Spark3.0中的AOE、DPP和Hint增强
1 Spark3.0 AQE
Spark 在 3.0 版本推出了 AQE(Adaptive Query Execution),即自适应查询执行。AQE 是 Spark SQL 的一种动态优化机制,在运行时,每当 Shuffle Map 阶段执行完毕,AQE 都会结合这个阶段的统计信息,基于既定的规则动态地调整、修正尚未执行的逻辑计划和物理计划,来完成对原始查询语句的运行时优化。
1.1 动态合并分区
在Spark中运行查询处理非常大的数据时,shuffle通常会对查询性能产生非常重要的影响。shuffle是非常昂贵的操作,因为它需要进行网络传输移动数据,以便下游进行计算。
最好的分区取决于数据,但是每个查询的阶段之间的数据大小可能相差很大,这使得该数字难以调整:
(1)如果分区太少,则每个分区的数据量可能会很大,处理这些数据量非常大的分区,可能需要将数据溢写到磁盘(例如,排序和聚合),降低了查询。
(2)如果分区太多,则每个分区的数据量大小可能很小,读取大量小的网络数据块,这也会导致I/O效率低而降低了查询速度。拥有大量的task(一个分区一个task)也会给Spark任务计划程序带来更多负担。
为了解决这个问题,我们可以在任务开始时先设置较多的shuffle分区个数,然后在运行时通过查看shuffle文件统计信息将相邻的小分区合并成更大的分区。
例如,假设正在运行select max(i) from tbl group by j。输入tbl很小,在分组前只有2个分区。那么任务刚初始化时,我们将分区数设置为5,如果没有AQE,Spark将启动五个任务来进行最终聚合,但是其中会有三个非常小的分区,为每个分区启动单独的任务这样就很浪费。

取而代之的是,AQE将这三个小分区合并为一个,因此最终聚只需三个task而不是五个

spark-submit --master yarn --deploy-mode client --driver-memory 1g --num-executors 3 --executor-cores 2 --executor-memory 2g --class com.atguigu.sparktuning.aqe.AQEPartitionTunning spark-tuning-1.0-SNAPSHOT-jar-with-dependencies.jar
结合动态申请资源:
spark-submit --master yarn --deploy-mode client --driver-memory 1g --num-executors 3 --executor-cores 2 --executor-memory 2g --class com.atguigu.sparktuning.aqe.DynamicAllocationTunning spark-tuning-1.0-SNAPSHOT-jar-with-dependencies.jar
1.2 动态切换Join策略
Spark支持多种join策略,其中如果join的一张表可以很好的插入内存,那么broadcast shah join通常性能最高。因此,spark join中,如果小表小于广播大小阀值(默认10mb),Spark将计划进行broadcast hash join。但是,很多事情都会使这种大小估计出错(例如,存在选择性很高的过滤器),或者join关系是一系列的运算符而不是简单的扫描表操作。
为了解决此问题,AQE现在根据最准确的join大小运行时重新计划join策略。从下图实例中可以看出,发现连接的右侧表比左侧表小的多,并且足够小可以进行广播,那么AQE会重新优化,将sort merge join转换成为broadcast hash join。
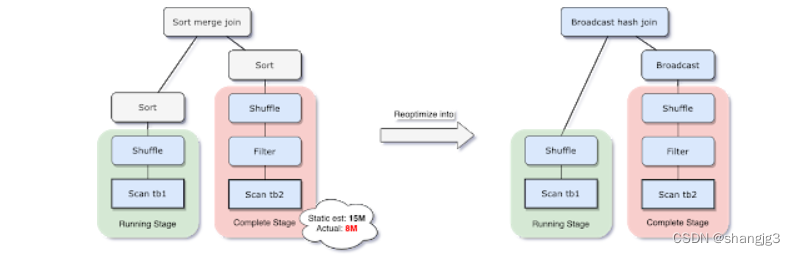
对于运行是的broadcast hash join,可以将shuffle优化成本地shuffle,优化掉stage 减少网络传输。Broadcast hash join可以规避shuffle阶段,相当于本地join。
spark-submit --master yarn --deploy-mode client --driver-memory 1g --num-executors 3 --executor-cores 4 --executor-memory 2g --class com.atguigu.sparktuning.aqe.AqeDynamicSwitchJoin spark-tuning-1.0-SNAPSHOT-jar-with-dependencies.jar
1.3 动态优化Join倾斜
当数据在群集中的分区之间分布不均匀时,就会发生数据倾斜。严重的倾斜会大大降低查询性能,尤其对于join。AQE skew join优化会从随机shuffle文件统计信息自动检测到这种倾斜。然后它将倾斜分区拆分成较小的子分区。
例如,下图 A join B,A表中分区A0明细大于其他分区

因此,skew join 会将A0分区拆分成两个子分区,并且对应连接B0分区

没有这种优化,会导致其中一个分区特别耗时拖慢整个stage,有了这个优化之后每个task耗时都会大致相同,从而总体上获得更好的性能。
可以采取第4章提到的解决方式,3.0有了AQE机制就可以交给Spark自行解决。Spark3.0增加了以下参数。
1)spark.sql.adaptive.skewJoin.enabled :是否开启倾斜join检测,如果开启了,那么会将倾斜的分区数据拆成多个分区,默认是开启的,但是得打开aqe。
2)spark.sql.adaptive.skewJoin.skewedPartitionFactor :默认值5,此参数用来判断分区数据量是否数据倾斜,当任务中最大数据量分区对应的数据量大于的分区中位数乘以此参数,并且也大于spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes参数,那么此任务是数据倾斜。
3)spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes :默认值256mb,用于判断是否数据倾斜
4)spark.sql.adaptive.advisoryPartitionSizeInBytes :此参数用来告诉spark进行拆分后推荐分区大小是多少。
spark-submit --master yarn --deploy-mode client --driver-memory 1g --num-executors 3 --executor-cores 4 --executor-memory 2g --class com.atguigu.sparktuning.aqe.AqeOptimizingSkewJoin spark-tuning-1.0-SNAPSHOT-jar-with-dependencies.jar
如果同时开启了spark.sql.adaptive.coalescePartitions.enabled动态合并分区功能,那么会先合并分区,再去判断倾斜,将动态合并分区打开后,重新执行:
spark-submit --master yarn --deploy-mode client --driver-memory 1g --num-executors 3 --executor-cores 4 --executor-memory 2g --class com.atguigu.sparktuning.aqe.AqeOptimizingSkewJoin spark-tuning-1.0-SNAPSHOT-jar-with-dependencies.jar
修改中位数的倍数为2,重新执行:
spark-submit --master yarn --deploy-mode client --driver-memory 1g --num-executors 3 --executor-cores 4 --executor-memory 2g --class com.atguigu.sparktuning.aqe.AqeOptimizingSkewJoin spark-tuning-1.0-SNAPSHOT-jar-with-dependencies.jar
2 Spark3.0 DPP
Spark3.0支持动态分区裁剪Dynamic Partition Pruning,简称DPP,核心思路就是先将join一侧作为子查询计算出来,再将其所有分区用到join另一侧作为表过滤条件,从而实现对分区的动态修剪。如下图所示
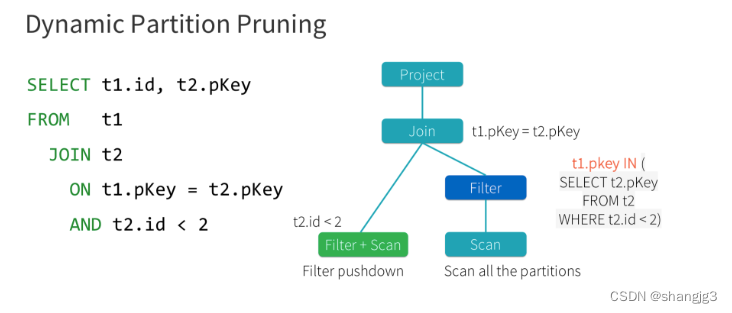
将select t1.id,t2.pkey from t1 join t2 on t1.pkey =t2.pkey and t2.id<2 优化成了select t1.id,t2.pkey from t1 join t2 on t1.pkey=t2.pkey and t1.pkey in(select t2.pkey from t2 where t2.id<2)
触发条件:
(1)待裁剪的表join的时候,join条件里必须有分区字段
(2)如果是需要修剪左表,那么join必须是inner join ,left semi join或right join,反之亦然。但如果是left out join,无论右边有没有这个分区,左边的值都存在,就不需要被裁剪
(3)另一张表需要存在至少一个过滤条件,比如a join b on a.key=b.key and a.id<2
参数spark.sql.optimizer.dynamicPartitionPruning.enabled 默认开启。
spark-submit --master yarn --deploy-mode client --driver-memory 1g --num-executors 3 --executor-cores 4 --executor-memory 2g --class com.atguigu.sparktuning.dpp.DPPTest spark-tuning-1.0-SNAPSHOT-jar-with-dependencies.jar
3 Spark3.0 Hint增强
在spark2.4的时候就有了hint功能,不过只有broadcasthash join的hint,这次3.0又增加了sort merge join,shuffle_hash join,shuffle_replicate nested loop join。
Spark的5种Join策略:https://www.cnblogs.com/jmx-bigdata/p/14021183.html
3.1 broadcasthast join
sparkSession.sql("select /*+ BROADCAST(school) */ * from test_student student left join test_school school on student.id=school.id").show()
sparkSession.sql("select /*+ BROADCASTJOIN(school) */ * from test_student student left join test_school school on student.id=school.id").show()
sparkSession.sql("select /*+ MAPJOIN(school) */ * from test_student student left join test_school school on student.id=school.id").show()
3.2 sort merge join
sparkSession.sql("select /*+ SHUFFLE_MERGE(school) */ * from test_student student left join test_school school on student.id=school.id").show()
sparkSession.sql("select /*+ MERGEJOIN(school) */ * from test_student student left join test_school school on student.id=school.id").show()
sparkSession.sql("select /*+ MERGE(school) */ * from test_student student left join test_school school on student.id=school.id").show()
3.3 shuffle_hash join
sparkSession.sql("select /*+ SHUFFLE_HASH(school) */ * from test_student student left join test_school school on student.id=school.id").show()
3.4 shuffle_replicate_nl join
使用条件非常苛刻,驱动表(school表)必须小,且很容易被spark执行成sort merge join。
sparkSession.sql("select /*+ SHUFFLE_REPLICATE_NL(school) */ * from test_student student inner join test_school school on student.id=school.id").show()
相关文章:
Spark3.0中的AOE、DPP和Hint增强
1 Spark3.0 AQE Spark 在 3.0 版本推出了 AQE(Adaptive Query Execution),即自适应查询执行。AQE 是 Spark SQL 的一种动态优化机制,在运行时,每当 Shuffle Map 阶段执行完毕,AQE 都会结合这个阶段的统计信…...

算法笔记-第五章-质因子分解
算法笔记-第五章-质因子分解 小试牛刀质因子2的个数丑数 质因子分解最小最大质因子约数个数 小试牛刀 质因子2的个数 #include<cstdio> int main() {int n; scanf_s("%d", &n); int count 0; while (n % 2 0) {count; n / 2; }printf("%…...
适用于WPF的设计模式
适用于WPF的设计模式 讨论“XAML能不能写逻辑代码”这个问题。我发现这是个有歧义的问题。这个问题可以有两种意思: XAML能不能用来写逻辑代码? XAML文件里能不能包含逻辑代码? 对于第一种意思——XAML是一种声明性语言,就是用来…...

C++与多态
多态的本质是允许对象以其实际类型的行为方式来操作,而不仅仅是其静态类型所声明的方式。 多态是面向对象编程中的一种核心概念,它允许对象根据其具体类型执行相应的操作,而不是其声明的类型。我们可以使用一个经典的动物的例子来说明这一点。…...
ios 对话框UIAlertController放 tableview
//强弱引用 #define kWeakSelf(type)__weak typeof(type)weak##type type; -(void) showUIAlertTable {kWeakSelf(self)UIAlertController *alert [UIAlertController alertControllerWithTitle:NSLocalizedString("select_stu", nil) message:nil prefer…...

警告:新版Outlook会向微软发送密码、邮件和其他数据
新的免费Outlook会将敏感数据发送给 Microsoft。 在没有通知或询问的情况下,Microsoft 授予自己对新 Outlook 用户的 IMAP 和 SMTP 访问数据的完全访问权限。也就是说,当用户设置 IMAP 帐户时,新的 Outlook 会将访问数据和服务器信息发送给 …...

数据结构C语言--基础实验
实验1 线性表的顺序实现 1.!顺序表的倒置 /**********************************/ /*文件名称:lab1-01.c */ /**********************************/ /*基于sequlist.h中定义的顺序表,编写算法函数reverse(sequence_list *L)&…...

wireshark抓包并进行Eigrp网络协议分析
路由协议 Eigrp EIGRP:Enhanced Interior Gateway Routing Protocol 即 增强内部网关路由协议。也翻译为 加强型内部网关路由协议。 EIGRP是Cisco公司的私有协议(2013年已经公有化)。 EIGRP结合了链路状态和距离矢量型路由选择协议的Cisco专用协议&a…...
力扣刷题-二叉树-二叉树的层序遍历(相关题目总结)
思路 层序遍历一个二叉树。就是从左到右一层一层的去遍历二叉树。这种遍历的方式和我们之前讲过的都不太一样。 需要借用一个辅助数据结构即队列来实现,队列先进先出,符合一层一层遍历的逻辑,而用栈先进后出适合模拟深度优先遍历也就是递归的…...

fundamental notes in 3D math
平面方程 a x b y c z d axbycz d axbyczd, 法向量 a , b , c a,b,c a,b,c, 点到平面的距离为 d / s q r t ( a 2 b 2 c 2 ) d / sqrt(a^2 b^2 c^2) d/sqrt(a2b2c2) , 距离可为正, 为负, 为正表示跟法向量方向一致, 为负表示相反 点 ( x o , y o , z o ) (x_o, y_o, z…...

【Java 进阶篇】JQuery DOM操作:舞动网页的属性魔法
在前端的舞台上,属性操作是我们与HTML元素进行互动的关键步骤之一。而JQuery,这位前端开发的巫师,通过简洁而强大的语法,为我们提供了便捷的属性操作工具。在这篇博客中,我们将深入研究JQuery DOM操作中的属性操作&…...
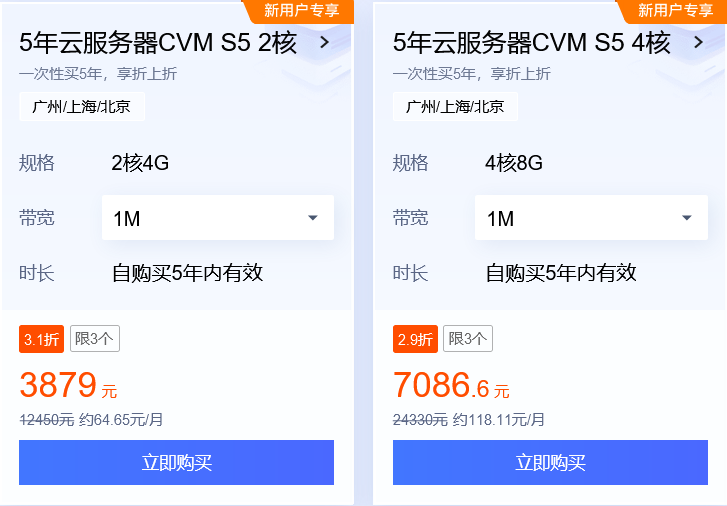
腾讯云5年云服务器还有吗?腾讯云5年时长服务器入口在哪?
如果你是一名企业家或者是一个热衷于数字化转型的创业者,那么腾讯云最近推出的一项优惠活动绝对不会让你无动于衷。现在,腾讯云正在大力推广一项5年特价云服务器活动,只需要花费3879元,你就可以享受到腾讯云提供的优质服务。 腾讯…...

odoo在iot领域的发展情况
Odoo 是一个全面的集成商业管理软件套装,主要提供企业资源规划 (ERP)、客户关系管理 (CRM)、电子商务、会计、库存管理等功能。在 IoT(物联网)领域,Odoo 侧重于通过提供一个中心化的平台来整合多方面的业务流程,包括生…...

Paas-云原生-容器-编排-持续部署
了解云原生 云原生架构让企业的基础设施,从简单的资源池化,转向以应用为中心,为应用赋能的敏捷、自运维、安全的云原生基础设施。以应用为中心的云原生基础设置,可以支持多种类型的应用,如微服务应用,中间件应用和AI 应用;可以提升应用交付效率,简化应用管理的复杂度;…...

sass 生成辅助色
背景 一个按钮往往有 4 个状态。 默认状态hover鼠标按下禁用状态 为了表示这 4 个状态,需要设置 4 个颜色来提示用户。 按钮类型一般有 5 个: 以 primary 类型按钮为例,设置它不同状态下的颜色: <button class"btn…...
DevEco Studio开发工具下载、安装(HarmonyOS开发)_For Mac
一、说明 初学HarmonyOS开发,DevEco Studio开发工具的安装和使用是必须的。 (注:不多废话,跟着下面流程操作下载、安装DevEco Studio即可。) 二、下载DevEco Studio 1.官网下载地址: https://developer.…...
按键精灵中的字符串常用的场景
在使用按键精灵编写脚本时,与字符串有关的场景有以下几种: 1. 用时间字符串记录脚本使用截止使用时间 Dim localTime "2023-11-12 00:15:14" Dim networkTime GetNetworkTime() TracePrint networkTime If networkTime > localTime The…...

python数据结构与算法-01_抽象数据类型和面向对象编程
Python 一切皆对象 举个例子,在 python 中我们经常使用的 list l list() # 实例化一个 list 对象 l l.append(1) # 调用 l 的 append 方法 l.append(2) l.remove(1) print(len(l)) # 调用对象的 __len__ 方法在后面实现新的数据类型时,我们将…...

纯手写 模态框、消息弹框、呼吸灯
在有些做某些网页中,应用不想引用一些前端框架,对于一些比较常用的插件可以纯手写实现 1、模态框 <!DOCTYPE html> <html> <head> <meta charset"UTF-8"> <title>Water Ripple Effect</title> <style…...

windows安装composer并更换国内镜像
第一步、官网下载 下载地址 Composer安装https://getcomposer.org/Composer-Setup.exe第二步、双击安装即可 第三步选择 php安装路径并配置path 第四步、 composer -v查看安装是否成功,出现成功界面 第五步、查看镜像地址并更换(composer国内可能较慢…...
)
蓝牙抓包不求人:从HCI日志里‘挖’出Link Key的两种实用方法(附安卓路径)
蓝牙安全逆向实战:从HCI日志中提取Link Key的深度解析在蓝牙协议安全研究领域,Link Key作为设备配对认证的核心凭证,其获取方式一直是逆向工程师关注的焦点。许多安全审计场景下,我们往往只能获得加密后的HCI通信日志,…...

用Python和MNE库玩转BCI Competition IV 2a脑电数据集:从数据加载到可视化全流程
用Python和MNE库玩转BCI Competition IV 2a脑电数据集:从数据加载到可视化全流程当你第一次接触脑电信号处理时,面对原始数据文件可能会感到无从下手。BCI Competition IV 2a数据集作为脑机接口领域的经典基准数据,包含了9名受试者四种运动想…...

AI IDE 革命:程序员正在被重新定义
很多开发者第一次使用 Cursor 的 CtrlK 或 Composer(高级多文件编辑模式)时,都会有一种强烈的、甚至让人有些脊背发凉的冲击感。 因为: 它已经不再是那个我们熟悉的、只能在原地等待光标落下的: “代码自动补全插件&am…...

INT8量化下TVA注意力对齐精度保障方案
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...
从模糊到电影级景深:Midjourney + Topaz Gigapixel联调方案(含LUT预设包+PSD分层模板)
更多请点击: https://codechina.net 第一章:从模糊到电影级景深:Midjourney Topaz Gigapixel联调方案(含LUT预设包PSD分层模板) 当Midjourney生成的图像存在主体边缘柔化、背景层次缺失或分辨率不足等问题时…...

多模型聚合平台如何助力网站AIB测试与选型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 多模型聚合平台如何助力网站AIB测试与选型 对于网站产品经理而言,首页文案的生成质量直接影响用户的第一印象和转化率。…...

NBTExplorer:让Minecraft数据编辑从专业工具变成人人可用的可视化平台
NBTExplorer:让Minecraft数据编辑从专业工具变成人人可用的可视化平台 【免费下载链接】NBTExplorer A graphical NBT editor for all Minecraft NBT data sources 项目地址: https://gitcode.com/gh_mirrors/nb/NBTExplorer 你是否曾经面对Minecraft世界文件…...

告别手动预约:i茅台自动预约系统5分钟部署指南
告别手动预约:i茅台自动预约系统5分钟部署指南 【免费下载链接】campus-imaotai i茅台app自动预约,每日自动预约,支持docker一键部署(本项目不提供成品,使用的是已淘汰的算法) 项目地址: https://gitcode…...

天文时序数据分析:机器学习评估、半监督学习与无监督方法实战
1. 项目概述:当机器学习遇见星空 处理海量的天文时序数据,比如来自Kepler、TESS这些“巡天巨眼”的光变曲线,早已不是靠人眼一张张图去翻的时代了。数据量太大,噪声复杂,信号微弱,传统方法常常力不从心。这…...

Claude Mythos Preview首月揪万余漏洞、拦截150万美元电诈,网络安全格局将变?
玻璃翼计划首战告捷A厂的玻璃翼计划首战告捷,Mythos 30天内就挖出1万个致命漏洞,甚至拦截了150万美元电诈。面对雪片式的报告,人类程序员崩溃求饶:「求别挖了,根本修不完啊!」就在刚刚,Anthropi…...