Flink SQL --命令行的使用(02)
1、窗口函数:
1、创建表:
-- 创建kafka 表
CREATE TABLE bid (bidtime TIMESTAMP(3),price DECIMAL(10, 2) ,item STRING,WATERMARK FOR bidtime AS bidtime
) WITH ('connector' = 'kafka','topic' = 'bid', -- 数据的topic'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092', -- broker 列表'properties.group.id' = 'testGroup', -- 消费者组'scan.startup.mode' = 'latest-offset', -- 读取数据的位置earliest-offset latest-offset'format' = 'csv' -- 读取数据的格式
);kafka-console-producer.sh --broker-list master:9092,node1:9092,node2:9092 --topic bid
2020-04-15 08:05:00,4.00,C
2020-04-15 08:07:00,2.00,A
2020-04-15 08:09:00,5.00,D
2020-04-15 08:11:00,3.00,B
2020-04-15 08:13:00,1.00,E
2020-04-15 08:17:00,6.00,F2、滚动窗口:
1、滚动的事件时间窗口:
-- TUMBLE: 滚动窗口函数,函数的作用时在原表的基础上增加[窗口开始时间,窗口结束时间,窗口时间]
-- TABLE;表函数,将里面函数的结果转换成动态表
SELECT * FROM
TABLE(TUMBLE(TABLE bid, DESCRIPTOR(bidtime), INTERVAL '10' MINUTES)
);-- 在基于窗口函数提供的字段进行聚合计算
-- 实时统计每隔商品的总的金额,每隔10分钟统计一次
SELECT item,window_start,window_end,sum(price) as sum_price
FROM
TABLE(-- 滚动的事件时间窗口TUMBLE(TABLE bid, DESCRIPTOR(bidtime), INTERVAL '10' MINUTES)
)
group by item,window_start,window_end;
2、滚动的处理时间窗口:
CREATE TABLE words (word STRING,proctime as PROCTIME() -- 定义处理时间,PROCTIME:获取处理时间的函数
) WITH ('connector' = 'kafka','topic' = 'words', -- 数据的topic'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092', -- broker 列表'properties.group.id' = 'testGroup', -- 消费者组'scan.startup.mode' = 'latest-offset', -- 读取数据的位置earliest-offset latest-offset'format' = 'csv' -- 读取数据的格式
);kafka-console-producer.sh --broker-list master:9092,node1:9092,node2:9092 --topic words
java
spark-- 在flink SQL中处理时间和事件时间的sql语法没有区别
SELECT * FROM
TABLE(TUMBLE(TABLE words, DESCRIPTOR(proctime), INTERVAL '5' SECOND)
);SELECT word,window_start,window_end,count(1) as c
FROM
TABLE(TUMBLE(TABLE words, DESCRIPTOR(proctime), INTERVAL '5' SECOND)
)
group by word,window_start,window_end3、滑动窗口:
-- HOP: 滑动窗口函数
-- 滑动窗口一条数据可能会落到多个窗口中SELECT * FROM
TABLE(HOP(TABLE bid, DESCRIPTOR(bidtime),INTERVAL '5' MINUTES, INTERVAL '10' MINUTES)
);-- 每隔5分钟计算最近10分钟所有商品总的金额
SELECT window_start,window_end,sum(price) as sum_price
FROM
TABLE(HOP(TABLE bid, DESCRIPTOR(bidtime),INTERVAL '5' MINUTES, INTERVAL '10' MINUTES)
)
group by window_start,window_end4、会话窗口:
CREATE TABLE words (word STRING,proctime as PROCTIME() -- 定义处理时间,PROCTIME:获取处理时间的函数
) WITH ('connector' = 'kafka','topic' = 'words', -- 数据的topic'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092', -- broker 列表'properties.group.id' = 'testGroup', -- 消费者组'scan.startup.mode' = 'latest-offset', -- 读取数据的位置earliest-offset latest-offset'format' = 'csv' -- 读取数据的格式
);kafka-console-producer.sh --broker-list master:9092,node1:9092,node2:9092 --topic words
java
sparkselect word,SESSION_START(proctime,INTERVAL '5' SECOND) as window_start,SESSION_END(proctime,INTERVAL '5' SECOND) as window_end,count(1) as c
from words
group by word,SESSION(proctime,INTERVAL '5' SECOND);2、OVER聚合:
1、批处理:
在Flink中的批处理的模式,over函数和hive是一致的。
SET 'execution.runtime-mode' = 'batch';
-- 有界流
CREATE TABLE students_hdfs_batch (sid STRING,name STRING,age INT,sex STRING,clazz STRING
)WITH ('connector' = 'filesystem', -- 必选:指定连接器类型'path' = 'hdfs://master:9000/data/student', -- 必选:指定路径'format' = 'csv' -- 必选:文件系统连接器指定 format
);-- row_number,sum,count,avg,lag,lead,max,min
-- 需要注意的是sum,sum在有排序的是聚合,在没有排序的是全局聚合。
-- 获取每隔班级年龄最大的前两个学生select *
from(select *,row_number() over(partition by clazz order by age desc) as rfrom students_hdfs_batch
) as a
where r <=22、流处理:
flink流处理中over聚合使用限制
1、order by 字段必须是时间字段升序排序或者使用over_number时可以增加条件过滤
2、在流处理里面,Flink中目前只支持按照时间属性升序定义的over的窗口。因为在批处理中,数据量的大小是固定的,不会有新的数据产生,所以在做排序的时候,只需要一次排序,所以排序字段可以随便指定,但是在流处理中,数据量是源源不断的产生,当每做一次排序的时候,就需要将之前的数据都取出来存储,随着时间的推移,数据量会不断的增加,在做排序时计算量非常大。但是按照时间的顺序,时间是有顺序的,可以减少计算的代价。
3、也可以选择top N 也可以减少计算量。
4、在Flink中做排序时,需要考虑计算代价的问题,一般使用的排序的字段是时间字段。
SET 'execution.runtime-mode' = 'streaming';
-- 创建kafka 表
CREATE TABLE students_kafka (sid STRING,name STRING,age INT,sex STRING,clazz STRING,proctime as PROCTIME()
) WITH ('connector' = 'kafka','topic' = 'students', -- 数据的topic'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092', -- broker 列表'properties.group.id' = 'testGroup', -- 消费者组'scan.startup.mode' = 'earliest-offset', -- 读取数据的位置earliest-offset latest-offset'format' = 'csv' -- 读取数据的格式
);
-- 在流处理模式下,flink只能按照时间字段进行升序排序-- 如果按照一个普通字段进行排序,在流处理模式下,每来一条新的数据都需重新计算之前的顺序,计算代价太大
-- 在row_number基础上增加条件,可以限制计算的代价不断增加select * from (
select *,row_number() over(partition by clazz order by age desc) as r
from students_kafka
)
where r <= 2;-- 在流处理模式下,flink只能按照时间字段进行升序排序
select
*,
sum(age) over(partition by clazz order by proctime)
from
students_kafka-- 时间边界
-- RANGE BETWEEN INTERVAL '10' SECOND PRECEDING AND CURRENT ROW
select
*,
sum(age) over(partition by clazzorder by proctime-- 统计最近10秒的数据RANGE BETWEEN INTERVAL '10' SECOND PRECEDING AND CURRENT ROW
)
from
students_kafka /*+ OPTIONS('scan.startup.mode' = 'latest-offset') */;-- 数据边界
--ROWS BETWEEN 10 PRECEDING AND CURRENT ROW
select
*,
sum(age) over(partition by clazzorder by proctime-- 统计最近10秒的数据ROWS BETWEEN 2 PRECEDING AND CURRENT ROW
)
from
students_kafka /*+ OPTIONS('scan.startup.mode' = 'latest-offset') */;kafka-console-producer.sh --broker-list master:9092,node1:9092,node2:9092 --topic students1500100003,tom,22,女,理科六班3、Order By:
在使用order by进行排序的时候,排序的字段中必须使用到时间字段:
-- 排序字段必须带上时间升序排序,使用到时间字段:proctime
select * from
students_kafka
order by proctime,age;-- 限制排序的计算代价,避免全局排序,在使用限制的时候,在做排序的时候,就只需要对限制的进行排序,减少了计算的代价。select *
from
students_kafka
order by age
limit 10;4、row_number去重
CREATE TABLE students_kafka (sid STRING,name STRING,age INT,sex STRING,clazz STRING,proctime as PROCTIME()
) WITH ('connector' = 'kafka','topic' = 'students', -- 数据的topic'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092', -- broker 列表'properties.group.id' = 'testGroup', -- 消费者组'scan.startup.mode' = 'earliest-offset', -- 读取数据的位置earliest-offset latest-offset'format' = 'csv' -- 读取数据的格式
);
kafka-console-producer.sh --broker-list master:9092,node1:9092,node2:9092 --topic students
1500100003,tom,22,女,理科六班select * from (
select
sid,name,age,
row_number() over(partition by sid order by proctime) as r
from students_kafka /*+ OPTIONS('scan.startup.mode' = 'latest-offset') */
)
where r = 1;5、JOIN
Regular Joins: 主要用于批处理,如果在流处理上使用,状态会越来越大
Interval Join: 主要用于双流join
Temporal Joins:用于流表关联时态表(不同时间状态不一样,比如汇率表)
Lookup Join:用于流表关联维表(不怎么变化的表)
1、Regular Joins
1、批处理:
CREATE TABLE students_hdfs_batch (sid STRING,name STRING,age INT,sex STRING,clazz STRING
)WITH ('connector' = 'filesystem', -- 必选:指定连接器类型'path' = 'hdfs://master:9000/data/student', -- 必选:指定路径'format' = 'csv' -- 必选:文件系统连接器指定 format
);CREATE TABLE score_hdfs_batch (sid STRING,cid STRING,score INT
)WITH ('connector' = 'filesystem', -- 必选:指定连接器类型'path' = 'hdfs://master:9000/data/score', -- 必选:指定路径'format' = 'csv' -- 必选:文件系统连接器指定 format
);SET 'execution.runtime-mode' = 'batch';-- inner join
select a.sid,a.name,b.score from
students_hdfs_batch as a
inner join
score_hdfs_batch as b
on a.sid=b.sid;-- left join
select a.sid,a.name,b.score from
students_hdfs_batch as a
left join
score_hdfs_batch as b
on a.sid=b.sid;-- full join
select a.sid,a.name,b.score from
students_hdfs_batch as a
full join
score_hdfs_batch as b
on a.sid=b.sid;2、流处理:
CREATE TABLE students_kafka (sid STRING,name STRING,age INT,sex STRING,clazz STRING
)WITH ('connector' = 'kafka','topic' = 'students', -- 数据的topic'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092', -- broker 列表'properties.group.id' = 'testGroup', -- 消费者组'scan.startup.mode' = 'latest-offset', -- 读取数据的位置earliest-offset latest-offset'format' = 'csv', -- 读取数据的格式'csv.ignore-parse-errors' = 'true' -- 如果数据解析异常自动跳过当前行
);
kafka-console-producer.sh --broker-list master:9092,node1:9092,node2:9092 --topic students
1500100001,tom,22,女,文科六班
1500100002,tom1,24,男,文科六班
1500100003,tom2,22,女,理科六班CREATE TABLE score_kafka (sid STRING,cid STRING,score INT
)WITH ('connector' = 'kafka','topic' = 'scores', -- 数据的topic'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092', -- broker 列表'properties.group.id' = 'testGroup', -- 消费者组'scan.startup.mode' = 'latest-offset', -- 读取数据的位置earliest-offset latest-offset'format' = 'csv', -- 读取数据的格式'csv.ignore-parse-errors' = 'true'
);
kafka-console-producer.sh --broker-list master:9092,node1:9092,node2:9092 --topic scores
1500100001,1000001,98
1500100001,1000002,5
1500100001,1000003,137SET 'execution.runtime-mode' = 'streaming'; -- 使用常规关联方式做流处理,flink会将两个表的数据一直保存在状态中,状态会越来越大
-- 可以设置状态有效期避免状态无限增大
SET 'table.exec.state.ttl' = '5000';-- full join
select a.sid,b.sid,a.name,b.score from
students_kafka as a
full join
score_kafka as b
on a.sid=b.sid;注意:以为在使用流处理的join的时候,首先流处理模式中,会将两张表中的实时数据存入当状态中
假设:前提是流处理模式,需要将两张实时的表中的姓名和成绩关联在一起,此时使用到join,当过了很长一段时间假设是一年,依旧可以将学生姓名和成绩关联在一起,原因就是之前的数据都会存储在状态中,但是也会产生问题,随着时间的推移,状态中的数据会越来越多。可能会导致任务失败。
可以通过参数指定保存状态的时间,时间一过,状态就会消失,数据就不存在:
-- 使用常规关联方式做流处理,flink会将两个表的数据一直保存在状态中,状态会越来越大
-- 可以设置状态有效期避免状态无限增大
SET 'table.exec.state.ttl' = '5000';'csv.ignore-parse-errors' = 'true'
-- 如果数据解析异常自动跳过当前行2、Interval Join
两个表在join时只关联一段时间内的数据,之前的数据就不需要保存在状态中,可以避免状态无限增大
CREATE TABLE students_kafka_time (sid STRING,name STRING,age INT,sex STRING,clazz STRING,ts TIMESTAMP(3),WATERMARK FOR ts AS ts - INTERVAL '5' SECOND
)WITH ('connector' = 'kafka','topic' = 'students', -- 数据的topic'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092', -- broker 列表'properties.group.id' = 'testGroup', -- 消费者组'scan.startup.mode' = 'latest-offset', -- 读取数据的位置earliest-offset latest-offset'format' = 'csv', -- 读取数据的格式'csv.ignore-parse-errors' = 'true' -- 如果数据解析异常自动跳过当前行
);
kafka-console-producer.sh --broker-list master:9092,node1:9092,node2:9092 --topic students
1500100001,tom,22,女,文科六班,2023-11-10 17:10:10
1500100001,tom1,24,男,文科六班,2023-11-10 17:10:11
1500100001,tom2,22,女,理科六班,2023-11-10 17:10:12CREATE TABLE score_kafka_time (sid STRING,cid STRING,score INT,ts TIMESTAMP(3),WATERMARK FOR ts AS ts - INTERVAL '5' SECOND
)WITH ('connector' = 'kafka','topic' = 'scores', -- 数据的topic'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092', -- broker 列表'properties.group.id' = 'testGroup', -- 消费者组'scan.startup.mode' = 'latest-offset', -- 读取数据的位置earliest-offset latest-offset'format' = 'csv', -- 读取数据的格式'csv.ignore-parse-errors' = 'true'
);
kafka-console-producer.sh --broker-list master:9092,node1:9092,node2:9092 --topic scores
1500100001,1000001,98,2023-11-10 17:10:09
1500100001,1000002,5,2023-11-10 17:10:11
1500100001,1000003,137,2023-11-10 17:10:12-- a.ts BETWEEN b.ts - INTERVAL '5' SECOND AND b.ts
-- a表数据的时间需要在b表数据的时间减去5秒到b表数据时间的范围内
SELECT a.sid,b.sid,a.name,b.score
FROM students_kafka_time a, score_kafka_time b
WHERE a.sid = b.sid
AND a.ts BETWEEN b.ts - INTERVAL '5' SECOND AND b.ts3、Temporal Joins
1、用于流表关联时态表,比如订单表和汇率表的关联
2、每一个时间数据都会存在不同的状态,如果只是用普通的关联,之恶能关联到最新的数
-- 订单表
CREATE TABLE orders (order_id STRING, -- 订单编号price DECIMAL(32,2), --订单金额currency STRING, -- 汇率编号order_time TIMESTAMP(3), -- 订单时间WATERMARK FOR order_time AS order_time -- 水位线
) WITH ('connector' = 'kafka','topic' = 'orders', -- 数据的topic'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092', -- broker 列表'properties.group.id' = 'testGroup', -- 消费者组'scan.startup.mode' = 'latest-offset', -- 读取数据的位置earliest-offset latest-offset'format' = 'csv' -- 读取数据的格式
);kafka-console-producer.sh --broker-list master:9092,node1:9092,node2:9092 --topic orders
001,100,CN,2023-11-11 09:48:10
002,200,CN,2023-11-11 09:48:11
003,300,CN,2023-11-11 09:48:14
004,400,CN,2023-11-11 09:48:16
005,500,CN,2023-11-11 09:48:18-- 汇率表
CREATE TABLE currency_rates (currency STRING, -- 汇率编号conversion_rate DECIMAL(32, 2), -- 汇率update_time TIMESTAMP(3), -- 汇率更新时间WATERMARK FOR update_time AS update_time, -- 水位线PRIMARY KEY(currency) NOT ENFORCED -- 主键
) WITH ('connector' = 'kafka','topic' = 'currency_rates', -- 数据的topic'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092', -- broker 列表'properties.group.id' = 'testGroup', -- 消费者组'scan.startup.mode' = 'earliest-offset', -- 读取数据的位置earliest-offset latest-offset'format' = 'canal-json' -- 读取数据的格式
);insert into currency_rates
values
('CN',7.2,TIMESTAMP'2023-11-11 09:48:05'),
('CN',7.1,TIMESTAMP'2023-11-11 09:48:10'),
('CN',6.9,TIMESTAMP'2023-11-11 09:48:15'),
('CN',7.4,TIMESTAMP'2023-11-11 09:48:20');kafka-console-consumer.sh --bootstrap-server master:9092,node1:9092,node2:9092 --from-beginning --topic currency_rates-- 如果使用常规关联方式,取的时最新的汇率,不是对应时间的汇率
select a.order_id,b.* from
orders as a
left join
currency_rates as b
on a.currency=b.currency;-- 时态表join
-- FOR SYSTEM_TIME AS OF orders.order_time: 使用订单表的时间到汇率表中查询对应时间的数据
SELECT order_id,price,conversion_rate,order_time
FROM orders
LEFT JOIN currency_rates FOR SYSTEM_TIME AS OF orders.order_time
ON orders.currency = currency_rates.currency;
4、Look Join:主要是用来关联维度表。维度表:指的是数据不怎么变化的表。
1、传统的方式是将数据库中的数据都读取到流表中,当来一条数据就会取关联一条数据。如果数据库中学生表更新了,flink不知道,关联不到最新的数据。
2、Look Join使用的原理:是当流表中的数据发生改变的时候,就会使用关联字段维表的数据源中查询数据。
优化:
在使用的时候可以使用缓存,将数据进行缓存,但是随着时间的推移,缓存的数量就会越来大,此时就可以对缓存设置一个过期时间。可以在建表的时候设置参数:
'lookup.cache.max-rows' = '1000', -- 缓存的最大行数'lookup.cache.ttl' = '20000' -- 缓存过期时间-- 学生表
CREATE TABLE students_jdbc (id BIGINT,name STRING,age BIGINT,gender STRING,clazz STRING,PRIMARY KEY (id) NOT ENFORCED -- 主键
) WITH ('connector' = 'jdbc','url' = 'jdbc:mysql://master:3306/student','table-name' = 'students','username' ='root','password' ='123456','lookup.cache.max-rows' = '1000', -- 缓存的最大行数'lookup.cache.ttl' = '20000' -- 缓存过期时间
);-- 分数表
CREATE TABLE score_kafka (sid BIGINT,cid STRING,score INT,proc_time as PROCTIME()
)WITH ('connector' = 'kafka','topic' = 'scores', -- 数据的topic'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092', -- broker 列表'properties.group.id' = 'testGroup', -- 消费者组'scan.startup.mode' = 'latest-offset', -- 读取数据的位置earliest-offset latest-offset'format' = 'csv', -- 读取数据的格式'csv.ignore-parse-errors' = 'true'
);
kafka-console-producer.sh --broker-list master:9092,node1:9092,node2:9092 --topic scores
1500100001,1000001,98
1500100001,1000002,5
1500100001,1000003,137-- 使用常规关联方式,关联维度表
-- 1、任务在启动的时候会将维表加载到flink 的状态中,如果数据库中学生表更新了,flink不知道,关联不到最新的数据
select
b.id,b.name,a.score
from
score_kafka as a
left join
students_jdbc as b
on a.sid=b.id; -- lookup join
-- FOR SYSTEM_TIME AS OF a.proc_time : 使用关联字段到维表中查询最新的数据
-- 优点: 流表每来一条数据都会去mysql中查询,可以关联到最新的数据
-- 每次查询mysql会降低性能
select
b.id,b.name,a.score
from
score_kafka as a
left join
students_jdbc FOR SYSTEM_TIME AS OF a.proc_time as b
on a.sid=b.id; 相关文章:
Flink SQL --命令行的使用(02)
1、窗口函数: 1、创建表: -- 创建kafka 表 CREATE TABLE bid (bidtime TIMESTAMP(3),price DECIMAL(10, 2) ,item STRING,WATERMARK FOR bidtime AS bidtime ) WITH (connector kafka,topic bid, -- 数据的topicproperties.bootstrap.servers m…...
)
【nlp】1.3 文本数据分析(标签数量分布、句子长度分布、词频统计与关键词词云)
文本数据分析 1 文本数据分析介绍2 数据集说明3 获取标签数量分布4 获取句子长度分布5 获取正负样本长度散点分布6 获取不同词汇总数统计7 获取训练集高频形容词词云8 获取验证集形容词词云1 文本数据分析介绍 文本数据分析的作用: 文本数据分析能够有效帮助我们理解数据语料…...
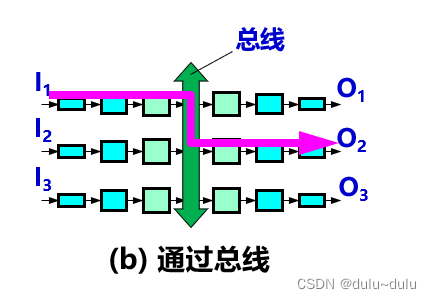
路由器的结构以及工作原理
目录 路由器的结构 交换结构三种常用的交换方式 1.通过存储器 2.通过总线 3.通过纵横交换结构(crossbar switch fabric) 路由器的结构 路由器结构可划分为两大部分:路由选择部分,分组转发部分 路由选择部分也叫做控制部分&…...
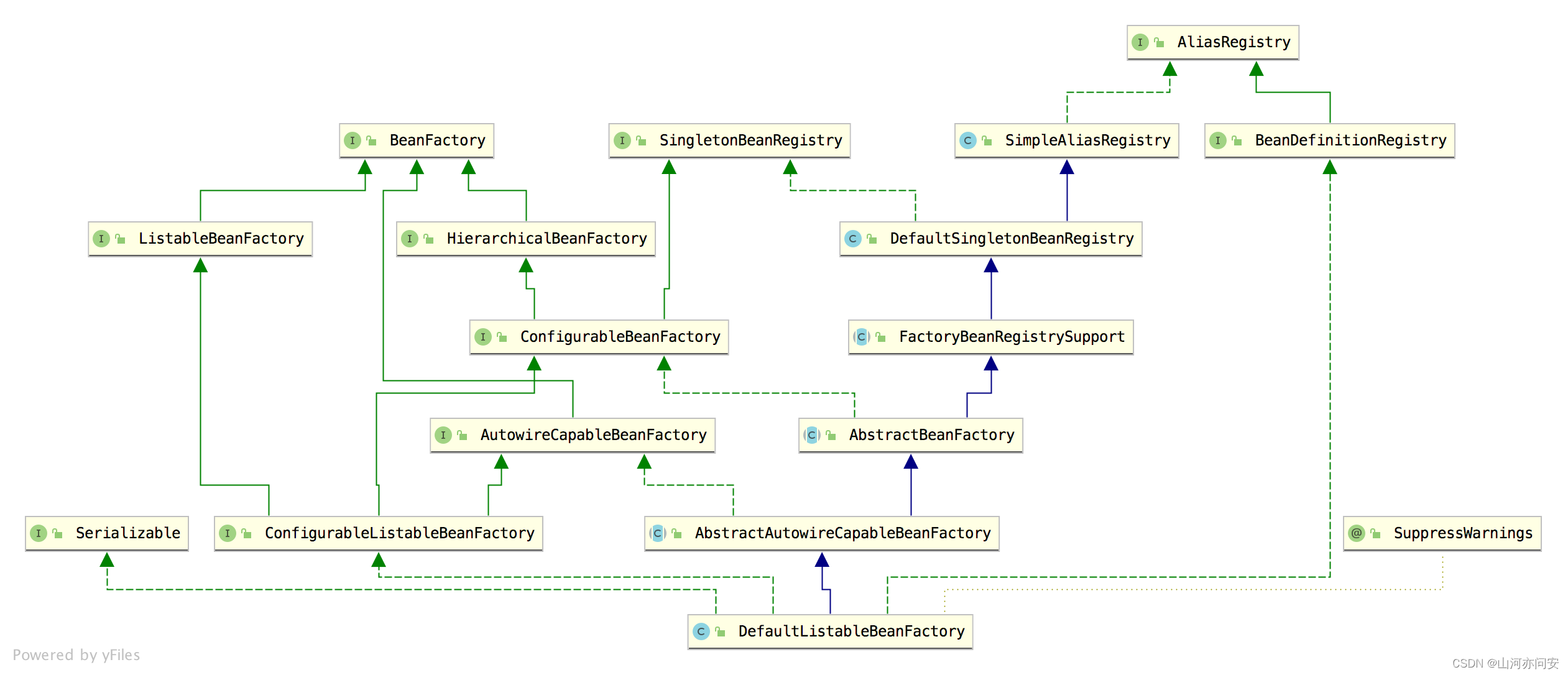
DefaultListableBeanFactory
DefaultListableBeanFactory 是一个完整的、功能成熟的 IoC 容器,如果你的需求很简单,甚至可以直接使用 DefaultListableBeanFactory,如果你的需求比较复杂,那么通过扩展 DefaultListableBeanFactory 的功能也可以达到,…...

NSF服务器
目录 1.简介 1.1 NFS背景介绍 1.2 生产应用场景 2.NFS工作原理 2.1 实例图 2.2 流程 3.NFS的使用 3.1.安装 3.2.配置文件 3.3.主配置文件分析 3.4 实验 服务端: 客户端: 3.5.NFS账户映射 3.5.1.实验2 3.5.2.实验3 4.autofs自动挂载服务…...

10 Go的映射
概述 在上一节的内容中,我们介绍了Go的结构体,包括:定义结构体、声明结构体变量、使用结构体、结构体关联函数、new、组合等。在本节中,我们将介绍Go的映射。Go语言中的映射(Map)是一种无序的键值对集合&am…...

瑞萨e2studio(29)----SPI速率解析
瑞萨e2studio.29--SPI速率解析 概述视频教学时钟配置解析RA4M2的BRR值时钟速率7.5M下寄存器值3K下寄存器值 概述 在嵌入式系统的设计中,串行外设接口(SPI)的通信速率是一个关键参数,它直接影响到系统的性能和稳定性。瑞萨电子的…...
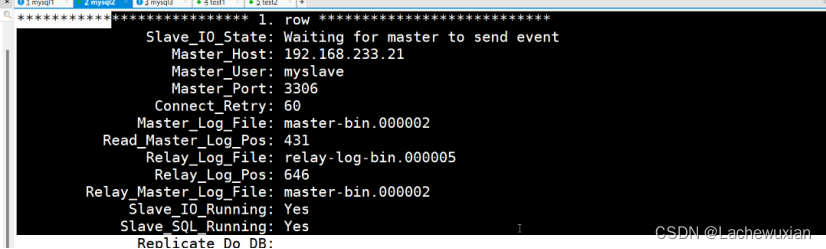
mysql的主从复制,读写分离
主从复制:主mysql的数据,新增,修改,表里的数据都会同步到从mysql上 主从复制的模式: 1 异步复制 mysql 的最常用的复制,只要执行完,客户端提交事务,主mysql 会立即把结果返回给从…...
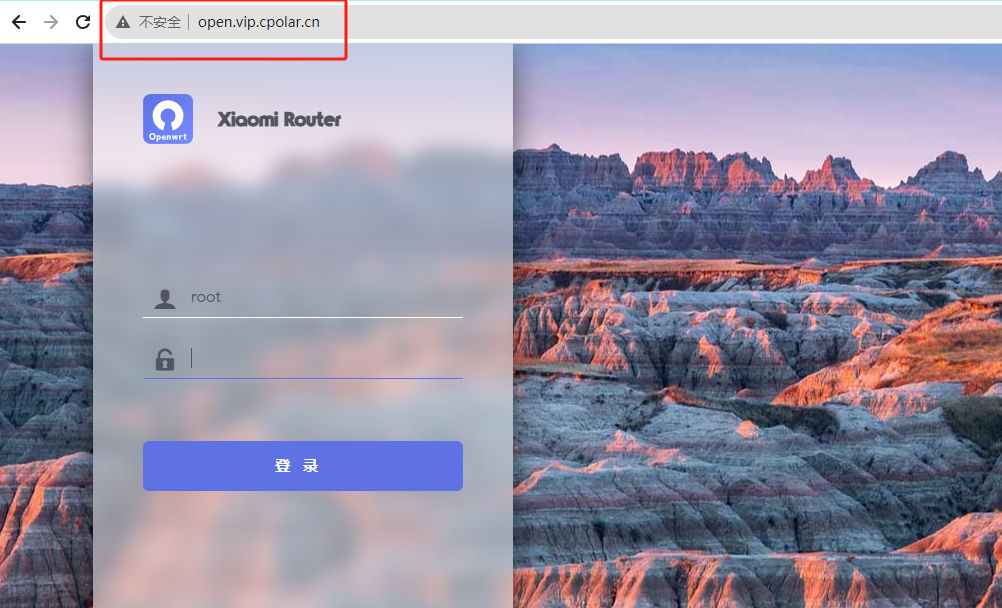
小米路由器4A千兆版刷入OpenWRT并远程访问
小米路由器4A千兆版刷入OpenWRT并远程访问 文章目录 小米路由器4A千兆版刷入OpenWRT并远程访问前言1. 安装Python和需要的库2. 使用 OpenWRTInvasion 破解路由器3. 备份当前分区并刷入新的Breed4. 安装cpolar内网穿透4.1 注册账号4.2 下载cpolar客户端4.3 登录cpolar web ui管理…...
)
【golang】探索for-range遍历实现原理(slice、map、channel)
for-range for-range其实是正常for循环的一种语法糖,在go语言中可以遍历arr,slice,map和channel等数据结构,但是在一些初学者使用for-range可能会遇见很多坑,这篇文章会带你探索一下for-range中非常有趣的一些实现机制…...


MATLAB | 官方举办的动图绘制大赛 | 第一周赛情回顾
嘿真的又是很久没见了,最近确实有点非常很特别小忙,今天带来一下MATHWORKS官方举办的迷你黑客大赛第三期(MATLAB Flipbook Mini Hack)的最新进展!!目前比赛已经刚好进行了一周,前两届都要求提交280个字符内的代码来生成…...
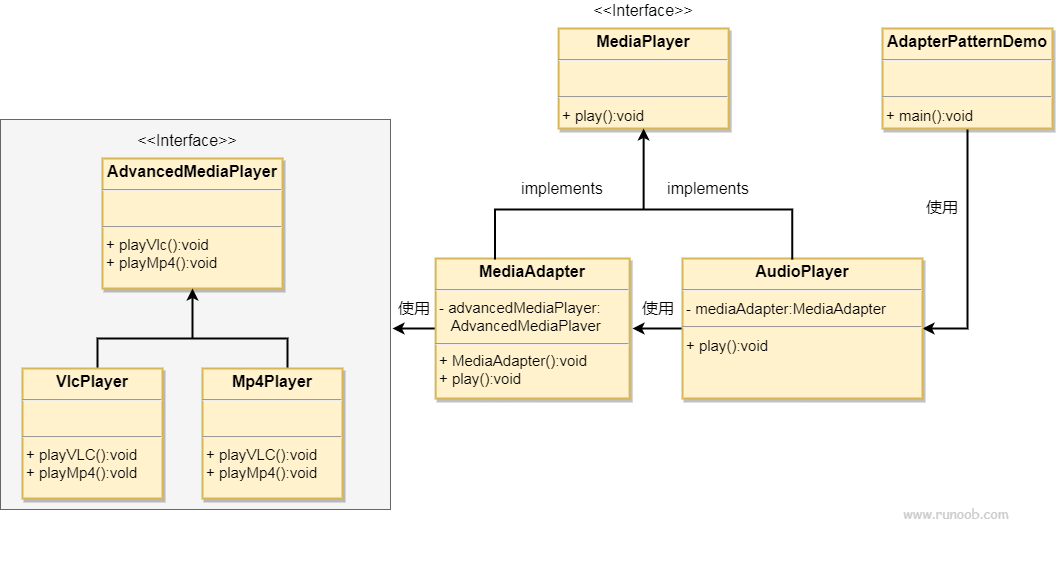
适配器模式 rust和java的实现
文章目录 适配器模式介绍何时使用应用实例优点缺点使用场景 实现java实现rust 实现 rust代码仓库 适配器模式 适配器模式(Adapter Pattern)是作为两个不兼容的接口之间的桥梁。这种类型的设计模式属于结构型模式,它结合了两个独立接口的功能…...

竞赛 题目:垃圾邮件(短信)分类 算法实现 机器学习 深度学习 开题
文章目录 1 前言2 垃圾短信/邮件 分类算法 原理2.1 常用的分类器 - 贝叶斯分类器 3 数据集介绍4 数据预处理5 特征提取6 训练分类器7 综合测试结果8 其他模型方法9 最后 1 前言 🔥 优质竞赛项目系列,今天要分享的是 基于机器学习的垃圾邮件分类 该项目…...
wpf devexpress项目中添加GridControl绑定数据
本教程讲解了如何添加GridControl到wpf项目中并且绑定数据 原文地址Lesson 1 - Add a GridControl to a Project and Bind it to Data | WPF Controls | DevExpress Documentation 1、使用 DevExpress Template Gallery创建一个新的空白mvvm应用程序,这个项目包括了…...

2023亚太杯数学建模A题思路解析
文章目录 0 赛题思路1 竞赛信息2 竞赛时间3 建模常见问题类型3.1 分类问题3.2 优化问题3.3 预测问题3.4 评价问题 4 建模资料5 最后 0 赛题思路 (赛题出来以后第一时间在CSDN分享) https://blog.csdn.net/dc_sinor?typeblog 1 竞赛信息 2023年第十三…...
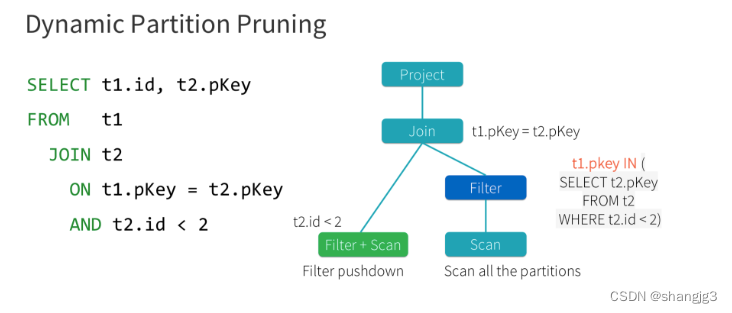
Spark3.0中的AOE、DPP和Hint增强
1 Spark3.0 AQE Spark 在 3.0 版本推出了 AQE(Adaptive Query Execution),即自适应查询执行。AQE 是 Spark SQL 的一种动态优化机制,在运行时,每当 Shuffle Map 阶段执行完毕,AQE 都会结合这个阶段的统计信…...

算法笔记-第五章-质因子分解
算法笔记-第五章-质因子分解 小试牛刀质因子2的个数丑数 质因子分解最小最大质因子约数个数 小试牛刀 质因子2的个数 #include<cstdio> int main() {int n; scanf_s("%d", &n); int count 0; while (n % 2 0) {count; n / 2; }printf("%…...
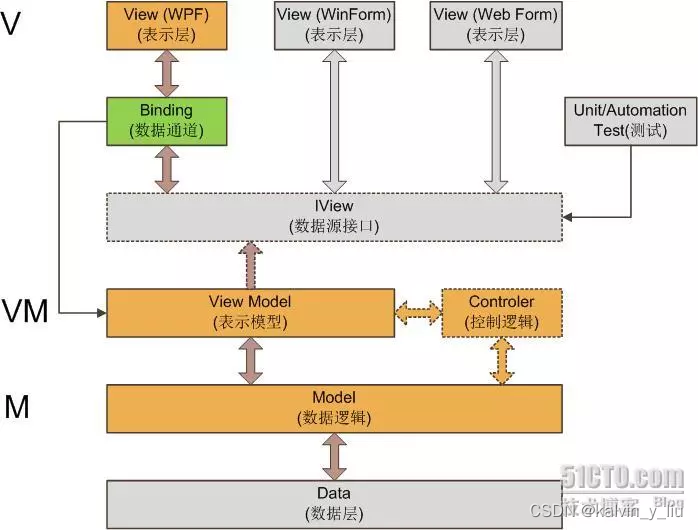
适用于WPF的设计模式
适用于WPF的设计模式 讨论“XAML能不能写逻辑代码”这个问题。我发现这是个有歧义的问题。这个问题可以有两种意思: XAML能不能用来写逻辑代码? XAML文件里能不能包含逻辑代码? 对于第一种意思——XAML是一种声明性语言,就是用来…...

C++与多态
多态的本质是允许对象以其实际类型的行为方式来操作,而不仅仅是其静态类型所声明的方式。 多态是面向对象编程中的一种核心概念,它允许对象根据其具体类型执行相应的操作,而不是其声明的类型。我们可以使用一个经典的动物的例子来说明这一点。…...

DeepSeek代码质量评估实战手册:7步完成从混沌到可度量的质变跃迁
更多请点击: https://kaifayun.com 第一章:DeepSeek代码质量评估的底层逻辑与核心价值 DeepSeek代码质量评估并非简单地统计行数或检测语法错误,而是基于多维语义理解构建的推理系统。其底层逻辑融合了静态分析、符号执行与大语言模型生成式…...

D3KeyHelper:暗黑3玩家的智能按键助手,告别重复操作疲劳
D3KeyHelper:暗黑3玩家的智能按键助手,告别重复操作疲劳 【免费下载链接】D3keyHelper D3KeyHelper是一个有图形界面,可自定义配置的暗黑3鼠标宏工具。 项目地址: https://gitcode.com/gh_mirrors/d3/D3keyHelper 你是否曾在《暗黑破坏…...

对比 Token Plan 与按量计费在 Taotoken 平台上的成本体感差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比 Token Plan 与按量计费在 Taotoken 平台上的成本体感差异 对于个人开发者或项目管理者而言,在接入大模型服务时&a…...

机器学习与SHAP在教育公平研究中的应用:精准定位学业困境根源
1. 项目概述:当机器学习遇见教育公平,我们如何精准定位学业困境的根源?在拉丁美洲的教育研究领域,一个长期困扰政策制定者和研究者的核心问题是:究竟是什么因素,在复杂的社会经济背景下,系统性地…...

UE5 Mac环境搭好了,然后呢?给新手的第一个5分钟:创建、操控并理解你的第一个角色
UE5 Mac环境搭好了,然后呢?给新手的第一个5分钟:创建、操控并理解你的第一个角色当你第一次打开UE5的Mac版本,面对那个闪烁着光芒的启动界面,内心可能既兴奋又忐忑。安装只是第一步,真正的旅程现在才开始。…...

量子机器学习与傅里叶分析:革新期权定价的混合计算范式
1. 项目概述:当量子机器学习遇见金融定价在金融工程的核心地带,期权定价一直是个计算密集型的硬骨头。传统的蒙特卡洛模拟虽然通用,但为了达到足够的精度,动辄需要百万甚至千万次的路径模拟,计算成本高昂。近年来&…...
)
用ESP32-C3的PWM做个RGB呼吸灯吧:从配置结构体到色彩渐变(乐鑫ESP-IDF实战)
ESP32-C3 RGB呼吸灯实战:从PWM配置到色彩渐变算法 当智能家居的灯光不再只是简单的开关控制,而是能像呼吸般自然渐变时,整个空间的氛围立刻变得生动起来。ESP32-C3凭借其出色的LED PWM控制器(LEDC)外设,为开…...

框架组件识别:从版本号到利用链的渗透实战指南
1. 这不是“扫个版本号”那么简单:框架组件识别在真实渗透中的战略定位 很多人看到“框架组件识别”,第一反应是跑个whatweb、wappalyzer,截图发报告里写一句“识别到Spring Boot 2.6.3”,就算交差了。我干这行十多年,…...
Elsevier-Tracker:5分钟打造您的学术论文审稿进度监控系统
Elsevier-Tracker:5分钟打造您的学术论文审稿进度监控系统 【免费下载链接】Elsevier-Tracker 项目地址: https://gitcode.com/gh_mirrors/el/Elsevier-Tracker 在科研工作者的日常中,论文审稿进度追踪常常成为消耗时间与精力的隐形负担。每天反…...

QuickDraw MediaPipe手势识别:无需画笔的手势控制绘画应用
QuickDraw MediaPipe手势识别:无需画笔的手势控制绘画应用 【免费下载链接】QuickDraw Implementation of Quickdraw - an online game developed by Google 项目地址: https://gitcode.com/gh_mirrors/qu/QuickDraw QuickDraw MediaPipe手势识别是一款创新…...