云贝教育 |【技术文章】pg缓存插件介绍
一、pg_buffercache
主要作用是查看pg的共享池中缓存的对象信息
1.1 创建扩展
postgres=# create extension pg_buffercache;
CREATE EXTENSION1.2 查看视图pg_buffercache
postgres=# \d pg_buffercacheView "public.pg_buffercache"Column | Type | Collation | Nullable | Default
------------------+----------+-----------+----------+---------bufferid | integer | | | relfilenode | oid | | | reltablespace | oid | | | reldatabase | oid | | | relforknumber | smallint | | | relblocknumber | bigint | | | isdirty | boolean | | | usagecount | smallint | | | pinning_backends | integer | | |1.3 要看当前模式下的表
postgres=# \dList of relationsSchema | Name | Type | Owner
--------+----------------+-------+----------public | pg_buffercache | view | postgrespublic | t1 | table | postgres
(2 rows)1.4 查看t1表在当前pg缓存中的信息
postgres=# select count(1) from pg_buffercache where relfilenode='t1'::regclass;count
-------0
(1 row)0表示没有缓存
1.5 查询一次t1表
postgres=# select count(1) from t1;count
-------1
(1 row)postgres=# select count(1) from pg_buffercache where relfilenode='t1'::regclass;count
-------1
(1 row)1.6 查看T1表缓存情况
postgres=# select * from pg_buffercache where relfilenode='t1'::regclass;bufferid | relfilenode | reltablespace | reldatabase | relforknumber | relblocknumber | isdirty | usagecount | pinning_backends
----------+-------------+---------------+-------------+---------------+----------------+---------+------------+------------------1006 | 16388 | 1663 | 5 | 0 | 0 | f | 1 | 0
(1 row)有记录表示被缓存
isdirty :f表示不是脏块
1.7 修改表t1数据
postgres=# update t1 set id=22 where id=1;
UPDATE 11.8 对比缓存的块是否变脏
postgres=# select * from pg_buffercache where relfilenode='t1'::regclass;bufferid | relfilenode | reltablespace | reldatabase | relforknumber | relblocknumber | isdirty | usagecount | pinning_backends
----------+-------------+---------------+-------------+---------------+----------------+---------+------------+------------------1006 | 16388 | 1663 | 5 | 0 | 0 | t | 2 | 0
(1 row)isdirty :t表示脏块
二、pg_prevarm
预热功能使用pg_prevarm函数,方便将数据缓存到OS缓存中或PG缓存中
比如生产系统中,数据库重启了,此时发起的业务SQL,就会发生物理读
语法
pg_prewarm(regclass, --预热的relationmode text default 'buffer', --使用预热的方法fork text derfault 'main', --relation fork被预热first_block int8 default null, --预热的第一块号last_block int8 default null --预热的最后一个块号
) return int8;prefetch/read:缓存到os cache
buffer:缓存到os cache和pg shared buffers参数说明:
regclass :数据库对像,通常情况为表名
mode :加载模式
-
prefetch:异步地将数据预加载到操作系统缓存
-
read:最终结果和 prefetch 一样,但它是同步方式,支持所有平台
-
buffer:将数据预加载到数据库缓存
fork
main :主表
fsm:空间空间地图
vm:可见性地图
first_block :开始prewarm的数据块
last_block :最后 prewarm 的数据块
2.1 创建prewarm插件
create EXTENSION pg_prewarm2.2 在默认shared_buffer参数,创建一张大表
testdb=# show shared_buffers;shared_buffers
----------------128MB
(1 row)testdb=# create table t1 ( id int,name varchar(100),c1 varchar(200),c2 varchar(200));
CREATE TABLE
testdb=# insert into t1 select id,md5(id::varchar),md5(md5(id::varchar)),md5(md5(md5(id::varchar))) from generate_series(1,10000000) as id;
INSERT 0 100000002.3 在没有OS和PG缓存的情况下
(一)不进行prewarm
1、查看表体积
testdb=# \d t1Table "public.t1"Column | Type | Collation | Nullable | Default
--------+------------------------+-----------+----------+---------id | integer | | | name | character varying(100) | | | c1 | character varying(200) | | | c2 | character varying(200) | | | testdb=# \dt+ t1List of relationsSchema | Name | Type | Owner | Persistence | Access method | Size | Descr
iption
--------+------+-------+----------+-------------+---------------+---------+-------------public | t1 | table | postgres | permanent | heap | 1281 MB |
(1 row)testdb=# SELECT pg_size_pretty(pg_total_relation_size('t1'));pg_size_pretty
----------------1281 MB
(1 row)2、重启数据库并消除OS缓存
pg_ctl restartecho 3 > /proc/sys/vm/drop_caches3、查看执行计划
testdb=# explain analyze select count(*) from t1;QUERY PLAN
-------------------------------------------------------------------------------------------------------------------------------------------Finalize Aggregate (cost=217018.73..217018.74 rows=1 width=8) (actual time=3584.950..3585.012 rows=1 loops=1)-> Gather (cost=217018.52..217018.73 rows=2 width=8) (actual time=3584.897..3584.981 rows=3 loops=1)Workers Planned: 2Workers Launched: 2-> Partial Aggregate (cost=216018.52..216018.53 rows=1 width=8) (actual time=3559.160..3559.160 rows=1 loops=3)-> Parallel Seq Scan on t1 (cost=0.00..205601.81 rows=4166681 width=0) (actual time=0.193..3373.351 rows=3333333 loops=3)Planning Time: 4.743 msExecution Time: 3586.400 ms
(8 rows)缓存1G的数据,耗时3586.400 ms
(二)进行prewarm
分别测试read和buffer模式下的效果
1、重启数据库并消除OS缓存
pg_ctl restartecho 3 > /proc/sys/vm/drop_caches2、预热数据到OS缓存
testdb=# select pg_prewarm('t1', 'read', 'main');pg_prewarm
------------163935
(1 row)3、查看执行计划
testdb=# explain analyze select count(*) from t1;QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------------------Finalize Aggregate (cost=217018.73..217018.74 rows=1 width=8) (actual time=657.884..658.970 rows=1 loops=1)-> Gather (cost=217018.52..217018.73 rows=2 width=8) (actual time=657.516..658.959 rows=3 loops=1)Workers Planned: 2Workers Launched: 2-> Partial Aggregate (cost=216018.52..216018.53 rows=1 width=8) (actual time=652.264..652.265 rows=1 loops=3)-> Parallel Seq Scan on t1 (cost=0.00..205601.81 rows=4166681 width=0) (actual time=0.092..405.615 rows=3333333 loops=3)Planning Time: 0.126 msExecution Time: 658.997 ms
(8 rows)4、预热到数据库缓存中
testdb=# select pg_prewarm('t1', 'buffer', 'main');pg_prewarm
------------163935
(1 row)5、查看执行计划
testdb=# explain analyze select count(*) from t1;QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------------------Finalize Aggregate (cost=217018.73..217018.74 rows=1 width=8) (actual time=681.629..683.325 rows=1 loops=1)-> Gather (cost=217018.52..217018.73 rows=2 width=8) (actual time=681.485..683.319 rows=3 loops=1)Workers Planned: 2Workers Launched: 2-> Partial Aggregate (cost=216018.52..216018.53 rows=1 width=8) (actual time=674.079..674.080 rows=1 loops=3)-> Parallel Seq Scan on t1 (cost=0.00..205601.81 rows=4166681 width=0) (actual time=0.025..445.632 rows=3333333 loops=3)Planning Time: 0.039 msExecution Time: 683.353 ms
(8 rows)缓存1G的数据,耗时683.353 ms
总结:缓存到OS缓存中和PG缓存中,两者性能差异不大。但比不预热的情况下效果提升明显。
| 预热 | 参数 | 耗时 |
| 否 | 无 | 3586.400 ms |
| 是 | read | 658.997 ms |
| 是 | buffer | 683.353 ms |
三、pgfincore( )
将数据库对象CACHE到OS层面的缓存
3.1 安装插件
testdb=# CREATE EXTENSION pgfincore;
CREATE EXTENSION3.2 查看对象缓存信息
testdb=# select * from pgfincore ('t1'); relpath | segment | os_page_size | rel_os_pages | pages_mem | group_mem | os_pages_free | databit | pages_dirty | group_dirty
--------------------+---------+--------------+--------------+-----------+-----------+---------------+---------+-------------+-------------base/16391/33102 | 0 | 4096 | 262144 | 262144 | 1 | 1191325 | | 0 | 0base/16391/33102.1 | 1 | 4096 | 65726 | 65726 | 1 | 1191325 | | 0 | 0
(2 rows)参数说明
-
relpath:文件位置及名称
-
segment:文件段编号
-
os_page_size:OS page或block大小
-
rel_os_pages:对象占用系统缓存需要的页面个数
-
pages_mem:对象已经占用缓存页面个数
-
group_mem:在缓存中连续的页面组的个数
-
os_pages_free:OS剩余的page数
-
databit:加载信息的位图
pgsysconf与pgsysconf_pretty
查看当前OS块大小及使用情况
testdb=# select * from pgsysconf(); os_page_size | os_pages_free | os_total_pages
--------------+---------------+----------------4096 | 1190139 | 1997572
(1 row)testdb=# select * from pgsysconf_pretty();os_page_size | os_pages_free | os_total_pages
--------------+---------------+----------------4096 bytes | 4649 MB | 7803 MB
(1 row)pgfadvise_willneed
将数据库对象缓存到OS CACHE
testdb=# select * from pgfadvise_willneed('t1'); relpath | os_page_size | rel_os_pages | os_pages_free
--------------------+--------------+--------------+---------------base/16391/33102 | 4096 | 262144 | 1190033base/16391/33102.1 | 4096 | 65726 | 1190033
(2 rows)pgfadvise_dontneed
将数据库对象刷出OS CACHE
对当前对象设置dontneed标记。dontneed标记的意思就是当操作系统需要释放内存时优先释放标记为dontneed的pages。
testdb=# select * from pgfadvise_dontneed('t1');relpath | os_page_size | rel_os_pages | os_pages_free
--------------------+--------------+--------------+---------------base/16391/33102 | 4096 | 262144 | 1452085base/16391/33102.1 | 4096 | 65726 | 1517801
(2 rows)testdb=# select * from pgfincore ('t1'); relpath | segment | os_page_size | rel_os_pages | pages_mem | group_mem | os_pages_free | databit | pages_dirty | group_dirty
--------------------+---------+--------------+--------------+-----------+-----------+---------------+---------+-------------+-------------base/16391/33102 | 0 | 4096 | 262144 | 0 | 0 | 1517805 | | 0 | 0base/16391/33102.1 | 1 | 4096 | 65726 | 0 | 0 | 1517805 | | 0 | 0
(2 rows)相关文章:

云贝教育 |【技术文章】pg缓存插件介绍
一、pg_buffercache 主要作用是查看pg的共享池中缓存的对象信息 1.1 创建扩展 postgres# create extension pg_buffercache; CREATE EXTENSION 1.2 查看视图pg_buffercache postgres# \d pg_buffercacheView "public.pg_buffercache"Column | Type | Co…...

Kohana框架的安装及部署
Kohana框架的安装及部署 tipsKohana安装以及部署1、重要文件作用说明1.1 /index.php1.2 /application/bootstrap.php 2、项目结构3、路由配置3.1、隐藏项目入口的路由3.2、配置默认路由3.3、配置自定义的路由(Controller目录下的控制器)3.4、配置自定义的路由(Controller/direc…...

无重复字符的最长子串 Golang leecode_3
刚开始的思路,先不管效率,跑出来再说,然后再进行优化。然后就有了下面的暴力代码: func lengthOfLongestSubstring(s string) int {// count 用来记录当前最长子串长度var count int// flag 用来对下面两个 if 语句分流var flag …...
Vue项目的学习一
1、Vue项目里面的.js文件里面对象添加属性 例如:在对象:row,需要在对象row里面添加一个属性状态:type,使用里面的Vue.set函数 Vue.set(参数1,参数2,参数3) Vue.set(row,type,false)解析: 参数1࿱…...

k8s备份
cpu 磁盘io 往主的写,同步给备 rootk8s-etcd02:~# cat /etc/systemd/system/etcd.service [Unit] DescriptionEtcd Server Afternetwork.target Afternetwork-online.target Wantsnetwork-online.target Documentationhttps://github.com/coreos[Service] Typen…...

python自己造轮子使用
项目结构 首先,需要按照下列格式组织你的 package project (项目名称,随意,与package无关)|----package (这个才是包名)|----…...

Elastic stack8.10.4搭建、启用安全认证,启用https,TLS,SSL 安全配置详解
ELK大家应该很了解了,废话不多说开始部署 kafka在其中作为消息队列解耦和让logstash高可用 kafka和zk 的安装可以参考这篇文章 深入理解Kafka3.6.0的核心概念,搭建与使用-CSDN博客 第一步、官网下载安装包 需要 elasticsearch-8.10.4 logstash-8.…...
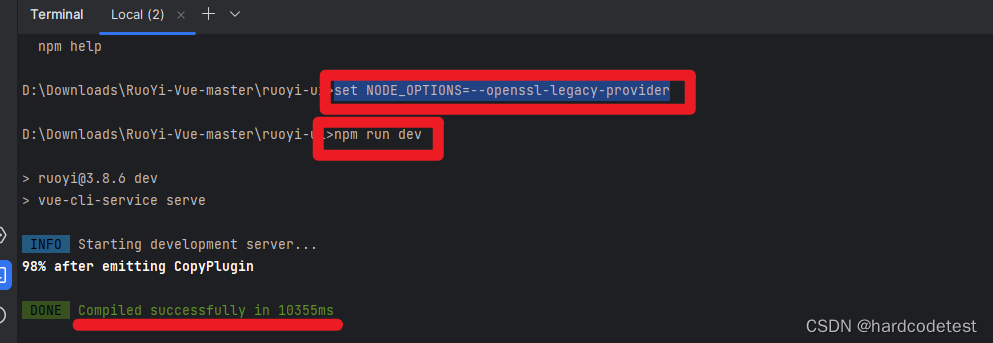
解决npm报错Error: error:0308010C:digital envelope routines::unsupported
解决npm报错Error: error:0308010C:digital envelope routines::unsupported。 解决办法;终端执行以下命令(windows): set NODE_OPTIONS--openssl-legacy-provider然后再执行 npm命令成功:...

高防IP是什么?有什么优势?
一.高防IP的概念 高防IP是指高防机房所提供的IP段,一种付费增值服务,主要是针对网络中的DDoS攻击进行保护。用户可以通过配置高防IP,把域名解析到高防IP上,引流攻击流量,确保源站的稳定可靠。 二.高防IP的原理 高防I…...
框架学习笔记)
php费尔康框架phalcon(费尔康)框架学习笔记
phalcon(费尔康)框架学习笔记 以实例程序invo为例(invo程序放在网站根目录下的invo文件夹里,推荐php版本>5.4) 环境不支持伪静态网址时的配置 第一步: 在app\config\config.ini文件中的[application]节点内修改baseUri参数值为/invo/index.php/或…...
StartUML的基本使用
文章目录 简介和安装创建包创建类视图时序图 简介和安装 最近在学习一个项目的时候用到了StartUML来构造项目的类图和时序图 虽然vs2019有类视图,但是也不是很清晰,并没有生成uml图,但是宇宙最智能的IDE IDEA有生成uml图的功能 下面就简单介…...

飞天使-django概念之urls
urls 容易搞混的概念,域名,主机名,路由 网站模块多主机应用 不同模块解析不同的服务器ip地址 网页模块多路径应用 urlpatterns [ path(‘admin/’, admin.site.urls), path(‘’, app01views.index), path(‘movie/’, app01views.movi…...
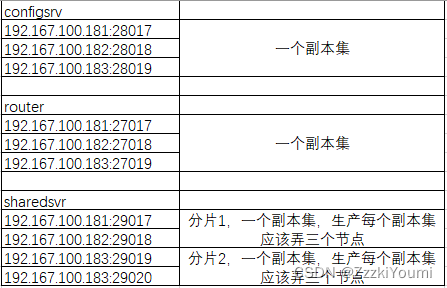
MongoDB分片集群搭建
----前言 mongodb分片 一般用得比较少,需要较多的服务器,还有三种的角色 一般把mongodb的副本集应用得好就足够用了,可搭建多套mongodb复本集 mongodb分片技术 mongodb副本集可以解决数据备份、读性能的问题,但由于mongodb副本集是…...

modbus报文
MODBUS规约报文解析-CSDN博客...

flutter报错: library “libflutter.so“ not found
修改android/app/build.gradle defaultConfig { // TODO: Specify your own unique Application ID (https://developer.android.com/studio/build/application-id.html). applicationId "cn.rentsoft.flutter.openim.consumer" // You can update the …...

MR混合现实情景实训教学系统模拟历史情景
二、应用场景 1. 古代战争场景:通过MR混合现实情景实训教学系统,学生可以亲身体验古代战争的场景,如战场布置、战术运用等。这不仅有助于学生更好地理解古代战争的特点,还能够培养他们的团队协作和战略思维能力。 2. 历史文化古…...
计算机视觉的应用16-基于pytorch框架搭建的注意力机制,在汽车品牌与型号分类识别的应用
大家好,我是微学AI,今天给大家介绍一下计算机视觉的应用16-基于pytorch框架搭建的注意力机制,在汽车品牌与型号分类识别的应用,该项目主要引导大家使用pytorch深度学习框架,并熟悉注意力机制模型的搭建,这个…...

Flutter 实现 Android CollapsingToolbarLayout折叠布局效果
Flutter 是通过Tabbar TabbarView 来实现 类似Android Viewpager 页面切换的效果的。我个人觉得Flutter 的tab 切换实现过程要比Android的实现过程要简单容易不是一星半点,哈哈哈哈 ,因为她所用到的widget 都是google 官方封装好的,用起来代…...

数据库管理-第116期 Oracle Exadata 06-ESS-下(202301114)
数据库管理-第116期 Oracle Exadata 06-ESS-下(202301114) 距离上一次正儿八经的技术分享又过了整整一周了,距离上一期Exadata专题文章也过了11天了,今天一鼓作气把ESS写完,毕竟明天又要飞北京了。 1 Smart Scan 其…...

阿里云C++二面面经
1.智能指针 1、shared_ptr 原理:shared_ptr是基于引用计数的智能指针,用于管理动态分配的对象。无论 std::shared_ptr 存储在堆区还是栈区,它所指向的内存块始终存储在堆区。这是因为 std::shared_ptr 是用于管理动态分配的内存的智能指针,它需要存储在堆区,以便进行引用…...
)
保姆级教程:Windows系统下Arcgis 10.2从下载、安装到汉化一次搞定(附常见License启动失败解决方案)
Windows系统下Arcgis 10.2完整安装与汉化实战指南第一次接触Arcgis的新手往往会被复杂的安装流程和神秘的License Manager搞得晕头转向。作为一款功能强大的地理信息系统软件,Arcgis在科研、城市规划、环境监测等领域有着广泛应用,但它的安装过程确实会让…...

破解材料数据荒:合成数据与随机森林预测聚合物阻燃性能
1. 项目概述与核心挑战在材料研发领域,尤其是涉及公共安全的聚合物阻燃性研究,传统实验方法正面临巨大瓶颈。想象一下,你是一位材料工程师,需要设计一种用于高铁内饰或高层建筑电缆护套的新型聚合物,其阻燃性能必须满足…...

交流电机驱动器的三种控制模式:前沿切相、后沿切相与同步模式详解
1. 项目概述:一个能玩出花的交流电机驱动器在汽车改装、工业控制或者一些创客项目里,驱动一个交流电机听起来简单,但想让它听话地变速、正反转,甚至实现软启动和精确同步,往往就得搬出笨重又昂贵的工业变频器。今天分享…...

WarcraftHelper终极指南:深度解析魔兽争霸III现代化兼容性解决方案
WarcraftHelper终极指南:深度解析魔兽争霸III现代化兼容性解决方案 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper WarcraftHelper是一款专…...

INT8量化下TVA注意力对齐精度保障方案
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...

对比不同模型在创意生成任务中的效果与token消耗差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比不同模型在创意生成任务中的效果与token消耗差异 在为一场创意大赛准备素材时,我们面临一个常见的选择:…...

Driver Store Explorer终极指南:轻松管理Windows驱动存储区,释放宝贵磁盘空间
Driver Store Explorer终极指南:轻松管理Windows驱动存储区,释放宝贵磁盘空间 【免费下载链接】DriverStoreExplorer Driver Store Explorer 项目地址: https://gitcode.com/gh_mirrors/dr/DriverStoreExplorer 你是否曾为Windows系统越来越慢而烦…...

告别Windows卡顿!在VMware里给Kubuntu 22.04 LTS分区和安装的保姆级避坑指南
告别Windows卡顿!在VMware里给Kubuntu 22.04 LTS分区和安装的保姆级避坑指南你是否已经厌倦了Windows系统越来越慢的启动速度、频繁的后台更新和资源占用?当你的电脑开始频繁卡顿,或许该考虑给系统来一次"减负"了。Kubuntu 22.04 L…...

如何让旧款Mac运行最新系统:OpenCore Legacy Patcher完整指南
如何让旧款Mac运行最新系统:OpenCore Legacy Patcher完整指南 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 想让你的老旧Mac设备重新焕发活力&a…...

Mysql?基础语法!!!
作为程序员、数据分析从业者,甚至是产品运营,SQL都是必须掌握的核心技能。不管是后端开发对数据库增删改查,还是数据分析提取业务数据,本质都是在写SQL语句。很多新手觉得SQL难,其实是没有理清逻辑。SQL的核心逻辑非常…...