好题分享(2023.11.5——2023.11.11)

目录
前情回顾:
前言:
题目一:补充《移除链表元素》
题目二:《反转链表》
解法一:三指针法
解法二:头插法
题目三: 《相交链表》
题目四:《合并两个有序数列》
题目五:《链表中倒数第K个节点》
题目六:《链表的分割》
题目七:《链表的回文结构》
题目八:《环形链表(一)》
题目九:《环形链表(二)》
由题目八引出结论:
对于第九题的算法:
总结:
题目十:《随机链表的复制》
1.先拷贝各个节点,再连接起来
2.对random进行赋值
3.断开连接
总结:
前情回顾:
我们在上一篇好题分析中,分析了以下几题:
《合并两个有序数组》《移除链表元素》《链表的中间节点》
上一篇的好题分析的blog在
好题分析(2023.10.29——2023.11.04)-CSDN博客
前言:
本次好题分享,我们将对《移除链表元素》进行一种算法即思路进行补充,因为在之后的题目,都是围绕此算法来实现的
同时,我们还将对Leecode和牛客网上的众多题目进行分析:
《反转链表》《相交链表》《环形链表(一)》《环形链表(二)》《随机链表的复制》《合并两个有序链表》
《链表中倒数第K个节点》《链表分割》《链表的回文结构》
题目一:补充《移除链表元素》
力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台

我们在上一篇blog中,我们是利用三个指针来进行操作,在删除节点前,保存该节点前后的节点,再进行修改指向的操作,此算法的不足之处,就在于如果我们要删除的元素位于头结点,那么这个时候就要考虑另外一种情况了。
接下来的算法将可以省去上述步骤,且在之后的刷题中会更高效!
/*** Definition for singly-linked list.* struct ListNode {* int val;* struct ListNode *next;* };*///创建“新链表”
struct ListNode* removeElements(struct ListNode* head, int val) {struct ListNode* newhead = NULL,*cur = head,*tail = NULL;while(cur){//不是val节点的拿下来尾插if(cur->val != val){//尾插if(tail==NULL){newhead = tail =cur;}else{tail->next = cur;tail = tail->next;}cur = cur->next;}else{cur =cur->next;}}if(tail){tail->next = NULL;}return newhead;
}该算法是先创建一个新链表,将需要的节点连接到新链表中,再返回新创建的指针。

刚开始由于newnode指向的是NULL,即该链表为空,所以我们需要进行尾插操作,同时tail也指向新链表的第一个节点。
即:
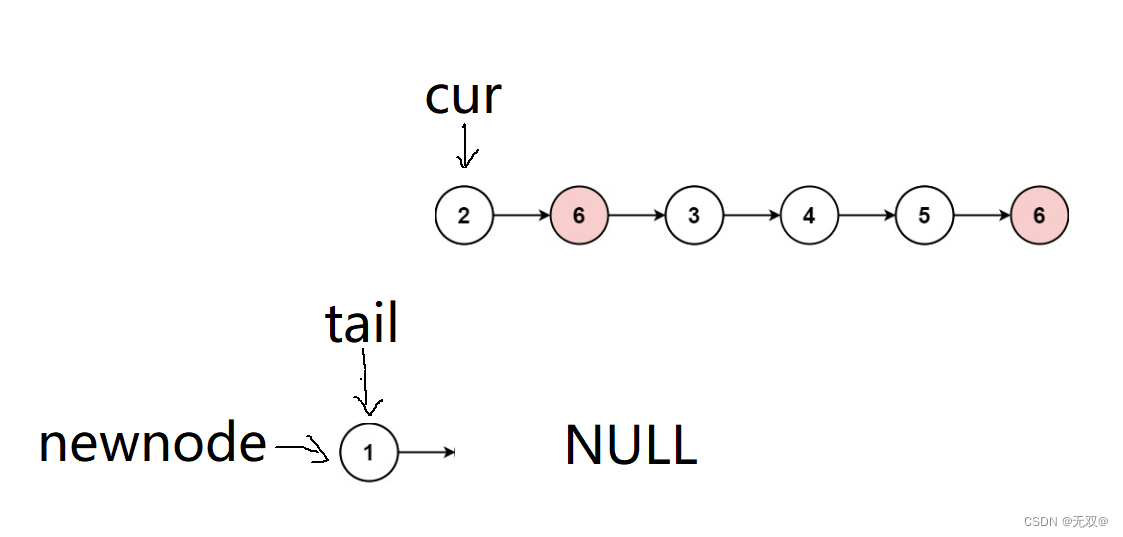
但是要注意的是,此时我们newnode中的头结点,它的next是指向原链表中所在位置的下一个节点的,并非指向NULL,即:

你可能会觉得代码中该部分是多余的
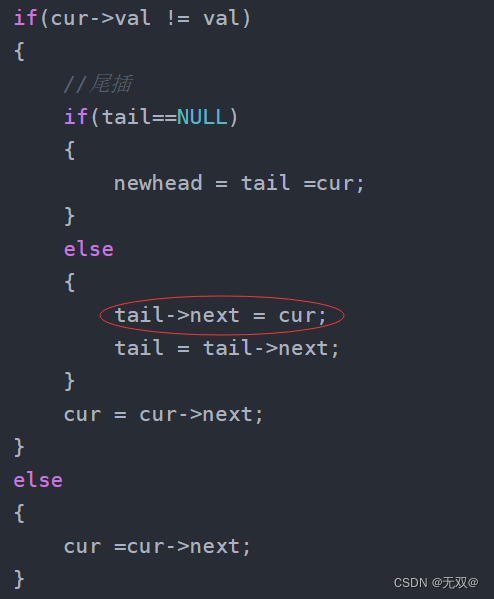
但是这一步缺失这种算法的关键。
如果我们这时候的cur指向了题目描述中的val,此时cur就会跳过该节点。
并指向下一个节点,那么如果没有tail->next = cur;这一行代码
那么新链表中的tail将直接指向题目描述中的val。
所以我们必须加上此代码!!! 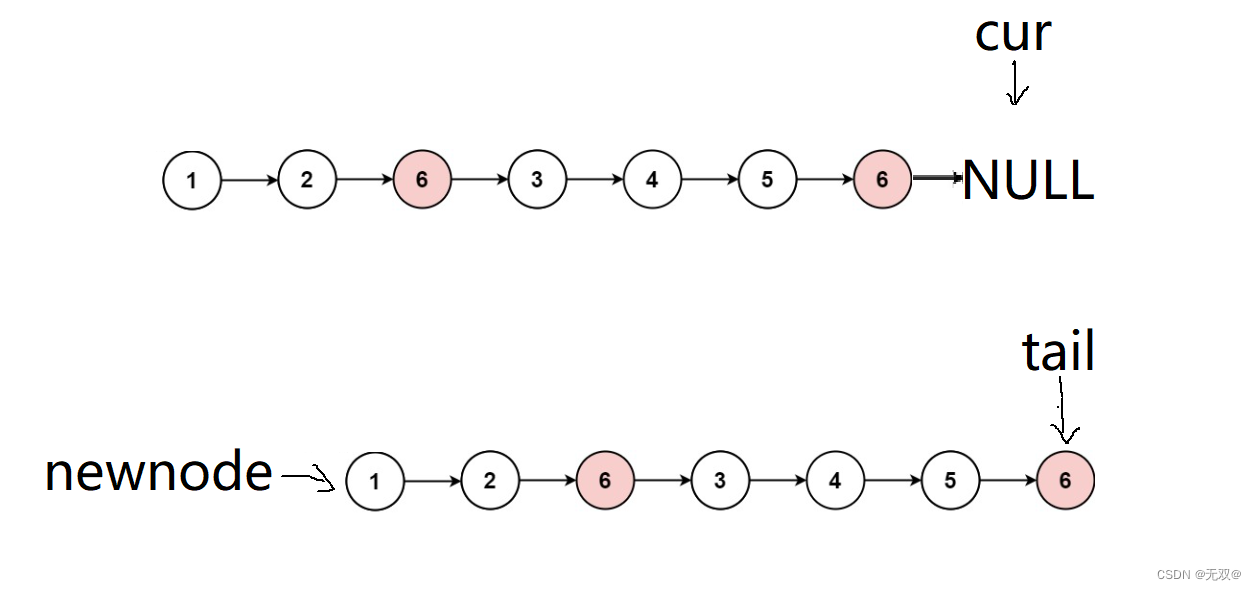
当遇到此时的情况时,如果我们直接放回newnode,就会是一个不完整的链表,因为尾结点并没有指向NULL,所有我们务必要在最后加上一句:tail->next = NULL;
这种创建新链表的思想需要我们去学习,在之后的题目中尤为重要!
题目二:《反转链表》
力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台

对于本题目我将给出两种算法,为了展示出创建新链表该种算法的优势。
解法一:三指针法
如果我们尝试常规解法来实现,那我们我们就务必需要保存前后节点的位置。
所以该算法实现:
/*** Definition for singly-linked list.* struct ListNode {* int val;* struct ListNode *next;* };*///三指针法
struct ListNode* reverseList(struct ListNode* head) {if(head==NULL){return NULL;}struct ListNode* n1 = NULL,*n2 = head,*n3 = head->next;if(n3 == NULL){return n2;}while(n2 != NULL){n2->next = n1;n1 = n2;n2 = n3;if(n3)n3 = n3->next;}return n1;
}

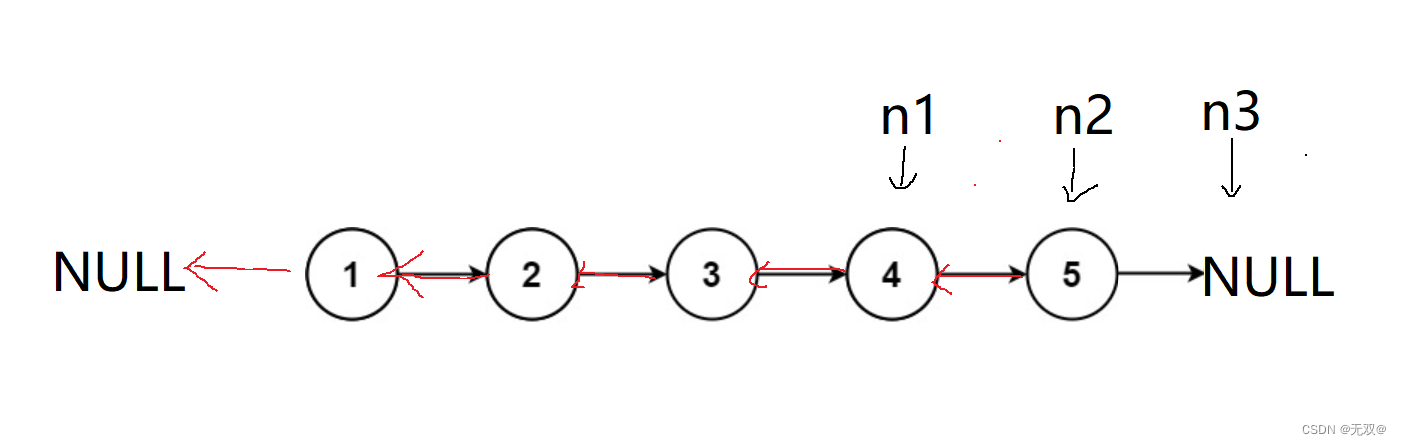

这道题还要注意,如果链表只要一个节点或者无节点时的返回值!
解法二:头插法
/*** Definition for singly-linked list.* struct ListNode {* int val;* struct ListNode *next;* };*///头插法
struct ListNode* reverseList(struct ListNode* head) {if(head == NULL){return NULL;}struct ListNode* newnode = NULL;struct ListNode* cur = head;struct ListNode* next = head->next;while(next){cur->next = newnode;newnode = cur;cur = next;next = next->next;}cur -> next = newnode;newnode = cur;return newnode; } 
反转的本质,就是在新链表中头插 。
那么我们就可以将cur->next指向newnode;
newnode再指向此时的cur,这就完成了头插操作
再将cur = next,
next = next -> next;
因为我们改变来cur->next的指向,所以我们对于保存cur下一个节点的位置就尤为重要!


完成操作后,我们最好可以将head = NULL,避免出现野指针。
题目三: 《相交链表》
力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台
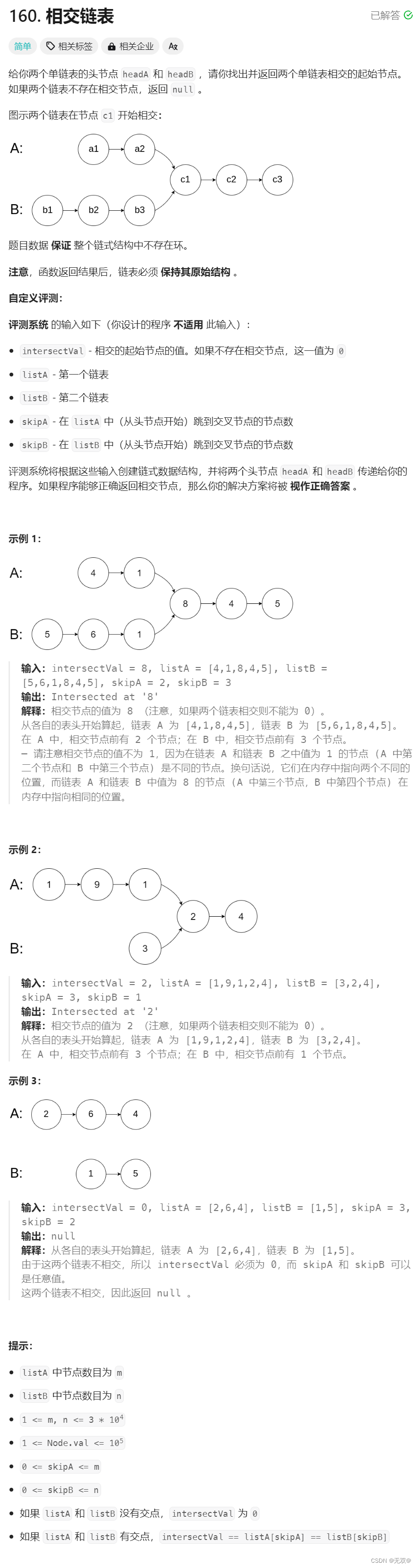
/*** Definition for singly-linked list.* struct ListNode {* int val;* struct ListNode *next;* };*/struct ListNode *getIntersectionNode(struct ListNode *headA, struct ListNode *headB) {struct ListNode* curA = headA, *curB = headB;int countA = 0;int countB = 0;//判断是否相交while(curA->next){curA = curA->next;countA++;} while(curB->next){curB = curB->next;countB++;} if(curA != curB){return NULL;}//找出相交的起始节点int n = abs(countA - countB);if(countA > countB){while(n){headA = headA->next;--n;}while(headA != headB){headA = headA->next;headB = headB->next;}return headA;}else{while(n){headB = headB->next;--n;}while(headA != headB){headA = headA->next;headB = headB->next;}return headB;}}对于该题目,我们提供一种算法:
1.先判断它们是否相交。
2.找到第一个公共节点。
相交好判断
我们可以先遍历,找到它们最后一个节点,如果节点相同,就说明它们相交!
因为相交链表只能是“Y”型相交,而绝对不可能是“X”型的 !
那么对于第二步,
我们可以先求出两个链表分别有多长,再相减求绝对值,得出相差步。
再使得短的链表的curA先走相差步,这样两个指针就是从同一位置起步了
再一起同时走一步,直到它们相等,如果这时两指针相等,则就说明相等的节点就是第一个公共节点!

让curB走向差步:
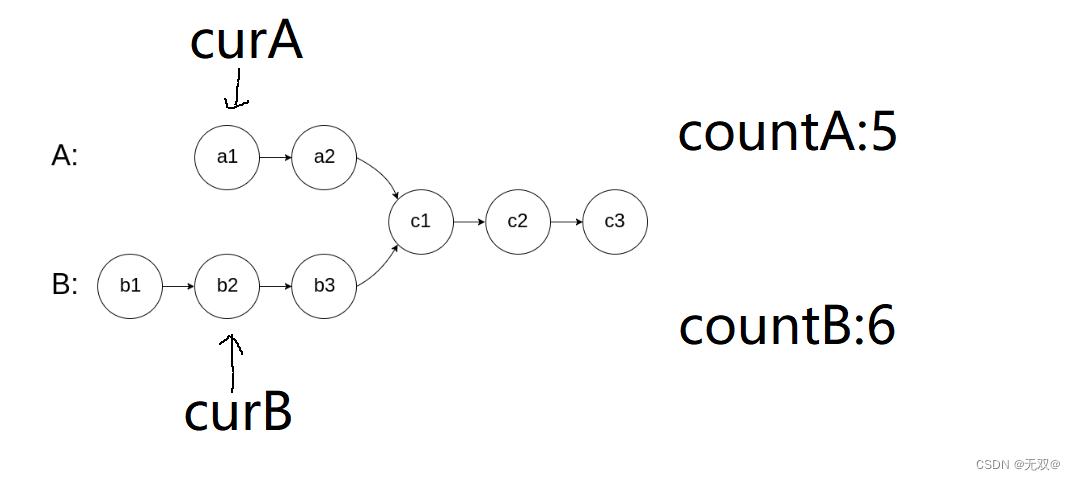
在同时走一步:

如此就可以得到公共节点!
题目四:《合并两个有序数列》
力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台

/*** Definition for singly-linked list.* struct ListNode {* int val;* struct ListNode *next;* };*/
struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2)
{struct ListNode* cur1 = list1,*cur2 = list2;struct ListNode* newnode = (struct ListNode*)malloc(sizeof(struct ListNode));newnode->next = NULL;struct ListNode* next = NULL;struct ListNode* tail = newnode;while(cur1 && cur2){if((cur1->val <= cur2->val)){next = cur1->next;tail->next = cur1;cur1 = next;tail = tail->next;}else{next = cur2->next;tail->next = cur2;cur2 = next;tail = tail->next;}}if(cur1==NULL){tail->next = cur2;}else{tail->next = cur1;}return newnode->next;
}对于该题目,我建议使用新链表法,同时我们最好创建一个哨兵位的头结点。
具体为什么我这里建议使用新链表法,想要反驳的同学下去可以自己动手创建一个无哨兵位的解法,相信你一定会被绕晕的。
鉴于我们已经学会了前面两道题目的算法,这道题相信大家一定很好理解!
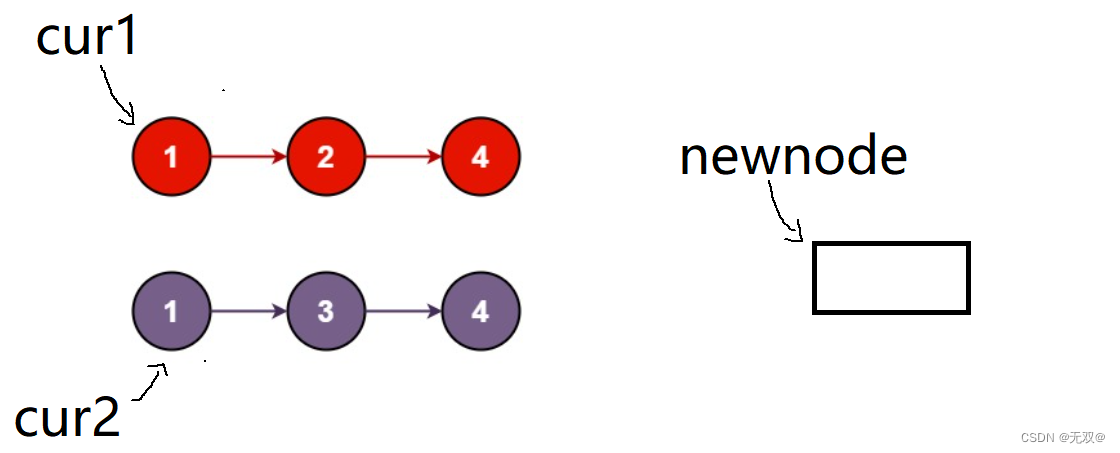



如此循环,当cur1或者cur2为NULL时,则直接让tail->next指向cur1或cur2.
即:

题目五:《链表中倒数第K个节点》
链表中倒数第k个结点_牛客题霸_牛客网

/*** struct ListNode {* int val;* struct ListNode *next;* };*//*** * @param pListHead ListNode类 * @param k int整型 * @return ListNode类*/
struct ListNode* FindKthToTail(struct ListNode* pListHead, int k ) {// write code hereif(pListHead == NULL){return NULL;}int count = 0;struct ListNode* tmp = pListHead;while(tmp){count++;tmp = tmp->next;}int n = count - k;if(n<=0 && k > count){return NULL;}while(n--){pListHead = pListHead->next;}return pListHead;}该题目的算法实现还是好理解
我们先统计该链表存在多少个节点。
然后再减去所谓的倒数第K个。
就可以得到正数第几个n,
再将pListHead进行遍历,同时n--
再返回此时的pListHead
思路还是好理解的,在这里我就不进行画图展示了。
题目六:《链表的分割》
链表分割_牛客题霸_牛客网

/*
struct ListNode {int val;struct ListNode *next;ListNode(int x) : val(x), next(NULL) {}
};*/
#include <cstddef>
class Partition {
public:ListNode* partition(ListNode* pHead, int x){// write code herestruct ListNode* head1,*tail1,*head2,*tail2;head1 = tail1 = (struct ListNode*)malloc(sizeof(struct ListNode));head2 = tail2 = (struct ListNode*)malloc(sizeof(struct ListNode));struct ListNode* cur = pHead;while(cur){if(cur->val<x){tail1->next = cur;tail1 = tail1->next;}else {tail2->next = cur;tail2 = tail2->next;}cur= cur->next;}tail1->next = head2->next;//防止成环tail2->next = NULL;pHead = head1->next;free(head1);free(head2);return pHead;}
};对于该题目的算法思路,要注意的有以下几点:
1.我们在此选择开辟两个哨兵位的头节点创建链表,小于等于x的到第一个链表,大于x的到第二个链表。
2.再将小链表的最后一个节点的next,链接到第二个哨兵位头节点的next。
3.同时还要注意成环问题!


如此一直循环:
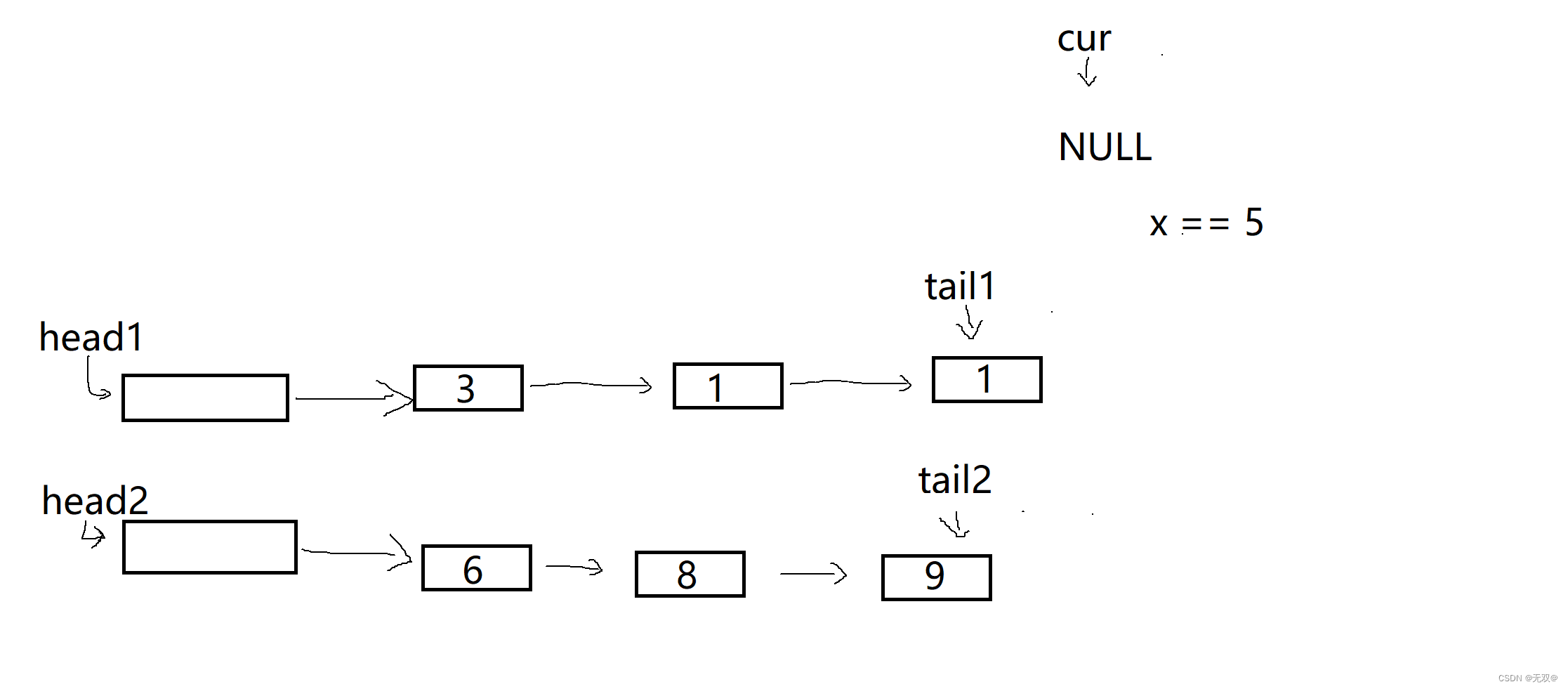
到这里时我们就可以直接将tail1->next = head2->next;
即:

此时一定不要忘记将tail2->next = NULL;
因为此时的tail2->next是指向的tail1指向的节点的
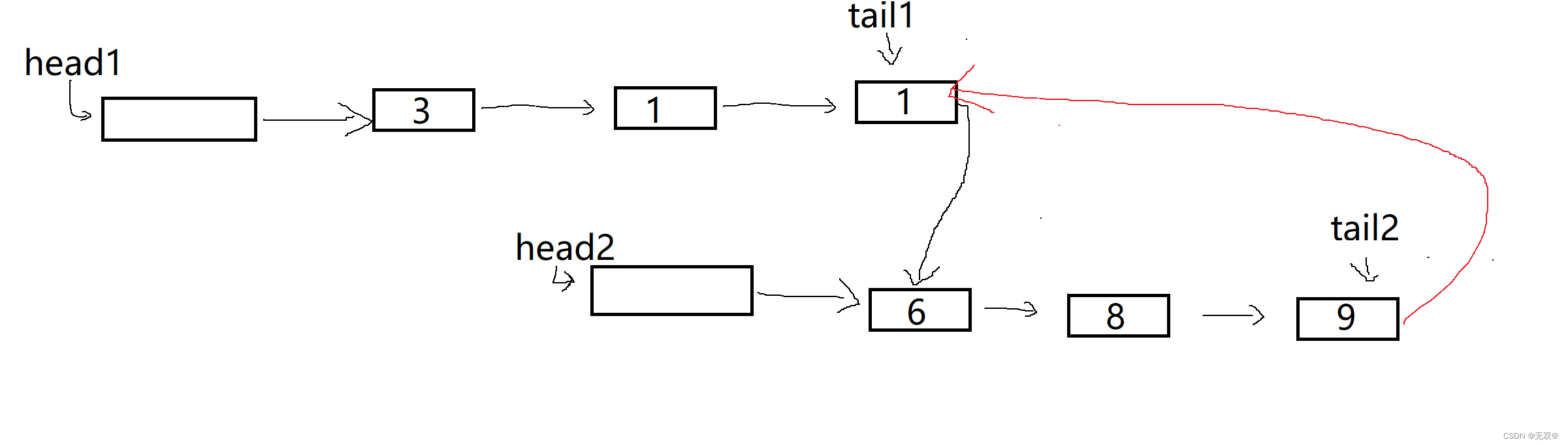
如果这里不注意的话,就会形成一个环!!!

如此才是正确的全部思路。
题目七:《链表的回文结构》
链表的回文结构_牛客题霸_牛客网
/*
struct ListNode {int val;struct ListNode *next;ListNode(int x) : val(x), next(NULL) {}
};*/
class PalindromeList {
public:bool chkPalindrome(ListNode* A) {// write code here//找中间节点ListNode* fast = A;ListNode* slow = A;while(fast && fast->next){fast = fast->next->next;slow = slow->next;}//逆序ListNode* next = slow ->next;ListNode* rehead = slow;rehead->next = NULL;while(next){slow = next;next = slow->next;slow->next = rehead;rehead = slow;}while(A && rehead){if(A->val == rehead->val){A = A->next;rehead = rehead->next;}else{return false;}}return true;}
};由于牛客网对于本题目只要C++一种格式,但是没关系,C++兼容C语言。
所有我们就按照我们的写法即可:

第一步,利用快慢指针找到中间节点!
即:

此时的该节点就为中间节点。
再逆序中间节点后面的全部节点
利用新链表法!
先创建个指针rehead

在创建的时候,提前将slow指向的节点拿下来,进行置空操作,即:

再进行一个经典的头插操作即while循环里面的全部操作:

如此就可以进行全部逆序的操作,则此时的图为:
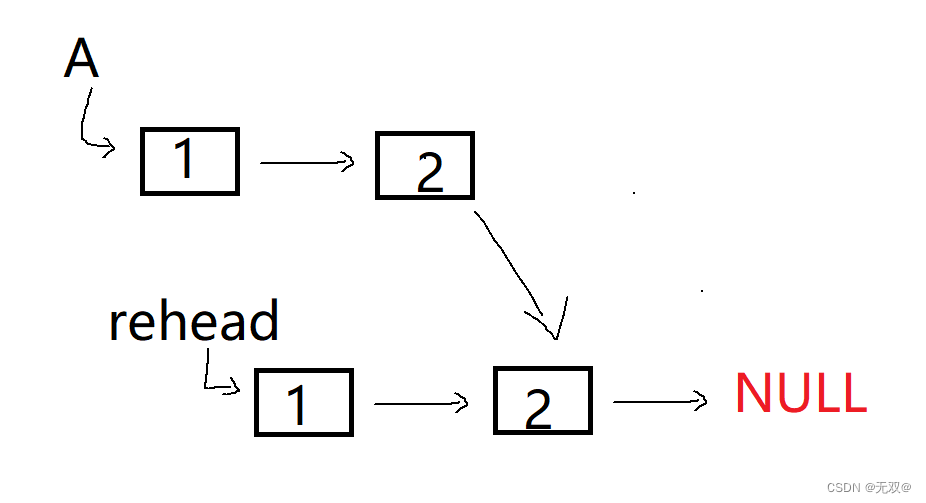
我们只需要分别将A和rehead每次挪动一步,再判断是否为相等即可。
如果一直相等直到循环结束,就return true
如果出现不想等的,直接return false
题目八:《环形链表(一)》
力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台
/*** Definition for singly-linked list.* struct ListNode {* int val;* struct ListNode *next;* };*/
bool hasCycle(struct ListNode *head) {struct ListNode* fast,*slow;fast = slow = head;while(fast && fast->next){fast = fast->next->next;slow = slow->next;if(fast == slow){return true;}}return false;
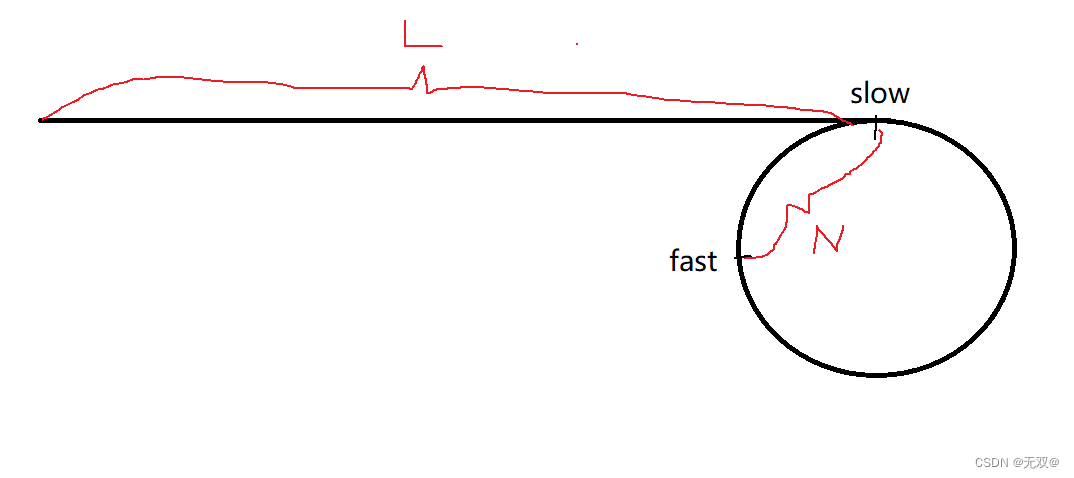
}对于一个带环链表,我们遇到该种题目应当先考虑考虑快慢指针算法。
如图:

fast一次走两步,slow一次走一步,当它们相遇的时候,一定是在圆环内!
例:

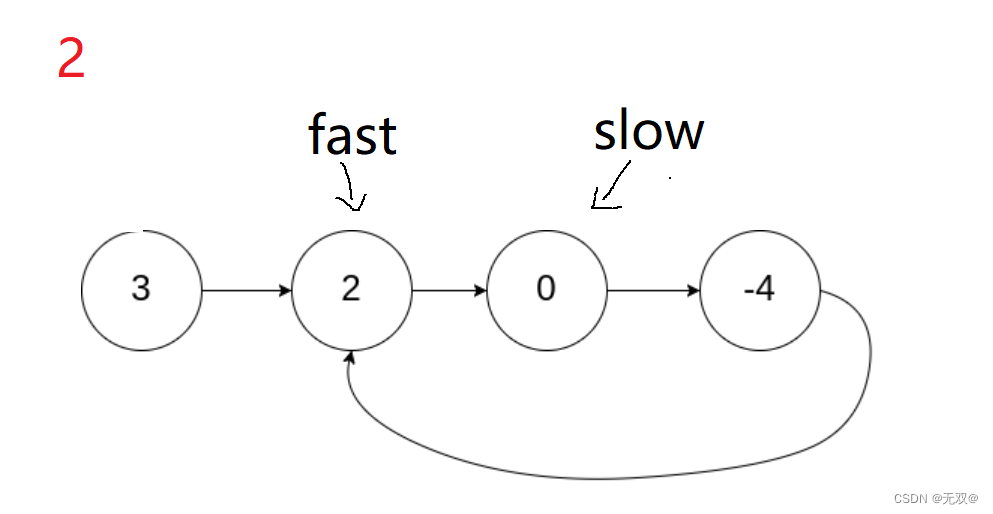

从上述可以看出,再进行第三次循环的时候,fast和slow就相遇,就说明此时的链表是带环链表。
题目九:《环形链表(二)》
力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台
/*** Definition for singly-linked list.* struct ListNode {* int val;* struct ListNode *next;* };*/
struct ListNode *detectCycle(struct ListNode *head) {struct ListNode* fast = head, *slow = head;struct ListNode* meet = NULL;while(fast && fast->next){fast = fast->next->next;slow = slow->next;if(fast == slow){meet = slow;while(head != meet){head = head->next;meet = meet->next;}return head;}}return NULL;
}这道题与上题类似,但区别在于现在已经告诉你这是一个环形链表,需要你求出进入环的第一个节点。
对于解决该问题的方法,此方法偏向于数学思维思路。
我们由图来分析。
由题目八引出结论:
我们在题目八中分析过,如果我们利用快慢指针,就可以求出它们是否再圆环内。
但是当快指针一次走三步呢?
那么还可以追上吗?
这就不得不利用数学思维来解决此问题。

我们可以将链表抽象为如图内容。
那么当fast一次三步时,怎么判断它们是否相遇:

当slow刚进入环内时,fast肯定比slow快3倍,走过的距离肯定也多三倍。
但是一旦它们都在环内时,距离就会一直-2.
假设一开始的距离为n
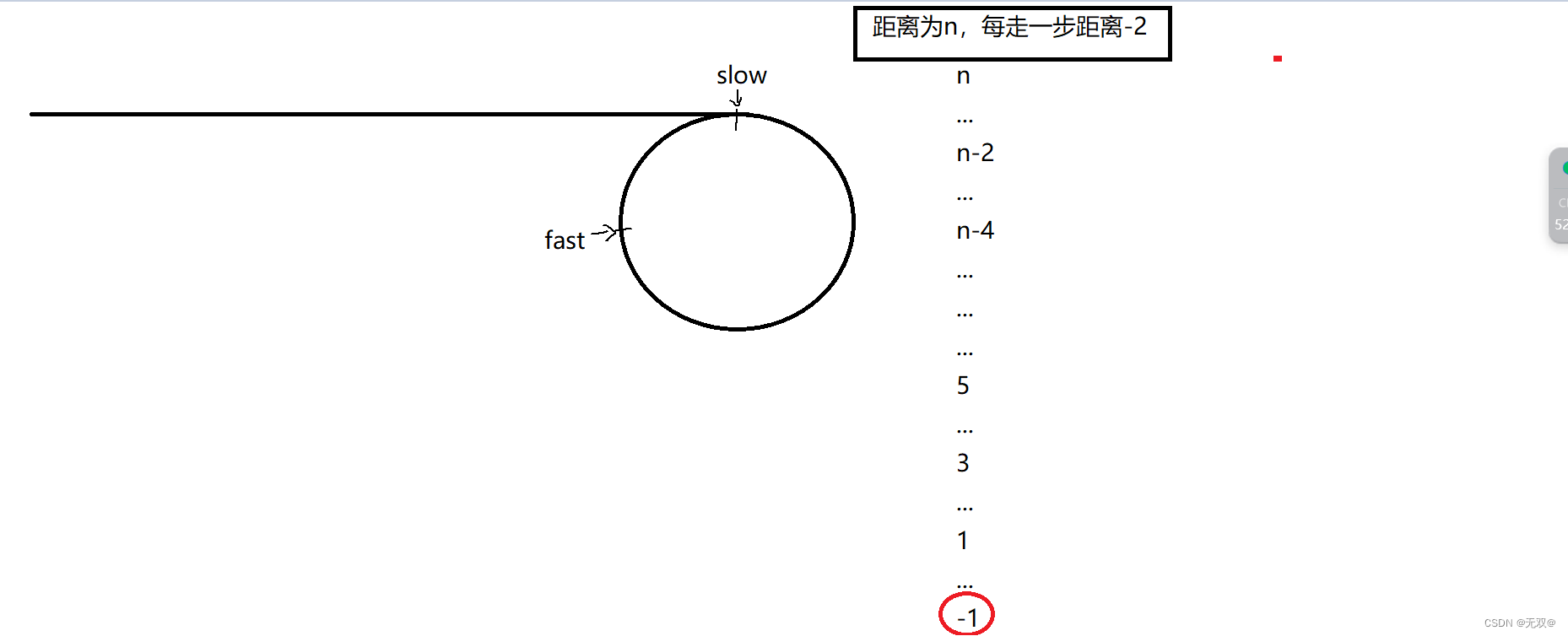
此时的-1就代表了它们的距离相差1,意思就是:
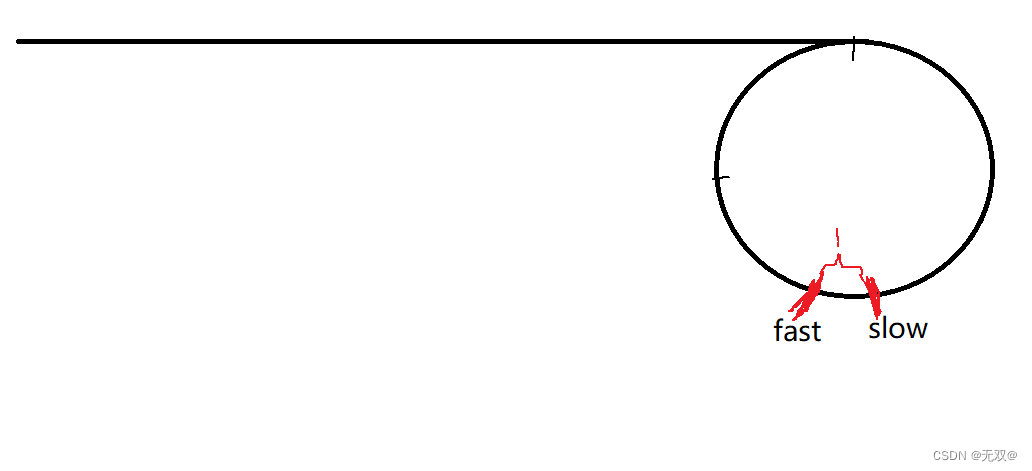
那么就不难的出以下结论:
假设C为圆的周长,此时它们距离就是C-1。
如果C-1为偶数,那么随着它们-2的操作,最后会相遇。
但如果C-1是奇数,那么随着它们-2的操作,最后还需要再来一圈才可以相遇!
即:
1.若n为偶数,直接就可以追上
2.若n是奇数,C是奇数,得过两圈才能追上。
3.如果n是奇数,C是偶数,永远都追不上。
但是第3条是不成立的,因为我们可以得出公式:
L为直线长
N是两指针在刚开始的距离,
3L = L +n*C - N
即2L = n*C - N
等号左边百分百为偶数,
而右边永远等于奇数。
所以它们不相等,即该结论永远不成立!
对于第九题的算法:
而对于该题目,我们只需要知道此时的fast只走一步,而它们绝对可以在圆环内相遇:
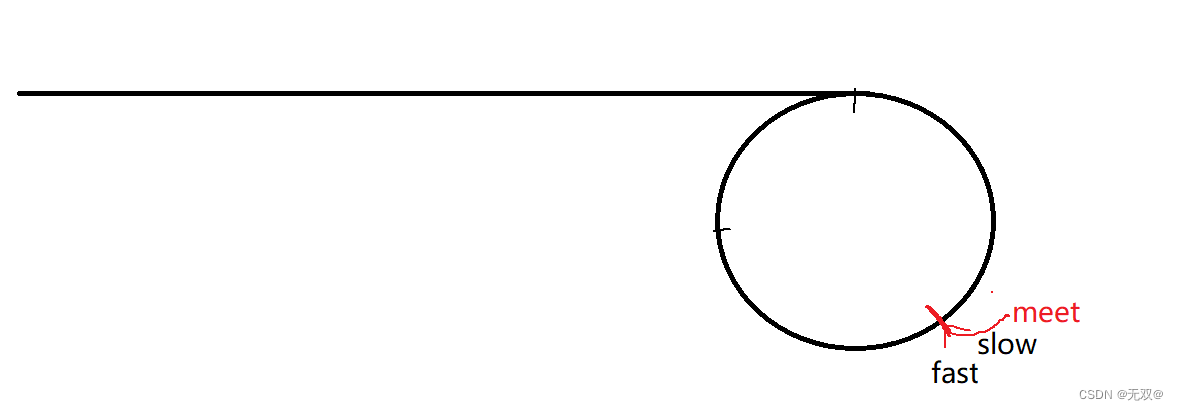
我们在它们相遇的地方创建个指针,指向该地方,后面我们就会用到此指针:

我们在创建个未知数X,代表第一个环节点到相遇点,
通过该图,我们可以知道,slow走过的路程 = fast的路程/2
所以就有2(L+X) = L + X + n*C
假设这个环足够小,那么我的fast很有可能在圆环内走很多圈,但我们假设就走过一圈。
则就有以下算式:
2(L+X) =L + X + C
L = C - X
通过以上的推导:
我们知道了以下:

L== Y
那我们就可以让meet和head同时走一步,直到它们相遇,因为相遇的地方就是圆环的第一个节点。
这样就可以求出来第一个节点了!
总结:
本题目设计到的数学思维和思路会使很多同学绕不清楚,还有转不过弯来。
对于这部分的解法下来需要好好熟练掌握并学习学习,在这里我就不再多讲了。
题目十:《随机链表的复制》
力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台

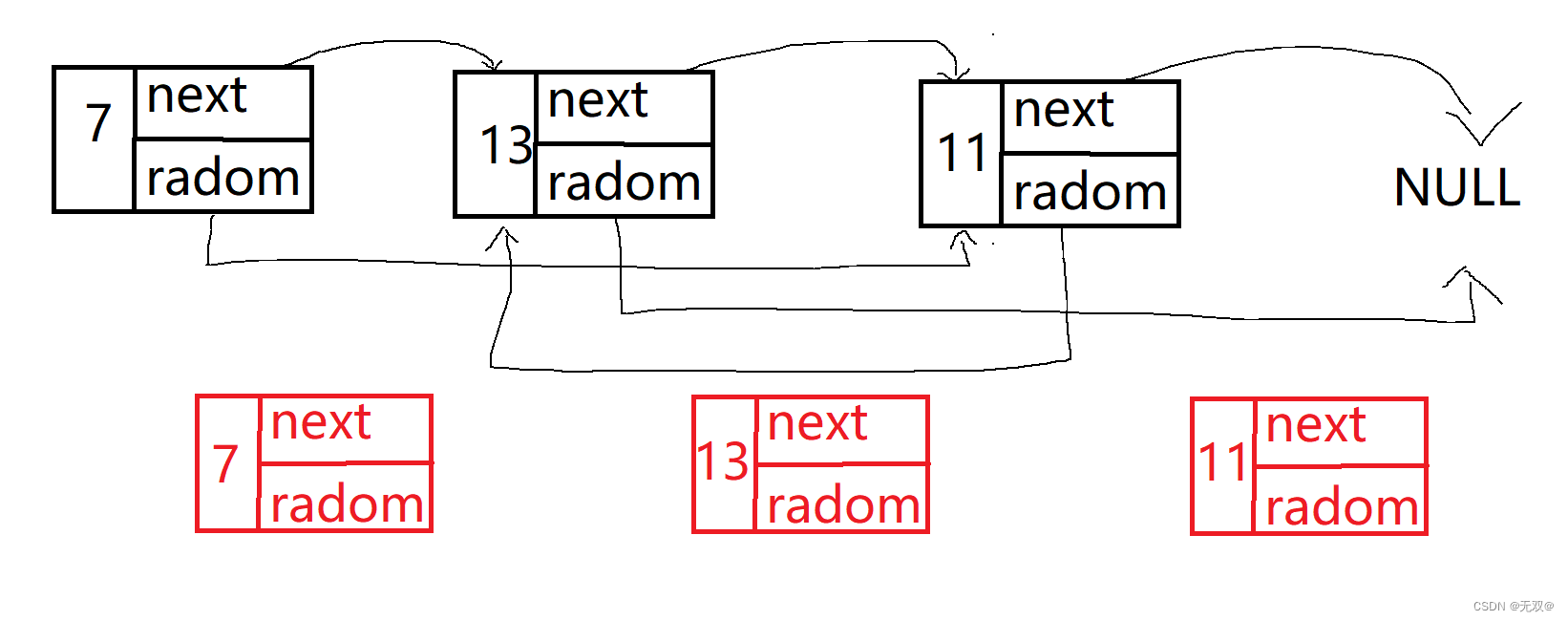
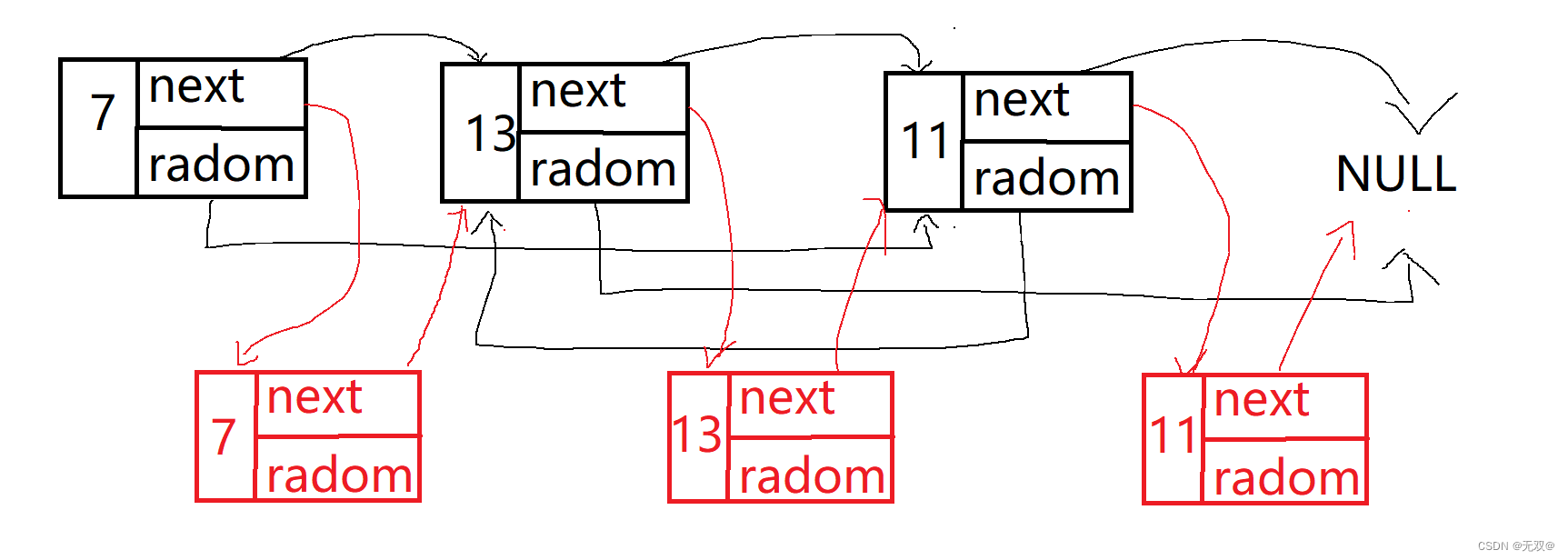
/*** Definition for a Node.* struct Node {* int val;* struct Node *next;* struct Node *random;* };*/struct Node* copyRandomList(struct Node* head) {if (head == NULL) {return NULL;}struct Node* cur = head;struct Node* copy = NULL;while(cur){copy = (struct Node*)malloc(sizeof(struct Node));copy->val = cur->val;copy->next = cur->next;cur->next = copy;cur = cur->next->next;}copy = head->next;struct Node* tmp = NULL;cur = head;while(cur){tmp = cur->next;tmp->random = (cur->random != NULL)?cur->random->next : NULL;cur = cur->next->next;}tmp = copy;while(tmp->next != NULL){tmp->next = tmp->next->next;tmp = tmp->next;}return copy;
}本道题目较难,我在这里先讲解以下思路:
1.先拷贝各个节点,再连接起来
2.对random进行赋值
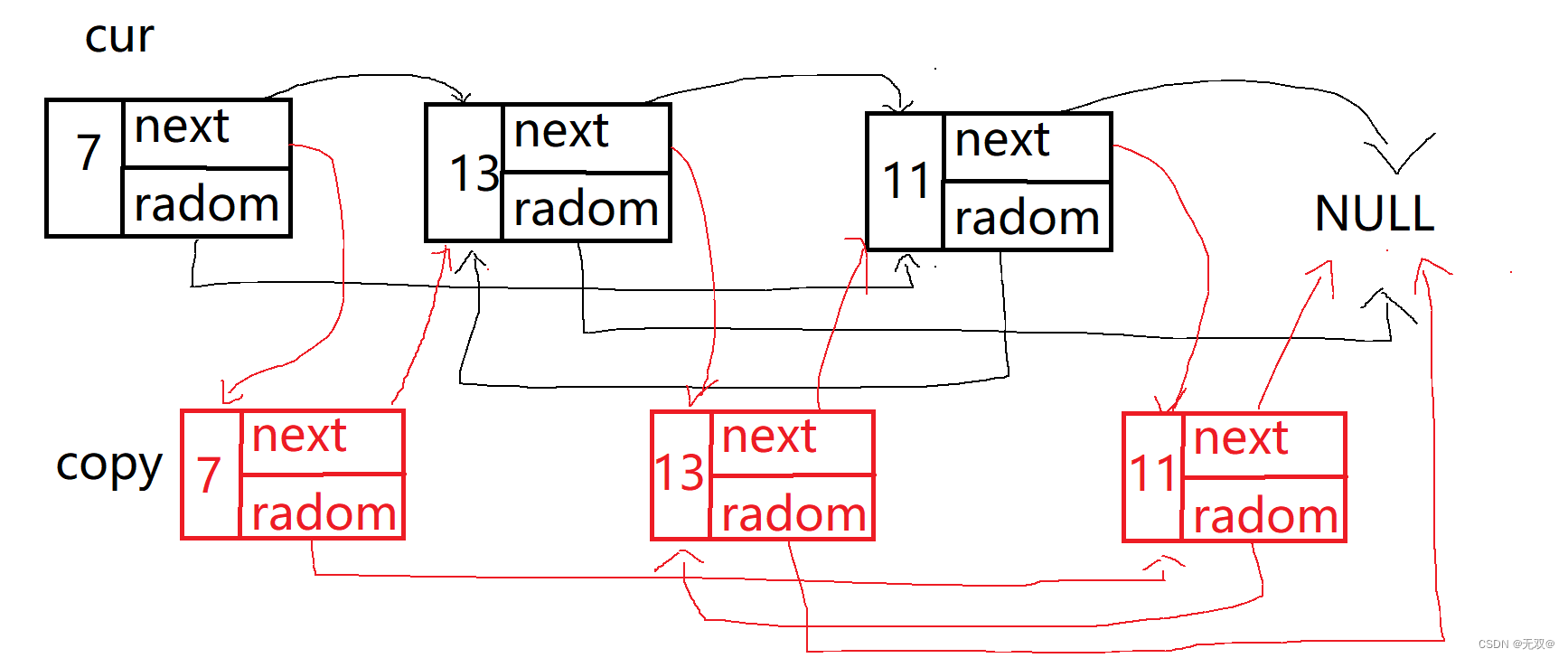
这里格外要注意,如果此时原radom是NULL,就要另外讨论。
如果不为空,则将cur->radom->next赋给copy
这一句代码则是精华所在!
3.断开连接
将拷贝好的各个节点互相链接,并且返回。
总结:
本周的好题分享设计到的知识面较广,我们在做题过程中难免会遇到一些难以实现的操作,但是只要我们沉下心来一点点的了解和学习,相信一定会有进步!
记住“坐而言不如起而行!”
Action speak louder than words!
相关文章:
好题分享(2023.11.5——2023.11.11)
目录 前情回顾: 前言: 题目一:补充《移除链表元素》 题目二:《反转链表》 解法一:三指针法 解法二:头插法 题目三: 《相交链表》 题目四:《合并两个有序数列》 题目五&…...
第二章 03Java基础-IDEA相关叙述
文章目录 前言一、IDEA概述二、IDEA下载和安装三、IDEA项目结构介绍四、IDEA的项目和模块操作总结前言 今天我们学习Java基础,IDEA下载以及相关配置和基础使用方法 一、IDEA概述 1.IDEA全称IntelliJ IDEA,是用于Java语言开发的集成工具,是业界公认的目前用于Java程序开发最…...
第三阶段第二章——Python高阶技巧
时间过得很快,这么快就来到了最后一篇Python基础的学习了。话不多说直接进入这最后的学习环节吧!!! 期待有一天 春风得意马蹄疾,一日看尽长安花 o(* ̄︶ ̄*)o 1.闭包 什么是闭包? 答…...

【Git】Git分支与应用分支Git标签与应用标签
一,Git分支 1.1 理解Git分支 在 Git 中,分支是指一个独立的代码线,并且可以在这个分支上添加、修改和删除文件,同时作为另一个独立的代码线存在。一个仓库可以有多个分支,不同的分支可以独立开发不同的功能࿰…...
本地PHP搭建简单Imagewheel私人云图床,在外远程访问——“cpolar内网穿透”
文章目录 1.前言2. Imagewheel网站搭建2.1. Imagewheel下载和安装2.2. Imagewheel网页测试2.3.cpolar的安装和注册 3.本地网页发布3.1.Cpolar临时数据隧道3.2.Cpolar稳定隧道(云端设置)3.3.Cpolar稳定隧道(本地设置) 4.公网访问测…...
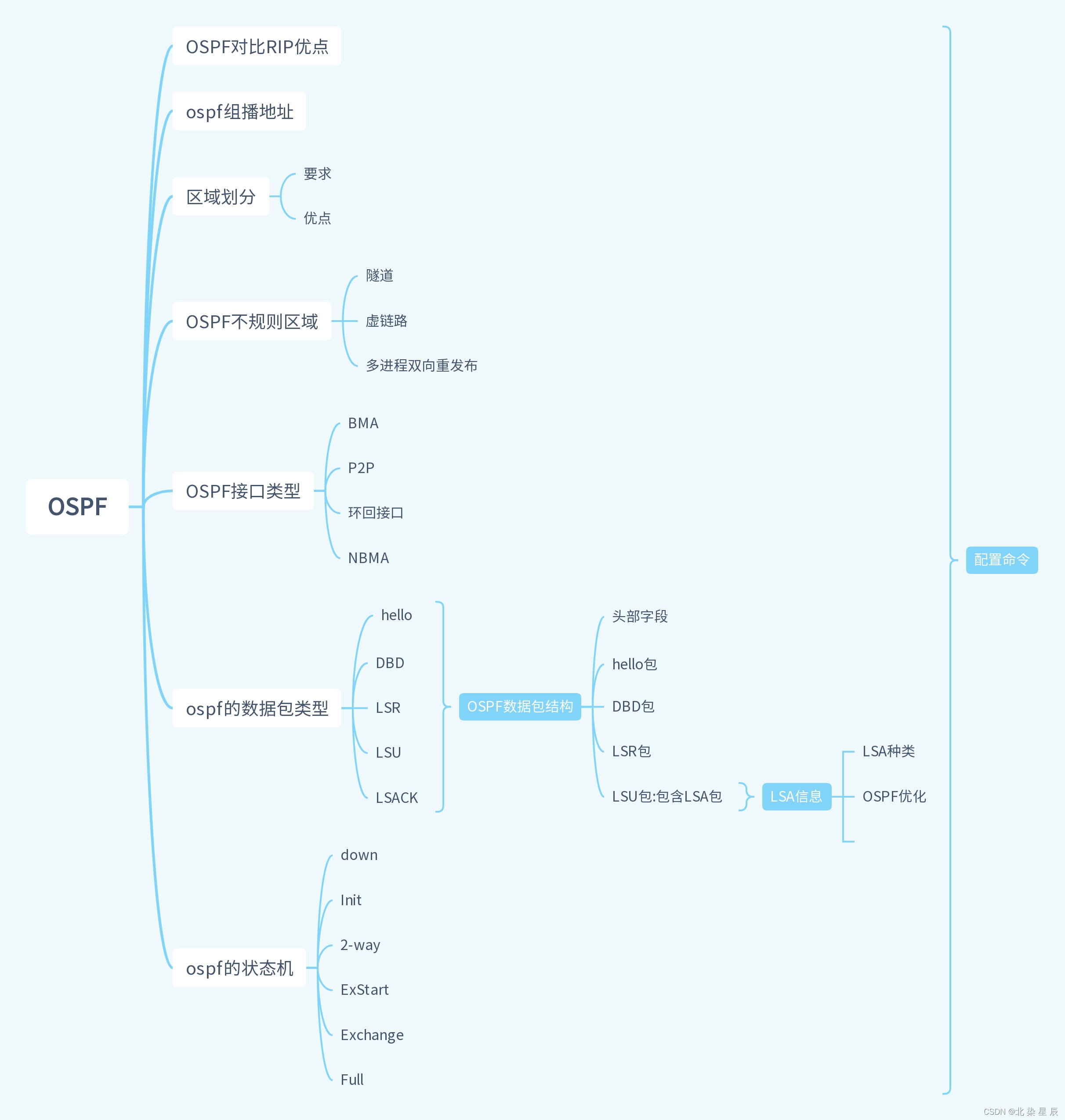
HCIP---OSPF思维导图
...
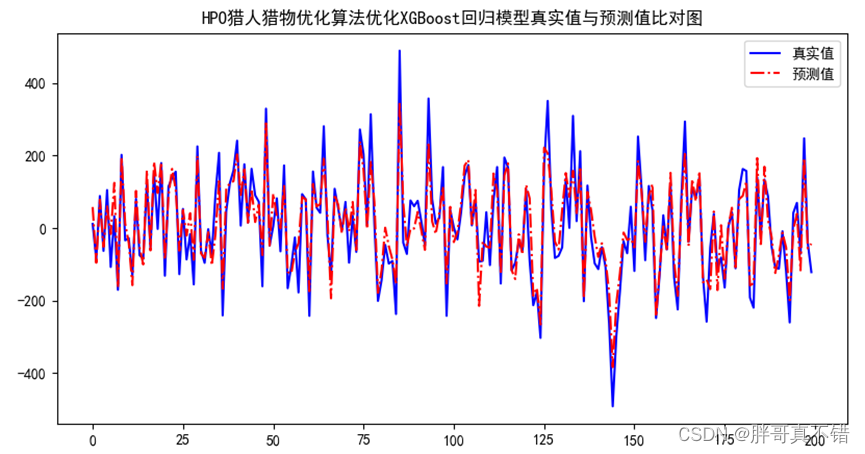
Python实现猎人猎物优化算法(HPO)优化XGBoost回归模型(XGBRegressor算法)项目实战
说明:这是一个机器学习实战项目(附带数据代码文档视频讲解),如需数据代码文档视频讲解可以直接到文章最后获取。 1.项目背景 猎人猎物优化搜索算法(Hunter–prey optimizer, HPO)是由Naruei& Keynia于2022年提出的一种最新的…...

pandas读写json的知识点
pandas对象可以直接转换为json,使用to_json即可。里面的orient参数很重要,可选值为columns,index,records,values,split,table A B C x 1 4 7 y 2 5 8 z 3 6 9 In [236]: dfjo.to_json(orient"columns") Out[236]: {"A":{"x&qu…...

图论——Dijkstra算法matlab代码
Dijkstra算法步骤 (1)构造邻接矩阵 (2)定义起始点 (3)运行代码 M[ 0 5 9 Inf Inf Inf InfInf 0 Inf Inf 12 Inf InfInf 3 0 15 Inf 23 InfInf 6 …...
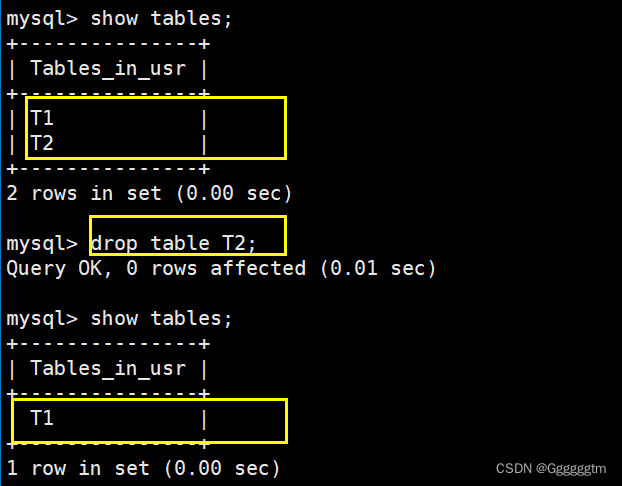
[MySQL] MySQL表的基础操作
文章目录 一、创建表 1、1 SQL语法 1、2 实例演示 二、查询表 三、修改表 3、1 修改表名字 3、2 新增列(字段) 3、3 修改列类型 3、4 修改列名 3、5 删除表 四、总结 🙋♂️ 作者:Ggggggtm 🙋♂️ 👀 专…...

SQL 部分解释。
这段SQL代码的主要作用是从V_order_L表中查询数据,并与V_AATB1DU_F52_M表进行左连接。查询的结果会按照订单时间(orderTime)、POS代码(posCode)和区间名称(f.DName)进行分组。 具体来说…...
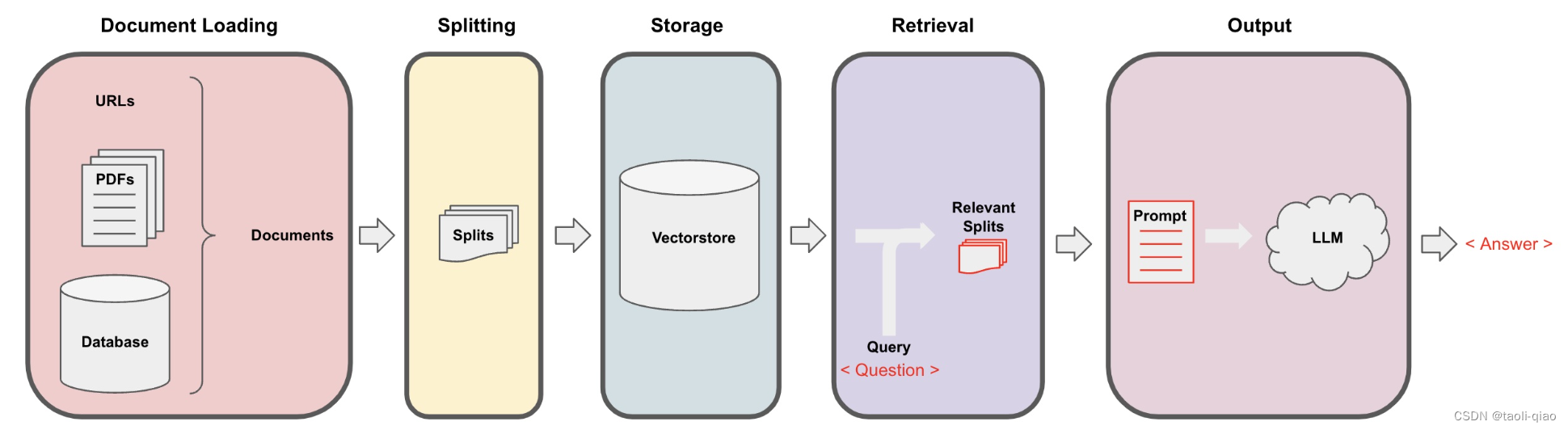
利用LangChain实现RAG
检索增强生成(Retrieval-Augmented Generation, RAG)结合了搜寻检索生成能力和自然语言处理架构,透过这个架构,模型可以从外部知识库搜寻相关信息,然后使用这些信息来生成response。要完成检索增强生成主要包含四个步骤…...

零基础学习Matlab,适合入门级新手,了解Matlab
一、认识Matlab Matlab安装请参见博客 安装步骤 1.界面 2.清空环境变量及命令 (1)clear all :清除Workspace中的所有变量 (2)clc:清除Command Window中的所有命令 二、Matlab基础 1.变量命名规则 &a…...

CCF ChinaSoft 2023 论坛巡礼 | 自动驾驶仿真测试论坛
2023年CCF中国软件大会(CCF ChinaSoft 2023)由CCF主办,CCF系统软件专委会、形式化方法专委会、软件工程专委会以及复旦大学联合承办,将于2023年12月1-3日在上海国际会议中心举行。 本次大会主题是“智能化软件创新推动数字经济与社…...

vue封装useWatch hook支持停止监听和重启监听功能
import { watch, reactive } from vue;export function useWatch(source, cb, options) {const state reactive({stop: null});function start() {state.stop watch(source, cb, options);}function stop() {state.stop();state.stop null;}// 返回一个对象,包含…...

智能配方颗粒管理系统解决方案,专业实现中医药产业数字化-亿发
“中药配方颗粒”,又被称为免煎中药,源自传统中药饮片,经过提取、分离、浓缩、干燥、制粒、包装等工艺加工而成。这种新型配方药物完整保留了原中药饮片的所有特性。既能满足医师的辨证论治和随症加减需求,同时具备强劲好人高效的…...
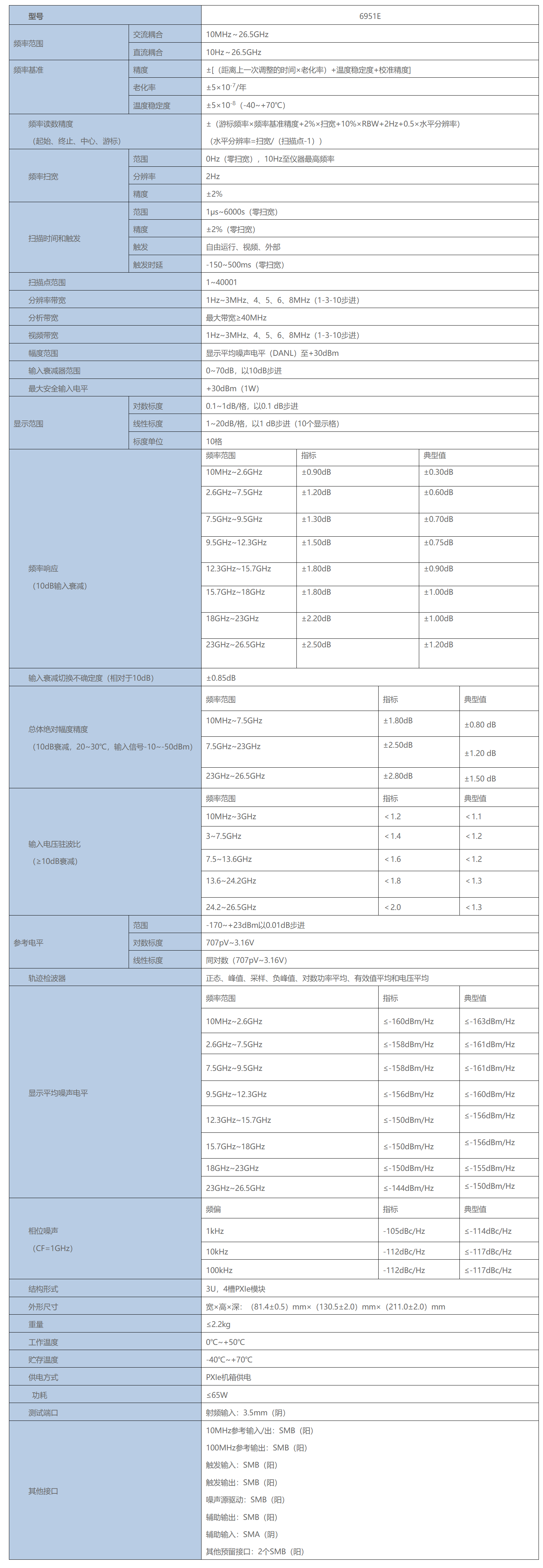
PXI总线测试模块-6951E 信号分析仪
6951E 信号分析仪 频率范围:10Hz~26.5GHz 6951E信号分析仪率范围覆盖10Hz~26.5GHz、带宽40MHz,具备频谱分析、相邻信道功率测试、模拟解调、噪声系数测试等多种测量功能。 6951E信号分析仪采用PXIe总线3U 4槽结构形式ÿ…...

精确杂草控制植物检测模型的改进推广
Improved generalization of a plant-detection model for precision weed control 摘要1、介绍2、结论摘要 植物检测模型缺乏普遍性是阻碍实现自主杂草控制系统的主要挑战之一。 本文研究了训练和测试数据集分布对植物检测模型泛化误差的影响,并使用增量训练来减小泛化误差。…...
C++:对象成员方法的使用
首先复习一下const : //const: //Complex* const pthis1 &ca; //约束指针自身 不能指向其他对象 // pthis1 &cb; err //pthis1->real; //const Complex* const pthis1 &ca;//指针指向 指针自身 都不能改 //pthis1->real; 只可读 …...
深入了解SpringMvc接收数据
目录 一、访问路径(RequestMapping) 1.1 访问路径注解作用域 1.2 路径精准(模糊)匹配 1.3 访问路径限制请求方式 1.4 进阶访问路径请求注解 1.5 与WebServlet的区别 二、接收请求数据 2.1 请求param参数 2.2 请求路径参数 2.3 请求…...

SPIRAN ART SUMMONER企业集成:Java面试题中的AI应用解析
SPIRAN ART SUMMONER企业集成:Java面试题中的AI应用解析 掌握AI集成核心考点,轻松应对Java面试中的技术难题 1. 企业级AI集成面试要点 在Java技术面试中,SPIRAN ART SUMMONER这类AI模型的集成能力已经成为衡量候选人综合技术水平的重要标准。…...

Wan2.2-I2V-A14B惊艳效果:动态镜头推移、自然光影变化、流畅运镜展示
Wan2.2-I2V-A14B惊艳效果:动态镜头推移、自然光影变化、流畅运镜展示 1. 专业级视频生成能力 Wan2.2-I2V-A14B模型带来了令人惊叹的视频生成效果,能够将简单的文字描述转化为专业水准的动态视频。这个模型特别擅长处理复杂的镜头运动和光影变化&#x…...

Free RTOS:任务状态,任务管理与调度理论
目录 1.任务状态 1.1 FreeRTOS的任务状态: 1.2 阻塞状态(Blocked) 1.3 暂停状态(Suspended) 原型如下: 1.4 就绪状态(Ready) 1.5 完整的状态转换图 1.6 代码 2.任务管理与调度理论 2.1 调度 2.2 FreeRTOS调度 STM32CubeMX FreeRTOS源码 代…...

别再死记硬背了!用这5个n8n核心节点,搞定你80%的自动化需求
别再死记硬背了!用这5个n8n核心节点,搞定你80%的自动化需求 每次打开n8n的节点库,就像走进一家琳琅满目的工具超市——HTTP、数据库、AI、邮件、表单...上百种节点让人既兴奋又迷茫。作为过来人,我完全理解那种"每个节点看起…...

六挡手动齿轮变速器设计【说明书、CAD图纸、 开题报告、任务书 ……】
六挡手动齿轮变速器作为汽车传动系统的核心部件,其设计需兼顾动力传递效率与驾驶操控性。该变速器通过齿轮组的啮合与分离实现六个前进挡位的切换,每个挡位对应不同的齿轮传动比,既能满足车辆起步时的大扭矩需求,也能在高速巡航时…...
)
告别抓瞎!手把手教你用Wireshark解密TLS 1.3流量(附SSLKEYLOGFILE环境变量配置)
从密文到明文:实战解密TLS 1.3流量的完整指南 当你在调试一个API接口时,发现请求总是返回异常状态码,但查看Wireshark抓包却只能看到一堆加密的TLS 1.3数据包,这种"睁眼瞎"的感觉确实令人沮丧。TLS 1.3作为目前最安全的…...

3步轻松解锁付费内容:Bypass Paywalls Clean完整使用教程
3步轻松解锁付费内容:Bypass Paywalls Clean完整使用教程 【免费下载链接】bypass-paywalls-chrome-clean 项目地址: https://gitcode.com/GitHub_Trending/by/bypass-paywalls-chrome-clean 在数字信息时代,付费墙常常成为获取优质内容的障碍&a…...

随堂笔记0403
负载监控计算机核心资源:CPU: 计算(lscpu)内存: 缓存数据(掉电丢失)硬盘: 持久化存储数据网络: 传播数据[rootCentos01 wyj]# lscpuCPU(s): 2型号名称&am…...
源码,彻底搞懂音频帧、周期和缓冲区)
别再混淆了!用Android AudioRecord.getMinBufferSize()源码,彻底搞懂音频帧、周期和缓冲区
从源码透视Android音频开发:帧、周期与缓冲区的实战解析 在移动音频开发领域,Android平台的AudioRecord API是构建录音功能的核心工具。许多开发者虽然能够调用getMinBufferSize()方法获取缓冲区大小,但当遇到音频卡顿、杂音或延迟问题时&…...

EduCoder实训答案查询站是怎么建起来的?从签到、解锁到数据抓取的全流程复盘
从零构建EduCoder答案查询站的技术实践与思考 去年冬天,我发现身边不少同学在EduCoder平台上刷实训时常常卡壳,而平台自带的答案解锁机制又需要消耗大量金币。作为一名计算机专业的学生兼业余开发者,我萌生了一个想法:能否通过技术…...