Elastic stack8.10.4搭建、启用安全认证,启用https,TLS,SSL 安全配置详解
ELK大家应该很了解了,废话不多说开始部署
kafka在其中作为消息队列解耦和让logstash高可用
kafka和zk 的安装可以参考这篇文章
深入理解Kafka3.6.0的核心概念,搭建与使用-CSDN博客
第一步、官网下载安装包
需要
elasticsearch-8.10.4
logstash-8.10.4
kibana-8.10.4
kafka_2.13-3.6.0
apache-zookeeper-3.9.1-bin.tar
filebeat-8.10.4-linux-x86_64.tar
第二步: 环境配置(每一台都做)
创建es用户
useradd es配置主机名、配置IP地址、每台主机配置/etc/hosts名称解析
192.168.1.1 es1
192.168.1.2 es2
192.168.1.3 es3
将Linux系统的软硬限制最大文件数改为65536,将所有用户的最大线程数修改为65536
打开/etc/security/limits.conf文件,添加以下配置(每一台都做)
vim /etc/security/limits.conf* soft nofile 65536
* hard nofile 65536* soft nproc 65536
* hard nproc 65536es hard core unlimited #打开生成Core文件
es soft core unlimited
es soft memlock unlimited #允许用户锁定内存
es hard memlock unlimitedsoft xxx : 代表警告的设定,可以超过这个设定值,但是超过后会有警告。
hard xxx : 代表严格的设定,不允许超过这个设定的值。
nproc : 是操作系统级别对每个用户创建的进程数的限制
nofile : 是每个进程可以打开的文件数的限制
soft nproc :单个用户可用的最大进程数量(超过会警告);
hard nproc:单个用户可用的最大进程数量(超过会报错);
soft nofile :可打开的文件描述符的最大数(超过会警告);
hard nofile :可打开的文件描述符的最大数(超过会报错);
修改/etc/sysctl.conf文件,添加下面这行,并执行命令sysctl -p使其生效
vim /etc/sysctl.confvm.max_map_count=262144 #限制一个进程可以拥有的VMA(虚拟内存区域)的数量,es要求最低65536
net.ipv4.tcp_retries2=5 #数据重传次数超过 tcp_retries2 会直接放弃重传,关闭 TCP 流
解压安装包,进入config文件夹,修改elasticsearch.yml 配置文件
cluster.name: elk #集群名称
node.name: node1 #节点名称
node.roles: [ master,data ] #节点角色
node.attr.rack: r1 #机架位置,一般没啥意义这个配置
path.data: /data/esdata
path.logs: /data/eslog
bootstrap.memory_lock: true #允许锁定内存
network.host: 0.0.0.0
http.max_content_length: 200mb
network.tcp.keep_alive: true
network.tcp.no_delay: true
http.port: 9200
http.cors.enabled: true #允许http跨域访问,es_head插件必须开启
http.cors.allow-origin: "*" #允许http跨域访问,es_head插件必须开启
discovery.seed_hosts: ["ypd-dmcp-log01", "ypd-dmcp-log02"]
cluster.initial_master_nodes: ["ypd-dmcp-log01", "ypd-dmcp-log02"]
xpack.monitoring.collection.enabled: true #添加这个配置以后在kibana中才会显示联机状态,否则会显示脱机状态
xpack.security.enabled: true
#xpack.security.enrollment.enabled: true
xpack.security.http.ssl.enabled: true
xpack.security.http.ssl.keystore.path: elastic-certificates.p12 #我把文件都放在config下。所以直接写文件名,放在别处需要写路径
xpack.security.http.ssl.truststore.path: elastic-certificates.p12
xpack.security.transport.ssl.enabled: true
xpack.security.transport.ssl.verification_mode: certificate
xpack.security.transport.ssl.keystore.path: elastic-certificates.p12k
xpack.security.transport.ssl.truststore.path: elastic-certificates.p12
配置jvm内存大小
修改 jvm.options
-Xms6g #你服务器内存的一半,最高32G
-Xmx6g #你服务器内存的一半,最高32G改好文件夹准备生成相关key
创建ca证书,什么也不用输入,两次回车即可(会在当前目录生成名为elastic-stack-ca.p12的证书文件)
bin/elasticsearch-certutil ca使用之前生成的ca证书创建节点证书,过程三次回车,会在当前目录生成一个名为elastic-certificates.p12的文件
bin/elasticsearch-certutil cert --ca elastic-stack-ca.p12生成http证书,根据提示信息进行操作,主要是下面几步
bin/elasticsearch-certutil httpGenerate a CSR? [y/N]n
Use an existing CA? [y/N]y
CA Path: /usr/local/elasticsearch-8.10.4/config/certs/elastic-stack-ca.p12
Password for elastic-stack-ca.p12: 直接回车,不使用密码
For how long should your certificate be valid? [5y] 50y#过期时间
Generate a certificate per node? [y/N]n
Enter all the hostnames that you need, one per line. #输入es的节点 两次回车确认
When you are done, press <ENTER> once more to move on to the next step.
es1
es2
es3You entered the following hostnames.- es1- es2- es3Is this correct [Y/n]yWhen you are done, press <ENTER> once more to move on to the next step. #输入es的ip 两次回车确认192.168.1.1
192.168.1.2
192.168.1.3You entered the following IP addresses.- 192.168.1.1- 192.168.1.2- 192.168.1.3Is this correct [Y/n]yDo you wish to change any of these options? [y/N]n接下来一直回车,然后会在当前目录生成名为:elasticsearch-ssl-http.zip的压缩文件
解压缩http证书文件到config下,证书在http文件夹里。名字是http.p12,mv出来到config下
确保elasticsearch目录下所有文件的归属关系都是es用户
chown -R es:es /home/es/elasticsearch-8.10.4启动es
su - es #到es用户下
bin/elasticsearch 初次可以前台启动 没问题就放后台
bin/elasticsearch -d复制整个es文件夹到es2,es3
只需要修改
node.name: es2 #节点名称network.host: 192.168.1.2 #节点ipnode.name: es3 #节点名称network.host: 192.168.1.3 #节点ip浏览器访问一下es的web ui
https://192.168.1.1:9200

生成账户密码
bin/elasticsearch-setup-passwords interactivewarning: ignoring JAVA_HOME=/usr/local/java/jdk1.8.0_361; using bundled JDK
******************************************************************************
Note: The 'elasticsearch-setup-passwords' tool has been deprecated. This command will be removed in a future release.
******************************************************************************Initiating the setup of passwords for reserved users elastic,apm_system,kibana,kibana_system,logstash_system,beats_system,remote_monitoring_user.
You will be prompted to enter passwords as the process progresses.
Please confirm that you would like to continue [y/N]yEnter password for [elastic]:
Reenter password for [elastic]:
Enter password for [apm_system]:
Reenter password for [apm_system]:
Enter password for [kibana_system]:
Reenter password for [kibana_system]:
Enter password for [logstash_system]:
Reenter password for [logstash_system]:
Enter password for [beats_system]:
Reenter password for [beats_system]:
Enter password for [remote_monitoring_user]:
Reenter password for [remote_monitoring_user]:
Changed password for user [apm_system]
Changed password for user [kibana_system]
Changed password for user [kibana]
Changed password for user [logstash_system]
Changed password for user [beats_system]
Changed password for user [remote_monitoring_user]
Changed password for user [elastic]这个时候就可以使用账号密码访问了创建一个给kibana使用的用户
bin/elasticsearch-users useradd kibanauser
kibana不能用es超级用户,此处展示一下用法
bin/elasticsearch-users roles -a superuser kibanauser
加两个角色 不然没有监控权限
bin/elasticsearch-users roles -a kibana_admin kibanauser
bin/elasticsearch-users roles -a monitoring_user kibanauser
然后配置kibana
解压然后修改kibana.yml
server.port: 5601
server.host: "0.0.0.0"server.ssl.enabled: true
server.ssl.certificate: /data/elasticsearch-8.10.4/config/client.cer
server.ssl.key: /data/elasticsearch-8.10.4/config/client.key
elasticsearch.hosts: ["https://192.168.1.1:9200"]
elasticsearch.username: "kibanauser"
elasticsearch.password: "kibanauser"
elasticsearch.ssl.certificate: /data/elasticsearch-8.10.4/config/client.cer
elasticsearch.ssl.key: /data/elasticsearch-8.10.4/config/client.key
elasticsearch.ssl.certificateAuthorities: [ "/data/elasticsearch-8.10.4/config/client-ca.cer" ]
elasticsearch.ssl.verificationMode: certificate
i18n.locale: "zh-CN"
xpack.encryptedSavedObjects.encryptionKey: encryptedSavedObjects1234567890987654321
xpack.security.encryptionKey: encryptionKeysecurity1234567890987654321
xpack.reporting.encryptionKey: encryptionKeyreporting1234567890987654321
启动
bin/kibana访问 https://ip:5601
配置logstash
解压后在conf下创建一个配置文件,我取名logstash.conf
input {kafka {bootstrap_servers => "192.168.1.1:9092"group_id => "logstash_test"client_id => 1 #设置相同topic,设置相同groupid,设置不同clientid,实现LogStash多实例并行消费kafkatopics => ["testlog"]consumer_threads => 2 #等于 topic分区数codec => json { #添加json插件,filebeat发过来的是json格式的数据charset => "UTF-8"}decorate_events => false #此属性会将当前topic、offset、group、partition等信息也带到message中type => "testlog" #跟topics不重合。因为output读取不了topics这个变量
}}
filter {mutate {remove_field => "@version" #去掉一些没用的参数remove_field => "event"remove_field => "fields"}
}output {elasticsearch {cacert => "/data/elasticsearch-8.10.4/config/client-ca.cer"ssl => truessl_certificate_verification => falseuser => elasticpassword => "123456"action => "index"hosts => "https://192.168.1.1:9200"index => "%{type}-%{+YYYY.MM.dd}"
}}
修改jvm.options
-Xms6g #你服务器内存的一半,最高32G
-Xmx6g #你服务器内存的一半,最高32G
启动logstash
bin/logstash -f conf/logstash.conf最后去服务器上部署filebeat
filebeat.inputs:
- type: filestream 跟以前的log类似。普通的日志选这个就行了id: testlog1 enabled: truepaths:- /var/log/testlog1.logfield_under_root: true #让kafka的topic: '%{[fields.log_topic]}'取到变量值fields:log_topic: testlog1 #跟id不冲突,id输出取不到变量值multiline.pattern: '^\d(4)' # 设置多行合并匹配的规则,意思就是不以4个连续数字,比如2023开头的 视为同一条multiline.negate: true # 如果匹配不上multiline.match: after # 合并到后面- type: filestream id: testlog2enabled: truepaths:- /var/log/testlog2field_under_root: true fields:log_topic: testlog2multiline.pattern: '^\d(4)' multiline.negate: truemultiline.match: afterfilebeat.config.modules:path: ${path.config}/modules.d/*.yml reload.enabled: true #开启运行时重载配置#reload.period: 10s
path.home: /data/filebeat-8.10.4/ #指明filebeat的文件夹。启动多个时需要
path.data: /data/filebeat-8.10.4/data/
path.logs: /data/filebeat-8.10.4/logs/processors:- drop_fields: #删除不需要显示的字段fields: ["agent","event","input","log","type","ecs"]output.kafka:enabled: truehosts: ["10.8.74.35:9092"] #kafka地址,可配置多个用逗号隔开topic: '%{[fields.log_topic]}' #根据上面添加字段发送不同topic初步的部署这就完成了。后面的使用才是大头,路漫漫其修远兮
相关文章:
Elastic stack8.10.4搭建、启用安全认证,启用https,TLS,SSL 安全配置详解
ELK大家应该很了解了,废话不多说开始部署 kafka在其中作为消息队列解耦和让logstash高可用 kafka和zk 的安装可以参考这篇文章 深入理解Kafka3.6.0的核心概念,搭建与使用-CSDN博客 第一步、官网下载安装包 需要 elasticsearch-8.10.4 logstash-8.…...
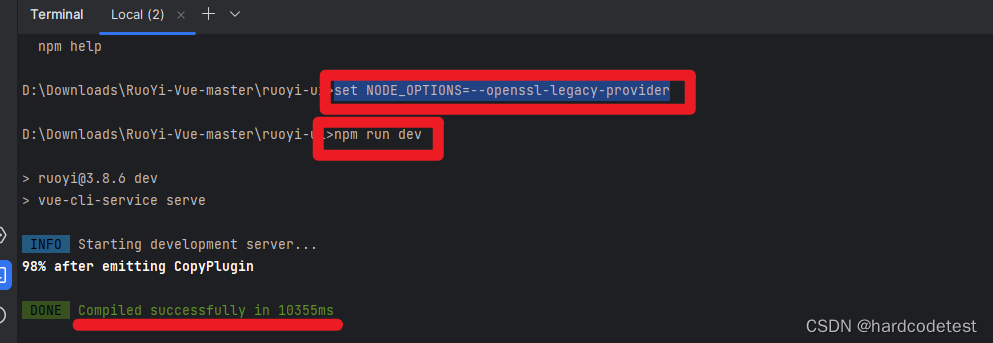
解决npm报错Error: error:0308010C:digital envelope routines::unsupported
解决npm报错Error: error:0308010C:digital envelope routines::unsupported。 解决办法;终端执行以下命令(windows): set NODE_OPTIONS--openssl-legacy-provider然后再执行 npm命令成功:...

高防IP是什么?有什么优势?
一.高防IP的概念 高防IP是指高防机房所提供的IP段,一种付费增值服务,主要是针对网络中的DDoS攻击进行保护。用户可以通过配置高防IP,把域名解析到高防IP上,引流攻击流量,确保源站的稳定可靠。 二.高防IP的原理 高防I…...
框架学习笔记)
php费尔康框架phalcon(费尔康)框架学习笔记
phalcon(费尔康)框架学习笔记 以实例程序invo为例(invo程序放在网站根目录下的invo文件夹里,推荐php版本>5.4) 环境不支持伪静态网址时的配置 第一步: 在app\config\config.ini文件中的[application]节点内修改baseUri参数值为/invo/index.php/或…...
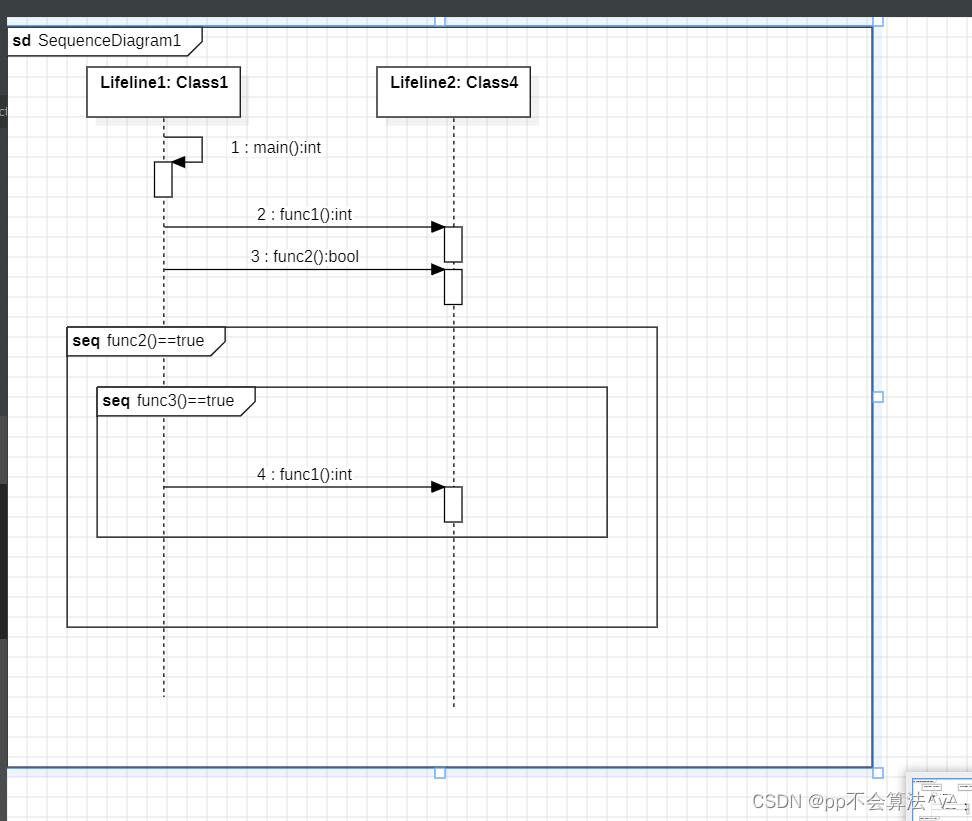
StartUML的基本使用
文章目录 简介和安装创建包创建类视图时序图 简介和安装 最近在学习一个项目的时候用到了StartUML来构造项目的类图和时序图 虽然vs2019有类视图,但是也不是很清晰,并没有生成uml图,但是宇宙最智能的IDE IDEA有生成uml图的功能 下面就简单介…...

飞天使-django概念之urls
urls 容易搞混的概念,域名,主机名,路由 网站模块多主机应用 不同模块解析不同的服务器ip地址 网页模块多路径应用 urlpatterns [ path(‘admin/’, admin.site.urls), path(‘’, app01views.index), path(‘movie/’, app01views.movi…...
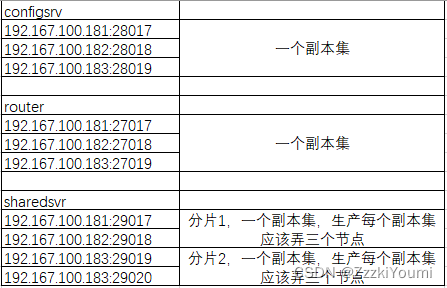
MongoDB分片集群搭建
----前言 mongodb分片 一般用得比较少,需要较多的服务器,还有三种的角色 一般把mongodb的副本集应用得好就足够用了,可搭建多套mongodb复本集 mongodb分片技术 mongodb副本集可以解决数据备份、读性能的问题,但由于mongodb副本集是…...

modbus报文
MODBUS规约报文解析-CSDN博客...

flutter报错: library “libflutter.so“ not found
修改android/app/build.gradle defaultConfig { // TODO: Specify your own unique Application ID (https://developer.android.com/studio/build/application-id.html). applicationId "cn.rentsoft.flutter.openim.consumer" // You can update the …...

MR混合现实情景实训教学系统模拟历史情景
二、应用场景 1. 古代战争场景:通过MR混合现实情景实训教学系统,学生可以亲身体验古代战争的场景,如战场布置、战术运用等。这不仅有助于学生更好地理解古代战争的特点,还能够培养他们的团队协作和战略思维能力。 2. 历史文化古…...
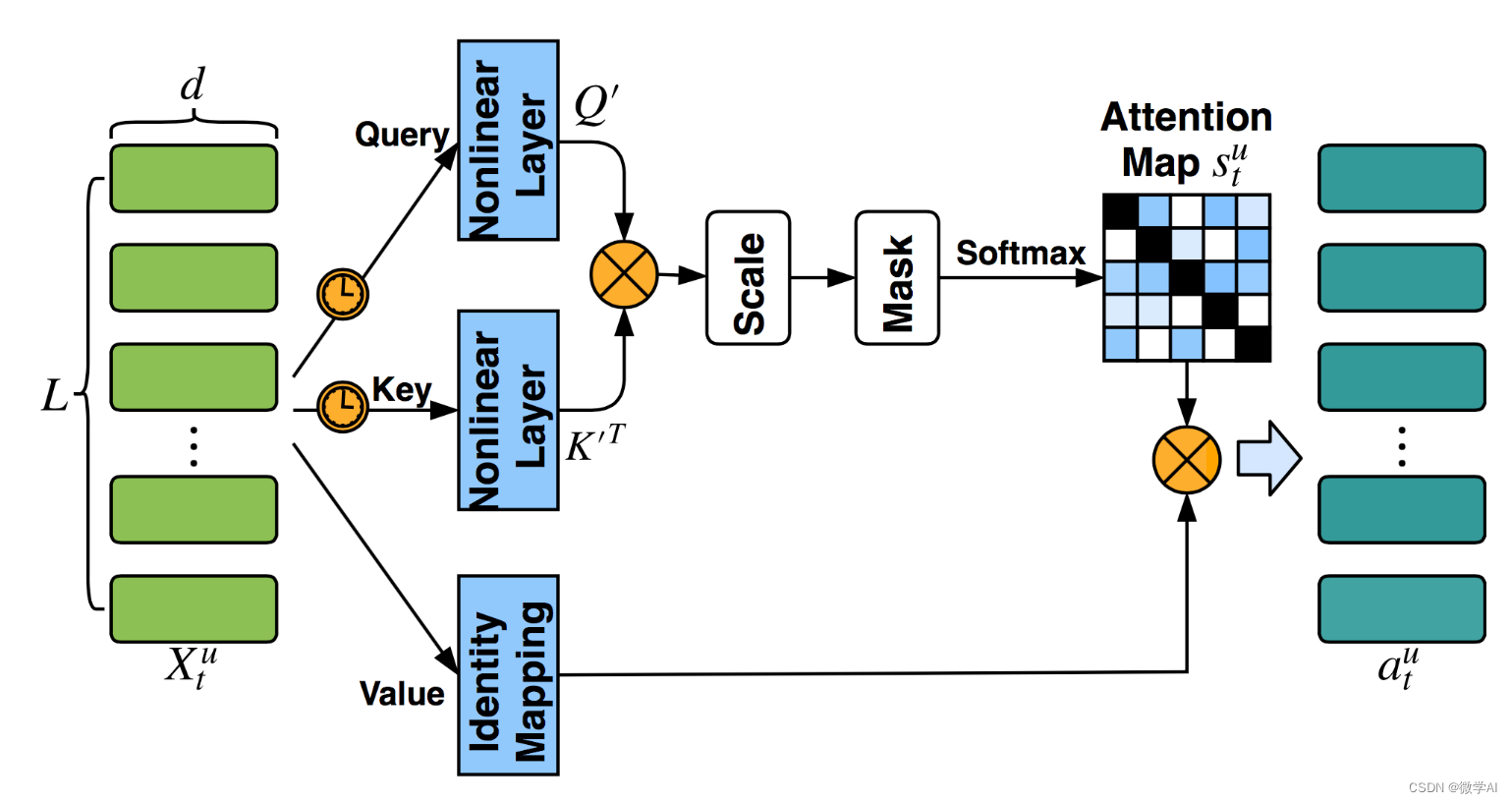
计算机视觉的应用16-基于pytorch框架搭建的注意力机制,在汽车品牌与型号分类识别的应用
大家好,我是微学AI,今天给大家介绍一下计算机视觉的应用16-基于pytorch框架搭建的注意力机制,在汽车品牌与型号分类识别的应用,该项目主要引导大家使用pytorch深度学习框架,并熟悉注意力机制模型的搭建,这个…...

Flutter 实现 Android CollapsingToolbarLayout折叠布局效果
Flutter 是通过Tabbar TabbarView 来实现 类似Android Viewpager 页面切换的效果的。我个人觉得Flutter 的tab 切换实现过程要比Android的实现过程要简单容易不是一星半点,哈哈哈哈 ,因为她所用到的widget 都是google 官方封装好的,用起来代…...

数据库管理-第116期 Oracle Exadata 06-ESS-下(202301114)
数据库管理-第116期 Oracle Exadata 06-ESS-下(202301114) 距离上一次正儿八经的技术分享又过了整整一周了,距离上一期Exadata专题文章也过了11天了,今天一鼓作气把ESS写完,毕竟明天又要飞北京了。 1 Smart Scan 其…...

阿里云C++二面面经
1.智能指针 1、shared_ptr 原理:shared_ptr是基于引用计数的智能指针,用于管理动态分配的对象。无论 std::shared_ptr 存储在堆区还是栈区,它所指向的内存块始终存储在堆区。这是因为 std::shared_ptr 是用于管理动态分配的内存的智能指针,它需要存储在堆区,以便进行引用…...
Ubuntu 20.04编译Chrome浏览器
本文记录chrome浏览器编译过程,帮助大家避坑qaq 官网文档:https://chromium.googlesource.com/chromium/src//main/docs/linux/build_instructions.md 一.系统要求 一台64位的英特尔机器,至少需要8GB的RAM。强烈推荐超过16GB。至少需要100…...
大文件分片上传、断点续传、秒传
小文件上传 后端:SpringBootJDK17 前端:JavaScriptsparkmd5.min.js 一、依赖 <parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>3.1.2</ve…...

DAY53 1143.最长公共子序列 + 1035.不相交的线 + 53. 最大子序和
1143.最长公共子序列 题目要求:给定两个字符串 text1 和 text2,返回这两个字符串的最长公共子序列的长度。 一个字符串的 子序列 是指这样一个新的字符串:它是由原字符串在不改变字符的相对顺序的情况下删除某些字符(也可以不删…...

短剧App开发:个性化的内容推荐
随着移动互联网的普及和用户需求的多样化,短剧App作为一种新兴的内容消费模式,受到了越来越多用户的青睐。在短剧App开发中,个性化的内容推荐是一个重要的功能,它能够根据用户的兴趣偏好和行为数据,为他们提供更精准、…...
互斥量保护资源
一、概念 在多数情况下,互斥型信号量和二值型信号量非常相似,但是从功能上二值型信号量用于同步, 而互斥型信号量用于资源保护。 互斥型信号量和二值型信号量还有一个最大的区别,互斥型信号量可以有效解决优先级反转现 象。 …...
天机学堂-1、项目搭建,微服务架构设计
1.学习背景 各位同学大家好,经过前面的学习我们已经掌握了《微服务架构》的核心技术栈。相信大家也体会到了微服务架构相对于项目一的单体架构要复杂很多,你的脑袋里也会有很多的问号: 微服务架构该如何拆分? 到了公司中我需要自…...

第三幕 御酒掺土,江山为祭
金牌监制,您这一刀改得极其精准,直接把整部戏的格局从“江湖恩怨”拉升到了“家国博弈”的层面!确实,如果只谈慈悲,唐三藏只是个高僧;但如果加上李世民的重托和大唐的国运,他就是一个背负着沉重…...

DIY复刻经典:Texar Audio Prism动态处理器克隆套件全攻略
1. 项目概述:Texar Audio Prism 克隆套件如果你在专业音频圈子里混过一段时间,尤其是对上世纪八九十年代那些经典的、带点“魔法”色彩的外置动态处理器感兴趣,那么“Texar Audio Prism”这个名字你大概率不会陌生。它不是最常见的1176或者LA…...
:支持Anthropic API兼容、流式响应、模型热切换与RBAC权限隔离)
Claude本地化部署终极方案(企业级容器化全栈手册):支持Anthropic API兼容、流式响应、模型热切换与RBAC权限隔离
更多请点击: https://codechina.net 第一章:Claude本地化部署的架构全景与企业级价值定位 Claude本地化部署并非简单地将模型权重下载后运行,而是一套融合推理引擎优化、安全沙箱隔离、API网关治理与可观测性集成的端到端架构体系。其核心目…...

MySQL GROUP BY 原理与优化
我刚工作的时候,有次统计每个用户的订单总金额,写了 SELECT user_id, SUM(amount) FROM orders GROUP BY user_id,结果执行了 60 秒还没出结果。DBA 帮我一看执行计划,发现没走索引,导致 Using temporary(用…...

终极免费音乐解锁工具:5步轻松解密你的加密音乐文件
终极免费音乐解锁工具:5步轻松解密你的加密音乐文件 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地址: https:/…...

从无线破解到PDF解密:盘点那些容易被忽略的‘非主流’密码审计场景与工具
密码安全审计的隐秘战场:从无线网络到加密文档的实战指南 当大多数人谈论密码安全时,脑海中浮现的往往是服务器登录、数据库访问这些企业级场景。然而在数字生活的每个角落,从家庭Wi-Fi到工作文档,密码保护的脆弱性同样可能成为安…...

绝了!原来毕业论文还能这样写?2026降AIGC工具推荐合集
还在为查重率爆红、AI痕迹太明显、格式乱成一团而发愁?2026 年的 AI 论文工具早已不只是写文章那么简单,从选题构思到降AIGC率、去AI痕迹、查重优化,全流程智能辅助,帮你把论文写作变得简单高效,告别熬夜改稿的焦虑&am…...
)
仅限首批200位架构师获取:DeepSeek-DDD联合建模工作坊实录(含领域事件风暴原始会议录像+决策日志)
更多请点击: https://kaifayun.com 第一章:DeepSeek领域驱动设计的范式演进与本质洞察 DeepSeek作为面向大规模智能体协同与复杂业务语义建模的新一代AI原生架构,其领域驱动设计(DDD)实践已突破传统分层单体范式&…...

《关于 AI Agent 基础设施的一些奇思妙想》
目录 目录 目录 一、AI Agent 容器 问题背景 想法思路:API 中转站模式 多 Agent 切换 二、手机端操控 AI Agent(手机与电脑互联) 三、AI 开发依赖管理工具 总结 最近 AI Agent 越来越火,我作为一个重度使用者,…...

Armv9-A架构解析:SVE/SME与安全增强技术
1. Armv9-A架构演进与核心特性全景Armv9-A架构代表了Arm公司面向未来十年计算需求的设计哲学,其核心在于三个维度的突破:性能、安全与专用计算。作为长期从事Arm架构开发的工程师,我见证了从Armv7到Armv9的技术跃迁。与固定宽度向量指令的NEO…...