mysql的主从复制,读写分离
主从复制:主mysql的数据,新增,修改,表里的数据都会同步到从mysql上
主从复制的模式:
1 异步复制
mysql 的最常用的复制,只要执行完,客户端提交事务,主mysql 会立即把结果返回给从服务器,主服务器并不关心从mysql是否接收是否处理,主一旦崩溃,主mysql的事务可能没有传到从MySQL,这个时候强行把从提升为主,可能到新mysql的数据不完整
2全同步复制
主库完成一个事务,所有的从库执行了该事物,才会返回给客户端,因为要等待所有从库全部执行完成,性能必须下降(适用于对数据一致性,和数据完整性很好的场景)
3 半同步复制
介于异步和全同步复制之后,主库执行完一个客户端的事务之后,至少等待一个库的接收完成之后,才会返回给客户端,半同步在一定程度上提高了数据的安全性,也会有一定的延迟延迟一般是个tcp、IP的往返时间(从发送到接收的时间,单位是是毫秒)半同步复制用在网络电视上,时间<1ms:round-trip time RTT
实验架构:
主从复制 和读写分离
Mysql1 主192.168.233.21
Mysql2 从 192.168.233.22
Mysql3 从192.168.233.23
Test1读写分离的服务器 amoeba 192.168.233.10
Test5 客户端 192.168.233.20
#关闭防火墙和安全机制
systemctl stop firewalld
setenforce 0
#设置主从服务器的时间同步工具
yum -y install ntp

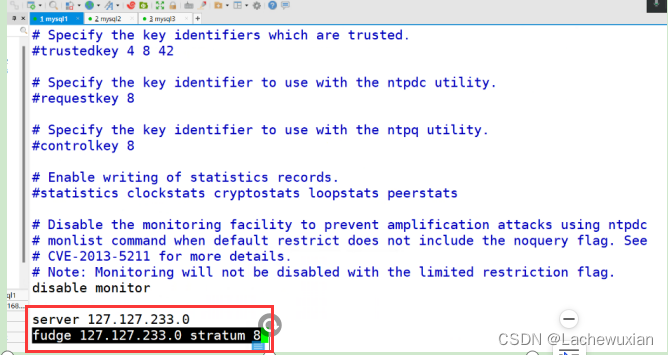
#主服务器上本地设置时钟源,注意网段修改
#设置时间层级为8(限制在15秒内)
#数字越小表示时钟源越精确。通常,
本地时钟源被设置为较高的 stratum 等级(例如,8)以表示它不是通过网络获取的,
而是本地的。
vim /etc/ntp.conf
systemctl restart ntpd

#从服务器设置
systemctl restart ntpd
#2台从服务器分别指向源服务器
/usr/sbin/ntpdate 192.168.233.21

#2台从服务器分别新建一个定时任务
crontab -e -u root


#3台主机的时间同时查看是否一致
date

#主mysql主服务器开启二进制日志,允许从服务器复制数据时,可以从主的二进制写到自己的二进制日志当中
vim /etc/my.cnf
systemctl restart mysqld

#进入主服务器的mysql的数据库
mysql -u root -p123456

##新建一个用户授权给从服务器授权
grant replication slave on *.* to 'myslave'@'192.168.233.%' indendified by '123456';


#查看主服务器的状态,查看position是多少
show master status;

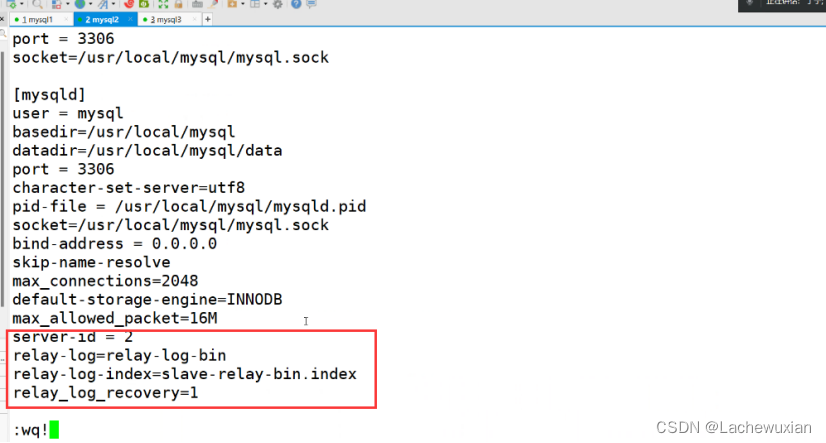
##修改从服务器的的mysqld ,注意id master 和两个slave的id 也要不同
vim /etc/my.cnf
systemctl restart mysqld
Server-id = 2
Relay-log=relay-log-bin
Relay-log-index=slave-relay-bin.index
Relay_log_recovery=1
默认是0 1开启中继日志的服务器,从服务器出现异常或者崩溃时,从服务器会从主服务器的二进制争取和应用中继日志同步
Server-id = 3
Relay-log=relay-log-bin
Relay-log-index=slave-relay-bin.index
Relay_log_recovery=1
第一台从id 是 2
第二台id是3
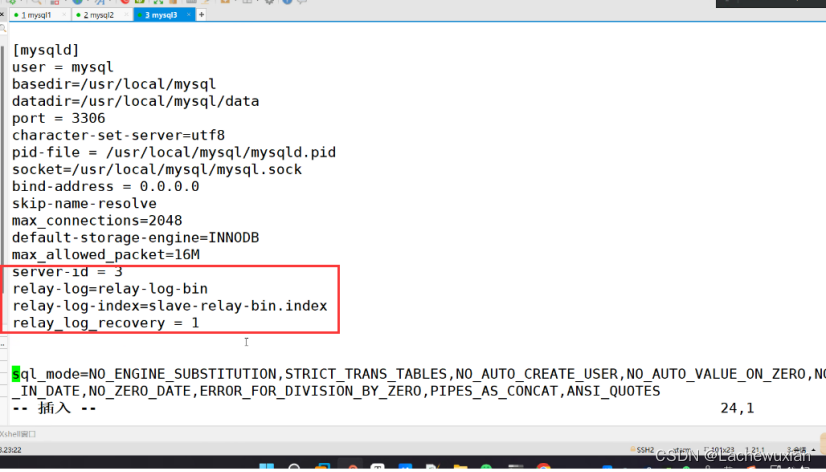
##2台服务器进入musql数据库
mysql -u root -p123456
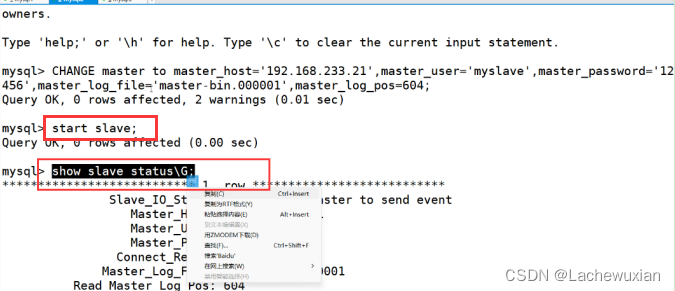
#配置同步,注意 master_log_file 和 master_log_pos 的值要与Master查询的一致
CHANGEmastertomaster_host='192.168.233.21',master_user='myslave',master_password='123456',master_log_file='master-bin.000001',master_log_pos=604;


2台从服务器操作
#启动同步,如有报错执行reset slave;
start slave;
#查看slave 状态
Slave_io_running:yes 负责和主库的io通信
Slave_sql running:yes 负责自己的slave mysql进程
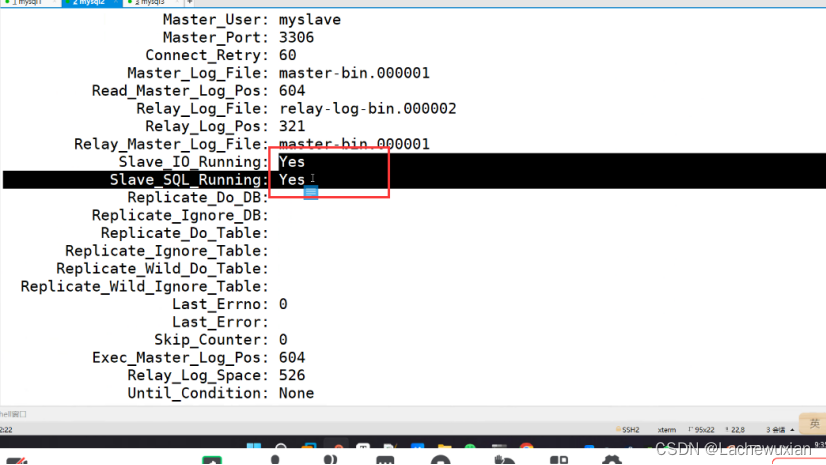
##这里 如果报错显示是 slave io running:no
1 网络问题
2 my.cnf 配置文件写错了
3 密码、file文件名、pos偏移量不对
4 防火墙没有关闭
##验证主从复制是否成功
在主服务器上创建一个表,两个从也有表
mysql 的主从复制延迟
原因:
网络延迟
主从硬件设备导致(CPU主频,内存IO,硬盘IO)
同步复制,而不是异步复制
解决方案:
1硬件方面
从库配置更好的硬件,提升随机写的性能,比如原本是机械盘,可以考虑更换为ssd固态。升级核心数更强的cpu,加大内存,避免使用虚拟云主机,使用物理机
2 网络方面
将从库分布在相同局域网内或者网路延迟较小的中,尽量避免夸机房,扩网域进行主从服务器的配置
3 架构方面
在事务中尽量对主库读写,其他事物的读在从库中,消除一部分延迟带来的数据库不一致,增加缓存降低一些从库的负载。
4 mysql 的服务配置方面
该配置针对mysql主从复制性能优化最大化,安全性并不高,如果从安全的角度考虑的话,就要设置双一设置
追求安全性的双一设置:
innodb_flush_log_at_trx_commit=1
0: 事务提交时不刷新事务日志,而是每秒进行一次日志刷新,这可以提高性能,但在发生故障时可能会导致数据丢失
1:默认值 每次事务提交都会刷新日志,确保事务的持久性,这提供了最高级别的数据安全性,但可能会影响性能
2 事务提交时将四五日志写入操作系统缓存中,但不进行物理刷新,这提供了一定的数据安全性和性能
sync_binlog=1
0: 二进制日志写入操作系统缓存,但不进行物理刷新,这提高了最高性能,但在发生故障时可能会导致数据丢失
1 :默认值,每次提交事务都会二进制日志刷新到磁盘,以确保日志的持久性,这提供了较高级别的数据安全性
N:每次事务提交时,将二进制日志刷新到磁盘,但是最多每N个事务执行一次物理刷新,这在某些情况下可以提高性能,但是在发生故障时可能会导致少量数据丢失
追求性能化设置:
sync_binlog=0:
设置为0表示二进制日志(binary log)写入操作系统缓存,但不进行物理刷新。
这提供了较高的性能,但在系统崩溃或断电时可能会导致未刷新的二进制日志数据的丢失。
innodb_flush_log_at_trx_commit=2:
设置为2表示事务提交时将事务日志写入操作系统缓存,但不进行物理刷新。
这提供了一定的性能提升,但在系统崩溃或断电时可能会导致未刷新的事务日志数据的丢失。
logs-slave-updates=0:
如果设置为0,表示不将从库的更新写入二进制日志。
这对于避免在主从复制中引入循环复制(circular replication)很有用。
增大 innodb_buffer_pool_size:
innodb_buffer_pool_size 控制 InnoDB 存储引擎的缓冲池大小。增大这个值可以提高 InnoDB 的性能,
因为更多的数据和索引可以缓存在内存中,减少了对磁盘的访问次数。但要注意,
设置得太大可能导致系统内存不足。
主从复制的工作过程:
1 主节点的数据记录发生变化,都会记录到二进制日志
2 slave节点会在一定时间内对主库的二进制文件进行探测,看是否发生 变化,开启一个I/O的线程,请求到主库的二进制事件
3 主库会把每一个I/O的线程启动一个dump,用于发送二进制事件给从库,从库通过I/O线程获取更新,slave sql 负责更新写入到从库本地,实现主从一致
主从复制问题:
1 只能在主库发生变化,然后同步到从
2 复制过程是串行化过程,在从库上时复制串行的,主库的更新不能从从库上操作。
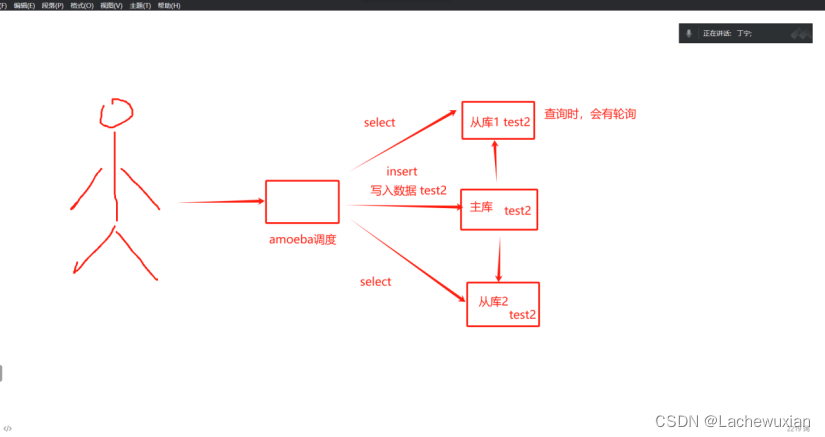
3 主从涉及的目的就是为了在主库上写,在从库上查,读写分离实现高可用
读写分离:
要实现读写分离,必须要实现主从复制
读写分离:所有的写入操作都在主库,从库只负责读(select)r如果有更新是从主库到从库
为什么要有读写分离:
1 数据库在写入数据时比较耗时
2 但是读的速度很快
读写分离之后数据库的写入和读取是分开,哪怕写入的数据量比较大,也不影响查询的效率。
什么场景下需要读写分离:
数据库不是一定要读写分离的,只有在某些程序的使用数据库中, 更新少查询的较多,或者读写读写需求差不多的情况下,会考虑读写分离
生产中一般都会读写分离
测试库一般不用
在工作中,数据库都会做读写分离,数据库的读写不在同一个库完成,否则不能实现高可用,高并发,
mysql读写分离的原理:
1 根据脚本实现,在代码中实现路由分类,select insert 进行路由分类,这种方式最多的,性能好,在代码中可以实现,不需要额外的设备
缺点:开发实现的和我们无关,如果是大型复杂的应用,涉及改动的代码非常多
2 基于中间代理层实现
mysql-proxy自带的开源项目,基于自带的java脚本,这些脚本不是现成的,要自己写,不熟悉他的内置变量,写不出来,
atlas 360 内部多自己使用的代理工具,每天的读写请求载量可以达到几十亿条,支持事务支持存储的过程,
amoeba 陈思儒是由Java开发的一个开源团建,不支持事务,也不支持存储过程
搭建MySQL读写分离
注:做读写分离实验之前必须有一主两从环境
Mysql1 主192.168.233.21
Mysql2 从 192.168.233.22
Mysql3 从192.168.233.23
Test1读写分离的服务器 amoeba 192.168.233.10
Test5 客户端 192.168.233.20
jdk1.5开发的官方推荐我们使用1.5.1.6
amoeba 服务器配置
##安装java环境
因为amoeba是基于jdk1.5开发的,所有官方推荐使用jdk1.5/jdk1.6版本,高版本不建议使用,
cd /opt/
cp jdk-6u14-linux-x64.bin /usr/local/
cd /usr/local/
chmod +x jdk-6u14-linux-x64.bin
./jdk-6u14-linux-x64.bin
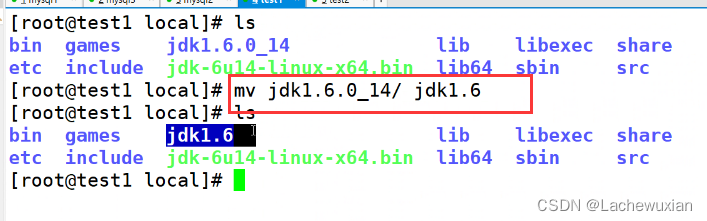
//按yes,按enter
mv jdk1.6.0_14/ /usr/local/jdk1.6
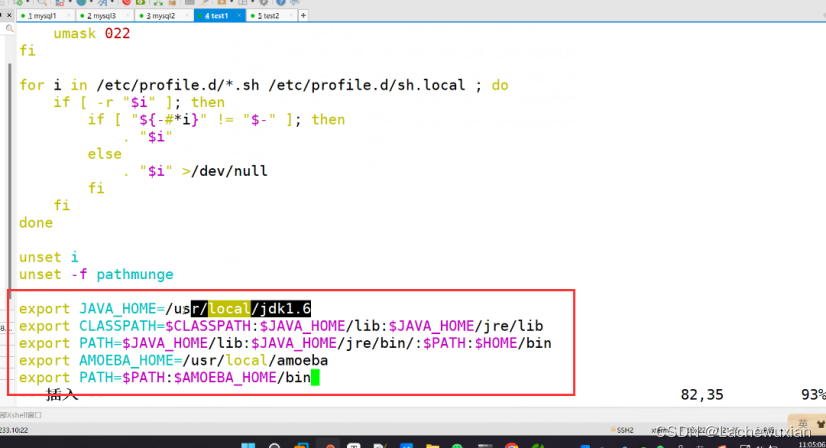
vim /etc/profile
export JAVA_HOME=/usr/local/jdk1.6
export CLASSPATH=$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export PATH=$JAVA_HOME/lib:$JAVA_HOME/jre/bin/:$PATH:$HOME/bin
export AMOEBA_HOME=/usr/local/amoeba
export PATH=$PATH:$AMOEBA_HOME/bin
source /etc/profile
java -version


##安装 Amoeba软件##
mkdir /usr/local/amoeba
tar zxvf amoeba-mysql-binary-2.2.0.tar.gz -C /usr/local/amoeba/
chmod -R 755 /usr/local/amoeba/
/usr/local/amoeba/bin/amoeba
//如显示amoeba start|stop说明安装成功
##配置 Amoeba读写分离,两个 Slave 读负载均衡##
#先在Master、Slave1、Slave2 的mysql上开放权限给 Amoeba 访问
grant all on *.* to amoeba@'192.168.233.%' identified by '123456';
flush privileges;





###再回到amoeba服务器配置amoeba服务:
cd /usr/local/amoeba/conf/
cp amoeba.xml amoeba.xml.bak
vim amoeba.xml #修改amoeba配置文件
--30行--
<property name="user">amoeba</property>
--32行--
<property name="password">123456</property>
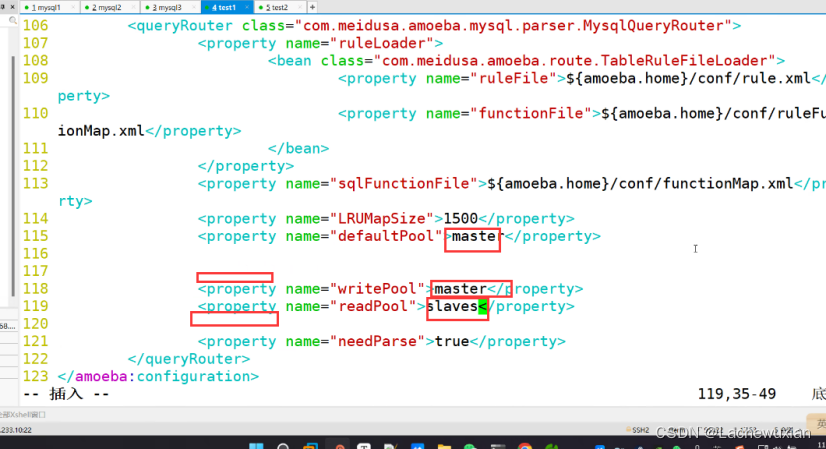
--115行--
<property name="defaultPool">master</property>
--117-去掉注释-
<property name="writePool">master</property>
<property name="readPool">slaves</property>
cp dbServers.xml dbServers.xml.bak
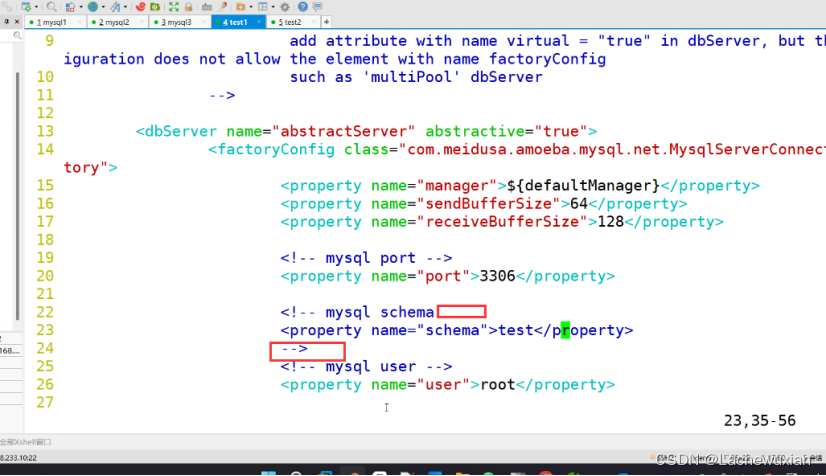
vim dbServers.xml #修改数据库配置文件
--23行--注释掉 作用:默认进入test库 以防mysql中没有test库时,会报错
<!-- <property name="schema">test</property> -->
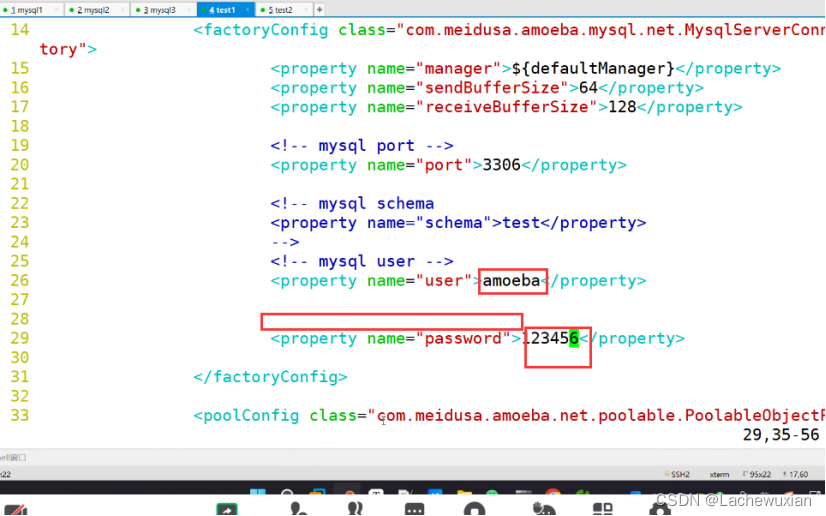
--26--修改
<property name="user">amoeba</property>
--28-30--去掉注释
<property name="password">123456</property>
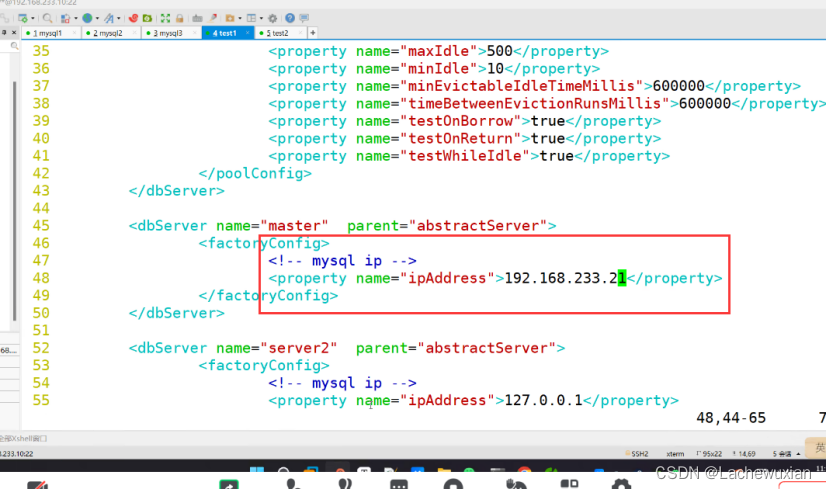
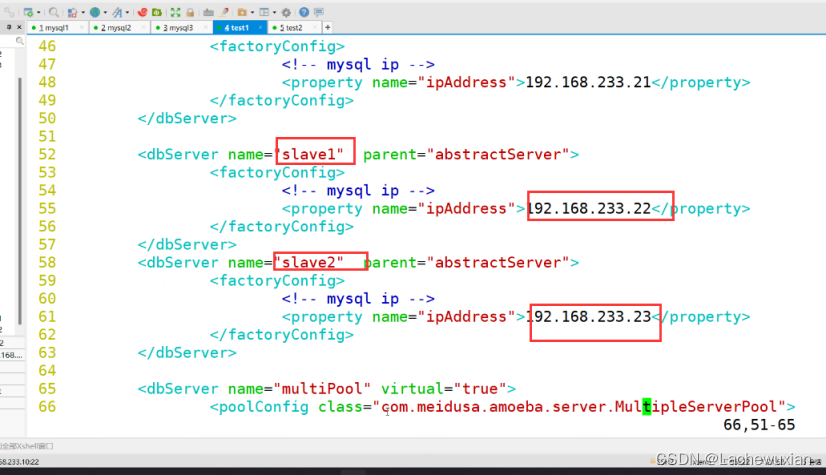
--45--修改,设置主服务器的名Master
<dbServer name="master" parent="abstractServer">
--48--修改,设置主服务器的地址
<property name="ipAddress">192.168.233.21</property>
--52--修改,设置从服务器的名slave1
<dbServer name="slave1" parent="abstractServer">
--55--修改,设置从服务器1的地址
<property name="ipAddress">192.168.233.22</property>
--58--复制上面6行粘贴,设置从服务器2的名slave2和地址
<dbServer name="slave2" parent="abstractServer">
<property name="ipAddress">192.168.233.23</property>
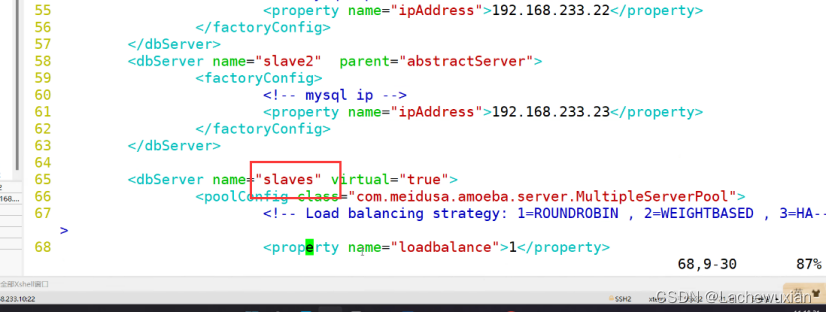
--65行--修改
<dbServer name="slaves" virtual="true">
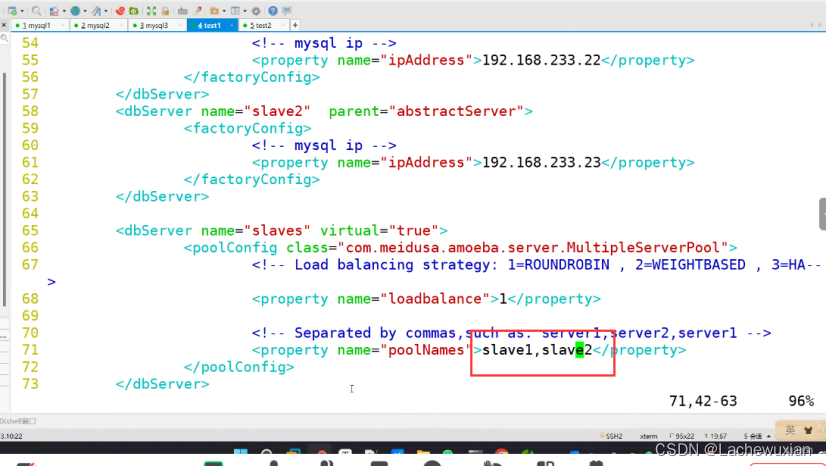
--71行--修改
<property name="poolNames">slave1,slave2</property>
/usr/local/amoeba/bin/amoeba start & #启动Amoeba软件,按ctrl+c 返回
netstat -anpt | grep java #查看8066端口是否开启,默认端口为TCP 8066
配置用户信息




![]()
少个图
----测试读写分离 ----
yum install -y mariadb-server mariadb
systemctl start mariadb.service
#在主从服务器上开启查询日志
general_log=ON
general_log_file=/usr/local/mysql/data/mysql_general.log
在客户端服务器上测试:
mysql -u amoeba -p123456 -h 192.168.233.10 -P8066
//通过amoeba服务器代理访问mysql ,在通过客户端连接mysql后写入的数据只有主服务会记录,然后同步给从--从服务器
在主服务器上:
use db_test;
create table test (id int(10),name varchar(10),address varchar(20));
在两台从服务器上:
stop slave; #关闭同步
use db_test;
//在slave1上:
insert into test values('1','zhangsan','this_is_slave1');
//在slave2上:
insert into test values('2','lisi','this_is_slave2');
//在主服务器上:
insert into test values('3','wangwu','this_is_master');
//在客户端服务器上:
use db_test;
select * from test; //客户端会分别向slave1和slave2读取数据,显示的只有在两个从服务器上添加的数据,没有在主服务器上添加的数据
insert into test values('4','qianqi','this_is_client'); //只有主服务器上有此数据
//在两个从服务器上执行 start slave; 即可实现同步在主服务器上添加的数据
start slave;
少了个图





面试题:
1 主从复制的原理
2 读取分离的实现方式: 脚本,amoeba实现,mycat实现
通过amoeba代理服务器,实现只在主服务器上写,只在从服务器上读;
主数据库处理事务性查询,从数据库处理select 查询;
数据库复制被用来把事务查询导致的变更同步的集群中的从数据库
3如何查看主从复制时候否成功?
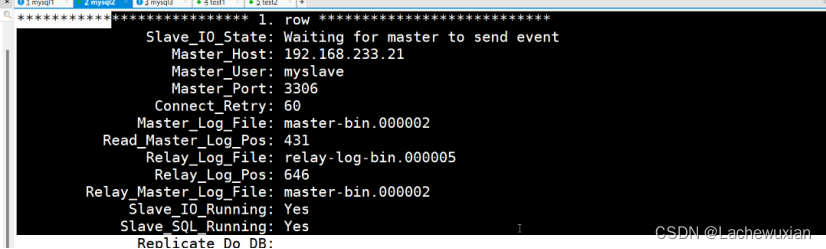
在从服务器上内输入 show slave status\G 查看主从信息查看里面有IO线程的状态信息,还有master服务器的IP地址、端口事务开始号。
当 Slave_IO_Running和Slave_SQL_Running都是YES时 ,表示主从同步状态成功


4 如果slave_IO_running no 排查思路?
大概率是配置文件出错
首先排查网络问题,使用ping 命令查看从服务器是否能与主服务器通信
再查看防火墙和核心防护是否关闭(增强功能)
接着查看从服务slave是否开启
两个从服务器的server-id 是否相同导致只能连接一台
master_log_file master_log_pos的值跟master值是否一致
5 show slave status\G;能看到的信息有哪些
IO和sql的线程状态信息
MASTER服务的ip 地址,端口事务开始的位置
最近一次的错误信息,和错误的位置
最近一次IO 报错信息
最近i一次sql的报错信息
6 主从复制的延迟如何解决?
主服务器的负载过大,被多个睡眠或 僵尸线程占用 导致系统负载过大,从库硬件比主库差,导致复制延迟
主从复制单线程,如果主库写作并发太大,来不及传送到从库,就会到导致延迟
慢sql语句过多
网络延迟
相关文章:
mysql的主从复制,读写分离
主从复制:主mysql的数据,新增,修改,表里的数据都会同步到从mysql上 主从复制的模式: 1 异步复制 mysql 的最常用的复制,只要执行完,客户端提交事务,主mysql 会立即把结果返回给从…...
小米路由器4A千兆版刷入OpenWRT并远程访问
小米路由器4A千兆版刷入OpenWRT并远程访问 文章目录 小米路由器4A千兆版刷入OpenWRT并远程访问前言1. 安装Python和需要的库2. 使用 OpenWRTInvasion 破解路由器3. 备份当前分区并刷入新的Breed4. 安装cpolar内网穿透4.1 注册账号4.2 下载cpolar客户端4.3 登录cpolar web ui管理…...
)
【golang】探索for-range遍历实现原理(slice、map、channel)
for-range for-range其实是正常for循环的一种语法糖,在go语言中可以遍历arr,slice,map和channel等数据结构,但是在一些初学者使用for-range可能会遇见很多坑,这篇文章会带你探索一下for-range中非常有趣的一些实现机制…...


MATLAB | 官方举办的动图绘制大赛 | 第一周赛情回顾
嘿真的又是很久没见了,最近确实有点非常很特别小忙,今天带来一下MATHWORKS官方举办的迷你黑客大赛第三期(MATLAB Flipbook Mini Hack)的最新进展!!目前比赛已经刚好进行了一周,前两届都要求提交280个字符内的代码来生成…...
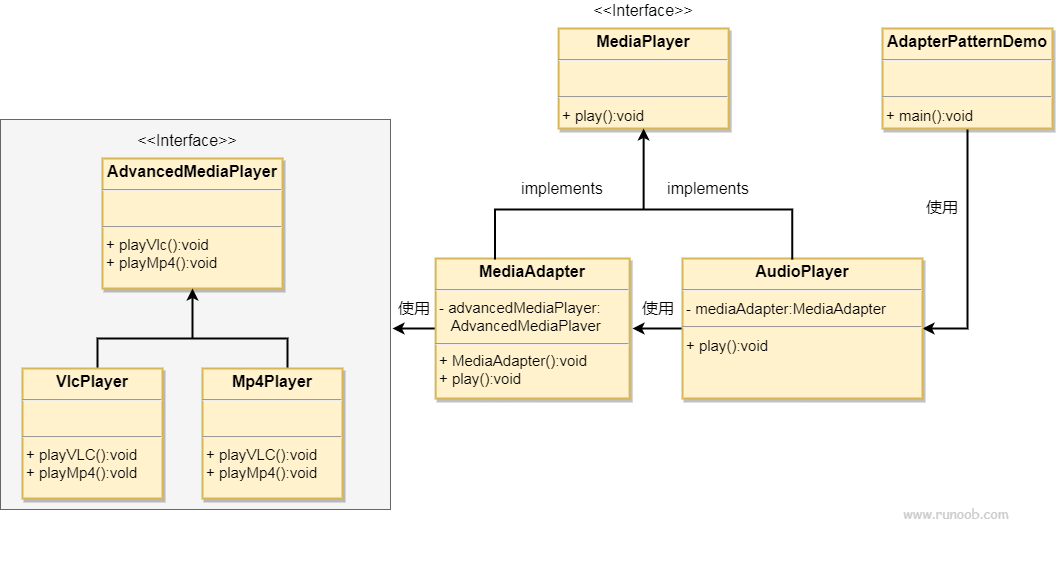
适配器模式 rust和java的实现
文章目录 适配器模式介绍何时使用应用实例优点缺点使用场景 实现java实现rust 实现 rust代码仓库 适配器模式 适配器模式(Adapter Pattern)是作为两个不兼容的接口之间的桥梁。这种类型的设计模式属于结构型模式,它结合了两个独立接口的功能…...

竞赛 题目:垃圾邮件(短信)分类 算法实现 机器学习 深度学习 开题
文章目录 1 前言2 垃圾短信/邮件 分类算法 原理2.1 常用的分类器 - 贝叶斯分类器 3 数据集介绍4 数据预处理5 特征提取6 训练分类器7 综合测试结果8 其他模型方法9 最后 1 前言 🔥 优质竞赛项目系列,今天要分享的是 基于机器学习的垃圾邮件分类 该项目…...
wpf devexpress项目中添加GridControl绑定数据
本教程讲解了如何添加GridControl到wpf项目中并且绑定数据 原文地址Lesson 1 - Add a GridControl to a Project and Bind it to Data | WPF Controls | DevExpress Documentation 1、使用 DevExpress Template Gallery创建一个新的空白mvvm应用程序,这个项目包括了…...

2023亚太杯数学建模A题思路解析
文章目录 0 赛题思路1 竞赛信息2 竞赛时间3 建模常见问题类型3.1 分类问题3.2 优化问题3.3 预测问题3.4 评价问题 4 建模资料5 最后 0 赛题思路 (赛题出来以后第一时间在CSDN分享) https://blog.csdn.net/dc_sinor?typeblog 1 竞赛信息 2023年第十三…...
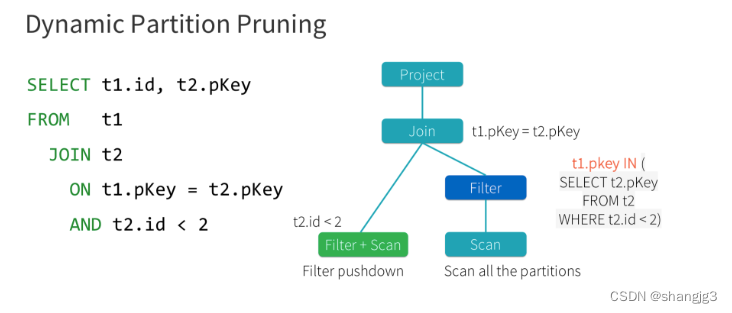
Spark3.0中的AOE、DPP和Hint增强
1 Spark3.0 AQE Spark 在 3.0 版本推出了 AQE(Adaptive Query Execution),即自适应查询执行。AQE 是 Spark SQL 的一种动态优化机制,在运行时,每当 Shuffle Map 阶段执行完毕,AQE 都会结合这个阶段的统计信…...

算法笔记-第五章-质因子分解
算法笔记-第五章-质因子分解 小试牛刀质因子2的个数丑数 质因子分解最小最大质因子约数个数 小试牛刀 质因子2的个数 #include<cstdio> int main() {int n; scanf_s("%d", &n); int count 0; while (n % 2 0) {count; n / 2; }printf("%…...
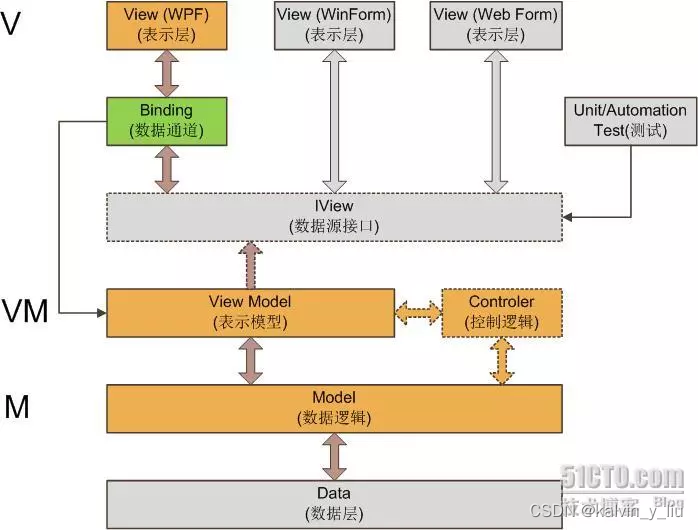
适用于WPF的设计模式
适用于WPF的设计模式 讨论“XAML能不能写逻辑代码”这个问题。我发现这是个有歧义的问题。这个问题可以有两种意思: XAML能不能用来写逻辑代码? XAML文件里能不能包含逻辑代码? 对于第一种意思——XAML是一种声明性语言,就是用来…...

C++与多态
多态的本质是允许对象以其实际类型的行为方式来操作,而不仅仅是其静态类型所声明的方式。 多态是面向对象编程中的一种核心概念,它允许对象根据其具体类型执行相应的操作,而不是其声明的类型。我们可以使用一个经典的动物的例子来说明这一点。…...
ios 对话框UIAlertController放 tableview
//强弱引用 #define kWeakSelf(type)__weak typeof(type)weak##type type; -(void) showUIAlertTable {kWeakSelf(self)UIAlertController *alert [UIAlertController alertControllerWithTitle:NSLocalizedString("select_stu", nil) message:nil prefer…...

警告:新版Outlook会向微软发送密码、邮件和其他数据
新的免费Outlook会将敏感数据发送给 Microsoft。 在没有通知或询问的情况下,Microsoft 授予自己对新 Outlook 用户的 IMAP 和 SMTP 访问数据的完全访问权限。也就是说,当用户设置 IMAP 帐户时,新的 Outlook 会将访问数据和服务器信息发送给 …...

数据结构C语言--基础实验
实验1 线性表的顺序实现 1.!顺序表的倒置 /**********************************/ /*文件名称:lab1-01.c */ /**********************************/ /*基于sequlist.h中定义的顺序表,编写算法函数reverse(sequence_list *L)&…...

wireshark抓包并进行Eigrp网络协议分析
路由协议 Eigrp EIGRP:Enhanced Interior Gateway Routing Protocol 即 增强内部网关路由协议。也翻译为 加强型内部网关路由协议。 EIGRP是Cisco公司的私有协议(2013年已经公有化)。 EIGRP结合了链路状态和距离矢量型路由选择协议的Cisco专用协议&a…...
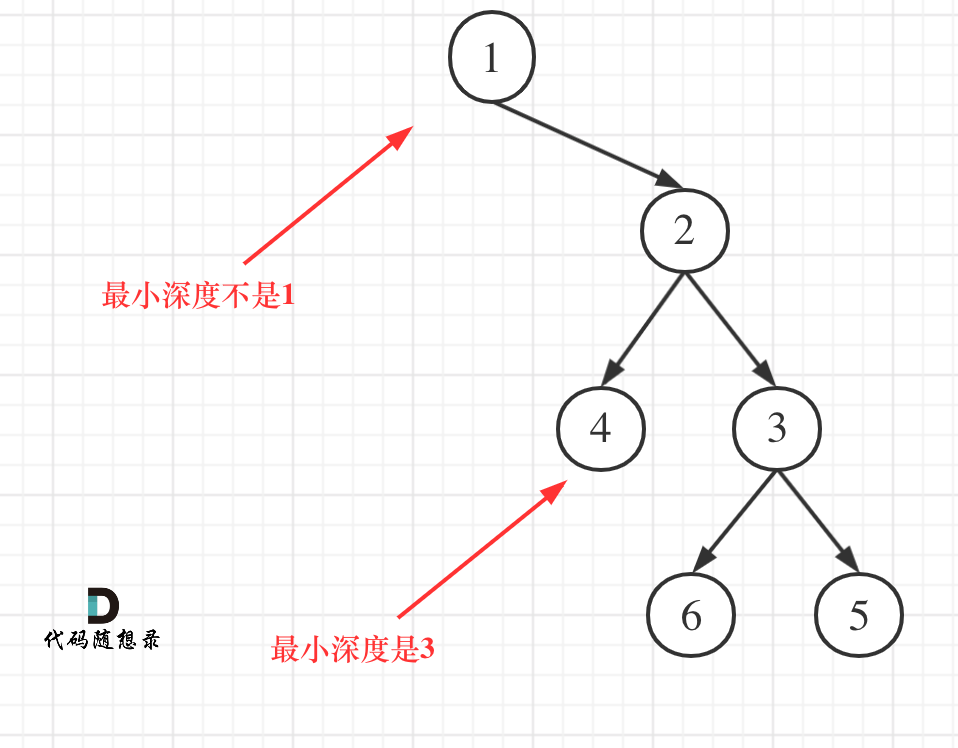
力扣刷题-二叉树-二叉树的层序遍历(相关题目总结)
思路 层序遍历一个二叉树。就是从左到右一层一层的去遍历二叉树。这种遍历的方式和我们之前讲过的都不太一样。 需要借用一个辅助数据结构即队列来实现,队列先进先出,符合一层一层遍历的逻辑,而用栈先进后出适合模拟深度优先遍历也就是递归的…...

fundamental notes in 3D math
平面方程 a x b y c z d axbycz d axbyczd, 法向量 a , b , c a,b,c a,b,c, 点到平面的距离为 d / s q r t ( a 2 b 2 c 2 ) d / sqrt(a^2 b^2 c^2) d/sqrt(a2b2c2) , 距离可为正, 为负, 为正表示跟法向量方向一致, 为负表示相反 点 ( x o , y o , z o ) (x_o, y_o, z…...

【Java 进阶篇】JQuery DOM操作:舞动网页的属性魔法
在前端的舞台上,属性操作是我们与HTML元素进行互动的关键步骤之一。而JQuery,这位前端开发的巫师,通过简洁而强大的语法,为我们提供了便捷的属性操作工具。在这篇博客中,我们将深入研究JQuery DOM操作中的属性操作&…...
)
保姆级教程:在ArcGIS Pro插件中集成你的自定义工具箱(以‘消除重复要素’为例)
从脚本到按钮:ArcGIS Pro插件开发实战指南 在GIS日常工作中,我们常常会遇到一些重复性的数据处理任务。比如数据质检环节的"消除重复要素"操作,虽然可以通过Python脚本实现,但每次都需要打开IDE或Python窗口执行代码&am…...

SwitchyOmega+Burp无感抓包实战:解决HTTPS拦截与流量路由难题
1. 为什么“无感抓包”是BurpSuite日常使用的分水岭刚接触Web安全测试的朋友常有个错觉:装上Burp Suite,配好代理,打开浏览器,点几下网页——流量就该自动进来了。结果现实是:首页打不开、登录态丢失、HTTPS报错满屏、…...

利用DiSEqC协议与AVR单片机驱动卫星天线电机改造户外设备
1. 项目概述:用卫星天线电机驱动一切如果你手头有一些需要承受风吹日晒、还得精确转动的设备,比如一个户外的大型定向天线,或者一个需要定期调整角度的太阳能板支架,甚至是一个坚固的监控云台,你可能会为驱动机构发愁。…...

基于ESP32的AIS转WiFi转换器:实现NMEA 0183数据无线传输
1. 项目概述:从VHF-AIS接收器到iPad的无线桥梁作为一名经常在海上折腾电子设备的航海爱好者,我最近遇到了一个挺实际的需求:我的主力导航设备是iPad上的iSailor应用,它功能强大、界面友好,但有个“硬伤”——它需要通过…...
:执行计划教我做事)
开发转兼职DBA(二):执行计划教我做事
开发转兼职DBA(二):执行计划教我做事 查询慢了不知道为什么,加了索引还是慢,复合索引怎么建,执行计划怎么看——这些不是DBA的专利,是每个写SQL的开发者迟早要面对的事。 文章目录 开发转兼职DB…...

荣耀出征官方网站下载正版手游 翅膀养成细节玩法全方位讲解
玩荣耀出征的玩家都清楚,翅膀不仅是角色的颜值象征,更是提升整体战力的核心途径。很多新手玩家只顾着升级、刷装备,完全忽略翅膀养成,导致等级很高但战力始终上不去。还有不少玩家胡乱合成、盲目进阶,浪费了大量稀有翅…...

为什么92%的团队用DeepSeek生成方案仍需人工重写?揭秘缺失的2个元认知层与1套校验协议
更多请点击: https://intelliparadigm.com 第一章:为什么92%的团队用DeepSeek生成方案仍需人工重写?揭秘缺失的2个元认知层与1套校验协议 当团队将DeepSeek-R1或DeepSeek-VL模型用于技术方案生成时,表面看响应迅速、逻辑连贯&…...

PCL 基于强度的双边滤波【2026最新版】
目录 一、算法原理 1、计算步骤 2、算法源码 3、函数解析 4、参考文献 二、代码实现 三、结果展示 四、滤波后未发生变化的原因 五、解决办法 六、结果展示 七、相关链接 本文由CSDN点云侠原创,博客长期更新,本文最近一次更新时间为:2026年5月24日。 一、算法原理 1、计算…...

CausalVLR基准测试报告:在IU X-Ray和MIMIC-CXR数据集上的性能分析
CausalVLR基准测试报告:在IU X-Ray和MIMIC-CXR数据集上的性能分析 【免费下载链接】CausalVLR CausalVLR: A Toolbox and Benchmark for Vision-Language Causal Reasoning (多模态因果推理开源框架) 项目地址: https://gitcode.com/gh_mirrors/ca/CausalVLR …...

Ubuntu经常安装软件
1、垃圾清理工具stacer sudo apt updatesudo apt install stacer apt cleanapt autocleanapt autoremove 2、类似与everything的工具Fsearcch 1sudo add-apt-repository ppa:christian-boxdoerfer/fsearch-stable 2sudo apt update 3sudo apt install fsearch (注…...