相关网站浏览体验不好各种广告,各种登录验证,需要很多步骤才能下载文档,该脚本就是为了解决…...

如何突破Windows窗口限制?WindowResizer终极调整指南
如何突破Windows窗口限制?WindowResizer终极调整指南 【免费下载链接】WindowResizer 一个可以强制调整应用程序窗口大小的工具 项目地址: https://gitcode.com/gh_mirrors/wi/WindowResizer 你是否曾被那些顽固的Windows窗口所困扰?有些应用程序…...
从‘你好世界’到模型输入:手把手用PyTorch+Transformers Tokenizer完成文本预处理全流程
从‘你好世界’到模型输入:手把手用PyTorchTransformers Tokenizer完成文本预处理全流程 当你第一次接触自然语言处理(NLP)时,可能会被各种术语和概念搞得晕头转向。但别担心,每个NLP工程师都曾经历过从"Hello Wo…...

激活函数选型指南:从ReLU到RReLU,如何根据你的数据集大小和任务特性做选择?
激活函数实战选型手册:从ReLU到RReLU的深度决策框架 在深度学习模型构建过程中,激活函数的选择往往被当作一个默认参数处理——大多数人会不假思索地选择ReLU。但当我们面对特定任务时,这种"一刀切"的做法可能让模型性能大打折扣。…...

图论基础:图的表示、遍历、最短路径入门
文章目录前言一、图论入门:先搞懂什么是图1.1 图的核心定义1.2 图的常见分类(1)无向图 vs 有向图(2)无权图 vs 有权图1.3 图的基础术语二、图的表示:计算机怎么存储图2.1 邻接矩阵:直观但费空间…...

Android Studio中文界面终极配置指南:5分钟告别英文困扰,开启高效开发之旅
Android Studio中文界面终极配置指南:5分钟告别英文困扰,开启高效开发之旅 【免费下载链接】AndroidStudioChineseLanguagePack AndroidStudio中文插件(官方修改版本) 项目地址: https://gitcode.com/gh_mirrors/an/AndroidStudioChineseLa…...

EasyAnimateV5-7b-zh-InP开源大模型实战:对接OSS对象存储自动归档生成视频
EasyAnimateV5-7b-zh-InP开源大模型实战:对接OSS对象存储自动归档生成视频 1. 从图片到视频:EasyAnimateV5-7b-zh-InP模型初探 你有没有想过,一张静态的照片,能在几秒钟内“活”过来,变成一段生动的短视频࿱…...

HsMod终极指南:55项功能解锁炉石传说高级玩法
HsMod终极指南:55项功能解锁炉石传说高级玩法 【免费下载链接】HsMod Hearthstone Modification Based on BepInEx 项目地址: https://gitcode.com/GitHub_Trending/hs/HsMod HsMod是基于BepInEx框架开发的炉石传说多功能增强插件,提供55项实用功…...