一、Hadoop3.1.3集群搭建
一、集群规划
| hadoop01(209.2) | hadoop02(209.3) | hadoop03(209.4) | |
|---|---|---|---|
| HDFS | NameNode DataNode | DataNode | SecondaryNameNode DataNode |
| YARN | NodeManager | ResourceManager NodeManager | NodeManager |
NameNode和SecondaryNameNode不要放在同一台服务器上
二、创建用户
useradd atguigu
passwd ***
配置atguigu用户权限
vim /etc/sudoers
## Allow root to run any commands anywhere
root ALL=(ALL) ALL
## Allows people in group wheel to run all commands
%wheel ALL=(ALL) ALL
atguigu ALL=(ALL) NOPASSWD:ALL
三、/opt下创建module、software
mkdir /opt/module
mkdir /opt/software
chown atguigu:atguigu /opt/module
chown atguigu:atguigu /opt/software
四、重新安装JDK
1、卸载原有的JDK
2、将jdk包上传到module下并解压
3、配置JDK环境变量
新建/etc/profile.d/my_env.sh 文件
vim /etc/profile.d/my_env.sh
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
source /etc/profile
java -version
五、hadoop01安装hadoop
https://archive.apache.org/dist/hadoop/common/hadoop-3.1.3/
1、解压到/opt/module下面
2、环境变量设置
vim /etc/profile.d/my_env.sh
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
source /etc/profile
3、SSH免密登录
进入 /home/atguigu/.ssh
ssh-keygen -t rsa
然后敲(三个回车),就会生成两个文件 id_rsa(私钥)、id_rsa.pub(公钥)
将公钥拷贝到要免密登录的目标机器上
ssh-copy-id hadoop01
ssh-copy-id hadoop02
ssh-copy-id hadoop03
注意:每台服务器都需要使用atguigu账号配置无密登录
六、集群配置
自定义配置文件存放在$HADOOP_HOME/etc/hadoop下
1、核心文件配置
配置core.site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration><!-- 指定 NameNode 的地址 --><property><name>fs.defaultFS</name><value>hdfs://hadoop01:8020</value></property><!-- 指定 hadoop 数据的存储目录 --><property><name>hadoop.tmp.dir</name><value>/opt/module/hadoop-3.1.3/data</value></property><!-- 配置 HDFS 网页登录使用的静态用户为 atguigu --><property><name>hadoop.http.staticuser.user</name><value>atguigu</value></property>
</configuration>
配置hdfs.site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- nn web 端访问地址-->
<property><name>dfs.namenode.http-address</name><value>hadoop01:9870</value></property>
<!-- 2nn web 端访问地址--><property><name>dfs.namenode.secondary.http-address</name><value>hadoop03:9868</value></property>
</configuration>
配置yarn.site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration><!-- 指定 MR 走 shuffle --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><!-- 指定 ResourceManager 的地址--><property><name>yarn.resourcemanager.hostname</name><value>hadoop02</value></property><!-- 环境变量的继承 --><property><name>yarn.nodemanager.env-whitelist</name><value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CO
NF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAP
RED_HOME</value></property>
</configuration>配置mapred-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定 MapReduce 程序运行在 Yarn 上 --><property><name>mapreduce.framework.name</name><value>yarn</value></property>
</configuration>2、配置历史服务器
mapred-site.xml
<!-- 历史服务器端地址 -->
<property><name>mapreduce.jobhistory.address</name><value>hadoop01:10020</value>
</property>
<!-- 历史服务器 web 端地址 -->
<property><name>mapreduce.jobhistory.webapp.address</name><value>hadoop01:19888</value>
</property>3、群起集群配置
vim /opt/module/hadoop3.1.3/etc/hadoop/workers 并添加
hadoop01
hadoop02
hadoop03
4、配置日志聚集
日志聚集概念:应用运行完成以后,将程序运行日志信息上传到 HDFS 系统上。
注意:开启日志聚集功能,需要重新启动 NodeManager 、ResourceManager 和 HistoryServer。
配置 yarn-site.xml
<!-- 开启日志聚集功能 -->
<property><name>yarn.log-aggregation-enable</name><value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property><name>yarn.log.server.url</name><value>http://hadoop02:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为 7 天 -->
<property><name>yarn.log-aggregation.retain-seconds</name><value>604800</value>
</property>
向其他节点分发所有修改过的配置,如:
rsync yarn-site.xml atguigu@hadoop02:/$HADOOP_HOME/etc/hadoop/yarnsite.xml
七、启动集群
如果集群是第一次启动,需要在 hadoop01 节点格式化 NameNode(注意:格式化 NameNode,会产生新的集群 id,导致 NameNode 和 DataNode 的集群 id 不一致,集群找 不到已往数据。如果集群在运行过程中报错,需要重新格式化 NameNode 的话,一定要先停 止 namenode 和 datanode 进程,并且要删除所有机器的 data 和 logs 目录,然后再进行格式化。
hdfs namenode -format
启动HDFS
sbin/start-dfs.sh
在配置了ResourceManager的节点hadoop02上启动yarn
sbin/start-yarn.sh
查看 HDFS 的 NameNode:http://hadoop102:9870
查看 YARN 的 ResourceManager:http://hadoop103:8088
启动历史服务器
mapred --daemon start historyserver
查看 JobHistory: http://hadoop102:19888/jobhistory
可使用jps查看启动的服务是否和一开始规划的一致
八、集群启动/停止方式总结
注意各节点之间的端口互通或者彻底关闭防火墙
1、各个模块分开启动/停止(配置 ssh 是前提)常用
(1)整体启动/停止 HDFS
start-dfs.sh/stop-dfs.sh
(2)整体启动/停止 YARN
start-yarn.sh/stop-yarn.sh
2、各个服务组件逐一启动/停止
(1)分别启动/停止 HDFS 组件
hdfs --daemon start/stop namenode/datanode/secondarynamenode
(2)启动/停止 YARN
yarn --daemon start/stop resourcemanager/nodemanager
3、Hadoop 集群启停脚本(包含 HDFS,Yarn,Historyserver):myhadoop.sh
cd /opt/module/hadoop-3.1.3/sbin
vim myhadoop.sh
#!/bin/bash
if [ $# -lt 1 ]
thenecho "No Args Input..."exit ;
fi
case $1 in
"start")echo " =================== 启动 hadoop 集群 ==================="echo " --------------- 启动 hdfs ---------------"ssh hadoop01 "/opt/module/hadoop-3.1.3/sbin/start-dfs.sh"echo " --------------- 启动 yarn ---------------"
ssh hadoop02 "/opt/module/hadoop-3.1.3/sbin/start-yarn.sh"echo " --------------- 启动 historyserver ---------------"ssh hadoop01 "/opt/module/hadoop-3.1.3/bin/mapred --daemon start historyserver"
;;
"stop")echo " =================== 关闭 hadoop 集群 ==================="echo " --------------- 关闭 historyserver ---------------"ssh hadoop01 "/opt/module/hadoop-3.1.3/bin/mapred --daemon stop historyserver"echo " --------------- 关闭 yarn ---------------"ssh hadoop02 "/opt/module/hadoop-3.1.3/sbin/stop-yarn.sh"echo " --------------- 关闭 hdfs ---------------"ssh hadoop01 "/opt/module/hadoop-3.1.3/sbin/stop-dfs.sh"
;;
*)echo "Input Args Error..."
;;
esac
chmod +x myhadoop.sh
查看三台服务器 Java 进程脚本:jpsall
cd /opt/module/hadoop-3.1.3/sbin
vim jpsall
#!/bin/bash
for host in hadoop01 hadoop02 hadoop03
doecho =============== $host ===============ssh $host jps
done
chmod +x jpsall
相关文章:

一、Hadoop3.1.3集群搭建
一、集群规划 hadoop01(209.2)hadoop02(209.3)hadoop03(209.4)HDFSNameNode DataNodeDataNodeSecondaryNameNode DataNodeYARNNodeManagerResourceManager NodeManagerNodeManager NameNode和SecondaryNameNode不要放在同一台服务器上 二、创建用户 useradd atguigu passwd *…...

QML16、从 C++ 定义 QML 类型
从 C++ 定义 QML 类型 当使用 C++ 代码扩展 QML 时,可以向 QML 类型系统注册 C++ 类,以使该类能够用作 QML 代码中的数据类型。 虽然任何 QObject 派生类的属性、方法和信号都可以从 QML 访问,如将 C++ 类型的属性暴露给 QML 中所讨论的,但在向类型系统注册之前,此类类不能…...
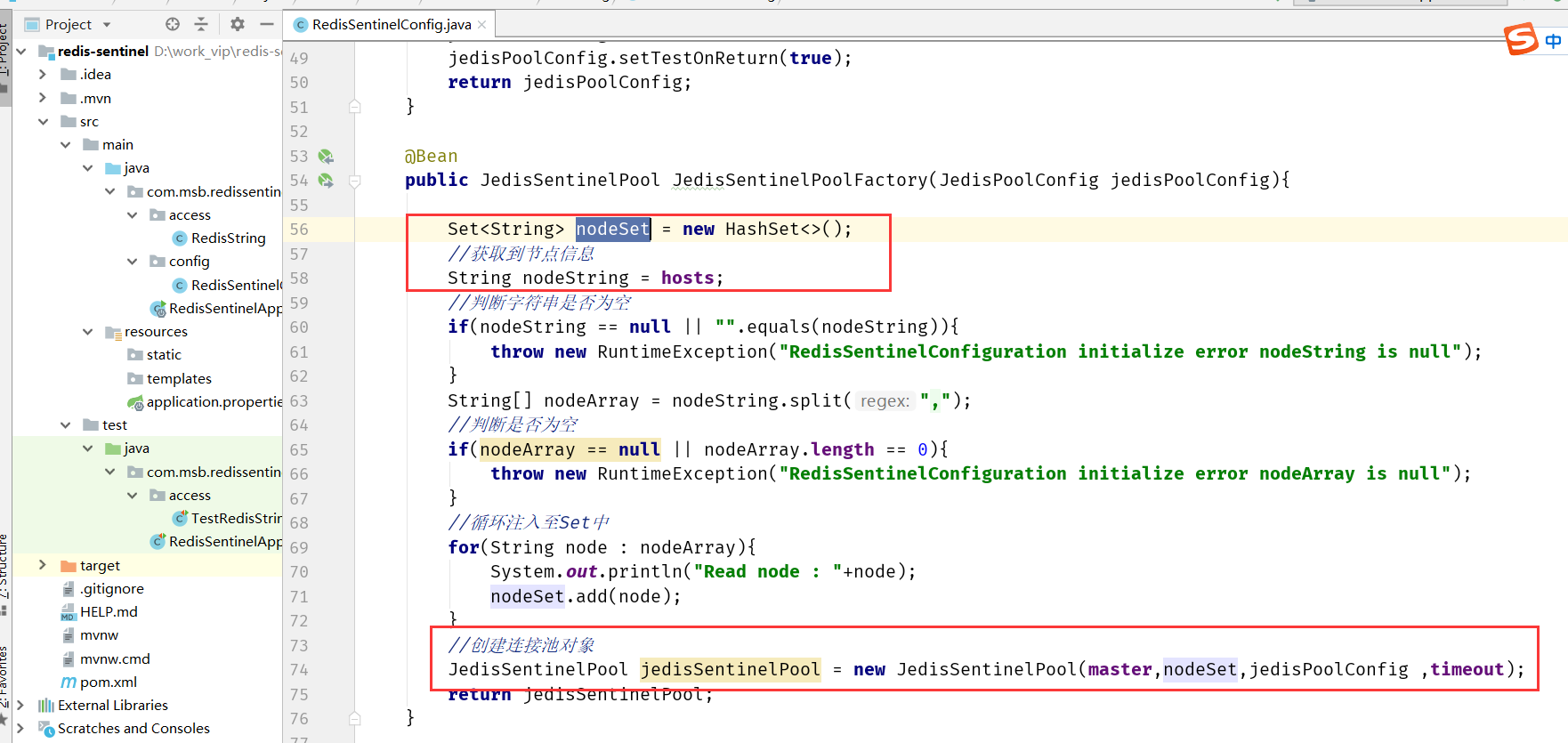
【中间件篇-Redis缓存数据库06】Redis主从复制/哨兵 高并发高可用
Redis高并发高可用 复制 在分布式系统中为了解决单点问题,通常会把数据复制多个副本部署到其他机器,满足故障恢复和负载均衡等需求。Redis也是如此,它为我们提供了复制功能,实现了相同数据的多个Redis 副本。复制功能是高可用Re…...
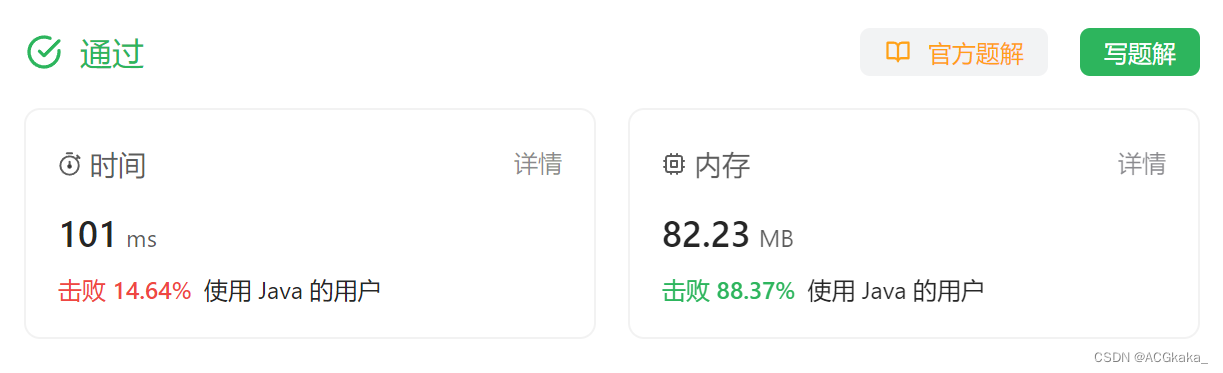
LeetCode(12)时间插入、删除和获取随机元素【数组/字符串】【中等】
目录 1.题目2.答案3.提交结果截图 链接: 380. O(1) 时间插入、删除和获取随机元素 1.题目 实现RandomizedSet 类: RandomizedSet() 初始化 RandomizedSet 对象bool insert(int val) 当元素 val 不存在时,向集合中插入该项,并返回…...

前端面试题 计算机网络
文章目录 ios 7层协议tcp协议和udp协议的区别tcp协议如何确保数据的可靠http和tcp的关系url输入地址到呈现网页有哪些步骤post和get本质区别,什么时候会触发二次预检GET请求:POST请求:触发二次预检(CORS中的预检请求)&…...
windows aseprite编译指南(白嫖)
aseprite是画像素图的专业软件,steam上有售卖,不过官方也在github开源了,需要自己编译。 1. 首先获取源码 直接在github上clone源码到本地指定目录 需要先下载git,下载好后在git.bash中执行(需要腾一个用来安放源码的…...

生活污水处理一体化处理设备有哪些
生活污水处理一体化处理设备有多种类型,包括但不限于以下几种: 鼓风机:提供曝气系统所需的气流。潜水污水提升泵:将污水从低处提升到高处。旋转式滚筒筛分机:对污水中的悬浮物进行分离和筛选。回旋式格栅:…...

JSON可视化管理工具JSON Hero
本文软件由网友 zxc 推荐; 什么是 JSON Hero ? JSON Hero 是一个简单实用的 JSON 工具,通过简介美观的 UI 及增强的额外功能,使得阅读和理解 JSON 文档变得更容易、直观。 主要功能 支持多种视图以便查看 JSON:列视图…...
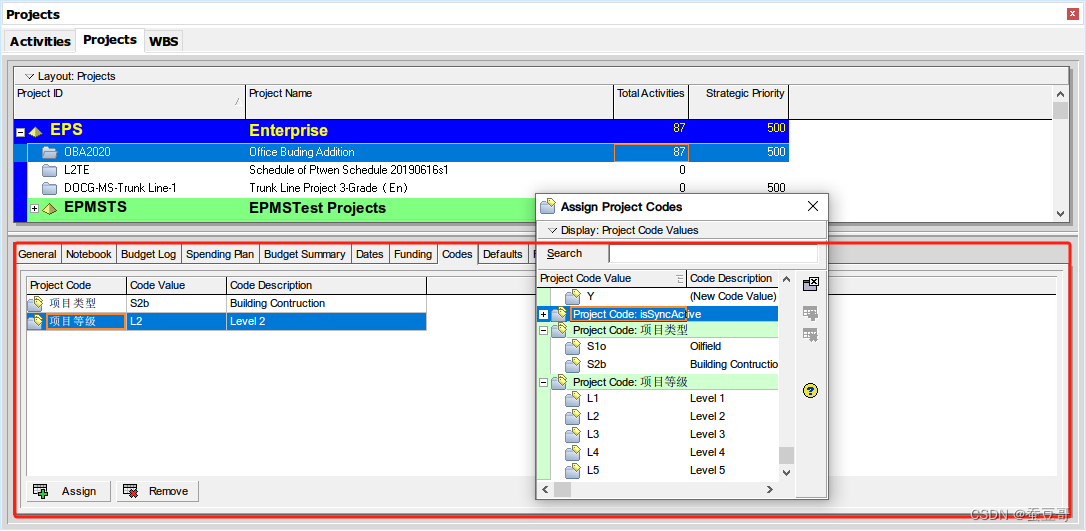
P6入门:项目初始化7-项目详情之代码/分类码Code
前言 使用项目详细信息查看和编辑有关所选项目的详细信息,在项目创建完成后,初始化项目是一项非常重要的工作,涉及需要设置的内容包括项目名,ID,责任人,日历,预算,资金,分类码等等&…...
跨国企业如何选择安全靠谱的跨国传输文件软件?
随着全球化的不断发展,跨国企业之间的合作变得越来越频繁。而在这种合作中,如何安全、可靠地将文件传输给合作伙伴或客户,成为了跨国企业必须面对的问题。 然而,跨国文件传输并不是一件容易的事情,由于网络物理条件的…...
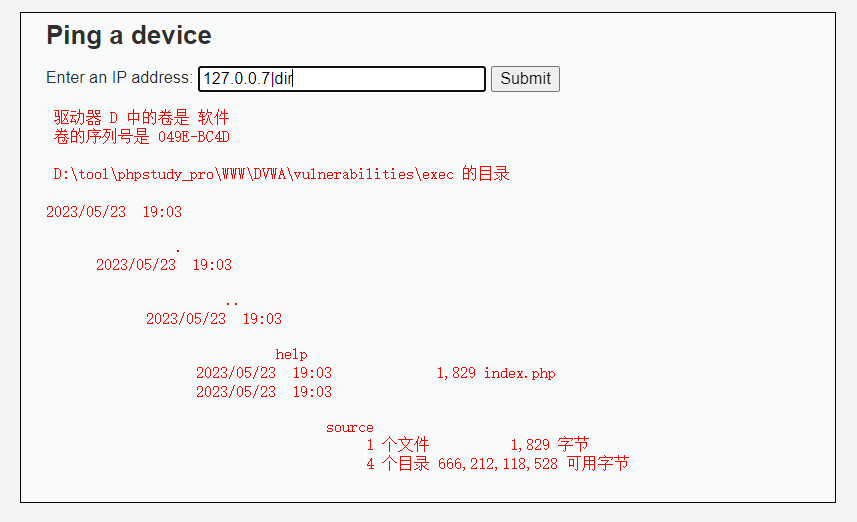
Command Injection
Command Injection "Command Injection"(命令注入),其目标是通过一个应用程序在主机操作系统上执行任意命令。当一个应用程序将用户提供的数据(如表单、cookies、HTTP头等)传递给系统shell时,就可能发生命令注入攻击。在…...

LeetCode | 20. 有效的括号
LeetCode | 20. 有效的括号 OJ链接 这道题可以使用栈来解决问题~~ 思路: 首先我们要使用我们之前写的栈的实现来解决此问题~~如果左括号,就入栈如果右括号,出栈顶的左括号跟右括号判断是否匹配 如果匹配,继续如果不匹配&#…...

英语语法 - 祈使句 | 虚拟语气
目录 [ 祈使句 ] 1. [ 及物动词原形 宾语 (状语) | 不及物动词原形 (状语) | be 表语 (状语) ] 2. [ Dont 及物动词原形 宾语 | dont 不及物动词原形 ] 3. [ dont be 表语 ] 4. 特殊 you [ 虚拟语气 ] 1. [ 条件状语从句 - 虚拟语气 ] 现在时态虚拟语气 将来…...
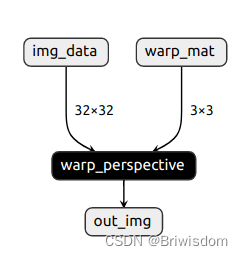
记录pytorch实现自定义算子并转onnx文件输出
概览:记录了如何自定义一个算子,实现pytorch注册,通过C编译为库文件供python端调用,并转为onnx文件输出 整体大概流程: 定义算子实现为torch的C版本文件注册算子编译算子生成库文件调用自定义算子 一、编译环境准备…...
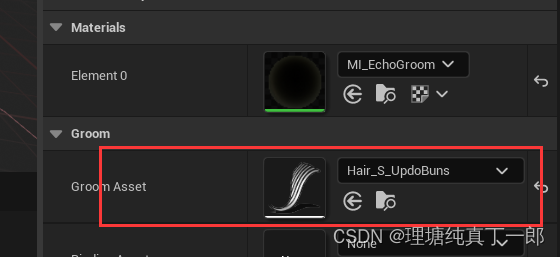
ARPG----C++学习记录04 Section8 角色类,移动
角色类输入 新建一个角色C,继承建立蓝图,和Pawn一样,绑定输入移动和相机. 在构造函数中添加这段代码也能实现。打开UsePawnControlRotation就可以让人物不跟随鼠标旋转 得到旋转后的向前向量 使用旋转矩阵 想要前进方向和旋转的方向对应。获取当前控制…...
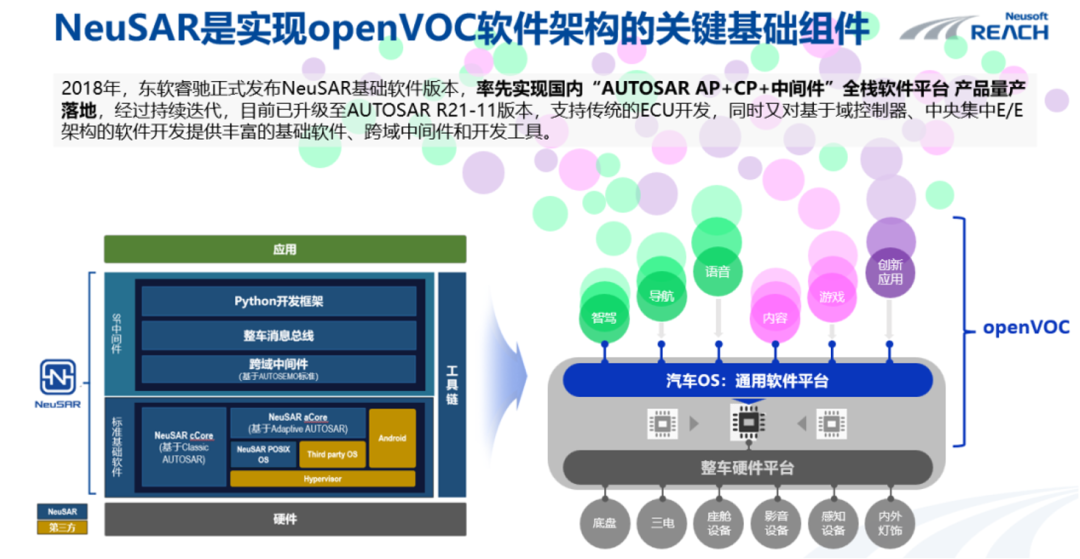
拆解软件定义汽车:OS突围
软件作为智能汽车的核心组成部分,由于自身较为独立和复杂的IT学科体系,其技术链路、产业分工、价值分配、商业模式相对硬件产品(如域控、激光雷达、摄像头等硬件)而言,在汽车产业内探讨和传播相对较少。 11月3日&…...
)
并发线程使用介绍(二)
2.2.6 线程的强占 Thread的非静态方法join方法 需要在某一个线程下去调用这个方法 如果在main线程中调用了t1.join(),那么main线程会进入到等待状态,需要等待t1线程全部执行完毕,在恢复到就绪状态等待 CPU调度。 如果在main线程中调用了t1.j…...
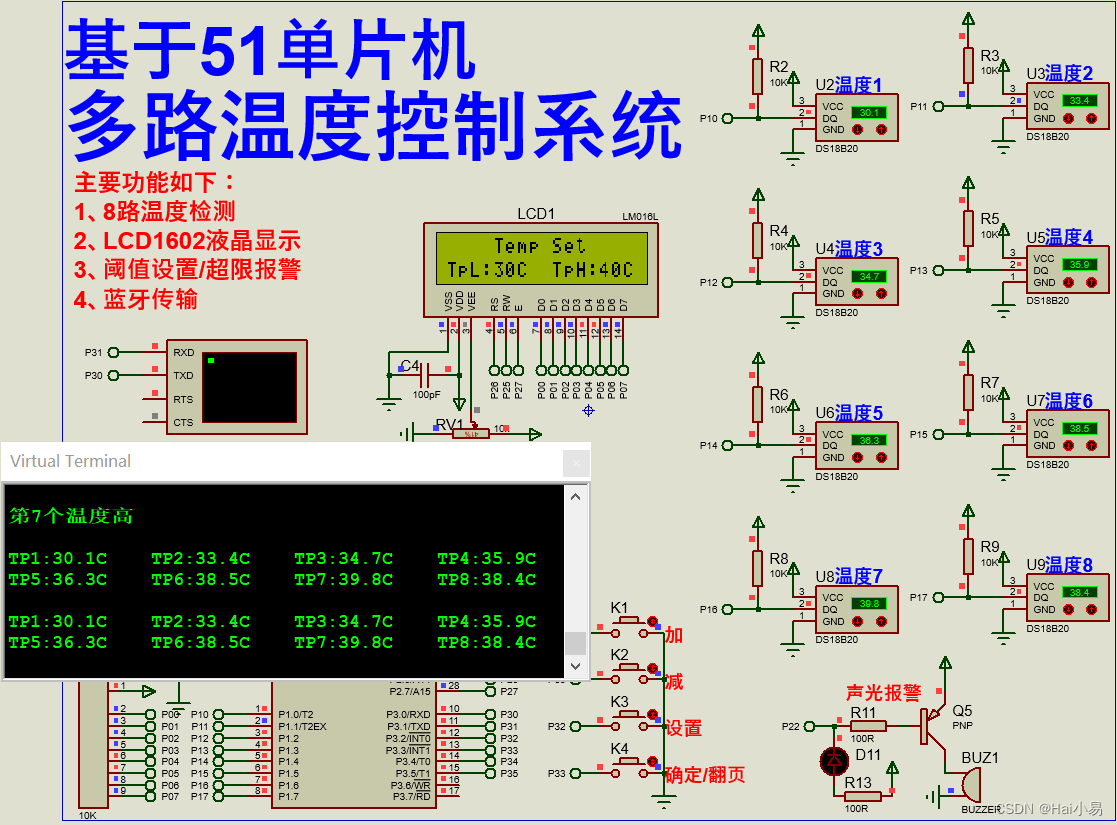
【Proteus仿真】【51单片机】多路温度控制系统
文章目录 一、功能简介二、软件设计三、实验现象联系作者 一、功能简介 本项目使用Proteus8仿真51单片机控制器,使用按键、LED、蜂鸣器、LCD1602、DS18B20温度传感器、HC05蓝牙模块等。 主要功能: 系统运行后,默认LCD1602显示前4路采集的温…...

一些可以参考的文档集合15
之前的文章集合: 一些可以参考文章集合1_xuejianxinokok的博客-CSDN博客 一些可以参考文章集合2_xuejianxinokok的博客-CSDN博客 一些可以参考的文档集合3_xuejianxinokok的博客-CSDN博客 一些可以参考的文档集合4_xuejianxinokok的博客-CSDN博客 一些可以参考的文档集合5…...
k8s的service自动发现服务:实战版
Service服务发现的必要性: 对于kubernetes整个集群来说,Pod的地址也可变的,也就是说如果一个Pod因为某些原因退出了,而由于其设置了副本数replicas大于1,那么该Pod就会在集群的任意节点重新启动,这个重新启动的Pod的I…...

身份证OCR识别接口接入实战:Python/Java/PHP/C#四语言代码示例与踩坑指南
#身份证OCR, #OCR接口, #API接入, #Python示例, #Java示例, #PHP示例, #踩坑指南, #石榴智能, #实名认证, #图片识别 身份证OCR识别接口接入实战:Python/Java/PHP/C#四语言代码示例与踩坑指南 作者:石榴智能技术团队 一、前言 身份证OCR识别已经不是什…...

C++中显示与隐式加载dll的使用与区别
一、什么是 DLL?DLL(Dynamic Link Library) 是 Windows 下的动态链接库,包含可被多个程序共享的函数、资源或类。使用 DLL 可以实现代码复用、模块化设计和插件机制。在 C 中,调用 DLL 中的函数有两种主要方式…...
)
别再乱用npm install了!手把手教你用npx only-allow为项目指定包管理器(支持pnpm/yarn/npm)
用only-allow统一团队包管理器:从配置到CI的全流程指南 你是否曾经在拉取一个新项目后,面对npm install、yarn还是pnpm i的抉择感到困惑?或者更糟的是,团队成员混用不同包管理器导致node_modules结构不一致,引发各种诡…...

诚信标签工厂端解决方案 适配俄标 CRPT 体系一体化技术方案
俄罗斯诚实标签依托 CRPT 体系执行强制管控,各类出口货品必须完成 Data Matrix 编码采集、格式转换、多层包装数据绑定,数据合规后方可通关流通。美妆食品、日化建材、玩具五金等品类包装形态差异较大,人工采集方式普遍存在识别精度不足、批量…...
)
放弃编码器!纯靠MPU6050和PID算法,手把手教你用TT马达实现平衡小车稳定控制(STM32F103C8T6实战)
纯MPU6050STM32F103的TT马达平衡车实战:无编码器PID控制全解析当大多数平衡小车方案都在强调编码器对速度反馈的不可或缺性时,我们决定挑战一个更极简的配置:仅用5美元的TT马达、9轴的MPU6050和STM32F103C8T6最小系统板,完全舍弃编…...

炉石传说自动对战助手:5分钟上手,彻底解放双手的终极指南
炉石传说自动对战助手:5分钟上手,彻底解放双手的终极指南 【免费下载链接】Hearthstone-Script Hearthstone script(炉石传说脚本) 项目地址: https://gitcode.com/gh_mirrors/he/Hearthstone-Script 还在为每天重复的炉石…...
)
ROS Noetic实战:从bag包里‘抠’出雷达点云和IMU数据的保姆级教程(Ubuntu 20.04)
ROS Noetic实战:从bag包里提取雷达点云和IMU数据的完整指南(Ubuntu 20.04)在机器人开发中,ROS bag文件就像是一个装满珍贵数据的宝箱,而雷达点云和IMU数据则是其中最闪亮的宝石。作为一名长期与ROS打交道的开发者&…...

关于psthon问题
我想问问各位 我python可以查到 但是我的bit文件查不到python怎么回事...

为Claude Code配置稳定API源并解决访问限制
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为Claude Code配置稳定API源并解决访问限制 Claude Code 作为一款强大的 AI 编程辅助工具,其原生服务在某些情况下可能…...

INT8量化下TVA注意力对齐精度保障方案
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...