深度学习 大数据 股票预测系统 - python lstm 计算机竞赛
文章目录
- 0 前言
- 1 课题意义
- 1.1 股票预测主流方法
- 2 什么是LSTM
- 2.1 循环神经网络
- 2.1 LSTM诞生
- 2 如何用LSTM做股票预测
- 2.1 算法构建流程
- 2.2 部分代码
- 3 实现效果
- 3.1 数据
- 3.2 预测结果
- 项目运行展示
- 开发环境
- 数据获取
- 最后
0 前言
🔥 优质竞赛项目系列,今天要分享的是
🚩 深度学习 大数据 股票预测系统
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:3分
- 创新点:4分
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
1 课题意义
利用神经网络模型如果能够提高对股票价格的预测精度,更好地掌握股票价格发展趋势,这对于投资者来说可以及时制定相应的发展策略,更好地应对未来发生的不确定性事件,对于个人来说可以降低投资风险,减少财产损失,实现高效投资,具有一定的实践价值。
1.1 股票预测主流方法
股票市场复杂、非线性的特点使我们难以捉摸其变化规律,目前有很多预测股票走势的论文和算法。
定量分析从精确的数据资料中获得股票发展的价值规律,通过建立模型利用数学语言对股市的发展情况做出解释与预测。
目前常用的定量分析方法有:
- 传统时间序列预测模型
- 马尔可夫链预测
- 灰色系统理论预测
- 遗传算法
- 机器学习预测等方法
2 什么是LSTM
LSTM是长短期记忆网络(LSTM,Long Short-Term Memory),想要理解什么是LSTM,首先要了解什么是循环神经网络。
2.1 循环神经网络
对于传统的BP神经网络如深度前馈网络、卷积神经网络来说,同层及跨层之间的神经元是独立的,但实际应用中对于一些有上下联系的序列来说,如果能够学习到它们之间的相互关系,使网络能够对不同时刻的输入序列产生一定的联系,像生物的大脑一样有“记忆功能”,这样的话我们的模型也就会有更低的训练出错频率及更好的泛化能力。
JordanMI提出序列理论,描述了一种体现“并行分布式处理”的网络动态系统,适用于语音生成中的协同发音问题,并进行了相关仿真实验,ElmanJL认为连接主义模型中对时间如何表示是至关重要的,1990年他提出使用循环连接为网络提供动态内存,从相对简单的异或问题到探寻单词的语义特征,网络均学习到了有趣的内部表示,网络还将任务需求和内存需求结合在一起,由此形成了简单循环网络的基础框架。
循环神经网络(RNN)之间的神经元是相互连接的,不仅在层与层之间的神经元建立连接,而且每一层之间的神经元也建立了连接,隐藏层神经元的输入由当前输入和上一时刻隐藏层神经元的输出共同决定,每一时刻的隐藏层神经元记住了上一时刻隐藏层神经元的输出,相当于对网络增添了“记忆”功能。我们都知道在输入序列中不可避免会出现重复或相似的某些序列信息,我们希望RNN能够保留这些记忆信息便于再次调用,且RNN结构中不同时刻参数是共享的,这一优点便于网络在不同位置依旧能将该重复信息识别出来,这样一来模型的泛化能力自然有所上升。
RNN结构如下:
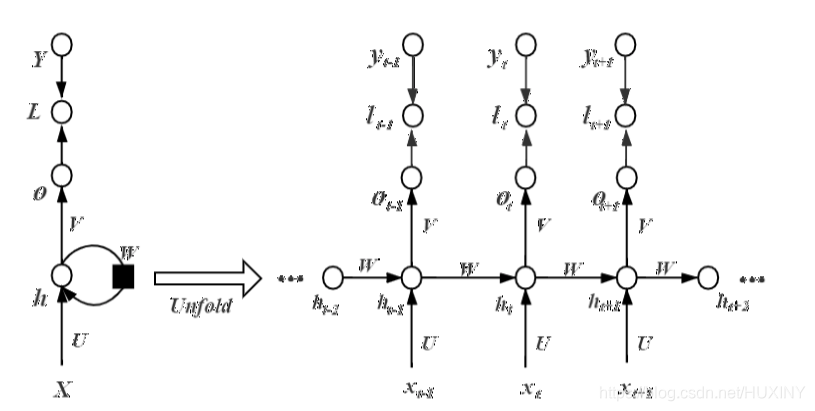
2.1 LSTM诞生
RNN在解决长序列问题时未能有良好的建模效果,存在长期依赖的弊端,对此HochreiterS等人对神经单元做出了改进,引入自循环使梯度信息得以长时间持续流动,即模型可以拥有长期记忆信息,且自循环权重可以根据前后信息进行调整并不是固定的。作为RNN的一种特殊结构,它可以根据前后输入情况决定历史信息的去留,增进的门控机制可以动态改变累积的时间尺度进而控制神经单元的信息流,这样神经网络便能够自己根据情况决定清除或保留旧的信息,不至于状态信息过长造成网络崩溃,这便是长短期记忆(LSTM)网络。随着信息不断流入,该模型每个神经元内部的遗忘门、输入门、输出门三个门控机制会对每一时刻的信息做出判断并及时进行调整更新,LSTM模型现已广泛应用于无约束手写识别、语音识别、机器翻译等领域。
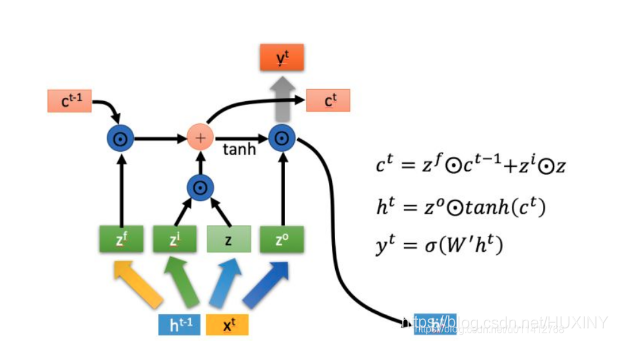
2 如何用LSTM做股票预测
2.1 算法构建流程

2.2 部分代码
import numpy as npimport matplotlib.pyplot as pltimport tensorflow as tfimport pandas as pdimport mathdef LSTMtest(data):n1 = len(data[0]) - 1 #因为最后一位为labeln2 = len(data)print(n1, n2)# 设置常量input_size = n1 # 输入神经元个数rnn_unit = 10 # LSTM单元(一层神经网络)中的中神经元的个数lstm_layers = 7 # LSTM单元个数output_size = 1 # 输出神经元个数(预测值)lr = 0.0006 # 学习率train_end_index = math.floor(n2*0.9) # 向下取整print('train_end_index', train_end_index)# 前90%数据作为训练集,后10%作为测试集# 获取训练集# time_step 时间步,batch_size 每一批次训练多少个样例def get_train_data(batch_size=60, time_step=20, train_begin=0, train_end=train_end_index):batch_index = []data_train = data[train_begin:train_end]normalized_train_data = (data_train - np.mean(data_train, axis=0)) / np.std(data_train, axis=0) # 标准化train_x, train_y = [], [] # 训练集for i in range(len(normalized_train_data) - time_step):if i % batch_size == 0:# 开始位置batch_index.append(i)# 一次取time_step行数据# x存储输入维度(不包括label) :X(最后一个不取)# 标准化(归一化)x = normalized_train_data[i:i + time_step, :n1]# y存储labely = normalized_train_data[i:i + time_step, n1, np.newaxis]# np.newaxis分别是在行或列上增加维度train_x.append(x.tolist())train_y.append(y.tolist())# 结束位置batch_index.append((len(normalized_train_data) - time_step))print('batch_index', batch_index)# print('train_x', train_x)# print('train_y', train_y)return batch_index, train_x, train_y# 获取测试集def get_test_data(time_step=20, test_begin=train_end_index+1):data_test = data[test_begin:]mean = np.mean(data_test, axis=0)std = np.std(data_test, axis=0) # 矩阵标准差# 标准化(归一化)normalized_test_data = (data_test - np.mean(data_test, axis=0)) / np.std(data_test, axis=0)# " // "表示整数除法。有size个sampletest_size = (len(normalized_test_data) + time_step - 1) // time_stepprint('test_size$$$$$$$$$$$$$$', test_size)test_x, test_y = [], []for i in range(test_size - 1):x = normalized_test_data[i * time_step:(i + 1) * time_step, :n1]y = normalized_test_data[i * time_step:(i + 1) * time_step, n1]test_x.append(x.tolist())test_y.extend(y)test_x.append((normalized_test_data[(i + 1) * time_step:, :n1]).tolist())test_y.extend((normalized_test_data[(i + 1) * time_step:, n1]).tolist())return mean, std, test_x, test_y# ——————————————————定义神经网络变量——————————————————# 输入层、输出层权重、偏置、dropout参数# 随机产生 w,bweights = {'in': tf.Variable(tf.random_normal([input_size, rnn_unit])),'out': tf.Variable(tf.random_normal([rnn_unit, 1]))}biases = {'in': tf.Variable(tf.constant(0.1, shape=[rnn_unit, ])),'out': tf.Variable(tf.constant(0.1, shape=[1, ]))}keep_prob = tf.placeholder(tf.float32, name='keep_prob') # dropout 防止过拟合# ——————————————————定义神经网络——————————————————def lstmCell():# basicLstm单元# tf.nn.rnn_cell.BasicLSTMCell(self, num_units, forget_bias=1.0,# tate_is_tuple=True, activation=None, reuse=None, name=None) # num_units:int类型,LSTM单元(一层神经网络)中的中神经元的个数,和前馈神经网络中隐含层神经元个数意思相同# forget_bias:float类型,偏置增加了忘记门。从CudnnLSTM训练的检查点(checkpoin)恢复时,必须手动设置为0.0。# state_is_tuple:如果为True,则接受和返回的状态是c_state和m_state的2-tuple;如果为False,则他们沿着列轴连接。后一种即将被弃用。# (LSTM会保留两个state,也就是主线的state(c_state),和分线的state(m_state),会包含在元组(tuple)里边# state_is_tuple=True就是判定生成的是否为一个元组)# 初始化的 c 和 a 都是zero_state 也就是都为list[]的zero,这是参数state_is_tuple的情况下# 初始state,全部为0,慢慢的累加记忆# activation:内部状态的激活函数。默认为tanh# reuse:布尔类型,描述是否在现有范围中重用变量。如果不为True,并且现有范围已经具有给定变量,则会引发错误。# name:String类型,层的名称。具有相同名称的层将共享权重,但为了避免错误,在这种情况下需要reuse=True.#basicLstm = tf.nn.rnn_cell.BasicLSTMCell(rnn_unit, forget_bias=1.0, state_is_tuple=True)# dropout 未使用drop = tf.nn.rnn_cell.DropoutWrapper(basicLstm, output_keep_prob=keep_prob)return basicLstmdef lstm(X): # 参数:输入网络批次数目batch_size = tf.shape(X)[0]time_step = tf.shape(X)[1]w_in = weights['in']b_in = biases['in']# 忘记门(输入门)# 因为要进行矩阵乘法,所以reshape# 需要将tensor转成2维进行计算input = tf.reshape(X, [-1, input_size])input_rnn = tf.matmul(input, w_in) + b_in# 将tensor转成3维,计算后的结果作为忘记门的输入input_rnn = tf.reshape(input_rnn, [-1, time_step, rnn_unit])print('input_rnn', input_rnn)# 更新门# 构建多层的lstmcell = tf.nn.rnn_cell.MultiRNNCell([lstmCell() for i in range(lstm_layers)])init_state = cell.zero_state(batch_size, dtype=tf.float32)# 输出门w_out = weights['out']b_out = biases['out']# output_rnn是最后一层每个step的输出,final_states是每一层的最后那个step的输出output_rnn, final_states = tf.nn.dynamic_rnn(cell, input_rnn, initial_state=init_state, dtype=tf.float32)output = tf.reshape(output_rnn, [-1, rnn_unit])# 输出值,同时作为下一层输入门的输入pred = tf.matmul(output, w_out) + b_outreturn pred, final_states# ————————————————训练模型————————————————————def train_lstm(batch_size=60, time_step=20, train_begin=0, train_end=train_end_index):# 于是就有了tf.placeholder,# 我们每次可以将 一个minibatch传入到x = tf.placeholder(tf.float32,[None,32])上,# 下一次传入的x都替换掉上一次传入的x,# 这样就对于所有传入的minibatch x就只会产生一个op,# 不会产生其他多余的op,进而减少了graph的开销。X = tf.placeholder(tf.float32, shape=[None, time_step, input_size])Y = tf.placeholder(tf.float32, shape=[None, time_step, output_size])batch_index, train_x, train_y = get_train_data(batch_size, time_step, train_begin, train_end)# 用tf.variable_scope来定义重复利用,LSTM会经常用到with tf.variable_scope("sec_lstm"):pred, state_ = lstm(X) # pred输出值,state_是每一层的最后那个step的输出print('pred,state_', pred, state_)# 损失函数# [-1]——列表从后往前数第一列,即pred为预测值,Y为真实值(Label)#tf.reduce_mean 函数用于计算张量tensor沿着指定的数轴(tensor的某一维度)上的的平均值loss = tf.reduce_mean(tf.square(tf.reshape(pred, [-1]) - tf.reshape(Y, [-1])))# 误差loss反向传播——均方误差损失# 本质上是带有动量项的RMSprop,它利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。# Adam的优点主要在于经过偏置校正后,每一次迭代学习率都有个确定范围,使得参数比较平稳.train_op = tf.train.AdamOptimizer(lr).minimize(loss)saver = tf.train.Saver(tf.global_variables(), max_to_keep=15)with tf.Session() as sess:# 初始化sess.run(tf.global_variables_initializer())theloss = []# 迭代次数for i in range(200):for step in range(len(batch_index) - 1):# sess.run(b, feed_dict = replace_dict)state_, loss_ = sess.run([train_op, loss],feed_dict={X: train_x[batch_index[step]:batch_index[step + 1]],Y: train_y[batch_index[step]:batch_index[step + 1]],keep_prob: 0.5})# 使用feed_dict完成矩阵乘法 处理多输入# feed_dict的作用是给使用placeholder创建出来的tensor赋值# [batch_index[step]: batch_index[step + 1]]这个区间的X与Y# keep_prob的意思是:留下的神经元的概率,如果keep_prob为0的话, 就是让所有的神经元都失活。print("Number of iterations:", i, " loss:", loss_)theloss.append(loss_)print("model_save: ", saver.save(sess, 'model_save2\\modle.ckpt'))print("The train has finished")return thelosstheloss = train_lstm()# 相对误差=(测量值-计算值)/计算值×100%test_y = np.array(test_y) * std[n1] + mean[n1]test_predict = np.array(test_predict) * std[n1] + mean[n1]acc = np.average(np.abs(test_predict - test_y[:len(test_predict)]) / test_y[:len(test_predict)])print("预测的相对误差:", acc)print(theloss)plt.figure()plt.plot(list(range(len(theloss))), theloss, color='b', )plt.xlabel('times', fontsize=14)plt.ylabel('loss valuet', fontsize=14)plt.title('loss-----blue', fontsize=10)plt.show()# 以折线图表示预测结果plt.figure()plt.plot(list(range(len(test_predict))), test_predict, color='b', )plt.plot(list(range(len(test_y))), test_y, color='r')plt.xlabel('time value/day', fontsize=14)plt.ylabel('close value/point', fontsize=14)plt.title('predict-----blue,real-----red', fontsize=10)plt.show()prediction()需要完整代码工程的同学,请联系学长获取
3 实现效果
3.1 数据
采集股票数据
任选几支股票作为研究对象。
3.2 预测结果
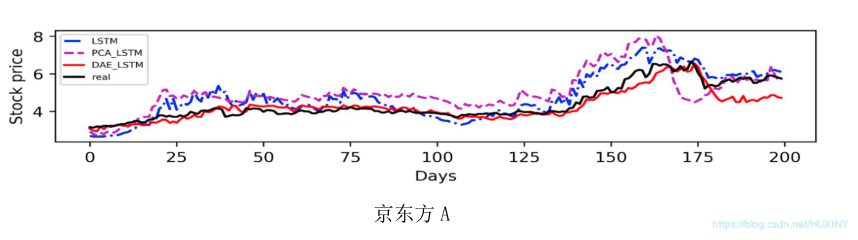
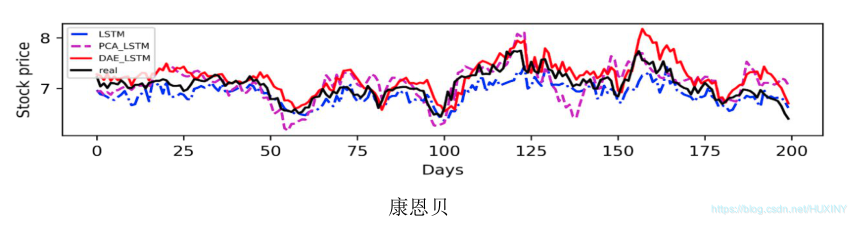
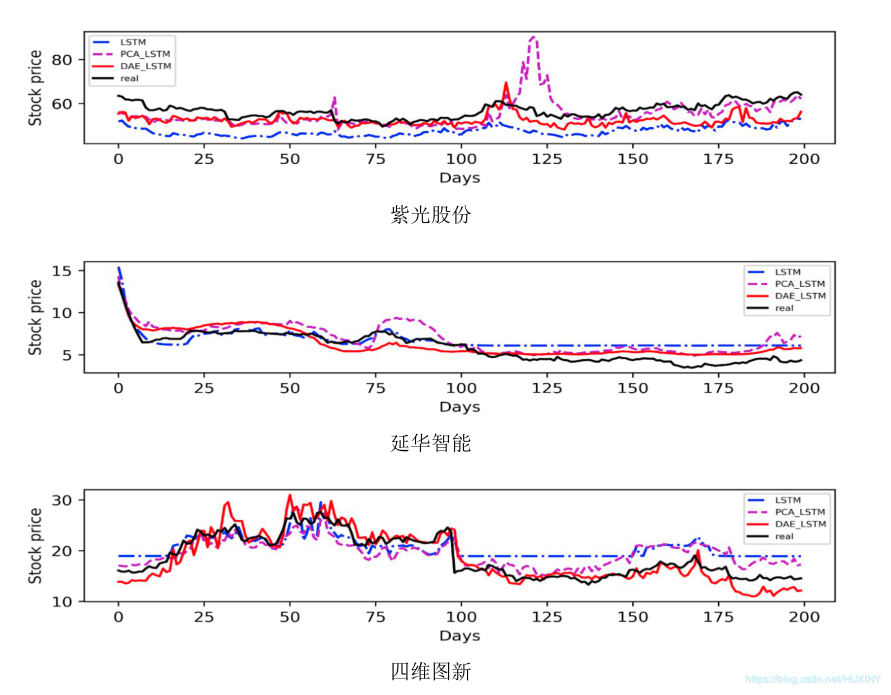
项目运行展示
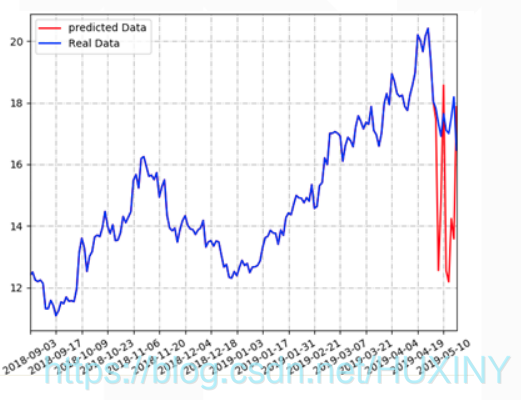
废话不多说, 先展示项目运行结果, 后面才进行技术讲解
对某公司的股票进行分析和预测 :

开发环境
如果只运行web项目,则只需安装如下包:
-
python 3.6.x
-
django >= 2.1.4 (或者使用conda安装最新版)
-
pandas >= 0.23.4 (或者使用conda安装最新版)
-
numpy >= 1.15.2 (或者使用conda安装最新版)
*apscheduler = 2.1.2 (请用pip install apscheduler==2.1.2 安装,conda装的版本不兼容)
如果需要训练模型或者使用模型来预测(注:需要保证本机拥有 NVIDIA GPU以及显卡驱动),则还需要安装: -
tensorflow-gpu >= 1.10.0 (可以使用conda安装最新版。如用conda安装,cudatoolkit和cudnn会被自动安装)
-
cudatoolkit >= 9.0 (根据自己本机的显卡型号决定,请去NVIDIA官网查看)
-
cudnn >= 7.1.4 (版本与cudatoolkit9.0对应的,其他版本请去NVIDIA官网查看对应的cudatoolkit版本)
-
keras >= 2.2.2 (可以使用conda安装最新版)
-
matplotlib >= 2.2.2 (可以使用conda安装最新版)
数据获取
训练模型的数据,即10个公司的历史股票数据。获取国内上市公司历史股票数据,
并以csv格式保存下来。csv格式方便用pandas读取,输入到LSTM神经网络模型, 用于训练模型以及预测股票数据。
最后
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
相关文章:
深度学习 大数据 股票预测系统 - python lstm 计算机竞赛
文章目录 0 前言1 课题意义1.1 股票预测主流方法 2 什么是LSTM2.1 循环神经网络2.1 LSTM诞生 2 如何用LSTM做股票预测2.1 算法构建流程2.2 部分代码 3 实现效果3.1 数据3.2 预测结果项目运行展示开发环境数据获取 最后 0 前言 🔥 优质竞赛项目系列,今天…...
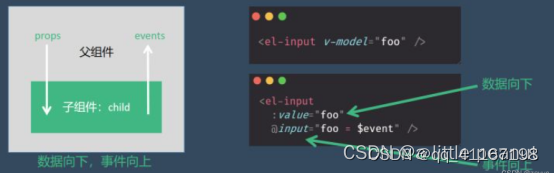
vue v-model
一、为什么使用v-model? v-model指令可以在表单input、textarea以及select元素上创建双向数据绑定。它会根据控件类型自动选取正确的方法来更新元素。本质上是语法糖,负责监听用户的输入事件来更新数据。 二、什么场景下会使用v-model? ①…...

springboot整合ELK
ELK是一种强大的分布式日志管理解决方案,它由三个核心组件组成: Elasticsearch:作为分布式搜索和分析引擎,Elasticsearch能够快速地存储、搜索和分析大量的日志数据,帮助用户轻松地找到所需的信息。 Logstashÿ…...

线性表->栈
文章目录 前言概述栈的初始化销毁压栈出栈判断栈为不为空栈的有效个数 前言 栈相对于链表,稍微简单一点,但是栈的难点在于通过栈去理解递归算法。 概述 **栈:**一种特殊的线性表,其只允许在固定的一端进行插入和删除元素操作。…...

linux rsyslog日志采集格式设定一
linux rsyslog日志采集格式设定一 1.创建日志接收模板 打开/etc/rsyslog.conf文件,在GLOBAL DIRECTIVES模块下任意位置添加以下内容 命令: vim /etc/rsyslog.conf 测试:rsyslog.conf文件结尾添加以下内容 $template ztj,"/var/log/%hostname%/%programname%.log&…...
)
[100天算法】-不同路径 III(day 75)
题目描述 在二维网格 grid 上,有 4 种类型的方格:1 表示起始方格。且只有一个起始方格。 2 表示结束方格,且只有一个结束方格。 0 表示我们可以走过的空方格。 -1 表示我们无法跨越的障碍。 返回在四个方向(上、下、左、右&#…...

【学习笔记】[CCO2021] Travelling Merchant
不难看出,这是一道在图上 D P DP DP的问题。设 f i f_i fi表示从 i i i出发,能够不停的游走下去,所需要的最少的初始资产。可以写出粗略的转移: f u min ( f u , max ( f v − p i , r i ) ) f_u\min(f_u,\max(f_v-p_i,r…...

【终端】记录mbedtls库的重新安装
记录mbedtls库的在终端上重新安装的步骤 ffmpeg -version dyld[17464]: Library not loaded: /usr/local/opt/mbedtls/lib/libmbedcrypto.14.dylibReferenced from: /usr/local/Cellar/librist/0.2.7_3/lib/librist.4.dylibReason: tried: /usr/local/opt/mbedtls/lib/libmbed…...
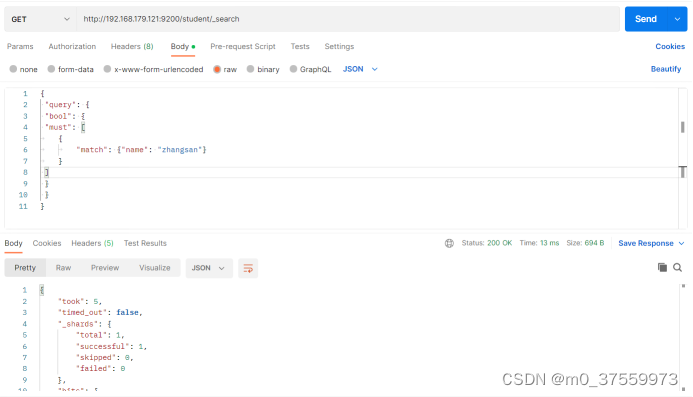
ElasticSearch简单操作
目录 1.单机部署 1.1 解压软件 1.2 创建软链接 1.3 修改配置文件 1.4 配置环境变量 1.5 后台启动 2.配置分词器 2.1 安装IK分词器 2.2 ES 扩展词汇 3.常用操作 3.1 索引 3.1.1 创建索引 3.1.2 查看所有索引 3.1.3 查看单个索引 3.1.4 删除索引 3.2.文档 3.2.1…...
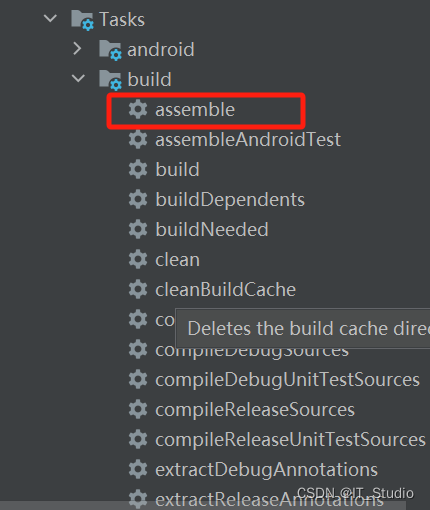
android studio新版本gradle Tasks找不到assemble
最近需要打包arr,但android studio新版本为了加快编译速度,取消了gradle下的assemble任务,网上还没有博主更新解决方案,因此一直找不到解决方案,后来尝试如下操作才解决,方便后来者解决。 先将这里勾选上&…...

uniapp 小程序 身份证 和人脸视频拍摄
使用前提: 已经在微信公众平台的用户隐私协议,已经选择配置“摄像头,录像”等权限 开发背景:客户需要使用带有拍摄边框的摄像头 ,微信小程序的方法无法支持,使用camera修改 身份证正反面: <…...

飞腾ARM UOS编译Qt 5.15.2源码及Qt Creator
背景 在 ARM 架构下,UOS 系统,需要使用 Qt 5.15.2 版本环境,所以只能通过源码编译的形式进行 Qt 环境的部署。 软硬件相关信息: 处理器: 飞腾 FT-2000 4 核制造商: Phytium架构: aarch 64家族: ARMv 8系统:UOS V 20…...
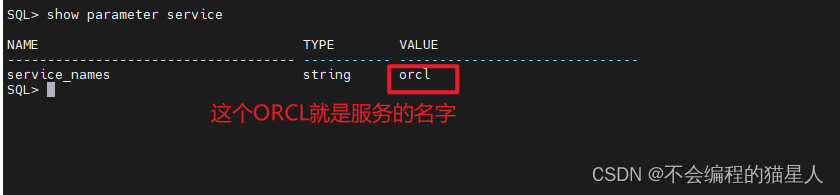
Oracle(2-2)Oracle Net Architecture
文章目录 一、基础知识1、Oracle Net Connections Oracle网络连接2、C/S Application Connection C/S应用程序连接3、OSI Communication Layers OSI通信层4、Oracle Protocol Support Oracle协议支持5、B/S Application Connections B/S应用程序连接6、TwoTypes JDBC Drivers 两…...

高速高精运动控制,富唯智能AI边缘控制器助力自动化行业变革
随着工业大数据时代的到来,传统控制与决策方式无法满足现代数字化工厂对工业大数据分析与决策的需求,AI边缘控制器赋能现代化智慧工厂,实现工业智造与行业变革。 富唯智能AI边缘控制器,基于x86架构的IPC形态产品,通过…...
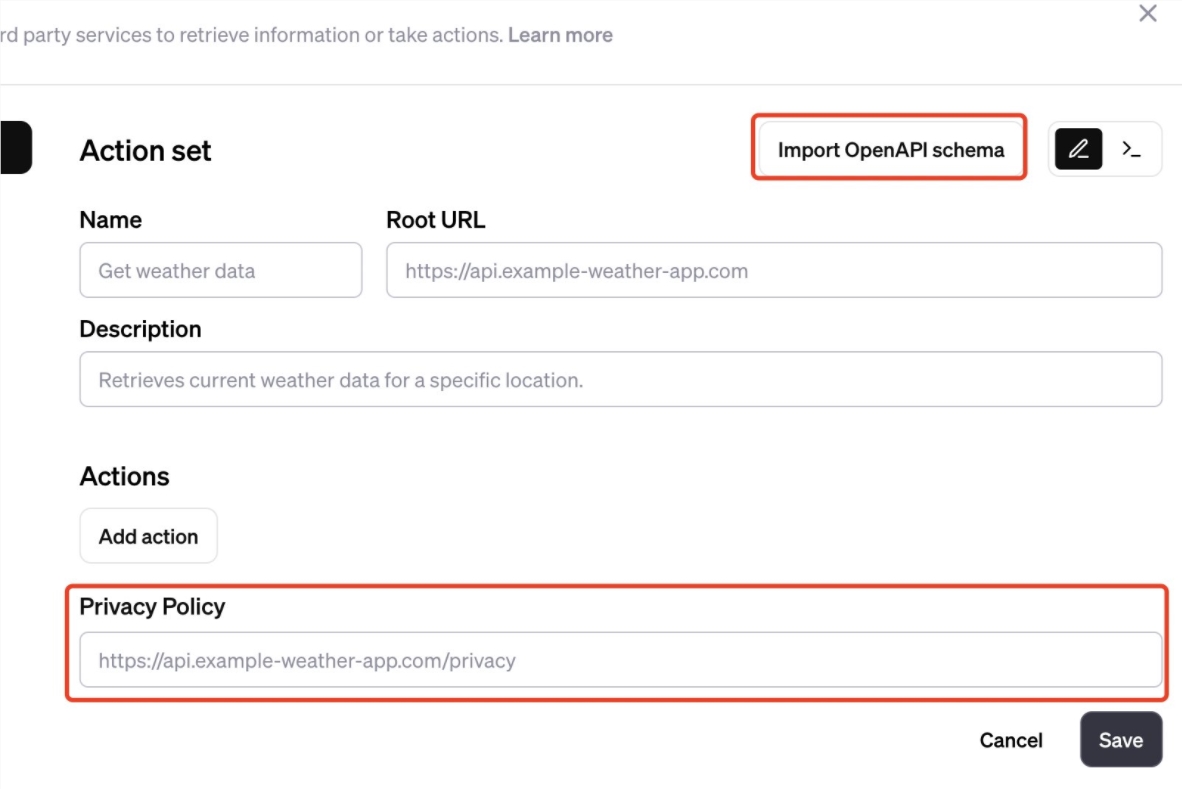
GPTS应用怎么创建?GPTS无法创建应用很卡怎么办
在首届开发者大会上,OpenAI宣布推出了GPTs功能,也就是GPT Store,类似App Store的应用商店,任何用户都可以去参与创建应用。那么GPTS应用该如何创建?碰到应用无法创建很卡怎么办呢?下面就为大家带来GPTS应用创建图文教程…...

目标检测YOLO实战应用案例100讲-基于无人机的运动目标检测
目录 前言 国内外研究现状 2运动目标检测相关理论基础 2.1 运动目标检测算法...

东莞松山湖数据中心|莞服务器托管的优势
东莞位于珠江三角洲经济圈,交通便利,与广州、深圳等大城市相邻,而且东莞是中国重要的制造业基地,有众多的制造业和科技企业集聚于此,随着互联网和数字化时代的到来,企业都向数字化转型,对于信息…...

时间序列预测实战(十五)PyTorch实现GRU模型长期预测并可视化结果
往期回顾:时间序列预测专栏——包含上百种时间序列模型带你从入门到精通时间序列预测 一、本文介绍 本文讲解的实战内容是GRU(门控循环单元),本文的实战内容通过时间序列领域最经典的数据集——电力负荷数据集为例,深入的了解GRU的基本原理和…...

探索STM32系列微控制器的特性和性能
STM32系列微控制器是意法半导体(STMicroelectronics)公司开发的一款强大的嵌入式微控制器系列。该系列微控制器以其丰富的特性和卓越的性能,成为了嵌入式系统开发领域的首选。本文将深入探索STM32系列微控制器的特性和性能,并结合…...
数据结构(超详细讲解!!)第二十三节 树型结构
1.定义 树型结构是一类重要的非线性数据结构,是以分支关系定义的层次结构。是一种一对多的逻辑关系。 树型结构是结点之间有分支,并且具有层次关系的结构,它非常类似于自然界中的树。树结构在客观世界中是大量存在的,例如家谱、…...

IPFS去中心化存储实战指南:黑马程序员音乐播放器项目开发完整教程
IPFS去中心化存储实战指南:黑马程序员音乐播放器项目开发完整教程 【免费下载链接】BlockChain 黑马程序员 120天全栈区块链开发 开源教程 项目地址: https://gitcode.com/gh_mirrors/blockchain95/BlockChain 你是否想过如何构建一个真正去中心化的音乐播放…...

隧道裂缝剥落病害AI识别系统
我国现有公路隧道超2.5万座,总里程超2.8万公里,其中运营超过15年的老旧隧道占比达35%。据交通运输部2025年统计,年均因隧道结构病害导致的交通中断超1200次,直接经济损失超45亿元。传统检测模式暴露四大核心痛点:检测周…...

Obsidian PDF++:如何在Obsidian中实现PDF与笔记的无缝双向链接?
Obsidian PDF:如何在Obsidian中实现PDF与笔记的无缝双向链接? 【免费下载链接】obsidian-pdf-plus PDF: the most Obsidian-native PDF annotation & viewing tool ever. Comes with optional Vim keybindings. 项目地址: https://gitcode.com/gh_…...

Visual Paradigm 17.0 团队协作新功能实测:手把手教你用项目模板和文件夹管理提效
Visual Paradigm 17.0 团队协作实战指南:从模板配置到文件夹管理的高效工作流在敏捷开发团队中,项目启动速度和资产管理的规范性往往直接影响整体效率。Visual Paradigm 17.0针对这一痛点推出的团队协作增强功能,特别是服务器端项目模板和文件…...
)
Postgresql基础实践教程(八)
⭐️⭐️⭐️⭐️⭐️ 完整数据详见 练习数据免费 ⭐️⭐️⭐️⭐️⭐️ 六十九、查找会员ID 27的向上推荐链 问题 查找会员ID 27的向上推荐链:即推荐该会员的人,以及推荐那个人的人,依此类推。返回会员ID、名字和姓氏。按会员ID降序排列。…...

如何快速解锁艾尔登法环帧率限制:终极性能优化指南
如何快速解锁艾尔登法环帧率限制:终极性能优化指南 【免费下载链接】EldenRingFpsUnlockAndMore A small utility to remove frame rate limit, change FOV, add widescreen support and more for Elden Ring 项目地址: https://gitcode.com/gh_mirrors/el/EldenR…...

Taotoken的审计日志功能为企业API安全与合规管理提供支持
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken的审计日志功能为企业API安全与合规管理提供支持 当企业决定将大模型能力集成到内部业务流程中时,IT管理员和安…...

深度解析:JetBrains IDE试用期重置机制的技术实现
深度解析:JetBrains IDE试用期重置机制的技术实现 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter 在软件开发工作流中,JetBrains IDE试用期管理是一个常见的技术挑战,尤其是在多…...

基于Shapley值与随机森林的印度CPI通胀预测与特征重要性分析
1. 项目概述与核心价值在宏观经济预测领域,通胀预测的准确性直接关系到货币政策制定、市场预期管理乃至社会民生稳定。传统的计量经济学模型,如基于菲利普斯曲线的线性回归,虽然具有良好的可解释性,但在捕捉现实世界中复杂、非线性…...

MySQL全局ID生成实战:从自增主键到自定义Sequence的平滑升级方案与避坑指南
MySQL全局ID生成实战:从自增主键到自定义Sequence的平滑升级方案与避坑指南 当电商平台的日订单量突破百万时,技术团队突然发现系统开始频繁出现"Duplicate entry"错误——那些原本可靠的自增主键,在分库分表的环境下变成了数据一致…...