【论文阅读】FreeMatch: Self-adaptive Thresholding for Semi-supervised Learning
论文下载
GitHub
bib:
@INPROCEEDINGS{wang2023freematch,title = {FreeMatch: Self-adaptive Thresholding for Semi-supervised Learning},author = {Wang, Yidong and Chen, Hao and Heng, Qiang and Hou, Wenxin and Fan, Yue and and Wu, Zhen and Wang, Jindong and Savvides, Marios and Shinozaki, Takahiro and Raj, Bhiksha and Schiele, Bernt and Xie, Xing},booktitle = {ICLR},year = {2023},pages = {1--20}
}
1. 摘要
-
Semi-supervised Learning (SSL) has witnessed great success owing to the impressive performances brought by various methods based on pseudo labeling and consistency regularization.
半监督学习(semi-supervised learning)的两大杀器,pseudo labeling(伪标记)和consistency regularization(一致性正则)。
-
However, we argue that existing methods might fail to utilize the unlabeled data more effectively since they either use a pre-defined / fixed threshold or an ad-hoc threshold adjusting scheme, resulting in inferior performance and slow convergence.
提出现有方法的不足,use a pre-defined / fixed threshold or an ad-hoc threshold adjusting scheme。这里的阈值应该是伪标签加入的阈值,只有大于阈值的伪标签才会加入训练,这一点在基于伪标签技术的方法中十分的常用。至于基于一致性正则中是否也存在这样的阈值,这一点是存疑的。
-
We first analyze a motivating example to obtain intuitions on the relationship between the desirable threshold and model’s learning status. Based on the analysis, we hence propose FreeMatch to adjust the confidence threshold in a self-adaptive manner according to the model’s learning status.
顺利提出自己的核心创新点: self-adaptive confidence threshold。
-
We further introduce a self-adaptive class fairness regularization penalty to encourage the model for diverse predictions during the early training stage.
一个trick,避免模型初期过早收敛。
-
Extensive experiments indicate the superiority of FreeMatch especially when the labeled data are extremely rare. FreeMatch achieves 5.78%, 13.59%, and 1.28% error rate reduction over the latest state-of-the-art method FlexMatch on CIFAR-10 with 1 label per class, STL-10 with 4 labels per class, and ImageNet with 100 labels per class, respectively. Moreover, FreeMatch can also boost the performance of imbalanced SSL.
自信的算法用三句话来描述自己是art-of-state的。
-
The codes can be found at https: //github.com/microsoft/Semi-supervised-learning.
代码地址。
2. 算法描述
2.1. 例子
通过一个分类的例子,有以下有趣的结论:
- 简单地说,未标记数据利用率(采样率) 1 − P ( Y p = 0 ) 1−P(Y_p = 0) 1−P(Yp=0) 直接由阈值 τ \tau τ 控制。随着置信度阈值 τ \tau τ 变大,未标记数据利用率变低。在训练初期,由于 β \beta β 仍然很小,采用较高的阈值可能会导致采样率较低且收敛速度较慢。
- 更有趣的是,如果 σ 1 ≠ σ 2 \sigma_1 \neq \sigma_2 σ1=σ2,则 P ( Y p = 1 ) ≠ P ( Y p = − 1 ) P(Y_p = 1) \neq P(Y_p = −1) P(Yp=1)=P(Yp=−1)。事实上, τ \tau τ 越大,伪标签越不平衡。从我们旨在解决平衡分类问题的意义上来说,这可能是不可取的。不平衡的伪标签可能会扭曲决策边界并导致所谓的伪标签偏差。对此的一个简单的补救措施是使用特定于类的阈值 τ 2 \tau_2 τ2 和 1 − τ 1 1 − \tau_1 1−τ1 来分配伪标签。(
different classes have different levels of intra-class diversity (different σ)) - 采样率 1 − P ( Y p = 0 ) 1 − P(Y_p = 0) 1−P(Yp=0) 随着 μ 2 − μ 1 \mu_2 − \mu_1 μ2−μ1 变小而降低。换句话说,两个类越相似,未标记的样本就越有可能被屏蔽。随着两个类别变得更加相似,特征空间中会混合更多的样本,而模型对其预测的信心较差,因此需要一个适度的阈值来平衡采样率。否则,我们可能没有足够的样本来训练模型来对已经很难分类的类进行分类。(
some classes are harder to classify than others (µ2 − µ1 being small)
Since different classes have different levels of intra-class diversity (different σ) and some classes are harder to classify than others (µ2 − µ1 being small), a fine-grained
class-specific thresholdis desirable to encourage fair assignment of pseudo labels to different classes.
2.2. Self-adaptive Threshold
Global Threshold:
τ t = { 1 C , if t = 0 , λ τ t − 1 + ( 1 − λ ) 1 μ B ∑ b = 1 μ B max q b , otherwise . \tau_t= \begin{cases} \frac{1}{C},& \text{if } t=0,\\ \lambda\tau_{t-1} + (1-\lambda)\frac{1}{\mu B}\sum_{b=1}^{\mu B}\max{q_b},& \text{otherwise}. \end{cases} τt={C1,λτt−1+(1−λ)μB1∑b=1μBmaxqb,if t=0,otherwise.
Local Threshold:
p ~ t ( c ) = { 1 C , if t = 0 , λ p ~ t − 1 ( c ) + ( 1 − λ ) 1 μ B ∑ b = 1 μ B q b ( c ) , otherwise . \widetilde{p}_t(c)= \begin{cases} \frac{1}{C},& \text{if } t=0,\\ \lambda\widetilde{p}_{t-1}(c) + (1-\lambda)\frac{1}{\mu B}\sum_{b=1}^{\mu B}q_b(c),& \text{otherwise}. \end{cases} p t(c)={C1,λp t−1(c)+(1−λ)μB1∑b=1μBqb(c),if t=0,otherwise.
Final Threshold:
τ t ( c ) = MaxNorm ( p ~ t ( c ) ) ⋅ τ t \tau_t(c) = \text{MaxNorm}(\widetilde{p}_t(c)) \cdot \tau_t τt(c)=MaxNorm(p t(c))⋅τt
一致性正则:
L u = 1 μ B ∑ b = 1 μ B I ( max ( q b ) ≥ τ t ( arg max ( q b ) ) ) ⋅ H ( q ^ b , Q b ) \mathcal{L}_u = \frac{1}{\mu B}\sum_{b=1}^{\mu B}\mathbb{I}(\max(q_b) \geq \tau_t(\argmax(q_b)))\cdot \mathcal{H}(\hat{q}_b, Q_b) Lu=μB1b=1∑μBI(max(qb)≥τt(argmax(qb)))⋅H(q^b,Qb)
Notice: 原文中,指示函数少打了个括号
2.3. Self-adaptive Fairness
KL散度:
D K L ( p ∥ q ) = ∑ i = 1 n p ( x i ) log ( p ( x i ) q ( x i ) ) D_{KL}(p\|q) = \sum_{i=1}^np(x_i)\log(\frac{p(x_i)}{q(x_i)}) DKL(p∥q)=i=1∑np(xi)log(q(xi)p(xi))
其中:
- p表示样本的真实分布,q表示模型的预测分布。从KL散度公式中可以看到q分布越接近p(q分布越拟合p),那么散度值越小,即损失值越小。
- KL散度称为KL距离,但它并不满足距离的性质:1. KL散度不是对称的;2. KL散度不满足三角不等式。
交叉熵:
D K L ( p ∥ q ) = ∑ i = 1 n p ( x i ) log ( p ( x i ) q ( x i ) ) = ∑ i = 1 n p ( x i ) log ( p ( x i ) ) − ∑ i = 1 n p ( x i ) log ( q ( x i ) ) = − H ( p ( x ) ) + [ − ∑ i = 1 n p ( x i ) log ( q ( x i ) ) ] \begin{align*} D_{KL}(p\|q) &= \sum_{i=1}^np(x_i)\log(\frac{p(x_i)}{q(x_i)})\\ &= \sum_{i=1}^n p(x_i)\log(p(x_i)) - \sum_{i=1}^n p(x_i)\log(q(x_i)) \\ &= -\mathcal{H}(p(x)) + [-\sum_{i=1}^n p(x_i)\log(q(x_i))] \end{align*} DKL(p∥q)=i=1∑np(xi)log(q(xi)p(xi))=i=1∑np(xi)log(p(xi))−i=1∑np(xi)log(q(xi))=−H(p(x))+[−i=1∑np(xi)log(q(xi))]
其中:
- 等式的前一部分恰巧就是p的熵(表示信息量),等式的后一部分,就是交叉熵。
- 在机器学习中,我们需要评估label(GroundTruth)和predicts之间的差距,使用KL散度刚刚好,即:由于KL散度中的前一部分 − H ( y ) −\mathcal{H}(y) −H(y)不变,故在优化过程中,只需要关注交叉熵就可以了。所以一般在机器学习中直接用用交叉熵做loss,评估模型。而在拟合可变分布时,则采用
KL散度。
本文提出的SAF正则是基于《Joint Optimization Framework for Learning with Noisy Labels》中的工作的。《Pseudo-Labeling and Confirmation Bias in Deep Semi-Supervised Learning》中的工作则是基于此的,并没有做更改。
The regularization loss L p ( θ ∣ X ) L_p(\theta|X) Lp(θ∣X) is required to prevent the assignment of all labels to a single class: In the case of minimizing only Eq. (6), we obtain a trivial global optimal solution with a network that always predicts constant one-hot y ^ ∈ H \hat{y} \in H y^∈H and each label y i = y ^ y_i = \hat{y} yi=y^ for any image x i x_i xi. To overcome this problem, we introduce a prior probability distribution p \mathbf{p} p, which is a distribution of classes among all training data. If the prior distribution of classes is known, then the updated labels should follow the same. Therefore, we introduce the KL-divergence from s ‾ ( θ , X ) \overline{s}(\theta,X) s(θ,X) to p \mathbf{p} p as a cost function as follows:
L p = ∑ j = 1 c p j log ( p j s ‾ ( θ , X ) ) \mathcal{L}_p = \sum_{j=1}^{c}p_j \log(\frac{p_j}{\overline{s}(\theta,X)}) Lp=j=1∑cpjlog(s(θ,X)pj)
s ‾ ( θ , X ) = ∑ i = 1 n s ( θ , x i ) \overline{s}(\theta,X) = \sum_{i=1}^{n}s(\theta,x_i) s(θ,X)=i=1∑ns(θ,xi)
Notice: 这里的正则是KL散度, p表示先验概率,这里采用的是均匀分布; s ‾ ( θ , X ) \overline{s}(\theta,X) s(θ,X) 表示模型的平均预测。
SAF:
这个正则的目的是鼓励模型对每个类别做出不同的预测,从而产生有意义的自适应阈值,特别是在标记数据很少的情况下。不同于只是要求模型对于无标记样本预测类别平衡(各个类别预测数量一样),数量波动也是自适应的。SAF 鼓励每个小批量的输出概率在通过直方图分布归一化后接近模型的边缘类分布。
p ‾ = 1 μ B ∑ b = 1 μ B I ( max ( q b ) ≥ τ t ( arg max ( q b ) ) ) Q b \overline{p} = \frac{1}{\mu B}\sum_{b=1}^{\mu B}\mathbb{I}(\max(q_b) \geq \tau_t(\argmax(q_b)))Q_b p=μB1b=1∑μBI(max(qb)≥τt(argmax(qb)))Qb
h ‾ = 1 μ B Hist μ B ( I ( max ( q b ) ≥ τ t ( arg max ( q b ) ) ) Q ^ b ) \overline{h} = \frac{1}{\mu B}\text{Hist}_{\mu B}(\mathbb{I}(\max(q_b) \geq \tau_t(\argmax(q_b)))\hat{Q}_b) h=μB1HistμB(I(max(qb)≥τt(argmax(qb)))Q^b)
h ~ t = λ h ~ t − 1 + ( 1 − λ ) Hist μ B ( q ^ b ) ) \widetilde{h}_t = \lambda \widetilde{h}_{t-1} + (1-\lambda)\text{Hist}_{\mu B}(\hat{q}_b)) h t=λh t−1+(1−λ)HistμB(q^b))
L f = − H ( SumNorm ( q ~ t h ~ t ) , SumNorm ( q ‾ t h ‾ t ) ) \mathcal{L}_f = -\mathcal{H}(\text{SumNorm}(\frac{\widetilde{q}_t }{\widetilde{h}_t }), \text{SumNorm}(\frac{\overline{q}_t }{\overline{h}_t })) Lf=−H(SumNorm(h tq t),SumNorm(htqt))
疑问?
- 这里的 L f \mathcal{L}_f Lf 表示交叉熵的相反数,那不是相当于是负数了。
- 这里魔改太多了,想了很久,还是没法明白这是为什么?
Answer:
我在这里尝试回答一下自己的疑问。
首先,可以肯定的是 L f \mathcal{L}_f Lf是负的。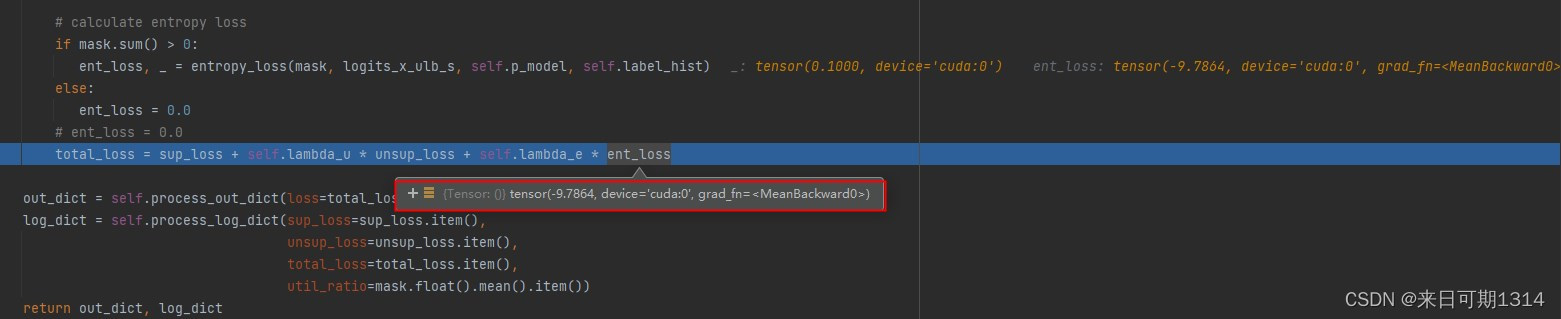
这里借鉴的 L f \mathcal{L}_f Lf可以理解为 SumNorm ( q ‾ t h ‾ t ) \text{SumNorm}(\frac{\overline{q}_t }{\overline{h}_t }) SumNorm(htqt)的熵,可以理解为信息量。但是信息量不能为负数,这里相当于最大化熵,即要求分布尽可能均匀,每个类的概率值相同。
那么现在就还有一个疑问了,为什么不是类似于 − H ( SumNorm ( q ‾ t h ‾ t ) , SumNorm ( q ‾ t h ‾ t ) ) -\mathcal{H}(\text{SumNorm}(\frac{\overline{q}_t }{\overline{h}_t }), \text{SumNorm}(\frac{\overline{q}_t }{\overline{h}_t })) −H(SumNorm(htqt),SumNorm(htqt))这样的形势。猜测是为了简化运算, SumNorm ( q ~ t h ~ t ) \text{SumNorm}(\frac{\widetilde{q}_t }{\widetilde{h}_t }) SumNorm(h tq t)其实是没有梯度值的,相当于是一个标量。当然这是强行解释了,其实不必纠结为什么吧,效果好就是了,原论文也没有进一步的解释。
3. 总结
论文写作技巧拉满了。关于自适应阈值这一块我倒是理解了,但是关于SAF这个负号我实在是没法理解。
相关文章:
【论文阅读】FreeMatch: Self-adaptive Thresholding for Semi-supervised Learning
论文下载 GitHub bib: INPROCEEDINGS{wang2023freematch,title {FreeMatch: Self-adaptive Thresholding for Semi-supervised Learning},author {Wang, Yidong and Chen, Hao and Heng, Qiang and Hou, Wenxin and Fan, Yue and and Wu, Zhen and Wang, Jindong and Savv…...

工业网关贴牌厂家有哪些?工业网关OEM厂家怎么选?
随着物联网技术的不断发展,市面上不断涌现出各种工业物联网厂商。中小型物联网企业苦于有技术,但是生产能力受限,需要寻找OEM代工厂家。但是在如何选择OEM代工厂家时又犯了难。工业网关类产品属于技术密集型产品,对厂家的生产能力…...
NetSuite 固定资产报表自定义原理及应用
NetSuite固定资产模块一直处于功能迭代更新中,目前23.2的版本能够支持报表的局部自定义,比如增加原值或已折旧期间,甚至固定资产自定义字段等。但是当我们在实际项目中,会遇到一些挑战,例如: 固定资产原值…...

【复杂网络建模】——基于关联矩阵构建超图网络
目录 一、复杂网络介绍 二、常规的构建方法 三、基于关联矩阵构建超图 一、复杂网络介绍 复杂网络是指由大量相互连接的元素或节点构成的网络,这些节点之间的连接关系通常是非常复杂和多样化的。这种网络结构通常用图论来表示,其中节点表示网络中的个体或元素,边表示它们…...

学习c#的第八天
目录 C# 方法 C# 中定义方法 C# 中调用方法 递归方法调用 参数传递 值参数 引用参数 输出参数 常见题 ref 和 out 的区别 方法中参数的类型有几种 扩展方法 对于复杂引用类型参数传递的控制 C# 方法 C# 中定义方法 在C#中定义方法时,需要遵循以下结构…...

我心目中的分布式操作系统
这是一位网友发给我的文字,我原样复制粘贴发出来给大家,他的观点我不过多评论,也不代表公司和研发团队的立场,但是最后一段本人不同意,因为Laxcus分布式操作系统已经发布了六个版本,在很多领域广泛部署使用…...
新型的铁塔基站“能源管家”
安科瑞 崔丽洁 引言:随着5G基站的迅猛发展,基站的能耗问题也越来越突出,高效可靠的基站配电系统方案,是提高基站能耗使用效率,实现基站节能降耗的重要保证,通过多回路仪表监测每个配电回路的用电负载情况&a…...

数字孪生智慧园区:大数据驱动下的运营管理革新
随着物联网、大数据、云计算等技术的飞速发展,数字孪生技术应运而生,它将物理世界与数字世界紧密连接起来,为各行各业提供了前所未有的解决方案。智慧园区作为城市的重要组成部分,通过数字孪生技术,可以实现更加高效、…...
sqli-labs关卡12(基于post提交的双引号闭合的字符型注入)通关思路
文章目录 前言一、回顾第十一关知识点二、靶场第十二关通关思路1、判断注入点2、爆显位个数3、爆显位位置4、爆数据库名5、爆数据库表名6、爆数据库列名7、爆数据库数据 总结 前言 此文章只用于学习和反思巩固sql注入知识,禁止用于做非法攻击。注意靶场是可以练习的…...
开放领域问答机器人2——开发流程和方案
开放领域问答机器人是指在任何领域都能够回答用户提问的智能机器人。与特定领域问答机器人不同,开放领域问答机器人需要具备更广泛的知识和更灵活的语义理解能力,以便能够回答各种不同类型的问题。 开发开放领域问答机器人的流程和方案可以包括以下步骤…...
)
pandas 常用45个操作方法(详解)
1、query函数进行数据筛选 相当于 bool 索引 data.query("Graduate_year==2020 & Language==Java")df.query("Language in [CPP,C,C#]") pandas.DataFrame.query(self, expr, inplace = False, **kwargs)Expr 评估查询字符inplace=False 修改数…...

PHP判断扫码支付扫码条码支付宝微信区分
微信:用户付款码规则:18位纯数字,前缀以10、11、12、13、14、15开头 支付宝:25~30开头的长度为16~24位的数字,实际字符串长度以开发者获取的付款码长度为准 <?php /*** 判断扫码支付的方式* param string $code 扫…...
一文了解芯片测试项目和检测方法 -纳米软件
芯片检测是芯片设计、生产、制造成过程中的关键环节,检测芯片的质量、性能、功能等,以满足设计要求和市场需求,确保芯片可以长期稳定运行。芯片测试内容众多,检测方法多样,今天纳米软件将为您介绍芯片的检测项目都有哪…...
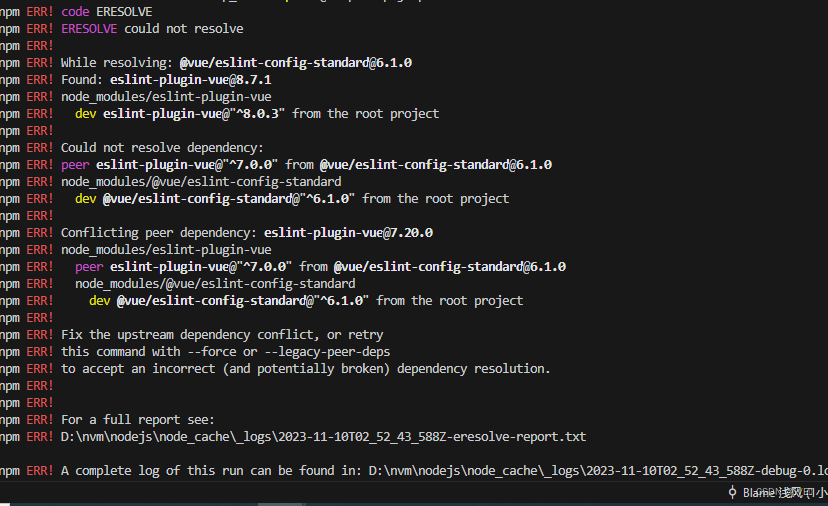
【npm 错误】:npm ERR! code ERESOLVE、npm ERR! ERESOLVE could not resolve问题
用过npm的小伙伴都会有这么一个情况出现,就是npm install /npm install xxxx 会出现改一连串的错误,如下: 解决办法: 只要在npm install后面加上--legacy-peer-deps就可以解决问题,安装插件也一样 npm install --legacy-peer-dep…...
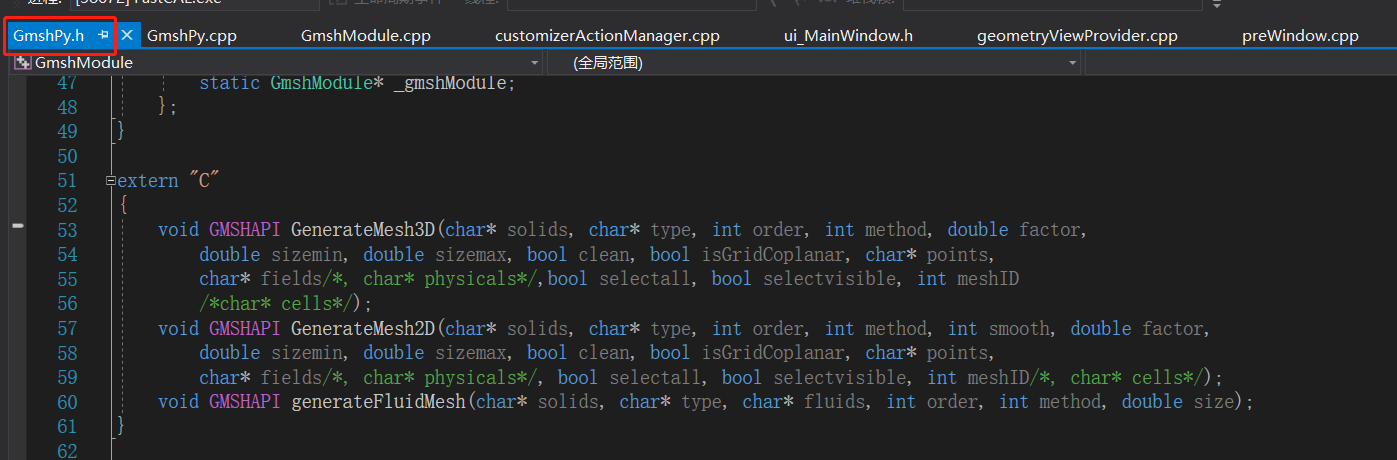
【FastCAE源码阅读8】调用gmsh生成网格
FastCAE使用gmsh进行网格划分,划分的时候直接启动一个新的gmsh进程,个人猜测这么设计是为了规避gmsh的GPL协议风险。 进行网格划分时,其大体运行如下图: 一、Python到gmshModule模块 GUI操作到Python这步不再分析,比…...
使用LLM-Tuning实现百川和清华ChatGLM的Lora微调
LLM-Tuning项目源码: GitHub - beyondguo/LLM-Tuning: Tuning LLMs with no tears💦, sharing LLM-tools with love❤️.Tuning LLMs with no tears💦, sharing LLM-tools with love❤️. - GitHub - beyondguo/LLM-Tuning: Tuning LLMs wit…...
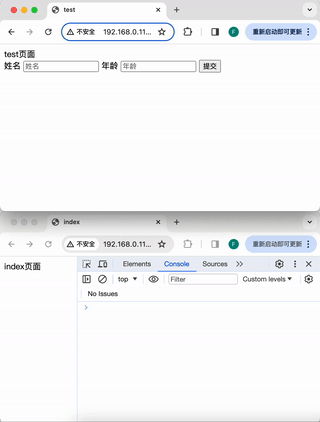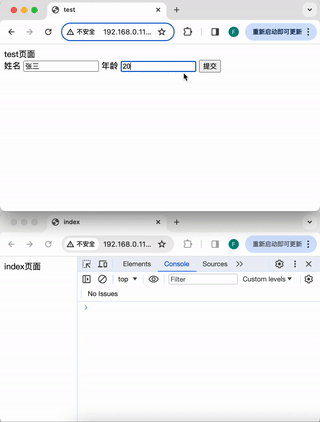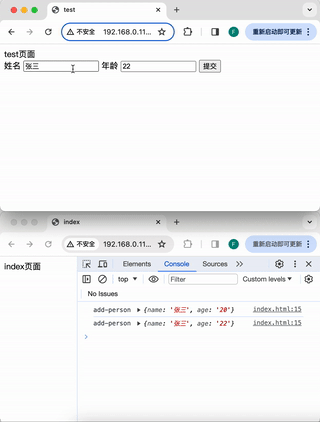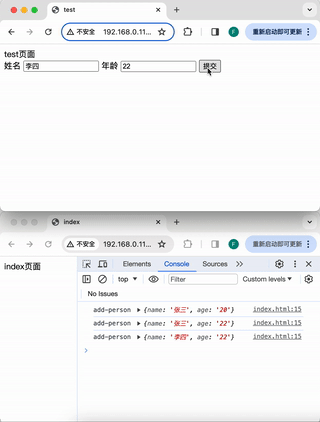
浏览器标签页之间的通信
前言 在开发管理后台页面的时候,会遇到这样一种需求:有一个列表页面,一个新增按钮,一个新增页面,点击新增按钮,在一个新的标签页中打开新增页面。并且,新增后要自动实时的更新列表页面的数据。…...
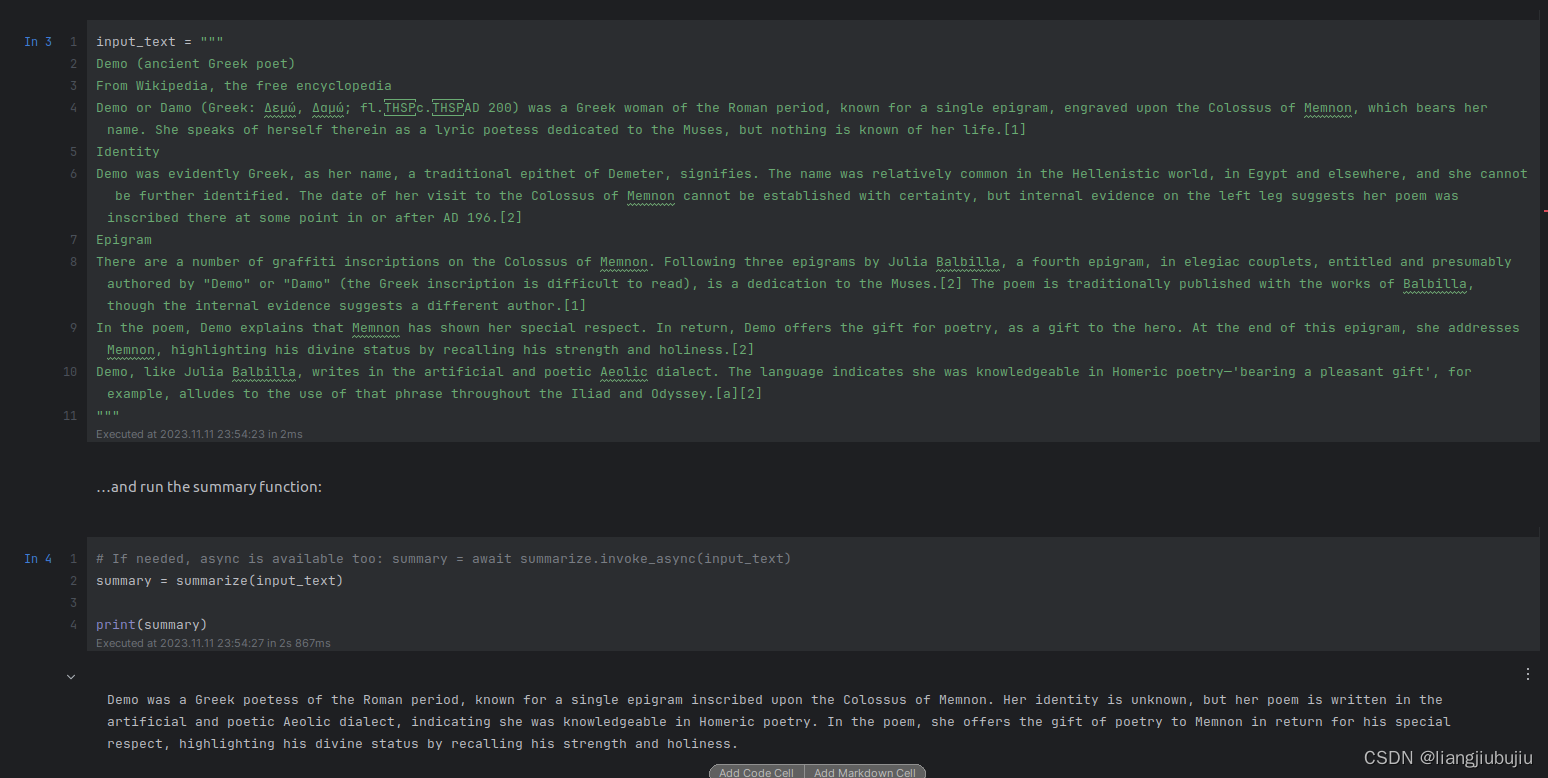
Semantic Kernel 学习笔记1
1. 挂代理跑通openai API 2. 无需魔法跑通Azure API 下载Semantic Kernel的github代码包到本地,主要用于方便学习python->notebooks文件夹中的内容。 1. Openai API:根据上述文件夹中的.env.example示例创建.env文件,需要填写下方两个内…...

图像二值化阈值调整——Triangle算法,Maxentropy方法
一. Triangle方法 算法描述:三角法求分割阈值最早见于Zack的论文《Automatic measurement of sister chromatid exchange frequency》主要是用于染色体的研究,该方法是使用直方图数据,基于纯几何方法来寻找最佳阈值,它的成立条件…...

监控视频片段合并完整视频|FFmpeg将多个视频片段拼接完整视频|PHP自动批量拼接合并视频
关于环境配置ffmpeg安装使用的看之前文章 哔哩哔哩缓存转码|FFmpeg将m4s文件转为mp4|PHP自动批量转码B站视频 <?php date_default_timezone_set("PRC"); header("Content-type: text/html; charsetutf-8"); set_time_limit(0);// 遍历获取文件 functi…...

自动化测试:等待方式详解
🍅 点击文末小卡片,免费获取软件测试全套资料,资料在手,涨薪更快 在自动化测试中,等待是一个重要的技术,用于处理页面加载、元素定位、元素状态改变等延迟问题。等待能够确保在条件满足后再进行后续操作&a…...

ESPHome配置避坑指南:从编译到OTA,让你的ESP32-CAM一次点亮不折腾
ESPHome实战避坑手册:ESP32-CAM从编译到OTA的进阶配置策略 第一次接触ESP32-CAM时,我对着闪烁的蓝色LED灯整整调试了六个小时——不是因为硬件故障,而是YAML配置里一个不起眼的frequency参数写错了单位。这种令人抓狂的经历促使我整理了这份实…...

腾讯优图Youtu-Parsing案例分享:手写体、印章、图表精准识别效果
腾讯优图Youtu-Parsing案例分享:手写体、印章、图表精准识别效果 1. 文档解析的新标杆 在日常工作中,我们经常遇到这样的场景:收到一份扫描的合同,需要提取关键条款;拿到一份手写笔记,想要转为电子版&…...
整流控制策略)
学Simulink——基于Simulink的单位功率因数(UPF)整流控制策略
目录 手把手教你学Simulink ——基于Simulink的单位功率因数(UPF)整流控制策略 一、问题背景 二、UPF 控制原理 1. 功率因数定义 2. dq 坐标系下的解耦控制 三、系统架构 四、Simulink 建模步骤 第一步:搭建主电路 第二步:实现锁相环(PLL) 第三步:坐标变换 第…...
)
500元预算搞定无人机高清图传?手把手教你用OpenIPC+SSC338Q+IMX415攒一套(附硬件清单与避坑指南)
500元预算打造无人机高清图传:OpenIPCSSC338QIMX415实战手册 当大多数无人机爱好者还在为动辄上千元的专业图传设备犹豫时,一群极客已经用开源方案将成本压缩到惊人的500元区间。这不仅是预算的胜利,更代表着硬件DIY文化的精髓——用智慧填补…...

性能引擎:G-Helper让创意工作流告别卡顿与过热
性能引擎:G-Helper让创意工作流告别卡顿与过热 【免费下载链接】g-helper Lightweight, open-source control tool for ASUS laptops and ROG Ally. Manage performance modes, fans, GPU, battery, and RGB lighting across Zephyrus, Flow, TUF, Strix, Scar, and…...

全球工业不间断电源行业市场规模与增长预测
工业不间断电源(简称工业UPS),专为严苛工业环境而设计,在复杂工业环境下为关键负荷提供高可靠性、高稳定性、强抗干扰能力的电力保护专。它的核心功能是在市电发生波动、短时断电或其他电力异常情况下,为关键设备提供持续、稳定的…...
)
vLLM运行XVERSE-13B-256K报错?可能是tokenizer版本不兼容(附降级解决方案)
解决vLLM运行XVERSE-13B-256K时的Tokenizer版本冲突问题 当你在Linux环境下使用vLLM框架加载XVERSE-13B-256K大模型时,可能会遇到一个令人困惑的错误:"data did not match any variant of untagged enum PyPreTokenizerTypeWrapper"。这个错误…...
)
C++游戏开发实战:从零构建局域网联机对战系统(附完整代码解析)
1. 为什么选择C开发局域网联机游戏? 用C做游戏联机功能就像给汽车装涡轮增压——虽然需要点技术含量,但跑起来是真的爽。我十年前第一次用C写联机坦克大战时,看着两台电脑上的坦克同步开火,那种成就感至今难忘。 性能优势是首要原…...

Qwen3-VL-8B-Instruct-GGUF效果展示:医疗报告图识别、工业零件缺陷描述、手写公式解析
Qwen3-VL-8B-Instruct-GGUF效果展示:医疗报告图识别、工业零件缺陷描述、手写公式解析 想象一下,你手头有一张复杂的医疗影像报告,上面布满了各种图表和标注;或者你面前是一个需要质检的工业零件,得找出上面细微的划痕…...