【中间件篇-Redis缓存数据库06】Redis主从复制/哨兵 高并发高可用
Redis高并发高可用
复制
在分布式系统中为了解决单点问题,通常会把数据复制多个副本部署到其他机器,满足故障恢复和负载均衡等需求。Redis也是如此,它为我们提供了复制功能,实现了相同数据的多个Redis 副本。复制功能是高可用Redis的基础,后面章节的哨兵和集群都是在复制的基础上实现高可用的。
默认情况下,Redis都是主节点。每个从节点只能有一个主节点,而主节点可以同时具有多个从节点。复制的数据流是单向的,只能由主节点复制到从节点。
复制的拓扑结构
Redis 的复制拓扑结构可以支持单层或多层复制关系,根据拓扑复杂性可以分为以下三种:一主一从、一主多从、树状主从结构,下面分别介绍。
一主一从结构
一主一从结构是最简单的复制拓扑结构,用于主节点出现宕机时从节点提供故障转移支持。
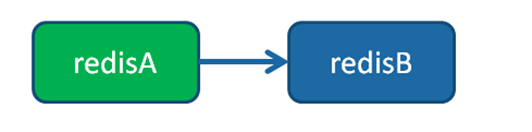
当应用写命令并发量较高且需要持久化时,可以只在从节点上开启AOF ,这样既保证数据安全性同时也避免了持久化对主节点的性能干扰。但需要注意的是,当主节点关闭持久化功能时,如果主节点脱机要避免自动重启操作。
因为主节点之前没有开启持久化功能自动重启后数据集为空,这时从节点如果继续复制主节点会导致从节点数据也被清空的情况,丧失了持久化的意义。安全的做法是在从节点上执行slaveof no one断开与主节点的复制关系,再重启主节点从而避免这一问题。
一主多从结构
一主多从结构(又称为星形拓扑结构)使得应用端可以利用多个从节点实现读写分离。
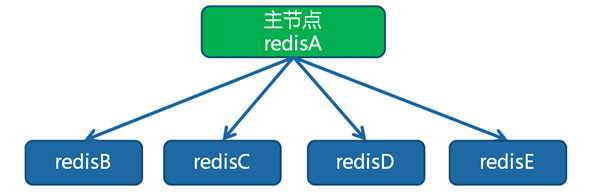
对于读占比较大的场景,可以把读命令发送到从节点来分担主节点压力。同时在日常开发中如果需要执行一些比较耗时的读命令,如:keys、sort等,可以在其中一台从节点上执行,防止慢查询对主节点造成阻塞从而影响线上服务的稳定性。对于写并发量较高的场景,多个从节点会导致主节点写命令的多次发送从而过度消耗网络带宽,同时也加重了主节点的负载影响服务稳定性。
树状主从结构
树状主从结构(又称为树状拓扑结构)使得从节点不但可以复制主节点数据,同时可以作为其他从节点的主节点继续向下层复制。通过引入复制中间层,可以有效降低主节点负载和需要传送给从节点的数据量。
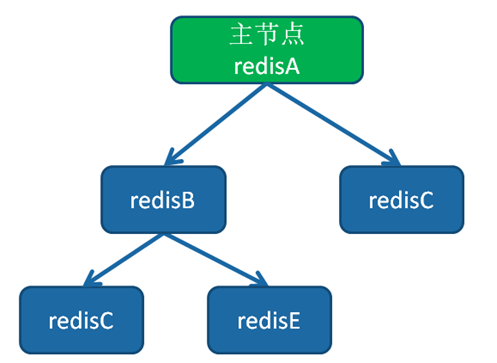
数据写入节点A后会同步到B和C节点,B节点再把数据同步到D和E节点,数据实现了一层一层的向下复制。当主节点需要挂载多个从节点时为了避免对主节点的性能干扰,可以采用树状主从结构降低主节点压力。
复制的配置
建立复制
参与复制的Redis实例划分为主节点(master)和从节点(slave)。默认情况下,Redis都是主节点。每个从节点只能有一个主节点,而主节点可以同时具有多个从节点。复制的数据流是单向的,只能由主节点复制到从节点。
配置复制的方式有以下三种
1)在配置文件中加入slaveof{masterHost } {masterPort}随 Redis启动生效。
2)在redis-server启动命令后加入–slaveof{masterHost} {masterPort }生效。
3)直接使用命令:slaveof {masterHost} { masterPort}生效。
综上所述,slaveof命令在使用时,可以运行期动态配置,也可以提前写到配置文件中。
比如:我在机器上启动2台Redis, 分别是6379 和6380 两个端口。
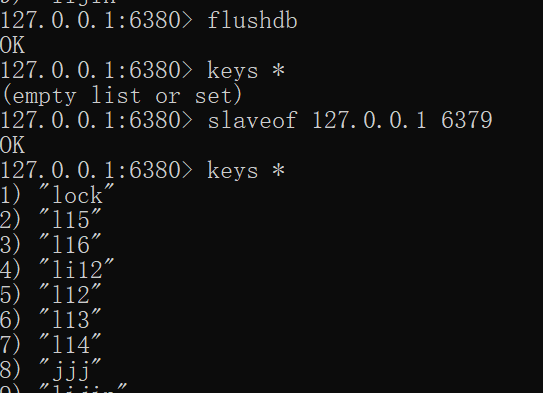
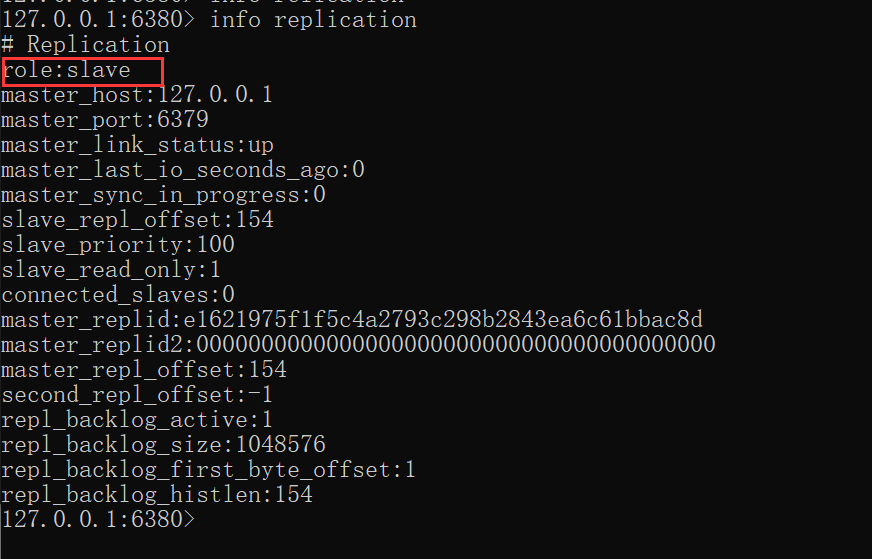
slaveof本身是异步命令,执行slaveof命令时,节点只保存主节点信息后返回,后续复制流程在节点内部异步执行,具体细节见之后。主从节点复制成功建立后,可以使用info replication命令查看复制相关状态。
断开复制
slaveof命令不但可以建立复制,还可以在从节点执行slaveof no one来断开与主节点复制关系。例如在6881节点上执行slaveof no one来断开复制。
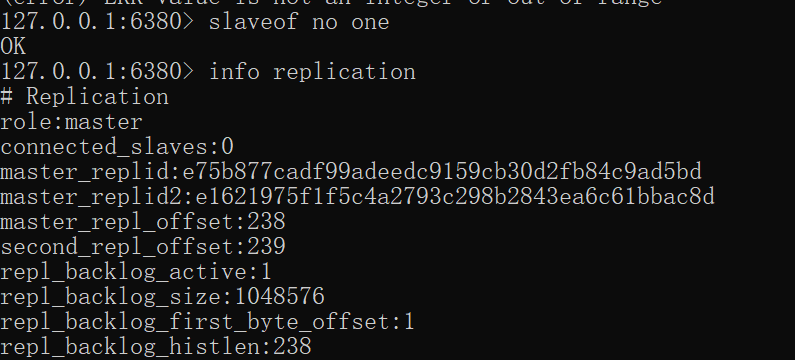
slaveof本身是异步命令,执行slaveof命令时,节点只保存主节点信息后返回,后续复制流程在节点内部异步执行,具体细节见之后。主从节点复制成功建立后,可以使用info replication命令查看复制相关状态。
断开复制主要流程:
1)断开与主节点复制关系。2)从节点晋升为主节点。
从节点断开复制后并不会抛弃原有数据,只是无法再获取主节点上的数据变化。
通过slaveof命令还可以实现切主操作,所谓切主是指把当前从节点对主节点的复制切换到另一个主节点。
执行slaveof{ newMasterIp} { newMasterPort}命令即可,例如把6881节点从原来的复制6880节点变为复制6879节点。

切主内部流程如下:
1)断开与旧主节点复制关系。
2)与新主节点建立复制关系。
3)删除从节点当前所有数据。
4)对新主节点进行复制操作。
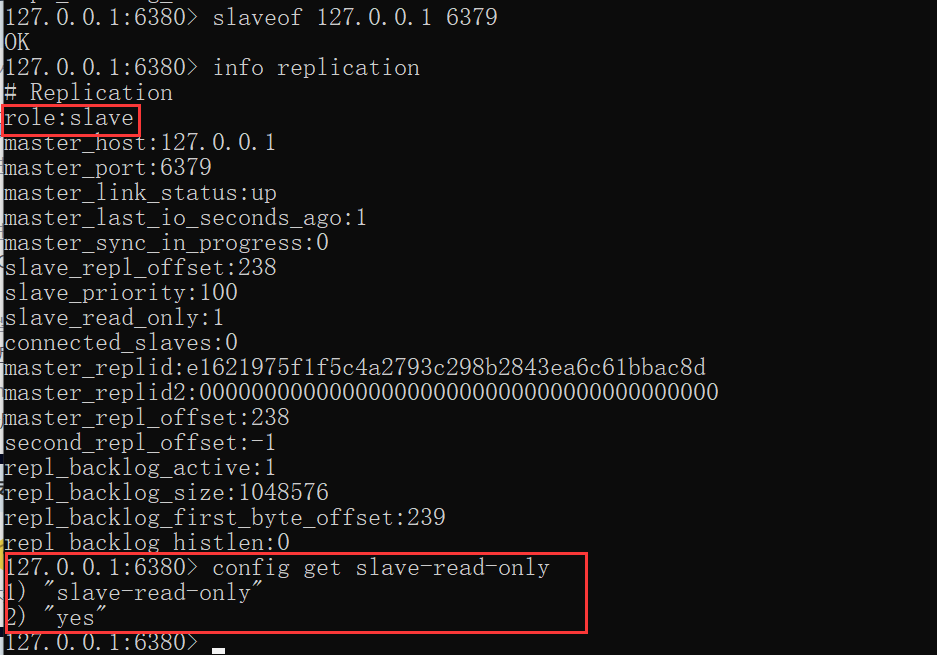
只读
默认情况下,从节点使用slave-read-only=yes配置为只读模式。由于复制只能从主节点到从节点,对于从节点的任何修改主节点都无法感知,修改从节点会造成主从数据不一致。因此建议线上不要修改从节点的只读模式。


传输延迟
主从节点一般部署在不同机器上,复制时的网络延迟就成为需要考虑的问题,Redis为我们提供了repl-disable-tcp-nodelay参数用于控制是否关闭TCP_NODELAY,默认关闭,说明如下:

当关闭时,主节点产生的命令数据无论大小都会及时地发送给从节点,这样主从之间延迟会变小,但增加了网络带宽的消耗。适用于主从之间的网络环境良好的场景,如同机架或同机房部署。
当开启时,主节点会合并较小的TCP数据包从而节省带宽。默认发送时间间隔取决于Linux的内核,一般默认为40毫秒。这种配置节省了带宽但增大主从之间的延迟。适用于主从网络环境复杂或带宽紧张的场景,如跨机房部署。
Redis主从复制原理
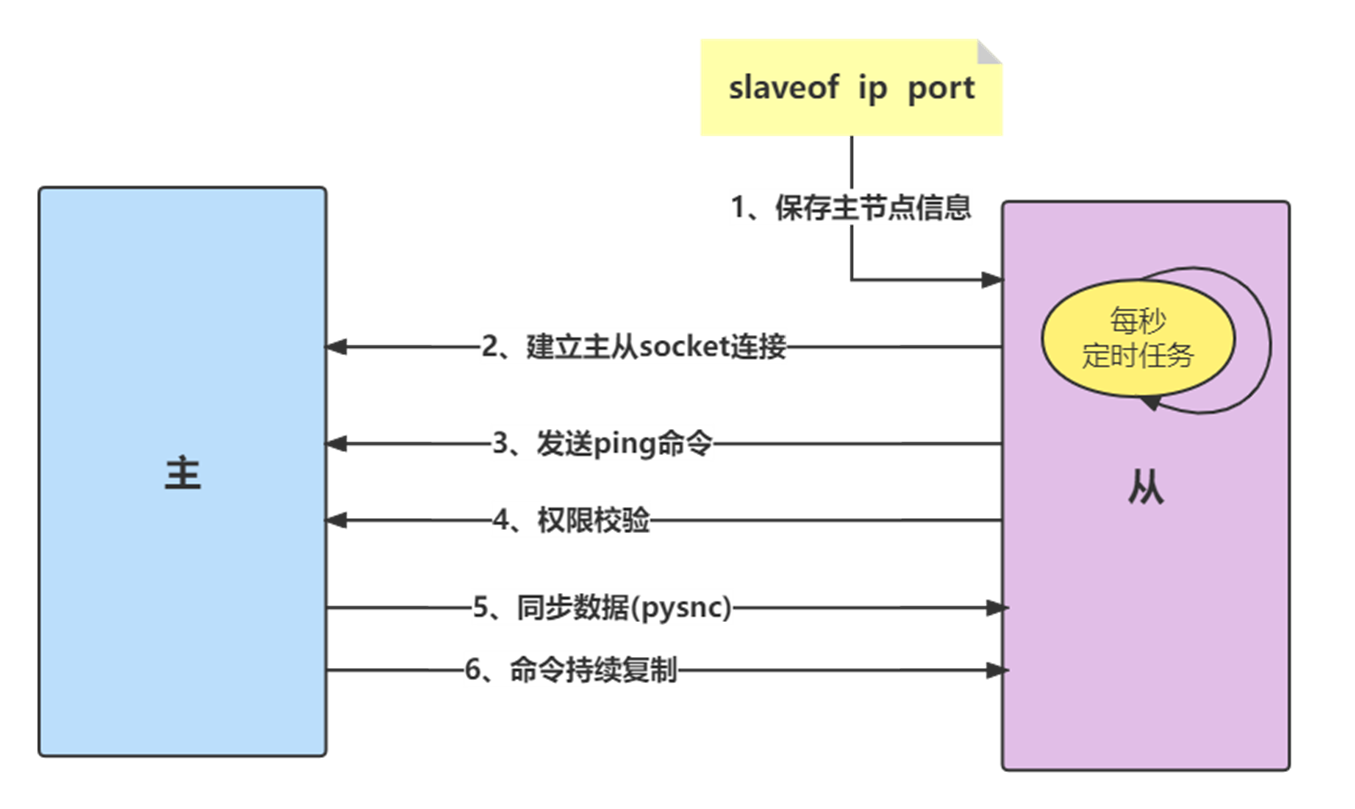
在从节点执行slaveof命令后,复制过程便开始运作。
1)保存主节点信息
执行slaveof后从节点只保存主节点的地址信息便直接返回,这时建立复制流程还没有开始。
2)建立主从socket连接
从节点(slave)内部通过每秒运行的定时任务维护复制相关逻辑,当定时任务发现存在新的主节点后,会尝试与该节点建立网络连接。
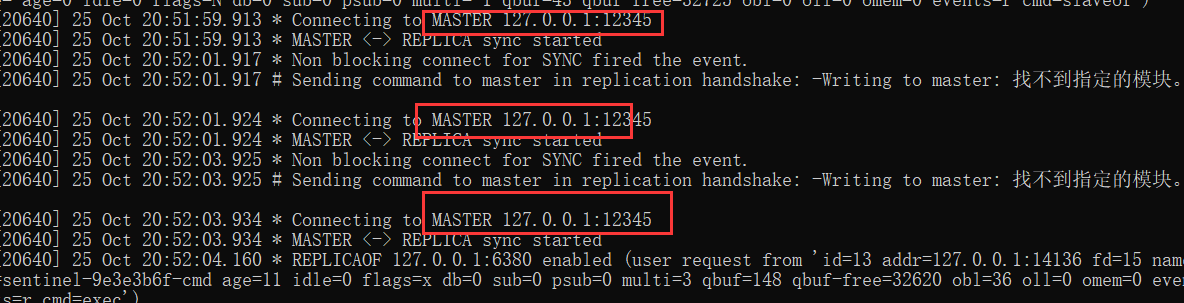
从节点会建立一个socket套接字,专门用于接受主节点发送的复制命令。从节点连接成功后打印日志。
如果从节点无法建立连接,定时任务会无限重试直到连接成功或者执行slaveof no one取消复制。
3)发送ping命令
连接建立成功后从节点发送ping请求进行首次通信,ping请求主要目的:检测主从之间网络套接字是否可用、检测主节点当前是否可接受处理命令。

从节点发送的ping命令成功返回,Redis打印日志,并继续后续复制流程:
4)权限验证
如果主节点设置了requirepass参数,则需要密码验证,从节点必须配置masterauth参数保证与主节点相同的密码才能通过验证;如果验证失败复制将终止,从节点重新发起复制流程。

5) 同步数据集
主从复制连接正常通信后,对于首次建立复制的场景,主节点会把持有的数据全部发送给从节点,这部分操作是耗时最长的步骤。Redis在2.8版本以后采用新复制命令 psync进行数据同步,原来的sync命令依然支持,保证新旧版本的兼容性。新版同步划分两种情况:全量同步和部分同步。
6) 命令持续复制
当主节点把当前的数据同步给从节点后,便完成了复制的建立流程。接下来主节点会持续地把写命令发送给从节点,保证主从数据一致性。
Redis数据同步
Redis早期支持的复制功能只有全量复制(sync命令),它会把主节点全部数据一次性发送给从节点,当数据量较大时,会对主从节点和网络造成很大的开销。
Redis在2.8版本以后采用新复制命令psync进行数据同步,原来的sync命令依然支持,保证新旧版本的兼容性。新版同步划分两种情况:全量复制和部分复制。
全量同步
全量复制:一般用于初次复制场景,Redis早期支持的复制功能只有全量复制,它会把主节点全部数据一次性发送给从节点,当数据量较大时,会对主从节点和网络造成很大的开销。
全量复制是Redis最早支持的复制方式,也是主从第一次建立复制时必须经历的阶段。触发全量复制的命令是sync和psync。
psync全量复制流程,它与2.8以前的sync全量复制机制基本一致。
流程说明
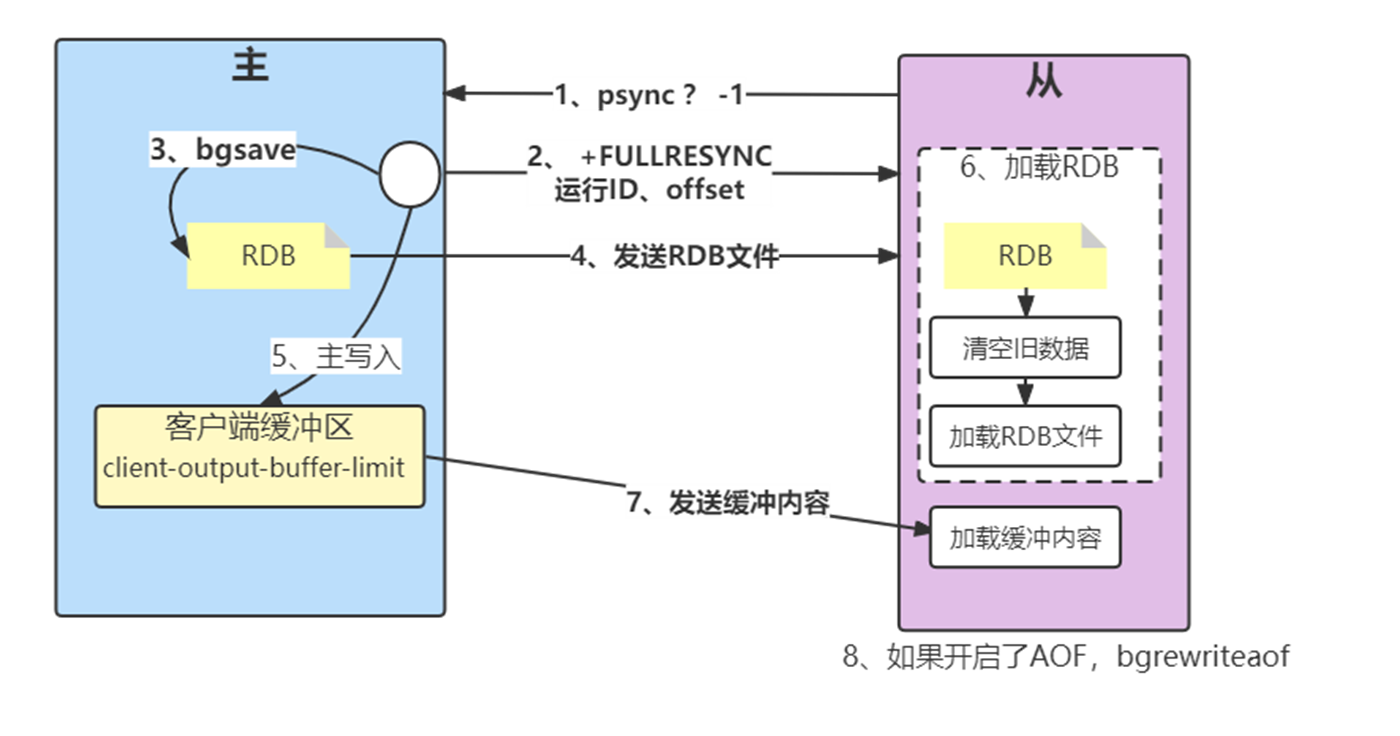
1)发送psync命令进行数据同步,由于是第一次进行复制,从节点没有复制偏移量和主节点的运行ID,所以发送psync ? -1。
2)主节点根据psync ? -1解析出当前为全量复制,回复 +FULLRESYNC响应,从节点接收主节点的响应数据保存运行ID和偏移量offset,并打印日志。
3)主节点执行bgsave保存RDB 文件到本地。
4)主节点发送RDB文件给从节点,从节点把接收的RDB文件保存在本地并直接作为从节点的数据文件,接收完RDB后从节点打印相关日志,可以在日志中查看主节点发送的数据量。

5)对于从节点开始接收RDB快照到接收完成期间,主节点仍然响应读写命令,因此主节点会把这期间写命令数据保存在复制客户端缓冲区内,当从节点加载完RDB文件后,主节点再把缓冲区内的数据发送给从节点,保证主从之间数据一致性。

需要注意,对于数据量较大的主节点,比如生成的RDB文件超过6GB 以上时要格外小心。传输文件这一步操作非常耗时,速度取决于主从节点之间网络带宽
问题
通过分析全量复制的所有流程,会发现全量复制是一个非常耗时费力的操作。它的时间开销主要包括:
1、主节点bgsave时间。
2、RDB文件网络传输时间。
3、从节点清空数据时间。
4、从节点加载RDB的时间。
5、可能的AOF重写时间。
因此当数据量达到一定规模之后,由于全量复制过程中将进行多次持久化相关操作和网络数据传输,这期间会大量消耗主从节点所在服务器的CPU、内存和网络资源。
另外最大的问题,复制还会失败!!!
例如我们线上数据量在6G左右的主节点,从节点发起全量复制的总耗时在2分钟左右。
1、如果总时间超过repl-timeout所配置的值(默认60秒),从节点将放弃接受RDB文件并清理已经下载的临时文件,导致全量复制失败。
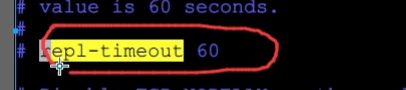
2、如果主节点创建和传输RDB的时间过长,对于高流量写入场景非常容易造成主节点复制客户端缓冲区溢出。默认配置为

意思是如果60秒内缓冲区消耗持续大于64MB或者直接超过256MB时,主节点将直接关闭复制客户端连接,造成全量同步失败。
所以除了第一次复制时采用全量复制在所难免之外,对于其他场景应该规避全量复制的发生。正因为全量复制的成本问题。
部分同步
部分复制主要是Redis针对全量复制的过高开销做出的一种优化措施。
使用psync {runId} {offset} 命令实现
当从节点(slave)正在复制主节点(master)时,如果出现网络闪断或者命令丢失等异常情况时,从节点会向主节点要求补发丢失的命令数据,如果主节点的复制积压缓冲区内存在这部分数据则直接发送给从节点,这样就可以保持主从节点复制的一致性。
流程说明
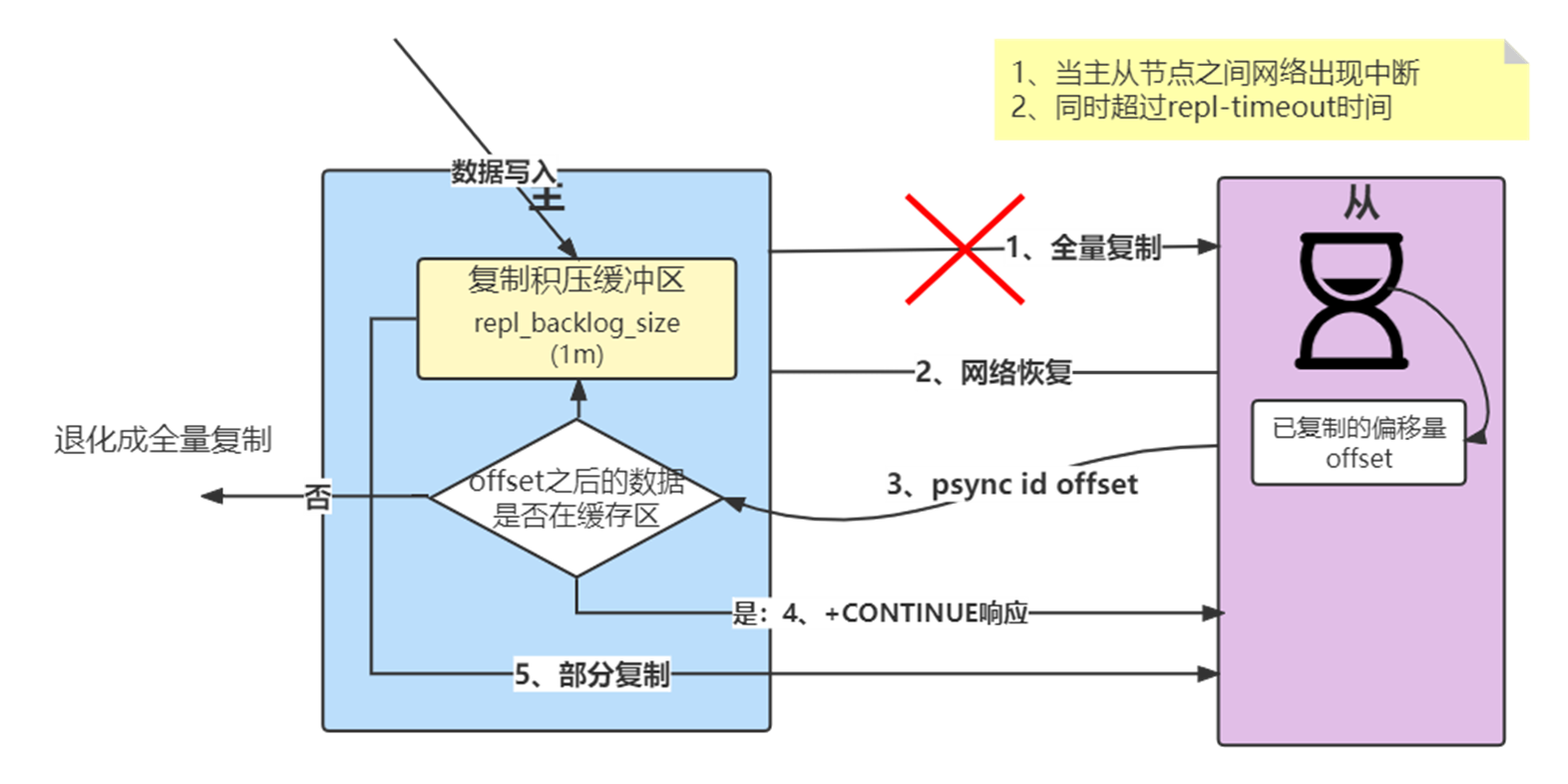
1)当主从节点之间网络出现中断时,如果超过repl-timeout时间,主节点会认为从节点故障并中断复制连接,打印日志。如果此时从节点没有宕机,也会打印与主节点连接丢失日志。
2)主从连接中断期间主节点依然响应命令,但因复制连接中断命令无法发送给从节点,不过主节点内部存在的复制积压缓冲区,依然可以保存最近一段时间的写命令数据,默认最大缓存1MB。
3)当主从节点网络恢复后,从节点会再次连上主节点,打印日志。
4)当主从连接恢复后,由于从节点之前保存了自身已复制的偏移量和主节点的运行ID。因此会把它们当作psync参数发送给主节点,要求进行部分复制操作。
5)主节点接到psync命令后首先核对参数runId是否与自身一致,如果一致,说明之前复制的是当前主节点;之后根据参数offset在自身复制积压缓冲区查找,如果偏移量之后的数据存在缓冲区中,则对从节点发送+CONTINUE响应,表示可以进行部分复制。如果不再,则退化为全量复制。
6)主节点根据偏移量把复制积压缓冲区里的数据发送给从节点,保证主从复制进入正常状态。发送的数据量可以在主节点的日志,传递的数据远远小于全量数据。
心跳
主从节点在建立复制后,它们之间维护着长连接并彼此发送心跳命令。
主从心跳判断机制:
1)主从节点彼此都有心跳检测机制,各自模拟成对方的客户端进行通信,通过client list命令查看复制相关客户端信息,主节点的连接状态为flags=M,从节点连接状态为flags=S。
2)主节点默认每隔10秒对从节点发送ping命令,判断从节点的存活性和连接状态。
可通过参数repl-ping-slave-period控制发送频率。
3)从节点在主线程中每隔1秒发送replconf ack {offset}命令,给主节点上报自身当前的复制偏移量。replconf命令主要作用如下:
实时监测主从节点网络状态;
上报自身复制偏移量,检查复制数据是否丢失,如果从节点数据丢失,再从主节点的复制缓冲区中拉取丢失数据
实现保证从节点的数量和延迟性功能,通过min-slaves-to-write、min-slaves-max-lag参数配置定义;
主节点根据replconf命令判断从节点超时时间,体现在info replication统计中的lag信息中,lag表示与从节点最后一次通信延迟的秒数,正常延迟应该在0和1之间。如果超过repl-timeout配置的值((默认60秒),则判定从节点下线并断开复制客户端连接。即使主节点判定从节点下线后,如果从节点重新恢复,心跳检测会继续进行。
异步复制机制
主节点不但负责数据读写,还负责把写命令同步给从节点。写命令的发送过程是异步完成,也就是说主节点自身处理完写命令后直接返回给客户端,并不等待从节点复制完成。
由于主从复制过程是异步的,就会造成从节点的数据相对主节点存在延迟。具体延迟多少字节,我们可以在主节点执行info replication命令查看相关指标获得。
在统计信息中可以看到从节点slave信息,分别记录了从节点的ip和 port,从节点的状态,offset表示当前从节点的复制偏移量,master_repl_offset表示当前主节点的复制偏移量,两者的差值就是当前从节点复制延迟量。Redis 的复制速度取决于主从之间网络环境,repl-disable-tcp-nodelay,命令处理速度等。正常情况下,延迟在1秒以内。
哨兵Redis Sentinel
Redis 的主从复制模式下,一旦主节点由于故障不能提供服务,需要人工将从节点晋升为主节点,同时还要通知应用方更新主节点地址,对于很多应用场景这种故障处理的方式是无法接受的。
Redis 从 2.8开始正式提供了Redis Sentinel(哨兵)架构来解决这个问题。
主从复制的问题
Redis 的主从复制模式可以将主节点的数据改变同步给从节点,这样从节点就可以起到两个作用
第一,作为主节点的一个备份,一旦主节点出了故障不可达的情况,从节点可以作为后备“顶”上来,并且保证数据尽量不丢失(主从复制是最终一致性)。
第二,从节点可以扩展主节点的读能力,一旦主节点不能支撑住大并发量的读操作,从节点可以在一定程度上帮助主节点分担读压力。
但是主从复制也带来了以下问题:
1、一旦主节点出现故障,需要手动将一个从节点晋升为主节点,同时需要修改应用方的主节点地址,还需要命令其他从节点去复制新的主节点,整个过程都需要人工干预。
2、主节点的写能力受到单机的限制。
3、主节点的存储能力受到单机的限制。
Redis Sentinel
Redis Sentinel是一个分布式架构,其中包含若干个Sentinel节点和Redis数据节点,每个Sentinel节点会对数据节点和其余Sentinel节点进行监控,当它发现节点不可达时,会对节点做下线标识。如果被标识的是主节点,它还会和其他Sentinel节点进行“协商”,当大多数Sentinel节点都认为主节点不可达时,它们会选举出一个Sentinel节点来完成自动故障转移的工作,同时会将这个变化实时通知给Redis应用方。整个过程完全是自动的,不需要人工来介入,所以这套方案很有效地解决了Redis的高可用问题。
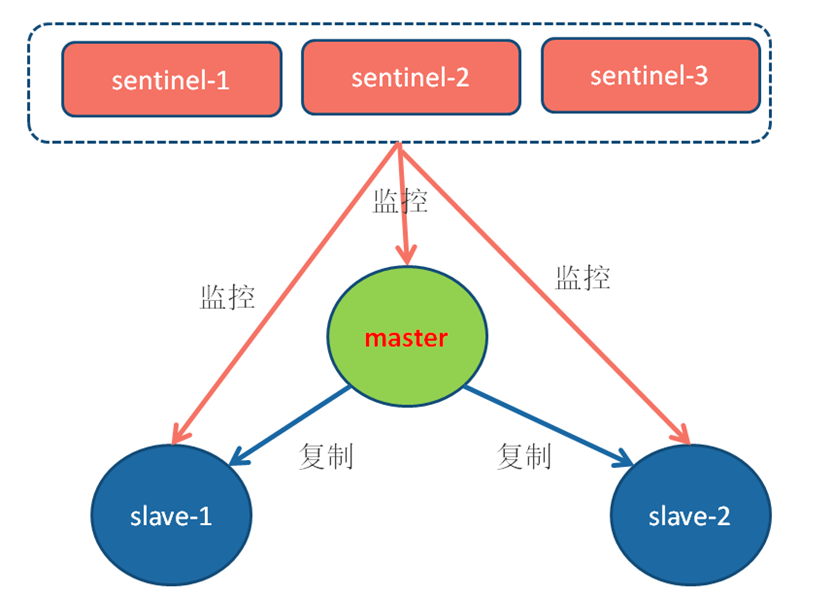
Redis Sentinel的搭建
我们以以3个 Sentinel节点、1个主节点、2个从节点组成一个Redis Sentinel进行说明。
启动主从的方式和普通的主从没有不同。
启动Sentinel节点
Sentinel节点的启动方法有两种:
方法一,使用redis-sentinel命令:
./redis-sentinel ../conf/reids.conf
方法二,使用redis-server命令加–sentinel参数:
./redis-server ../conf/reids.conf --sentinel
两种方法本质上是—样的。
确认
Sentinel节点本质上是一个特殊的Redis节点,所以也可以通过info命令来查询它的相关信息

实现原理
Redis Sentinel的基本实现中包含以下:
Redis Sentinel 的定时任务、主观下线和客观下线、Sentinel领导者选举、故障转移等等知识点,学习这些可以让我们对Redis Sentinel的高可用特性有更加深入的理解和认识。
三个定时监控任务
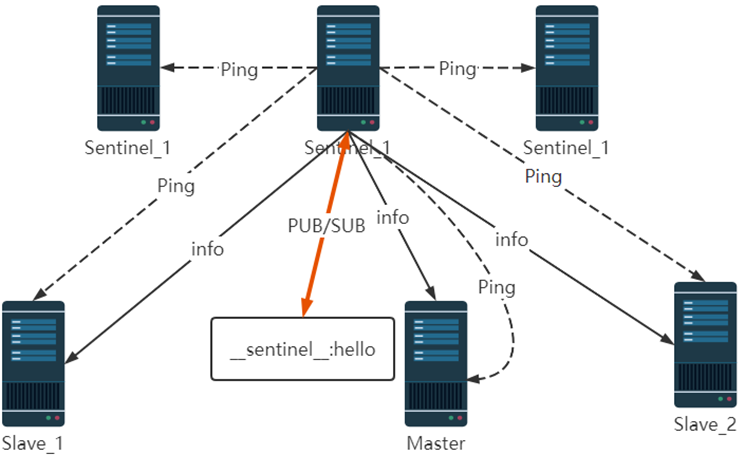
一套合理的监控机制是Sentinel节点判定节点不可达的重要保证,Redis Sentinel通过三个定时监控任务完成对各个节点发现和监控:
1、每隔10秒的定时监控
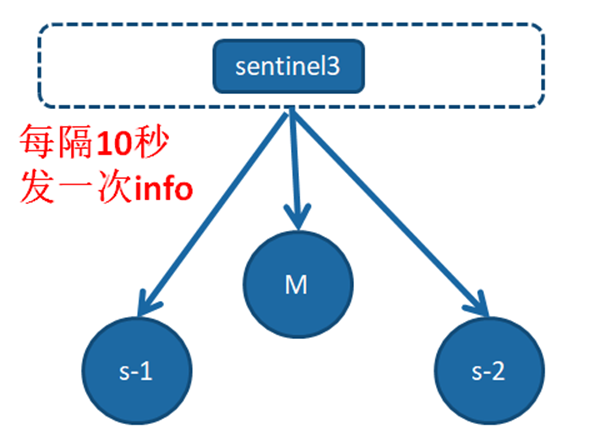
每隔10秒,每个Sentinel节点会向主节点和从节点发送info命令获取最新的拓扑结构,Sentinel节点通过对上述结果进行解析就可以找到相应的从节点。
这个定时任务的作用具体可以表现在三个方面:
1、通过向主节点执行info命令,获取从节点的信息,这也是为什么Sentinel节点不需要显式配置监控从节点。
2、当有新的从节点加入时都可以立刻感知出来。
3、节点不可达或者故障转移后,可以通过info命令实时更新节点拓扑信息。
2、每隔2秒的定时监控
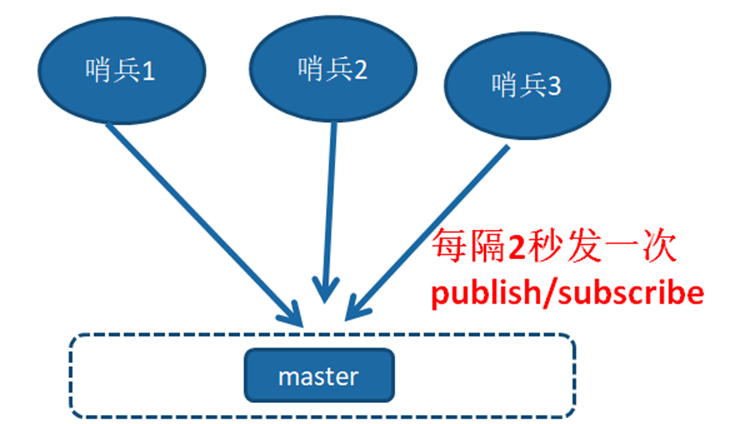
每隔2秒,每个Sentinel节点会向Redis数据节点的_sentinel_:hello频道上发送该Sentinel节点对于主节点的判断以及当前Sentinel节点的信息,同时每个Sentinel节点也会订阅该频道,来了解其他Sentinel节点以及它们对主节点的判断,所以这个定时任务可以完成以下两个工作:
发现新的Sentinel节点:通过订阅主节点的__sentinel__:hello了解其他的Sentinel节点信息,如果是新加入的Sentinel节点,将该Sentinel节点信息保存起来,并与该 Sentinel节点创建连接。
Sentinel节点之间交换主节点的状态,作为后面客观下线以及领导者选举的依据。
3、每隔1秒的定时监控
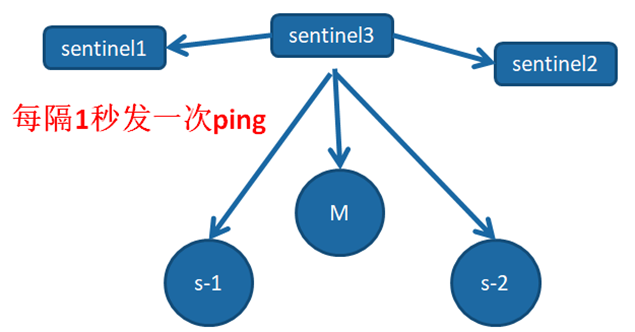
每隔1秒,每个Sentinel节点会向主节点、从节点、其余Sentinel节点发送一条ping命令做一次心跳检测,来确认这些节点当前是否可达。
通过上面的定时任务,Sentinel节点对主节点、从节点、其余Sentinel节点都建立起连接,实现了对每个节点的监控,这个定时任务是节点失败判定的重要依据。
主观下线和客观下线
主观下线
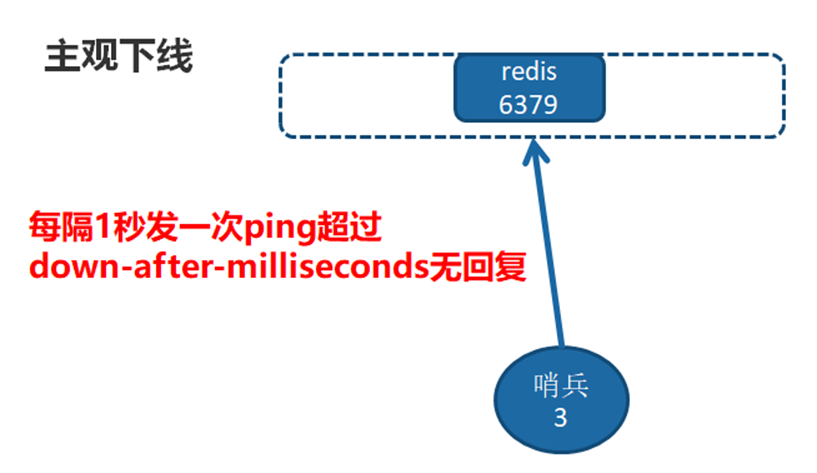

上一小节介绍的第三个定时任务,每个Sentinel节点会每隔1秒对主节点、从节点、其他Sentinel节点发送ping命令做心跳检测,当这些节点超过down-after-milliseconds没有进行有效回复,Sentinel节点就会对该节点做失败判定,这个行为叫做主观下线。从字面意思也可以很容易看出主观下线是当前Sentinel节点的一家之言,存在误判的可能。
客观下线
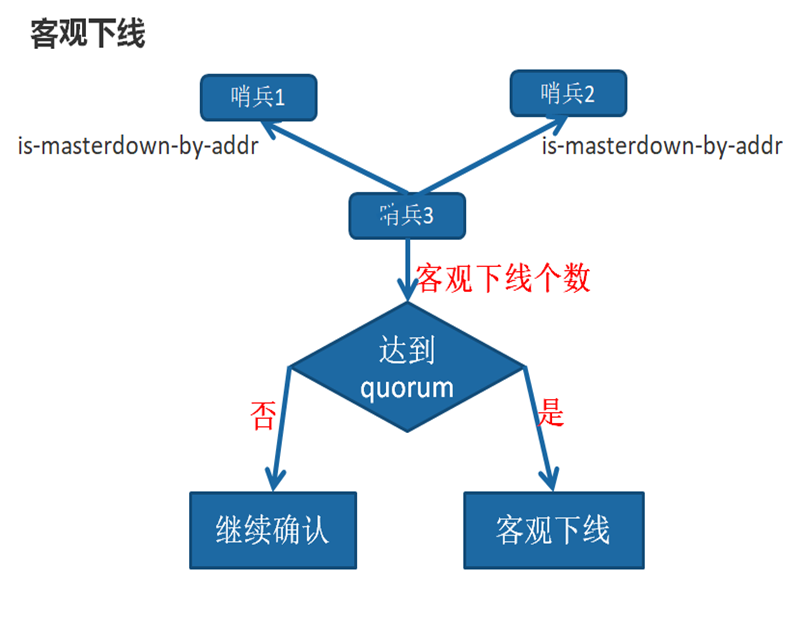
当Sentinel主观下线的节点是主节点时,该Sentinel节点会通过sentinel is-master-down-by-addr命令向其他Sentinel节点询问对主节点的判断,当超过<quorum>个数,Sentinel节点认为主节点确实有问题,这时该Sentinel节点会做出客观下线的决定,这样客观下线的含义是比较明显了,也就是大部分Sentinel节点都对主节点的下线做了同意的判定,那么这个判定就是客观的。

领导者Sentinel节点选举
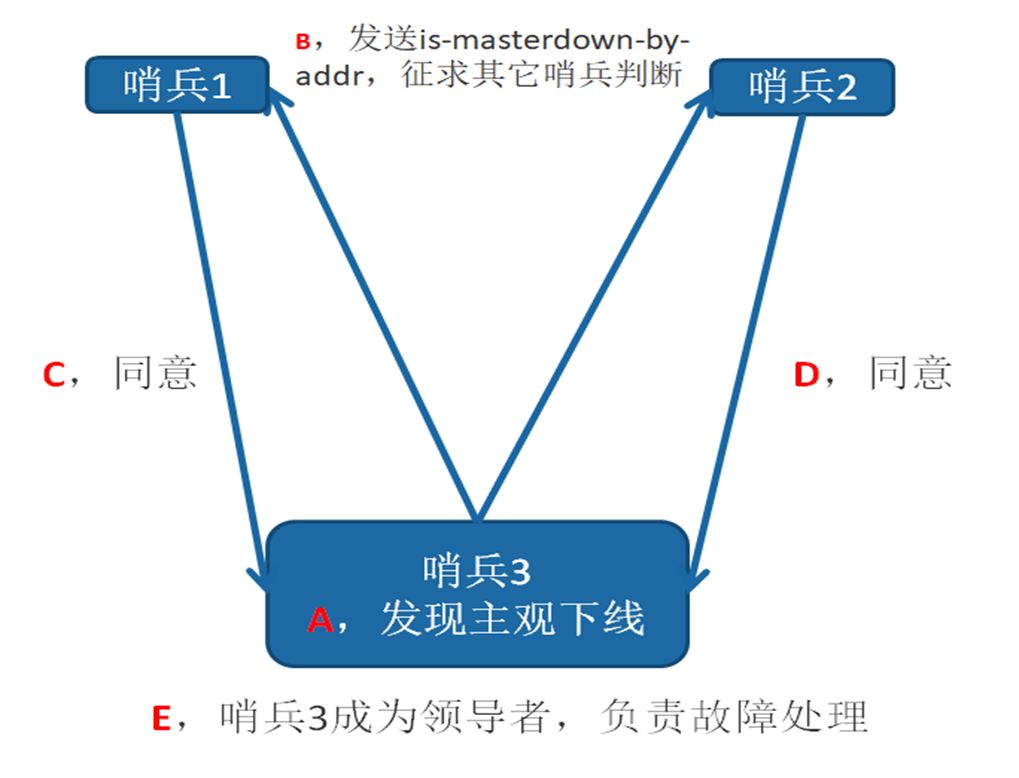
假如Sentinel节点对于主节点已经做了客观下线,那么是不是就可以立即进行故障转移了?当然不是,实际上故障转移的工作只需要一个Sentinel节点来完成即可,所以 Sentinel节点之间会做一个领导者选举的工作,选出一个Sentinel节点作为领导者进行故障转移的工作。Redis使用了Raft算法实现领导者选举,Redis Sentinel进行领导者选举的大致思路如下:
1 )每个在线的Sentinel节点都有资格成为领导者,当它确认主节点主观下线时候,会向其他Sentinel节点发送sentinel is-master-down-by-addr命令,要求将自己设置为领导者。
2)收到命令的Sentinel节点,如果没有同意过其他Sentinel节点的sentinel is-master-down-by-addr命令,将同意该请求,否则拒绝。
3)如果该Sentinel节点发现自己的票数已经大于等于max (quorum,num(sentinels)/2+1),那么它将成为领导者。
4)如果此过程没有选举出领导者,将进入下一次选举。
选举的过程非常快,基本上谁先完成客观下线,谁就是领导者。
Raft协议的详细版本:
raft-zh_cn/raft-zh_cn.md at master · maemual/raft-zh_cn · GitHub
如果你想手写一个Raft协议,可以看下蚂蚁金服的开发生产的raft算法组件
GitHub - sofastack/sofa-jraft: A production-grade java implementation of RAFT consensus algorithm.
选举很快的!!

故障转移
领导者选举出的Sentinel节点负责故障转移,具体步骤如下:
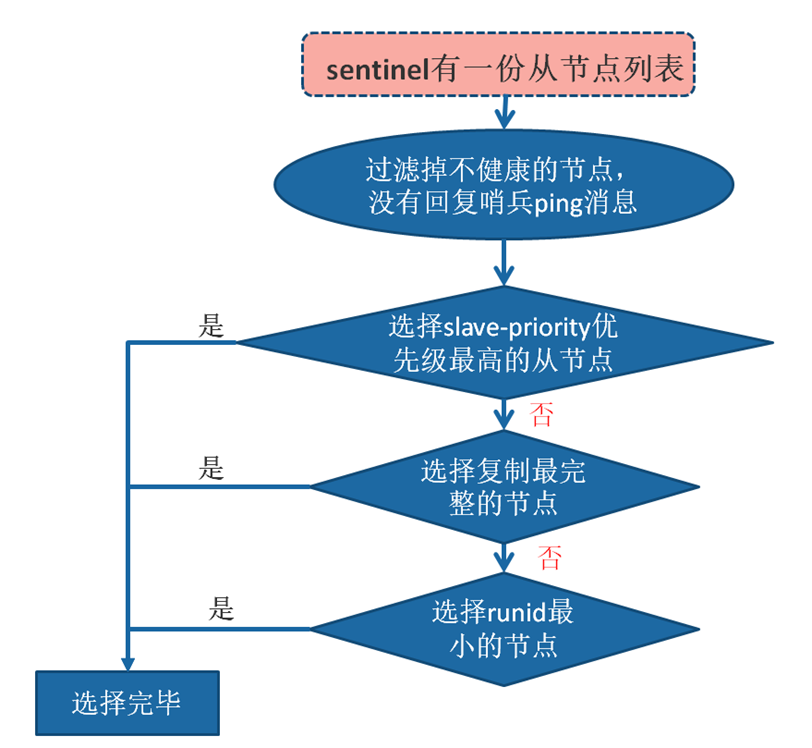
1)在从节点列表中选出一个节点作为新的主节点,选择方法如下:
a)过滤:“不健康”(主观下线、断线)、5秒内没有回复过Sentinel节点 ping响应、与主节点失联超过down-after-milliseconds*10秒。
b)选择slave-priority(从节点优先级)最高的从节点列表,如果存在则返回,不存在则继续。
c)选择复制偏移量最大的从节点(复制的最完整),如果存在则返回,不存在则继续。
d)选择runid最小的从节点。
2 ) Sentinel领导者节点会对第一步选出来的从节点执行slaveof no one命令让其成为主节点。
3 ) Sentinel领导者节点会向剩余的从节点发送命令,让它们成为新主节点的从节点,复制规则和parallel-syncs参数有关。
4 ) Sentinel节点集合会将原来的主节点更新为从节点,并保持着对其关注,当其恢复后命令它去复制新的主节点。
Redis Sentinel的客户端
如果主节点挂掉了,虽然Redis Sentinel可以完成故障转移,但是客户端无法获取这个变化,那么使用Redis Sentinel的意义就不大了,所以各个语言的客户端需要对Redis Sentinel进行显式的支持。
Sentinel节点集合具备了监控、通知、自动故障转移、配置提供者若干功能,也就是说实际上最了解主节点信息的就是Sentinel节点集合,而各个主节点可以通过<host-name>进行标识的,所以,无论是哪种编程语言的客户端,如果需要正确地连接Redis Sentinel,必须有Sentinel节点集合和masterName两个参数。
我们依然使用Jedis 作为Redis 的 Java客户端,Jedis能够很好地支持Redis
Sentinel,并且使用Jedis连接Redis Sentinel也很简单,按照Redis Sentinel的原理,需要有masterName和Sentinel节点集合两个参数。Jedis针对Redis Sentinel给出了一个 JedisSentinelPool。
具体代码可以参见redis-sentinel:
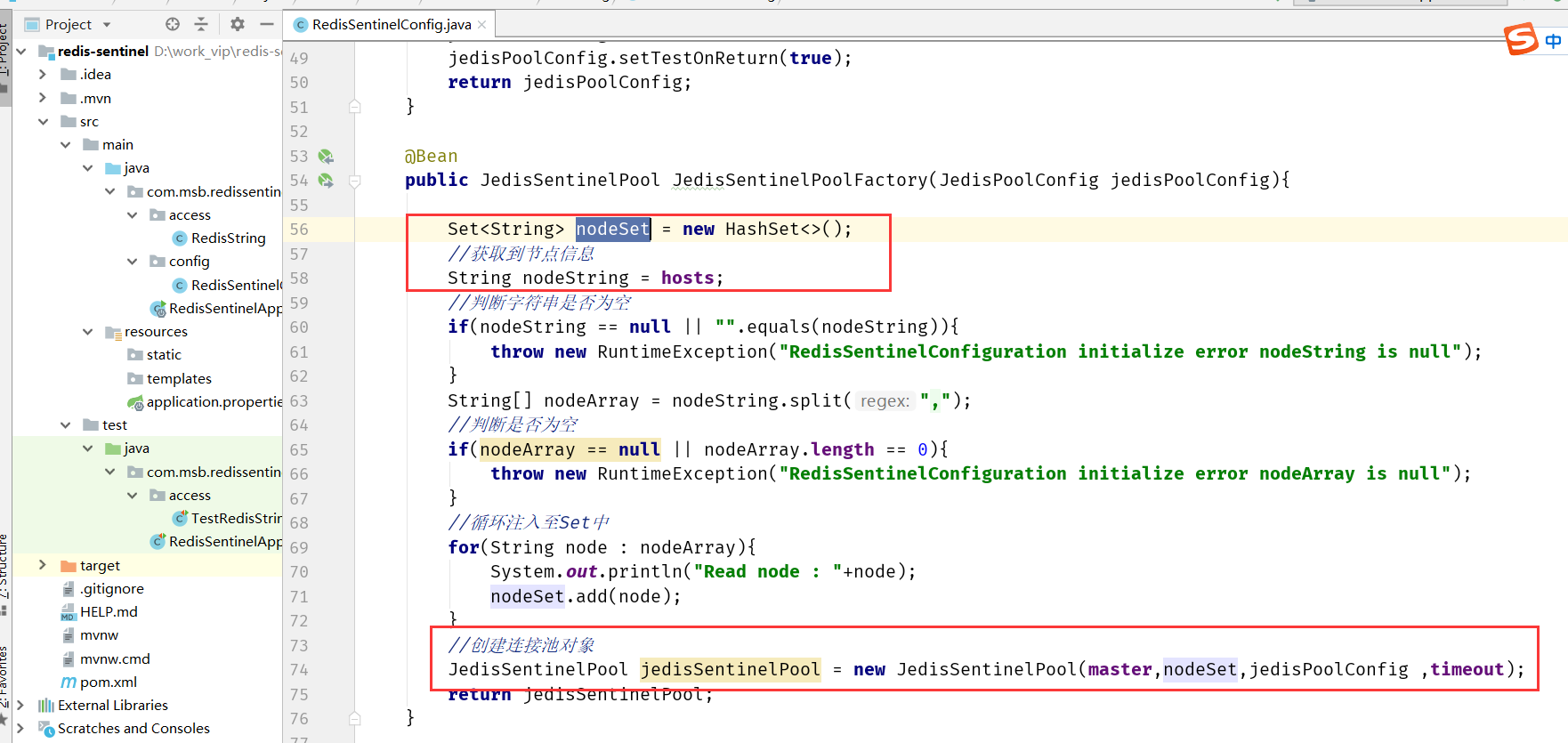
实现一个Redis Sentinel客户端一般来说需要:
1)遍历Sentinel节点集合获取一个可用的Sentinel节点,Sentinel节点之间可以共享数据,所以从任意一个Sentinel节点获取主节点信息都是可以的。
2)通过sentinel get-master-addr-by-name host-name这个API来获取对应主节点的相关信息。
3)验证当前获取的“主节点”是真正的主节点,这样做的目的是为了防止故障转移期间主节点的变化。
4)保持和 Sentinel节点集合的“联系”,时刻获取关于主节点的相关“信息”。
但是注意,JedisSentinel的实现是不支持读写分离的,所有的连接都是连接到Master上面,Slave就完全当成Master的备份,存在着性能浪费。因此如果想支持读写分离,需要自行实现,这里给一个参考
基于Spring 的 Redis Sentinel 读写分离 Slave 连接池 (jack-yin.com)
高可用读写分离
从节点的作用
第一,当主节点出现故障时,作为主节点的后备“顶”上来实现故障转移,Redis Sentinel已经实现了该功能的自动化,实现了真正的高可用。
第二,扩展主节点的读能力,尤其是在读多写少的场景非常适用。
但上述模型中,从节点不是高可用的:
如果slave-1节点出现故障,首先客户端client-1将与其失联,其次Sentinel节点只会对该节点做主观下线,因为Redis Sentinel的故障转移是针对主节点的。所以很多时候,Redis Sentinel中的从节点仅仅是作为主节点一个热备,不让它参与客户端的读操作,就是为了保证整体高可用性,但实际上这种使用方法还是有一些浪费,尤其是在有很多从节点或者确实需要读写分离的场景,所以如何实现从节点的高可用是非常有必要的。
Redis Sentinel读写分离设计思路参考
Redis Sentinel在对各个节点的监控中,如果有对应事件的发生,都会发出相应的事件消息,其中和从节点变动的事件有以下几个:
+switch-master
切换主节点(原来的从节点晋升为主节点),说明减少了某个从节点。
+convert-to-slave
切换从节点(原来的主节点降级为从节点),说明添加了某个从节点。
+sdown
主观下线,说明可能某个从节点可能不可用(因为对从节点不会做客观下线),所以在实现客户端时可以采用自身策略来实现类似主观下线的功能。
+reboot
重新启动了某个节点,如果它的角色是slave,那么说明添加了某个从节点。
所以在设计Redis Sentinel的从节点高可用时,只要能够实时掌握所有从节点的状态,把所有从节点看做一个资源池,无论是上线还是下线从节点,客户端都能及时感知到(将其从资源池中添加或者删除),这样从节点的高可用目标就达到了。
相关文章:
【中间件篇-Redis缓存数据库06】Redis主从复制/哨兵 高并发高可用
Redis高并发高可用 复制 在分布式系统中为了解决单点问题,通常会把数据复制多个副本部署到其他机器,满足故障恢复和负载均衡等需求。Redis也是如此,它为我们提供了复制功能,实现了相同数据的多个Redis 副本。复制功能是高可用Re…...
LeetCode(12)时间插入、删除和获取随机元素【数组/字符串】【中等】
目录 1.题目2.答案3.提交结果截图 链接: 380. O(1) 时间插入、删除和获取随机元素 1.题目 实现RandomizedSet 类: RandomizedSet() 初始化 RandomizedSet 对象bool insert(int val) 当元素 val 不存在时,向集合中插入该项,并返回…...

前端面试题 计算机网络
文章目录 ios 7层协议tcp协议和udp协议的区别tcp协议如何确保数据的可靠http和tcp的关系url输入地址到呈现网页有哪些步骤post和get本质区别,什么时候会触发二次预检GET请求:POST请求:触发二次预检(CORS中的预检请求)&…...
windows aseprite编译指南(白嫖)
aseprite是画像素图的专业软件,steam上有售卖,不过官方也在github开源了,需要自己编译。 1. 首先获取源码 直接在github上clone源码到本地指定目录 需要先下载git,下载好后在git.bash中执行(需要腾一个用来安放源码的…...

生活污水处理一体化处理设备有哪些
生活污水处理一体化处理设备有多种类型,包括但不限于以下几种: 鼓风机:提供曝气系统所需的气流。潜水污水提升泵:将污水从低处提升到高处。旋转式滚筒筛分机:对污水中的悬浮物进行分离和筛选。回旋式格栅:…...

JSON可视化管理工具JSON Hero
本文软件由网友 zxc 推荐; 什么是 JSON Hero ? JSON Hero 是一个简单实用的 JSON 工具,通过简介美观的 UI 及增强的额外功能,使得阅读和理解 JSON 文档变得更容易、直观。 主要功能 支持多种视图以便查看 JSON:列视图…...
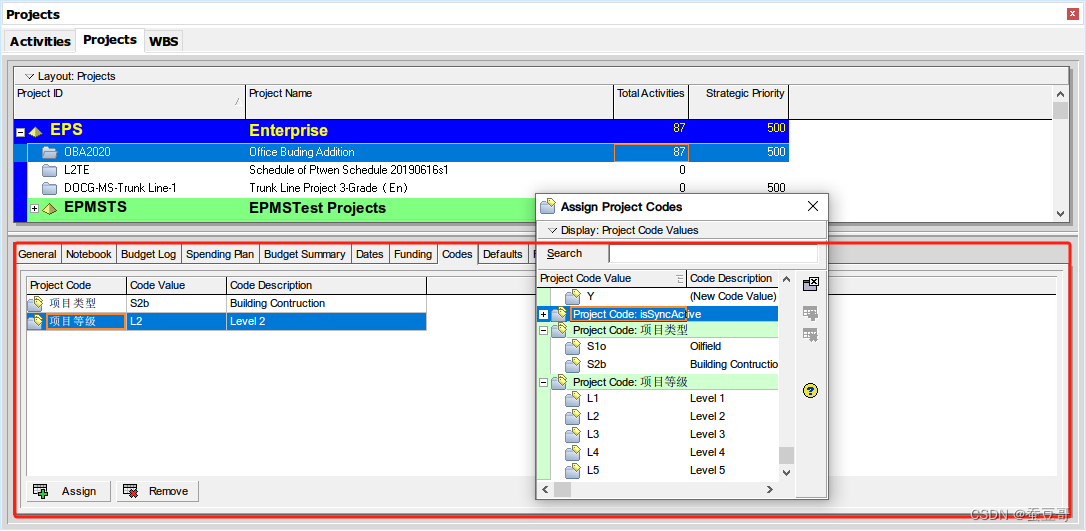
P6入门:项目初始化7-项目详情之代码/分类码Code
前言 使用项目详细信息查看和编辑有关所选项目的详细信息,在项目创建完成后,初始化项目是一项非常重要的工作,涉及需要设置的内容包括项目名,ID,责任人,日历,预算,资金,分类码等等&…...
跨国企业如何选择安全靠谱的跨国传输文件软件?
随着全球化的不断发展,跨国企业之间的合作变得越来越频繁。而在这种合作中,如何安全、可靠地将文件传输给合作伙伴或客户,成为了跨国企业必须面对的问题。 然而,跨国文件传输并不是一件容易的事情,由于网络物理条件的…...
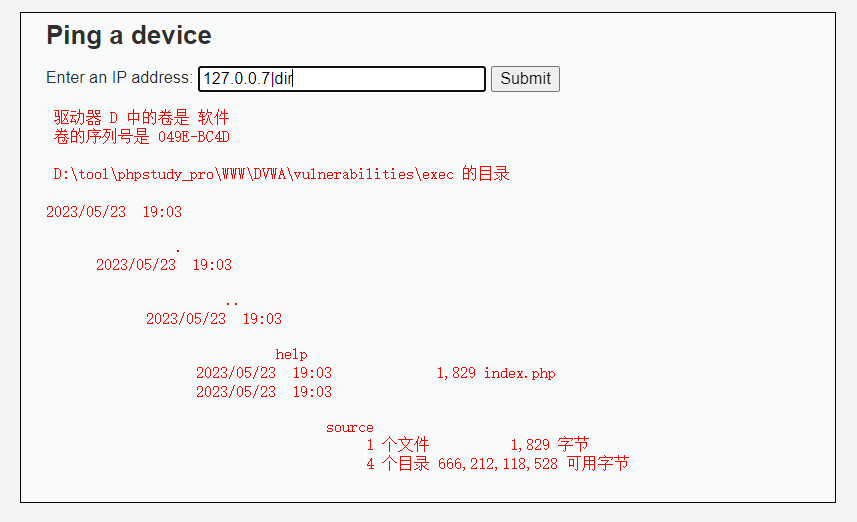
Command Injection
Command Injection "Command Injection"(命令注入),其目标是通过一个应用程序在主机操作系统上执行任意命令。当一个应用程序将用户提供的数据(如表单、cookies、HTTP头等)传递给系统shell时,就可能发生命令注入攻击。在…...

LeetCode | 20. 有效的括号
LeetCode | 20. 有效的括号 OJ链接 这道题可以使用栈来解决问题~~ 思路: 首先我们要使用我们之前写的栈的实现来解决此问题~~如果左括号,就入栈如果右括号,出栈顶的左括号跟右括号判断是否匹配 如果匹配,继续如果不匹配&#…...

英语语法 - 祈使句 | 虚拟语气
目录 [ 祈使句 ] 1. [ 及物动词原形 宾语 (状语) | 不及物动词原形 (状语) | be 表语 (状语) ] 2. [ Dont 及物动词原形 宾语 | dont 不及物动词原形 ] 3. [ dont be 表语 ] 4. 特殊 you [ 虚拟语气 ] 1. [ 条件状语从句 - 虚拟语气 ] 现在时态虚拟语气 将来…...
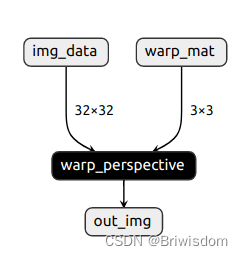
记录pytorch实现自定义算子并转onnx文件输出
概览:记录了如何自定义一个算子,实现pytorch注册,通过C编译为库文件供python端调用,并转为onnx文件输出 整体大概流程: 定义算子实现为torch的C版本文件注册算子编译算子生成库文件调用自定义算子 一、编译环境准备…...
ARPG----C++学习记录04 Section8 角色类,移动
角色类输入 新建一个角色C,继承建立蓝图,和Pawn一样,绑定输入移动和相机. 在构造函数中添加这段代码也能实现。打开UsePawnControlRotation就可以让人物不跟随鼠标旋转 得到旋转后的向前向量 使用旋转矩阵 想要前进方向和旋转的方向对应。获取当前控制…...
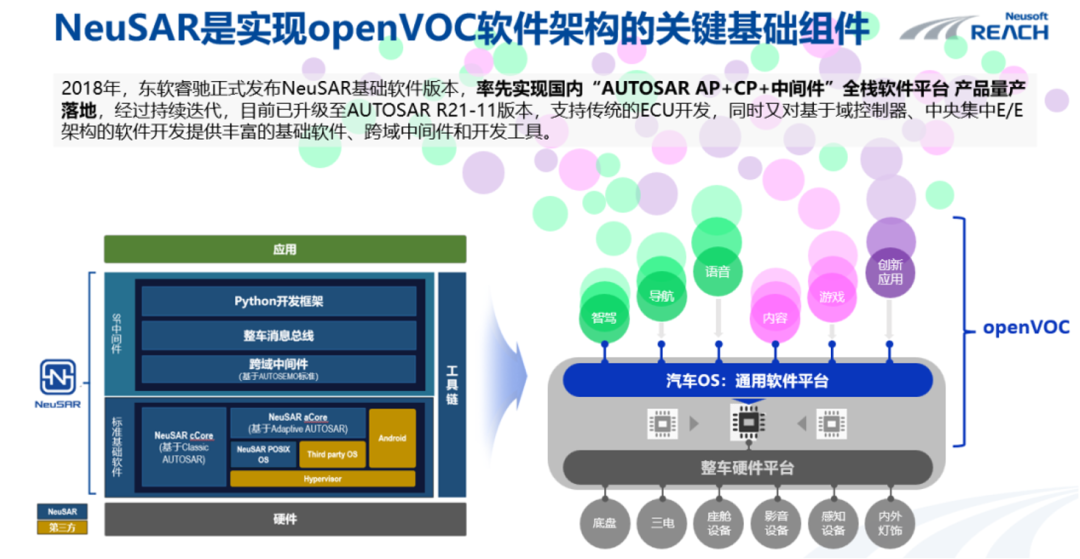
拆解软件定义汽车:OS突围
软件作为智能汽车的核心组成部分,由于自身较为独立和复杂的IT学科体系,其技术链路、产业分工、价值分配、商业模式相对硬件产品(如域控、激光雷达、摄像头等硬件)而言,在汽车产业内探讨和传播相对较少。 11月3日&…...
)
并发线程使用介绍(二)
2.2.6 线程的强占 Thread的非静态方法join方法 需要在某一个线程下去调用这个方法 如果在main线程中调用了t1.join(),那么main线程会进入到等待状态,需要等待t1线程全部执行完毕,在恢复到就绪状态等待 CPU调度。 如果在main线程中调用了t1.j…...
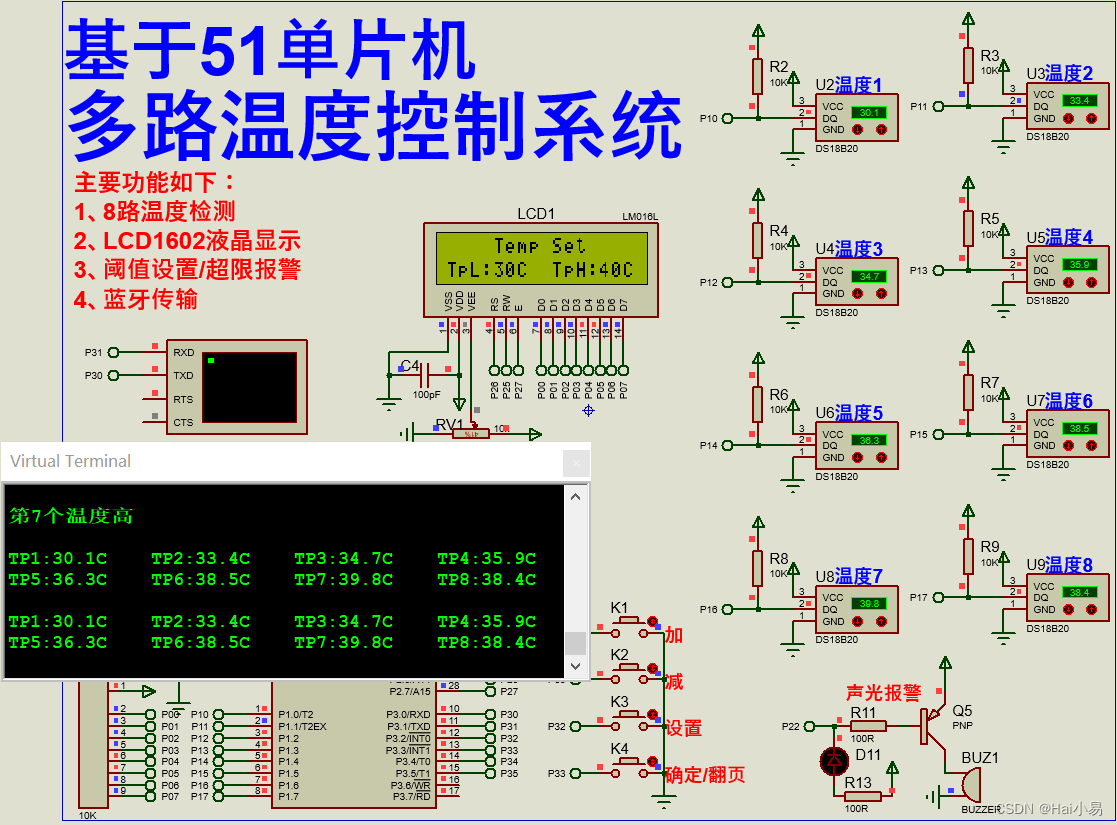
【Proteus仿真】【51单片机】多路温度控制系统
文章目录 一、功能简介二、软件设计三、实验现象联系作者 一、功能简介 本项目使用Proteus8仿真51单片机控制器,使用按键、LED、蜂鸣器、LCD1602、DS18B20温度传感器、HC05蓝牙模块等。 主要功能: 系统运行后,默认LCD1602显示前4路采集的温…...

一些可以参考的文档集合15
之前的文章集合: 一些可以参考文章集合1_xuejianxinokok的博客-CSDN博客 一些可以参考文章集合2_xuejianxinokok的博客-CSDN博客 一些可以参考的文档集合3_xuejianxinokok的博客-CSDN博客 一些可以参考的文档集合4_xuejianxinokok的博客-CSDN博客 一些可以参考的文档集合5…...
k8s的service自动发现服务:实战版
Service服务发现的必要性: 对于kubernetes整个集群来说,Pod的地址也可变的,也就是说如果一个Pod因为某些原因退出了,而由于其设置了副本数replicas大于1,那么该Pod就会在集群的任意节点重新启动,这个重新启动的Pod的I…...

项目笔记记录
一、node下载版本报错:npm install --legacy-peer-deps 二、Scheduled: 任务自动化调度 Scheduled 标记要调度的方法的注解,必须指定 cron,fixedDelay或fixedRate属性之一 fixedDelay:固定延迟 延迟执行任务,任务在…...

【leetcode】1137. 第 N 个泰波那契数
题目 泰波那契序列 Tn 定义如下: T0 0, T1 1, T2 1, 且在 n > 0 的条件下 Tn3 Tn Tn1 Tn2 给你整数 n,请返回第 n 个泰波那契数 Tn 的值。 示例 1: 输入:n 4 输出:4 解释: T_3 0 1 1 2 …...

从分立逻辑到单片机:基于ATmega8的MIDI通道分析仪设计与实现
1. 项目概述:从分立逻辑到单片机的MIDI通道分析仪进化史二十年前,当我在《Elektor》杂志上发表第一版MIDI通道分析仪时,整个数字音乐世界还处于一个相当“硬核”的阶段。那个版本的设计,用今天的话来说,简直就是一场“…...

解密高校教师必会的Gemini 3.1 Pro五大科研隐藏技能:从论文评估到创新点锁定
各位同仁好,我是七哥。一个在高校里从事人工智能相关领域研究,钻研用大模型AI实操的学术人。可以和七哥交流学术写作或Gemini、GPT、Claude等大模型学术实操相关问题,多多交流,相互成就,共同进步。 科研路上,有人发完顶刊顺利晋升,有人还在为创新点抓耳挠腮。 大多数教…...

应对Claude Code访问不稳定,快速切换至Taotoken的应急方案
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 应对Claude Code访问不稳定,快速切换至Taotoken的应急方案 对于依赖Claude Code进行日常开发或自动化任务的用户来说&a…...

别再只比参数了!从插件生态到中文优化,聊聊ChatGPT和文心一言的“隐形”差异
超越参数之争:ChatGPT与文心一言的生态与本土化实战解析 当技术评测文章还在反复比较模型参数量与发布时间时,真正影响日常工作效率的往往是那些未被量化的"软实力"。本文将从插件生态构建与中文场景优化两个维度,带您重新认识这两…...

BiliBiliCCSubtitle终极指南:5个实战技巧高效下载B站字幕
BiliBiliCCSubtitle终极指南:5个实战技巧高效下载B站字幕 【免费下载链接】BiliBiliCCSubtitle 一个用于下载B站(哔哩哔哩)CC字幕及转换的工具; 项目地址: https://gitcode.com/gh_mirrors/bi/BiliBiliCCSubtitle 还在为无法保存B站视频字幕而烦恼࿱…...

taotoken用量看板如何帮助团队精细化管理api调用成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 taotoken用量看板如何帮助团队精细化管理api调用成本 对于团队管理者而言,将大模型能力集成到产品开发或业务流程中&am…...

Arduino土壤湿度监测仪制作:从传感器原理到自动灌溉实现
1. 项目概述:用Arduino Uno和LCD屏打造你的土壤湿度监测仪作为一个喜欢在阳台种点番茄、辣椒的业余园丁,我经常为浇水这事儿头疼。浇多了怕烂根,浇少了又怕旱着,光靠手指插土里感觉,实在是不准。后来玩上了Arduino&…...
)
【独家首发】Sora 2 AVI支持并非“开箱即用”:3层封装校验机制详解(RIFF→AVI→OpenCV Mat内存映射链路图解)
更多请点击: https://codechina.net 第一章:Sora 2 AVI支持并非“开箱即用”:核心矛盾与技术定位 Sora 2 的官方文档与发布说明中明确将 AVI 视为“实验性容器支持”,而非默认启用的输入格式。其底层解码栈基于 FFmpeg 5.1 构建&…...

ThingLinks-IoT:一站式物联网平台解决方案
ThingLinks-IoT 物联网平台 | 多协议接入物模型告警联动视频接入AI 助手 一体化方案 一个面向项目交付与企业生产场景的国产物联网中台——把"设备接入 → 数据处理 → 告警联动 → 业务集成"这条链路上的通用能力一次性做完做稳,让你只关心自己的业务。 …...

5分钟掌握文件完整性验证:HashCalculator终极免费批量哈希计算工具指南
5分钟掌握文件完整性验证:HashCalculator终极免费批量哈希计算工具指南 【免费下载链接】HashCalculator 哈希值计算工具,批量计算/批量校验/查找重复文件/改变哈希值等,支持集成到系统右键菜单 项目地址: https://gitcode.com/gh_mirrors/…...