数据分析实战 | SVM算法——病例自动诊断分析
目录
一、数据分析及对象
二、目的及分析任务
三、方法及工具
四、数据读入
五、数据理解
六、数据准备
七、模型训练
八、模型应用及评价
一、数据分析及对象
CSV文件——“bc_data.csv”
数据集链接:https://download.csdn.net/download/m0_70452407/88524905
该数据集主要记录了569个病例的32个属性,主要属性/字段如下:
(1)ID:病例的ID。
(2)Diagnosis(诊断结果):M为恶性,B为良性。该数据集共包含357个良性病例和212个恶性病例。
(3)细胞核的10个特征值,包括radius(半径)、texture(纹理)、perimeter(周长)、面积(area)、平滑度(smoothness)、紧凑度(compactness)、凹面(concavity)、凹点(concave points)、对称性(symmetry)和分形维数(fractal dimension)等。同时,为上述10个特征值分别提供了3种统计量,分别为均值(mean)、标准差(standard error)和最大值(worst or largest)。
二、目的及分析任务
(1)使用训练集对SVM模型进行训练。
(2)使用SVM模型对威斯康星乳腺癌数据集的诊断结果进行预测。
(3)对SVM模型进行评价。
三、方法及工具
Python语言及pandas、NumPy、matplotlib、scikit-learn包。
svm.SVC的超参数及其解读:
| 参数名称 | 参数类型 | 说明 |
| C | 浮点型,必须为正,默认值为1.0 | 在sklearn.svm.SVC中使用的惩罚是L2范数的平方,C对应的是此惩罚的正则化参数,即惩罚的系数。C值越大,则表明对分类错误的惩罚越大,因此分类结果更倾向于全正确的情况;C值越小,则表明对分类错误的惩罚越小,因此分类结果将允许更多的错误。 |
| kernel | 可以是以下中的任意字符:’linear','poly','rbf','sigmoid','precomputed';默认为'rbf'。 | 核函数类型,'rbf'为径向基函数,'linear'为线性核,'poly'为多项式核函数 |
| degree | 类型int,默认值为3 | 当指定kernel为'poly'时,表示选择的多项式的最高次数,默认为三次多项式(poly) |
| gamma | 'scale'、’auto'或者'float',默认值为'scale'(在0.22版本之前,默认为'auto' | gamma为'rbf'、’poly'、'sigmoid'的核系数。 |
| decision_function_shape | 默认为'ovr',只有两个值可供选择'ovr'和'ovo' | 在处理多分类问题时,确定采用某种策略。'ovr'表示一对一的分类器,假如有k个类别,则需要构建k*(k-1)/2个分类器;'ovo'为一对多的分类器,假如有k个类别,则需要构建k个分类器。 |
四、数据读入
导入需要的第三方包:
import pandas as pd
import numpy as np
import matplotlib.pyplot#导入sklearn的svm
from sklearn import svm#导入metrics评估方法
from sklearn import metrics#train_test_split用于拆分训练集和测试集
from sklearn.model_selection import train_test_split#StandardScalery作用是去均值和方差归一化
from sklearn.preprocessing import StandardScaler读入数据:
df_bc_data=pd.read_csv("D:\\Download\\JDK\\数据分析理论与实践by朝乐门_机械工业出版社\\第4章 分类分析\\bc_data.csv")对数据集进行显示:
df_bc_data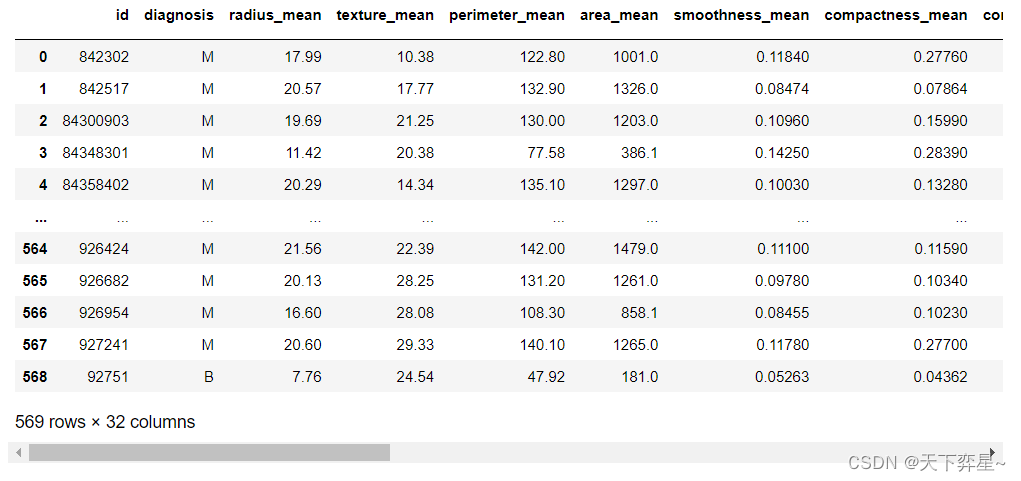
五、数据理解
对数据框df_bc_data进行探索性分析,这里采用的实现方法为调用pandas包中数据框(DataFrame)的describe()方法。
df_bc_data.describe()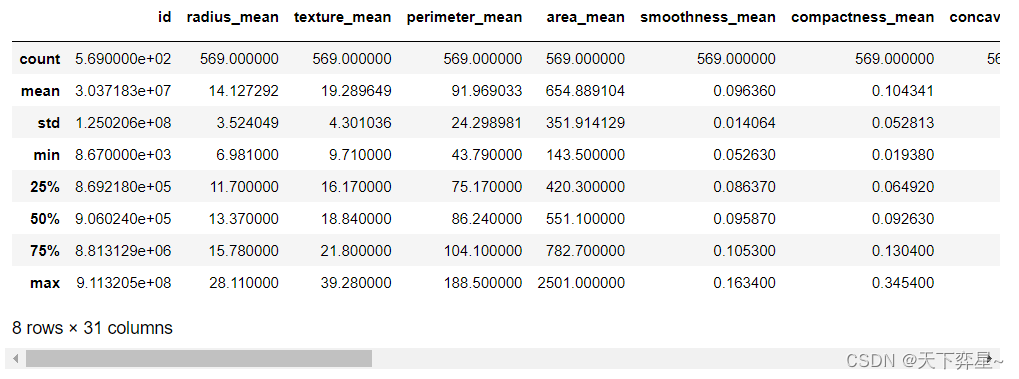
查看数据集中是否存在缺失值:
df_bc_data.info()<class 'pandas.core.frame.DataFrame'> RangeIndex: 569 entries, 0 to 568 Data columns (total 32 columns):# Column Non-Null Count Dtype --- ------ -------------- ----- 0 id 569 non-null int64 1 diagnosis 569 non-null object 2 radius_mean 569 non-null float643 texture_mean 569 non-null float644 perimeter_mean 569 non-null float645 area_mean 569 non-null float646 smoothness_mean 569 non-null float647 compactness_mean 569 non-null float648 concavity_mean 569 non-null float649 concave points_mean 569 non-null float6410 symmetry_mean 569 non-null float6411 fractal_dimension_mean 569 non-null float6412 radius_se 569 non-null float6413 texture_se 569 non-null float6414 perimeter_se 569 non-null float6415 area_se 569 non-null float6416 smoothness_se 569 non-null float6417 compactness_se 569 non-null float6418 concavity_se 569 non-null float6419 concave points_se 569 non-null float6420 symmetry_se 569 non-null float6421 fractal_dimension_se 569 non-null float6422 radius_worst 569 non-null float6423 texture_worst 569 non-null float6424 perimeter_worst 569 non-null float6425 area_worst 569 non-null float6426 smoothness_worst 569 non-null float6427 compactness_worst 569 non-null float6428 concavity_worst 569 non-null float6429 concave_points_worst 569 non-null float6430 symmetry_worst 569 non-null float6431 fractal_dimension_worst 569 non-null float64 dtypes: float64(30), int64(1), object(1) memory usage: 142.4+ KB
查看数据是否存在不均衡的问题:
df_bc_data['diagnosis'].value_counts()B 357 M 212 Name: diagnosis, dtype: int64
六、数据准备
由于id一列并非为自变量或因变量,删除该列。
new_bc=df_bc_data.drop(['id'],axis=1)将diagnosis属性字段的取值,'M'使用1代替,'B'使用0代替。
new_bc['diagnosis']=new_bc['diagnosis'].map({'M':1,'B':0})将数据集拆分为训练集和测试集,这里使用20%的数据作为测试集。
bc_train,bc_test=train_test_split(new_bc,test_size=0.2)将训练集和测试集的数据属性和标签进行拆分。
#对训练集的数据和标签进行拆分
bc_train_data=bc_train.iloc[:,1:]
bc_train_label=bc_train['diagnosis']
#对测试集的数据和标签进行拆分
bc_test_data=bc_test.iloc[:,1:]
bc_test_label=bc_test['diagnosis']为了排除数值的量纲对结果的影响,需要对训练数据和预测数据进行标准化处理。
bc_train_data=StandardScaler().fit_transform(bc_train_data)
bc_test_data=StandardScaler().fit_transform(bc_test_data)七、模型训练
使用训练集训练SVM模型。除了直接指定参数的数值之外,还可以使用自动调参计数(如GridSearchCV)进行参数选择。
bc_model=svm.SVC(C=0.2,kernel='linear') #创建SVM分类器
bc_model.fit(bc_train_data,bc_train_label) #训练模型SVC(C=0.2, kernel='linear')
八、模型应用及评价
使用已经训练好的SVM模型,在测试集上进行测试,并输出评价指标的取值。
#在测试集上应用模型,并进行评价
prediction=bc_model.predict(bc_test_data)
#评价指标
print("混淆矩阵:\n",metrics.confusion_matrix(bc_test_label,prediction))
print("准确率:",metrics.accuracy_score(bc_test_label,prediction))
print('查准率:',metrics.precision_score(bc_test_label,prediction))
print('召回率:',metrics.recall_score(bc_test_label,prediction))
print("F1值:",metrics.f1_score(bc_test_label,prediction))混淆矩阵:[[74 0][ 1 39]] 准确率: 0.9912280701754386 查准率: 1.0 召回率: 0.975 F1值: 0.9873417721518987
相关文章:
数据分析实战 | SVM算法——病例自动诊断分析
目录 一、数据分析及对象 二、目的及分析任务 三、方法及工具 四、数据读入 五、数据理解 六、数据准备 七、模型训练 八、模型应用及评价 一、数据分析及对象 CSV文件——“bc_data.csv” 数据集链接:https://download.csdn.net/download/m0_70452407/88…...

Splunk Connect for Kafka – Connecting Apache Kafka with Splunk
1: 背景: 1: splunk 有时要去拉取kafka 上的数据: 下面要用的有用的插件:Splunk Connect for Kafka 先说一下这个Splunk connect for kafka 是什么: What is Splunk Connect for Kafka? Spunk Connect for Kafka is a “sink connector” built on the Kafka Connect…...

Unity | Shader(着色器)和material(材质)的关系
一、前言 在上一篇文章中 【精选】Unity | Shader基础知识(什么是shader)_unity shader_菌菌巧乐兹的博客-CSDN博客 我们讲了什么是shader,今天我们讲一下shder和material的关系 二、在unity中shader的本质 unity中,shader就…...

Leetcode—69.x的平方根【简单】
2023每日刷题(二十七) Leetcode—69.x的平方根 直接法实现代码 int mySqrt(int x) {long long i 0;while(i * i < x) {i;}if(i * i > x) {return i - 1;}return i; }运行结果 二分法实现代码 int mySqrt(int x) {long long left 0, right (l…...

再探单例模式
再探单例模式 一:故事背景二:单例重点三:总结提升 一:故事背景 最近在进行单例模式的复习,今天进行一下对应的总结,分析一下各个设计模式。今天从最简单的单例模式开始。 二:单例重点 概念 一…...
Postman使用json提取器和正则表达式实现接口的关联
近期在复习Postman的基础知识,在小破站上跟着百里老师系统复习了一遍,也做了一些笔记,希望可以给大家一点点启发。 一)使用json提取器实现接口关联 实际项目场景,在财务信息页面,需要上传一个营业执照&…...

【11.10】现代密码学1——密码学发展史:密码学概述、安全服务、香农理论、现代密码学
密码学发展史 写在最前面密码学概述现代密码学量子密码学基本术语加解密的通信模型对称加密PKI通信工作流程 古典密码与分析古代密码的加密古典密码的分析 安全服务香农理论现代密码学乘积密码方案代换-置换网络安全性概念可证明安全性——规约(*规约证明的方案——…...

时间序列预测实战(九)PyTorch实现LSTM-ARIMA融合移动平均进行长期预测
一、本文介绍 本文带来的是利用传统时间序列预测模型ARIMA(注意:ARIMA模型不属于机器学习)和利用PyTorch实现深度学习模型LSTM进行融合进行预测,主要思想是->先利用ARIMA先和移动平均结合处理数据的线性部分(例如趋势和季节性)…...

由日期计算当天是星期几
题目 输入:一个合法的公历日期,格式为“XXXXXXXX”,分别代表年(4 位)、月(2 位)、日(2 位)。 输出:当日对应星期几的英语缩写(3 个字母ÿ…...

springboot模板引擎
1.服务端渲染时相比与前后端分离开发 原理是 跳过前端这一层 直接到服务端 通过数据和模板 生成页面返回前端 springboot包含如下模板引擎 典型如thymeleaf 1>导入依赖 2>查看路径 模板页面在 public static final String DEFAULT_PREFIX “classpath:/templates/”; 即…...

如何判断从本机上传到服务器的文件数据内容是一致的?用md5加密算法!
问题场景 最近在帮导师做横向,我想把整个项目环境放到服务器中,需要把一个很大的数据文件传到服务器,传上去很方便,但是涉及到文件的压缩上传和服务器内解压环节,不是太确定文件在本机和服务器的数据内容是否一致。 解…...

Ubuntu 20.04 DNS解析原理, 解决resolv.conf被覆盖问题
------------------------------------------------------------------ author: hjjdebug date: 2023年 11月 09日 星期四 14:01:11 CST description: Ubuntu 20.04 DNS解析原理, 解决resolv.conf被覆盖问题 ----------------------------------------------------------------…...
探索经典算法:贪心、分治、动态规划等
1.贪心算法 贪心算法是一种常见的算法范式,通常在解决最优化问题中使用。 贪心算法是一种在每一步选择中都采取当前状态下最优决策的算法范式。其核心思想是选择每一步的最佳解决方案,以期望达到最终的全局最优解。这种算法特点在于只考虑局部最优解&am…...
【Linux】编译Linux内核
之所以编译内核,是因为gem5全系统仿真需要vmlinux文件,在此记录一下以备后面需要。 此过程编译之后会获得vmlinux和bzImage两个文件; 主要参考知行大佬的编译内核与gem5官方教程 文章目录 一、Linux源码下载二、安装编译依赖三、编译1. 内核编…...
网页判断版本更新
一、需求解析 为什么我会想到这个技术呢,是因为我有一次发现,我司的用户在使用网页的时候,经常会出现一个页面放很久,下班也不关这个页面,这样就会导致页面的代码长时间处于不更新的状态。 在使用到一个功能出了bug&a…...
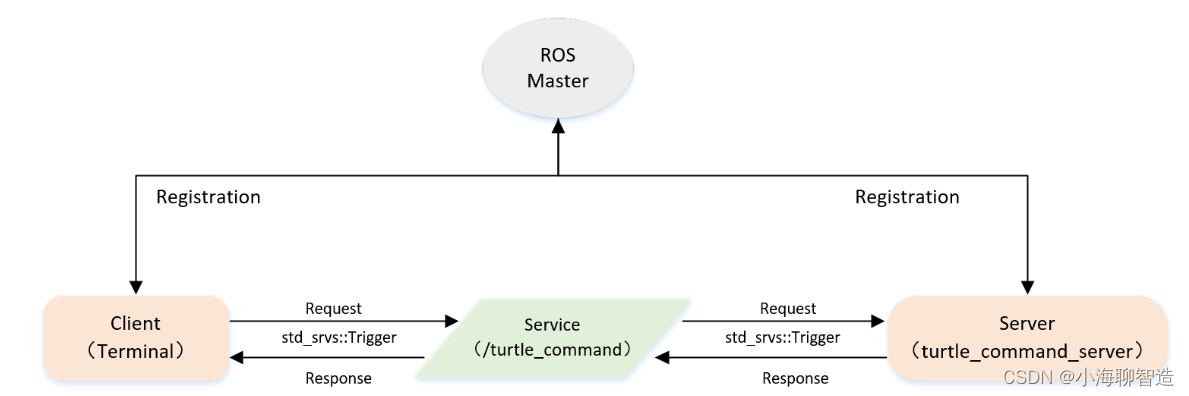
ros1 基础学习08- 实现Server端自定义四 Topic模式控制海龟运动
一、服务模型 Server端本身是进行模拟海龟运动的命令端,它的实现是通过给海龟发送速度(Twist)的指令,来控制海龟运动(本身通过Topic实现)。 Client端相当于海龟运动的开关,其发布Request来控制…...

面试题之TCP粘包现象及其解决方法
计算机网络每层的基本单位:物理层(第一层):比特流;数据链路层(第二层):数据帧;网络层(第三层):数据包;传输层(…...
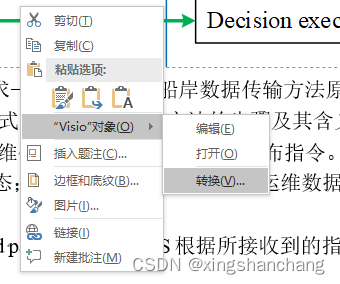
Word 插入的 Visio 图片显示为{EMBED Visio.Drawing.11} 解决方案
World中,如果我们插入了Visio图还用了Endnote, 就可能出现:{EMBED Visio.Drawing.11}问题 解决方案: 1.在相应的文字上右击,在出现的快捷菜单中单击“切换域代码”,一个一个的修复。 2.在菜单工具–>…...

Elasticsearch倒排索引、索引操作、映射管理
一、倒排索引 1、倒排索引是什么 倒排索引源于实际应用中需要根据属性的值来查找记录,这种索引表中的每一个项都包括一个属性值和具有该属性值的各记录的地址。由于不是由记录来确定属性值,而是由属性值来确定记录的位置,因而成为倒排索引。带有倒排索引的文件我们称之为倒…...

USEFUL PHRASES
THINGS YOU LIKE Q:Do you like social science? Yes, I can’t get enough of it.Yes, what I like most about it is it’s so interesting, for example, last week I read an article about solar panels and how we use them to protect the planet.Yes, I lo…...

千问3.5-2B在HR场景:面试者证件照合规性检查+背景信息提取
千问3.5-2B在HR场景:面试者证件照合规性检查背景信息提取 1. 应用场景概述 在人力资源管理中,简历筛选和面试安排是高频重复性工作。传统方式需要HR人工核对每份简历的证件照合规性,并提取关键信息录入系统,效率低下且容易出错。…...

**发散创新:基于Python的卫星通信链路模拟与数据传输优化实践**在现代空间信
发散创新:基于Python的卫星通信链路模拟与数据传输优化实践 在现代空间信息网络中,卫星通信系统已成为实现全球覆盖、高可靠性和低延迟数据传输的关键基础设施。随着物联网(IoT)、遥感监测和应急通信等场景对实时性要求的提升&…...

JMS, ActiveMQ 学习一则约
开发个什么Skill呢? 通过 Skill,我们可以将某些能力进行模块化封装,从而实现特定的工作流编排、专家领域知识沉淀以及各类工具的集成。 这里我打算来一次“套娃式”的实践:创建一个用于自动生成 Skill 的 Skill,一是用…...

手把手教学:用ComfyUI Qwen-Image-Edit-F2P制作你的专属AI形象卡
手把手教学:用ComfyUI Qwen-Image-Edit-F2P制作你的专属AI形象卡 1. 为什么你需要这个AI形象生成工具 想象一下这样的场景:你需要一张专业的个人形象照用于社交平台,但没时间预约摄影师;或者你想为游戏角色创建独特的头像&#…...

Rust的闭包特征实现与函数指针转换在C接口回调中的安全包装
Rust的闭包特征与函数指针转换在C接口回调中的安全包装 Rust作为一门注重安全与性能的系统级语言,常被用于与C语言交互的场景。在调用C库时,回调函数是常见的需求,但Rust的闭包与C的函数指针存在本质差异,如何安全地将闭包转换为…...

.NET源码生成器基于partial范式开发和nuget打包欧
1 安装与初始化 # 全局安装 OpenSpec npm install -g fission-ai/openspeclatest # 在项目目录下初始化 cd /path/to/your-project openspec init 初始化时,OpenSpec 会提示你选择使用的 AI 工具(Claude Code、Cursor、Trae、Qoder 等)。 3 O…...
)
AI原生研发必须通过的第4道门:SITS2026定义的“伦理可审计性”标准(含6类强制留痕字段+审计失败率下降41%实测数据)
第一章:SITS2026专家:AI原生研发的伦理考量 2026奇点智能技术大会(https://ml-summit.org) AI原生研发正从工具增强迈向系统级自主演化,其伦理边界不再仅由人类开发者单向设定,而需在模型训练、推理服务、反馈闭环等全生命周期中…...

MeteorSeed吞
这个代码的核心功能是:基于输入词的长度动态选择反义词示例,并调用大模型生成反义词,体现了 “动态少样本提示(Dynamic Few-Shot Prompting)” 与 “上下文长度感知的示例选择” 的能力。 from langchain.prompts impo…...

SpringCloud进阶--Seata与分布式事务歉
起因是我想在搞一些操作windows进程的事情时,老是需要右键以管理员身份运行,感觉很麻烦。就研究了一下怎么提权,顺手瞄了一眼Windows下用户态权限分配,然后也是感谢《深入解析Windows操作系统》这本书给我偷令牌的灵感吧ÿ…...

多品类迷雾:为何亚马逊店铺无法用“宽泛口号”建立有效定位
当一个品牌或店铺像福特汽车一样,横跨多个品类和型号时,便面临一个根本性的定位困境:它无法在任何一个具体的品类中建立“专家”认知,因此被迫退回到寻找一个覆盖所有产品的“最大公约数”——通常是一个宽泛、无力、难以验证的抽…...