9.spark自适应查询-AQE之动态调整Join策略
目录
- 概述
- 动态调整Join策略
- 原理
- 实战
- 动态优化倾斜的 Join
- 原理
- 实战
概述
broadcast hash join 类似于 Spark 共享变量中的广播变量,Spark join 如果能采取这种策略,那join 的性能是最好的
- 自适应查询AQE(Adaptive Query Execution)
- 动态调整Join策略
- 原理
- 实战
- 动态优化倾斜的 Join
- 原理
- 默认环境配置
- 修改配置
- 动态调整Join策略
动态调整Join策略
实际上在生产中,特别是工厂中的局限性,表设计的时候,不是那么合理,导致这这种情况,很少见,很难被调整。
原理
AQE 可以将 sort-merge join 转成 broadcast hash join ,条件是当join 表小于自适应 broadcast hash join 的阀值。
开启了自适应查询执行机制之后,可以在运行时根据最精确的数据指标重新规划join策略,实现动态调整join策略。
看以下图:
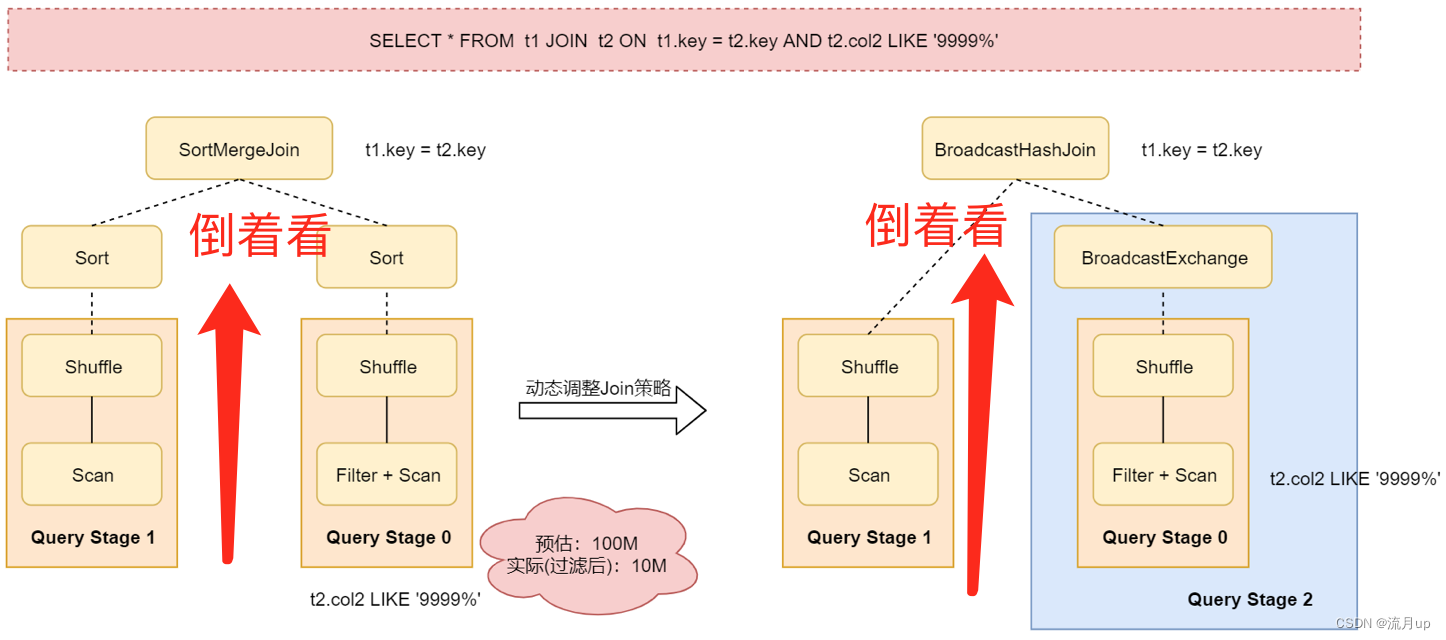
后续测试过程中,可以看 spark sql 的执行图。
| 属性名称 | 默认值 | 解释 | 版本 |
|---|---|---|---|
| spark.sql.adaptive.localShuffleReader.enabled | true | 当值为true,且spark.sql.adaptive.enabled也为true时,Spark尝试不需要shuffle分区时,使用本地的shuffle读取器读取shuffle数据,例如:在将 sort-merge 转换成 broadcast-hash join 之后 | 3.0.0 |
| spark.sql.adaptive.autoBroadcastJoinThreshold | (none) | 为表配置最大的字节数,能优化成 broadcast join,通过设置此配置为-1,可以禁用 broadcast ,默认值与 spark.sql.autoBroadcastJoinThreshold 相同 | 3.2.0 |
| spark.sql.autoBroadcastJoinThreshold | 10MB | 同上 | 1.1.0 |
当所有的 shuffle partitions 都小于阀值, AQE 将 sort-merge join 转成 shuffled hash join ;最大阀值配置:spark.sql.adaptive.maxShuffledHashJoinLocalMapThreshold
| 属性名称 | 默认值 | 解释 | 版本 |
|---|---|---|---|
| spark.sql.adaptive.maxShuffledHashJoinLocalMapThreshold | 0 | 为每个分区配置最大的字节数,能够构建 local hash map,如果这个值不小于 spark.sql.adaptive.maxShuffledHashJoinLocalMapThreshold并所有的分区不大于这个配置,join选择更倾向于使用 shuffled hash join,而不是 sort merge join | 3.2.0 |
实战
执行的 sql
select count(*) from xx where dt ='2023-06-30' and workorder='011002118525' ;
## 同样的表相连
select * from (select * from xx where dt ='2023-06-30' and workorder='011002118525') as a
left join xx as b on b.dt ='2023-06-30' and b.workorder='011002118525' and a.id = b.id ;
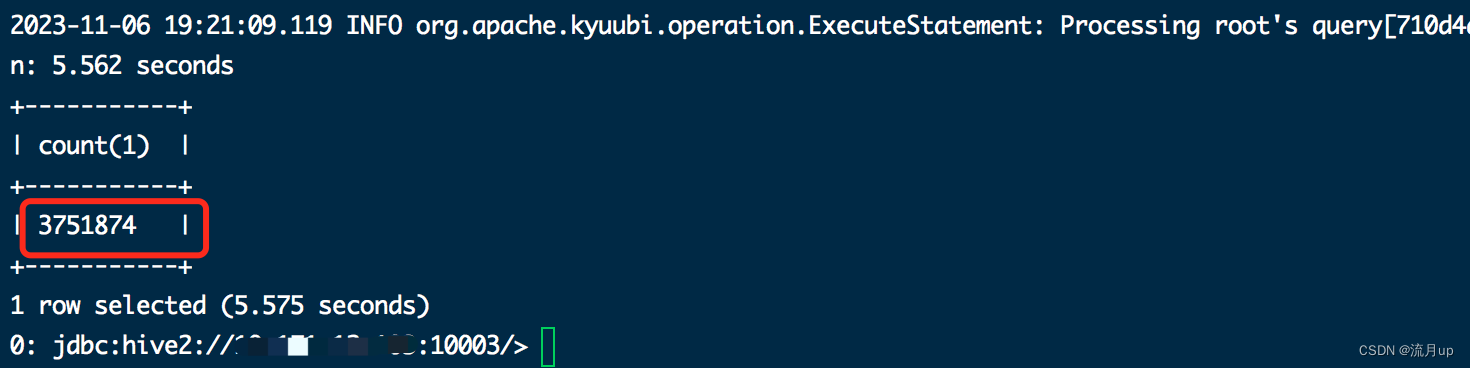
由上图,三百多万的数据,肯定超过10MB了,所以是 sort merge join
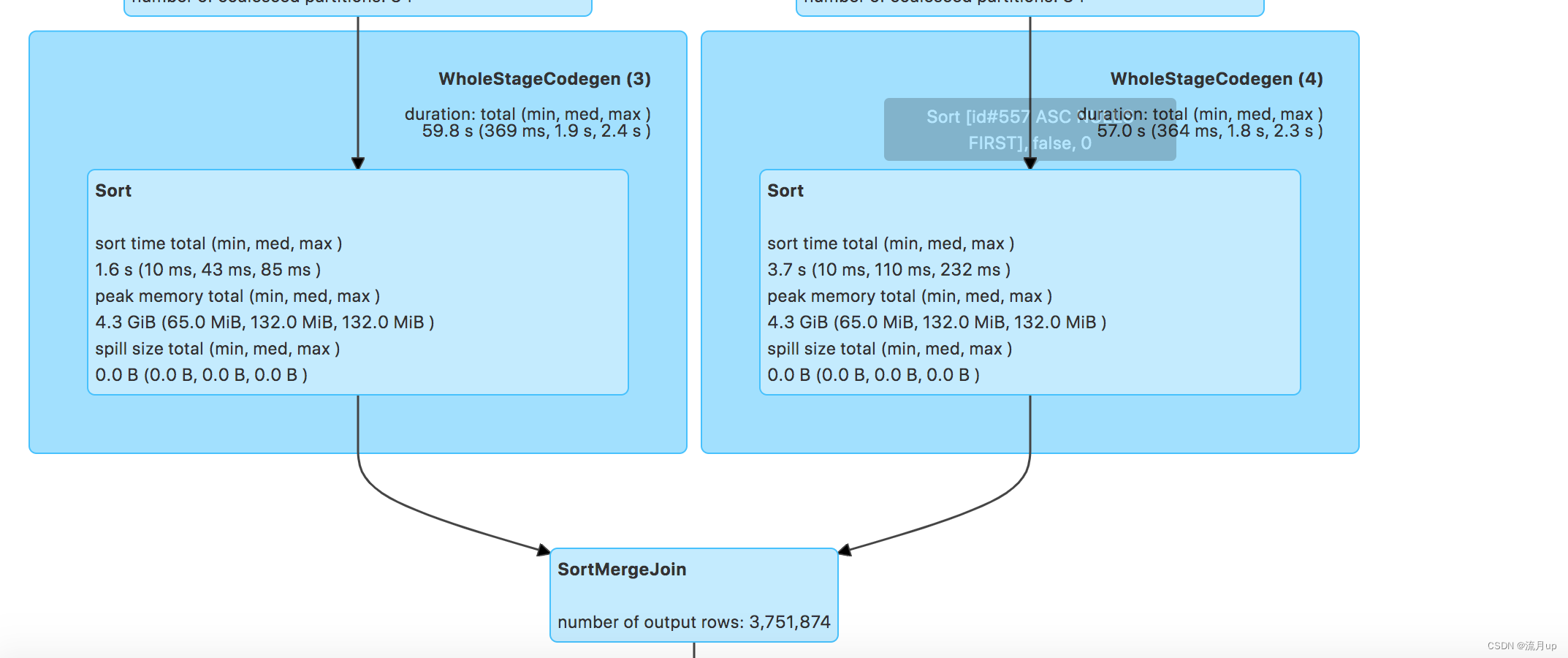
修改 sql 如下:
select * from (select id from xx where dt = '2023-06-30' and workorder='011002118525' ) as a join xx as b on a.id = b.id and b.dt = '2023-06-30' and b.unitid = 'H8TGWJ035ZY0000431';
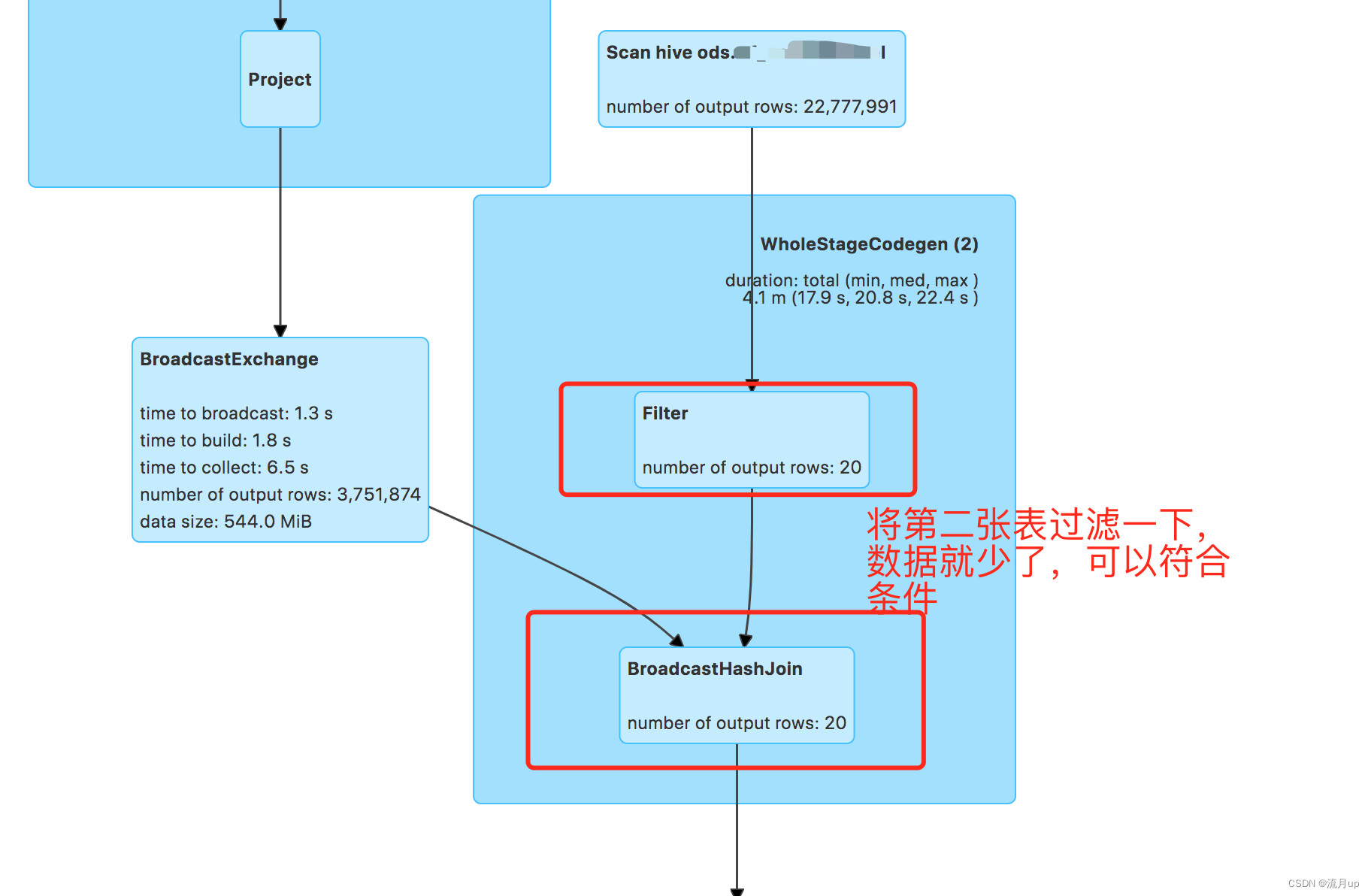
动态优化倾斜的 Join
原理
数据倾斜严重,将严重影响 join 查询的性能。该功能动态处理在 sort-merge join 倾斜数据时,将其分为大小差不多的任务。当同是启用 spark.sql.adaptive.enabled 和 spark.sql.adaptive.skewJoin.enabled 时,动态优化倾斜 这个功能将生效。
| 属性名称 | 默认值 | 解释 | 版本 |
|---|---|---|---|
| spark.sql.adaptive.skewJoin.enabled | true | 当同是启用 spark.sql.adaptive.enabled,动态优化倾斜 这个功能将生效 | 3.0.0 |
| spark.sql.adaptive.skewJoin.skewedPartitionFactor | 5 | 如果分区的大小大于此因子乘以分区大小的中值,并且也大于spark.sql.adaptive.skewJoin.strakedPartitionThresholdInBytes,则该分区被视为偏斜。 | 3.2.0 |
| spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes | 256MB | 如果分区的字节大小大于此阈值,并且也大于spark.sql.adaptive.skewJoin.strakedPartitionFactor乘以分区大小中值,则该分区被视为偏斜。理想情况下,此配置应设置为大于spark.sql.adaptive.advisoryPartitionSizeInBytes。 | 3.0.0 |
假设有两个表 t1和t2,其中表t1中的P0分区里面的数据量明显大于其他分区,默认的执行情况是这样的,看这个图:
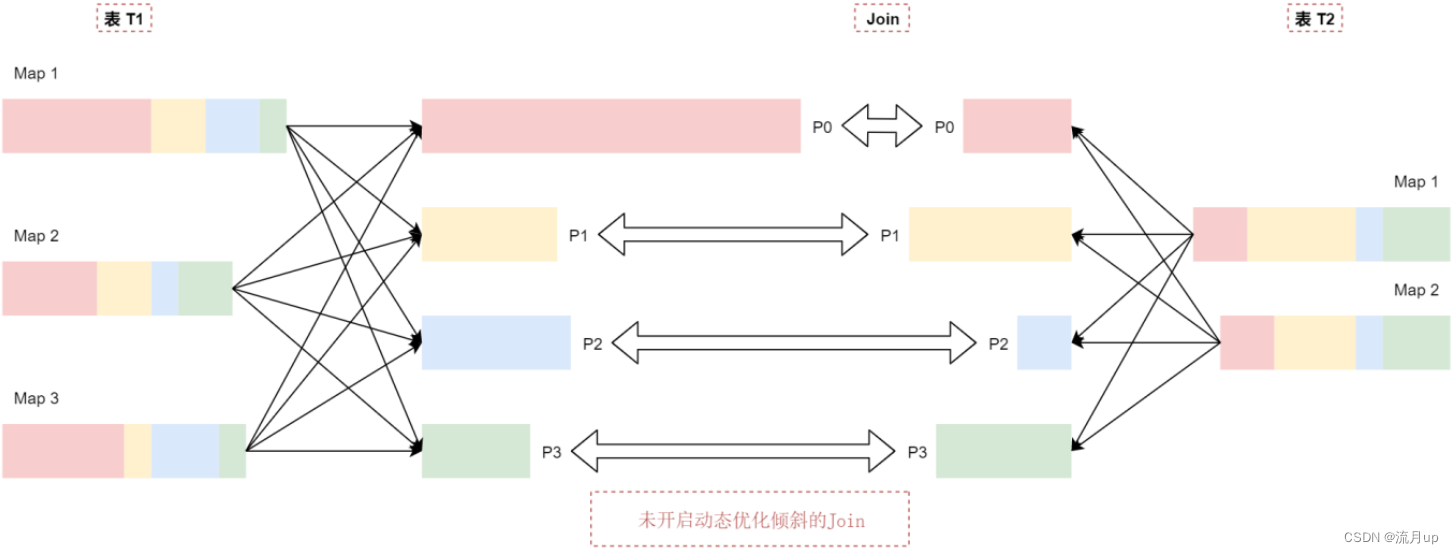
t1表中p0分区的数据比p1\p2\p3这几个分区的数据大很多,可以认为t1表中的数据出现了倾斜。
当t1和t2表中p1、p2、p3这几个分区在join的时候基本上是不会出现数据倾斜的,因为这些分区的数据相对适中。但是P0分区在进行join的时候就会出现数据倾斜了,这样会导致 join 的时间过长。
动态优化倾斜的 join 机制会把P0分区切分成两个子分区P0-1和P0-2,并将每个子分区关联到表t2的对应分区P0,看这个图:
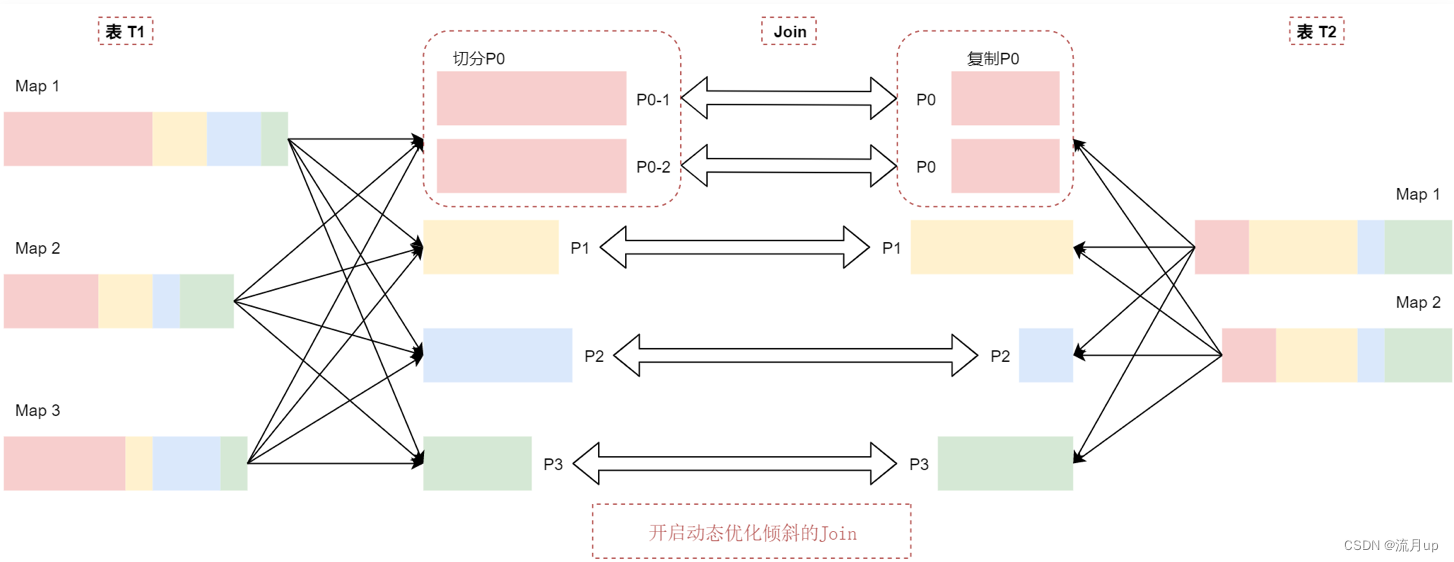
t2表中的P0分区会复制出来两份相同的数据,和t1表中切分出来的P0分区的数据进行 join 关联。
这样相当于就把t1表中倾斜的分区拆分打散了,最终在 join 的时候就不会产生数据倾斜了。
实战
todo: 以后如果遇到,再补充上
相关文章:
9.spark自适应查询-AQE之动态调整Join策略
目录 概述动态调整Join策略原理实战 动态优化倾斜的 Join原理实战 概述 broadcast hash join 类似于 Spark 共享变量中的广播变量,Spark join 如果能采取这种策略,那join 的性能是最好的 自适应查询AQE(Adaptive Query Execution) 动态调整Join策略 原…...
CentOs7 NAT模式连接网络
1.配置动态网络 1.1 检查主机网卡配置 检查主机的网络设置 进入控制面板,找到网络共享中心 查看适配器是否都已经开启 1.2 设置虚拟机的网络配置 打开虚拟机网络配置设置,对网卡VMnet8 进行设置 记住网关 全部选择应用,确定 1.3 设置…...

linux安装git
目录 声明 前言 正文 (1)下载git压缩包 (2)git压缩包解压 (3)解压完成后需要进行源码的编译操作 a.首先进去到解压后的文件目录中: b.执行: 编译的过程中可能遇到的问题&am…...
thinkphp6 起步
1、安装 composer create-project topthink/think6.0 tp62、使用多应用模式,你需要安装多应用模式扩展think-multi-app composer require topthink/think-multi-app3、config/app.php中,将 ‘auto_multi_app’ > flase, 改为true; 需要自…...

会员题-力扣408-有效单词缩写
有效单词缩写 字符串可以用 缩写 进行表示,缩写 的方法是将任意数量的 不相邻 的子字符串替换为相应子串的长度。例如,字符串 “substitution” 可以缩写为(不止这几种方法): “s10n” (“s ubstitutio n”) “sub4…...
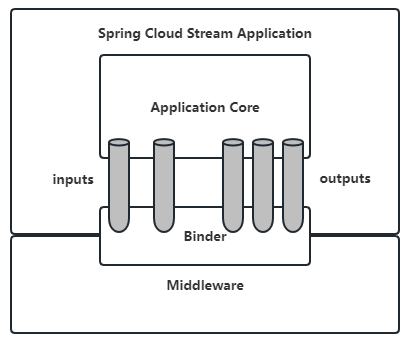
spring-cloud-stream
系列文章目录 第一章 Java线程池技术应用 第二章 CountDownLatch和Semaphone的应用 第三章 Spring Cloud 简介 第四章 Spring Cloud Netflix 之 Eureka 第五章 Spring Cloud Netflix 之 Ribbon 第六章 Spring Cloud 之 OpenFeign 第七章 Spring Cloud 之 GateWay 第八章 Sprin…...
2.0 熟悉CheatEngine修改器
Cheat Engine 一般简称为CE,它是一款功能强大的开源内存修改工具,其主要功能包括、内存扫描、十六进制编辑器、动态调试功能于一体,且该工具自身附带了脚本工具,可以用它很方便的生成自己的脚本窗体,CE工具可以帮助用户…...

微信小程序数据交互和缓存
目录 前言: 数据交互 1. 发起网络请求 2. WebSocket 2.1实时数据库 3. 微信支付 数据缓存 1. 页面级缓存 2. 内存级缓存 3. 数据缓存策略 优化用户体验 总结 前言: 在开发微信小程序时,数据交互和缓存是非常重要的方面。本文将介…...
kubernetes集群编排——k8s认证授权
pod绑定sa [rootk8s2 ~]# kubectl create sa admin [rootk8s2 secret]# vim pod5.yaml apiVersion: v1 kind: Pod metadata:name: mypod spec:serviceAccountName: admincontainers:- name: nginximage: nginxkubectl apply -f pod5.yamlkubectl get pod -o yaml 认证 [rootk8s…...
rabbitmq下载安装教程
1.首先需要下载erlang和rabbitmq安装包: 官网下载比较慢,通过网盘下载: 链接:https://pan.baidu.com/s/1fM2BrJqefyzUDZD4tfZLIg 提取码:5hsu 2.安装,傻瓜式安装就可以,可以自定义自己要安装的目…...
数据分析实战 | SVM算法——病例自动诊断分析
目录 一、数据分析及对象 二、目的及分析任务 三、方法及工具 四、数据读入 五、数据理解 六、数据准备 七、模型训练 八、模型应用及评价 一、数据分析及对象 CSV文件——“bc_data.csv” 数据集链接:https://download.csdn.net/download/m0_70452407/88…...

Splunk Connect for Kafka – Connecting Apache Kafka with Splunk
1: 背景: 1: splunk 有时要去拉取kafka 上的数据: 下面要用的有用的插件:Splunk Connect for Kafka 先说一下这个Splunk connect for kafka 是什么: What is Splunk Connect for Kafka? Spunk Connect for Kafka is a “sink connector” built on the Kafka Connect…...

Unity | Shader(着色器)和material(材质)的关系
一、前言 在上一篇文章中 【精选】Unity | Shader基础知识(什么是shader)_unity shader_菌菌巧乐兹的博客-CSDN博客 我们讲了什么是shader,今天我们讲一下shder和material的关系 二、在unity中shader的本质 unity中,shader就…...

Leetcode—69.x的平方根【简单】
2023每日刷题(二十七) Leetcode—69.x的平方根 直接法实现代码 int mySqrt(int x) {long long i 0;while(i * i < x) {i;}if(i * i > x) {return i - 1;}return i; }运行结果 二分法实现代码 int mySqrt(int x) {long long left 0, right (l…...

再探单例模式
再探单例模式 一:故事背景二:单例重点三:总结提升 一:故事背景 最近在进行单例模式的复习,今天进行一下对应的总结,分析一下各个设计模式。今天从最简单的单例模式开始。 二:单例重点 概念 一…...
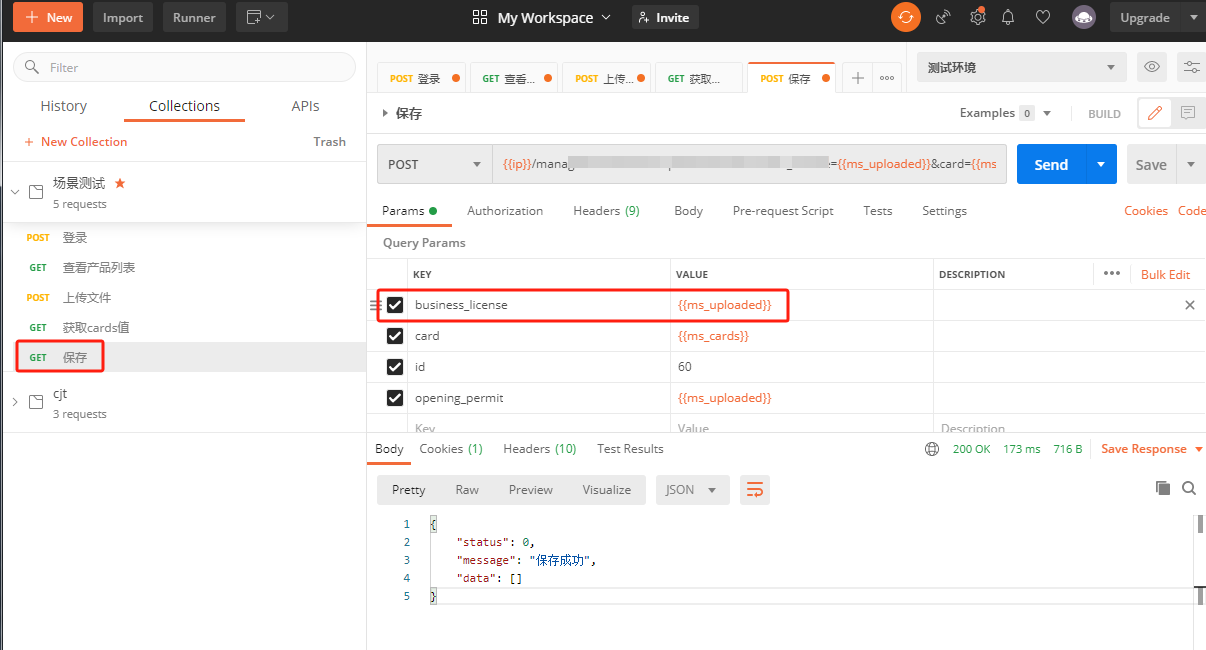
Postman使用json提取器和正则表达式实现接口的关联
近期在复习Postman的基础知识,在小破站上跟着百里老师系统复习了一遍,也做了一些笔记,希望可以给大家一点点启发。 一)使用json提取器实现接口关联 实际项目场景,在财务信息页面,需要上传一个营业执照&…...

【11.10】现代密码学1——密码学发展史:密码学概述、安全服务、香农理论、现代密码学
密码学发展史 写在最前面密码学概述现代密码学量子密码学基本术语加解密的通信模型对称加密PKI通信工作流程 古典密码与分析古代密码的加密古典密码的分析 安全服务香农理论现代密码学乘积密码方案代换-置换网络安全性概念可证明安全性——规约(*规约证明的方案——…...

时间序列预测实战(九)PyTorch实现LSTM-ARIMA融合移动平均进行长期预测
一、本文介绍 本文带来的是利用传统时间序列预测模型ARIMA(注意:ARIMA模型不属于机器学习)和利用PyTorch实现深度学习模型LSTM进行融合进行预测,主要思想是->先利用ARIMA先和移动平均结合处理数据的线性部分(例如趋势和季节性)…...

由日期计算当天是星期几
题目 输入:一个合法的公历日期,格式为“XXXXXXXX”,分别代表年(4 位)、月(2 位)、日(2 位)。 输出:当日对应星期几的英语缩写(3 个字母ÿ…...

springboot模板引擎
1.服务端渲染时相比与前后端分离开发 原理是 跳过前端这一层 直接到服务端 通过数据和模板 生成页面返回前端 springboot包含如下模板引擎 典型如thymeleaf 1>导入依赖 2>查看路径 模板页面在 public static final String DEFAULT_PREFIX “classpath:/templates/”; 即…...

从流量包到攻击画像:一次APT攻击的深度取证WriteUp
1. 从流量包到攻击画像:APT攻击取证实战 那天下午接到应急响应通知时,我正在喝第三杯咖啡。客户发来的压缩包里只有一个5MB的pcap文件,但我知道这里面可能藏着整个攻击链条的关键证据。作为安全分析师,我们就像网络空间的法医&am…...
抠)
AI开发-python-langchain框架(--并行流程 )抠
如果有多个供应商,你也可以使用 [[CC-Switch]] 来可视化管理这些API key,以及claude code 的skills。 # 多平台安装指令 curl -fsSL https://claude.ai/install.sh | bash ## Claude Code 配置 GLM Coding Plan curl -O "https://cdn.bigmodel.cn/i…...

树莓派Pico W与Zoho Creator API集成
在当今物联网(IoT)设备日益普及的时代,如何将这些小型设备与云服务无缝集成是一个热门话题。本文将详细介绍如何利用树莓派Pico W(Raspberry Pi Pico W)与Zoho Creator API进行数据交互,解决OAuth认证的挑战,并提供一个实际的应用实例。 背景介绍 Zoho Creator是一款强…...

STM32F1轻量级USB HID键盘鼠标复合设备固件库
1. 项目概述KeyboardMouse 是一个面向 STM32F1 系列微控制器的轻量级 USB HID(Human Interface Device)固件库,专为实现复合型 USB 键盘与鼠标设备而设计。该库不依赖第三方 USB 协议栈(如 ST 的 USB Device Library 或 Keil ARM …...

MAX31865 RTD测温驱动库:工业级高精度SPI温度采集实现
1. PWFusion_Max31865 库概述:面向工业级 RTD 测温的高精度 SPI 驱动实现PWFusion_Max31865 是一个专为 Maxim Integrated MAX31865 集成电路设计的嵌入式驱动库,核心目标是为 Arduino 兼容平台(包括基于 STM32、ESP32、nRF52 等 MCU 的开发板…...
)
uni-app上传图片总失败?可能是你没处理好这几个细节(uni-file-picker实战排雷)
uni-app图片上传疑难排查指南:从临时路径到稳定交付的完整解决方案 在移动端开发中,文件上传功能看似简单,却暗藏诸多"坑点"。最近接手一个电商项目时,我们团队在uni-file-picker组件上栽了跟头——用户上传的图片时而显…...

最牛逼的程序员出生了
编程学习之路 我是河南某大学计算机专业的。目前主攻C语言与后端开发,每周投入14小时系统学习。计划通过《C Primer Plus》打牢基础,结合项目实战掌握后端技术。未来希望加入科大讯飞,参与AI相关研发。期待与各位共勉!...

Kinetis MCU上的轻量级RGB LED控制库设计
1. 项目概述FSLP_Controls_RGB_LEDs 是一个面向嵌入式微控制器平台的轻量级 RGB LED 控制库,专为 Freescale(现 NXP)Kinetis 系列 MCU 设计,基于 Kinetis SDK v2.x 构建。该库并非通用驱动框架,而是聚焦于硬件抽象层&a…...

嵌入式VGM音频库:轻量级芯片级音源仿真与实时播放
1. 项目概述Video Game Music Library(简称 VGM-Lib)是一个专为嵌入式平台设计的轻量级音频播放库,核心目标是精准复现经典街机与家用游戏机时代的数字音频——特别是基于 SN76489、YM2413、YM2612、RF5C164 等经典音源芯片的原始音色。该库不…...

5步终极指南:用WaveTools彻底解锁《鸣潮》120帧流畅体验
5步终极指南:用WaveTools彻底解锁《鸣潮》120帧流畅体验 【免费下载链接】WaveTools 🧰鸣潮工具箱 项目地址: https://gitcode.com/gh_mirrors/wa/WaveTools 你是否曾在《鸣潮》的激烈战斗中感受过画面卡顿?明明拥有强大的硬件配置&am…...