5 逻辑回归及Python实现
1 主要思想
分类就是分割数据:
- 两个条件属性:直线;
- 三个条件属性:平面;
- 更多条件属性:超平面。
使用数据:
5.1,3.5,0
4.9,3,0
4.7,3.2,0
4.6,3.1,0
5,3.6,0
5.4,3.9,0
. . .
6.2,2.9,1
5.1,2.5,1
5.7,2.8,1
6.3,3.3,1
2 理论
2.1 线性分割面的表达
平面几何表达直线(两个系数):
y=ax+b.y = ax + b.y=ax+b.
重新命名变量:
w0+w1x1+w2x2=0.w_0 + w_1 x_1 + w_2 x_2 = 0.w0+w1x1+w2x2=0.
强行加一个x0≡1x_0 \equiv 1x0≡1:
w0x0+w1x1+w2x2=0.w_0 x_0 + w_1 x_1 + w_2 x_2 = 0.w0x0+w1x1+w2x2=0.
向量表达(x\mathbf{x}x为行向量, w\mathbf{w}w为列向量,)
xw=0.\mathbf{xw} = 0.xw=0.
2.2 学习与分类
- Logistic regression的学习任务,就是计算向量w\mathbf{w}w;
- 分类(两个类别):对于新对象x′\mathbf{x}'x′,计算x′w\mathbf{x}'\mathbf{w}x′w,结果小于0则为0类,否则为1类;
- 线性模型(加权和)是机器学习诸多主流方法的核心。
2.3 基本思路
2.3.1 第一种损失函数:
w\mathbf{w}w在训练集中(X,Y)(\mathbf{X}, \mathbf{Y})(X,Y)表现要好。
Heaviside跃迁函数为
H(z)={0,if z<0,12,if z=0,1,otherwise.H(z) = \left\{\begin{array}{ll} 0, & \textrm{ if } z < 0,\\ \frac{1}{2}, & \textrm{ if } z = 0,\\ 1, & \textrm{ otherwise.} \end{array}\right. H(z)=⎩⎨⎧0,21,1, if z<0, if z=0, otherwise.
令X={x1,…,xm}\mathbf{X} = \{\mathbf{x}_1, \dots, \mathbf{x}_m\}X={x1,…,xm}, 错误率即:
1m∑i=1m∣H(xiw)−yi∣,\frac{1}{m}\sum_{i = 1}^m |H(\mathbf{x}_i\mathbf{w}) - y_i|, m1i=1∑m∣H(xiw)−yi∣,
其中H(xiw)H(\mathbf{x}_i\mathbf{w})H(xiw)是分类器给的标签,而yiy_iyi是实际标签。
- 优点:表达了错误率;
- 缺点:函数HHH不连续,无法使用优化理论。
2.3.2 第二种损失函数
Sigmoid函数:
σ(z)=11+e−z.\sigma(z) = \frac{1}{1 + e^{-z}}. σ(z)=1+e−z1.
优点:连续,可导。
Sigmoid函数的导数:
σ′(z)=ddz11+e−z=−1(1+e−z)2(e−z)(−1)=e−z(1+e−z)2=11+e−z(1−11+e−z)=σ(z)(1−σ(z)).\begin{array}{ll} \sigma'(z) & = \frac{d}{dz}\frac{1}{1 + e^{-z}}\\ & = - \frac{1}{(1 + e^{-z})^2} (e^{-z}) (-1)\\ & = \frac{e^{-z}}{(1 + e^{-z})^2} \\ & = \frac{1}{1 + e^{-z}} (1 - \frac{1}{1 + e^{-z}}) \\ &= \sigma(z) (1 - \sigma(z)). \end{array} σ′(z)=dzd1+e−z1=−(1+e−z)21(e−z)(−1)=(1+e−z)2e−z=1+e−z1(1−1+e−z1)=σ(z)(1−σ(z)).
令y^i=σ(xiw)\hat{y}_i = \sigma(\mathbf{x}_i\mathbf{w})y^i=σ(xiw),
1m∑i=1m12(y^i−yi)2,\frac{1}{m} \sum_{i = 1}^m \frac{1}{2}(\hat{y}_i - y_i)^2, m1i=1∑m21(y^i−yi)2,
其中平方使得函数连续可导,12\frac{1}{2}21是为了适应求导的惯用手法。
缺点:非凸优化, 多个局部最优解
2.3.3 凸与非凸
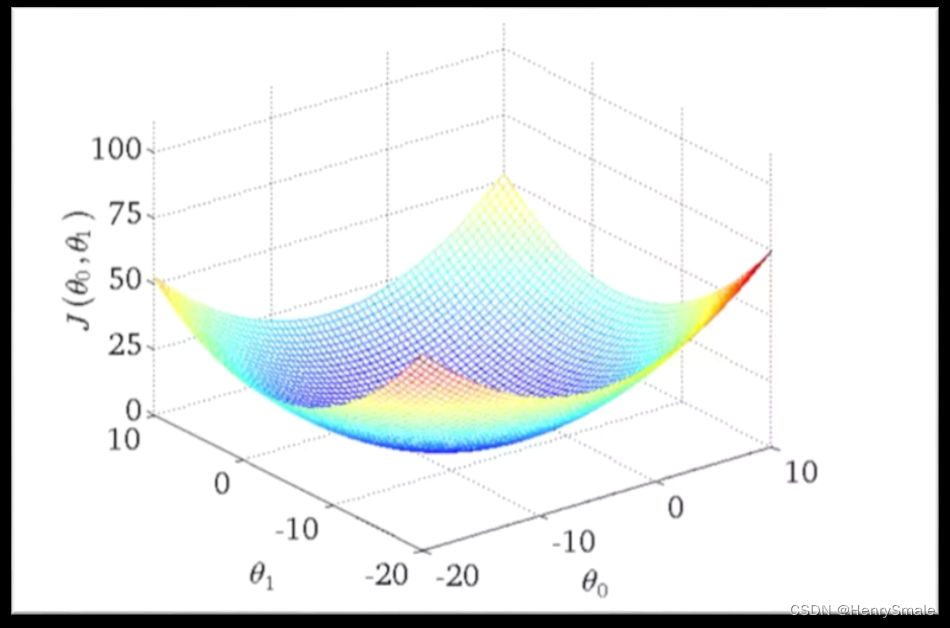
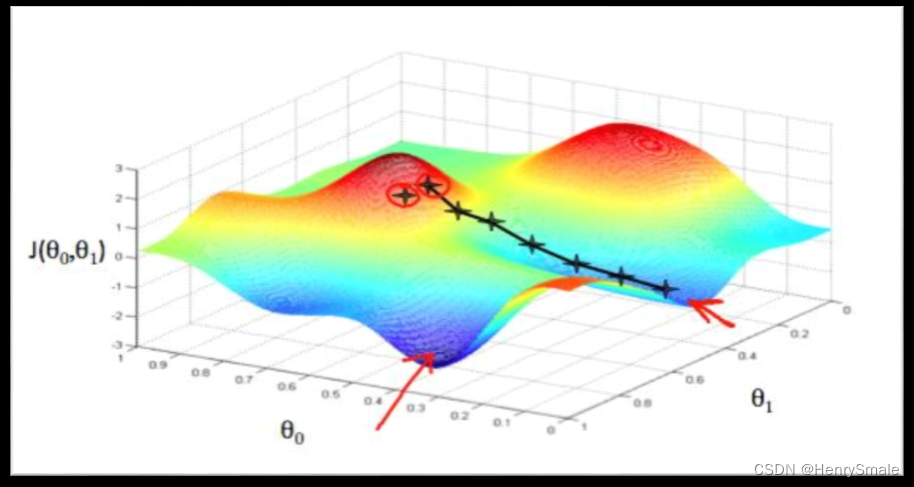
2.3.4 第三种损失函数(强行看作概率)
由于0<σ(z)<10 < \sigma(z) < 10<σ(z)<1, 将σ(xiw)\sigma(\mathbf{x}_i \mathbf{w})σ(xiw)看作类别为1的概率, 即
P(yi=1∣xi;w)=σ(xiw),P(y_i = 1 | \mathbf{x}_i; \mathbf{w}) = \sigma(\mathbf{x}_i \mathbf{w}), P(yi=1∣xi;w)=σ(xiw),
其中xi\mathbf{x}_ixi是条件, w\mathbf{w}w是参数。
相应地
P(yi=0∣xi;w)=1−σ(xiw),P(y_i = 0 | \mathbf{x}_i; \mathbf{w}) = 1 - \sigma(\mathbf{x}_i \mathbf{w}), P(yi=0∣xi;w)=1−σ(xiw),
综合上两式, 可得
P(yi∣xi;w)=(σ(xiw))yi(1−σ(xiw))1−yiP(y_i | \mathbf{x}_i; \mathbf{w}) = (\sigma(\mathbf{x}_i \mathbf{w}))^{y_i} (1 - \sigma(\mathbf{x}_i \mathbf{w}))^{1 - y_i} P(yi∣xi;w)=(σ(xiw))yi(1−σ(xiw))1−yi
该值越大越好。
假设训练样本独立, 且同等重要。
为获得全局最优, 将不同样本涉及的概率连乘, 获得似然函数:
L(w)=P(Y∣X;w)=∏i=1mP(yi∣xi;w)=∏i=1m(σ(xiw))yi(1−σ(xiw))1−yi\begin{array}{ll} L(\mathbf{w}) & = P(\mathbf{Y} | \mathbf{X}; \mathbf{w})\\ & = \prod_{i = 1}^m P(y_i | \mathbf{x}_i; \mathbf{w})\\ & = \prod_{i = 1}^m (\sigma(\mathbf{x}_i \mathbf{w}))^{y_i} (1 - \sigma(\mathbf{x}_i \mathbf{w}))^{1 - y_i} \end{array} L(w)=P(Y∣X;w)=∏i=1mP(yi∣xi;w)=∏i=1m(σ(xiw))yi(1−σ(xiw))1−yi
对数函数具有单调性:
l(w)=logL(w)=log∏i=1mP(yi∣xi;w)=∑i=1myilogσ(xiw)+(1−yi)log(1−σ(xiw))\begin{array}{ll} l(\mathbf{w}) & = \log L(\mathbf{w})\\ & = \log \prod_{i = 1}^m P(y_i | \mathbf{x}_i; \mathbf{w})\\ & = \sum_{i = 1}^m {y_i} \log \sigma(\mathbf{x}_i \mathbf{w}) + (1 - y_i) \log (1 - \sigma(\mathbf{x}_i \mathbf{w})) \end{array} l(w)=logL(w)=log∏i=1mP(yi∣xi;w)=∑i=1myilogσ(xiw)+(1−yi)log(1−σ(xiw))
平均损失:
- L(w)L(\mathbf{w})L(w), l(w)l(\mathbf{w})l(w)越大越好;
- l(w)l(\mathbf{w})l(w)为负值;
- 求相反数, 除以实例个数, 损失函数:
1m∑i=1m−yilogσ(xiw)−(1−yi)log(1−σ(xiw)).\frac{1}{m} \sum_{i = 1}^m - {y_i} \log \sigma(\mathbf{x}_i \mathbf{w}) - (1 - y_i) \log (1 - \sigma(\mathbf{x}_i \mathbf{w})). m1i=1∑m−yilogσ(xiw)−(1−yi)log(1−σ(xiw)).
分析:
- yi=0y_i = 0yi=0 时退化为−log(1−σ(xiw))- \log(1 - \sigma(\mathbf{x}_i \mathbf{w}))−log(1−σ(xiw)), σ(xiw)\sigma(\mathbf{x}_i \mathbf{w})σ(xiw)越接近0越损失越小;
- yi=1y_i = 1yi=1 时退化为−logσ(xiw)- \log \sigma(\mathbf{x}_i \mathbf{w})−logσ(xiw), σ(xiw)\sigma(\mathbf{x}_i \mathbf{w})σ(xiw)越接近1越损失越小。
优化目标:
minw1m∑i=1m−yilogσ(xiw)−(1−yi)log(1−σ(xiw)).\min_\mathbf{w} \frac{1}{m} \sum_{i = 1}^m - {y_i} \log \sigma(\mathbf{x}_i \mathbf{w}) - (1 - y_i) \log (1 - \sigma(\mathbf{x}_i \mathbf{w})). wminm1i=1∑m−yilogσ(xiw)−(1−yi)log(1−σ(xiw)).
2.4 梯度下降法
梯度下降法是机器学习的一种主流优化方法
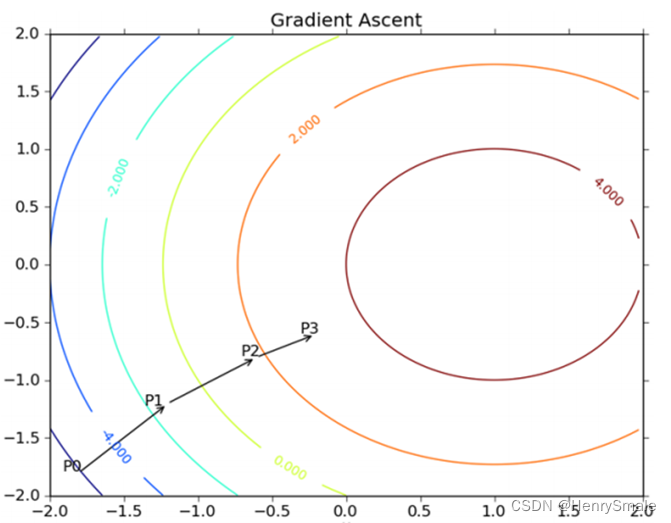
迭代式推导:
由于
l(w)=∑i=1myilogσ(xiw)+(1−yi)log(1−σ(xiw))l(\mathbf{w}) = \sum_{i = 1}^m y_i \log \sigma(\mathbf{x}_i \mathbf{w}) + (1 - y_i) \log (1 - \sigma(\mathbf{x}_i \mathbf{w})) l(w)=i=1∑myilogσ(xiw)+(1−yi)log(1−σ(xiw))
∂l(w)∂wj=∑i=1m(yiσ(xiw)−1−yi1−σ(xiw))∂σ(xiw)∂wj=∑i=1m(yiσ(xiw)−1−yi1−σ(xiw))σ(xiw)(1−σ(xiw))∂xiw∂wj=∑i=1m(yiσ(xiw)−1−yi1−σ(xiw))σ(xiw)(1−σ(xiw))xij=∑i=1m(yi−σ(xiw))xij\begin{array}{ll} \frac{\partial l(\mathbf{w})}{\partial w_j} & = \sum_{i = 1}^m \left(\frac{y_i}{\sigma(\mathbf{x}_i \mathbf{w})} - \frac{1 - y_i}{1 - \sigma(\mathbf{x}_i \mathbf{w})}\right) \frac{\partial \sigma(\mathbf{x}_i \mathbf{w})}{\partial w_j}\\ & = \sum_{i = 1}^m \left(\frac{y_i}{\sigma(\mathbf{x}_i \mathbf{w})} - \frac{1 - y_i}{1 - \sigma(\mathbf{x}_i \mathbf{w})}\right) \sigma(\mathbf{x}_i \mathbf{w}) (1 - \sigma(\mathbf{x}_i \mathbf{w})) \frac{\partial \mathbf{x}_i \mathbf{w}}{\partial w_j}\\ & = \sum_{i = 1}^m \left(\frac{y_i}{\sigma(\mathbf{x}_i \mathbf{w})} - \frac{1 - y_i}{1 - \sigma(\mathbf{x}_i \mathbf{w})}\right) \sigma(\mathbf{x}_i \mathbf{w}) (1 - \sigma(\mathbf{x}_i \mathbf{w})) x_{ij}\\ & = \sum_{i = 1}^m (y_i - \sigma(\mathbf{x}_i \mathbf{w})) x_{ij} \end{array} ∂wj∂l(w)=∑i=1m(σ(xiw)yi−1−σ(xiw)1−yi)∂wj∂σ(xiw)=∑i=1m(σ(xiw)yi−1−σ(xiw)1−yi)σ(xiw)(1−σ(xiw))∂wj∂xiw=∑i=1m(σ(xiw)yi−1−σ(xiw)1−yi)σ(xiw)(1−σ(xiw))xij=∑i=1m(yi−σ(xiw))xij
3 程序分析
3.1 Sigmoid函数
return 1.0/(1 + np.exp(-paraX))
3.2 使用sklearn
#Test my implemenation of Logistic regression and existing one.
import time, sklearn
import sklearn.datasets, sklearn.neighbors, sklearn.linear_model
import matplotlib.pyplot as plt
import numpy as np"""
The version using sklearn,支持多个决策属性值
"""
def sklearnLogisticTest():#Step 1. Load the datasettempDataset = sklearn.datasets.load_iris()x = tempDataset.datay = tempDataset.target#Step 2. ClassifytempClassifier = sklearn.linear_model.LogisticRegression()tempStartTime = time.time()tempClassifier.fit(x, y)tempScore = tempClassifier.score(x, y)tempEndTime = time.time()tempRuntime = tempEndTime - tempStartTime#Step 3. Outputprint('sklearn score: {}, runtime = {}'.format(tempScore, tempRuntime))"""
The sigmoid function, map to range (0, 1)
"""
def sigmoid(paraX):return 1.0/(1 + np.exp(-paraX))"""
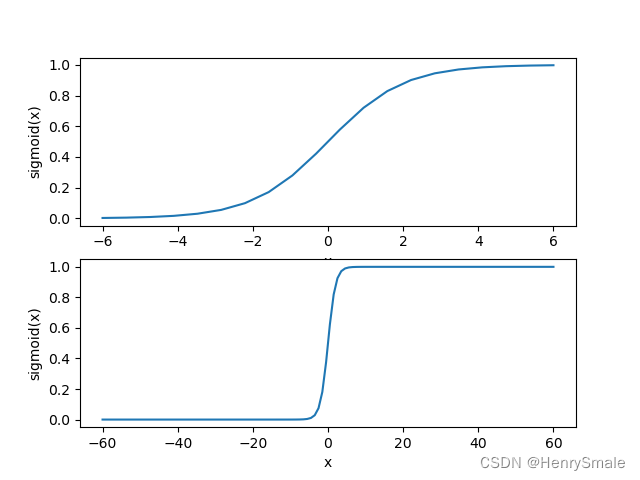
Illustrate the sigmoid function.
Not used in the learning process.
"""
def sigmoidPlotTest():xValue = np.linspace(-6, 6, 20)#print("xValue = ", xValue)yValue = sigmoid(xValue)x2Value = np.linspace(-60, 60, 120)y2Value = sigmoid(x2Value)fig = plt.figure()ax1 = fig.add_subplot(2, 1, 1)ax1.plot(xValue, yValue)ax1.set_xlabel('x')ax1.set_ylabel('sigmoid(x)')ax2 = fig.add_subplot(2, 1, 2)ax2.plot(x2Value, y2Value)ax2.set_xlabel('x')ax2.set_ylabel('sigmoid(x)')plt.show()"""
函数:梯度上升算法,核心
"""
def gradAscent(dataMat,labelMat):dataSet = np.mat(dataMat) # m*nlabelSet = np.mat(labelMat).transpose() # 1*m->m*1m, n = np.shape(dataSet) # m*n: m个样本,n个特征alpha = 0.001 # 学习步长maxCycles = 1000 # 最大迭代次数weights = np.ones( (n,1) )for i in range(maxCycles):y = sigmoid(dataSet * weights) # 预测值error = labelSet - yweights = weights + alpha * dataSet.transpose() * errorreturn weights"""
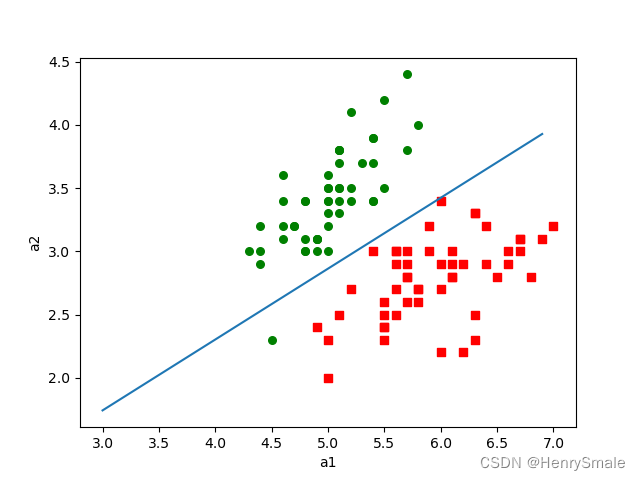
函数:画出决策边界,仅为演示用,且仅支持两个条件属性的数据
"""
def plotBestFit(paraWeights):dataMat, labelMat = loadDataSet()dataArr=np.array(dataMat)m,n=np.shape(dataArr)x1=[] #x1,y1:类别为1的特征x2=[] #x2,y2:类别为2的特征y1=[]y2=[]for i in range(m):if (labelMat[i])==1:x1.append(dataArr[i,1])y1.append(dataArr[i,2])else:x2.append(dataArr[i,1])y2.append(dataArr[i,2])fig=plt.figure()ax=fig.add_subplot(111)ax.scatter(x1,y1,s=30,c='red',marker='s')ax.scatter(x2,y2,s=30,c='green')#画出拟合直线x=np.arange(3, 7.0, 0.1)y=(-paraWeights[0]-paraWeights[1]*x)/paraWeights[2] #直线满足关系:0=w0*1.0+w1*x1+w2*x2ax.plot(x,y)plt.xlabel('a1')plt.ylabel('a2')plt.show()"""
读数据, csv格式
"""
def loadDataSet(paraFilename="data/iris2class.txt"):dataMat=[] #列表listlabelMat=[]txt=open(paraFilename)for line in txt.readlines():tempValuesStringArray = np.array(line.replace("\n", "").split(','))tempValues = [float(tempValue) for tempValue in tempValuesStringArray]tempArray = [1.0] + [tempValue for tempValue in tempValues]tempx = tempArray[:-1] #不要最后一列tempy = tempArray[-1] #仅最后一列dataMat.append(tempx)labelMat.append(tempy)#print("dataMat = ", dataMat)#print("labelMat = ", labelMat)return dataMat,labelMat"""
Logistic regression分类
"""
def mfLogisticClassifierTest():#Step 1. Load the dataset and initialize#如果括号内不写数据,则使用4个属性前2个类别的irisx, y = loadDataSet("data/iris2condition2class.csv")#tempDataset = sklearn.datasets.load_iris()#x = tempDataset.data#y = tempDataset.targettempStartTime = time.time()tempScore = 0numInstances = len(y)#Step 2. Trainweights = gradAscent(x, y)#Step 2. ClassifytempPredicts = np.zeros((numInstances))#Leave one outfor i in range(numInstances):tempPrediction = x[i] * weights#print("x[i] = {}, weights = {}, tempPrediction = {}".format(x[i], weights, tempPrediction))if tempPrediction > 0:tempPredicts[i] = 1else:tempPredicts[i] = 0#Step 3. Which are correct?tempCorrect = 0for i in range(numInstances):if tempPredicts[i] == y[i]:tempCorrect += 1tempScore = tempCorrect / numInstancestempEndTime = time.time()tempRuntime = tempEndTime - tempStartTime#Step 4. Outputprint('Mf logistic socre: {}, runtime = {}'.format(tempScore, tempRuntime))#Step 5. Illustrate 仅对两个属性情况有效rowWeights = np.transpose(weights).A[0]plotBestFit(rowWeights)def main():#sklearnLogisticTest()mfLogisticClassifierTest()#sigmoidPlotTest()main()相关文章:
5 逻辑回归及Python实现
1 主要思想 分类就是分割数据: 两个条件属性:直线;三个条件属性:平面;更多条件属性:超平面。 使用数据: 5.1,3.5,0 4.9,3,0 4.7,3.2,0 4.6,3.1,0 5,3.6,0 5.4,3.9,0 . . . 6.2,2.9,1 5.1,2.5…...
技术干货 | Modelica建模秘籍之状态变量
在很多领域都有“系统”这个概念,它描述的往往是一些复杂关系的总和。假如我们将系统看做一个黑箱,那么,在系统的作用下,外界的输入有时会产生令人意想不到的输出,“蝴蝶效应”就是其中的典型案例。图1 一只南美洲亚马…...

LeetCode 2574. 左右元素和的差值
给你一个下标从 0 开始的整数数组 nums ,请你找出一个下标从 0 开始的整数数组 answer ,其中: answer.length nums.length answer[i] |leftSum[i] - rightSum[i]| 其中: leftSum[i] 是数组 nums 中下标 i 左侧元素之和。如果不…...

rollup环境配置
VUE2.x源码学习笔记 1. rollup环境配置 首先在VScode中新建文件夹vue_sc,然后终端打开定位到打开的文件夹,输入“npm init -y”初始化配置项,运行成功之后文件夹新增package.json文件 继续在终端运行"npm install babel/preset-env ba…...

二分查找与二分答案、递推与递归、双指针、并查集和单调队列
二分查找与二分答案 文章目录二分查找与二分答案应用总结例题木材加工题目背景题目描述输入格式输出格式样例 #1样例输入 #1样例输出 #1提示数据规模与约定思路代码递归与递推应用总结[NOIP2003 普及组] 栈题目背景题目描述输入格式输出格式样例 #1样例输入 #1样例输出 #1提示思…...
如何进行域名购买,获取免费ssl证书,使用springboot绑定ssl证书
前言 小编我将用CSDN记录软件开发求学之路上亲身所得与所学的心得与知识,有兴趣的小伙伴可以关注一下!也许一个人独行,可以走的很快,但是一群人结伴而行,才能走的更远!让我们在成长的道路上互相学习&#…...
LabVIEW网络服务安全2
LabVIEW网络服务安全2在客户端应用程序中创建签名对请求进行签名要求您具有能够从客户端的编程语言调用的MD5摘要算法以及SHA256加密摘要算法的实现。这两种算法通常都可用于大多数平台。还需要:1. 要使用的HTTP方法的字符串(“GET”、“POST”、“PUT”…...
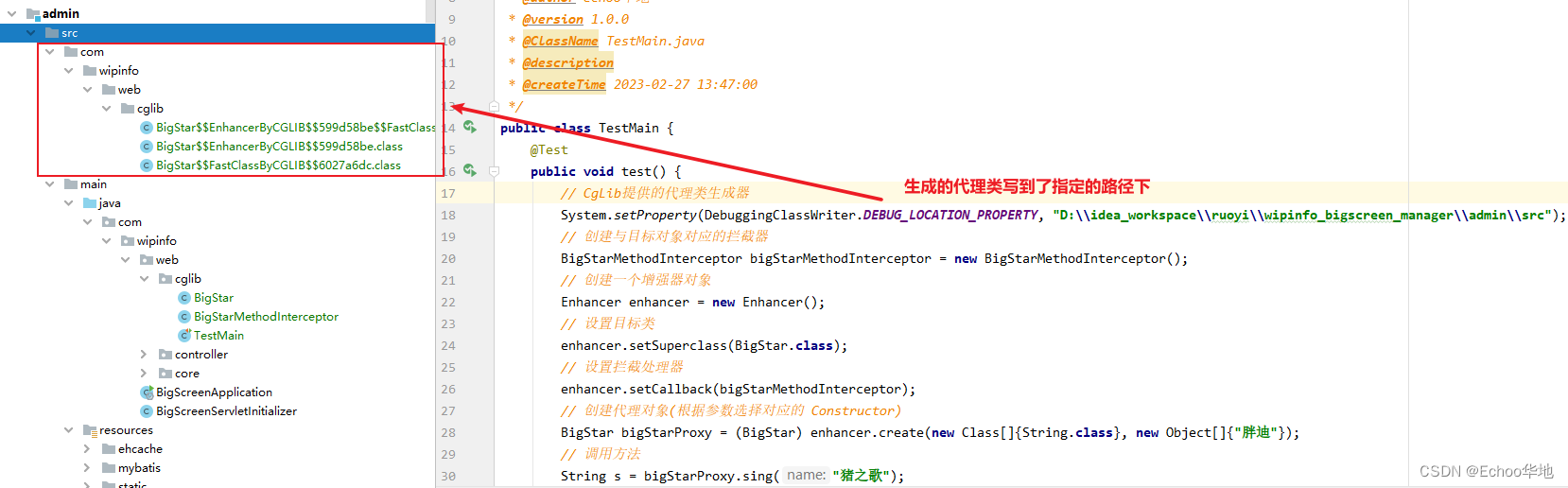
java动态代理
目录儿一、代理模式的作用二、实现代理的方式三、动态代理的实现3.1 jdk动态代理3.2 cglib动态代理一、代理模式的作用 功能增强: 基于某个功能,再增加一些功能。 (比如目标类只负责核心功能,其他附属功能通过代理类完成。代理类的方法名与目…...
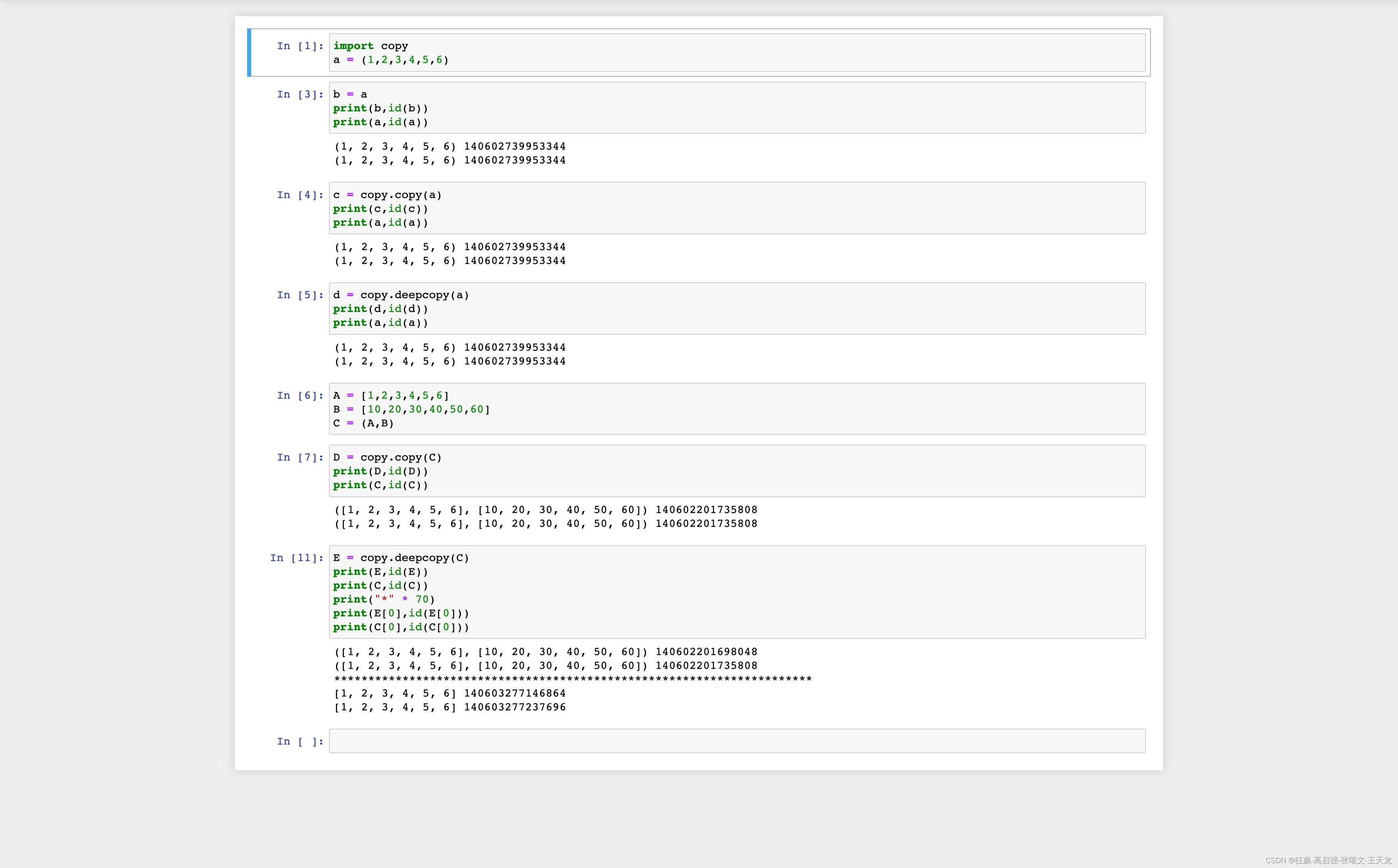
Python 简单可变、复杂可变、简单不可变、复杂不可变类型的copy、deepcopy的行为
copy模块:copy:浅拷贝deepcopy:深拷贝简单可变类型、复杂可变的copy()、deepcopy():简单不可变、复杂不可变类型的copy()、deepcopy():结论:对于简单类型的可变类型copy是深拷贝,改变了该拷贝变…...
QML Item
在QML中所有的可视项目都继承自Item,虽然Item本身没有可视化的外观,但它定义了可视化项目的所有属性。 Item可以作为容器使用: Item{Rectangle{id:retc}Rectangle{id:retc1}Rectangle{id:retc2}Rectangle{id:retc3}} item拥有children属性…...
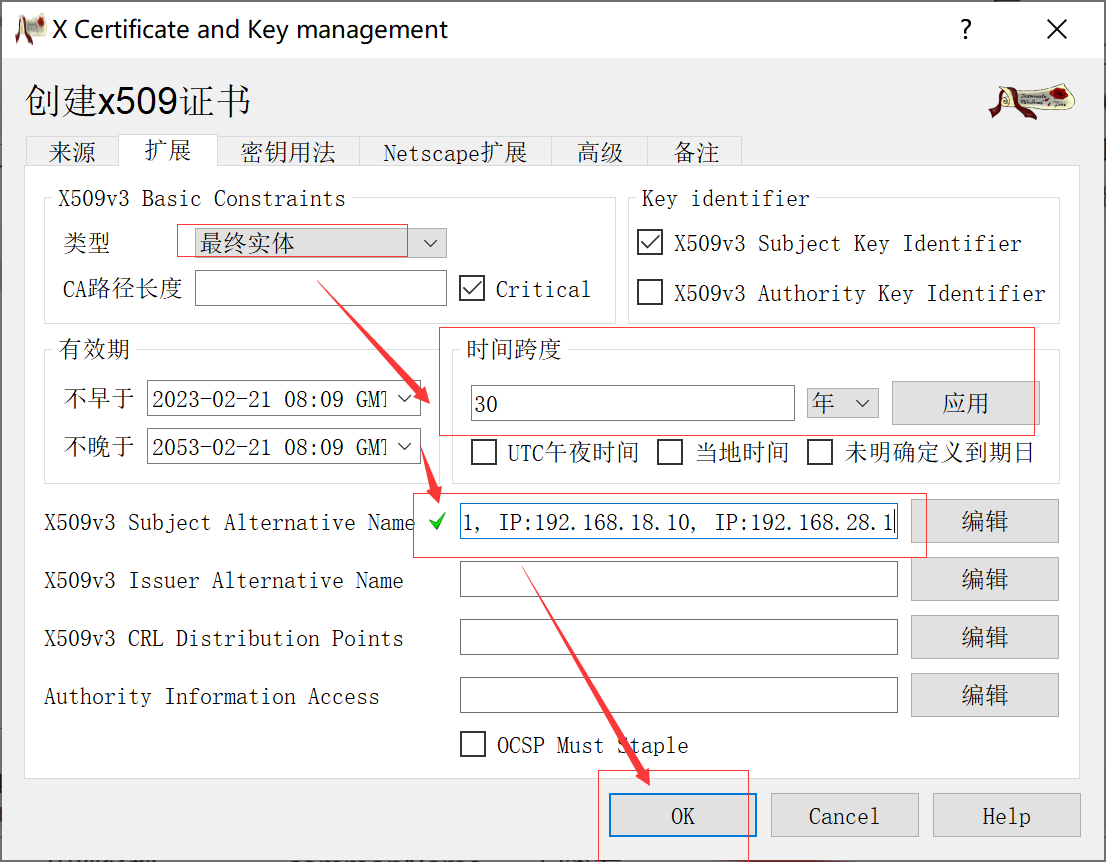
使用xca工具生成自签证书
本文使用 xca 生成自签证书。 概述 之前使用 openssl 生成证书,在 golang 中测试,发现客户端连接失败,经查发现是Subject Alternative Name不支持导致的。因虚拟机 openssl 版本较低,有个功能无法实现,且升级麻烦&…...

Unity IOS 通过命令行导出IPA
新建一个文件然后输入如下内容 #!/usr/bin/env sh /Applications/Unity/Hub/Editor/2020.1.5f1c1/Unity.app/Contents/MacOS/Unity -quit -batchmode -projectPath /Users/zyt/Test -executeMethod Test.BuildEditor.BuildApp cd /Users/zyt/Test/Xcode/unity-xcode xcodebuil…...
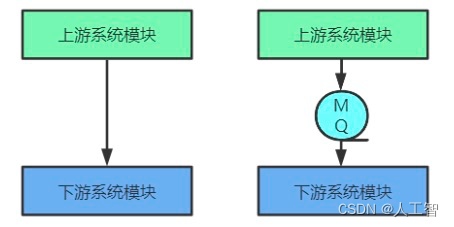
「架构」全链路异步模式
总结自尼恩的全链路异步:网关纯异步化网关层的特点:不需要访问业务数据库只做协议转换和流量转发特点是 IO 密集型,特别适合纯异步的架构,可以极大的节省资源。如何进行网关异步化?使用高性能的通信框架Nettyÿ…...
CleanMyMac4.20最新版新增功能及电脑清理垃圾使用教程
CleanMyMac4.20作为知名的Mac清理工具,仅需一键即可快速而安全地清理系统垃圾,释放磁盘空间,因此一直深受Mac用户的喜爱。在不断更新的版本中,CleanMyMac已经不仅仅满足于只做简单的Mac清理工具,而是为Mac用户提供更多…...

Vue2的tsx开发入门完全指南
本篇文章尽量不遗漏重要环节,本着真正分享的心态,不做标题党 下面进入正题: 由于现在vue的官方脚手架已经非常完善我们就不单独配置webpack了,节省大量的时间成本。 首先使用vue/cli创建一个vue模版项目(记得是vue/…...

GLSL shader学习系列1-Hello World
这是GLSL shader系列第一篇文章,本文学习目标: 安装编辑工具编写hello world程序 安装插件 我使用VSCode编写shader代码,在VSCode上有两个好用的插件需要先装一下: Shader languages support for VS Code glsl-canvas…...

Codeforces Round #851 (Div. 2)(A~D)
A. One and Two给出一个数组,该数组仅由1和2组成,问是否有最小的k使得k位置的前缀积和后缀积相等。思路:计算2个数的前缀和即可,遍历判断。AC Code:#include <bits/stdc.h>typedef long long ll; const int N 1…...

内存保护_1:Tricore芯片MPU模块介绍
上一篇 | 返回主目录 | 下一篇 内存保护_1:Tricore芯片MPU模块介绍1 何为MPU2 MPU相关的硬件子系统2.1 基于地址范围保护逻辑说明2.1.1 地址范围寄存器2.1.2 读、写、执行权限寄存器2.1.3 保护集设置位2.1.4 内存保护功能使能位2.1.5 核的内存保护范围获取说明2.1.6…...

Vue3 -- PDF展示、添加签名(带笔锋)、导出
文章目录笔锋签名方案一实现要点实现过程组件引用页面元素添加引用实现代码效果展示缺点方案二修改页面元素替换引用修改代码效果展示完整代码地址实现功能的时候采用了两个方案,主要是第一个方案最后的实现效果并不太理想,但实现起来比较简单࿰…...
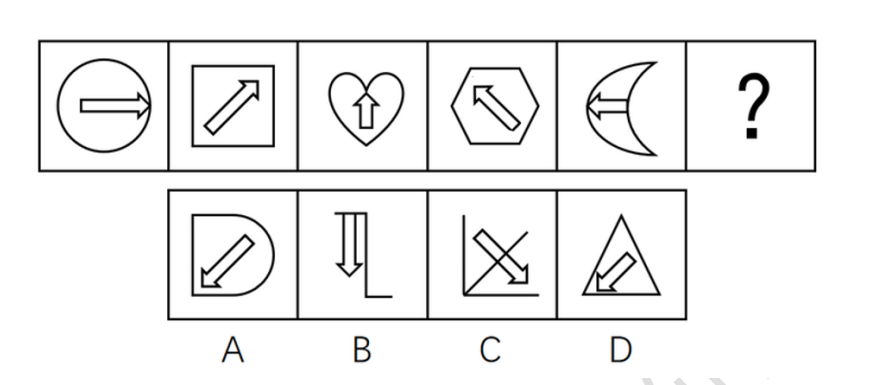
行测-判断推理-图形推理-样式规律-属性规律-曲直性
左边的图全是由曲线构成的选C1 3 5全是由曲线构成的2 4 6全是由直线构成的第三行的图形有曲有直选A1 3 5有曲有直2 4 6全是直线选D图形有曲有直,排除B D外曲内直->内曲外直->外曲内直->内曲外直->外曲内直->内曲外直所以问号出的图形应该是内曲外直选…...

5分钟免费安装终极Markdown阅读器:浏览器最强文档查看解决方案
5分钟免费安装终极Markdown阅读器:浏览器最强文档查看解决方案 【免费下载链接】markdown-viewer Markdown Viewer / Browser Extension 项目地址: https://gitcode.com/gh_mirrors/ma/markdown-viewer Markdown Viewer是一款功能强大的浏览器扩展࿰…...

好用的AI软件开发选哪家
在当今数字化飞速发展的时代,AI软件已经成为众多企业和个人提升效率、创新业务的重要工具。然而,面对市场上众多的AI软件开发公司,如何选择一家靠谱且好用的公司成为了许多人的困扰。今天,我就为大家推荐广州飞进信息科技有限公司…...

为AI智能体注入人类洞察:用户研究技能全链路实践指南
1. 项目概述:为AI智能体注入“人类洞察层”如果你正在构建或使用AI智能体,无论是Claude Code、Cursor还是其他基于代码的智能助手,你可能会发现一个核心瓶颈:这些智能体虽然能处理代码、分析数据,但在涉及产品决策、功…...

SLEICL框架:用“魔法书”提示工程提升小模型上下文学习性能
1. 项目概述:用“魔法书”解锁小模型的大潜能 如果你最近在折腾大语言模型,尤其是那些参数规模在7B、13B左右的“小模型”,可能会发现一个头疼的问题:想让它们通过上下文学习(In-context Learning, ICL)的方…...

Universal Data Tool 新功能解析:骨骼姿态标注与数据格式转换实战
1. 项目概述:一个数据标注工具的进化最近在整理一个计算机视觉项目的数据集时,我又一次打开了Universal Data Tool(UDT)。这个工具我用了快两年了,从它早期版本支持基础的图像分类和物体检测框标注开始,就一…...

分布式缓存策略:提升应用性能和可扩展性
分布式缓存策略:提升应用性能和可扩展性 一、分布式缓存概述 1.1 分布式缓存的定义 分布式缓存是一种将数据存储在多个节点上的缓存系统,它通过在内存中存储常用数据,减少对后端数据库的访问,从而提高应用性能和可扩展性。 1.…...

终极开源语音AI工具包:Sherpa-Onnx一站式解决方案
终极开源语音AI工具包:Sherpa-Onnx一站式解决方案 【免费下载链接】sherpa-onnx Speech-to-text, text-to-speech, speaker diarization, speech enhancement, source separation, and VAD using next-gen Kaldi with onnxruntime without Internet connection. Sup…...

Tessera:内核级异构GPU分解技术解析与应用
1. Tessera:内核级异构GPU分解技术解析现代GPU数据中心正变得越来越异构化,不同型号的GPU在计算能力、内存带宽和成本效率上存在显著差异。这种异构性源于GPU发布周期与退役时间表的不匹配,以及高昂的成本和有限的供应。例如,Goog…...

SAR ADC性能优化:电压基准设计与THD改善方案
1. 电压基准对SAR ADC性能的影响机制在精密数据采集系统设计中,工程师们常常花费大量精力选择高性能的模数转换器(ADC)和优化输入驱动电路,却容易忽视一个关键因素——电压基准的质量及其驱动能力。对于逐次逼近型(SAR)ADC而言,基准电压的稳定…...

C++ 入门核心语法|从 Hello World 到基础特性一次性吃透
文章目录前言一、C 第一个程序:Hello World二、命名空间 namespace1. 为什么需要命名空间?2. 命名空间定义规则3. 三种使用方式三、C 输入 & 输出1. 核心对象2. 最大优势四、缺省参数(默认参数)1. 定义2. 使用方式3. 声明与定…...