◢Django 自写分页与使用
目录
1、设置分页样式,并展示到浏览器
2、模拟页码
3、生成分页
4、数据显示
5、上一页下一页
6、数据库的数据分页
7、封装分页
8、使用封装好的分页
建立好app后,设置路径path('in2/',views.in2),视图def in2(request): ,HTML: in2.html
1、设置分页样式,并展示到浏览器
def in2(request):return render(request,'in2.html')<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><title>Title</title><style>*{padding: 0;list-style: none;margin: 0;}span{display: inline-block;width: 40px;text-align: center;font-size: 20px;border: 1px solid;background-color: #2aabd2;}a{text-decoration: none;color: white;}</style>
</head>
<body><span><a>1</a></span>
</body>
</html>![]()
2、模拟页码
def in2(request):# 假设有100条数据data_count = 100 #350#每页有8条数据page_size = 8#共有多少页page_count, count=divmod(data_count,page_size)if count:page_count+=1page_string = ''for i in range(page_count):page_string+=f"<span><a>{i}</a></span>"#page_string = mark_safe("".join(page_string))return render(request,'in2.html',{"page_string":page_string})若是在html中直接导入page_string 那就是一个字符串,

需要将循环生成的page_string进行,【取消注释】
page_string = mark_safe("".join(page_string))
作用是:将字符串列表(`page_string`)中的元素连接起来,并将结果标记为安全的HTML内容。使用`join()`函数将字符串列表中的所有元素连接在一起,然后`mark_safe()`函数将连接起来的字符串标记为安全的,这样在显示HTML内容时,就不会对其中的标签和特殊字符进行转义处理。通常用于在模板中生成动态的HTML内容,以避免对HTML标签和特殊字符进行转义。

3、生成分页
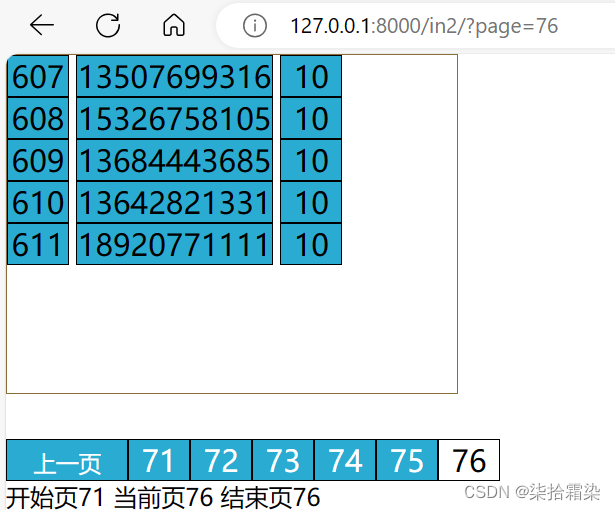
数据量增多后,页码就变多了,需要设置显示的分页,在当前页的基础上显示前5页后5页,多出的页码不显示
为每个a标签附带参数page,使用字符串拼接,用for循环标明每个a所附带的参数,
点击a标签,发送的是get请求,GET请求没有获得page时,默认为第一页,点击之后,url自动携带page参数,每次点击获取该a标签的携带page参数,用作当前页
def in2(request):#默认设置当前页为1,若有get请求传递过来的当前页,则进行更改if request.GET.get('page'):current_page = int(request.GET.get('page'))else:current_page = 1data_count = 350 page_size = 8 page_count, count=divmod(data_count,page_size) if count:page_count+=1#设置当前页的前后可见页数为5plus = 5#当前页小于等于5 起始页始终为1 ;当前页大于5 起始页为当前页减5if current_page <= plus + 1:start_page = 1else:start_page = current_page - plus# 当前页大于等于最终点页 结束页始终为终点页 ;当前页小于终点页减5 结束页为当前页+5if current_page >= page_count - plus:end_page = page_countelse:end_page = current_page + pluspage_string = ''for i in range(start_page, end_page + 1):page_string += f"<span><a href=?page={i}>{i}</a></span>"page_string = mark_safe("".join(page_string))context={"current_page":current_page,"start_page":start_page,"end_page" :end_page,"page_string":page_string,}return render(request,'in2.html',context)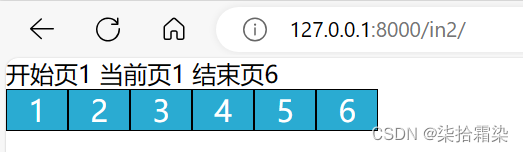
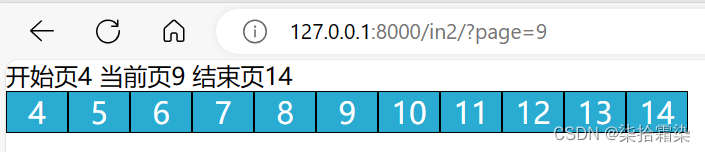
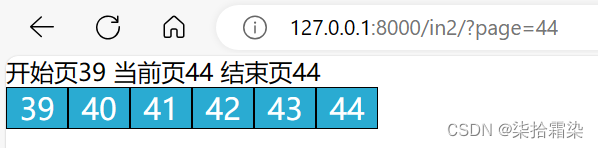
成功后,为了显示当前页的不同,需要在for循环那里,增加一个if,用以判断,i与当前页是否相同,相同则为该页加上不同的样式
for i in range(start_page, end_page + 1):if i == current_page:page_string += f"<span style='background-color:#fff;'><a style='color:#000' href=?page={i}>{i}</a></span>"else:page_string += f"<span><a href=?page={i}>{i}</a></span>"4、数据显示
增加数据的时候,注意最后一页数据是不满的[44*8=352],一共有350条数据,所以最后一页的end为总数据条数。
#获取数据的起始位置与结束位置[1,8],[9,16]
start = int(current_page - 1 ) * page_size + 1
if current_page == page_count:#当前页是最后一页时,数据并不是8条数据end = data_count
else:end = int(current_page) * page_size
print(start,end)给context字典中补充起始数据,与结束数据,这里采用的是整型数字用来模拟数据总数,在HTML中for不能同平时使用,不能迭代整型数据,直接传入range(start,end,step)作为迭代器
context={
"data":range(start,end+1),
}
在HTML中遍历data
<style>
.data{width: 300px;height: 166px;border: 1px solid #8a6d3b;margin-bottom: 30px;
}
</style><body>
<div class="data">{% for i in data %}<li>这是第 {{ i }} 条数据</li>{% endfor %}
</div>
</body>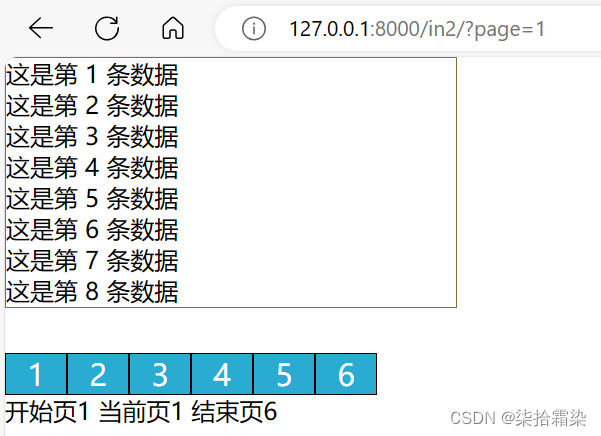

5、上一页下一页
在点击页码的情况下增加上一页下一页的按钮,当前看到的最后页码变为第一个页码。
看见第一页不显示上一页按钮,同样最后一页也不带按钮。
处于看不见首页,但又不超过加减页时,点击上一页会跳出合适的页码,应当设置page=1,拉回跳转位置,放置page变为负数,尾页也一样。
页码满足加减页时,实行最后一个页码变第一个页码,在当前页的页码基础上 加上 或 减去 plus的2倍
# 上一页,下一页if current_page <= plus +1:#当前页在前5页时,不需要上一页pre = ''else:if current_page <= plus * 2 :#当前页处于5-10页时,点击上一页,跳转到第1页pre=f'<span class="updown"><a href=?page={1}>首页</a></span>'else:pre = f'<span class="updown"><a href=?page={current_page - plus * 2}>上一页</a></span>'if current_page >= page_count - plus:next = ''else:if current_page >= page_count - plus * 2:next = f'<span class="updown"><a href=?page={page_count}>尾页</a></span>'else:next = f'<span class="updown"><a href=?page={current_page + plus * 2}>下一页</a></span>'整合分页和上下页的程序,减少if的判断
6、数据库的数据分页
605/8=75,605%8=5【最后一页是75,有5条数据】第一列是表的id不是序号,中间有删掉的id,所以最终值不为605
data_count = models.表名.objects.all().count()
<div class="data">{% for i in data %}<li><span>{{ i.id }}</span> <span style="width: 130px">{{ i.phone }}</span> <span>{{ i.price }}</span></li>{% endfor %}
</div>
在 SQL Server 中,索引是从 1 开始计数的,需要 +1,而MySql数据库的索引是从0开始,所以不用加,注意区别自己使用的数据起始索引
7、封装分页
建立软件包,命名为utils
在utils中建立SplitPage.py,整合前面程序,该封装的封装,该方法体的方法体,page_size不写默认为8,写则加载
from django.utils.safestring import mark_safe
class Splitpagenumber:def __init__(self,request, queryset, page_size=8, plus=5, ):#定义变量,方法体实现分页if request.GET.get('page'):self.current_page = int(request.GET.get('page'))else:self.current_page = 1#数据库,self.queryset = querysetself.data_count = queryset.count()#数据总条数self.page_size = page_size'''可分为多少个页码'''self.page_count,self.count = divmod(self.data_count, page_size)if self.count:self.page_count += 1start = int(self.current_page - 1) * page_sizeif self.current_page == self.page_count: # 当前页是最后一页时,数据并不是8条数据end = self.data_countelse:end = int(self.current_page) * page_sizeself.data = self.queryset[start:end]self.plus =plusdef html(self):# 获取数据的起始位置与结束位置[0,8],[start = int(self.current_page - 1) * self.page_sizeif self.current_page == self.page_count: # 当前页是最后一页时,数据并不是8条数据end = self.data_countelse:end = int(self.current_page) * self.page_sizeprint(start, end)data = self.queryset[start:end]#实现 起始页,结束页 ,与 上一页下一页if self.current_page <= self.plus + 1:start_page = 1pre = ''else:start_page = self.current_page - self.plusif self.current_page <= self.plus * 2: # 当前页处于5-10页时,点击上一页,跳转到第1页pre = f'<span class="updown"><a href=?page={1}>首页</a></span>'else:pre = f'<span class="updown"><a href=?page={self.current_page - self.plus * 2}>上一页</a></span>'# 当前页大于等于最终点页 结束页始终为终点页 ;当前页小于终点页减5 结束页为当前页+5if self.current_page >= self.page_count - self.plus:end_page = self.page_countnext = ''else:end_page = self.current_page + self.plusif self.current_page >= self.page_count - self.plus * 2:next = f'<span class="updown"><a href=?page={self.page_count}>尾页</a></span>'else:next = f'<span class="updown"><a href=?page={self.current_page + self.plus * 2}>下一页</a></span>'""" 生成html格式 """page_string = ''page_string += prefor i in range(start_page, end_page + 1):if i == self.current_page:page_string += f"<span style='background-color:#fff;'><a style='color:#000' href=?page={i}>{i}</a></span>"else:page_string += f"<span><a href=?page={i}>{i}</a></span>"page_string += nextpage_string = mark_safe("".join(page_string))return page_string8、使用封装好的分页
完善in3的路径联系,然后运行in3
from app02.utils import SplitPage
def in3(request):queryset = models.User.objects.all()page_object = SplitPage.Splitpagenumber(request, queryset)context={"info":page_object.data,"page_string":page_object.html()}return render(request,'in3.html',context)默认分页 【数据显示添加css】

page_object = SplitPage.Splitpagenumber(request, queryset,page_size=31,plus=5)
page_object = SplitPage.Splitpagenumber(request, queryset,page_size=2,plus=10)
只截了最后一页,分页显示的就不一样,但数据相同


相关文章:
◢Django 自写分页与使用
目录 1、设置分页样式,并展示到浏览器 2、模拟页码 3、生成分页 4、数据显示 5、上一页下一页 6、数据库的数据分页 7、封装分页 8、使用封装好的分页 建立好app后,设置路径path(in2/,views.in2),视图def in2(request): ,HTML: in2.html…...
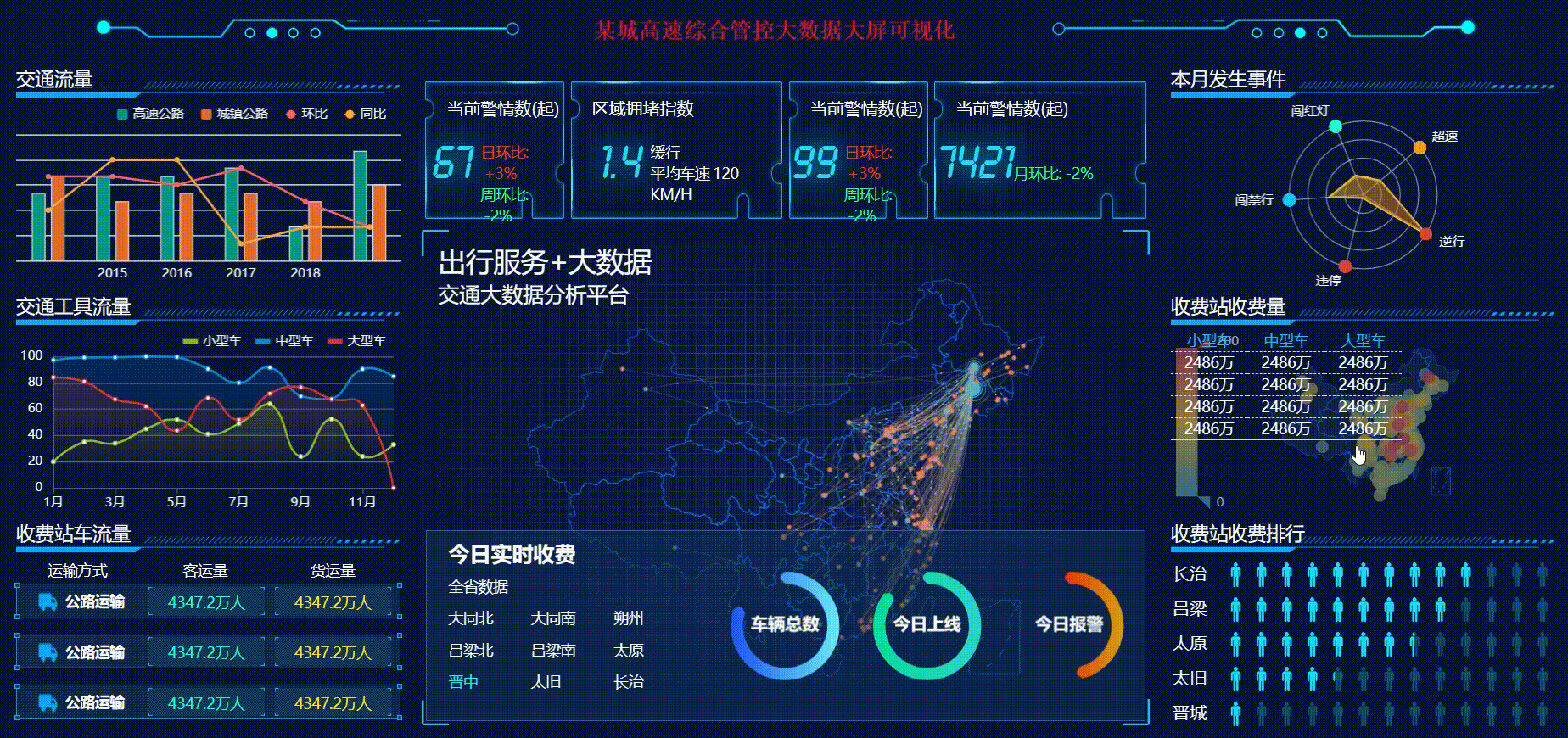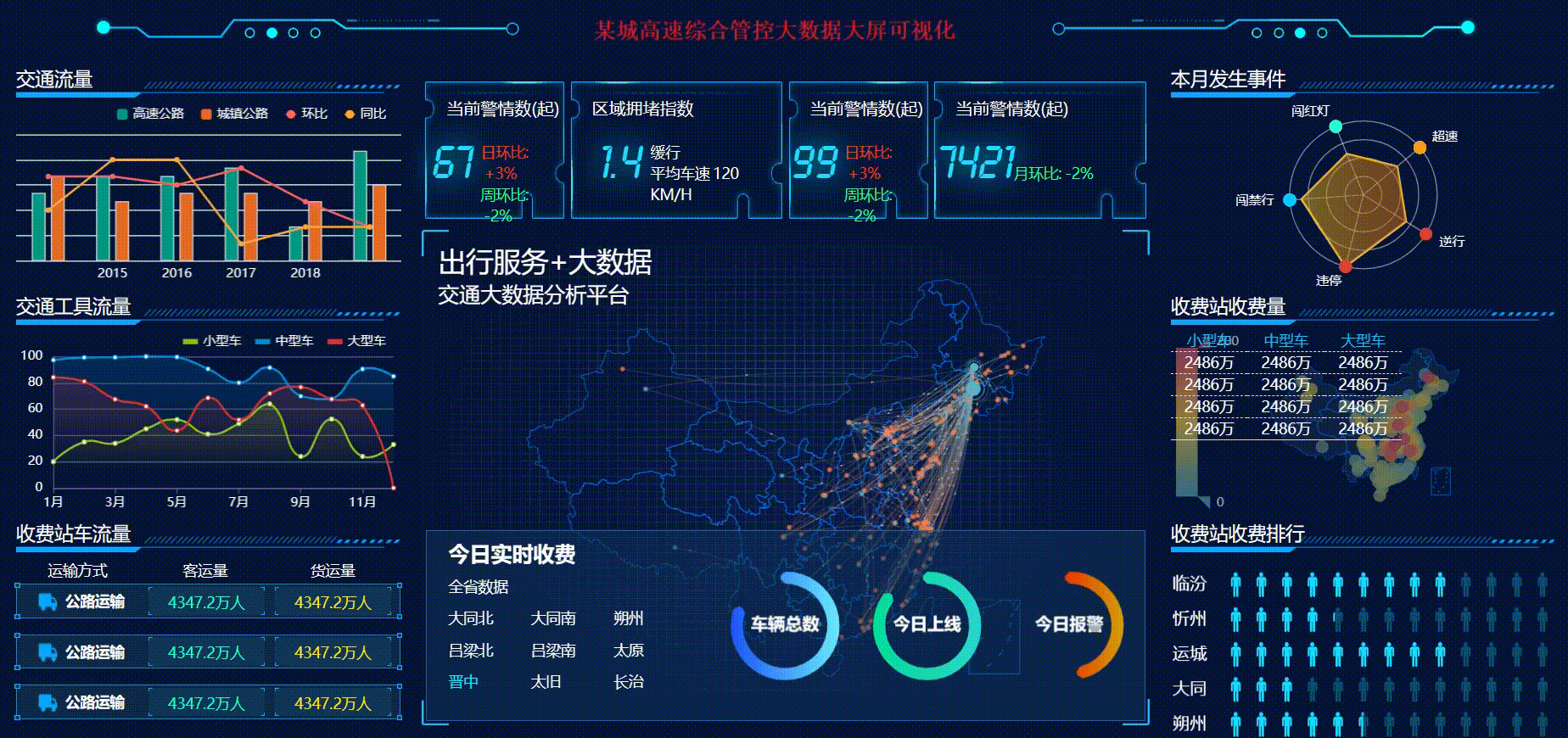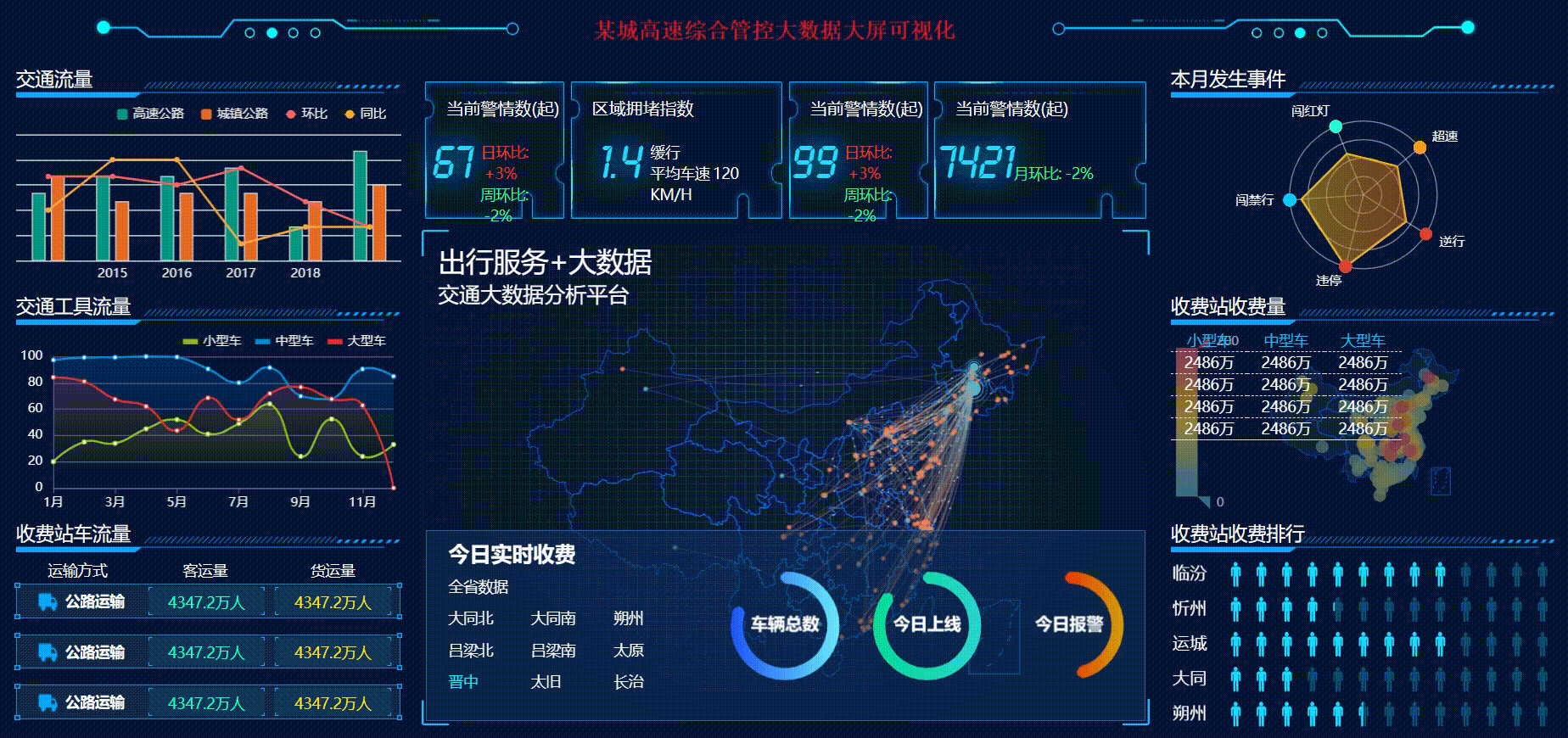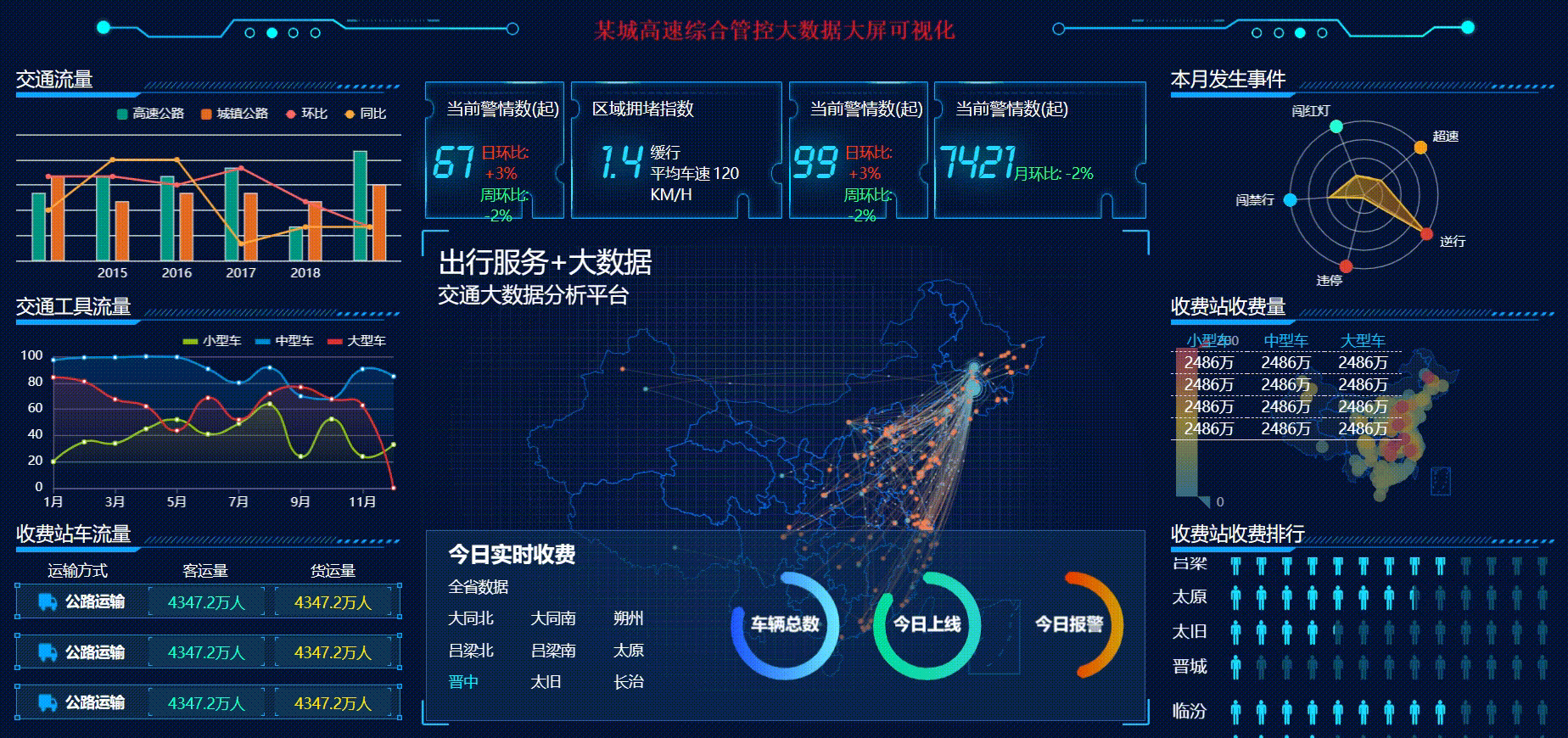
某城高速综合管控大数据大屏可视化【可视化项目案例-04】
🎉🎊🎉 你的技术旅程将在这里启航! 🚀🚀 本文选自专栏:可视化技术专栏100例 可视化技术专栏100例,包括但不限于大屏可视化、图表可视化等等。订阅专栏用户在文章底部可下载对应案例源码以供大家深入的学习研究。 🎓 每一个案例都会提供完整代码和详细的讲解,不…...

如何在Linux下进行文件查看
cat 文本内容显示到终端 head 查看文件开头 tail 查看文件结尾 常用参数 -f 文件内容更新后,显示信息同步更新 wc 统计文件内容信息...
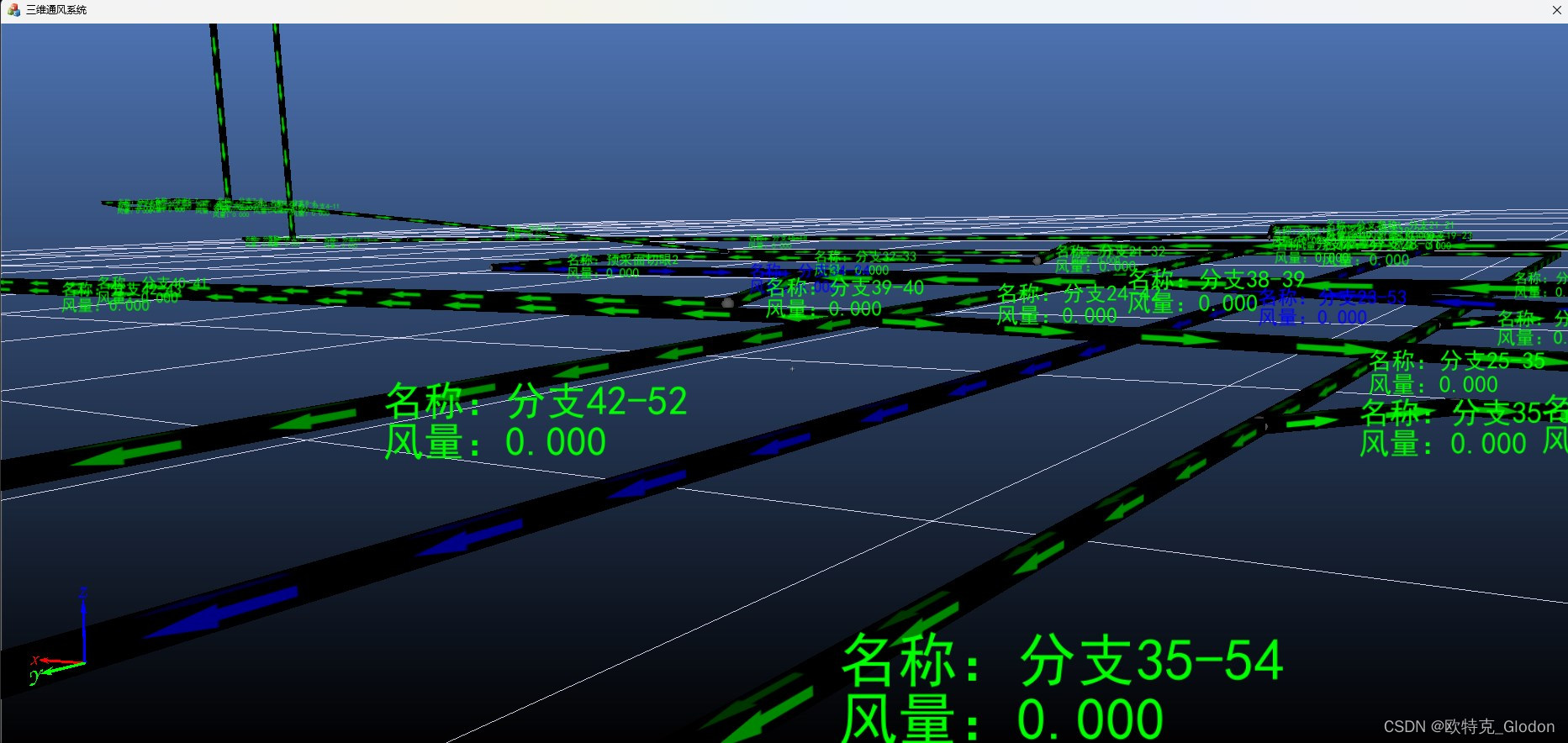
OSG练习:模仿Ventsim制作三维矿井智能通风系统
1、效果 2、计划内容 1) 三维场景的加载显示;已实现 2)矿井巷道建模及纹理;已实现 3)矿井基础数据采集及修正;已实现 4)通风网络解算算法;已实现 5)通风设备及设施模型制作;未实现 6)风流模拟效果 ;进行中 7)火灾模拟效果;未实现 8)巷道属性查看栏;未实现 9)…...

【数据结构】非递归实现二叉树的前 + 中 + 后 + 层序遍历(听说面试会考?)
👦个人主页:Weraphael ✍🏻作者简介:目前学习C和算法 ✈️专栏:数据结构 🐋 希望大家多多支持,咱一起进步!😁 如果文章对你有帮助的话 欢迎 评论💬 点赞&…...

32 Feign性能优化
2.3.Feign使用优化 Feign底层发起http请求,依赖于其它的框架。其底层客户端实现包括: •URLConnection:默认实现,不支持连接池 •Apache HttpClient :支持连接池 •OKHttp:支持连接池 因此提高Feign的…...

星岛专栏|从Web3发展看金融与科技的融合之道
11月起,欧科云链与香港主流媒体星岛集团开设Web3.0安全技术专栏,该专栏主要面向香港从业者、交易机构、监管机构输出专业性的安全合规建议,旨在促进香港Web3.0行业向安全与合规发展。 出品|欧科云链研究院 自2016年首届香港金融…...

什么是网络爬虫?
网络爬虫是一种自动化程序,可以自动地浏览网站并从网站上抽取数据。APP数据抓取实际上也是运用了网络爬虫的技术,只不过抓取的对象不是网站上的信息,而是手机APP上的数据。下面详细介绍APP数据抓取的过程。 1、确定数据需求 首先需要明确要抓…...
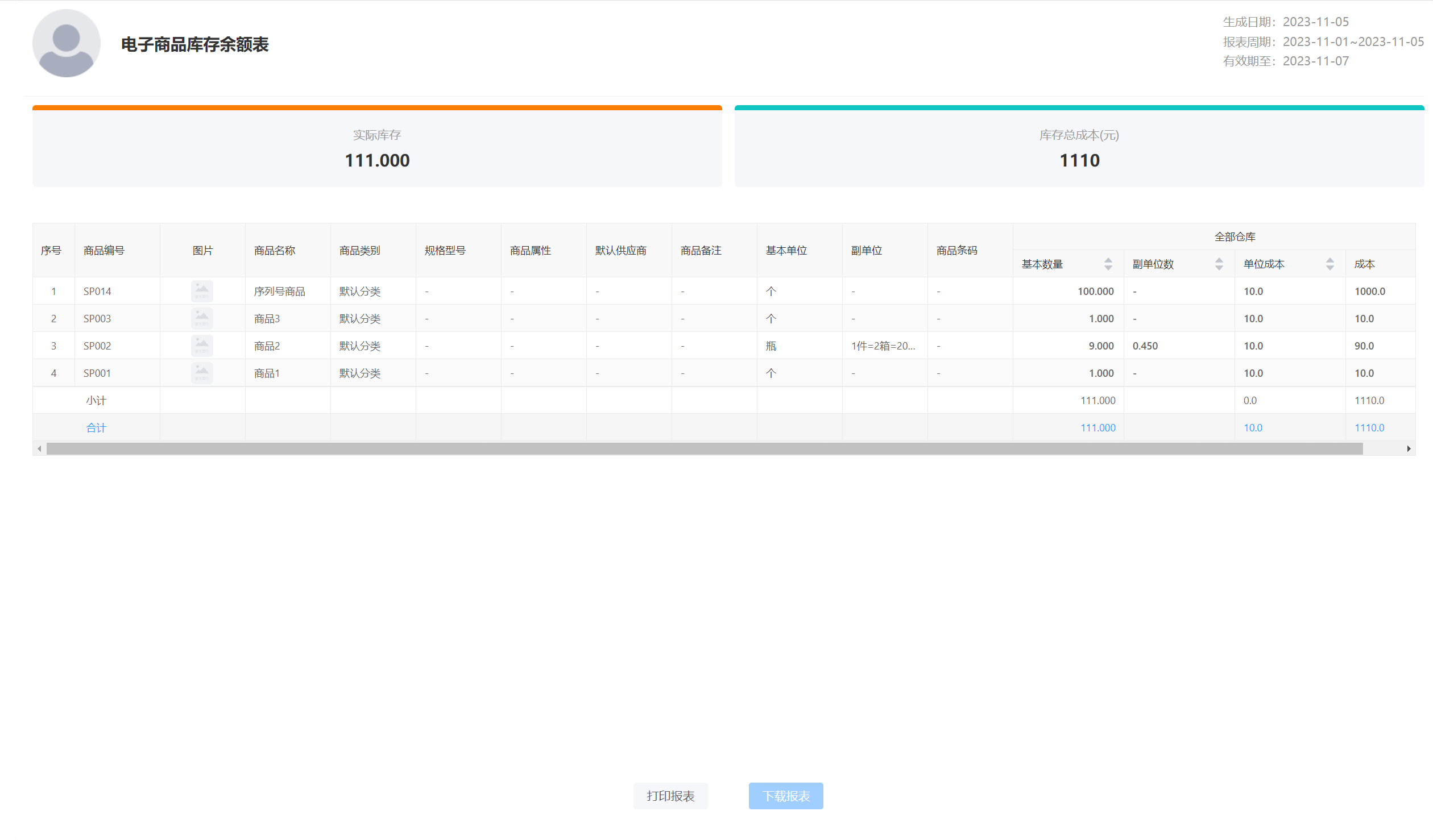
酷柚易汛ERP - 商品库存余额表操作指南
1、应用场景 商品库存余额表用于查询商品在各仓库的实际结存量、单位成本以及成本等明细。 2、主要操作 打开【仓库】-【商品库存余额表】,可筛选仓库、商品、商品类别,导出/打印等操作见【销货单】不再赘述。 3、分享操作 库存余额分享,…...

第27期 | GPTSecurity周报
GPTSecurity是一个涵盖了前沿学术研究和实践经验分享的社区,集成了生成预训练Transformer(GPT)、人工智能生成内容(AIGC)以及大型语言模型(LLM)等安全领域应用的知识。在这里,您可以…...

大数据-玩转数据-Flume
一、Flume简介 Flume提供一个分布式的,可靠的,对大数据量的日志进行高效收集、聚集、移动的服务,Flume只能在Unix环境下运行。Flume基于流式架构,容错性强,也很灵活简单。Flume、Kafka用来实时进行数据收集,Spark、Flink用来实时处理数据,impala用来实时查询。二、Flume…...

【Linux】进程概念IV 进程地址空间
Halo,这里是Ppeua。平时主要更新C语言,C,数据结构算法…感兴趣就关注我吧!你定不会失望。 本篇导航 0. 数据在内存中的分布1. 虚拟地址与真实物理地址2. 进程地址空间2.1 进程地址空间概念2.2 进程->页表->内存 0. 数据在内…...

Flink在汽车行业的应用【面试加分系列】
很多同学问我为什么要发这些大数据前沿汇报? 一方面是自己学习完后觉得非常好,然后总结发出来方便大家阅读;另外一方面,看这些汇报对你的面试帮助会很大,特别是面试前可以看看即将面试公司在大数据前沿的发展动向&…...
智慧工地源码:助力数字建造、智慧建造、安全建造、绿色建造
智慧工地围绕建设过程管理,建设项目与智能生产、科学管理建设项目信息生态系统集成在一起,该数据在虚拟现实环境中,将物联网收集的工程信息用于数据挖掘和分析,提供过程趋势预测和专家计划,实现工程建设的智能化管理&a…...

Spring Boot(二)
1、运行维护 1.1、打包程序 SpringBoot程序是基于Maven创建的,在Maven中提供有打包的指令,叫做package。本操作可以在Idea环境下执行。 mvn package 打包后会产生一个与工程名类似的jar文件,其名称是由模块名版本号.jar组成的。 1.2、程序…...
上海亚商投顾:沪指缩量调整跌 高位强势股继续退潮
上海亚商投顾前言:无惧大盘涨跌,解密龙虎榜资金,跟踪一线游资和机构资金动向,识别短期热点和强势个股。 一.市场情绪 三大指数11月10日弱势震荡,上证50盘中跌超1%,以保险为首的权重板块走势较弱。 高位强…...

药理学试卷
1【单选题】关于尼可刹米,错误的是 C A、直接兴奋延脑呼吸中枢 B、刺激颈动脉体化学感受器 C、作用时间较长 D、过量可致惊厥 2【单选题】属于第三代头孢菌素的药物是 C A、头孢克洛 B、头孢噻吩 C、头孢曲松 D、头孢匹罗 3【单选题】不属于β受体阻断药禁…...

SpringBoot3-快速入门
1.前置知识 Java17Spring、SpringMVC、MyBatisMaven、IDEA\ 2. 环境要求 环境&工具 版本(or later) SpringBoot 3.0.5 IDEA 2021.2.1 Java 17 Maven 3.5 Tomcat 10.0 Servlet 5.0 GraalVM Community 22.3 Native Build Tools 0.9…...

具名挂载和匿名挂载
匿名卷挂载 : -v 的时候只指定容器内的路径 如下面这个:/etc/nginx 1.docker run -d -P --name nginx -v /etc/nginx nginx 2.查看所有卷 docker volume ls 这里发现,这就是匿名挂载,只指定容器内的路径,没有指定…...
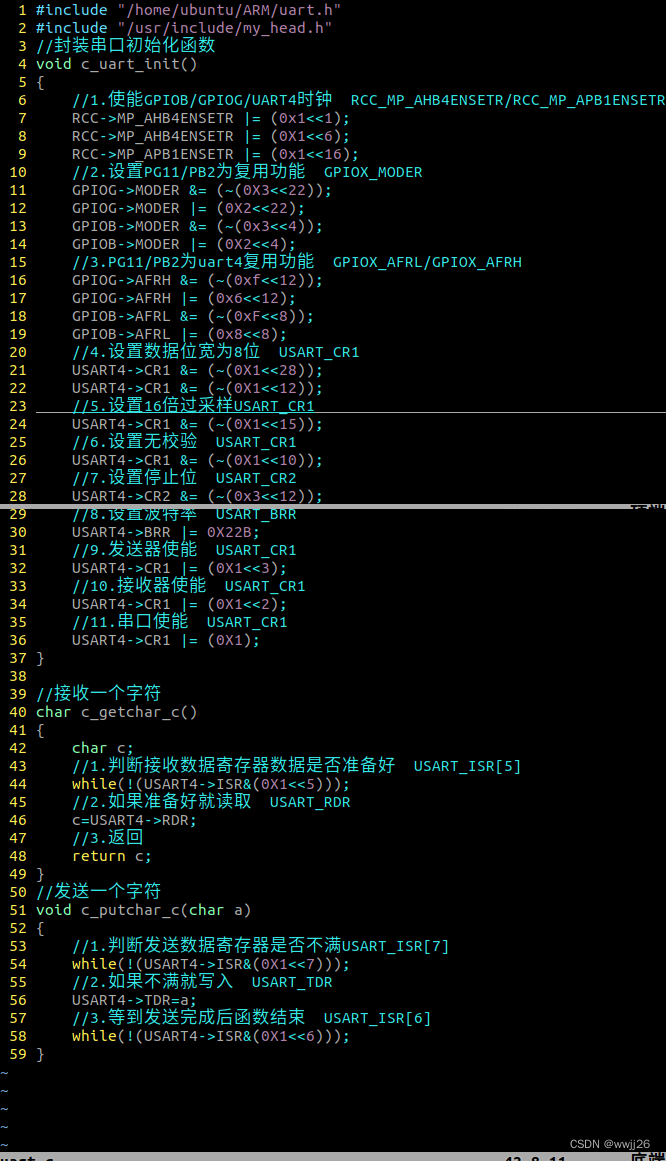
ARM串口
...

探索SillyTavern:重新定义AI角色交互体验的开源平台
探索SillyTavern:重新定义AI角色交互体验的开源平台 【免费下载链接】SillyTavern LLM Frontend for Power Users. 项目地址: https://gitcode.com/GitHub_Trending/si/SillyTavern 在人工智能与人类交互日益紧密的今天,如何打破传统聊天界面的局…...

Cadence计算器实战:从波形运算到自定义函数编程
1. 差分信号处理的核心挑战 在模拟电路设计中,差分信号的处理一直是工程师们面临的常见难题。我刚入行时,第一次看到差分信号的波形图完全懵了——两条看似镜像对称的曲线,到底该怎么计算它们的共模电压、差模电压这些关键参数?传…...

Java高频面试题:如何编写一个MyBatis插件?
大家好,我是锋哥。今天分享关于【Java高频面试题:如何编写一个MyBatis插件?】面试题 。希望对大家有帮助;Java高频面试题:如何编写一个MyBatis插件?编写一个 MyBatis 插件主要是通过实现 Interceptor 接口来…...

如何快速上手AICoverGen:免费制作专业级AI翻唱歌曲的完整指南
如何快速上手AICoverGen:免费制作专业级AI翻唱歌曲的完整指南 【免费下载链接】AICoverGen A WebUI to create song covers with any RVC v2 trained AI voice from YouTube videos or audio files. 项目地址: https://gitcode.com/gh_mirrors/ai/AICoverGen …...

技术解析:ncmdump如何破解网易云音乐NCM格式加密机制
技术解析:ncmdump如何破解网易云音乐NCM格式加密机制 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 在数字音乐版权保护日益严格的今天,网易云音乐采用NCM格式对下载的音乐文件进行加密保护,这种…...

别再手动配IP了!用NI-USRP Configuration Utility快速搞定USRP 2954与LabVIEW连接
告别手动配置:NI-USRP Configuration Utility 快速连接 USRP 2954 与 LabVIEW 全攻略 刚拿到 USRP 2954 设备时,许多工程师和研究人员的第一道坎往往不是复杂的信号处理算法,而是看似基础却令人头疼的网络配置问题。传统的手动 IP 配置方式不…...

StructBERT中文语义匹配系统开发者案例:语义向量用于排序模型特征
StructBERT中文语义匹配系统开发者案例:语义向量用于排序模型特征 1. 项目核心价值:从“虚高”到“精准”的跨越 如果你做过搜索推荐或者内容去重,大概率遇到过这样的头疼事:两段明明不相关的文本,用传统的语义模型一…...

从服务器被黑到主动防御:fail2ban实战部署与多服务防护策略
1. 从一次真实的服务器入侵说起 去年夏天的一个凌晨,我被手机警报声惊醒——自建服务器的CPU占用率飙升至100%。登录管理界面后,发现有个名为kworker的进程持续消耗资源。经过排查,在/tmp目录下发现了伪装成系统文件的挖矿程序,攻…...
)
避开PLC烧毁陷阱:FX3S晶体管输出必须知道的7个细节(含虚设电阻计算)
避开PLC烧毁陷阱:FX3S晶体管输出必须知道的7个细节(含虚设电阻计算) 在工业自动化现场,FX3S系列PLC的晶体管输出模块烧毁问题堪称"隐形杀手"。去年某汽车生产线因一个0.5A保险丝选型错误导致全线停产8小时,损…...

小白也能当对联大师!春联生成模型-中文-base开箱即用教程
小白也能当对联大师!春联生成模型-中文-base开箱即用教程 1. 前言:人人都能创作春联 春节贴春联是中国人延续千年的传统习俗,但创作一副对仗工整、寓意美好的春联并非易事。传统春联创作需要掌握平仄、对仗等复杂规则,这让许多对…...