python爬取网站数据,作为后端数据
一. 内容简介
python爬取网站数据,作为后端数据
二. 软件环境
2.1vsCode
2.2Anaconda
version: conda 22.9.0
2.3代码
链接:
三.主要流程
3.1 通过urllib请求网站
里面用的所有的包
! pip install lxml
! pip install selenium
! pip install pyautogui
通过urllib请求网站,需要注意一个问题,需要js加载的他都会没有,
使用 urllib 或 requests 库通常无法获取完整的页面内容,因为这些库只会获取页面的初始 HTML,而不会执行 JavaScript。
import urllib.request
from lxml import etree
import json
from selenium.webdriver.common.by import By
from selenium import webdriver
import random
import time
import pyautogui
from datetime import datetimedef urllibRequest(url):headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36'}request = urllib.request.Request(url=url, headers=headers)response = urllib.request.urlopen(request)content = response.read().decode('UTF-8')return contenturl = "https://cxcy.upln.cn/"
print(url)
content = urllibRequest(url)
print(content)
最原始的网页,什么也没有,部分网页是这样的,没办法通过urllib 或 requests来获取完整的结构。
3.2 通过selenium请求网站
这个是通过驱动调用浏览器去进行访问,Selenium 可以模拟真实浏览器的行为,包括执行 JavaScript 代码,从而获取完整的页面内容。代码只需要给定链接,谷歌浏览器的exe位置,和网页加载时间就可以了,不需要下载谷歌浏览器驱动。
import urllib.request
from lxml import etree
import json
from selenium.webdriver.common.by import By
from selenium import webdriver
import random
import time
import pyautogui
from datetime import datetimedef seleniumRequest(url,chrome_path,waitTime): options = webdriver.ChromeOptions()options.add_experimental_option('excludeSwitches', ['enable-automation'])options.add_experimental_option('useAutomationExtension', False)# 谷歌浏览器exe位置options.binary_location = chrome_path# 是否要启动页面options.add_argument("--headless") # 启用无头模式# GPU加速有时候会出bugoptions.add_argument("--disable-gpu") # 禁用GPU加速options.add_argument("--disable-blink-features=AutomationControlled")driver = webdriver.Chrome(options=options)driver.execute_cdp_cmd('Page.addScriptToEvaluateOnNewDocument',{'source': 'Object.defineProperty(navigator, "webdriver", {get: () => undefined})'})# 启动要填写的地址,这就启动浏览器driver.get(url)# 这是关闭浏览器# 等待页面加载,可以根据实际情况调整等待时间driver.implicitly_wait(waitTime)# 获取完整页面结构full_page_content = driver.page_source# 关闭浏览器driver.quit()return full_page_content
# # 处理完整页面结构
# print(full_page_content)
url = "https://cxcy.upln.cn/"
print(url)chrome_path = r"C:\Program Files\Google\Chrome\Application\chrome.exe"
waitTime = 8
# 获取网页结构
# 通过selenium调用浏览器访问
content = seleniumRequest(url,chrome_path,waitTime)
print(content)
可以看到拿到了完整的网页结构了
3.2 通过request请求api,并保存json数据
import requests
import jsondef apiRequset(api_url):headers={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36",}# 发起带有头部信息的 GET 请求response = requests.get(api_url, headers=headers)# 检查请求是否成功if response.status_code == 200:# 解析 JSON 数据data = response.json()return data
api_url = 'https://cxcy.upln.cn/provincial/match/competition/queryOngoing?_t=1699950536&year=2023&code=2&column=createTime&order=desc&field=id,&pageNo=1&pageSize=10'
data = apiRequset(api_url)
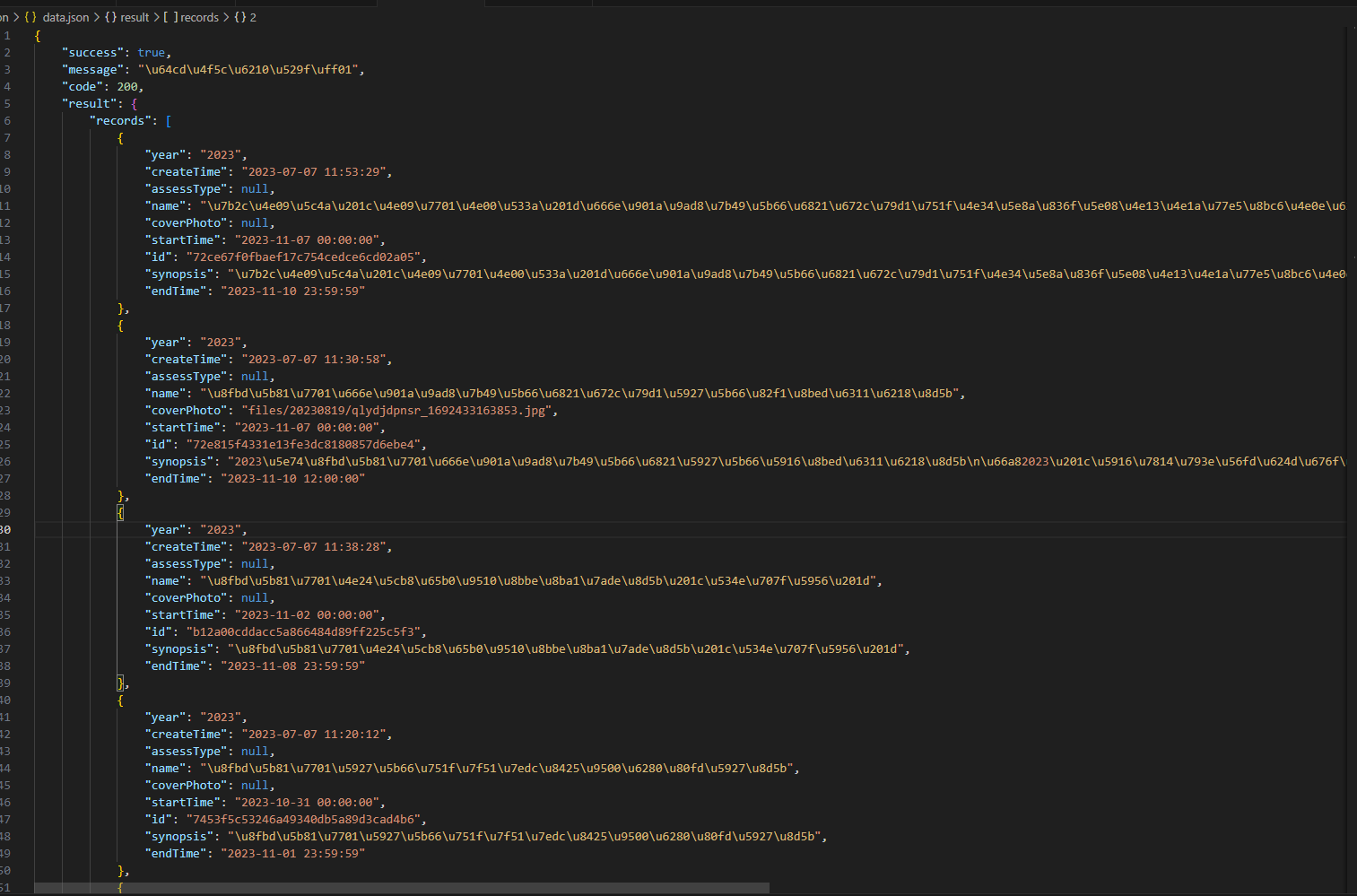
json_data = json.dumps(data, indent=4)# 将JSON数据写入文件
with open("data.json", "w") as json_file:json_file.write(json_data)
3.4 通过xpath获取网页结构里面的数据,并存入json
xpath语法可以自己查一下,网上有很多
import urllib.request
from lxml import etree
import json
from selenium.webdriver.common.by import By
from selenium import webdriver
import random
import time
import pyautogui
from datetime import datetimeurl = "https://cxcy.upln.cn/"
print(url)
imgs = []
chrome_path = r"C:\Program Files\Google\Chrome\Application\chrome.exe"
waitTime = 8
# 获取网页结构
# 通过selenium调用浏览器访问
content = seleniumRequest(url,chrome_path,waitTime)
# 这是直接请求得到的html,
# slelenium会拼接字符串
# content = urllibRequest(url)# 给html变成tree用于xpath解析用
tree = etree.HTML(content)
# 改进的XPath表达式,选择你感兴趣的div元素
# 解析对应数据
bannerimgs = tree.xpath("//div[@class='img-box']//img/@src")
print(bannerimgs)
current_time = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
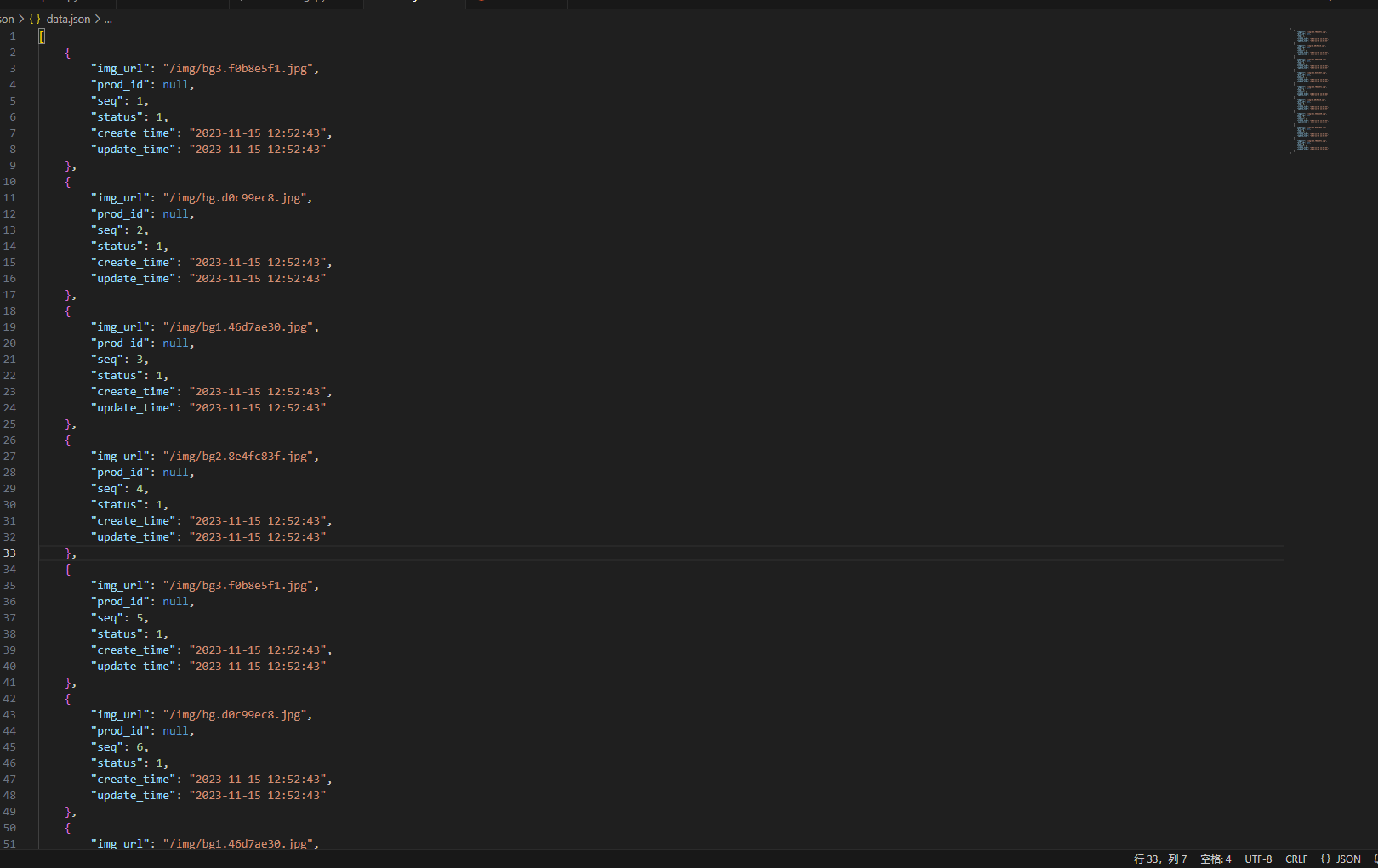
for index, url in enumerate(bannerimgs):print(index,url)img = {# 'img_id':,'img_url':url,'prod_id':None,'seq':index+1,'status':1,'create_time':current_time,'update_time':current_time,}imgs.append(img)json_data = json.dumps(imgs, indent=4)# 将JSON数据写入文件
with open("data.json", "w") as json_file:json_file.write(json_data)
print("JSON数据已保存到文件")
3.4 读取json,将数据存入对应的数据库中
先下载驱动
! pip install mysql-connector-python
import json
import mysql.connector# 读取JSON文件
with open('ceshi.json', 'r') as file:data = json.load(file)# 连接到MySQL数据库
conn = mysql.connector.connect(host='localhost',port=3306, # MySQL默认端口号user='root',password='1234',database='ceshi'
)cursor = conn.cursor()# 创建表(如果不存在的话),并清空表数据
cursor.execute('''CREATE TABLE IF NOT EXISTS your_table (id INT AUTO_INCREMENT PRIMARY KEY,name VARCHAR(255),age INT,other_field VARCHAR(255))
''')cursor.execute('TRUNCATE TABLE your_table')
# 将数据插入数据库
for item in data:cursor.execute('''INSERT INTO your_table (name, age, other_field)VALUES (%s, %s, %s)''', (item['year'], item['assessType'], item['id']))# 提交更改并关闭连接
conn.commit()
conn.close()
相关文章:
python爬取网站数据,作为后端数据
一. 内容简介 python爬取网站数据,作为后端数据 二. 软件环境 2.1vsCode 2.2Anaconda version: conda 22.9.0 2.3代码 链接: 三.主要流程 3.1 通过urllib请求网站 里面用的所有的包 ! pip install lxml ! pip install selenium ! pip install…...
【机器学习】K近邻算法:原理、实例应用(红酒分类预测)
案例简介:有178个红酒样本,每一款红酒含有13项特征参数,如镁、脯氨酸含量,红酒根据这些特征参数被分成3类。要求是任意输入一组红酒的特征参数,模型需预测出该红酒属于哪一类。 1. K近邻算法介绍 1.1 算法原理 原理&a…...

基于安卓android微信小程序的快递取件及上门服务系统
项目介绍 本文从管理员、用户的功能要求出发,快递取件及上门服务中的功能模块主要是实现管理员服务端;首页、个人中心、用户管理、快递下单管理、预约管理、管理员管理、系统管理、订单管理,用户客户端;首页、快递下单、预约管理…...
leetCode 92.反转链表 II + 图解
92. 反转链表 II - 力扣(LeetCode) 给你单链表的头指针 head 和两个整数 left 和 right ,其中 left < right 。请你反转从位置 left 到位置 right 的链表节点,返回 反转后的链表 206. 反转链表 - 力扣(LeetCode&am…...
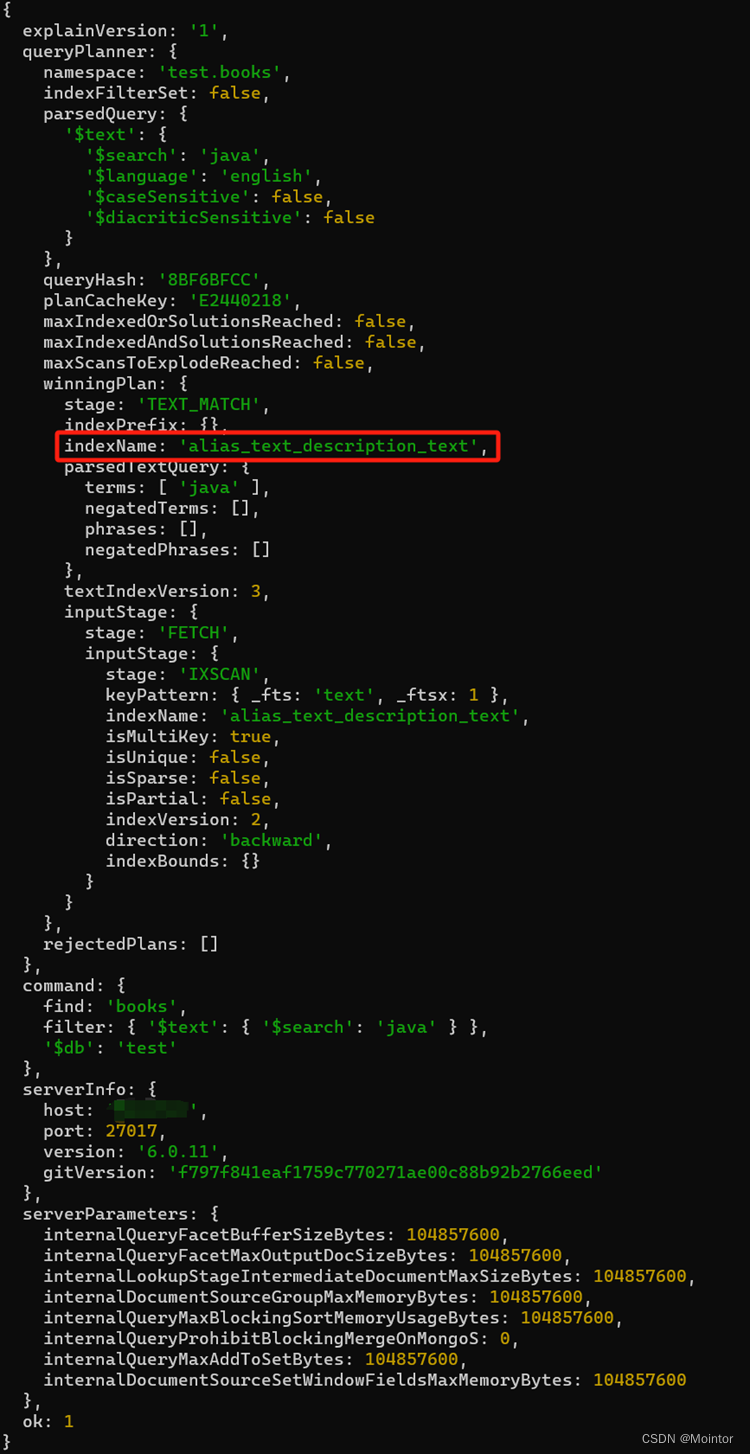
【MongoDB】索引 – 通配符索引
一、准备工作 这里准备一些数据 db.books.drop();db.books.insert({_id: 1, name: "Java", alias: "java 入门", description: "入门图书" }); db.books.insert({_id: 2, name: "C", alias: "c", description: "C 入…...

python安装pip install报错Could not fetch URL https://pypi.org/simple/pip/...更换镜像源
更换镜像源 一. 现象pycharm使用 pip install xxx安装包时,一直报错: 二. 原因:三. 解决办法:一. 临时使用二. 永久更改三. 永久更改1. Windowswindows环境下Windows(示例win10) 2. Linux or Mac3. Pycharm…...

C++ 算数运算符 学习资料
C 算数运算符 在 C 中,算数运算符用于执行各种数学运算。以下是常用的算数运算符: :加法运算符,用于将两个表达式相加。-:减法运算符,用于从一个表达式中减去另一个表达式。*:乘法运算符&…...

问题 H: 棋盘游戏(二分图变式)
题意:要求找到 不放车就无法达到最大数的点 的个数 题解:1.以行列绘制二分图 2.先算出最大二分匹配数 3.依次遍历所有边 删除该边,并计算二分匹配最大值 (若小于原最大值即为重要点)࿰…...

SQL 主从数据库实时备份
在SQL数据库中,主从复制(Master-Slave Replication)是一种常见的实时备份和高可用性解决方案。这种配置允许将一个数据库服务器(主服务器)的更改同步到一个或多个其他数据库服务器(从服务器)&am…...
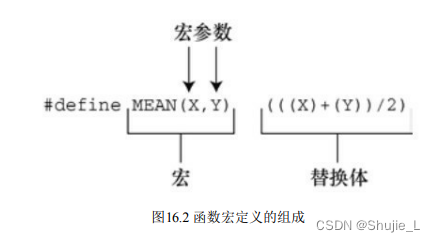
C/C++:在#define中使用参数
文章目录 在#define中使用参数参考资料 在#define中使用参数 在#define中使用参数可以创建外形和作用与函数类似的类函数宏。带有 参数的宏看上去很像函数,因为这样的宏也使用圆括号。类函数宏定义的圆 括号中可以有一个或多个参数,随后这些参数出现在替…...

Hive 查询优化
Hive 查询优化 -- 本地 set mapreduce.framework.namelocal; set hive.exec.mode.local.autotrue; set mapperd.job.trackerlocal; -- yarn set mapreduce.framework.nameyarn; set hive.exec.mode.local.autofalse; set mapperd.job.trackeryarn-- 向量模式 set hive.vectori…...

【Java 进阶篇】JQuery 案例:优雅的隔行换色
在前端的设计中,页面的美观性是至关重要的。而其中一个简单而实用的设计技巧就是隔行换色。通过巧妙地使用 JQuery,我们可以轻松地实现这一效果,为网页增添一份优雅。本篇博客将详细解析 JQuery 隔行换色的实现原理和应用场景,让我…...

Redis 常用的类型和 API
前言 在当今的软件开发中,数据存储与操作是至关重要的一部分。为了满足日益增长的数据需求和对性能的追求,出现了许多不同类型的数据库。其中,Redis 作为一种基于内存且高性能的键值存储数据库,因其快速的读取速度、丰富的数据结…...
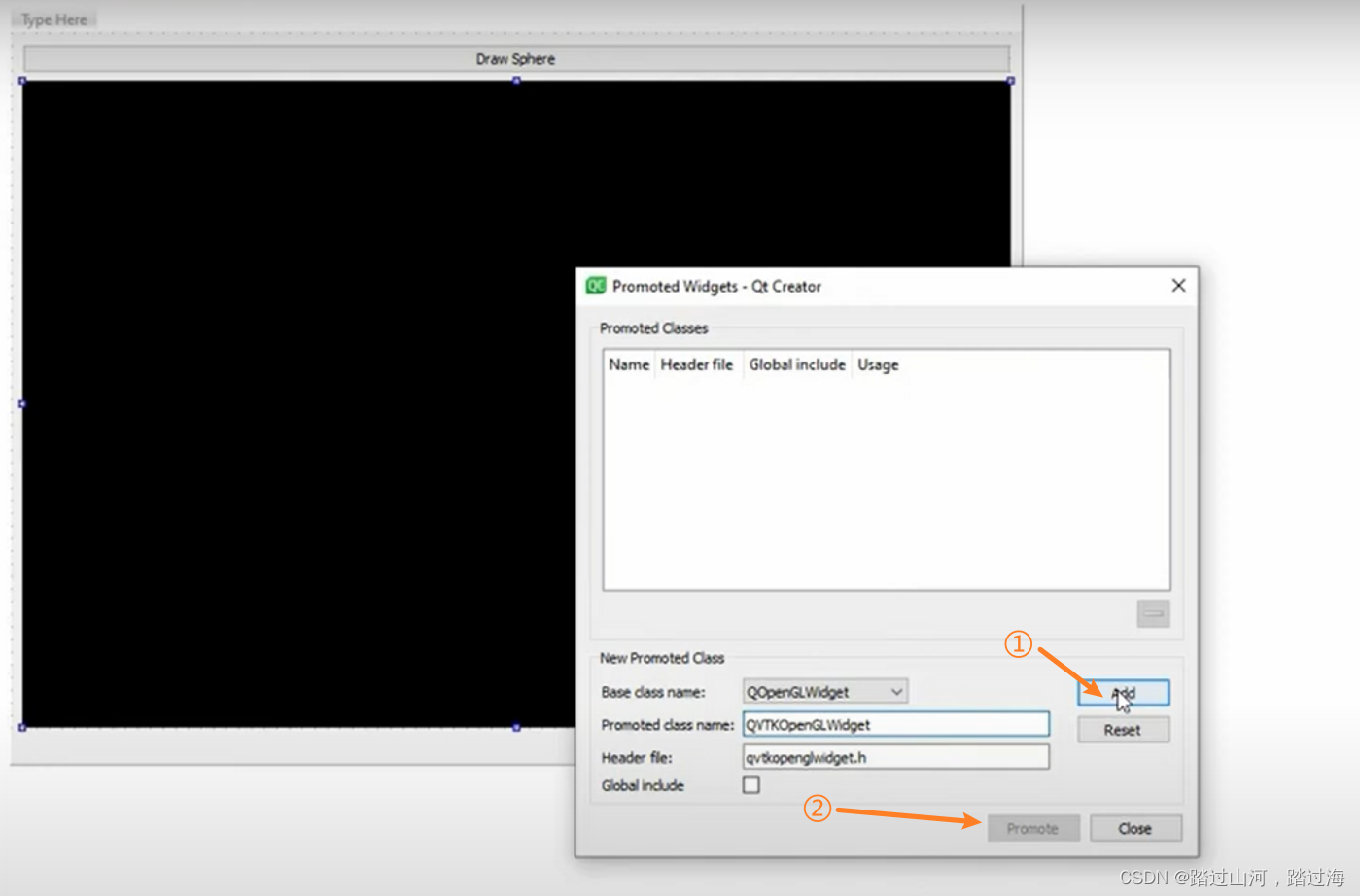
在qt的设计师界面没有QVTKOpenGLWidget这个类,只有QOpenGLWidget,那么我们如何得到QVTKOpenGLWidget呢?
文章目录 前言不过,时过境迁,QVTKOpenGLWidget用的越来越少,官方推荐使用qvtkopengnativewidget代替QVTKOpenGLWidget 前言 在qt的设计师界面没有QVTKOpenGLWidget这个类,只有QOpenGLWidget,我们要使用QVTKOpenGLWidget,那么我们如何得到QVTKOpenGLWidget呢? 不过,时过境迁,Q…...
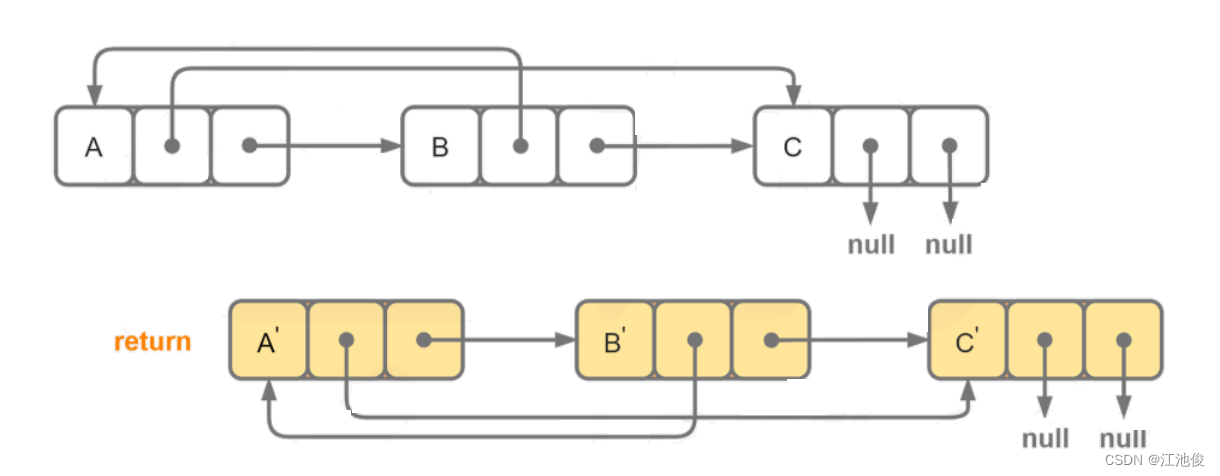
力扣每日一道系列 --- LeetCode 138. 随机链表的复制
📷 江池俊: 个人主页 🔥个人专栏: ✅数据结构探索 ✅LeetCode每日一道 🌅 有航道的人,再渺小也不会迷途。 LeetCode 138. 随机链表的复制 给你一个长度为 n 的链表,每个节点包含一个额外增加…...

无人零售:创新优势与广阔前景
无人零售:创新优势与广阔前景 无人零售在创新方面具有优势。相比发展较为成熟的欧洲和日本的自动贩卖机市场,中国的无人零售市场人均占有量较少,这表明该市场具有广阔的前景和巨大的市场潜力。 此外,无人零售涉及到许多相关行业&…...
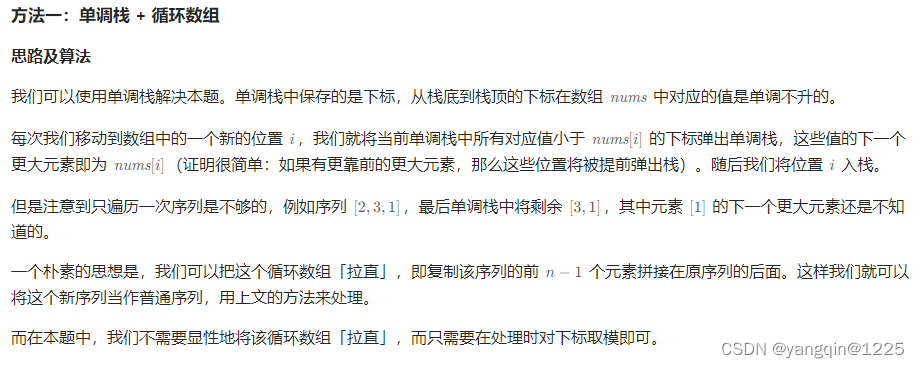
【华为OD题库-022】阿里巴巴找黄金宝箱(IV)-java
题目 一贫如洗的椎夫阿里巴巴在去砍柴的路上,无意中发现了强盗集团的藏宝地,藏宝地有编号从0-N的子,每个箱子上面有一个数字,箱子排列成一个环,编号最大的箱子的下一个是编号为0的箱子。请输出每个箱子贴的数字之后的第…...
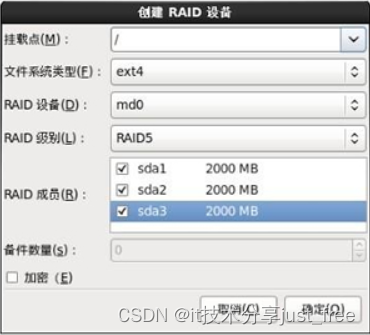
Linux 图形界面配置RAID
目录 RAID 1 配置 RAID 5配置 , RAID 配置起来要比 LVM 方便,因为它不像 LVM 那样分了物理卷、卷组和逻辑卷三层,而且每层都需要配置。我们在图形安装界面中配置 RAID 1和 RAID 5,先来看看 RAID 1 的配置方法。 RAID 1 配置 配置 RAID 1…...
、( 什么是qps,tps,并发量,pv,uv)、(什么是接口幂等性问题,如何解决?))
(脏读,不可重复读,幻读 ,mysql5.7以后默认隔离级别)、( 什么是qps,tps,并发量,pv,uv)、(什么是接口幂等性问题,如何解决?)
1 脏读,不可重复读,幻读 ,mysql5.7以后默认隔离级别是什么? 2 什么是qps,tps,并发量,pv,uv 3 什么是接口幂等性问题,如何解决? 1 脏读,不可重复读…...
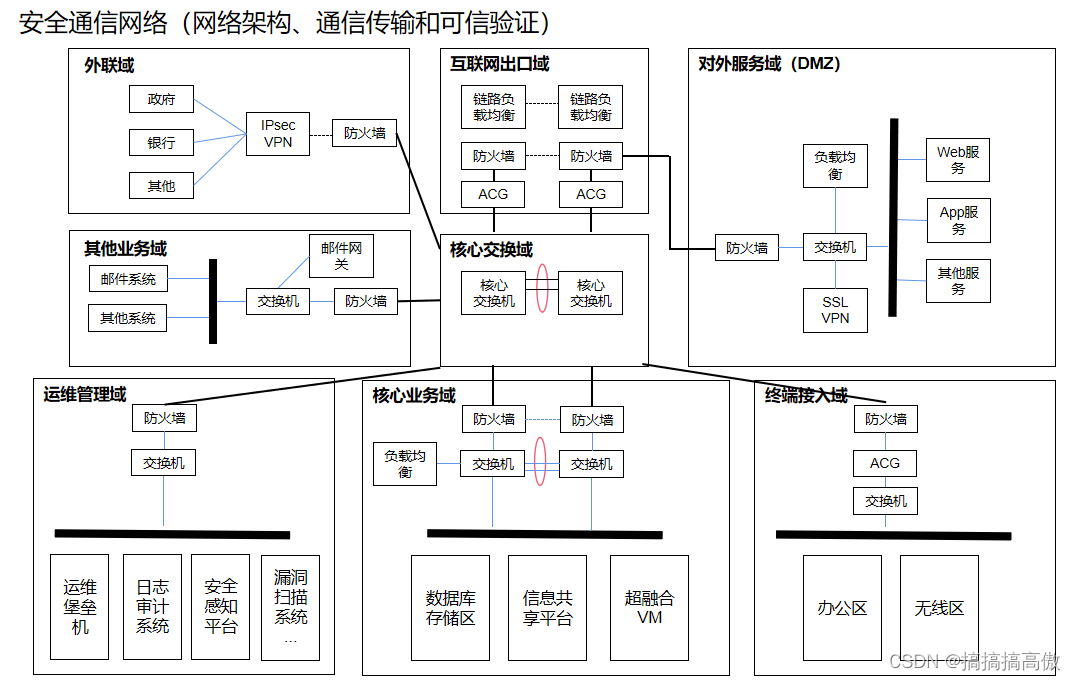
安全通信网络(设备和技术注解)
网络安全等级保护相关标准参考《GB/T 22239-2019 网络安全等级保护基本要求》和《GB/T 28448-2019 网络安全等级保护测评要求》 密码应用安全性相关标准参考《GB/T 39786-2021 信息系统密码应用基本要求》和《GM/T 0115-2021 信息系统密码应用测评要求》 1网络架构 1.1保证网络…...

别再让模型在Unity里‘抽风’了!Blender导出FBX到Unity的7步避坑自查清单
别再让模型在Unity里‘抽风’了!Blender导出FBX到Unity的7步避坑自查清单当你花了三天三夜精心雕琢的Blender模型,导入Unity后却变成了一团旋转错乱、贴图闪烁的"抽象艺术",那种崩溃感每个3D开发者都懂。本文将用实战经验帮你建立一…...

Redis分布式锁进阶第二十篇
一、本篇前置衔接 第二十篇我们完成了全系列终局复盘,整理了故障排查SOP与企业级落地铁律。常规单资源锁、热点分片锁、隔离锁全部讲透,但真实复杂业务永远不是单一资源:下单要扣库存、扣优惠券、扣积分、冻结余额,多资源并行争抢…...
重构)
嘈杂工业场景下的自适应VAD与双码本声纹识别鉴权系统:基于端侧轻量化神经网络与向量量化(VQ)重构
在大型化工车间、能源集控中心以及金融极密隔离库房中,离线声纹识别是物理访问控制和身份安全核验的重要生物特征屏障。然而,在环境本底噪声高达80dB以上的恶劣工业场景下,常规的语音活动检测(VAD)会频繁误触ÿ…...

炉石传说自动对战助手:5分钟上手,彻底解放双手的终极指南
炉石传说自动对战助手:5分钟上手,彻底解放双手的终极指南 【免费下载链接】Hearthstone-Script Hearthstone script(炉石传说脚本) 项目地址: https://gitcode.com/gh_mirrors/he/Hearthstone-Script 还在为每天重复的炉石…...

基于MaixCam的延时摄影系统:从硬件选型到Python编程全解析
1. 项目概述:用MaixCam打造你的专属延时摄影工坊延时摄影,这个听起来有点专业、甚至带点“魔法”色彩的词,其实离我们并不遥远。想想看,把一朵花从含苞到绽放的几天时间,压缩成十几秒的惊艳绽放;或者把一座…...

别被忽悠了!2026亲测靠谱的AI论文网站|避坑精选版
2026 年学术写作工具已高度分化,千笔AI与ThouPen为全流程首选,豆包、DeepSeek 为专项强手;避坑关键:拒绝假文献、严控 AIGC 率、优先国内适配、免费试用先行。 一、TOP3 全流程首选(亲测不踩雷) 1. 千笔AI&…...

FairyGUI Unity鼠标悬停与点击对象获取原理与实战
1. 这不是“加个OnMouseEnter就能用”的事:FairyGUI在Unity中处理鼠标交互的真实困境很多人第一次在Unity里集成FairyGUI,想实现“鼠标悬停显示提示”或“点击高亮当前按钮”,下意识就去翻Unity的MonoBehaviour文档,找OnMouseEnte…...

Jupyter Notebook里跑argparse脚本总报错?一个空列表参数搞定ipykernel_launcher.py error
Jupyter Notebook中argparse报错的终极解决方案:空列表参数实战解析在数据科学和机器学习的工作流中,Jupyter Notebook因其交互式特性成为众多研究者的首选工具。然而,当我们尝试在Notebook中运行那些原本为命令行设计的Python脚本时…...
)
手把手教你用Mind+和Blynk,让手机轻松遥控掌控板(含自建服务器避坑指南)
从零搭建物联网控制平台:Mind与Blynk深度整合实战 当你第一次尝试用手机控制硬件设备时,那种"隔空取物"的奇妙感总会让人兴奋不已。想象一下,躺在沙发上就能调节书桌上的智能台灯亮度,或者在外出时随时查看家中的温湿度…...

保姆级教程:在Windows 10上用QEMU+Kylin搭建可内外网访问的完整开发环境
在Windows 10上构建QEMUKylin全功能开发环境的终极指南当开发者需要在本地快速搭建一个隔离的国产操作系统开发环境时,QEMU虚拟化方案配合银河麒麟系统能提供高度灵活的沙箱体验。本文将手把手带你完成从零配置到内外网联通的完整工作流,涵盖虚拟化环境部…...