无监督学习的集成方法:相似性矩阵的聚类
在机器学习中,术语Ensemble指的是并行组合多个模型,这个想法是利用群体的智慧,在给出的最终答案上形成更好的共识。
这种类型的方法已经在监督学习领域得到了广泛的研究和应用,特别是在分类问题上,像RandomForest这样非常成功的算法。通常应用一些投票/加权系统,将每个单独模型的输出组合成最终的、更健壮的和一致的输出。
在无监督学习领域,这项任务变得更加困难。首先,因为它包含了该领域本身的挑战,我们对数据没有先验知识,无法将自己与任何目标进行比较。其次,因为找到一种合适的方法来结合所有模型的信息仍然是一个问题,而且对于如何做到这一点还没有达成共识。
在本文中,我们讨论关于这个主题的最佳方法,即相似性矩阵的聚类。
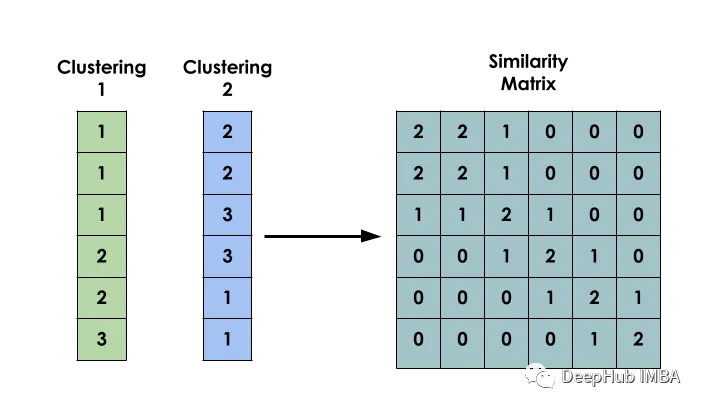
该方法的主要思想是:给定一个数据集X,创建一个矩阵S,使得Si表示xi和xj之间的相似性。该矩阵是基于几个不同模型的聚类结果构建的。
二元共现矩阵
构建模型的第一步是创建输入之间的二元共现矩阵。

它用于指示两个输入i和j是否属于同一个簇。
import numpy as npfrom scipy import sparsedef build_binary_matrix( clabels ):data_len = len(clabels)matrix=np.zeros((data_len,data_len))for i in range(data_len):matrix[i,:] = clabels == clabels[i]return matrixlabels = np.array( [1,1,1,2,3,3,2,4] )build_binary_matrix(labels)
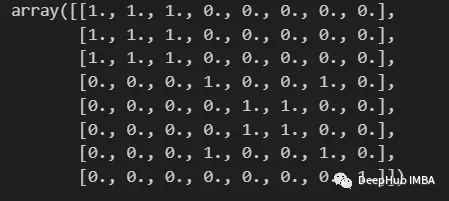
用KMeans构造相似矩阵
我们已经构造了一个函数来二值化我们的聚类,下面可以进入构造相似矩阵的阶段。
我们这里介绍一个最常见的方法,只包括计算M个不同模型生成的M个共现矩阵之间的平均值。定义为:

这样,落在同一簇中的条目的相似度值将接近于1,而落在不同组中的条目的相似度值将接近于0。
我们将基于K-Means模型创建的标签构建一个相似矩阵。使用MNIST数据集进行。为了简单和高效,我们将只使用10000张经过PCA降维的图像。
from sklearn.datasets import fetch_openmlfrom sklearn.decomposition import PCAfrom sklearn.cluster import MiniBatchKMeans, KMeansfrom sklearn.model_selection import train_test_splitmnist = fetch_openml('mnist_784')X = mnist.datay = mnist.targetX, _, y, _ = train_test_split(X,y, train_size=10000, stratify=y, random_state=42 )pca = PCA(n_components=0.99)X_pca = pca.fit_transform(X)
为了使模型之间存在多样性,每个模型都使用随机数量的簇实例化。
NUM_MODELS = 500MIN_N_CLUSTERS = 2MAX_N_CLUSTERS = 300np.random.seed(214)model_sizes = np.random.randint(MIN_N_CLUSTERS, MAX_N_CLUSTERS+1, size=NUM_MODELS)clt_models = [KMeans(n_clusters=i, n_init=4, random_state=214) for i in model_sizes]for i, model in enumerate(clt_models):print( f"Fitting - {i+1}/{NUM_MODELS}" )model.fit(X_pca)
下面的函数就是创建相似矩阵
def build_similarity_matrix( models_labels ):n_runs, n_data = models_labels.shape[0], models_labels.shape[1]sim_matrix = np.zeros( (n_data, n_data) )for i in range(n_runs):sim_matrix += build_binary_matrix( models_labels[i,:] )sim_matrix = sim_matrix/n_runsreturn sim_matrix
调用这个函数:
models_labels = np.array([ model.labels_ for model in clt_models ])sim_matrix = build_similarity_matrix(models_labels)
最终结果如下:
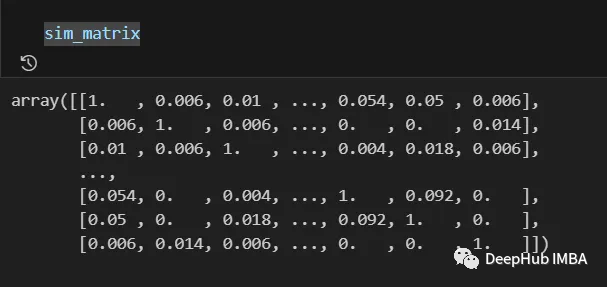
来自相似矩阵的信息在最后一步之前仍然可以进行后处理,例如应用对数、多项式等变换。
在我们的情况下,我们将不做任何更改。
Pos_sim_matrix = sim_matrix
对相似矩阵进行聚类
相似矩阵是一种表示所有聚类模型协作所建立的知识的方法。
通过它,我们可以直观地看到哪些条目更有可能属于同一个簇,哪些不属于。但是这些信息仍然需要转化为实际的簇。
这是通过使用可以接收相似矩阵作为参数的聚类算法来完成的。这里我们使用SpectralClustering。
from sklearn.cluster import SpectralClusteringspec_clt = SpectralClustering(n_clusters=10, affinity='precomputed',n_init=5, random_state=214)final_labels = spec_clt.fit_predict(pos_sim_matrix)
与标准KMeans模型的比较
我们来与KMeans进行性对比,这样可以确认我们的方法是否有效。
我们将使用NMI, ARI,集群纯度和类纯度指标来评估标准KMeans模型与我们集成模型进行对比。此外我们还将绘制权变矩阵,以可视化哪些类属于每个簇。
from seaborn import heatmapimport matplotlib.pyplot as pltdef data_contingency_matrix(true_labels, pred_labels):fig, (ax) = plt.subplots(1, 1, figsize=(8,8))n_clusters = len(np.unique(pred_labels))n_classes = len(np.unique(true_labels))label_names = np.unique(true_labels)label_names.sort()contingency_matrix = np.zeros( (n_classes, n_clusters) )for i, true_label in enumerate(label_names):for j in range(n_clusters):contingency_matrix[i, j] = np.sum(np.logical_and(pred_labels==j, true_labels==true_label))heatmap(contingency_matrix.astype(int), ax=ax,annot=True, annot_kws={"fontsize":14}, fmt='d')ax.set_xlabel("Clusters", fontsize=18)ax.set_xticks( [i+0.5 for i in range(n_clusters)] )ax.set_xticklabels([i for i in range(n_clusters)], fontsize=14)ax.set_ylabel("Original classes", fontsize=18)ax.set_yticks( [i+0.5 for i in range(n_classes)] )ax.set_yticklabels(label_names, fontsize=14, va="center")ax.set_title("Contingency Matrix\n", ha='center', fontsize=20)

from sklearn.metrics import normalized_mutual_info_score, adjusted_rand_scoredef purity( true_labels, pred_labels ):n_clusters = len(np.unique(pred_labels))n_classes = len(np.unique(true_labels))label_names = np.unique(true_labels)purity_vector = np.zeros( (n_classes) )contingency_matrix = np.zeros( (n_classes, n_clusters) )for i, true_label in enumerate(label_names):for j in range(n_clusters):contingency_matrix[i, j] = np.sum(np.logical_and(pred_labels==j, true_labels==true_label))purity_vector = np.max(contingency_matrix, axis=1)/np.sum(contingency_matrix, axis=1)print( f"Mean Class Purity - {np.mean(purity_vector):.2f}" ) for i, true_label in enumerate(label_names):print( f" {true_label} - {purity_vector[i]:.2f}" ) cluster_purity_vector = np.zeros( (n_clusters) )cluster_purity_vector = np.max(contingency_matrix, axis=0)/np.sum(contingency_matrix, axis=0)print( f"Mean Cluster Purity - {np.mean(cluster_purity_vector):.2f}" ) for i in range(n_clusters):print( f" {i} - {cluster_purity_vector[i]:.2f}" ) kmeans_model = KMeans(10, n_init=50, random_state=214)km_labels = kmeans_model.fit_predict(X_pca)data_contingency_matrix(y, km_labels)print( "Single KMeans NMI - ", normalized_mutual_info_score(y, km_labels) )print( "Single KMeans ARI - ", adjusted_rand_score(y, km_labels) )purity(y, km_labels)

data_contingency_matrix(y, final_labels)print( "Ensamble NMI - ", normalized_mutual_info_score(y, final_labels) )print( "Ensamble ARI - ", adjusted_rand_score(y, final_labels) )purity(y, final_labels)

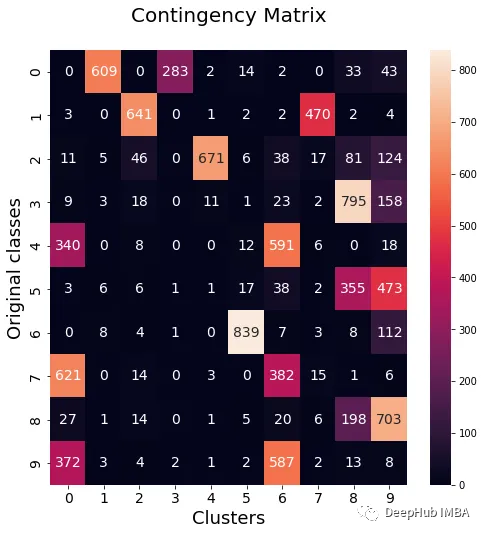
从上面的值可以看出,Ensemble方法确实能够提高聚类的质量。我们还可以在权变矩阵中看到更一致的行为,具有更好的分布类和更少的“噪声”。
本文引用
Strehl, Alexander, and Joydeep Ghosh. “Cluster ensembles — -a knowledge reuse framework for combining multiple partitions.” Journal of machine learning research 3.Dec (2002): 583–617.
Fred, Ana, and Anil K. Jain. “Combining multiple clusterings using evidence accumulation.” IEEE transactions on pattern analysis and machine intelligence 27.6 (2005): 835–850.
Topchy, Alexander, et al. “Combining multiple weak clusterings.” Third IEEE International Conference on Data Mining. IEEE, 2003.
Fern, Xiaoli Zhang, and Carla E. Brodley. “Solving cluster ensemble problems by bipartite graph partitioning.” Proceedings of the twenty-first international conference on Machine learning. 2004.
Gionis, Aristides, Heikki Mannila, and Panayiotis Tsaparas. “Clustering aggregation.” ACM Transactions on Knowledge Discovery from Data (TKDD) 1.1 (2007): 1–30.
https://avoid.overfit.cn/post/526bea5f183249008f77ccc479e2f555
作者:Nielsen Castelo Damasceno Dantas
相关文章:
无监督学习的集成方法:相似性矩阵的聚类
在机器学习中,术语Ensemble指的是并行组合多个模型,这个想法是利用群体的智慧,在给出的最终答案上形成更好的共识。 这种类型的方法已经在监督学习领域得到了广泛的研究和应用,特别是在分类问题上,像RandomForest这样…...

16. 机器学习——决策树
机器学习面试题汇总与解析——决策树 本章讲解知识点 什么是决策树决策树原理决策树优缺点决策树的剪枝决策树的改进型本专栏适合于Python已经入门的学生或人士,有一定的编程基础。 本专栏适合于算法工程师、机器学习、图像处理求职的学生或人士。 本专栏针对面试题答案进行了…...

DevOps系列---【jenkinsfile使用sshpass发送到另一台服务器】
1.首先在宿主机安装sshpass 2.把物理机的sshpass复制到容器中 which sshpass cp $(which sshpass) /usr/local/app/ docker cp sshpass 容器id:/usr/local/bin/sshpass 3.在jenkinsfile中添加 #在stages中添加stage stage(部署TEST服务){steps{sh "sshpass -p root1234 sc…...

Docker 和 Kubernetes:技术相同和不同之处
Docker和Kubernetes是当今最流行的容器化技术解决方案。本文将探讨Docker和Kubernetes的技术相似之处和不同之处,以帮助读者更好地理解这两种技术。 Docker和Kubernetes:当今最流行的容器化技术解决方案 在当今的IT领域,Docker和Kubernetes无…...

通信世界扫盲基础二(原理部分)
上次我们刚学习了关于通信4/G的组成和一些通识,今天我们来更深层次了解一些原理以及一些新的基础~ 目录 专业名词 LTE(4G系统) EPC s1 E-UTRAN UE UU X2 eNodeB NR(5G系统) NGC/5GC NG NG-RAN Xn gNodeB N26接口 手机的两种状态 空闲态 连接态 …...

手机厂商参与“百模大战”,vivo发布蓝心大模型
在2023 vivo开发者大会上,vivo发布自研通用大模型矩阵——蓝心大模型,其中包含十亿、百亿、千亿三个参数量级的5款自研大模型,其中,10亿量级模型是主要面向端侧场景打造的专业文本大模型,具备本地化的文本总结、摘要等…...

【微软技术栈】C#.NET 中的泛型
本文内容 定义和使用泛型泛型的利与弊类库和语言支持嵌套类型和泛型 借助泛型,你可以根据要处理的精确数据类型定制方法、类、结构或接口。 例如,不使用允许键和值为任意类型的 Hashtable 类,而使用 Dictionary<TKey,TValue> 泛型类并…...
【毕业论文】基于微信小程序的植物分类实践教学系统的设计与实现
基于微信小程序的植物分类实践教学系统的设计与实现https://download.csdn.net/download/No_Name_Cao_Ni_Mei/88519758 基于微信小程序的植物分类实践教学系统的设计与实现 Design and Implementation of Plant Classification Practical Teaching System based on WeChat Mini…...

[量化投资-学习笔记011]Python+TDengine从零开始搭建量化分析平台-MACD金死叉策略回测
在上一章节 MACD金死叉中结束了如何根据 MACD 金死叉计算交易信号。 目录 脚本说明文档(DevChat 生成)MACD 分析脚本安装依赖库参数配置查询与解析数据计算 MACD 指标判断金叉和死叉计算收益绘制图形运行脚本 本次将根据交易信号,模拟交易。更…...
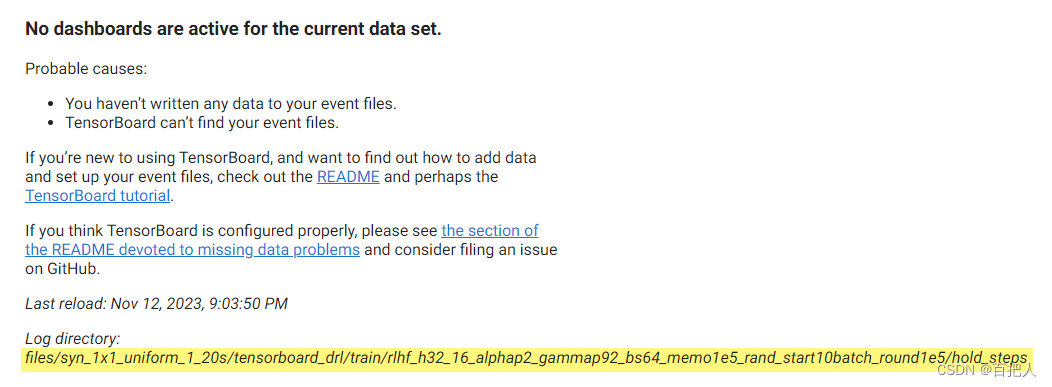
tensorboard报错解决:No dashboards are active for the current data set
版本:tensorboard 2.10.0 问题:文件夹下明明有events文件,但用tensorboard命令却无法显示。 例如: 原因:有可能是文件路径太长了,导致系统无法读取文件。在win系统中规定,目录的绝对路径不得超…...

线性代数本质系列(一)向量,线性组合,线性相关,矩阵
本系列文章将从下面不同角度解析线性代数的本质,本文是本系列第一篇 向量究竟是什么? 向量的线性组合,基与线性相关 矩阵与线性相关 矩阵乘法与线性变换 三维空间中的线性变换 行列式 逆矩阵,列空间,秩与零空间 克莱姆…...

python语法之注释
注释可用于解释Python代码。 注释可用于使代码更易读。 注释可用于在测试代码时阻止执行。 (1)创建注释 注释以#开头,Python会忽略它们: #This is a comment print("Hello, World!") 注释可以放在一行…...

React【异步逻辑createAsyncThunk(一)、createAsyncThunk(二)、性能优化、createSelector】(十二)
文章目录 异步逻辑 createAsyncThunk(一) createAsyncThunk(二) 性能优化 createSelector 异步逻辑 //Product.js const onAdd () > {const name nameRef.current.value// 触发添加商品的事件dispatch(addProduct({name…...
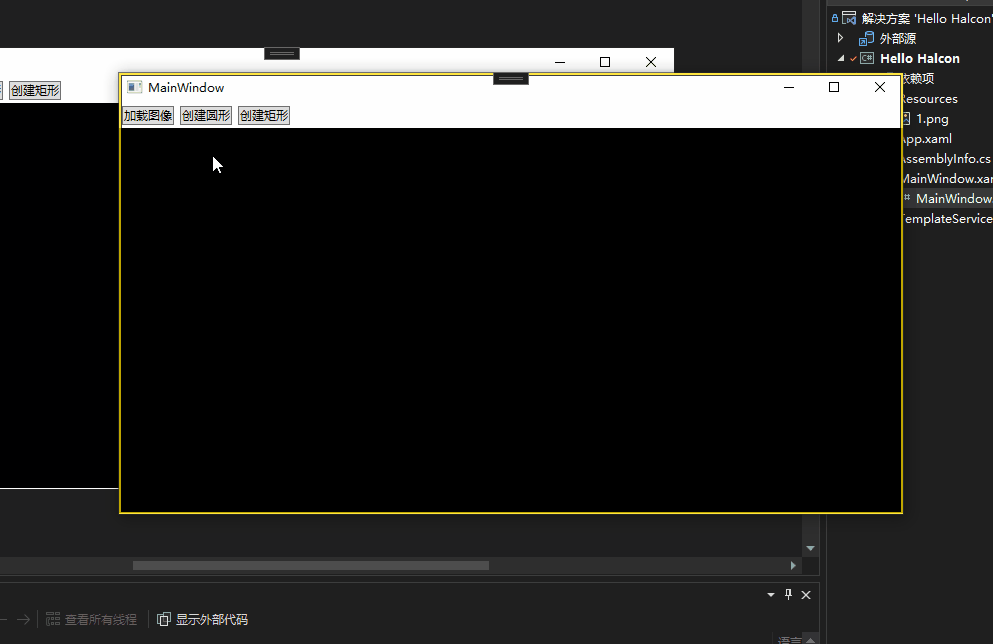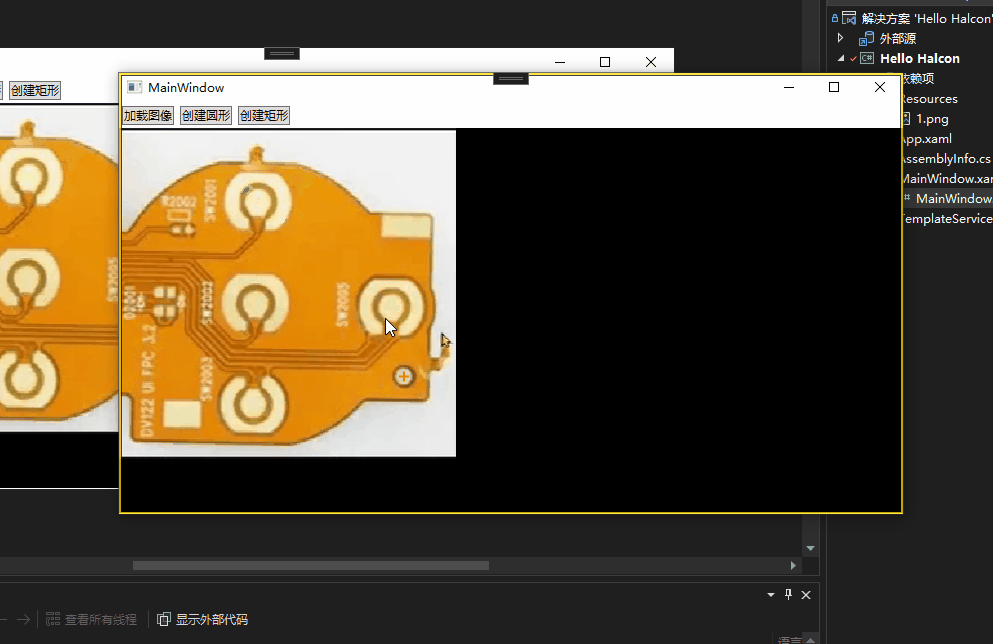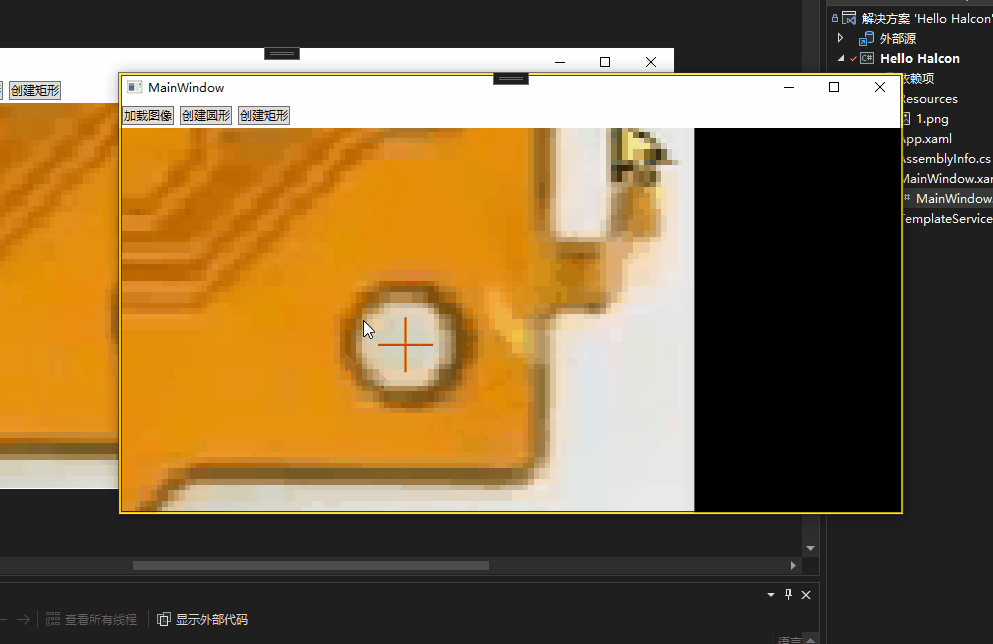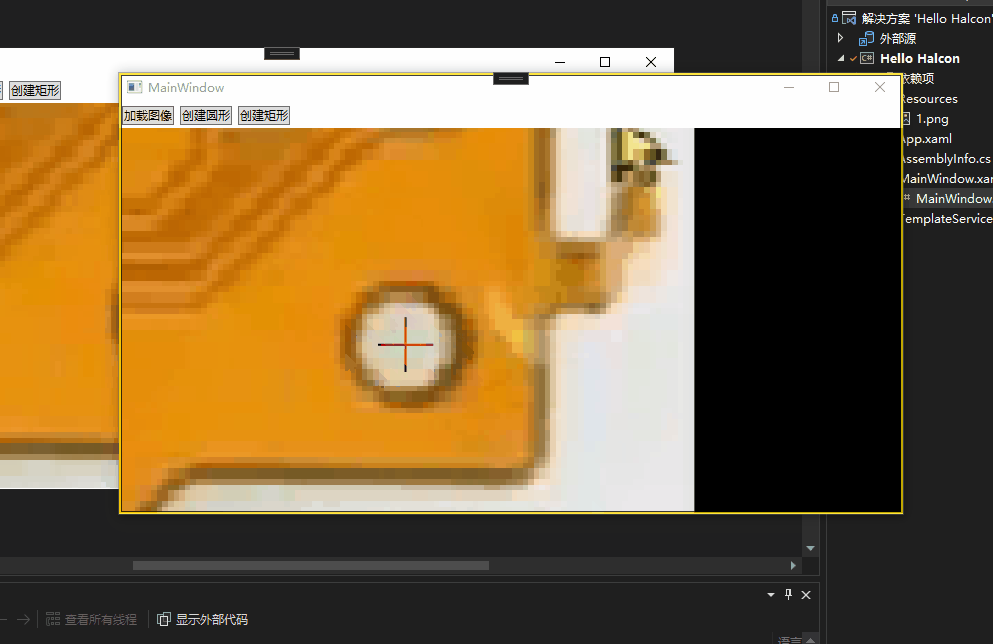
Halcon WPF 开发学习笔记(3):WPF+Halcon初步开发
文章目录 前言在MainWindow.xaml里面导入Halcon命名空间WPF简单调用Halcon创建矩形简单调用导出脚本函数 正确显示匹配效果 前言 本章会简单讲解如何调用Halcon组件和接口,因为我们是进行混合开发模式。即核心脚本在平台调试,辅助脚本C#直接调用。 在M…...

P6入门:项目初始化9-项目详情之资源 Resource
前言 使用项目详细信息查看和编辑有关所选项目的详细信息,在项目创建完成后,初始化项目是一项非常重要的工作,涉及需要设置的内容包括项目名,ID,责任人,日历,预算,资金,分类码等等&…...

Python高级语法----使用Python进行模式匹配与元组解包
文章目录 1. 模式匹配的新特性2. 高级元组解包技巧3. 数据类的匹配与应用1. 模式匹配的新特性 Python自3.10版本起引入了结构化模式匹配的新特性,这是一种强大的工具,允许开发者用更清晰、更直观的方式处理数据结构。模式匹配类似于其他编程语言中的switch-case语句,但它更…...
)
MySQL安装配置与使用教程(2023.11.13 MySQL8.0.35)
CONTENTS 1. MySQL的安装与配置2. MySQL常用操作教程 1. MySQL的安装与配置 MySQL Windows Installer 下载地址:MySQL Installer。 我们下载最新版本(目前是8.0.35)的安装包,注意要选择更大的那个,名字为 mysql-inst…...

【阿里云数据采集】采集标准Docker容器日志:部署阿里云Logtail容器以及创建Logtail配置,用于采集标准Docker容器日志
文章目录 引言I 预备知识1.1 Logtail1.2 安装Logtail1.3 创建用户自定义标识机器组1.4 设置logtail容器组件重启策略II 采集服务器日志2.1 采集同一账号下同地域服务器的日志2.2 不同账号下同地域服务器的日志2.3 创建Logtail配置III 查询语法3.1 具体查询语法3.2 查询示例3.3 …...
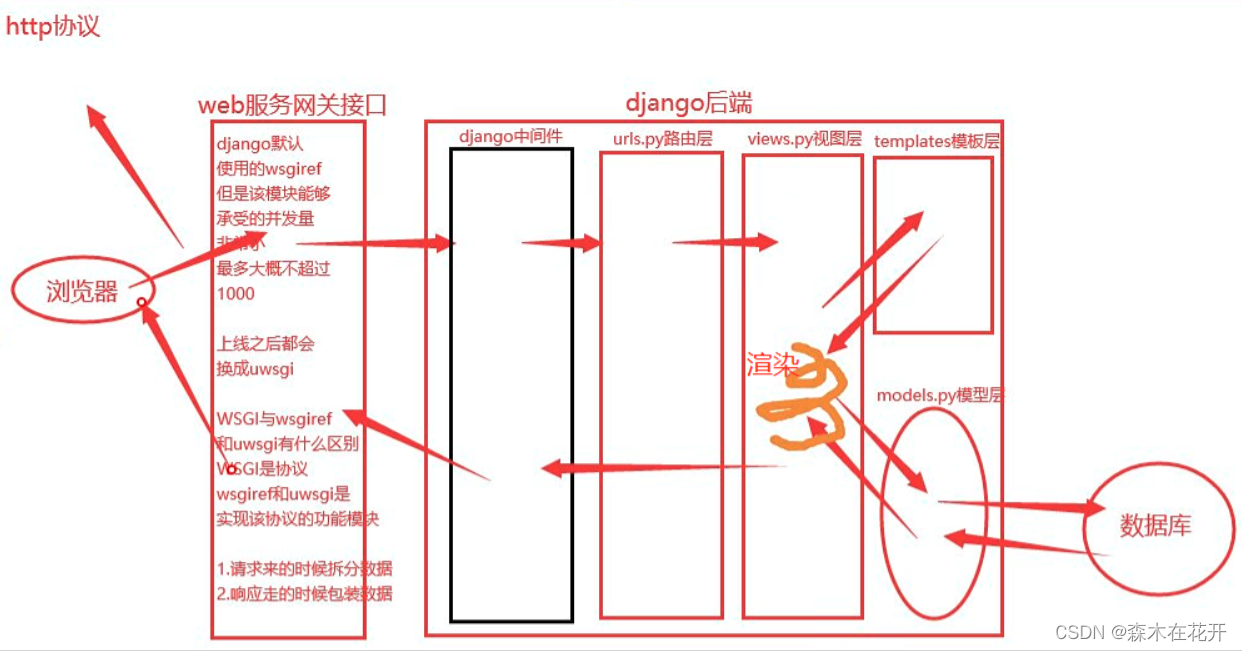
Django中如何创建表关系,请求生命周期流程图
Django中ORM创建表关系 如何创建表关系(一对一 , 一对多 , 多对多) 图书表,出版社表,作者表,作者详情表 换位思考法判断表关系 图书表和出版社表 >>> 一对多 >>> 图书表是多,出…...

MongoDB副本集配置和创建
副本集有三类角色:master(primary),slave(secondary),仲裁服务器。 primary是主,只有primary能写入,secondary无法插入数据,且需要声明是slave才能查看数据 一般生产搞三个服务器做一个master和两个slave&a…...

DeepSeek代码质量评估实战手册:7步完成从混沌到可度量的质变跃迁
更多请点击: https://kaifayun.com 第一章:DeepSeek代码质量评估的底层逻辑与核心价值 DeepSeek代码质量评估并非简单地统计行数或检测语法错误,而是基于多维语义理解构建的推理系统。其底层逻辑融合了静态分析、符号执行与大语言模型生成式…...

作业本耐用度差距巨大?深圳大明印刷厂拆解合规工艺,告别定制作业本掉页开裂通病
在校园日常教学中,很多学校都会遇到同一个难题:同一学期采购的作业本、定制作业本,品质差距悬殊,有的完好无损用到期末,有的短短几周就出现书脊开裂、页面脱落、边角破损、翻页卡顿等问题。不少人误以为是学生使用习惯…...

51单片机驱动ST7735S彩屏避坑指南:从5秒刷屏到流畅贪吃蛇的优化实战
51单片机驱动ST7735S彩屏性能优化实战:从卡顿到流畅游戏的蜕变之路当一块128x160分辨率的ST7735S彩屏遇上传统的51单片机,这种组合看似矛盾却又充满挑战。许多开发者初次尝试时会发现,原本在STM32等平台上运行流畅的显示驱动,移植…...

BLE四大广播模式详解:可连接/不可连接/定向/周期广播
一、前言在低功耗蓝牙(BLE)开发中,广播(Advertising)是设备发现、连接建立、数据广播、设备重连的核心基石,所有BLE交互流程均始于广播报文的收发。不同于传统经典蓝牙,BLE所有广播行为标准化、…...

基于Arduino的模块化DIY智能时钟:从RTC到RGB LED的完整实现
1. 项目概述:打造一台高度可定制的DIY RGB LED时钟如果你和我一样,对市面上千篇一律的电子钟感到审美疲劳,同时又对Arduino和电子DIY充满热情,那么这个项目可能就是为你准备的。我们不是在简单地组装一个套件,而是在亲…...

GitLab External Wiki代理权限绕过漏洞深度解析
1. 这个漏洞不是“修个补丁”就能完事的——它暴露的是 GitLab 权限模型里一个被长期忽视的逻辑断层GitLab 安全漏洞 CVE-2025-2614,光看编号容易误以为是又一个常规的越权或 XSS 类型漏洞。但我在实际复现和审计过程中发现,它根本不是配置疏漏或代码拼写…...

基于MaixCam的延时摄影系统:从硬件选型到Python编程全解析
1. 项目概述:用MaixCam打造你的专属延时摄影工坊延时摄影,这个听起来有点专业、甚至带点“魔法”色彩的词,其实离我们并不遥远。想想看,把一朵花从含苞到绽放的几天时间,压缩成十几秒的惊艳绽放;或者把一座…...

武汉国电华美串联谐振试验装置,现场用着心里有底
在高压试验现场干了这么多年,这位老师傅常说,一台好的串联谐振装置,就是试验人员的胆。面对GIS、大型变压器、超高压电缆这些大电容试品,没有趁手的谐振设备,交流耐压试验根本没法干。16875kVA/225kV这个规格ÿ…...

基于GSM与Arduino的远程控制系统:DIY电话控制与短信报警方案
1. 项目概述与核心价值如果你曾经想过,在离家几十公里外,仅凭一部普通的手机,就能远程打开家里的车库门、查看门窗是否关好,甚至在异常情况发生时让系统自动打电话给你报警,那么这个基于GSM的远程控制系统项目…...

抖音内容批量下载实战:从零开始构建个人视频资料库
抖音内容批量下载实战:从零开始构建个人视频资料库 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support.…...