数据湖架构
数据湖架构介绍
数据湖(Data Lake)是一个存储大量结构化和非结构化数据的集中式数据存储库。
与传统的数据仓库不同,数据湖采用扁平化结构,将数据存储在原始形式下,不需要进行预处理或转化。这使得数据湖能够同时支持多种分析和处理方式,包括机器学习、数据挖掘、ETL等。
以下从多个方面介绍数据湖架构:
存储层
存储层是数据湖最基本的层级,负责存储各种类型的数据,包括结构化数据、半结构化数据和非结构化数据。存储层应该采用高可用性、可伸缩性、安全性和低成本的设计原则。
常见的存储技术包括:
对象存储(如S3)
分布式文件系统(如HDFS)
NoSQL数据库(如Cassandra、HBase)
处理层
处理层负责对存储层中的数据进行处理和计算。处理层可以使用各种工具和技术,包括:
数据仓库(如Redshift、Snowflake)
Hadoop生态系统(如Hive、Pig、Spark)
流处理引擎(如Kafka Streams、Flink)
访问层
访问层提供用户对数据湖的访问和查询接口。访问层可以使用各种API或界面,包括:
SQL查询(如Athena、Presto)
API接口(如REST API、GraphQL)
数据可视化工具(如Tableau、Power BI)
安全性与隔离性
由于数据湖中存储了大量敏感信息和机密数据,因此安全性和隔离性是架构设计中不可忽略的问题。在设计数据湖时,需要考虑以下几个方面:
权限控制:采用身份验证、授权和审计等措施,确保只有授权人员才能访问敏感数据。
数据加密:对存储在数据湖中的数据进行加密处理,确保数据在传输和存储过程中不被窃取或篡改。
隔离性:将不同业务部门的数据分开存储,在物理上实现数据的隔离,以避免数据泄露和误用。
技术选型
在选择数据湖架构时,需要根据实际应用场景和需求来确定技术选型。下面介绍一些常见的技术选型:
存储技术:选择适合自己业务场景的存储技术,比如对象存储、分布式文件系统或NoSQL数据库等。
处理引擎:选择适合自己业务场景的处理引擎,比如使用Hadoop生态系统进行批处理,使用Storm或Flink进行流处理等。
访问接口:选择适合自己业务场景的访问接口,比如使用SQL查询工具、REST API或GraphQL等。
应用场景
数据湖架构在各个领域有广泛应用。以下是一些常见的应用场景:
大数据分析和决策支持
机器学习和人工智能
实时数据处理和流计算
数据搜索和发现
总之,数据湖架构是一种灵活、高效且安全的数据存储和处理方法,它能够满足当前大数据分析和人工智能等领域的需求。通过存储原始数据,数据湖能够更好地支持多种分析和处理方式,并能够帮助企业进行实时数据处理、流计算、大数据分析、机器学习和人工智能等方面的应用。在设计数据湖架构时,需要考虑存储层、处理层和访问层的设计,同时也需要考虑安全性和隔离性等问题,选择适合自己业务场景的技术选型,才能充分发挥数据湖架构的优势。
数据湖架构的其他优势
数据湖架构还有一些其他的优势:
灵活性:相比传统的数据仓库,数据湖具有更高的灵活性。数据湖不需要预处理数据,而是直接存储原始数据。这使得数据湖能够更好地支持多种分析和处理方式,并且能够适应业务需求的变化。
可扩展性:数据湖采用分布式架构,可以很容易地扩展存储和处理能力。当存储和处理需求增加时,只需要增加硬件资源即可。
开放性:数据湖架构采用开放的标准和技术,使用标准的API和协议进行访问和查询,方便与其他系统集成。
低成本:数据湖采用廉价的硬件设备和开源软件,因此具有较低的成本。同时,数据湖不需要进行预处理或转化,也能够节省数据存储和处理的成本。
总之,数据湖架构具有灵活性、可扩展性、开放性和低成本等优势,能够满足当前大数据分析和人工智能等领域的需求,并为企业提供更好的数据处理和决策支持。
除了数据湖架构的优势,还需要注意一些数据湖架构的挑战和问题:
数据湖架构的挑战与问题。
数据质量:由于数据湖存储的是原始数据,因此需要处理低质量数据、缺失数据和重复数据等问题。在设计数据湖架构时,需要考虑如何管理和清理数据,以确保数据质量。
数据集成:由于数据湖包含大量异构数据,因此需要进行数据集成和转换等工作。在设计数据湖架构时,需要考虑如何实现数据集成和转换,并确保数据无误地导入数据湖中。
数据安全性:由于数据湖中存储了大量敏感信息和机密数据,因此需要采用适当的安全措施来保护数据安全。在设计数据湖架构时,需要考虑如何控制数据访问权限和加强数据安全性等问题。
数据信任度:由于数据湖中存储的是原始数据,在使用时需要对数据进行验证和审核,以提高数据信任度和可靠性。在设计数据湖架构时,需要考虑如何实现数据审计和验证等功能。
除了挑战和问题,还有一些最佳实践需要在数据湖架构设计中考虑:
定义数据治理策略:在设计数据湖架构时,需要定义数据治理策略和流程,包括数据质量、数据规范、审计和验证等。这有助于确保数据湖中的数据是准确、可信和合规的。
采用元数据管理工具:元数据是描述数据的数据,它可以提供关于数据来源、格式、结构和质量等信息。在设计数据湖架构时,需要考虑如何管理元数据,并选择适当的元数据管理工具来管理元数据。
使用云服务提供商:云服务提供商可以提供高效、灵活、安全和经济的存储和处理服务。因此,在设计数据湖架构时,可以考虑使用云服务提供商来搭建数据湖。
采用自动化工具:数据湖中的数据量很大,对数据的管理和维护需要大量的人力和时间。因此,在设计数据湖架构时,可以考虑采用自动化工具来管理、清理和审核数据。
需要注意的是,在设计数据湖架构时需要遵循一些基本原则和最佳实践,包括:
采用标准化格式:在数据湖中存储数据时,应该采用标准化的格式(如Parquet、ORC等),以便于不同的处理引擎进行处理和分析。
保持数据的可追溯性:数据湖中的数据通常经过多次修改和处理,因此需要保证每一步操作都可以被追溯。为了实现数据的可追溯性,需要采用元数据管理工具和数据审计机制等措施。
实现数据访问控制:数据湖中存储了大量敏感数据,因此需要实现严格的数据访问控制。在设计数据湖架构时,需要考虑如何实现身份验证、授权和审计等功能。
规划数据增量更新策略:数据湖中的数据通常是不断增加的,因此需要规划数据增量更新策略。在设计数据湖架构时,需要考虑如何实现数据的增量更新,并确保增量更新不会影响到已有的数据。
在实施数据湖架构之前,还需要进行一些准备工作:
明确需求和目标:在实施数据湖架构之前,需要明确业务需求和目标。这有助于选择适当的技术选型,并确保数据湖架构能够满足业务需求。
准备计划和资源:实施数据湖架构需要一定的人力、物力和财力资源。在实施之前,需要制定详细的计划和预算,并准备好相关资源。
确定数据来源和格式:数据湖中存储了大量原始数据,因此需要确定数据来源和格式。在实施数据湖架构之前,需要对数据进行分类、清理、转换和集成等处理过程,以确保数据质量和可用性。
选择适当的技术:数据湖架构包括存储层、处理层和访问层,需要选择适当的技术进行搭建。在选择技术时,需要考虑技术成熟度、可扩展性、安全性和可靠性等方面。
除了上述准备工作,还需要注意以下问题:
技术选型:数据湖架构中涉及到多种技术和工具,需要根据实际需求来选择适合自己业务场景的技术选型。在选择技术时,需要考虑技术成熟度、可扩展性、安全性和可靠性等方面。
管理和维护:数据湖中存储了大量数据,因此需要进行管理和维护。在实施数据湖架构之前,需要制定详细的管理和维护计划,并分配相应的人力资源。
安全措施:由于数据湖中存储了大量敏感数据,因此需要采取适当的安全措施来保障数据安全。在实施数据湖架构之前,需要考虑如何实现数据访问控制、数据加密和身份验证等安全功能。
综上所述,在实施数据湖架构之前,需要做好充分的准备工作,并注意技术选型、管理和维护、安全措施等问题。只有通过合理的规划和实施,才能够建立高效、灵活、安全和可靠的数据湖架构。
亚马逊为例简述智能湖仓的运用
亚马逊是全球最大的在线零售商之一,同时也是云计算领域的领先厂商之一。亚马逊在数据湖架构的应用方面拥有丰富的经验,其中智能数据湖Lake Formation则是亚马逊的新型服务,它提供了快速建设数据湖的工具和功能。下面简述一下亚马逊智能数据湖Lake Formation的运用:
Lake Formation可以通过视觉化的界面来帮助用户快速创建和管理数据湖,包括添加数据源、定义表结构、配置数据访问权限等。
Lake Formation提供了灵活的权限管理机制,可以对不同用户和组织授权不同级别的访问权限,从而保证数据安全性和隐私性。
Lake Formation集成了AWS Glue数据目录,可以根据元数据信息来搜索和查询数据,从而帮助用户更有效地分析数据。
Lake Formation采用AWS Identity and Access Management(IAM)服务进行身份验证和授权,可以确保数据的安全性和可靠性。
除了Lake Formation,亚马逊AWS还提供了多种数据湖相关的服务和工具,包括:
Amazon S3:Amazon S3是一种高度可扩展、可靠和经济的云存储服务,可以用于搭建数据湖的存储层。Amazon S3支持多种文件格式,包括Parquet、ORC、Avro等,并提供了各种功能以管理和保护数据。
AWS Glue:AWS Glue是一种完全托管的ETL(Extract, Transform, Load)服务,可以用于数据的转换和集成。AWS Glue可以根据元数据信息来自动发现关系型数据库、NoSQL数据库和文件系统中的数据,并将其转换为目标格式。
Amazon Athena:Amazon Athena是一种交互式查询服务,可以在S3上执行SQL查询。用户可以使用标准SQL语言进行查询,而无需进行任何复杂的数据转换和加载操作。
Amazon RedShift:Amazon Redshift是一种快速、可扩展、完全托管的数据仓库服务,可以用于数据的存储和分析。与其他数据仓库不同,Amazon Redshift可以与数据湖直接集成,从而实现更高效的数据处理和分析。
在亚马逊AWS的数据湖架构中,最重要的是S3和Glue。S3作为存储层,提供了高可靠性、高可扩展性和多种文件格式支持等功能,可以方便地存储海量的原始数据。而Glue作为处理层,则提供了ETL服务,可以将原始数据转换为目标格式,并自动创建表结构和元数据信息。此外,Glue还具有高度的灵活性和可扩展性,可以满足不同用户的需求。
在使用S3和Glue构建数据湖时,需要注意以下几点:
确定数据源和格式:在使用S3和Glue构建数据湖之前,需要确定数据源和格式。不同的数据源和格式需要采用不同的ETL策略和工具来进行转换和集成。
规划数据治理策略:数据湖中存储了大量敏感数据,因此需要规划数据治理策略,包括数据质量、数据规范、审计和验证等措施。
设计数据访问控制:数据湖中存储了大量敏感数据,因此需要设计严格的访问控制机制,确保只有授权的人员能够访问数据。
选择合适的技术:在使用S3和Glue构建数据湖时,需要选择合适的技术。例如,在使用Glue进行ETL时,需要选择适合自己业务场景的ETL工具和策略,以确保数据质量和可用性。
此外,在使用亚马逊AWS构建数据湖时,还需要考虑以下一些关键问题:
数据格式转换:在进行数据湖的搭建过程中,通常需要将原始数据转换为目标格式,以方便后续的处理和分析。在进行数据格式转换时,需要确保数据质量和可用性,并选择合适的ETL工具和策略。
元数据管理:元数据是数据湖中不可或缺的组成部分,它可以帮助用户快速搜索、查询和访问数据。在构建数据湖时,需要规划元数据信息的管理和维护,包括元数据的创建、更新、删除和查询等操作。
安全措施:数据湖中存储了大量敏感数据,因此需要采取适当的安全措施来保障数据安全。在使用亚马逊AWS构建数据湖时,需要考虑如何实现数据访问控制、数据加密和身份验证等安全功能。
数据访问和分析:数据湖主要用于存储和管理数据,而对于数据的访问和分析,则需要使用相应的工具和服务。在使用亚马逊AWS构建数据湖时,需要考虑如何选择适当的工具和服务进行数据的访问和分析。
成本控制:使用亚马逊AWS构建数据湖需要付出一定的成本,因此需要对成本进行合理的控制。在进行数据湖搭建时,可以选择按需支付或预留实例等计费方式来降低成本。
参除了上述问题,使用亚马逊AWS构建数据湖还需要注意以下几点:
处理海量数据:数据湖中存储了大量的原始数据,因此在搭建数据湖时需要考虑如何处理海量数据。亚马逊AWS提供了高度扩展性和可靠性的服务,可以帮助用户处理海量数据。
保证数据质量:数据湖中存储了大量的原始数据,因此需要进行数据清洗、去重和规范化等操作,以确保数据质量和可用性。亚马逊AWS提供了多种工具和服务,可以帮助用户实现数据清洗和规范化等操作。
构建分层架构:为了更好地管理和分析数据,可以采用分层架构来组织数据湖。分层架构包括原始数据层、加工层、应用层等。通过这样的架构,可以更好地管理和利用数据湖中的数据。
设计数据治理策略:数据湖中存储了大量敏感数据,因此需要设计严格的数据治理策略,包括数据安全、数据隐私和数据合规等方面的措施。亚马逊AWS提供了多种数据安全和隐私保护的服务和工具,可以帮助用户实现数据治理策略。
选择合适的解决方案:亚马逊AWS提供了多种数据湖架构的解决方案,包括QuickSight、EMR、Kinesis等。在选择解决方案时,需要根据实际需求和场景进行选择,以确保数据湖能够满足业务需求。
综上所述,在使用亚马逊AWS构建数据湖时,需要注意如何处理海量数据、保证数据质量、构建分层架构、设计数据治理策略和选择合适的解决方案等问题。只有通过充分考虑这些问题,并灵活运用亚马逊AWS提供的服务和工具,才能够建立高效、灵活、安全和可靠的数据湖架构,并实现大数据分析和人工智能等方面的应用场景。
参考文献:
《Data Lake Architecture: Designing the Data Lake and Avoiding the Garbage Dump》
《Building a Modern Data Warehouse on AWS》
《Intelligent Data Lake: A New Era for Big Data》
相关文章:

数据湖架构
数据湖架构介绍 数据湖(Data Lake)是一个存储大量结构化和非结构化数据的集中式数据存储库。 与传统的数据仓库不同,数据湖采用扁平化结构,将数据存储在原始形式下,不需要进行预处理或转化。这使得数据湖能够同时支持…...
Zabbix 5.0部署(centos7+server+MySQL+Apache)
环境 系统IPZABBIX版本主机名centos7192.168.231.2195.0zabbix-server 安装zabbix 我选择版本是zabbix-5.0 zabbix的官网是Zabbix :: The Enterprise-Class Open Source Network Monitoring Solution 安装Zabbix软件源 rpm -Uvh https://repo.zabbix.com/zabbix/5.0/rhel/7/…...
YOLO改进系列之注意力机制(CloAttention模型介绍)
CloAttention来自清华大学的团队提出的一篇论文CloFormer,作者从频域编码的角度认为现有的轻量级视觉Transformer中,大多数方法都只关注设计稀疏注意力,来有效地处理低频全局信息,而使用相对简单的方法处理高频局部信息。很少有方…...
)
openssl+AES开发实例(linux)
文章目录 一、AES介绍二、AES原理三、AES开发实例 一、AES介绍 AES(Advanced Encryption Standard)是一种对称密钥加密标准,它是一种对称加密算法,意味着相同的密钥用于加密和解密数据。AES 是 NIST(美国国家标准与技…...

FreeRTOS源码阅读笔记3--queue.c
消息队列可以应用于发送不定长消息的场合,包括任务与任务间的消息交换,队列是 FreeRTOS 主要的任务间通讯方式,可以在任务与任务间、中断和任务间传送信息,发送到 队列的消息是通过拷贝方式实现的,这意味着队列存储…...

云原生Kubernetes系列 | 通过容器互联搭建wordpress博客系统
云原生Kubernetes系列 | 通过容器互联搭建wordpress博客系统 通过容器互联搭建一个wordpress博客系统。wordpress系统是需要连接到数据库上的,所以wordpress和mysql的镜像都是需要的。wordpress在创建过程中需要指定一些参数。创建mysql容器时需要把mysql的数据保存在宿主机本…...

java读取OPC DA数据---Utgard
java读取OPC DA数据—Utgard Utgard库已经过时,原作者早已删除库,建议使用OPC UA,兼容OPC DA。 下面讲解Utgard使用 C#和C都不用配置DCOM,直接调用函数 既然是非要用Java,那就别想太方便,需要配置DCOM(后…...

在 Android 上简单安全地登录——使用凭证管理器和密钥
我踏马很高兴地听说, Credential Manager的公开版本将于 11 月 1 日开始提供。Credential Manager 为 Android 带来了身份验证的未来,简化了用户登录应用程序和网站的方式,同时使其更加安全。 登录可能具有挑战性 - 密码经常使用,…...
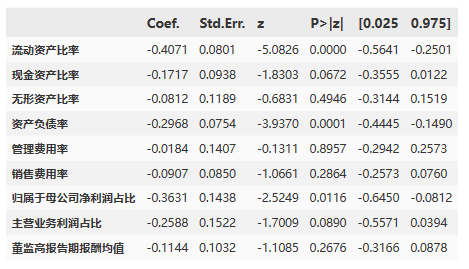
【Python】上市公司数据进行经典OLS回归实操
一、题目二、数据合并、清洗、描述性统计1、数据获取2、数据合并3、选择董监高薪酬作为解释变量的理论逻辑分析 三、多元回归模型的参数估计、结果展示与分析1、描述性统计分析2、剔除金融类上市公司3、对所有变量进行1%缩尾处理4、0-1标准化,所有解释变量5、绘制热…...
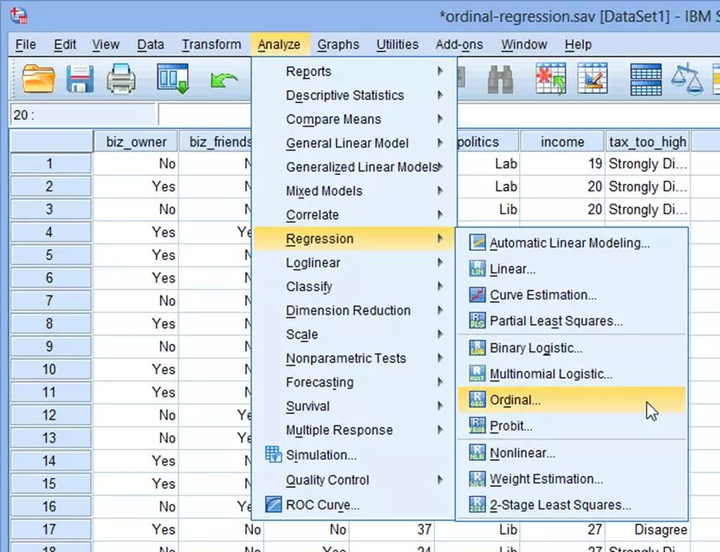
科研学习|科研软件——有序多分类Logistic回归的SPSS教程!
一、问题与数据 研究者想调查人们对“本国税收过高”的赞同程度:Strongly Disagree——非常不同意,用“0”表示;Disagree——不同意,用“1”表示;Agree--同意,用“2”表示;Strongly Agree--非常…...
微服务简单理解与快速搭建
分布式和微服务 含义 微服务架构 微服务架构风格是一种将一个单一应用程序开发为一组小型服务的方法,每个服务运行在自己的进程中,服务间通信采用轻量级通信机制(通常用HTTP资源API)。这些服务围绕业务能力构建并且可通过全自动部署机制独立部署。这些服…...

QColorDialog开发实例
文章目录 一、QColorDialog基本用法:二、QColorDialog详解三、QColorDialog接口说明静态函数成员函数 四、QColorDialog代码开发实例 QColorDialog 是 Qt 框架中用于选择颜色的对话框类。它提供了一个用户友好的界面,允许用户选择颜色。以下是 QColorDi…...

linux实现全局快捷键
文章目录 第一步:加载KF5GlobalAccel库第二步:代码实现2.1 定义一个QAction2.2 KGlobalAccel::self()注册快捷键3 源码地址有一个需求,就是在应用在后台运行时,用户可以通过快捷键将应用唤起。或者应用响应。 其实就是全局快捷键的功能。 这个功能利用了linux操作系统中的d…...

共享台球室小程序系统:智能化预约与管理
在当今数字化的时代,共享经济模式已经渗透到各个领域。其中,共享台球室作为一个结合了传统与现代元素的项目,越来越受到年轻人的喜爱。为了满足市场需求,我们设计了一款基于微信小程序的共享台球室预约与管理系统,通过…...
百度文心一言
1分钟了解一言是谁? 一句话介绍【文心一言】 我是百度研发的人工智能模型,任何人都可以通过输入【指令】和我进行互动,对我提出问题或要求,我能高效地帮助你们获取信息、知识和灵感哦 什么是指令?我该怎么和你互动&am…...

225.用队列实现栈(LeetCode)
思路 思路:用两个队列实现栈后进先出的特性 ,两个队列为空时,先将数据都导向其中一个队列。 当要模拟出栈时,将前面的元素都导入另一个空队列,再将最后一个元素移出队列 实现 实现: 因为C语言没有库可以…...
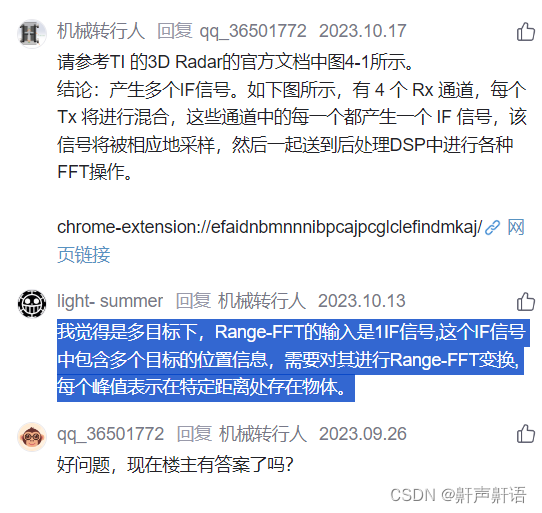
汽车FMCW毫米波雷达信号处理流程(推荐---基础详细---清楚的讲解了雷达的过程---强烈推荐)
毫米波雷达在进行多目标检测时,TX发射一个Chirp,在不同距离下RX会接收到多个反射Chirp信号(仅以单个chirp为例)。 雷达通过接收不同物体的发射信号,并转为IF信号,利用傅里叶变换将产生一个具有不同的分离峰值的频谱,每个峰值表示在特定距离处存在物体。 请问,这种多目标…...
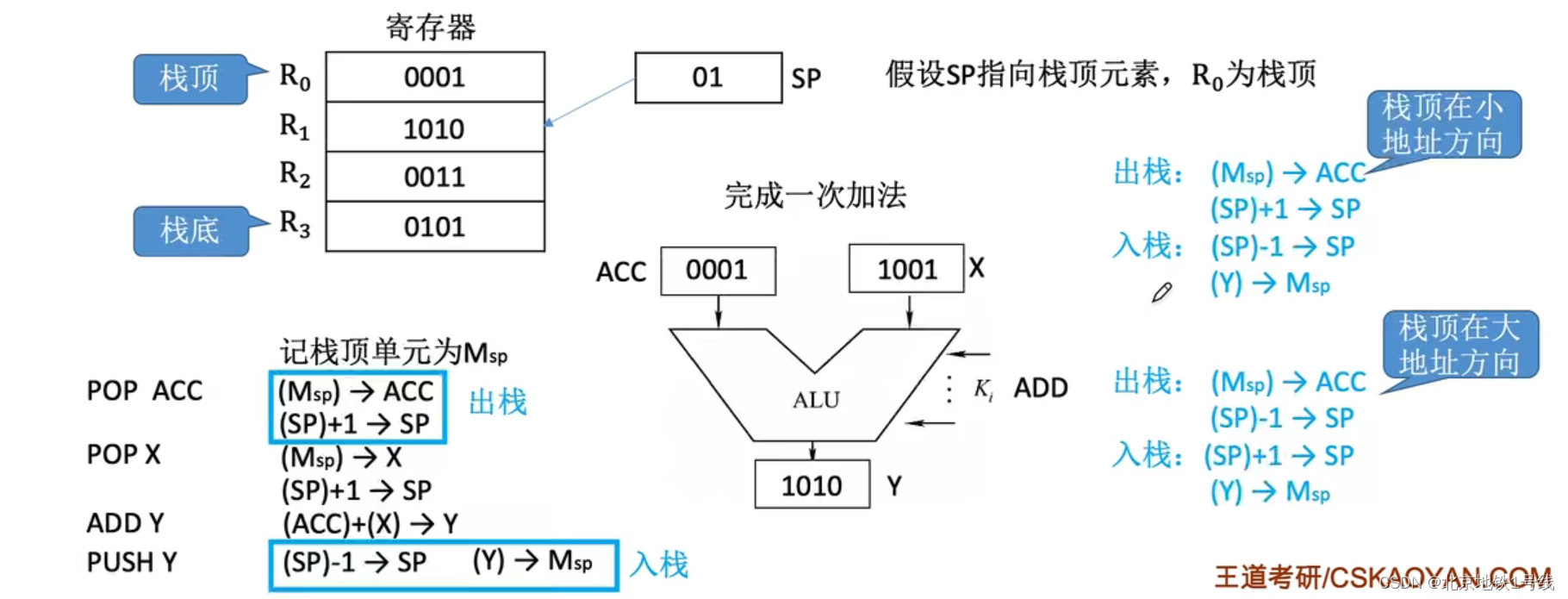
8.指令格式,指令的寻址方式
目录 一. 指令格式 二. 扩展操作码 三. 指令寻址 (1)指令寻址 (2)数据寻址 1.直接寻址 2.间接寻址 3.寄存器寻址 4.寄存器间接寻址 5.隐含寻址 6.立即寻址 7.基址寻址 8.变址寻址 9.相对寻址 10.堆栈寻址 一. 指令…...
k8s自定义Endpoint实现内部pod访问外部应用
自定义endpoint实现内部pod访问外部应用 endpoint除了可以暴露pod的IP和端口还可以代理到外部的ip和端口 使用场景 公司业务还还没有完成上云, 一部分云原生的,一部分是实体的 业务上云期间逐步实现上云,保证各个模块之间的解耦性 比如使…...
)
[100天算法】-分割等和子集(day 78)
题目描述 给定一个只包含正整数的非空数组。是否可以将这个数组分割成两个子集,使得两个子集的元素和相等。注意:每个数组中的元素不会超过 100 数组的大小不会超过 200 示例 1:输入: [1, 5, 11, 5]输出: true解释: 数组可以分割成 [1, 5, 5] 和 [11].示例 2:输入:…...

Obsidian PDF++:如何在Obsidian中实现PDF与笔记的无缝双向链接?
Obsidian PDF:如何在Obsidian中实现PDF与笔记的无缝双向链接? 【免费下载链接】obsidian-pdf-plus PDF: the most Obsidian-native PDF annotation & viewing tool ever. Comes with optional Vim keybindings. 项目地址: https://gitcode.com/gh_…...

Blender渲染通道完全指南:如何像电影后期一样,分离出深度、阴影与反射图
Blender渲染通道完全指南:影视级后期制作的深度解析在数字内容创作领域,Blender已经从一个简单的3D建模工具成长为能够处理复杂视觉特效的全流程解决方案。对于追求影视级质量的中高级用户而言,掌握渲染通道技术是提升作品专业度的关键一步。…...

【CP-05】RTE运行时环境 - SWC的操作系统接口
CP-05_RTE运行时环境【CP-05】RTE运行时环境 - SWC的“操作系统接口”前言在AUTOSAR架构中,RTE(Runtime Environment,运行时环境)是一个常被提及却难以理解的概念。它像是应用层软件组件(SW-C)与底层基础软…...

金融合规审核为何人力堆积却仍漏洞百出?2026年RegTech演进与Agent全链路闭环解决方案
在2026年的金融监管环境下,合规审核已不再是简单的“查漏补缺”,而是演变为一场高强度的算力与逻辑博弈。尽管金融机构在合规成本上的投入逐年攀升,甚至不惜以“人海战术”填补流程断点,但监管罚单的数额与频率却并未显著下降。这…...

如何进行TVA仿真引擎的“光照地狱”训练?
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...

自制极低频电流探头:负电阻补偿原理与低频方波测量实践
1. 项目概述:为极低频电流测量而生在电子测试领域,电流探头是个再常见不过的工具,无论是排查开关电源的纹波,还是分析电机驱动的波形,都离不开它。但如果你尝试用市面上常见的电流探头去观察一个频率低至几赫兹&#x…...

基于ESP32与MQTT的家庭环境监测系统:从传感器选型到数据可视化实战
1. 项目概述与核心价值最近几年,我身边越来越多的朋友开始关注家里的空气质量、温湿度这些看不见摸不着,但又实实在在影响生活舒适度和健康的环境指标。从新装修的房子担心甲醛,到有老人小孩的家庭在意PM2.5和二氧化碳浓度,再到南…...
原理与ScalableHD架构优化实践)
超维计算(HDC)原理与ScalableHD架构优化实践
1. 超维计算(HDC)基础解析超维计算(Hyperdimensional Computing, HDC)是一种受大脑信息处理机制启发的计算范式,其核心思想是用高维随机向量(通常称为超向量或HV)来表示和处理信息。与传统神经网…...
)
大模型测试新范式:Claude端到端验证的5层断言体系(语义一致性/上下文连贯性/安全边界/成本阈值/时序鲁棒性)
更多请点击: https://codechina.net 第一章:大模型测试新范式:Claude端到端验证的5层断言体系(语义一致性/上下文连贯性/安全边界/成本阈值/时序鲁棒性) 传统LLM测试常聚焦于准确率或BLEU等静态指标,而Cla…...

UnityExplorer:如何在游戏运行时实时调试和修改Unity项目
UnityExplorer:如何在游戏运行时实时调试和修改Unity项目 【免费下载链接】UnityExplorer An in-game UI for exploring, debugging and modifying IL2CPP and Mono Unity games. 项目地址: https://gitcode.com/gh_mirrors/un/UnityExplorer UnityExplorer是…...