OpenCV+相机校准和3D重建
相机校准至少需要10个测试图案,所需的重要输入数据是3D现实世界点集以及图像中这些点的相应2D坐标。3D点称为对象点,而2D图像点称为图像点。
准备工作
除了棋盘,我们还可以使用圆形网格。 在这种情况下,我们必须使用函数cv.findCirclesGrid()来找到模式。 较少的图像足以使用圆形网格执行相机校准。
一旦找到拐角,就可以使用cv.cornerSubPix()来提高其精度。我们还可以使用cv.drawChessboardCorners()绘制图案。
import numpy as np
import cv2 as cv
import glob
# 终止条件
criteria = (cv.TERM_CRITERIA_EPS + cv.TERM_CRITERIA_MAX_ITER, 30, 0.001)
# 准备对象点, 如 (0,0,0), (1,0,0), (2,0,0) ....,(6,5,0)
objp = np.zeros((6*7,3), np.float32)
objp[:,:2] = np.mgrid[0:7,0:6].T.reshape(-1,2)
# 用于存储所有图像的对象点和图像点的数组。
objpoints = [] # 真实世界中的3d点
imgpoints = [] # 图像中的2d点
images = glob.glob('*.jpg')
for fname in images:img = cv.imread(fname)
gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
# 找到棋盘角落
ret, corners = cv.findChessboardCorners(gray, (7,6), None)
# 如果找到,添加对象点,图像点(细化之后)
if ret == True:objpoints.append(objp)
corners2 = cv.cornerSubPix(gray,corners, (11,11), (-1,-1), criteria)
imgpoints.append(corners)
# 绘制并显示拐角
cv.drawChessboardCorners(img, (7,6), corners2, ret)
cv.imshow('img', img)
cv.waitKey(500)
cv.destroyAllWindows()
校准
现在我们有了目标点和图像点,现在可以进行校准了。我们可以使用函数cv.calibrateCamera()返回相机矩阵,失真系数,旋转和平移矢量等。
ret, mtx, dist, rvecs, tvecs = cv.calibrateCamera(objpoints, imgpoints,
gray.shape[::-1], None, None)
不失真
现在,我们可以拍摄图像并对其进行扭曲。OpenCV提供了两种方法来执行此操作。但是,首先,我们可以使用cv.getOptimalNewCameraMatrix()基于自由缩放参数来优化相机矩阵。如果缩放参数alpha = 0,则返回具有最少不需要像素的未失真图像。因此,它甚至可能会删除图像角落的一些像素。如果alpha = 1,则所有像素都保留有一些额外的黑色图像。此函数还返回可用于裁剪结果的图像ROI。
使用cv.undistort()
这是最简单的方法。只需调用该函数并使用上面获得的ROI裁剪结果即可。
使用remapping
该方式有点困难。首先,找到从扭曲图像到未扭曲图像的映射函数。然后使用重映射功能。
img = cv.imread('left12.jpg')
h, w = img.shape[:2]
newcameramtx, roi = cv.getOptimalNewCameraMatrix(mtx, dist, (w,h), 1, (w,h))
# 1
dst = cv.undistort(img, mtx, dist, None, newcameramtx)
# 剪裁图像
x, y, w, h = roi
dst = dst[y:y+h, x:x+w]
cv.imwrite('calibresult.png', dst)
# 2
mapx, mapy = cv.initUndistortRectifyMap(mtx, dist, None, newcameramtx, (w,h), 5)
dst = cv.remap(img, mapx, mapy, cv.INTER_LINEAR)
# 裁剪图像
x, y, w, h = roi
dst = dst[y:y+h, x:x+w]
cv.imwrite('calibresult.png', dst)
参数:重投影误差
重投影误差可以很好地估计找到的参数的精确程度。重投影误差越接近零,我们发现的参数越准确。给定固有,失真,旋转和平移矩阵,我们必须首先使用cv.projectPoints()将对象点转换为图像点。然后,我们可以计算出通过变换得到的绝对值和拐角发现算法之间的绝对值范数。为了找到平均误差,我们计算为所有校准图像计算的误差的算术平均值。
mean_error = 0
for i in xrange(len(objpoints)):
imgpoints2, _ = cv.projectPoints(objpoints[i], rvecs[i], tvecs[i], mtx, dist)
error = cv.norm(imgpoints[i], imgpoints2, cv.NORM_L2)/len(imgpoints2)
mean_error += error
print( "total error: {}".format(mean_error/len(objpoints)) )
姿态估计
先优化。然后使用函数cv.solvePnPRansac()计算旋转和平移。一旦有了这些变换矩阵,就可以使用它们将轴点投影到图像平面上。
for fname in glob.glob('left*.jpg'):
img = cv.imread(fname)
gray = cv.cvtColor(img,cv.COLOR_BGR2GRAY)
ret, corners = cv.findChessboardCorners(gray, (7,6),None)
if ret == True:
corners2 = cv.cornerSubPix(gray,corners,(11,11),(-1,-1),criteria)
# 找到旋转和平移矢量。
ret,rvecs, tvecs = cv.solvePnP(objp, corners2, mtx, dist)
# 将3D点投影到图像平面
imgpts, jac = cv.projectPoints(axis, rvecs, tvecs, mtx, dist)
img = draw(img,corners2,imgpts)
cv.imshow('img',img)
k = cv.waitKey(0) & 0xFF
if k == ord('s'):
cv.imwrite(fname[:6]+'.png', img)
cv.destroyAllWindows()
对极几何
首先我们需要在两个图像之间找到尽可能多的匹配项,以找到基本矩阵。为此,我们将SIFT描述符与基于FLANN的匹配器和比率测试结合使用。
import numpy as np
import cv2 as cv
from matplotlib import pyplot as plt
img1 = cv.imread('myleft.jpg',0) #索引图像 # left image
img2 = cv.imread('myright.jpg',0) #训练图像 # right image
sift = cv.SIFT()
# 使用SIFT查找关键点和描述符
kp1, des1 = sift.detectAndCompute(img1,None)
kp2, des2 = sift.detectAndCompute(img2,None)
# FLANN 参数
FLANN_INDEX_KDTREE = 1
index_params = dict(algorithm = FLANN_INDEX_KDTREE, trees = 5)
search_params = dict(checks=50)
flann = cv.FlannBasedMatcher(index_params,search_params)
matches = flann.knnMatch(des1,des2,k=2)
good = []
pts1 = []
pts2 = []
# 根据Lowe的论文进行比率测试
for i,(m,n) in enumerate(matches):
if m.distance < 0.8*n.distance:
good.append(m)
pts2.append(kp2[m.trainIdx].pt)
pts1.append(kp1[m.queryIdx].pt)
现在,我们获得了两张图片的最佳匹配列表。 让我们找到基本面矩阵。
pts1 = np.int32(pts1)
pts2 = np.int32(pts2)
F, mask = cv.findFundamentalMat(pts1,pts2,cv.FM_LMEDS)
# 我们只选择内点
pts1 = pts1[mask.ravel()==1]
pts2 = pts2[mask.ravel()==1]
接下来,我们找到Epilines。在第二张图像上绘制与第一张图像中的点相对应的Epilines。因此,在这里提到正确的图像很重要。我们得到了一行线。因此,我们定义了一个新功能来在图像上绘制这些线条。
def drawlines(img1,img2,lines,pts1,pts2):
''' img1 - 我们在img2相应位置绘制极点生成的图像
lines - 对应的极点 '''
r,c = img1.shape
img1 = cv.cvtColor(img1,cv.COLOR_GRAY2BGR)
img2 = cv.cvtColor(img2,cv.COLOR_GRAY2BGR)
for r,pt1,pt2 in zip(lines,pts1,pts2):
color = tuple(np.random.randint(0,255,3).tolist())
x0,y0 = map(int, [0, -r[2]/r[1] ])
x1,y1 = map(int, [c, -(r[2]+r[0]*c)/r[1] ])
img1 = cv.line(img1, (x0,y0), (x1,y1), color,1)
img1 = cv.circle(img1,tuple(pt1),5,color,-1)
img2 = cv.circle(img2,tuple(pt2),5,color,-1)
return img1,img2
现在,我们在两个图像中都找到了Epiline并将其绘制。
# 在右图(第二张图)中找到与点相对应的极点,然后在左图绘制极线
lines1 = cv.computeCorrespondEpilines(pts2.reshape(-1,1,2), 2,F)
lines1 = lines1.reshape(-1,3)
img5,img6 = drawlines(img1,img2,lines1,pts1,pts2)
# 在左图(第一张图)中找到与点相对应的Epilines,然后在正确的图像上绘制极线
lines2 = cv.computeCorrespondEpilines(pts1.reshape(-1,1,2), 1,F)
lines2 = lines2.reshape(-1,3)
img3,img4 = drawlines(img2,img1,lines2,pts2,pts1)
plt.subplot(121),plt.imshow(img5)
plt.subplot(122),plt.imshow(img3)
plt.show()
立体图像的深度图
import numpy as np
import cv2 as cv
from matplotlib import pyplot as plt
imgL = cv.imread('tsukuba_l.png',0)
imgR = cv.imread('tsukuba_r.png',0)
stereo = cv.StereoBM_create(numDisparities=16, blockSize=15)
disparity = stereo.compute(imgL,imgR)
plt.imshow(disparity,'gray')
plt.show()
结果受到高度噪声的污染。通过调整numDisparities和blockSize的值,可以获得更好的结果。
参数:
- texture_threshold:过滤出纹理不足以进行可靠匹配
- 区域斑点范围和大小:基于块的匹配器通常会在对象边界附近产生“斑点”,其中匹配窗口捕获一侧的前景和背景
- 在另一场景中,匹配器似乎还在桌子上投影的纹理中找到小的虚假匹配项。为了消除这些伪像,我们使用由speckle_size和speckle_range参数控制的散斑滤镜对视差图像进行后处理。speckle_size是将视差斑点排除为“斑点”的像素数。speckle_range控制必须将值差异视为同一对象的一部分的程度
- 视差数量:滑动窗口的像素数。它越大,可见深度的范围就越大,但是需要更多的计算
- min_disparity:从开始搜索的左像素的x位置开始的偏移量
- uniqueness_ratio:另一个后过滤步骤。如果最佳匹配视差不足够好于搜索范围中的所有其他视差,则将像素滤出。如果texture_threshold和斑点过滤仍在
- 通过虚假匹配,则可以尝试进行调整
- prefilter_size和prefilter_cap:预过滤阶段,可标准化图像亮度并增强纹理,以准备块匹配
- 通常,你不需要调整这些
相关文章:

OpenCV+相机校准和3D重建
相机校准至少需要10个测试图案,所需的重要输入数据是3D现实世界点集以及图像中这些点的相应2D坐标。3D点称为对象点,而2D图像点称为图像点。 准备工作 除了棋盘,我们还可以使用圆形网格。 在这种情况下,我们必须使用函数cv.find…...

2023.11.14-hive之表操作练习和文件导入练习
目录 需求1.数据库基本操作 需求2. 默认分隔符案例 需求1.数据库基本操作 -- 1.创建数据库test_sql,cs1,cs2,cs3 create database test_sql; create database cs1; create database cs2; create database cs3; -- 2.1删除数据库cs2 drop database cs2; -- 2.2在cs3库中创建…...
idea2023启动springboot项目如何指定配置文件
方法一: 方法二: 举例:...
在 uniapp 中 一键转换单位 (px 转 rpx)
在 uniapp 中 一键转换单位 px 转 rpx Uni-app 官方转换位置利用【px2rpx】插件Ctrl S一键全部转换下载插件修改插件 Uni-app 官方转换位置 首先在App.vue中输入这个: uni.getSystemInfo({success(res) {console.log("屏幕宽度", res.screenWidth) //屏…...

SQL对数据进行去重
工作中使用SQL对数据进行处理计算时可能会遇到这样的问题;读取的表数据会有重复,或者我们关注的几个字段的数据会有重复,直接使用原表数据会引起计算结果不准或者做表连接时产生笛卡尔积。 本文记录使用SQL进行数据去重的几种算法。 distinc…...
登录注册代码模板(Vue3+SpringBoot)[邮箱发送验证码(HTML)、RSA 加密解密(支持长文本)、黑暗与亮色主题切换、AOP信息校验]
文章归档:https://www.yuque.com/u27599042/coding_star/cx5ptule64utcr9e 仓库地址 https://gitee.com/tongchaowei/login-register-template 网页效果展示 相关说明 在该代码模板中,实现了如下功能: 邮箱发送验证码(邮件内容…...

【计算机网络】VRRP协议理论和配置
目录 1、VRRP虚拟路由器冗余协议 1.1、协议作用 1.2、名词解释 1.3、简介 1.4、工作原理 1.5、应用实例 2、 VRRP配置 2.1、配置命令 2.2、拓扑与配置: 1、VRRP虚拟路由器冗余协议 1.1、协议作用 虚拟路由冗余协议(Virtual Router Redundancy Protocol&am…...
ubuntu操作系统的docker更换存储目录
前言 要将Docker的存储目录更改为/home/docker,你需要进行以下步骤: 目录 前言1、停止Docker服务2、创建新的存储目录3、编辑Docker配置文件4、启动Docker服务5、验证更改 1、停止Docker服务 首先停止Docker守护进程,可以使用以下命令&…...

【人工智能Ⅰ】6-机器学习之分类
【人工智能Ⅰ】6-机器学习之分类 6-1 机器学习在人工智能中的地位 学习能力是智能的本质 人工智能 > 机器学习 > 深度学习 什么是机器学习? baidu:多领域交叉学科(做什么) wiki:the study of algorithms and…...

本地部署_语音识别工具_Whisper
1 简介 Whisper 是 OpenAI 的语音识别系统(几乎是最先进),它是免费的开源模型,可供本地部署。 2 docker https://hub.docker.com/r/onerahmet/openai-whisper-asr-webservice 3 github https://github.com/ahmetoner/whisper…...

秋招求职经验分享
0.个人简介 2023年10月底,最终拿到了海康威视、汇川技术等十余家公司的Offer,最终签了自己心仪的Offer,秋招对我来说算是正式结束了,写个博客纪念一下,顺便分享以下秋招的经验,为后来人求职提供一些参考。…...
DNS域名解析
目录 1.概述 1.1产生原因 1.2作用 1.3连接方式 1.4因特网的域名结构 1.4.1拓扑 1.4.2分类 1.4.3域名服务器类型划分 2. DNS域名解析过程 2.1分类 2.2解析图 2.2.2过程分析 3.搭建DNS域名解析服务器 3.1.概述 3.2安装软件 3.3bind服务中三个关键文件 3.4主配置…...

Flink SQL --命令行的使用(02)
1、窗口函数: 1、创建表: -- 创建kafka 表 CREATE TABLE bid (bidtime TIMESTAMP(3),price DECIMAL(10, 2) ,item STRING,WATERMARK FOR bidtime AS bidtime ) WITH (connector kafka,topic bid, -- 数据的topicproperties.bootstrap.servers m…...
)
【nlp】1.3 文本数据分析(标签数量分布、句子长度分布、词频统计与关键词词云)
文本数据分析 1 文本数据分析介绍2 数据集说明3 获取标签数量分布4 获取句子长度分布5 获取正负样本长度散点分布6 获取不同词汇总数统计7 获取训练集高频形容词词云8 获取验证集形容词词云1 文本数据分析介绍 文本数据分析的作用: 文本数据分析能够有效帮助我们理解数据语料…...
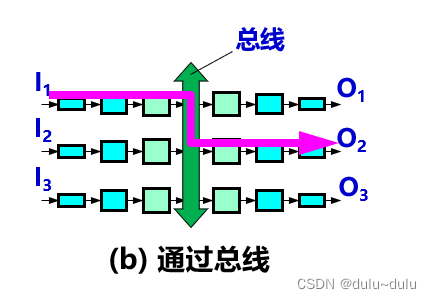
路由器的结构以及工作原理
目录 路由器的结构 交换结构三种常用的交换方式 1.通过存储器 2.通过总线 3.通过纵横交换结构(crossbar switch fabric) 路由器的结构 路由器结构可划分为两大部分:路由选择部分,分组转发部分 路由选择部分也叫做控制部分&…...
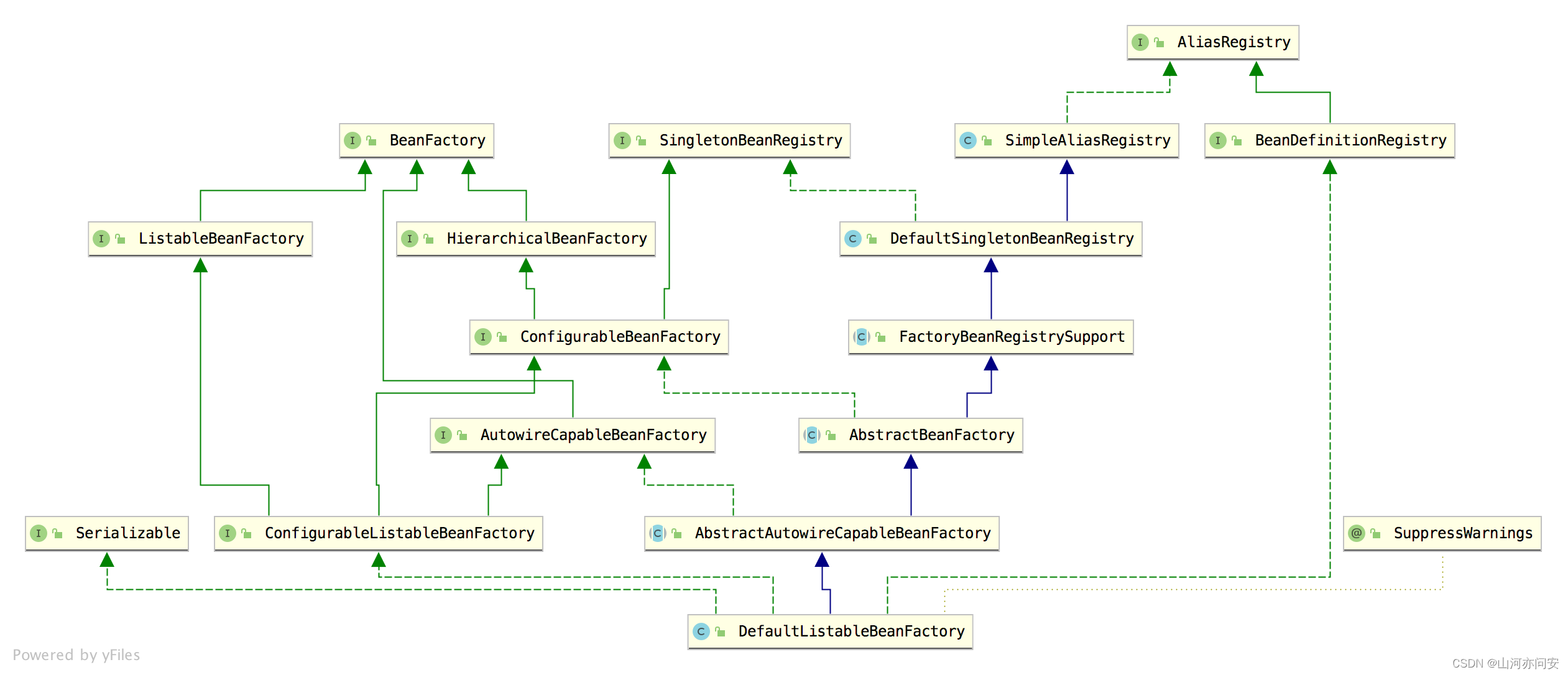
DefaultListableBeanFactory
DefaultListableBeanFactory 是一个完整的、功能成熟的 IoC 容器,如果你的需求很简单,甚至可以直接使用 DefaultListableBeanFactory,如果你的需求比较复杂,那么通过扩展 DefaultListableBeanFactory 的功能也可以达到,…...

NSF服务器
目录 1.简介 1.1 NFS背景介绍 1.2 生产应用场景 2.NFS工作原理 2.1 实例图 2.2 流程 3.NFS的使用 3.1.安装 3.2.配置文件 3.3.主配置文件分析 3.4 实验 服务端: 客户端: 3.5.NFS账户映射 3.5.1.实验2 3.5.2.实验3 4.autofs自动挂载服务…...

10 Go的映射
概述 在上一节的内容中,我们介绍了Go的结构体,包括:定义结构体、声明结构体变量、使用结构体、结构体关联函数、new、组合等。在本节中,我们将介绍Go的映射。Go语言中的映射(Map)是一种无序的键值对集合&am…...

瑞萨e2studio(29)----SPI速率解析
瑞萨e2studio.29--SPI速率解析 概述视频教学时钟配置解析RA4M2的BRR值时钟速率7.5M下寄存器值3K下寄存器值 概述 在嵌入式系统的设计中,串行外设接口(SPI)的通信速率是一个关键参数,它直接影响到系统的性能和稳定性。瑞萨电子的…...
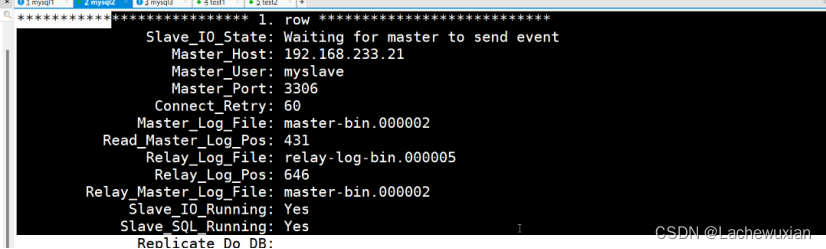
mysql的主从复制,读写分离
主从复制:主mysql的数据,新增,修改,表里的数据都会同步到从mysql上 主从复制的模式: 1 异步复制 mysql 的最常用的复制,只要执行完,客户端提交事务,主mysql 会立即把结果返回给从…...

SwitchyOmega+Burp无感抓包实战:解决HTTPS拦截与流量路由难题
1. 为什么“无感抓包”是BurpSuite日常使用的分水岭刚接触Web安全测试的朋友常有个错觉:装上Burp Suite,配好代理,打开浏览器,点几下网页——流量就该自动进来了。结果现实是:首页打不开、登录态丢失、HTTPS报错满屏、…...

MBTI性格测试
简介 MBTI(Myers‑Briggs Type Indicator,迈尔斯‑布里格斯类型指标)是基于荣格心理类型理论发展出的性格类型工具,由凯瑟琳库克布里格斯及其女儿伊莎贝尔布里格斯迈尔斯创建。它通过四对偏好维度将个体的认知与行为倾向归纳为 16…...
)
Postgresql基础实践教程(八)
⭐️⭐️⭐️⭐️⭐️ 完整数据详见 练习数据免费 ⭐️⭐️⭐️⭐️⭐️ 六十九、查找会员ID 27的向上推荐链 问题 查找会员ID 27的向上推荐链:即推荐该会员的人,以及推荐那个人的人,依此类推。返回会员ID、名字和姓氏。按会员ID降序排列。…...

CausalVLR基准测试报告:在IU X-Ray和MIMIC-CXR数据集上的性能分析
CausalVLR基准测试报告:在IU X-Ray和MIMIC-CXR数据集上的性能分析 【免费下载链接】CausalVLR CausalVLR: A Toolbox and Benchmark for Vision-Language Causal Reasoning (多模态因果推理开源框架) 项目地址: https://gitcode.com/gh_mirrors/ca/CausalVLR …...

3分钟快速安装BetterNCM插件管理器,让你的网易云音乐功能翻倍
3分钟快速安装BetterNCM插件管理器,让你的网易云音乐功能翻倍 【免费下载链接】BetterNCM-Installer 一键安装 Better 系软件 项目地址: https://gitcode.com/gh_mirrors/be/BetterNCM-Installer 还在为网易云音乐功能单一而烦恼吗?想要解锁更多个…...
)
别再只用鼠标了!用Leap Motion手势控制Unity游戏,保姆级配置避坑指南(2024版)
2024年Unity手势交互开发实战:Leap Motion从配置到游戏逻辑全解析在游戏开发领域,交互方式的创新往往能带来全新的体验。想象一下,玩家不再需要键盘鼠标,仅凭自然的手部动作就能操控游戏角色——这正是Leap Motion手势识别技术为U…...

Nacos CVE-2021-29441漏洞深度解析:User-Agent绕过与鉴权失效
1. 这个漏洞不是“改个Header就能登录”,而是Nacos鉴权体系的一道裂缝CVE-2021-29441这个编号在Nacos社区里曾被轻描淡写地归为“低危”,直到我接手一个金融客户线上告警——他们的Nacos集群在凌晨三点被批量创建了37个高权限用户,所有操作日…...
)
保姆级教程:手把手教你搞定ESXi 6.7安装前的BIOS设置(VT-x/VT-d/AES全开)
从零开始:ESXi 6.7安装前的BIOS设置终极指南当你第一次接触企业级虚拟化平台时,那种既兴奋又忐忑的心情我完全理解。作为过来人,我记得自己第一次在Dell PowerEdge服务器上安装ESXi时,光是搞清楚BIOS里那些晦涩的选项就花了整整一…...

独立开发者利用taotoken模型广场为不同任务选择性价比最优模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者利用taotoken模型广场为不同任务选择性价比最优模型 对于独立开发者而言,在有限的预算内高效完成多样化的开…...

公共卫生机器学习项目中的算法公平性实践:ACAR框架详解
1. 项目概述:当机器学习遇见公共卫生,公平性为何成为“必答题”?在公共卫生领域,机器学习(ML)正以前所未有的速度渗透到疾病监测、风险分层和资源分配等核心环节。想象一下,一个模型被用来预测某…...