爬虫项目(12):正则、多线程抓取腾讯动漫,Flask展示数据
文章目录
- 书籍推荐
- 正则抓取腾讯动漫数据
- Flask展示数据
书籍推荐
如果你对Python网络爬虫感兴趣,强烈推荐你阅读《Python网络爬虫入门到实战》。这本书详细介绍了Python网络爬虫的基础知识和高级技巧,是每位爬虫开发者的必读之作。详细介绍见👉: 《Python网络爬虫入门到实战》 书籍介绍
正则抓取腾讯动漫数据
import requests
import re
import threading
from queue import Queuedef format_html(html):li_pattern = re.compile('<li class="ret-search-item clearfix">[\s\S]+?</li>')title_pattern = re.compile('title="(.*?)"')img_src_pattern = re.compile('data-original="(.*?)"')update_pattern = re.compile('<span class="mod-cover-list-text">(.*?)</span>')tags_pattern = re.compile('<span href="/Comic/all/theme/.*?" target="_blank">(.*?)</span>')popularity_pattern = re.compile('<span>人气:<em>(.*?)</em></span>')items = li_pattern.findall(html)for item in items:title = title_pattern.search(item).group(1)img_src = img_src_pattern.search(item).group(1)update_info = update_pattern.search(item).group(1)tags = tags_pattern.findall(item)popularity = popularity_pattern.search(item).group(1)data_queue.put(f'{title},{img_src},{update_info},{"#".join(tags)},{popularity}\n')def run(index):try:headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'}response = requests.get(f"https://ac.qq.com/Comic/index/page/{index}", headers=headers)html = response.textformat_html(html)except Exception as e:print(f"Error occurred while processing page {index}: {e}")finally:semaphore.release()if __name__ == "__main__":data_queue = Queue()semaphore = threading.BoundedSemaphore(5)lst_record_threads = []for index in range(1, 3):print(f"正在抓取{index}")semaphore.acquire()t = threading.Thread(target=run, args=(index,))t.start()lst_record_threads.append(t)for rt in lst_record_threads:rt.join()with open("./qq_comic_data.csv", "a+", encoding="gbk") as f:while not data_queue.empty():f.write(data_queue.get())print("数据爬取完毕")Flask展示数据
上面能够实现爬取数据,但是我希望展示在前端。
main.py代码如下:
# coding= gbk
from flask import Flask, render_template
import csvapp = Flask(__name__)def read_data_from_csv():with open("qq_comic_data.csv", "r", encoding="utf-8") as f:reader = csv.reader(f)data = list(reader)[1:] # 跳过标题行# 统一转换人气数据为浮点数(单位:亿)for row in data:popularity = row[4]if '亿' in popularity:row[4] = float(popularity.replace('亿', ''))elif '万' in popularity:row[4] = float(popularity.replace('万', '')) / 10000 # 将万转换为亿# 按人气排序并保留前10条记录data.sort(key=lambda x: x[4], reverse=True)return data[:10]@app.route('/')
def index():comics = read_data_from_csv()return render_template('index.html', comics=comics)if __name__ == '__main__':app.run(debug=True)templates/index.html如下:
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><title>漫画信息</title><style>body {font-family: Arial, sans-serif;background-color: #f4f4f4;color: #333;line-height: 1.6;padding: 20px;}.container {width: 80%;margin: auto;overflow: hidden;}h1 {text-align: center;color: #333;}.comic {background: #fff;margin-bottom: 20px;padding: 15px;border-radius: 10px;box-shadow: 0 5px 10px rgba(0,0,0,0.1);}.comic h2 {margin-top: 0;}.comic p {line-height: 1.25;}.comic:nth-child(even) {background: #f9f9f9;}</style>
</head>
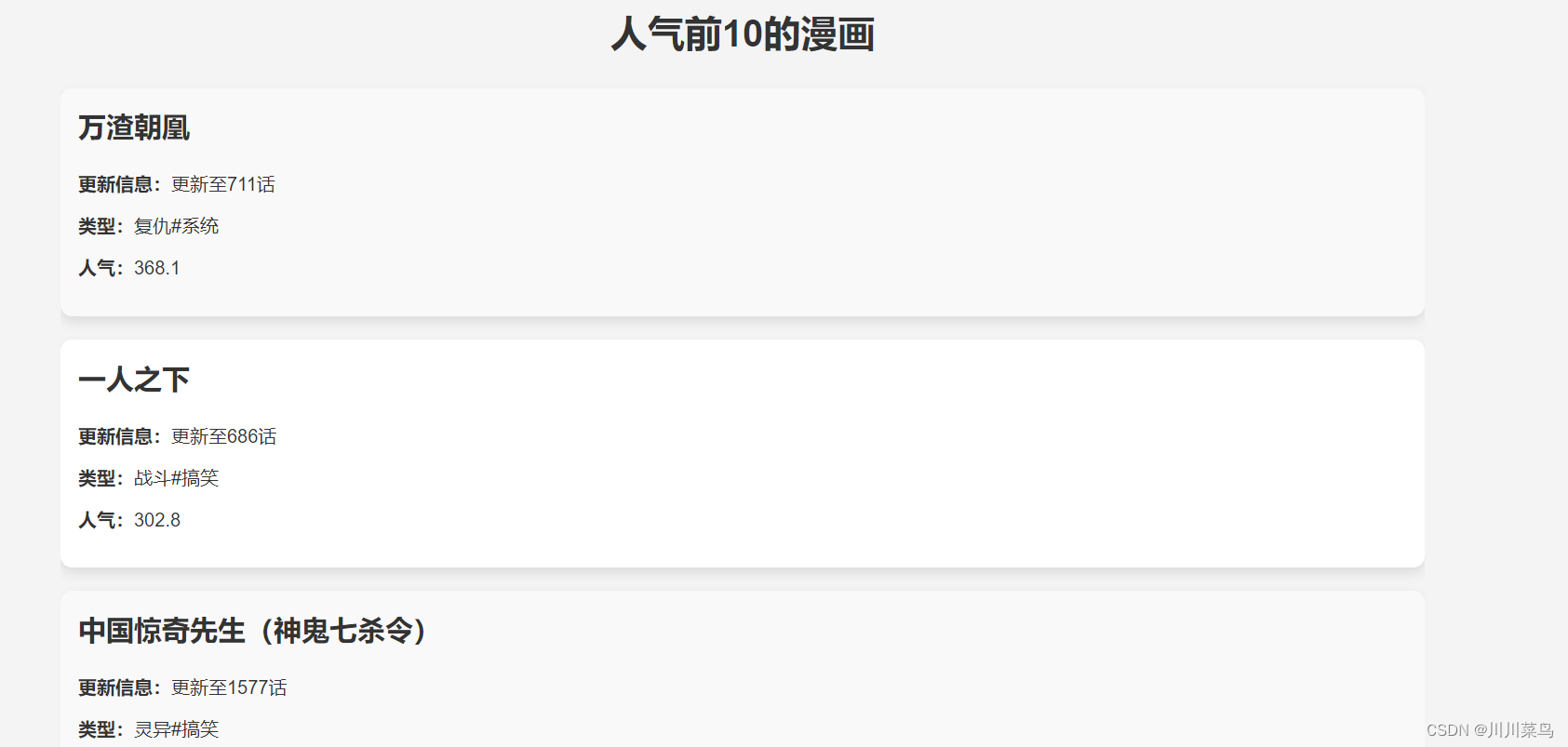
<body><div class="container"><h1>人气前10的漫画</h1>{% for comic in comics %}<div class="comic"><h2>{{ comic[0] }}</h2><p><strong>更新信息:</strong>{{ comic[2] }}</p><p><strong>类型:</strong>{{ comic[3] }}</p><p><strong>人气:</strong>{{ comic[4] }}</p></div>{% endfor %}</div>
</body>
</html>效果如下:
相关文章:
爬虫项目(12):正则、多线程抓取腾讯动漫,Flask展示数据
文章目录 书籍推荐正则抓取腾讯动漫数据Flask展示数据 书籍推荐 如果你对Python网络爬虫感兴趣,强烈推荐你阅读《Python网络爬虫入门到实战》。这本书详细介绍了Python网络爬虫的基础知识和高级技巧,是每位爬虫开发者的必读之作。详细介绍见ὄ…...

gedit编辑文件时常用快捷键
问题: 最近在修改文件时提到了gedit这个工具,与vi一样也是一个文件编辑器。但是在命令方面又有不同,在快捷键方面和Windows的使用习惯非常相似。 gedit举例: CTRL-Z:撤销CTRL-C:复制CTRL-V:粘贴CTRL-T:缩进CTRL-Q:退出CTRL-S:保…...

【C++干货铺】剖析string | 底层实现
个人主页点击直达:小白不是程序媛 C专栏:C干货铺 代码仓库:Gitee 目录 成员变量 成员函数 构造和拷贝构造 赋值重载 析构函数 operator[ ] size 迭代器 reserve(扩容函数) push_back(尾插函数)…...
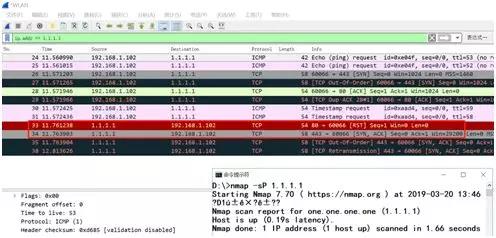
nmap原理与使用
kali的命令行中可以直接使用 nmap 命令,打开一个「终端」,输入 nmap 后回车,可以看到 nmap 的版本,证明 nmap 可用。 一、端口扫描 扫描主机的「开放端口」,在nmap后面直接跟主机IP(默认扫描1000个端口&am…...

AI批量剪辑矩阵托管系统----源码技术开发
AI批量剪辑矩阵托管系统----源码技术开发 抖音账号矩阵系统是基于抖音开放平台研发的用于管理和运营多个抖音账号的平台。它可以帮助用户管理账号、发布内容、营销推广、分析数据等多项任务,从而提高账号的曝光度和影响力。 具体来说,抖音账号矩阵系统可…...

Pandas数据预处理python 数据分析之4——pandas 预处理在线闯关_头歌实践教学平台
Pandas数据预处理python 数据分析之4——pandas 预处理 第1关 数据读取与合并第2关 数据清洗第3关 数据转换 第1关 数据读取与合并 任务描述 本关任务:加载 csv 数据集,实现 DataFrame 合并。 编程要求 根据提示,在右侧编辑器补充代码&#…...

[html] 动态炫彩渐变背景
废话不多说,直接上源码 <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>ZXW-NUDT: 动态炫…...
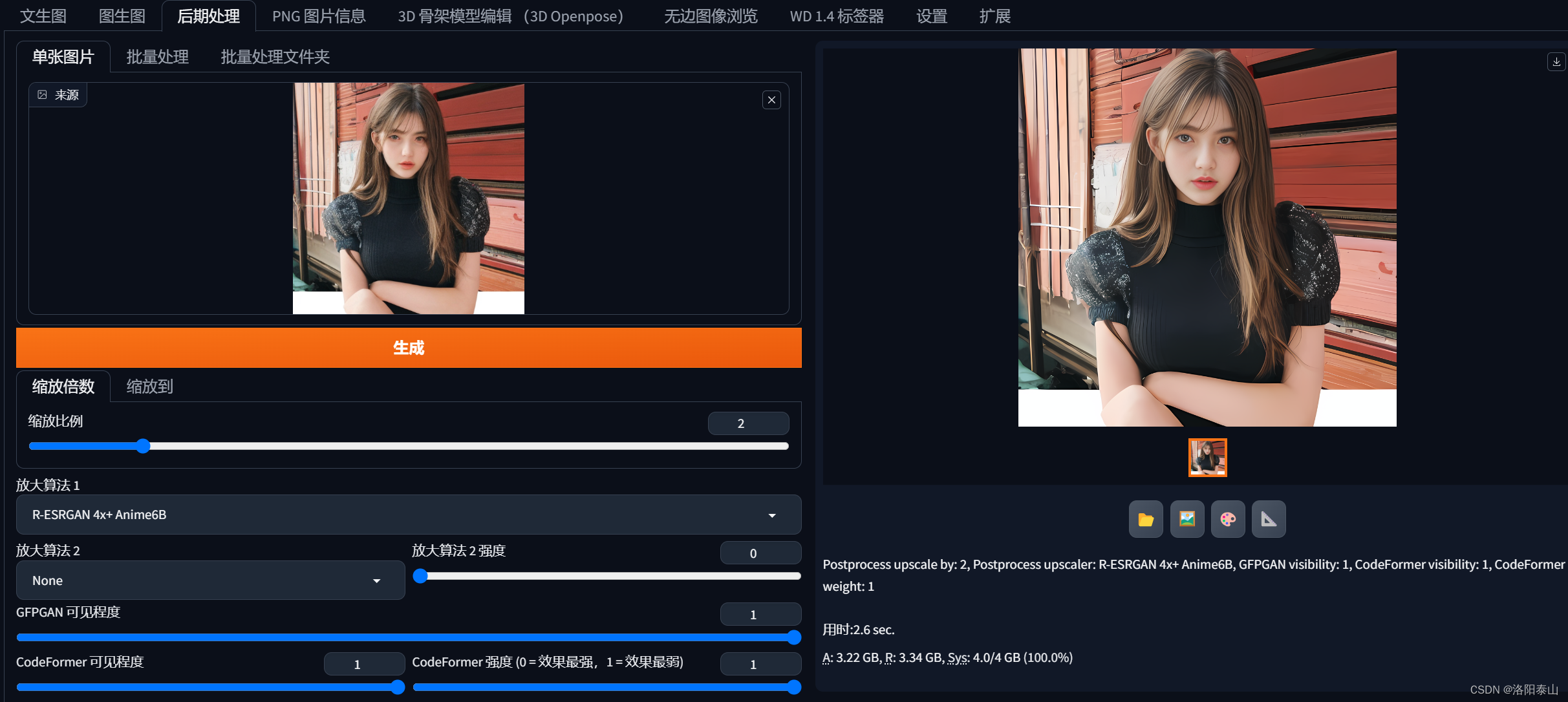
AI 绘画 | Stable Diffusion 高清修复、细节优化
前言 在 Stable Diffusion 想要生成高清分辨率的图片。在文生图的功能里,需要设置更大的宽度和高度。在图生图的功能里,需要设置更大的重绘尺寸或者重绘尺寸。但是设置完更大的图像分辨率,需要更大显存,1024*1024的至少要电脑的空…...
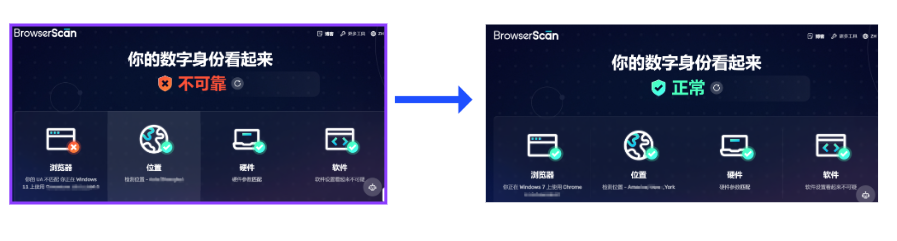
想要检测TikTok网络是否安全?这五个网站请收好
Tiktok目前在海外大火,越来越多的人想要进入TikTok的海外市场并捞一桶金。然而,成功并非易事。想要在TikTok中立足,我们必须保证我们的设备、网络环境和网络节点完全符合官方的要求,并且没有任何异常或风险。那么我们该如何设置、…...
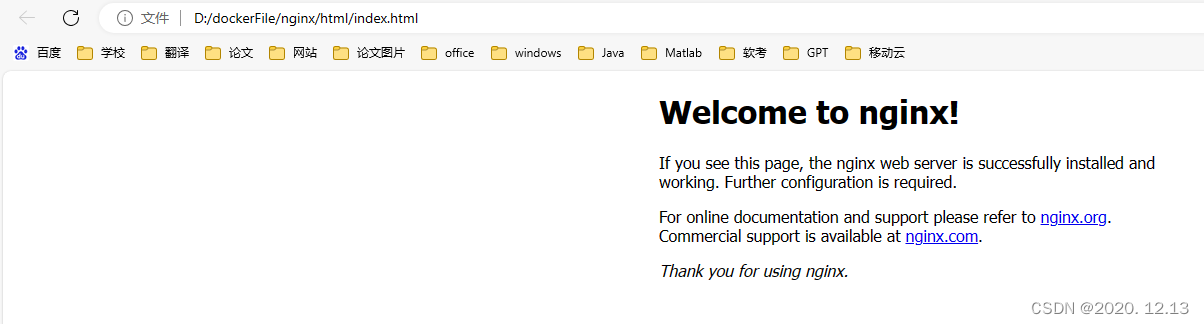
【docker:容器提交成镜像】
容器创建部分请看:点击此处查看我的另一篇文章 容器提交为镜像 docker commit -a "sinwa lee" -m "首页变化" mynginx lxhnginx:1.0docker run -d -p 88:80 --name lxhnginx lxhnginx:1.0为啥没有变啊,首页? 镜像打包 …...

UE5中一机一码功能
创建蓝图函数库 1、获取第一个有效的硬盘ID // Fill out your copyright notice in the Description page of Project Settings.#pragma once#include "CoreMinimal.h" #include "Kismet/BlueprintFunctionLibrary.h" #include "GetDiskIDClass.gen…...
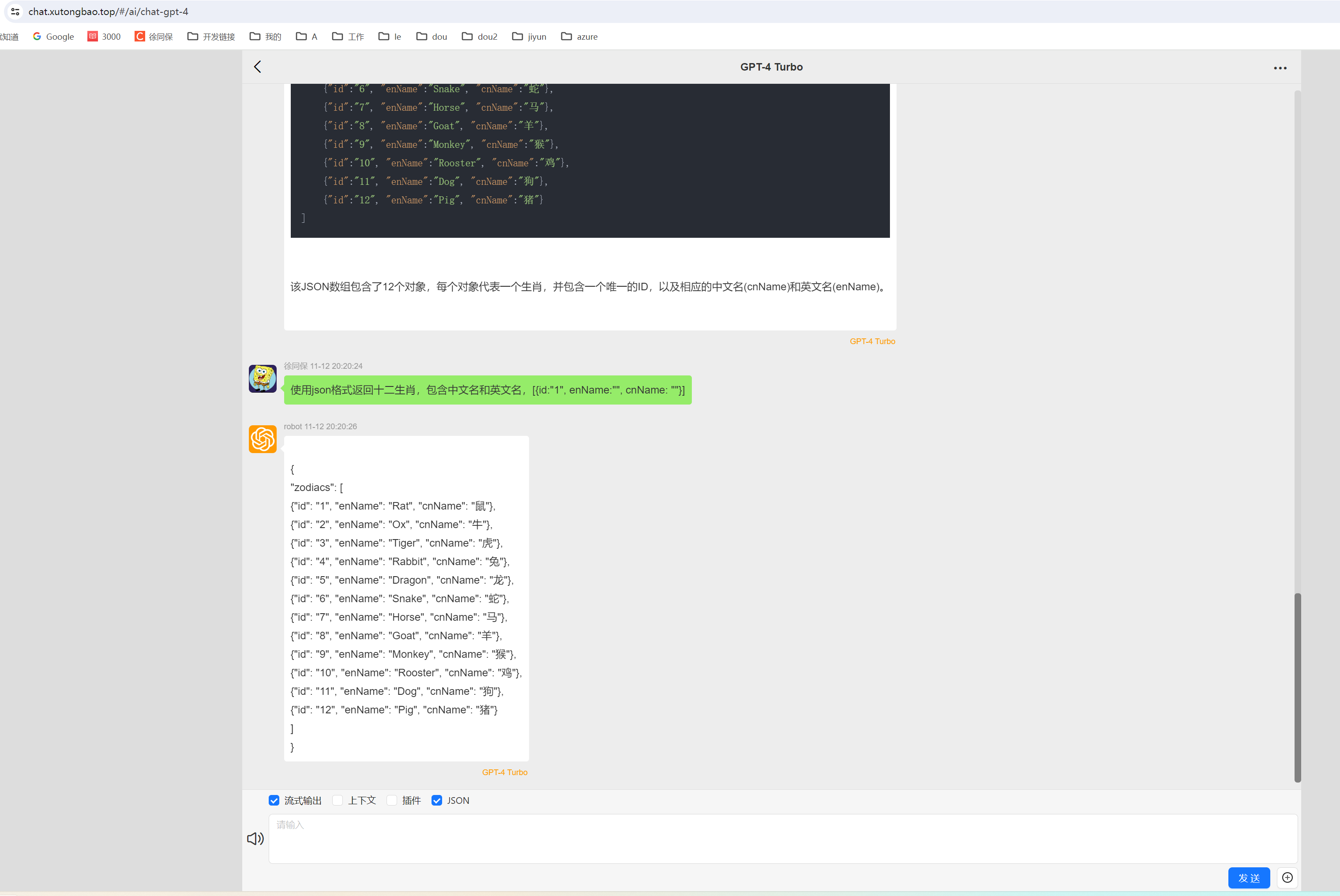
gpt支持json格式的数据返回(response_format: ‘json_object‘)
Api.h5.chatCreateChatCompletion({model: gpt-3.5-turbo-1106,token: sk-f4fe8b67-fcbe-46fd-8cc9-fd1dac5d6d59,messages: [{role: user,content:使用json格式返回十二生肖,包含中文名和英文名,[{id:"1", enName:"", cnName: &quo…...
:约束)
MySQL(13):约束
约束(constraint)概述 数据完整性(Data Integrity)是指数据的精确性(Accuracy)和可靠性(Reliability)。 它是防止数据库中存在不符合语义规定的数据和防止因错误信息的输入输出造成无效操作或错误信息 而提…...
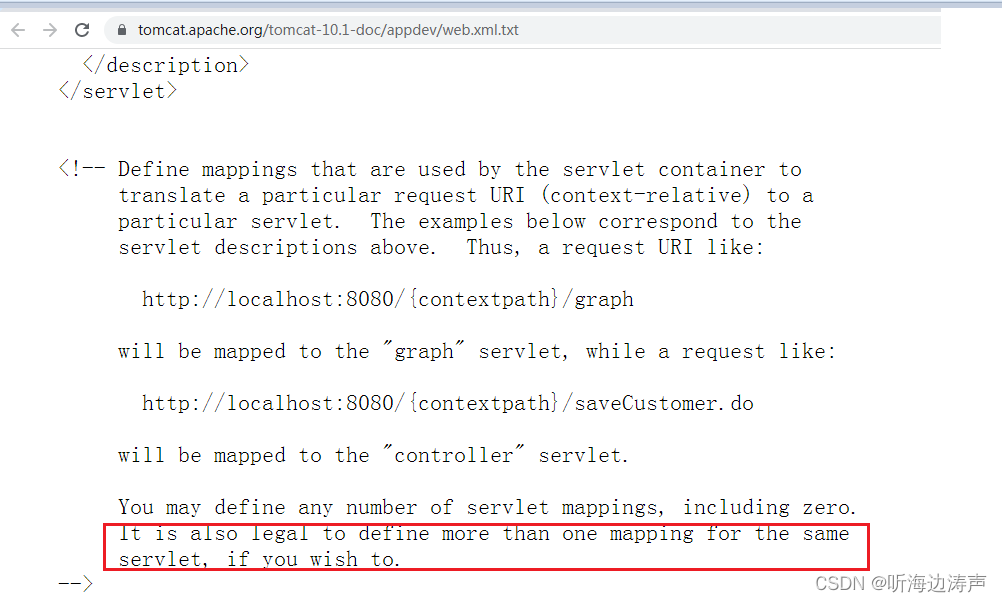
可以为一个servlet定义多个servlet-mapping、或url-pattern
在web描述符文件web.xml文件中,可以为同一个servlet定义多个servlet-mapping;也可以在同一个servlet-mapping中,定义多个url-pattern。也就是说,可以把多个地址(相对于上下文路径)映射到同一个servlet处理。…...

.net在使用存储过程中IN参数的拼接方案,使用Join()方法
有时候拼接SQL语句时,可能会需要将list中的元素都加上单引号,并以逗号分开,但是Join只能简单的分开,没有有单引号! 1.第一种拼接方案 List<string> arrIds new List<string>(); arrIds.Add("aa&qu…...
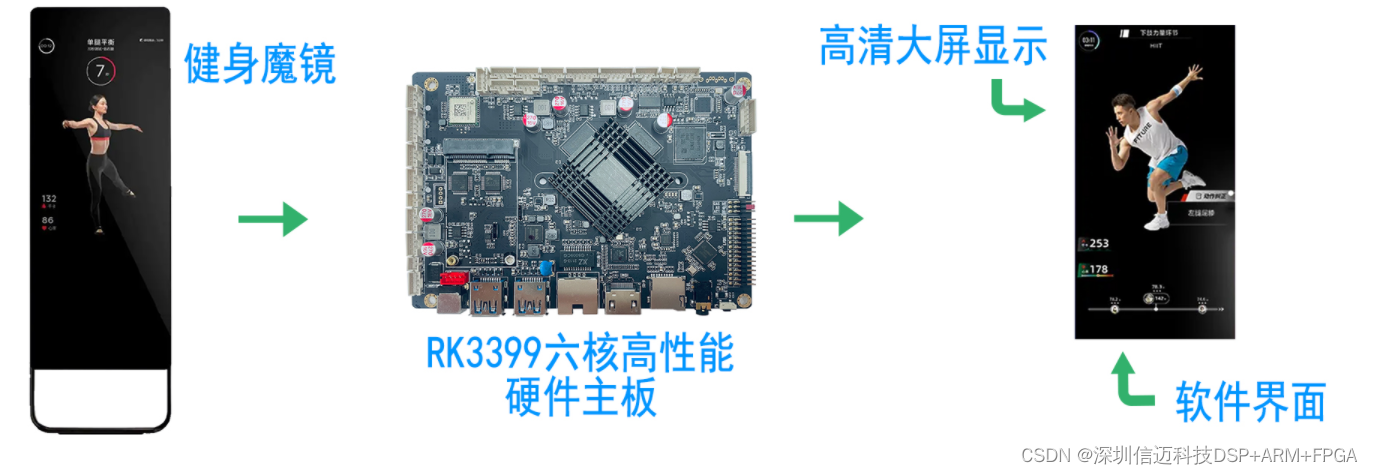
基于RK3399的室内健身魔镜方案
I 方案背景 一、健身魔镜的兴起 2020年疫情席卷全球,宅家是防疫的措施之一,因而宅家运动火爆,随之而来的宅家运动器材也风靡起来,其中包含既有颜值又具有多种功能的健身魔镜。 Ⅱ 方案介绍 一、健身魔镜的方案介绍 …...

leetCode 25.K 个一组翻转链表
给你链表的头节点 head ,每 k 个节点一组进行翻转,请你返回修改后的链表。k 是一个正整数,它的值小于 或 等于链表的长度。如果节点总数不是 k 的整数倍,那么请将最后剩余的节点保持原有顺序。你不能只是单纯的改变节点内部的值&a…...
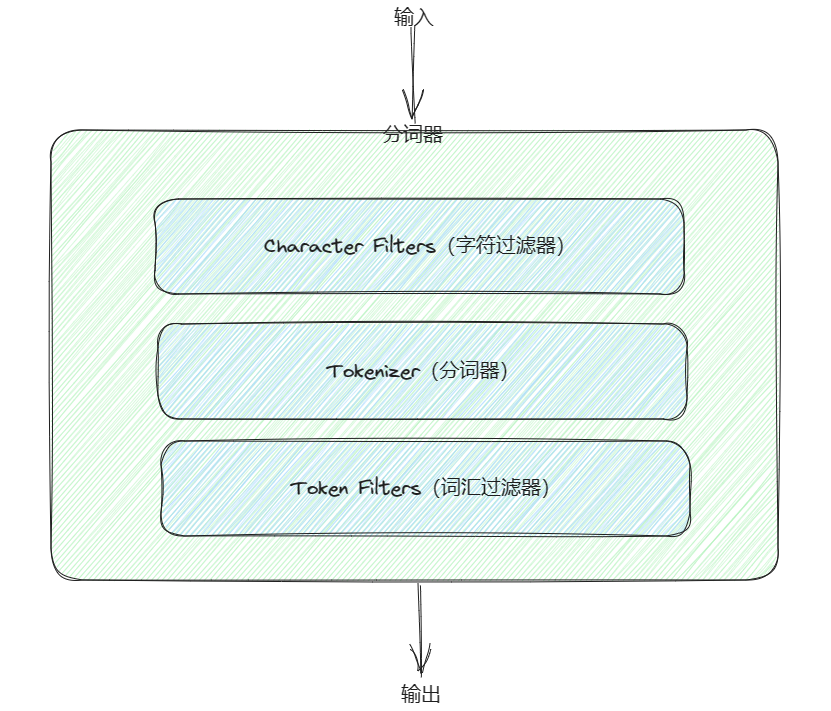
ElasticSearch中常见的分词器介绍
文章目录 ElasticSearch中常见的分词器介绍前言分词器的作用如何指定分词器分词器的组成分词器的类型标准分词器空格分词器简单分词器关键词分词器停用词分词器IK分词器NGram分词器正则匹配分词器语言分词器自定义分词器 ElasticSearch中常见的分词器介绍 前言 ElasticSearch是…...

前端案例-css实现ul中对li进行换行
场景描述: 我想要实现,在展示的item个数少于4个的时候,则排成一行,并且均分(比如说有3个,则每个的宽度为33.3%),如果item 个数大于4,则进行换行。 效果如下:…...
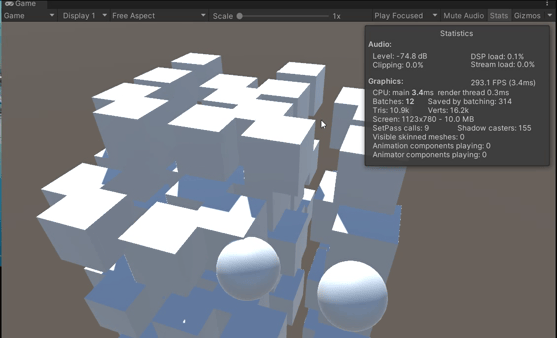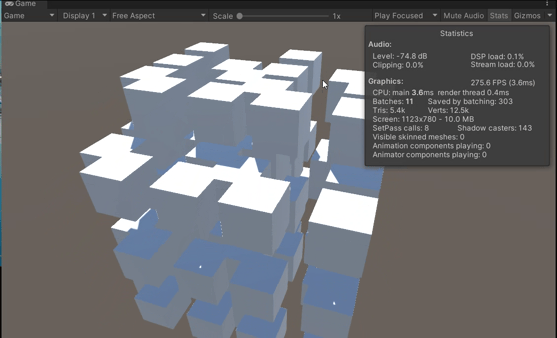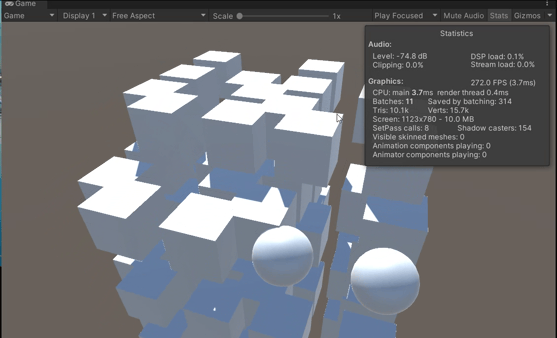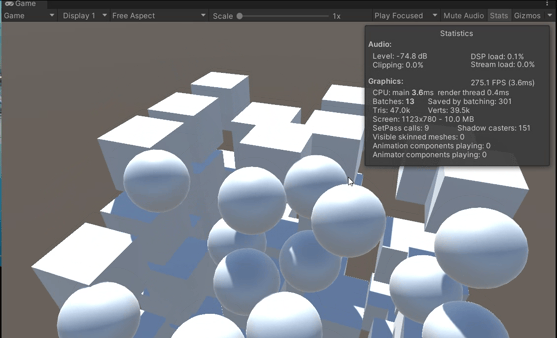
【Unity】 场景优化策略
Unity 场景优化策略 GPU instancing 使用GPU Instancing可以将多个网格相同、材质相同、材质属性可以不同的物体合并为一个批次,从而减少Draw Calls的次数。这可以提高性能和渲染效率。 GPU instancing可用于绘制在场景中多次出现的几何体,例如树木或…...

Kerberos身份认证原理与企业级排错实战指南
1. 这不是“另一个登录框”,而是一套精密运转的身份验证齿轮系统很多人第一次听说 Kerberos,是在公司内网登录邮箱或访问内部系统时,看到那个带小盾牌图标的弹窗——“正在使用 Kerberos 协议进行身份验证”。于是下意识觉得:“哦…...

销售怎么通过各种方法获取电话号码
第一种就是那个用爬虫电话号码,然后再打电话给客户。第二种是在别人的挪车电话看车挪车电话,然后再打电话找客户。第三就是。扫楼一顿顿的扫,第四就是这个那种商店,一个个的去问陌拜地推一个个的问店子要不要贷款,去问…...

新能源车轻量化为什么开始盯上高强镁合金?
续航,是悬在每一台纯电动汽车头上的达摩克利斯之剑。多充一度电、多堆一些正极材料,是一条路;但还有另一条路——把车造得更轻。 SAE(美国汽车工程师学会)的测算已经被反复引用:整车每减重100千克ÿ…...

自制极低频电流探头:负电阻补偿原理与低频方波测量实践
1. 项目概述:为极低频电流测量而生在电子测试领域,电流探头是个再常见不过的工具,无论是排查开关电源的纹波,还是分析电机驱动的波形,都离不开它。但如果你尝试用市面上常见的电流探头去观察一个频率低至几赫兹&#x…...

可解释AI新突破:基于局部帕累托最优的模型解释框架
1. 项目概述:当AI模型成为“黑箱”,我们如何撬开它?在机器学习项目里摸爬滚打十几年,我见过太多这样的场景:团队花大力气训练出一个准确率高达95%的复杂模型(比如深度神经网络),业务…...

GEO生成引擎优化:当AI成为信息分发的主角,品牌如何抢占对话窗口?
当用户不再"搜索-浏览",而是直接"AI提问-获取答案",传统SEO的逻辑正在被彻底改写。2026年,GEO(Generative Engine Optimization,生成式引擎优化)已经从概念走向规模化落地。本文从技术…...

Web渗透测试能力成长地图:从工具使用到漏洞认知跃迁
1. 这不是工具清单,而是一张Web渗透测试的“能力成长地图”你刚点开这篇文章,大概率正站在两个路口之间:一边是网上铺天盖地的“十大免费扫描器推荐”,点进去全是截图下载链接一句“一键扫漏洞”,结果装完跑两下&#…...

如何快速掌握MoveIt2:面向ROS 2开发者的工业机器人运动规划完整指南
如何快速掌握MoveIt2:面向ROS 2开发者的工业机器人运动规划完整指南 【免费下载链接】moveit2 :robot: MoveIt for ROS 2 项目地址: https://gitcode.com/gh_mirrors/mo/moveit2 想要为你的机器人实现智能运动规划吗?MoveIt2作为ROS 2生态中最强大…...

特定任务需求场景下的过约束并联机构构型设计与控制方法【附代码】
✨ 长期致力于曲面加工、构型综合、运动学和动力学建模、性能评价、多目标优化、滑模控制、鲁棒控制、视觉传感技术研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (…...

利用FTDI芯片MPSSE模式构建Arduino兼容开发环境
1. 项目概述:当FTDI芯片遇上Arduino生态如果你手头有一些闲置的FTDI USB转串口模块,比如常见的FT232R、FT2232H,或者像我一样,从某个旧设备上拆下来一块FT2232C的老古董,除了用来给单片机烧录程序或者做串口调试&#…...