大数据开发面试(一)
1、Kafka 和 Flume 的应用场景?
Kafka 和 Flume 的应用场景如下:
-
Kafka:定位消息队列,适用于多个生产者和消费者共享一个主题队列的场景。适用于需要高吞吐量、可扩展性和容错能力的场景。主要用于大数据处理、实时数据流分析和日志收集等场景。
-
Flume:定位数据传输,主要用于将数据从源头传输到目标存储系统。适用于需要将大量数据发送到 HDFS、HBase 等存储系统的场景。具有较强的可靠性、可扩展性和集成 Hadoop 安全特性的特点。
总之,Kafka 更适合用于消息处理和实时数据流分析场景,而 Flume 更适合用于大数据传输和数据存储场景。根据实际需求选择合适的技术。
2、LightGBM和XGBoost的使用场景有什么不一样?
LightGBM和XGBoost都是梯度提升框架,但它们的使用场景有所不同。
XGBoost在处理数据时,采用level-wise的分裂策略,对每一层所有节点进行无差别分裂,这可能导致一些节点的增益非常小,对结果影响不大,但XGBoost也会进行分裂,带来不必要的开销。因此,XGBoost更适用于处理大规模数据集,尤其是那些需要复杂计算和内存占用量较大的情况。
LightGBM则采用了leaf-wise的分裂策略,在当前所有叶子节点中选择分裂收益最大的节点进行分裂,这种策略更容易陷入过拟合,因此需要限制最大深度以避免过拟合。然而,LightGBM的优势在于其更快的训练速度和更好的数据处理能力。它通过采用基于直方图的方法进行特征离散化和数据划分,显著减少了计算复杂度和内存占用。当处理大规模数据集时,这种优势尤其明显。此外,当数据集存在大量的稀疏特征时,LightGBM可以更好地处理,因为它使用了稀疏特征优化算法。因此,LightGBM更适合处理大规模稀疏数据集和高维稀疏数据处理。
综上所述,LightGBM和XGBoost各有其优点和使用场景。XGBoost更适合处理大规模数据集,而LightGBM则更适合处理大规模稀疏数据集和高维稀疏数据处理。在实际应用中,用户可以根据自己的数据特点选择合适的模型。
3、做ETL的时候遇到数据倾斜怎么处理?小文件呢?
数据倾斜是指在ETL(Extract-Transform-Load)过程中,数据分布不均匀,导致某些节点处理数据量过大,而其他节点处理数据量较小的情况。处理数据倾斜的方法主要有以下几种:
-
采样:对于倾斜的数据集进行采样,使得数据集分布更加均匀。
-
数据分区:将数据按照某个字段进行分区,从而减少每个分区的数据量,减轻数据处理压力。
-
增加资源:为处理倾斜数据的节点增加资源,如CPU、内存等,以提高数据处理速度。
-
使用分布式计算框架:使用分布式计算框架,如Spark、Hadoop等,将数据处理任务分配到多个节点上,提高数据处理效率。
-
数据预处理:在ETL之前,对数据进行预处理,如数据清洗、数据合并等,减少数据倾斜的发生。
-
使用专用算法:针对数据倾斜的问题,可以尝试使用一些专用算法,如MapReduce、Spark等,提高数据处理效率。
-
调整参数:调整ETL过程中的参数,如并发度、缓冲区大小等,以提高数据处理效率。
在做ETL(Extract-Transform-Load,数据提取、转换和加载)时,如果出现大量小文件,可以考虑以下几种处理方法:
-
合并小文件:使用Linux命令(如
cat、grep、awk等)或Python脚本将小文件合并成一个或多个大文件。 -
压缩小文件:使用压缩工具(如
gzip、bzip2等)将小文件压缩成一个或多个压缩文件。 -
使用分布式文件系统:使用Hadoop、Spark等分布式文件系统来处理大量小文件,提高处理效率。
-
优化数据处理流程:调整ETL流程,减少产生小文件的情况,例如在数据提取阶段就尽量减少小文件的产生。
-
使用专门的ETL工具:使用专门针对大量小文件的ETL工具,如
Apache NiFi、Talend等。
需要注意的是,具体处理方法需要根据实际需求和场景进行选择和调整。
4、已知成绩表和学生表,查询各科成绩前三名的记录?排序相关的窗口函数除了rank还有什么?
假设成绩表名为score_table,学生表名为student_table,学生表中有student_id,姓名,科目,成绩等字段,成绩表中有score_id,student_id,科目,成绩等字段。
SQL查询各科成绩前三名的记录可以这样写:
SELECTstudent_table.student_id,student_table.姓名,score_table.科目,score_table.成绩
FROMscore_table
INNER JOINstudent_table
ONscore_table.student_id = student_table.student_id
ORDER BYscore_table.成绩DESC
LIMIT3;
这个查询首先通过JOIN连接成绩表和学生表,然后按照成绩降序排序,最后取出前三名的记录。
排序相关的窗口函数除了rank,还有dense_rank、percent_rank、ntile、row_number等。这些函数都可以在窗口函数中用来对数据进行排序和分组。
5、Hive SQL优化性能的原则是什么?
Hive SQL优化性能的原则主要包括以下几点:
-
选择适当的数据存储格式:根据数据的特点和查询需求,选择适合的存储格式(如Parquet、ORC等),以提高查询性能。
-
索引和分区:在合适的列上创建索引和分区,以便快速过滤和查找数据。
-
查询优化:使用
MapJoin、ReduceJoin、Filter等查询优化技术,减少数据传输和计算量。 -
分桶和聚合:在需要统计或聚合的列上使用分桶,提高数据处理的效率。
-
数据压缩:对数据进行压缩,降低存储和传输成本。
-
参数化查询:使用参数化查询,避免重复计算相同的查询。
-
查询计划:分析查询计划,找出性能瓶颈,并进行相应的优化。
-
数据仓库和数据湖:根据业务需求,合理划分数据仓库和数据湖,实现数据的有序存储和管理。
-
异构计算:利用多核CPU、GPU等硬件资源,提高计算性能。
-
监控和调优:定期监控Hive SQL的性能,根据监控结果进行调优。
相关文章:
)
大数据开发面试(一)
1、Kafka 和 Flume 的应用场景? Kafka 和 Flume 的应用场景如下: Kafka:定位消息队列,适用于多个生产者和消费者共享一个主题队列的场景。适用于需要高吞吐量、可扩展性和容错能力的场景。主要用于大数据处理、实时数据流分析和日…...
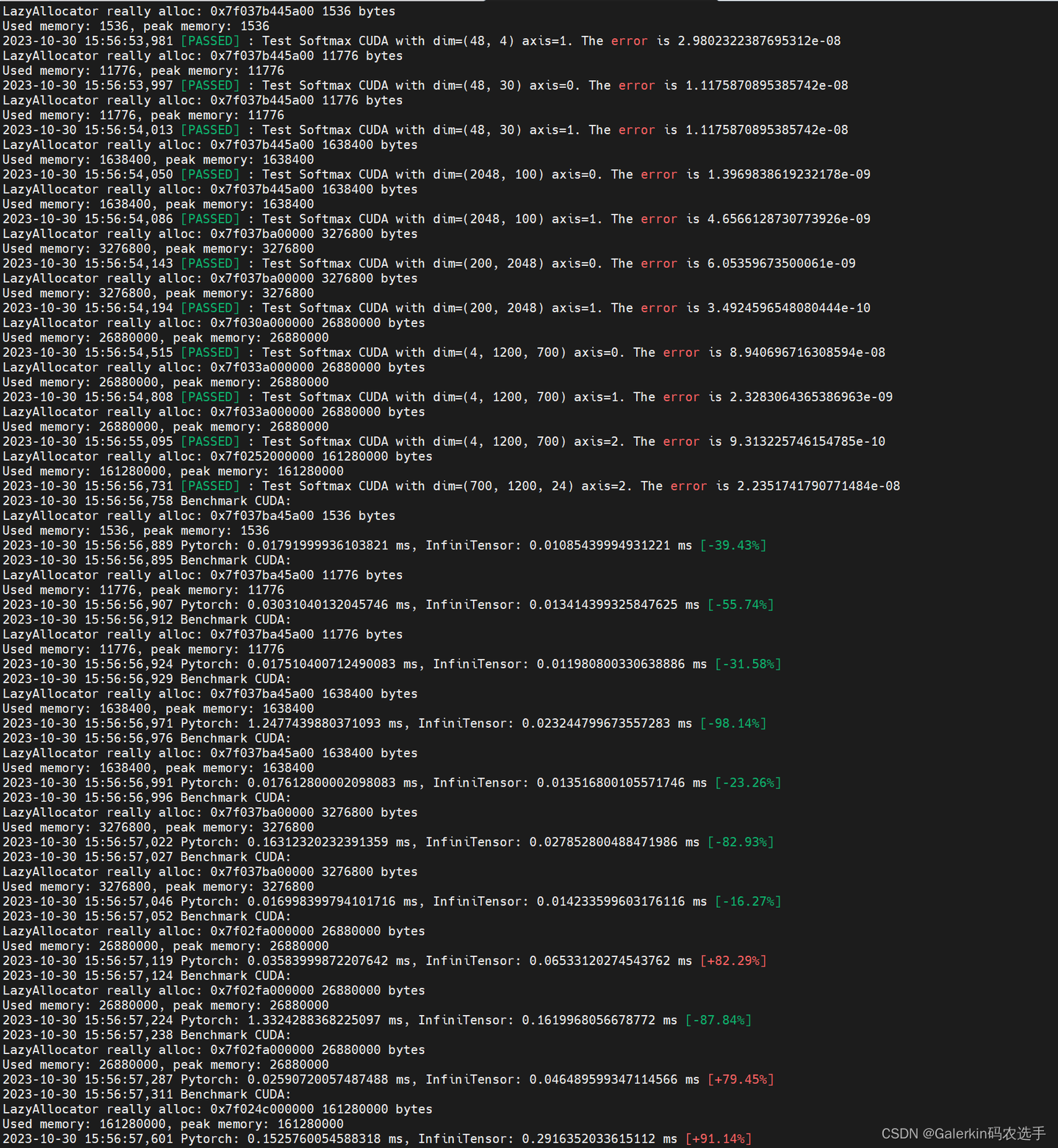
softmax的高效CUDA编程和oneflow实现初步解析
本文参考了添加链接描述,其中oneflow实现softmax的CUDA编程源代码参考链接添加链接描述 关于softmax的解读以及CUDA代码实现可以参考本人之前编写的几篇文章添加链接描述,添加链接描述,添加链接描述 下面这个图片是之前本人实现的softmax.cu经过接入python接口,最终和pytor…...

如何解决 Node.js 20 升级中未预期的请求问题
在 Tubi,我们使用 Node.js 为 Web/OTT 应用进行服务端渲染及代理请求。近来,为了从新版本的性能改进和新功能中受益,我们将 Node.js 从 14.x 版本升级到了 20.x。 升级像 Node.js 这样的基础设施绝非易事,尤其是有着许多第三方依…...

no tests were found
将带有Test的方法返回类型设为void...

泛型擦除是什么
//在编译阶段使用泛型,运行阶段取消泛型,就是擦除. //因为泛型其实只是在编译器中实现的而虚拟机并不认识泛型类项,所以要在虚拟机中将泛型类型进行擦除, //擦除是将泛型以其父类代替,如String变成了object等. //在使用的时候还是进行带强制类型转化,只不过这是比较安全的转换,…...

7、线性数据结构-切片
切片slice 容器容量可变,所以长度不能定死长度可变,元素个数可变底层必须依赖数组,可以理解它依赖于顺序表,表现也像个可变容量和长度顺序表引用类型,和值类型有区别 定义切片 var s1 []int //长度、容量为0的切片&…...
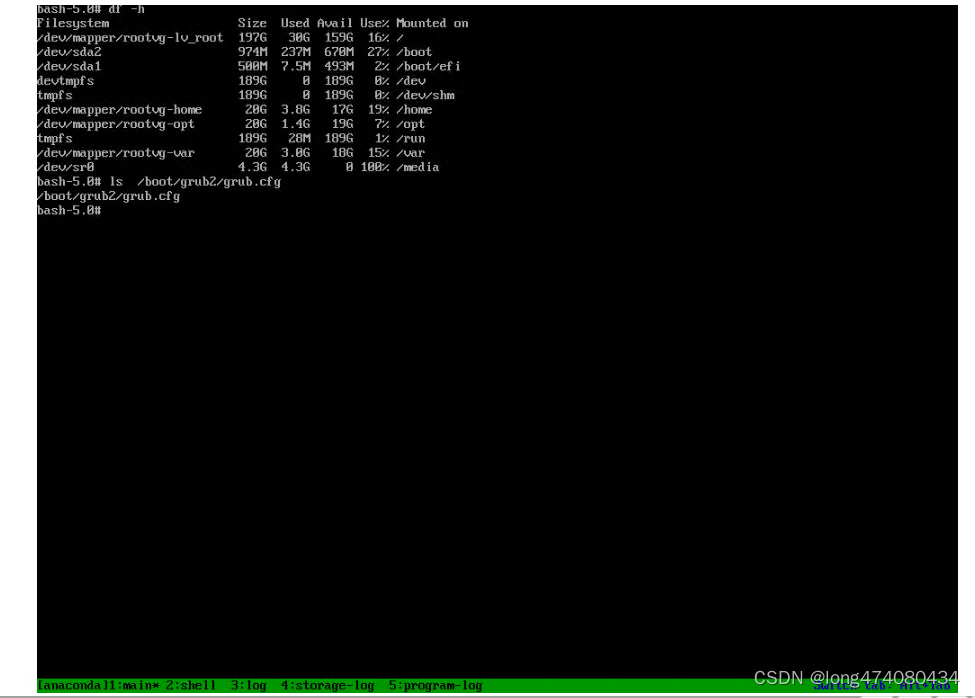
linux grub2 不引导修复 grub2-install:error:/usr/lib/grub/x86_64-efi/modinfo.sh
系统部署在物理机上,开机后一直pxe不进系统,怀疑GRUB丢失。 查看bios 里 采用uefi 启动方式, 无硬盘系统引导选项, 且BMC设置为硬盘永久启动也无效。 挂载光驱ISO进入救援模式,sda为系统盘,重装grub报错 grub2-inst…...

建筑楼宇智慧能源管理系统,轻松解决能源管理问题
随着科技的进步与人们节能减排意识的不断增强,建筑楼宇是当下节能减排的重要工具。通过能源管理平台解决能效管理、降低用能成本、一体化管控、精细化管理和服务提供有力支撑。 建筑楼宇智慧能源管理系统是一种利用先进手段,采用微服务架构,…...

【洛谷算法题】P5711-闰年判断【入门2分支结构】
👨💻博客主页:花无缺 欢迎 点赞👍 收藏⭐ 留言📝 加关注✅! 本文由 花无缺 原创 收录于专栏 【洛谷算法题】 文章目录 【洛谷算法题】P5711-闰年判断【入门2分支结构】🌏题目描述🌏输入格式&a…...
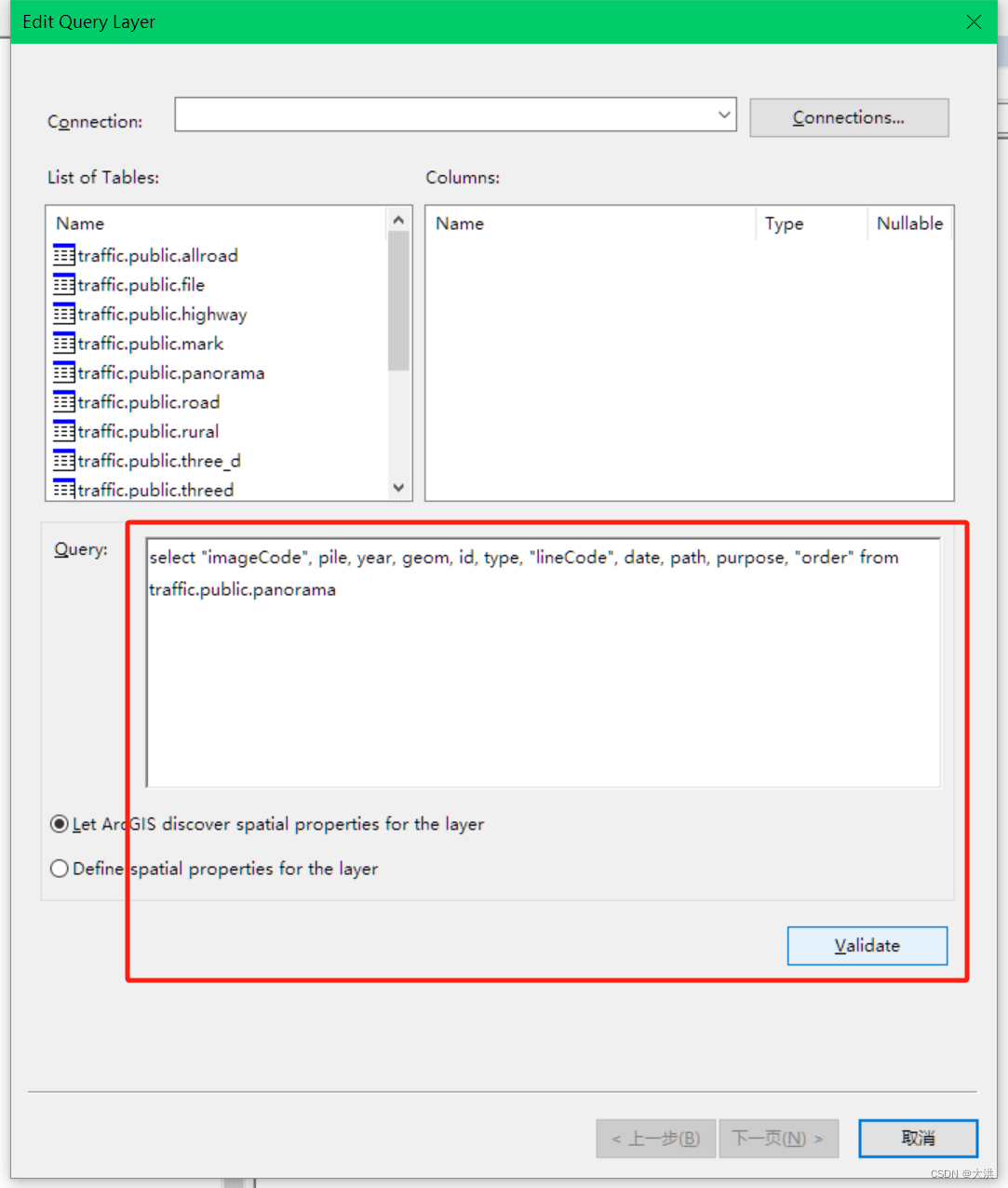
ArcGIS10.8 连接 PostgreSQL 及遇到的两个问题
前提 以前同事用过我的电脑连PostgreSQL,失败了。当时不知道原因,只能使用GeoServer来发布数据了。现在终于搞明白了,原因是ArcGIS10.2版本太老,无法连接PostgreSQL9.4。参考这里 为了适应时代的发展,那我就用新的Ar…...
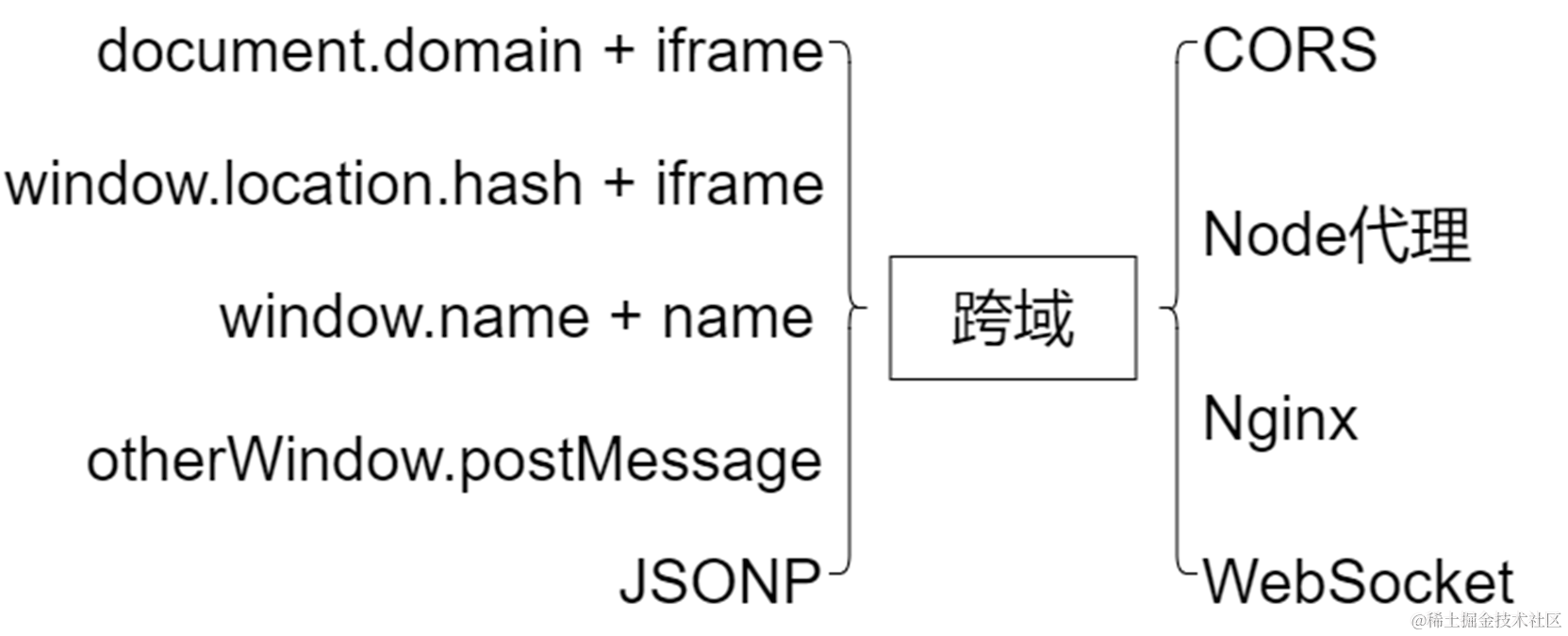
深入跨域 - 从初识到入门 | 京东物流技术团队
前言 跨域这两个字就像一块狗皮膏药一样黏在每一个前端开发者身上,无论你在工作上或者面试中无可避免会遇到这个问题。如果在网上搜索跨域问题,会出现许许多多方案,这些方案有好有坏,但是对于阐述跨域的原理和在什么情况下需要用…...
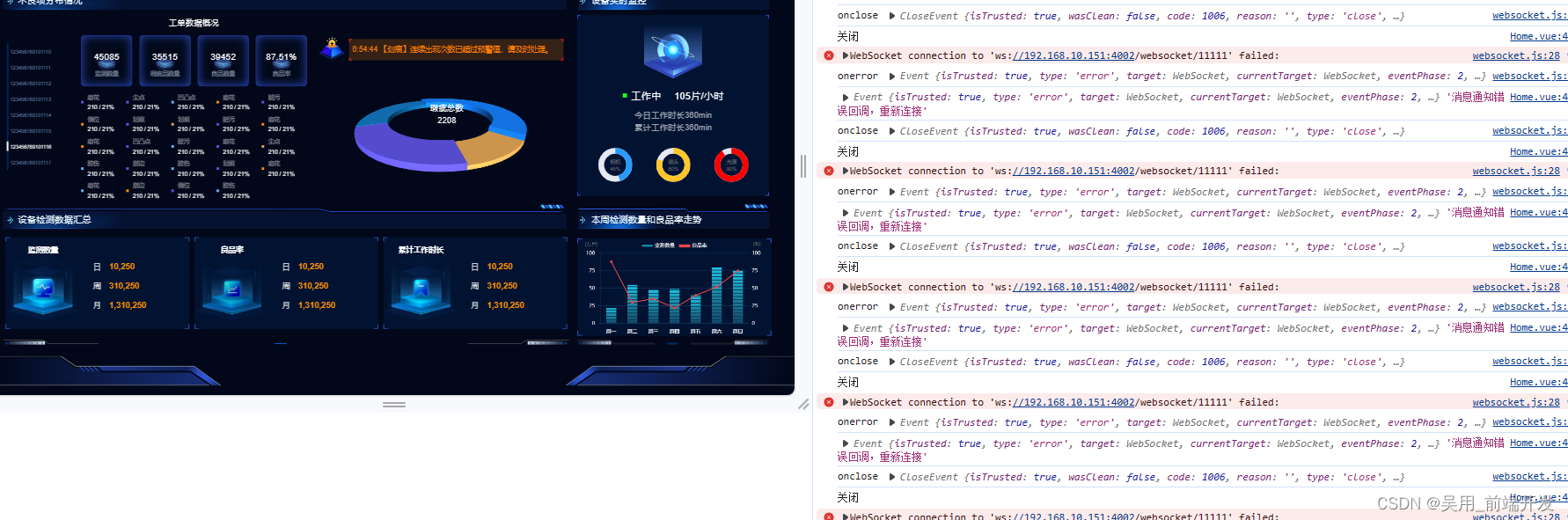
WebSocket真实项目总结
websocket websocket是什么? websocket是一种网络通讯协议。 websocket 是HTML5开始提供的一种在单个TCP链接上进行全双工通讯的协议。 为什么需要websocket? 初次接触websocket,都会带着疑惑去学习,既然已经有了HTTP协议,为什么还需要另一…...

Python 如何实现解释器(Interpreter)设计模式?什么是解释器设计模式?
什么是解释器(Interpreter)设计模式? 解释器(Interpreter)设计模式是一种行为型设计模式,它定义了一种语言文法的表示,并提供了一个解释器,用于解释语言中的句子。该模式使得可以定…...
单片机与PLC的区别有哪些?
单片机与PLC的区别有哪些? 什么是单片机? 单片机(Microcontroller,缩写MCU)是一种集成了中央处理器(CPU)、存储器和输入/输出接口等功能模块的微型计算机系统。它通常被用于嵌入式系统和控制系统中&#x…...

修改浏览器滚动条样式--ios同款
::-webkit-scrollbar{width: 5px;height: 5px; } ::-webkit-scrollbar-thumb{border-radius: 1em;background-color: rgba(50,50,50,.3); } ::-webkit-scrollbar-track{border-radius: 1em;background-color: rgba(50,50,50,.1); } 修改滚动条样式用到的CSS伪类: :…...
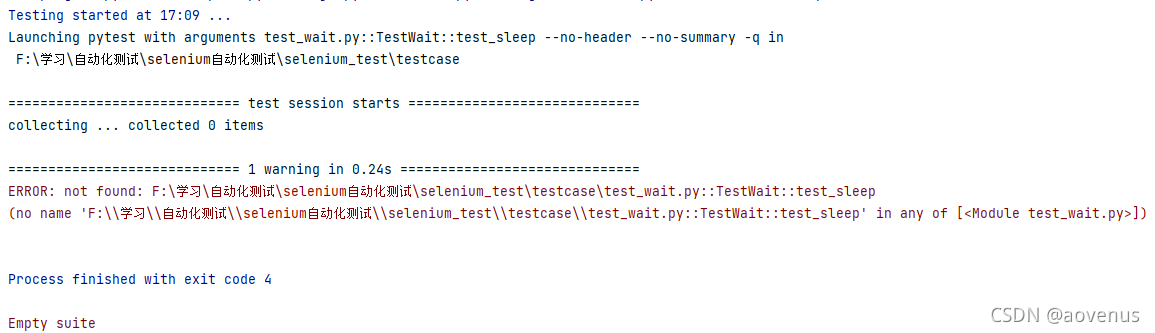
python自动化测试selenium核心技术3种等待方式详解
这篇文章主要为大家介绍了python自动化测试selenium的核心技术三种等待方式示例详解,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步早日升职加薪 UI自动化测试过程中,可能会出现因测试环境不稳定、网络慢等情况&a…...
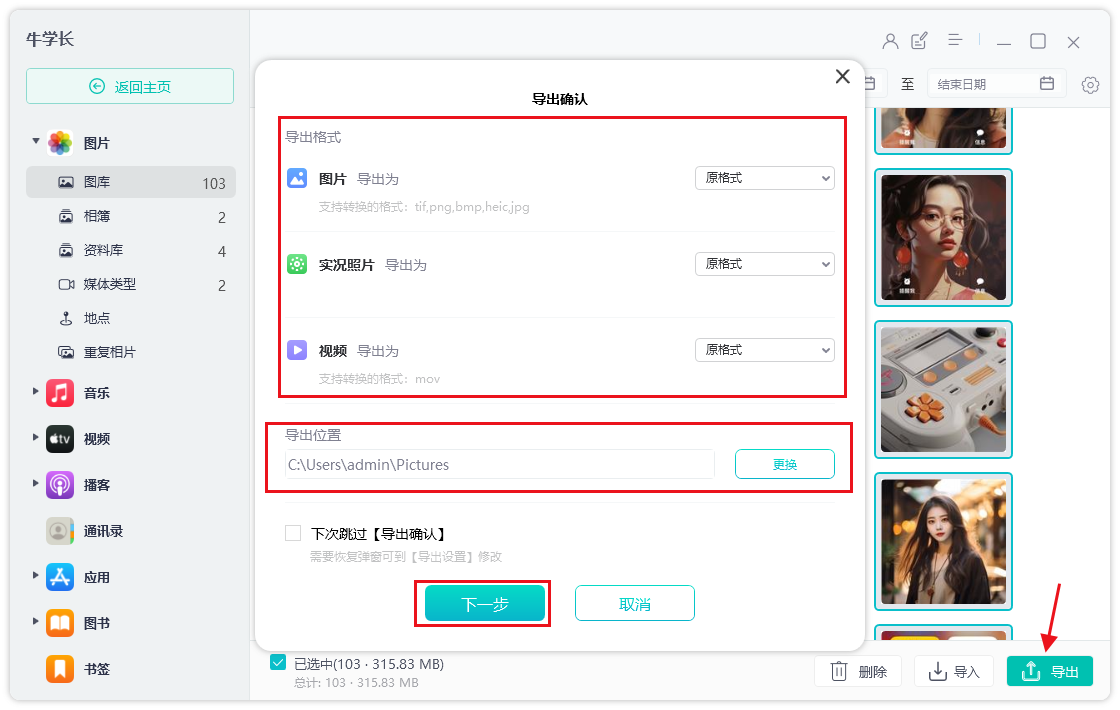
苹果手机照片如何导入电脑?无损快速的传输办法分享!
前些天小编的朋友联系到我,说是自己苹果手机里面的照片太多,有好几千张,不知道该怎么快而无损地传到电脑。我想遇到这种情况的不止是小编的朋友,生活中遇到手机照片导入电脑的同学不在少数。不管是苹果手机还是安卓手机࿰…...

csh 脚本批量处理文件并将文件扔给程序
文章目录 前言程序批量造 case 并将 cmd 扔给程序运行批量收集数据汇总 前言 Linux下我们经常会写一些shell脚本来辅助我们学习或者工作,从而提高效率。 之前就写过一篇博客:Linux下利用shell脚本批量产生内容有规律变化的文件 程序 批量造 case 并将…...

程序员技能成长树,程序员的曙光
一、背景 初创的计算机公司,主要低市场占有率和日益增长的市场规模之间的矛盾,此时只有一件事情,那就是快速抢占市场,在面对计算机飞速发展的时期,企业广泛的招聘计算机人才进行信息化项目建设,随着公司业…...
灰度图处理方法
做深度学习项目图像处理的时候常常涉及到灰度图处理,这里对自己处理灰度图的方式做一个记录,后续有更新的话会在此更新 一,多维数组可视化 将多维数组可视化为灰度图 img_gray Image.fromarray(img, modeL) # 实现array到image的转换,m…...
)
从USB转TTL接线到手机热点配网:ESP8266无线通信保姆级避坑指南(附软件包)
从USB转TTL接线到手机热点配网:ESP8266无线通信保姆级避坑指南 当你第一次拿起ESP8266模块时,可能会被这个小巧的Wi-Fi模块惊艳到——它只有指甲盖大小,却蕴含着强大的无线通信能力。但很快,这种惊艳就会变成困惑:为什…...
)
保姆级教程:在ROS2 Humble/Foxy的Gazebo中配置RGB-D相机(附解决点云颜色/坐标问题)
ROS2 Humble/Foxy中Gazebo深度相机仿真全攻略:从配置到点云问题解决在机器人仿真开发中,深度相机(RGB-D)是不可或缺的传感器之一。它能够同时提供彩色图像和深度信息,为SLAM、物体识别、避障等任务提供关键数据支持。本…...

BetterJoy完整配置指南:5分钟让Switch手柄在PC上完美运行
BetterJoy完整配置指南:5分钟让Switch手柄在PC上完美运行 【免费下载链接】BetterJoy Allows the Nintendo Switch Pro Controller, Joycons and SNES controller to be used with CEMU, Citra, Dolphin, Yuzu and as generic XInput 项目地址: https://gitcode.c…...

3步解锁专业级MMD创作:Blender插件如何重塑二次元动画工作流
3步解锁专业级MMD创作:Blender插件如何重塑二次元动画工作流 【免费下载链接】blender_mmd_tools MMD Tools is a blender addon for importing/exporting Models and Motions of MikuMikuDance. 项目地址: https://gitcode.com/gh_mirrors/bl/blender_mmd_tools …...

从CTF题看RSA安全:为什么你的密钥不能‘共享素数’?
从CTF实战看RSA密钥安全:那些年我们踩过的坑 在网络安全竞赛和实际渗透测试中,RSA算法的错误实现方式往往成为突破的关键点。本文将通过典型CTF赛题案例,揭示五种常见RSA实现漏洞背后的数学原理和安全启示,帮助开发者在实际项目中…...

轻量化部署,异地机房快速接入,多机房管理不用再大动干戈
随着业务拓展,不少企业、单位陆续建起异地分部机房、多区域节点机房。传统资产管理系统部署复杂、对接困难,异地机房接入成本高、周期长,改造繁琐,让很多运维团队望而却步,只能继续沿用分散人工管理,资产混…...

谷氨酸发酵过程的软测量建模【附模型】
✨ 长期致力于软测量、谷氨酸发酵、动力学模型、支持向量机、高斯过程、变量选择、异常状态研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)多阶段高斯…...

Qri高级功能:如何使用JSON Schema验证和描述数据集结构
Qri高级功能:如何使用JSON Schema验证和描述数据集结构 【免费下载链接】qri youre invited to a data party! 项目地址: https://gitcode.com/gh_mirrors/qr/qri Qri是一个强大的开源数据协作工具,它提供了丰富的功能来帮助用户管理、共享和验证…...

LVGL多页面开发避坑:用内部Timer替代轮询,解决页面切换时的内存踩踏问题
LVGL多页面开发中的内存安全实践:用Timer机制替代轮询的工程解决方案 在嵌入式UI开发中,LVGL因其轻量级和跨平台特性成为热门选择。但当项目复杂度提升到多页面交互时,开发者往往会遇到一个棘手问题:如何在频繁切换页面的同时保证…...

LDBlockShow实战指南:基因组连锁不平衡分析与可视化解决方案
LDBlockShow实战指南:基因组连锁不平衡分析与可视化解决方案 【免费下载链接】LDBlockShow LDBlockShow: a fast and convenient tool for visualizing linkage disequilibrium and haplotype blocks based on VCF files 项目地址: https://gitcode.com/gh_mirror…...