经典算法(查找与排序)
查找
- 顺序查找
顺序查找(Linear Search)是一种在有序数组中查找目标元素的基本算法。它的时间复杂度为 O(n),适用于查找少量数据。顺序查找的基本思想是从数组的第一个元素开始,逐个与待查找的元素进行比较,直到找到目标元素或遍历完整个数组。
package com.zhx;public class Test {//顺序查找public static int seqSearch(int[] array, int target) {for (int i = 0; i < array.length; i++) {int p = array[i];if (p == target) {System.out.println("sucess to find out "+target+" from array, index="+i);return i;}}System.out.println("fail to find out the target");return -1;}public static void main(String[] args) {int[] data = { 3, 6, 7, 2, 12, 9, 0, 11 };System.out.println(seqSearch(data, 12));}
}
- 折半查找
折半查找(Binary Search)是一种在有序数组中查找目标元素的高效算法。它的时间复杂度为 O(logn),常用于查找大量数据。折半查找的基本思想是将待查找的范围逐步缩小,每次将范围缩小一半。前提是数组有序。
package com.zhx;public class Test1 {//折半查找public static int seqSearch(int[] array, int target) {int lo = 0;int hi = array.length - 1;while (lo <= hi) {int mid = lo + (hi - lo) / 2;if (target < array[mid]) {hi = mid - 1;} else if (target > array[mid]) {lo = mid + 1;} else {return mid;}}return -1;}public static void main(String[] args) {int[] data = { 10, 11, 12, 16, 18, 23, 29, 33, 48, 54, 57, 68, 77, 84, 98 };System.out.println(seqSearch(data, 23));}
}
排序
- 冒泡排序
冒泡排序(Bubble Sort)是一种简单的排序算法,它重复地遍历待排序的数列,一次比较两个元素,如果顺序错误就把它们交换过来。遍历数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。
import java.util.Arrays;public class Test {public static void bubbleSort(int[] arr) {for (int i = 1; i < arr.length; i++) {// i=1, j=4// i=2, j=3// i=3, j=2// j=arr.length-1-ifor (int j = 0; j <= arr.length - 1 - i; j++) {if (arr[j] > arr[j + 1]) {int temp = arr[j];arr[j] = arr[j + 1];arr[j + 1] = temp;}}}}public static void main(String[] args) {int[] arr = { 9, 8, 5, 4, 2, 0 };bubbleSort(arr);System.out.println(Arrays.toString(arr));}
}
- 快速排序
快速排序(Quick Sort)是一种分治策略(Divide and Conquer)的排序算法。它通过选取一个基准元素(pivot),将数组分为两个子数组,其中一个子数组的元素都小于基准元素,另一个子数组的元素都大于基准元素。然后对这两个子数组分别进行递归排序。当整个数组所有元素有序时,排序完成。
package com.zhx;import java.util.Arrays;public class QuickSort {public static void quickSort(int[] arr, int low, int high) {if (low < high) {// 1. 定义基准pivot,int pivot = arr[low];// ...... pivot移动到中间,左边都比pivot小,后边都比pivot大, indexint i = low;int j = high;while (i < j) {while (i < j && arr[j] >= pivot) {j--;}// 交换swap(arr, i, j);while (i < j && arr[i] <= pivot) {i++;}// 交换swap(arr, i, j);}// 2. 递归对左右2部分快排quickSort(arr, low, j - 1);quickSort(arr, j + 1, high);}}public static void swap(int arr[], int i, int j) {int temp = arr[i];arr[i] = arr[j];arr[j] = temp;}public static void main(String[] args) {int[] arr = { 5, 3, 7, 6, 4, 1, 0, 2, 9, 10, 8 };quickSort(arr, 0, arr.length - 1);System.out.println(Arrays.toString(arr));}
}
- 插入排序
插入排序(Insertion Sort)是一种简单直观的排序算法。它的工作原理是将待排序的元素一个一个地插入到已经排序好的序列中的适当位置。插入排序在实现上,通常采用 in-place 排序(即只需用到 O(1) 的额外空间的排序),因而在从后向前排序的过程中,需要反复把已排序元素逐步向后挪位,为最新元素提供插入空间。
package com.zhx;import java.util.Arrays;public class SortTest {public static void InsertSort(int[] arr) {for (int i = 1; i < arr.length; i++) {for (int j = i; j > 0; j--) {if (arr[j] < arr[j - 1]) {int temp = arr[j];arr[j] = arr[j - 1];arr[j - 1] = temp;} else {break;}}}}public static void main(String[] args) {int[] arr = { 7, 6, 9, 3, 1, 5, 2, 4 };InsertSort(arr);System.out.println(Arrays.toString(arr));}
}
- 希尔排序
希尔排序(Shell Sort)是一种插入排序的算法,它的主要思想是使数组中任意间隔为 h 的元素都是有序的。这样的数组被称为 h 有序数组。希尔排序会不断减小 h 的值,直到最后 h=1 时,所有元素就都是有序的了。
package com.zhx;import java.util.Arrays;
public class SortTest {public static void shellSort(int[] arr) {// 增量gap, 并逐步的缩小增量for (int gap = arr.length / 2; gap > 0; gap /= 2) {// 从第gap个元素,逐个对其所在的组进行直接插入排序for (int i = gap; i < arr.length; i++) {for (int j = i; j >= gap; j -= gap) {if (arr[j] < arr[j - gap]) {int temp = arr[j];arr[j] = arr[j - gap];arr[j - gap] = temp;} else {break;}}}}}public static void main(String[] args) {int[] arr = { 8, 9, 1, 7, 2, 3, 5, 4, 6, 0 };shellSort(arr);System.out.println(Arrays.toString(arr));}
}
- 选择排序
选择排序(Selection Sort)是一种简单直观的排序算法。它的工作原理是每次从待排序的数据元素中选出最小(或最大)的一个元素,将其与待排序的数据序列的最前面(或最后面)的元素进行交换,然后缩小待排序数据序列的范围,直到全部待排序的数据元素都排好序为止。
package com.zhx;import java.util.Arrays;
public class SortTest {//选择排序public static void selectionSort(int[] arr) {int len = arr.length;int minIndex, temp;for (int i = 0; i < len - 1; i++) { //最后一个数不用排序minIndex = i;for (int j = i + 1; j < len; j++) {if (arr[j] < arr[minIndex]) { // 寻找最小的数minIndex = j; // 将最小数的索引保存}}temp = arr[i];arr[i] = arr[minIndex];arr[minIndex] = temp;}}public static void main(String[] args) {int[] arr = { 29, 38, 65, 87, 78, 23, 27, 29 };selectionSort(arr);System.out.println(Arrays.toString(arr));}
}
- 堆排序
堆排序(Heap Sort)是一种基于二叉堆(Binary Heap)的选择排序算法。它的基本思想是:将待排序的序列构造成一个大顶堆(或小顶堆),此时整个序列的最大值(或最小值)就是堆顶的根节点。然后将其与末尾元素进行交换,得到当前最大(或最小)值。接着调整剩余元素,使其满足堆的性质,然后继续重复这个过程,直到所有元素排好序。
大顶堆(Big Heap)和小顶堆(Little Heap)是两种不同的堆结构,它们在计算机科学中有着广泛的应用。
大顶堆:在大顶堆中,每个节点都大于或等于其子节点。换句话说,大顶堆满足以下条件:
对于任意的节点 i,有 arr[i] >= arr[2 * i] 和 arr[i] >= arr[2 * i + 1]。
小顶堆:在小顶堆中,每个节点都小于或等于其子节点。换句话说,小顶堆满足以下条件:
对于任意的节点 i,有 arr[i] <= arr[2 * i] 和 arr[i] <= arr[2 * i + 1]。
大顶堆和小顶堆的主要区别在于节点之间的顺序关系。大顶堆的特点是父节点大于子节点,而小顶堆的特点是父节点小于子节点。
在 Java 编程中,我们可以使用数组来表示堆结构。对于大顶堆,我们可以使用以下方法维护堆性质:
- 构造大顶堆:从数组的最后一个元素开始,逐个将元素向上调整,使其满足大顶堆的性质。
- 调整大顶堆:对于任意的节点 i,将节点 i 与其子节点进行比较,如果节点 i 的值小于其子节点的值,则交换它们的位置。然后继续调整子节点,使其满足大顶堆的性质。
类似地,对于小顶堆,我们可以使用以下方法维护堆性质: - 构造小顶堆:从数组的最后一个元素开始,逐个将元素向上调整,使其满足小顶堆的性质。
- 调整小顶堆:对于任意的节点 i,将节点 i 与其子节点进行比较,如果节点 i 的值大于其子节点的值,则交换它们的位置。然后继续调整子节点,使其满足小顶堆的性质。
大顶堆和小顶堆在排序算法、数据结构以及实际应用中都有广泛的应用。例如,在 Java 中的优先队列(PriorityQueue)就是基于大顶堆实现的。
package com.zhx;import java.util.Arrays;public class HeapSort {public static void main(String[] args) {int[] arr = { 27, 46, 12, 33, 49, 27, 36, 40, 42, 50, 51 };heapSort(arr);System.out.println(Arrays.toString(arr));}public static void heapSort(int[] arr) {// 建最大堆(arr数组本身就可以看做是一个二叉堆,下面需要将arr变成一个最大堆)/** 1、第一个非叶子节点的下标为:arr.length/2-1* 2、从第一个非叶子节点开始,遍历每一个非叶子节点,使它们都成为最大堆*/for (int i = arr.length / 2 - 1; i >= 0; i--) {heapify(arr, i, arr.length - 1);}for (int i = arr.length - 1; i > 0; i--) {//将arr数组的第一个元素(因为此元素是最大堆顶点)与数组最后一个元素交换(因为是升序)swap(arr, 0, i);//交换之后arr不是最大堆了(i已经排好序了,不用考虑)heapify(arr, 0, i - 1);}}//将i节点变成一个最大堆public static void heapify(int[] arr, int i, int last_index) {int max = i;if (2 * i + 1 <= last_index && arr[2 * i + 1] > arr[max]) {max = 2 * i + 1;// max记为左节点}if (2 * i + 2 <= last_index && arr[2 * i + 2] > arr[max]) {max = 2 * i + 2;// max记为右节点}if (max != i) {// 将i节点与它的最大子节点进行交换swap(arr, max, i);// 递归对调用的子节点进行heapifyheapify(arr, max, last_index);}}public static void swap(int[] arr, int i, int j) {int temp = arr[i];arr[i] = arr[j];arr[j] = temp;}
}
- 归并排序
归并排序(Merge Sort)是一种分治算法,它的基本思想是将一个数组(或列表)分成两半,将两半分别排序,然后将排序后的两半合并起来。
package com.zhx;import java.util.Arrays;public class MergeSort {public static void mergeSort(int arr[], int[] temp, int low, int high) {if (low < high) {// 分2部分int mid = (low + high) / 2;// 1. 对左边进行归并排序mergeSort(arr, temp, low, mid);// 2. 对右边进行归并排序mergeSort(arr, temp, mid + 1, high);// 3. 合并左右两个有序集合merge(arr, temp, low, mid, high);}}public static void merge(int[] arr, int[] temp, int low, int mid, int high) {int i = low; //设置左指针初始位置int j = mid + 1; //设置右指针初始位置int k = 0; //临时数组指针while (i <= mid && j <= high) {if (arr[i] <= arr[j]) {temp[k++] = arr[i++];} else {temp[k++] = arr[j++];}}// 左边有剩余,将左边剩余的填入tempwhile (i <= mid) {temp[k++] = arr[i++];}// 右边有剩余,将右边剩余的填入tempwhile (j <= high) {temp[k++] = arr[j++];}// 将临时数组,从头开始拷贝到arr中k = 0;while (low <= high) {arr[low++] = temp[k++];}}public static void main(String[] args) {int[] arr = { 8, 4, 5, 7, 1, 3, 6, 2 };// 辅助数组int[] temp = new int[arr.length];mergeSort(arr, temp, 0, arr.length - 1);System.out.println(Arrays.toString(arr));}
}
- 计数排序
计数排序(Counting Sort)是一种线性时间复杂度的排序算法,适用于处理整数类型的数据。它的工作原理是根据输入数据的值建立一个计数器数组,然后根据计数器数组的值将原始数据重新排列。
package com.zhx;import java.util.Arrays;
public class CountSort {public static void countSort(int[] arr) {// 找到最大值int max = arr[0];for (int i = 0; i < arr.length; i++) {if (arr[i] > max) {max = arr[i];}}// 找到最小值int min = arr[0];for (int i = 0; i < arr.length; i++) {if (arr[i] < min) {min = arr[i];}}// 创建计数数组int[] count = new int[max - min + 1];for (int i = 0; i < arr.length; i++) {count[arr[i] - min]++;}int k = 0;// 往数组中输出for (int i = 0; i < count.length; i++) {while (count[i] > 0) {arr[k++] = i + min;count[i]--;}}}public static void main(String[] args) {int[] arr = { 108, 109, 106, 101, 107, 102, 103, 102, 104, 106, 101, 110 };countSort(arr);System.out.println(Arrays.toString(arr));}
}
- 桶排序
桶排序(Bucket Sort)是一种线性时间复杂度的排序算法,适用于处理整数类型的数据。它的工作原理是将原始数据分成若干个桶,然后对每个桶内的数据进行排序,最后将所有桶内的数据依次取出,得到排序后的序列。
package com.zhx;
import java.util.Arrays;
import java.util.ArrayList;
import java.util.Collections;public class BucketSort {public static void bucketSort(int[] arr) {// 找到数组的最大值int max = arr[0];for (int i = 0; i < arr.length; i++) {if (arr[i] > max) {max = arr[i];}}// 找到数组的最小值int min = arr[0];for (int i = 0; i < arr.length; i++) {if (arr[i] < min) {min = arr[i];}}// 创建桶的容器ArrayList<ArrayList<Integer>> list = new ArrayList<>();// 确定桶的数量int count = (max - min) / arr.length + 1;for (int i = 0; i < count; i++) {list.add(new ArrayList<Integer>());}// 往桶里放for (int i = 0; i < arr.length; i++) {list.get((arr[i] - min) / arr.length).add(arr[i]);}// 给每个桶排序for (int i = 0; i < list.size(); i++) {Collections.sort(list.get(i));}// 把桶里的内容输出int k = 0;for (int i = 0; i < list.size(); i++) {ArrayList<Integer> bucket = list.get(i);for (int j = 0; j < bucket.size(); j++) {arr[k++] = bucket.get(j);}}}public static void main(String[] args) {int[] arr = { 3, 44, 38, 5, 47, 15, 36, 26, 27, 2, 46, 4, 19, 50, 48 };bucketSort(arr);System.out.println(Arrays.toString(arr));}
}
- 基数排序
基数排序(Radix Sort)是一种非对比排序算法,适用于处理整数和小数。它的工作原理是根据数字的位数进行分组,然后对每组数据进行递归排序。
方法一:
package com.zhx;import java.util.Arrays;public class RadixSort {public static void main(String[] args) {int[] arr = {26,3,49,556,81,9,863,0};radixSort(arr);System.out.println(Arrays.toString(arr));}private static void radixSort(int[] arr) {//待排序列最大值int max = arr[0];int exp;//指数//计算最大值for (int anArr : arr) {if (anArr > max) {max = anArr;}}//从个位开始,对数组进行排序for (exp = 1; max / exp > 0; exp *= 10) {//存储待排元素的临时数组int[] temp = new int[arr.length];//分桶个数int[] buckets = new int[10];//将数据出现的次数存储在buckets中for (int value : arr) {//(value / exp) % 10 :value的最底位(个位)buckets[(value / exp) % 10]++;}//更改buckets[i],记录当前位置i的元素累计记数,方便对应到数组temp中的位置for (int i = 1; i < 10; i++) {buckets[i] += buckets[i - 1];}//从后向前,将数据存储到临时数组temp中for (int i = arr.length - 1; i >= 0; i--) {temp[buckets[(arr[i] / exp) % 10] - 1] = arr[i];buckets[(arr[i] / exp) % 10]--;}//将有序元素temp赋给arrSystem.arraycopy(temp, 0, arr, 0, arr.length);}}
}
方法二:
package com.zhx;/** 另一种实现方式:* 数组:[26, 3, 49, 556, 81, 9, 863, 0]* 1、创建桶(下标0~9),并以个位数为下标,从第一个元素开始,依次放入桶中。* 0[0]* 1[81]* 2[]* 3[3,863]* 4[]* 5[]* 6[26,556]* 7[]* 8[]* 9[49,9]* 遍历桶,将元素依次取出,完成第一次排序:[0, 81, 3, 863, 26, 556, 49, 9]* 2、以十位数为下标,将完成第一次排序的数组从第一个元素开始,依次放入桶中。* 0[0,3,9]* 1[]* 2[26]* 3[]* 4[49]* 5[556]* 6[863]* 7[]* 8[81]* 9[]* 遍历桶,将元素依次取出,完成第二次排序:[0, 3, 9, 26, 49, 556, 863, 81]* 3、以百位数为下标,将完成第二次排序的数组从第一个元素开始,依次放入桶中。* 0[0,3,9,26,49,81]* 1[]* 2[]* 3[]* 4[]* 5[556]* 6[]* 7[]* 8[863]* 9[]* 遍历桶,将元素依次取出,完成第三次排序:[0, 3, 9, 26, 49, 81, 556, 863]*/
import java.util.ArrayList;
import java.util.Arrays;
public class Test {private static void radixSort(int[] arr) {//查找最大值,确定排序的次数int max = arr[0];for (int anArr : arr) {if (anArr > max) {max = anArr;}}//从个位开始,对数组进行排序for (int exp=1; max/exp>0; exp*=10) {// 创建桶并初始化(桶的下标 0~9)ArrayList<ArrayList<Integer>> buckets = new ArrayList<ArrayList<Integer>>();for(int i=0;i<10;i++) {buckets.add(i,new ArrayList());}// 将数据存储在buckets中for (int value : arr) {buckets.get((value/exp)%10).add(value);}//将每一次排序的结果复制到arr数组中int k=0;for(ArrayList<Integer> list : buckets) {for(Integer num : list) {arr[k++]=num;}}//System.out.println(Arrays.toString(arr));}}public static void main(String[] args) {int[] arr = { 26, 3, 49, 556, 81, 9, 863, 0 };radixSort(arr);System.out.println(Arrays.toString(arr));}
}
相关文章:
)
经典算法(查找与排序)
查找 顺序查找 顺序查找(Linear Search)是一种在有序数组中查找目标元素的基本算法。它的时间复杂度为 O(n),适用于查找少量数据。顺序查找的基本思想是从数组的第一个元素开始,逐个与待查找的元素进行比较,直到找到…...

微软和Red Hat合体:帮助企业更方便部署容器
早在2015年,微软就已经和Red Hat达成合作共同为企业市场开发基于云端的解决方案。时隔两年双方在企业市场的多个方面开展更紧密的合作,今天两家公司再次宣布帮助企业更方便地部署容器。 双方所开展的合作包括在微软Azure上部署Red Hat OpenShift…...
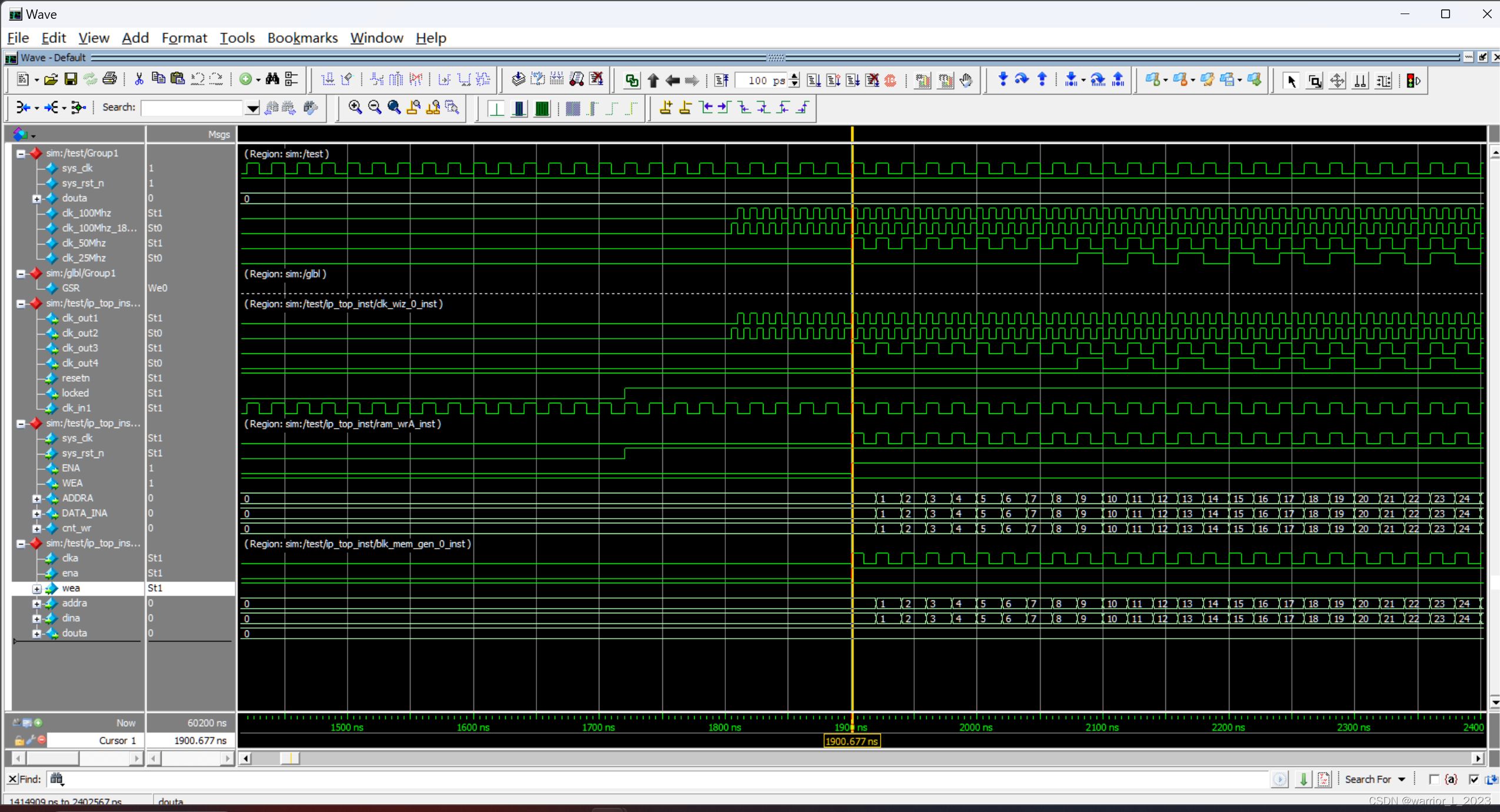
ZYNQ_project:IP_ram_pll_test
例化MMCM ip核,产生100Mhz,100Mhz并相位偏移180,50Mhz,25Mhz的时钟信号。 例化单口ram,并编写读写控制器,实现32个数据的写入与读出。 模块框图: 代码: module ip_top(input …...
Leetcode刷题详解——优美的排列
1. 题目链接:526. 优美的排列 2. 题目描述: 假设有从 1 到 n 的 n 个整数。用这些整数构造一个数组 perm(下标从 1 开始),只要满足下述条件 之一 ,该数组就是一个 优美的排列 : perm[i] 能够被…...
[PHP]Kodexplorer可道云 v4.47
KodExplorer可道云,原名芒果云,是基于Web技术的私有云和在线文件管理系统,由上海岱牧网络有限公司开发,发布于2012年6月。致力于为用户提供安全可控、可靠易用、高扩展性的私有云解决方案。 用户只需通过简单环境搭建,…...

C/C++数字判断 2021年9月电子学会青少年软件编程(C/C++)等级考试一级真题答案解析
目录 C/C数字判断 一、题目要求 1、编程实现 2、输入输出 二、算法分析 三、程序编写 四、程序说明 五、运行结果 六、考点分析 C/C数字判断 2021年9月 C/C编程等级考试一级编程题 一、题目要求 1、编程实现 输入一个字符,如何输入的字符是数字&#x…...

云栖大会丨桑文锋:打造云原生数字化客户经营引擎
近日,2023 云栖大会在杭州举办。今年云栖大会回归了 2015 的主题:「计算,为了无法计算的价值」。神策数据创始人 & CEO 桑文锋受邀出席「生态产品与伙伴赋能」技术主题,并以「打造云原生数字化客户经营引擎」为主题进行演讲。…...

如何用java写一个网站:从零搭建个性化网站
随着互联网的迅猛发展,Java作为一种强大而灵活的编程语言,为构建各类网站提供了丰富的解决方案。本文将探讨如何使用Java编写一个个性化网站,并通过具体实例进行深入分析。 第一步:选择适当的技术栈 在着手构建网站之前࿰…...
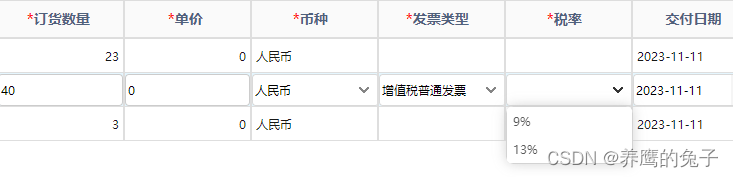
Easyui DataGrid combobox联动下拉框内容
发票信息下拉框联动,更具不同的发票类型,显示不同的税率 专票 普票 下拉框选择事件 function onSelectType(rec){//选中值if (rec2){//普通发票对应税率pmsPlanList.pmsInvoiceTaxRatepmsPlanList.pmsInvoiceTaxRateT}else {//专用发票对应税率pmsPlan…...

力扣学习笔记——11. 盛最多水的容器
链接:https://leetcode.cn/problems/container-with-most-water/ 11. 盛最多水的容器 给定一个长度为 n 的整数数组 height 。有 n 条垂线,第 i 条线的两个端点是 (i, 0) 和 (i, height[i]) 。 找出其中的两条线,使得它们与 x 轴共同构成的…...

Spring Boot: 约定优于配置的软件设计思想
文章目录 传统Spring框架的繁琐配置1. **管理jar包依赖**2. **维护web.xml**3. **维护Dispatch-Servlet.xml配置项**4. **应用部署到Web容器**5. **第三方组件集成到Spring IOC容器中的配置项维护** Spring Boot的简化与自动化1. Spring Boot Starter启动依赖2. 自动装配机制3.…...
TCP触发海康扫码相机S52CN-IC-JQR-NNN25
PC环境设置 为保证客户端正常运行以及数据传输的稳定性,在使用客户端软件前,需要对 PC 环境 进行设置 关闭防火墙 操作步骤如下: 1. 打开系统防火墙。 2. 在自定义设置界面中,选择关闭防火墙的对应选项,并单击…...
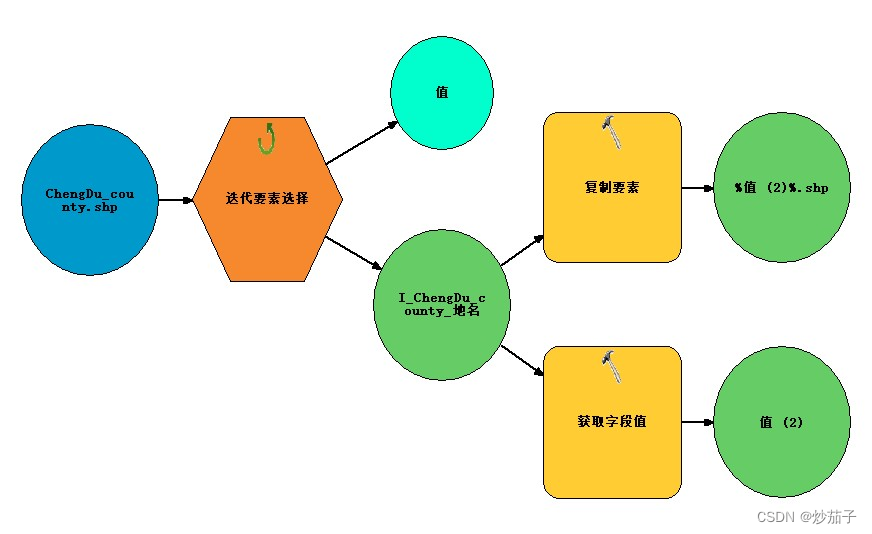
ArcGIS:如何迭代Shp文件所有要素并分别导出为Shp文件?
01 前言 尝试用IDL实现,奈何又涉及新的类IDLffShape,觉得实在没有必要学习的必要,毕竟不是搞开发,只是做做数据处理,没必要拿IDL不擅长的且底层的东西自己造轮子。 这里想到使用Python去解决,gdal太久没用…...

[工业自动化-11]:西门子S7-15xxx编程 - PLC从站 - 分布式IO从站/从机
目录 一、什么是以分布式IO从站/从机 二、分布式IO从站的意义 三、ET200分布式从站系列 一、什么是以分布式IO从站/从机 在工业自动化领域中,分布式 IO 系统是目前应用最为广泛的一种 I/O 系统,其中分布式 IO 从站是一个重要的组成部分。 分布式 IO …...
Linux技能篇-yum源搭建(本地源和公网源)
文章目录 前言一、yum源是什么?二、使用镜像搭建本地yum源1.搭建临时仓库第一步:挂载系统ios镜像到虚拟机第二步:在操作系统中挂载镜像第三步:修改yum源配置文件 2.搭建本地仓库第一步:搭建临时yum源来安装httpd并做文…...
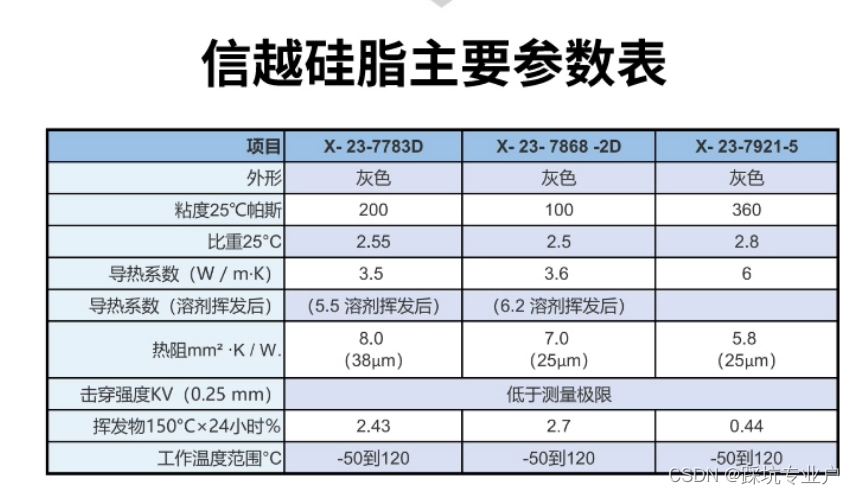
电脑清灰涂硅脂后电脑CPU温度不降反升
目录 一.问题描述二.问题解决三.拆机注意事项四.影响散热的主要因素说明1.通风差2.硅脂材料差3.硅脂涂抹方式错误 一.问题描述 电脑型号:暗影精灵5 测温工具:硬件狗狗(只要是测温软件都可以,比如omen hub和Core Temp…࿰…...
吴恩达《机器学习》8-1->8-2:非线性假设、神经元和大脑
一、非线性假设 在之前学到的线性回归和逻辑回归中,存在一个缺点,即当特征数量很多时,计算的负荷会变得非常大。考虑一个例子,假设我们使用 𝑥₁, 𝑥₂ 的多项式进行预测,这时我们可以很好地应…...

services.Jenkins Additional property tags is not allowed
今天需要给Jenkins server添加几个tag,于是就在docker的compose文件中添加了如下的tags, version: "3.9" services:jenkins:image: testbuild: context: services/jenkinsargs:- jenkins_version2.346.2- plugin_cli_version2.9.3volumes:- j…...

vColorPicker——基于 Vue 的颜色选择器插件
文章目录 前言样例特点 一、使用步骤?1. 安装2.引入3.在项目中使用 vcolorpicker 二、选项三、事件 前言 vColorPicker——官网 vColorPicker——GitHub 样例 vColorPicker是基于 Vue 的一款颜色选择器插件,仿照Angular的color-picker插件制作 特点 …...
Direct3D粒子系统
粒子和点精灵 粒子(是种微小的物体,在数学上通常用点来表示其模型。所以显示粒子时,使用点图元(由 D3 DPRIMITIVETYPE类型的D3 DPT POINTLIST枚举常量表示)是一个很好的选择。但是光栅化时,点图元将被映射为一个单个像素。这样就无法为我们提供很大的灵活性,因为实际应用…...

2026年外墙保温防火一站式服务,哪家专业?带你一探究竟!
在建筑行业蓬勃发展的当下,外墙保温防火工程愈发重要。优质的外墙保温防火服务,不仅能提升建筑的节能性和安全性,还能延长建筑使用寿命。然而,市场上相关服务提供商众多,质量良莠不齐,让客户在选择时犯了难…...

Intv_AI_MK11 Visio图表智能生成:根据文本描述自动创建系统架构图
Intv_AI_MK11 Visio图表智能生成:根据文本描述自动创建系统架构图 1. 效果惊艳开场 想象一下,你正在会议室里讨论系统架构设计。突然有人问:"能不能把刚才说的架构画出来?"传统方式可能需要花半小时在Visio上手动绘制…...

Scroll Reverser:彻底解决Mac多设备滚动冲突的终极方案
Scroll Reverser:彻底解决Mac多设备滚动冲突的终极方案 【免费下载链接】Scroll-Reverser Per-device scrolling prefs on macOS. 项目地址: https://gitcode.com/gh_mirrors/sc/Scroll-Reverser 你是否曾经在MacBook上使用触控板时习惯自然滚动(…...

AI知识库集问答
框架图架构图(模块视角)当前真实生效路径(精简图)“知识库”模块,当前实现可以概括为:文档管理 上下文拼接式问答(非RAG检索库),主问答链路是 单智能体调用 DeepSeek。先…...

OBS多平台直播插件:如何一次性解决多平台直播的三大痛点
OBS多平台直播插件:如何一次性解决多平台直播的三大痛点 【免费下载链接】obs-multi-rtmp OBS複数サイト同時配信プラグイン 项目地址: https://gitcode.com/gh_mirrors/ob/obs-multi-rtmp 你是否曾经为了在不同直播平台同步直播而手忙脚乱?你是否…...
Windows任务栏透明美化终极指南:TranslucentTB完整配置教程
Windows任务栏透明美化终极指南:TranslucentTB完整配置教程 【免费下载链接】TranslucentTB A lightweight utility that makes the Windows taskbar translucent/transparent. 项目地址: https://gitcode.com/gh_mirrors/tr/TranslucentTB TranslucentTB是一…...

大模型---模型的后训练
目录 1.继续训练 2.SFT 3.对齐训练 这篇文章会讲三种不同的后训练方式:继续训练,SFT,对齐训练,这里先总体说一下。Dont Stop Pretraining把继续训练定义为多阶段自适应预训练,并证明在目标领域语料和任务相关无标注语料上继续预训练,通常能提升下游表现;SFT在对齐训练…...

Go语言的runtime.SetBlockProfile集成
Go语言作为一门高效、简洁的并发编程语言,其强大的运行时系统为开发者提供了丰富的性能分析工具。其中,runtime.SetBlockProfile是一个关键的功能,它能够帮助开发者捕获和分析程序中的阻塞事件,从而优化并发性能。本文将围绕这一功…...

genanki性能优化指南:如何高效处理大规模卡片生成
genanki性能优化指南:如何高效处理大规模卡片生成 【免费下载链接】genanki A Python 3 library for generating Anki decks 项目地址: https://gitcode.com/gh_mirrors/ge/genanki genanki是一款强大的Python 3库,专为生成Anki卡片而设计。当处理…...

GLDAS数据变量单位速查与避坑指南:别再搞混土壤湿度和蒸散发单位了!
GLDAS数据变量单位解析与科研避坑实战指南 科研工作中最令人沮丧的瞬间之一,莫过于花费数周时间分析数据后,发现因为单位换算错误导致所有结论需要推倒重来。GLDAS数据集作为全球陆地水文研究的重要数据源,其NOAH、VIC等模型输出的土壤湿度、…...