微信小程序数据交互和缓存

目录
前言:
数据交互
1. 发起网络请求
2. WebSocket
2.1实时数据库
3. 微信支付
数据缓存
1. 页面级缓存
2. 内存级缓存
3. 数据缓存策略
优化用户体验
总结
前言:
在开发微信小程序时,数据交互和缓存是非常重要的方面。本文将介绍如何进行数据交互并有效地使用缓存来提高小程序的性能和用户体验。
数据交互
微信小程序通过与后端服务器进行数据交互,实现页面内容的动态更新。以下是几种常见的数据交互方式:
1. 发起网络请求
通过wx.request API可以发起网络请求,获取后端服务器返回的数据。这可以是GET或POST请求,可以携带参数、请求头等信息。例如:
wx.request({url: 'https://api.example.com/data',method: 'GET',data: {key: 'value'},success: function(res) {// 处理成功返回的数据},fail: function(err) {// 处理请求失败的情况}
});
2. WebSocket
如果需要实时性更高的数据交互,可以使用WebSocket来建立长连接。通过wx.connectSocket API来建立WebSocket连接,并监听onMessage事件接收服务器推送的数据。WebSocket 是一种全双工通信协议,能够实现长连接,适用于实时性较高的场景。在微信小程序中,我们可以使用 wx.connectSocket() 方法建立 WebSocket 连接,实现与服务器的即时数据传输。这种方式适用于聊天室、在线游戏等需要实时交互的场景。
// 建立WebSocket连接
wx.connectSocket({url: 'wss://api.example.com/socket',success: function() {// 连接成功},fail: function(err) {// 连接失败}
});// 监听WebSocket消息
wx.onSocketMessage(function(res) {// 处理服务器推送的数据
});
2.1实时数据库
微信小程序还提供了实时数据库的功能,即小程序云开发中的云数据库。通过使用云数据库,我们可以方便地进行数据的增删改查操作,并实现数据的实时同步。这种方式适用于需求频繁变动或需要多端共享数据的场景。
3. 微信支付
如果你的小程序需要支持支付功能,可以使用微信支付API进行支付交互。具体的支付流程和接口调用方式可以参考微信支付文档。
数据缓存
在小程序中,为了提高用户体验和减少网络请求次数,可以使用缓存来临时存储和管理数据。以下是一些常见的缓存策略:
1. 页面级缓存
通过页面级缓存,可以在小程序的不同页面之间共享数据。可以使用wx.setStorage方法将数据存储到本地缓存中,并使用wx.getStorage方法从缓存中读取数据。
// 存储数据到本地缓存
wx.setStorage({key: 'key',data: 'value'
});// 从本地缓存中读取数据
wx.getStorage({key: 'key',success: function(res) {// 处理读取到的数据},fail: function(err) {// 处理读取失败的情况}
});
2. 内存级缓存
内存级缓存适合存储临时性的数据,例如当前会话的状态信息。可以使用一个全局变量来保存这些数据,在需要的时候直接读取或修改它们。
// 在App全局对象中定义一个全局变量
App({globalData: {userInfo: null}
});// 在任意页面中读取或修改全局变量
const app = getApp();
console.log(app.globalData.userInfo);
app.globalData.userInfo = { name: 'John', age: 25 };
3. 数据缓存策略
根据具体的业务需求,可以制定适合的数据缓存策略。例如,可以使用wx.getStorageSync和wx.setStorageSync方法来同步读写数据,也可以使用异步方法wx.getStorage和wx.setStorage来处理大量数据的读写操作。
此外,还可以设置缓存的过期时间,并定期清理过期的缓存数据,以保持缓存的有效性和可靠性。
优化用户体验
为了优化用户体验,我们可以从以下几个方面入手:
- 合理设计 API 接口,减少数据交互的次数和数据量。
- 使用合适的数据缓存方式,减少服务器请求和提高数据访问速度。
- 对于需要实时更新的数据,使用 WebSocket 或实时数据库,实现即时通信和数据同步。
- 合理利用本地缓存、页面数据缓存和全局数据缓存,减少数据请求次数,提升用户体验。
- 定期清理过期或不再需要的缓存数据,避免占用过多的存储空间。
总结
通过合理的数据交互和缓存策略,我们可以有效地提高微信小程序的性能和用户体验。合理利用网络请求、WebSocket和微信支付等技术实现数据交互,同时使用页面级缓存和内存级缓存来减少网络请求次数,并提供临时存储和共享数据的功能。
在实际开发中,根据具体的业务需求,可以根据以上介绍的方法选择适合的数据交互和缓存策略。通过优化数据交互和合理使用缓存,我们可以为用户提供更流畅、响应快速的小程序体验。
希望本文对您有所帮助!
相关文章:
微信小程序数据交互和缓存
目录 前言: 数据交互 1. 发起网络请求 2. WebSocket 2.1实时数据库 3. 微信支付 数据缓存 1. 页面级缓存 2. 内存级缓存 3. 数据缓存策略 优化用户体验 总结 前言: 在开发微信小程序时,数据交互和缓存是非常重要的方面。本文将介…...
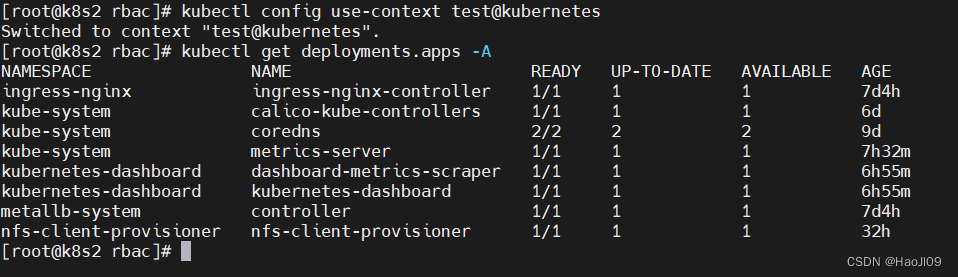
kubernetes集群编排——k8s认证授权
pod绑定sa [rootk8s2 ~]# kubectl create sa admin [rootk8s2 secret]# vim pod5.yaml apiVersion: v1 kind: Pod metadata:name: mypod spec:serviceAccountName: admincontainers:- name: nginximage: nginxkubectl apply -f pod5.yamlkubectl get pod -o yaml 认证 [rootk8s…...
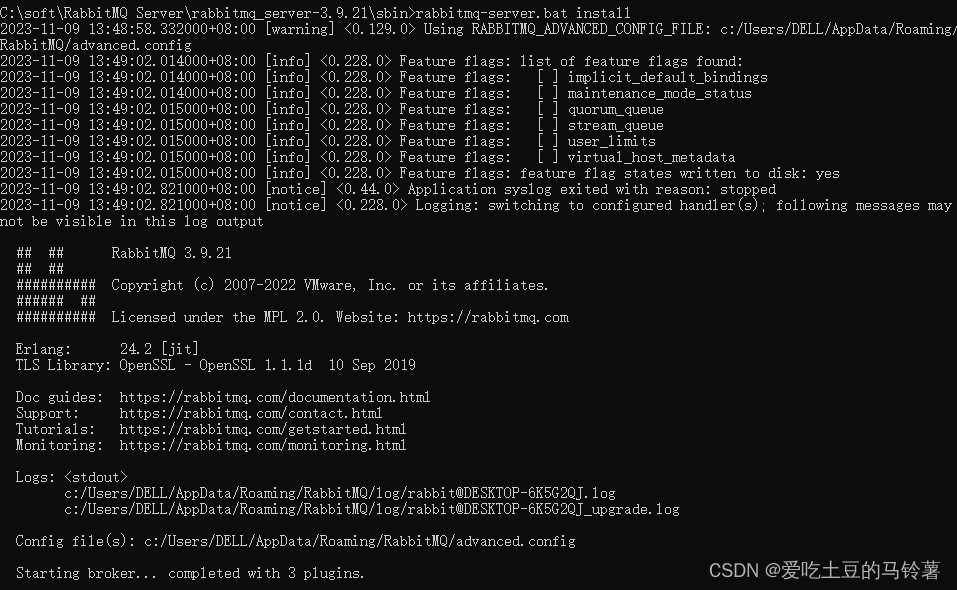
rabbitmq下载安装教程
1.首先需要下载erlang和rabbitmq安装包: 官网下载比较慢,通过网盘下载: 链接:https://pan.baidu.com/s/1fM2BrJqefyzUDZD4tfZLIg 提取码:5hsu 2.安装,傻瓜式安装就可以,可以自定义自己要安装的目…...
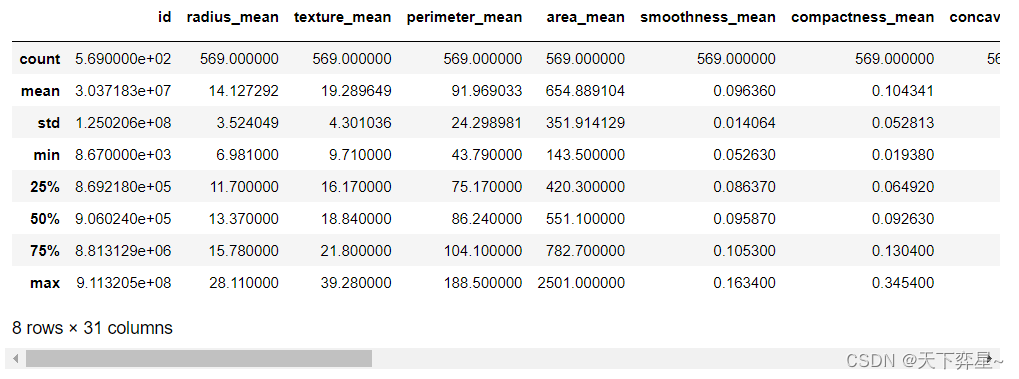
数据分析实战 | SVM算法——病例自动诊断分析
目录 一、数据分析及对象 二、目的及分析任务 三、方法及工具 四、数据读入 五、数据理解 六、数据准备 七、模型训练 八、模型应用及评价 一、数据分析及对象 CSV文件——“bc_data.csv” 数据集链接:https://download.csdn.net/download/m0_70452407/88…...

Splunk Connect for Kafka – Connecting Apache Kafka with Splunk
1: 背景: 1: splunk 有时要去拉取kafka 上的数据: 下面要用的有用的插件:Splunk Connect for Kafka 先说一下这个Splunk connect for kafka 是什么: What is Splunk Connect for Kafka? Spunk Connect for Kafka is a “sink connector” built on the Kafka Connect…...

Unity | Shader(着色器)和material(材质)的关系
一、前言 在上一篇文章中 【精选】Unity | Shader基础知识(什么是shader)_unity shader_菌菌巧乐兹的博客-CSDN博客 我们讲了什么是shader,今天我们讲一下shder和material的关系 二、在unity中shader的本质 unity中,shader就…...

Leetcode—69.x的平方根【简单】
2023每日刷题(二十七) Leetcode—69.x的平方根 直接法实现代码 int mySqrt(int x) {long long i 0;while(i * i < x) {i;}if(i * i > x) {return i - 1;}return i; }运行结果 二分法实现代码 int mySqrt(int x) {long long left 0, right (l…...

再探单例模式
再探单例模式 一:故事背景二:单例重点三:总结提升 一:故事背景 最近在进行单例模式的复习,今天进行一下对应的总结,分析一下各个设计模式。今天从最简单的单例模式开始。 二:单例重点 概念 一…...
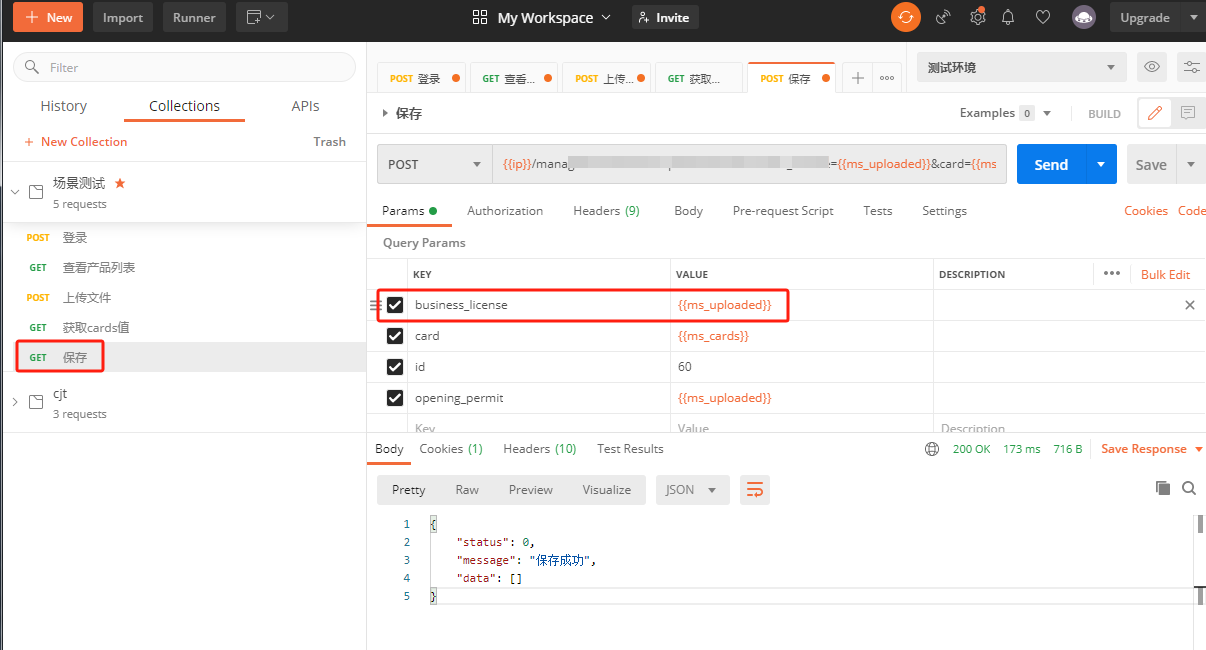
Postman使用json提取器和正则表达式实现接口的关联
近期在复习Postman的基础知识,在小破站上跟着百里老师系统复习了一遍,也做了一些笔记,希望可以给大家一点点启发。 一)使用json提取器实现接口关联 实际项目场景,在财务信息页面,需要上传一个营业执照&…...

【11.10】现代密码学1——密码学发展史:密码学概述、安全服务、香农理论、现代密码学
密码学发展史 写在最前面密码学概述现代密码学量子密码学基本术语加解密的通信模型对称加密PKI通信工作流程 古典密码与分析古代密码的加密古典密码的分析 安全服务香农理论现代密码学乘积密码方案代换-置换网络安全性概念可证明安全性——规约(*规约证明的方案——…...

时间序列预测实战(九)PyTorch实现LSTM-ARIMA融合移动平均进行长期预测
一、本文介绍 本文带来的是利用传统时间序列预测模型ARIMA(注意:ARIMA模型不属于机器学习)和利用PyTorch实现深度学习模型LSTM进行融合进行预测,主要思想是->先利用ARIMA先和移动平均结合处理数据的线性部分(例如趋势和季节性)…...

由日期计算当天是星期几
题目 输入:一个合法的公历日期,格式为“XXXXXXXX”,分别代表年(4 位)、月(2 位)、日(2 位)。 输出:当日对应星期几的英语缩写(3 个字母ÿ…...

springboot模板引擎
1.服务端渲染时相比与前后端分离开发 原理是 跳过前端这一层 直接到服务端 通过数据和模板 生成页面返回前端 springboot包含如下模板引擎 典型如thymeleaf 1>导入依赖 2>查看路径 模板页面在 public static final String DEFAULT_PREFIX “classpath:/templates/”; 即…...

如何判断从本机上传到服务器的文件数据内容是一致的?用md5加密算法!
问题场景 最近在帮导师做横向,我想把整个项目环境放到服务器中,需要把一个很大的数据文件传到服务器,传上去很方便,但是涉及到文件的压缩上传和服务器内解压环节,不是太确定文件在本机和服务器的数据内容是否一致。 解…...

Ubuntu 20.04 DNS解析原理, 解决resolv.conf被覆盖问题
------------------------------------------------------------------ author: hjjdebug date: 2023年 11月 09日 星期四 14:01:11 CST description: Ubuntu 20.04 DNS解析原理, 解决resolv.conf被覆盖问题 ----------------------------------------------------------------…...
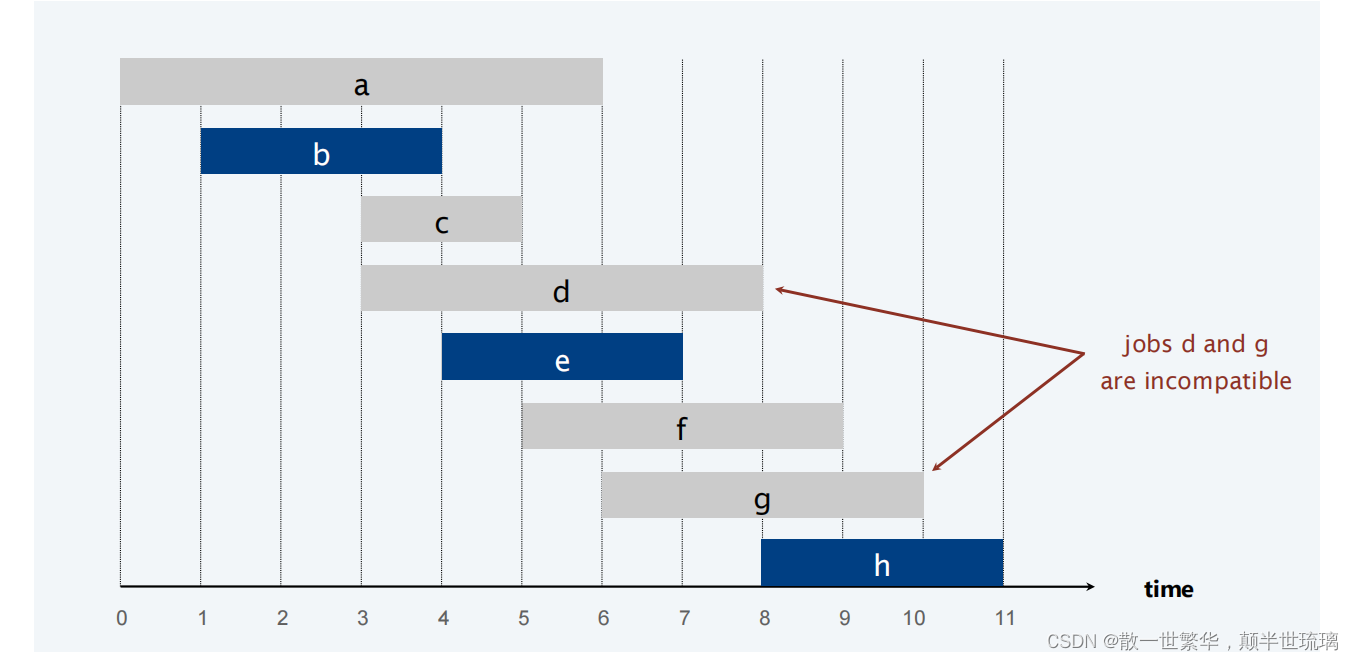
探索经典算法:贪心、分治、动态规划等
1.贪心算法 贪心算法是一种常见的算法范式,通常在解决最优化问题中使用。 贪心算法是一种在每一步选择中都采取当前状态下最优决策的算法范式。其核心思想是选择每一步的最佳解决方案,以期望达到最终的全局最优解。这种算法特点在于只考虑局部最优解&am…...
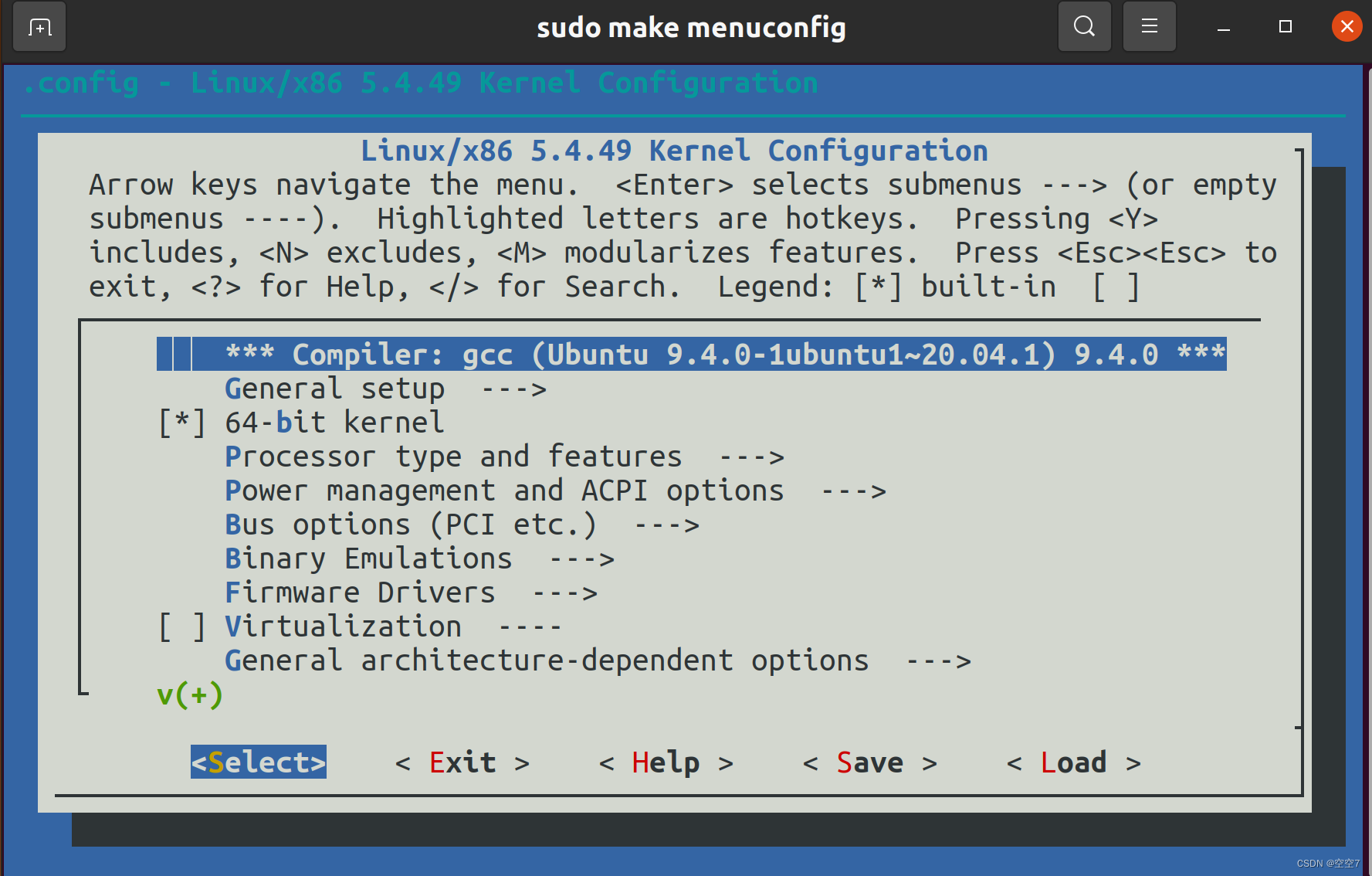
【Linux】编译Linux内核
之所以编译内核,是因为gem5全系统仿真需要vmlinux文件,在此记录一下以备后面需要。 此过程编译之后会获得vmlinux和bzImage两个文件; 主要参考知行大佬的编译内核与gem5官方教程 文章目录 一、Linux源码下载二、安装编译依赖三、编译1. 内核编…...
网页判断版本更新
一、需求解析 为什么我会想到这个技术呢,是因为我有一次发现,我司的用户在使用网页的时候,经常会出现一个页面放很久,下班也不关这个页面,这样就会导致页面的代码长时间处于不更新的状态。 在使用到一个功能出了bug&a…...
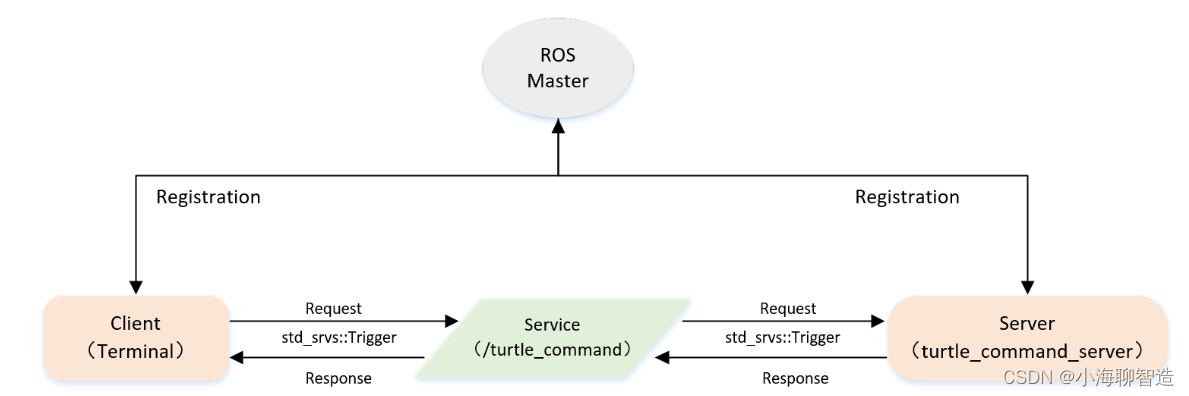
ros1 基础学习08- 实现Server端自定义四 Topic模式控制海龟运动
一、服务模型 Server端本身是进行模拟海龟运动的命令端,它的实现是通过给海龟发送速度(Twist)的指令,来控制海龟运动(本身通过Topic实现)。 Client端相当于海龟运动的开关,其发布Request来控制…...

面试题之TCP粘包现象及其解决方法
计算机网络每层的基本单位:物理层(第一层):比特流;数据链路层(第二层):数据帧;网络层(第三层):数据包;传输层(…...

中文评论分析新选择:SiameseAOE属性抽取模型详细使用教程
中文评论分析新选择:SiameseAOE属性抽取模型详细使用教程 1. 认识SiameseAOE属性抽取模型 1.1 什么是属性观点抽取? 属性观点抽取(Aspect-Based Sentiment Analysis,简称ABSA)是一种能够从文本中精准识别具体属性和…...

容器安全扫描:镜像漏洞检测与运行时保护
容器安全扫描:镜像漏洞检测与运行时保护 随着容器技术的广泛应用,其安全性问题日益凸显。容器安全扫描成为保障云原生环境安全的关键环节,涵盖镜像构建阶段的漏洞检测与运行时的动态防护。本文将深入探讨容器安全的核心实践,帮助…...

玩客云打造全能家庭服务器:Armbian+CasaOS+Docker+青龙面板+内网穿透一站式部署
1. 玩客云改造前的准备工作 家里闲置的玩客云放着吃灰?不如把它改造成全能家庭服务器!这个不到百元的小盒子,刷上Armbian系统后性能直接起飞,跑Docker、挂青龙面板、做内网穿透样样都行。我去年把家里的三台玩客云都改造了&#x…...

NeurIPS 2024新作SOFTS实战:用PyTorch复现这个高效的多元时间序列预测模型
NeurIPS 2024新作SOFTS实战:用PyTorch复现高效的多元时间序列预测模型 多元时间序列预测在能源管理、交通流量分析和金融市场预测等领域具有广泛应用。2024年NeurIPS会议上提出的SOFTS模型,通过创新的Series-cOre Fusion机制,在预测精度和计算…...

银行数据中心基础设施建设与运维管理【1.2】
2. 2 数据中心的容量 如何规划数据中心容量一直是数据中心管理者和从业者的一个重大问题。 当一个数据中心建设意向提出之后, 数据中心的建设容量到底该多大? 到底该按照哪些因素去规划数据中心的容量? 数据中心到底该按照那种方式去建设? 如何使将要建设的数据中心能够面…...
)
C盘告急?保姆级教程:将Kali WSL2完美迁移至D盘并安装完整工具包(避坑指南)
Kali WSL2迁移至D盘全攻略:释放C盘空间并部署完整工具链 每次打开资源管理器看到C盘飘红的剩余空间,是不是感觉血压也跟着升高了?特别是当你在Windows上运行Kali WSL2时,那些渗透测试工具包就像一群贪吃蛇,转眼间就能吞…...

有没有类似trello或者teambition的本地版的任务管理工具?盘点7款
很多企业在找任务管理工具时,最先想到的是 Trello 这类看板工具,或者 Teambition 这类团队协作平台。问题也往往出在这里:在线版好上手,但一旦涉及内网部署、数据分级、权限审计、长期留存、与内部系统打通,纯 SaaS 方…...

5分钟上手IndexTTS2:让AI语音合成真正听懂你的情感!
5分钟上手IndexTTS2:让AI语音合成真正听懂你的情感! 【免费下载链接】index-tts An Industrial-Level Controllable and Efficient Zero-Shot Text-To-Speech System 项目地址: https://gitcode.com/gh_mirrors/in/index-tts 还在为视频配音找不到…...

RA595库:面向RAGPIO平台的74HC595高性能移位寄存器驱动
1. RA595库概述:面向RAGPIO平台的74HC595移位寄存器驱动框架RA595是一个专为RAGPIO硬件抽象层(Hardware Abstraction Layer)设计的Arduino兼容库,用于高效、可靠地控制标准TTL/CMOS逻辑器件74HC595(八位串行输入、并行…...

AI 编程盛行的时代,为什么 “『DC- WFW』” 仍然具有必要性?淄
这,是一个采用C精灵库编写的程序,它画了一幅漂亮的图形: 复制代码 #include "sprites.h" //包含C精灵库 Sprite turtle; //建立角色叫turtle void draw(int d){for(int i0;i<5;i)turtle.fd(d).left(72); } int main(){ …...