7天入门python系列之爬取热门小说项目实战,互联网的东西怎么算白嫖呢
第七天 Python项目实操
编者打算开一个python 初学主题的系列文章,用于指导想要学习python的同学。关于文章有任何疑问都可以私信作者。对于初学者想在7天内入门Python,这是一个紧凑的学习计划。但并不是不可完成的。
学到第7天说明你已经对python有了一个基本的认识,下面通过完成一个小项目来巩固之前几天所学的知识。
接下来我们上干货, 编者是一个网文读者,常常因为小说需要订阅或者有时候网路不好,看不到小说,因此选择将小说下载下来,保证能过随时随地的阅读。看看这个小项目的效果
接下来你需要熟悉几个词语,网页开发,flask 框架,request 、BeautifulSoup库,
源代码我放在**源代码地址**
-
网页开发:
- 定义: 网页开发是指创建和维护网页的过程。它涵盖了从设计、编写前端代码(HTML、CSS、JavaScript)到后端开发(服务器端代码、数据库交互)以及整个网站的部署和维护等一系列工作。网页开发旨在创造用户友好的、功能完善的网站和Web应用。
-
Flask 框架:
- 定义: Flask 是一个基于 Python 的轻量级 Web 框架,用于构建 Web 应用程序。它提供了一些核心工具,如路由、视图函数、模板引擎等,使得开发者能够以简洁而灵活的方式构建 Web 应用。Flask 是一个微框架,它提供了一些基础的功能,但让开发者有更大的自由度选择其他库来满足特定需求。
-
requests 库:
- 定义:
requests是一个用于发送 HTTP 请求的 Python 第三方库。它提供了简单而强大的 API,用于处理各种类型的请求和响应,如 GET、POST 等。requests库使得在 Python 中进行网络请求变得更加方便,可以用于从 Web 服务器获取数据、与 API 交互等场景。
- 定义:
-
BeautifulSoup 库:
- 定义:
BeautifulSoup是一个 Python 库,用于从 HTML 或 XML 文档中提取数据。它提供了一种方便的方式来搜索文档树、遍历文档树中的元素,以及修改文档树。在网页开发中,BeautifulSoup主要用于解析 HTML 页面,从中提取结构化的信息,例如抓取特定标签的内容、提取链接、或者进行数据挖掘。
- 定义:
在网页开发中,通常会使用 Flask 框架来构建 Web 应用的后端,同时使用 requests 库来进行与其他服务器的通信,获取数据。而在处理获取到的 HTML 页面时,可以借助 BeautifulSoup 库进行解析和信息提取。这三者的结合使得开发者能够更轻松地构建和处理 Web 应用。
代码我放在gitee 仓库:https://gitee.com/constantine-G/getbook
项目搭建
然后开始我们的项目搭建:
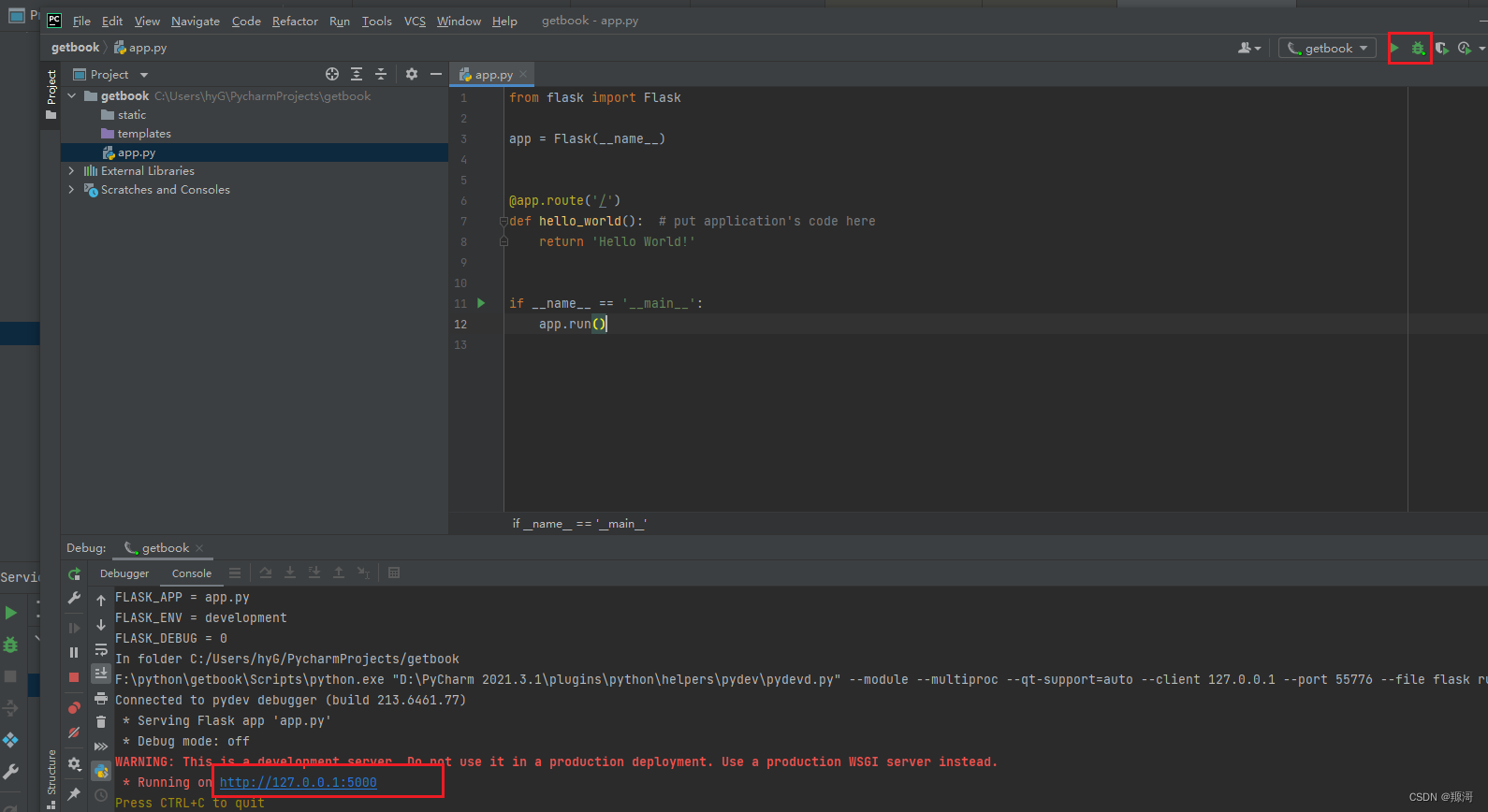
使用pycharm 编辑器, 创建项目
新建好的干净项目
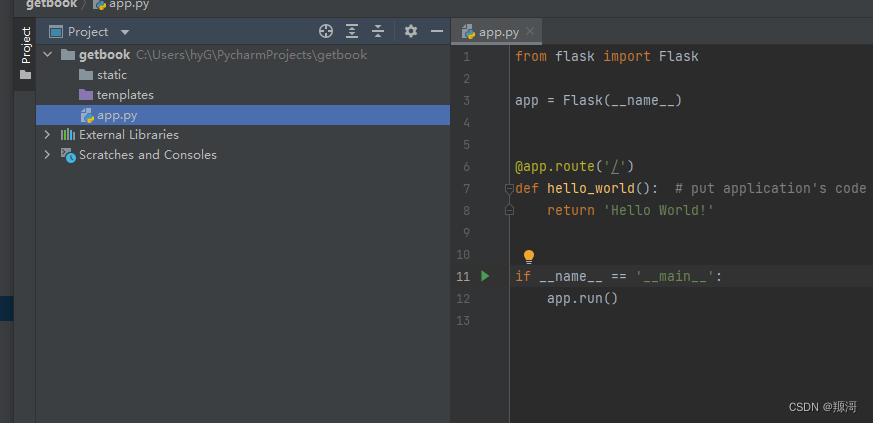 > 此时你可以启动这个项目,会返回一句话
> 此时你可以启动这个项目,会返回一句话

创建交互页面
创建这样两个文件

网络下载这个文件,如果找不到,直接到我的仓库下载
index.html 内容
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><title>hello,my world!</title>
</head>
<body>
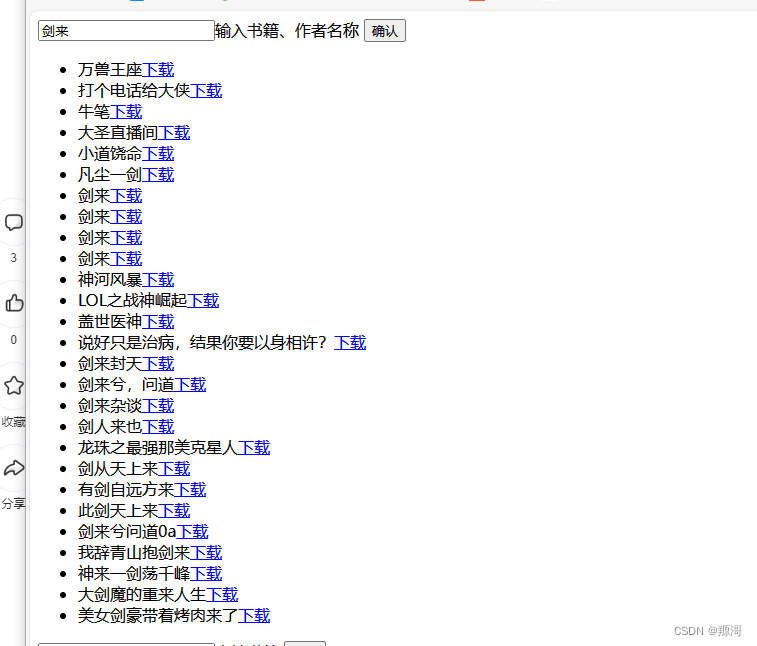
<div id="app"><input id="bookName">输入书籍、作者名称</input><button id="swap">确认</button><ul id="data-list"></ul><input id="bdbookName">本地书籍</input><button id="search">搜索</button><ul id="bd-list"></ul>
</div>
{# <script src="/static/js/common/vue/vue.js"></script>#}
{# <script type="text/javascript" src="/static/js/common/require/require.min.js"></script>#}<script src="/static/js/common/jquery.js"></script><script src="/static/js/index.js"></script></body>
</html>
iondex,js 内容
const person = document.getElementById('bookName');
const bdbookName = document.getElementById('bdbookName');
$(document).ready(function () {$("#swap").click(function () {$.ajax({type: "POST",url: "/searchBook",dataType: "json",data: {"bookName": person.value},success: function (res) {displayData(res);// addListener();},error: function (xhr, status, error) {alert(error);}});});$("#search").click(function () {$.ajax({type: "POST",url: "/searchBd",dataType: "json",data: {"bookName": bdbookName.value},success: function (res) {dbdisplayData(res);// addListener();},error: function (xhr, status, error) {alert(error);}});});//
});function addListener(){// 获取列表项元素const listItems = document.querySelectorAll('#data-list li');// 为每个列表项添加点击事件listItems.forEach(item => {item.addEventListener('click', () => {downLoadBook(item)});});
}function addListener(){// 获取列表项元素const listItems = document.querySelectorAll('#bd-list li');// 为每个列表项添加点击事件listItems.forEach(item => {item.addEventListener('click', () => {downLoadBook(item)});});
}
function downLoadBook(event) {$.ajax({type: "POST",url: "/downLoadBook",dataType: "json",data: {"book": data},success: function (res) {alert(res);},error: function (xhr, status, error) {alert(error);}});
}
function dbdisplayData(data) {var dataList = $("#bd-list");dataList.empty();data.forEach(function (item) {// <a href="{{ url_for('downLoadBook', id=post['id']) }}">Edit</a>// var url = "/downLoadBook" + item.link;var url = "/downLoadBook" + item.bookLink;dataList.append("<li>" + item.bookName + "<a href=\""+url+"\"> 下载 </a>"+"地址: "+item.path+"</li>");// dataList.append("<li>" + item.bookName + "</li>");});
}function displayData(data) {var dataList = $("#data-list");dataList.empty();data.forEach(function (item) {// <a href="{{ url_for('downLoadBook', id=post['id']) }}">Edit</a>var url = "/downLoadBook" + item.link;dataList.append("<li>" + item.name + "<a href=\""+url+"\">下载</a>"+"</li>");});
}在app.py 文件中添加一个方法
@app.route('/')
def hello_world(): # put application's code herereturn render_template("index.html")此时再次重启项目,并访问 http://127.0.0.1:5000/
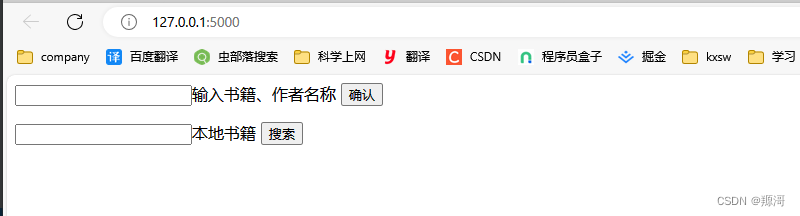
可以看到已经多了一些内容。这是用于一个简单交互的页面。主要是输入想要下载的书籍,发起查询,然后在下载
完成时的效果:

网站后端查询小说
新增一个文件叫book.py
并新增以下内容 :
主要是点击查询的功能实现
def searchBooklist(bookName):try:# 发送GET请求 = "http://www.biqu5200.net"response = requests.get(url== "http://www.biqu5200.net" + "/modules/article/search.php?searchkey=" + bookName, headers=header)response.encoding = 'utf-8'# 检查请求是否成功res = []bookList = []if response.status_code == 200:# 如果请求成功,获取响应数据soup = BeautifulSoup(response.content, "html.parser")even_items = soup.find_all("tr")# 遍历并打印匹配的元素内容for item in even_items:booklink = item.find("a")if booklink != None and booklink["href"] != None and booklink.text != None:book = {"name": booklink.text,"link": booklink["href"]}bookO = {"name": booklink.text,"link": url+booklink["href"]}res.append(book)# book = select(booklink.text)if book == None:bookList.append(bookO)# insert(bookList)return reselse:# 如果请求失败,打印错误信息print("请求失败,状态码:", response.status_code)return resexcept requests.exceptions.RequestException as e:# 处理请求异常print("请求异常:", e)return res这个方法是返回一个书籍的列表

接下来实现下载功能
def downLoadBook(bookLink):# 发送GET请求# response = requests.get(url=book["link"], headers=header)# 请求数据response = getRequsetContent(url+"/"+bookLink)if response != None:# 如果请求成功,获取响应数据soup = BeautifulSoup(response, "html.parser")even_items = soup.find_all("dd")bookName = soup.find(id='info').find('h1').textstart = time.time()min = len(even_items) / (60/second)hour = min / 60print("预估时间:" + str(min) +"分钟" + "= "+str(hour)+"小时")# 遍历并打印匹配的元素内容# open(bookName+".txt", mode="r")# 读文件# open("demo1/1.txt", mode="w")# 写文件file = open(bookName + ".txt", mode="w",encoding='utf-8')file = open(bookName + ".txt", mode="a",encoding='utf-8')# 追加ret_message = {"code": 0, "status": "successful", "msg": "成功,耗时:" + str(min)}failed = []# book = select(bookName)try:chapterList = []for item in even_items:booklink = item.find("a")chapter = {"bookid": book["id"],"chapterLink": url+ booklink["href"],"chapterName": booklink.text}chapterList.append(chapter)# insertChapter(chapterList)leastchaper = ''for item in even_items:booklink = item.find("a")contemxUrl =booklink["href"]chaper = booklink.textleastchaper = chaperchaperurl = url + contemxUrl# 休息1秒time.sleep(second)content = getRequsetContent(chaperurl)contentList = []if content != None:soup = BeautifulSoup(content, "html.parser")chapername = soup.find(class_="bookname").find("h1").textcontentList.append(chapername + '\n')pList = soup.find(id="content").find_all("p")contentList = []for p in pList:constr = p.textif constr.find("请记住本书首发域名:。顶点小说手机版阅读网址:") != -1:print("有广告:" + constr)contentList.append(p.text + '\n')else:failed.append(chaper)file.writelines(contentList)# update(chaper,url+ booklink["href"])print("完成:"+chaper)upBook = Book(book['id'],1,os.path.abspath(os.path.dirname(file.__str__())).replace('\\','/'),leastchaper,';'.join(failed))# updateBook(upBook)print("failed:" + ''.join(failed))size =file.seek(0, os.SEEK_END)end = time.time()print("size:" + ''.join(size))print("time:" + end - start)file.close()return ret_messageexcept Exception as e:# 处理请求异常file.close()print("异常:", e)return ret_messageelse:# 如果请求失败,打印错误信息print("请求失败,状态码:", response.status_code)# 公用方法
def getRequsetContent(url):try:# 发送GET请求response = requests.get(url=url, headers=header)response.encoding = 'utf-8'# 检查请求是否成功if response.status_code == 200:# 如果请求成功,获取响应数据return response.contentelse:# 如果请求失败,打印错误信息print("请求失败,状态码:", response.status_code)return Noneexcept requests.exceptions.RequestException as e:# 处理请求异常print("请求异常:", e)return None到此我们的功能就基本完成了。实现了查询数据,并选择自己想要的书籍下载,有任何疑问请联系我
相关文章:
7天入门python系列之爬取热门小说项目实战,互联网的东西怎么算白嫖呢
第七天 Python项目实操 编者打算开一个python 初学主题的系列文章,用于指导想要学习python的同学。关于文章有任何疑问都可以私信作者。对于初学者想在7天内入门Python,这是一个紧凑的学习计划。但并不是不可完成的。 学到第7天说明你已经对python有了一…...
产品经理墨刀学习----注册页面
我们做的产品是一个校园论坛学习开发系统,目前才开始学习。 (一)流程图 (二)简单墨刀设计--注册页面 (1)有账号 (a)直接登录: (b)忘…...
算法通关村——归并排序
归并排序 1、归并排序原理 归并排序是一种很经典的分治策略。 归并排序(MERGE-SORT)简单来说就是将大的序列先视为若干小的数组,分成几个比较小的结构,然后是利用归并的思想实现的排序方法。将一个大的问题分解成一些小的问题分别求解ÿ…...
SDL2 播放音频数据(PCM)
1.简介 这里以常用的视频原始数据PCM数据为例,展示音频的播放。 SDL播放音频的流程如下: 初始化音频子系统:SDL_Init()。设置音频参数:SDL_AudioSpec。设置回调函数:SDL_AudioCallback。打开音频设备:SD…...

优秀智慧园区案例 - 重庆AI PARK智慧创意园区,先进智慧园区建设方案经验
一、项目背景 1、智慧园区是国家实现经济增长、产业升级的载体 智慧园区建设是城市智慧化创新发展的核心,在数智化升级和低碳化转型的经济发展双引擎的驱动下,十四五、数字经济的政策大力支持,以及人工智能、5G、大数据、区块链等技术的不断…...

如何编写一个Perl爬虫程序
要编写一个Perl爬虫程序,首先需要安装LWP::UserAgent模块。你可以使用cpan命令来安装该模块: cpan LWP::UserAgent 安装完成后,可以使用以下代码来编写爬虫程序: use LWP::UserAgent; use HTML::TreeBuilder; my $proxy_host …...

linux查看当前目录大小及磁盘大小
1、查看当前目录大小 du -sh ./*-h:以K,M,G为单位,提高信息的可读性 -s:仅显示总计 ./*:列出当前目录下的子项 2、查看磁盘大小 df -h还可以加个路径,仅查看当前目录所在的磁盘。例如&#x…...
windows系统pycharm程序通过urllib下载权重https报错解决
报错内容: raise URLError(unknown url type: %s % type) urllib.error.URLError: <urlopen error unknown url type: https> 解决办法记录: 1. 下载 pyopenssl : pip install pyopenssl 此时, import ssl 可以通过提示指导你安…...

Python数据结构: 列表(List)详解
在Python中,列表(List)是一种有序、可变的数据类型,被广泛用于存储和处理多个元素。列表是一种容器,可以包含任意数据类型的元素,包括数字、字符串、列表、字典等。本文将深入讨论列表的各个方面࿰…...

查找py源代码目录
要查找Python源代码目录,你可以按照以下步骤进行操作: 打开终端或命令提示符窗口。输入以下命令来查找Python源代码目录: python -m site该命令将显示Python安装位置的相关信息,包括site-packages目录路径。该目录通常包含Pytho…...
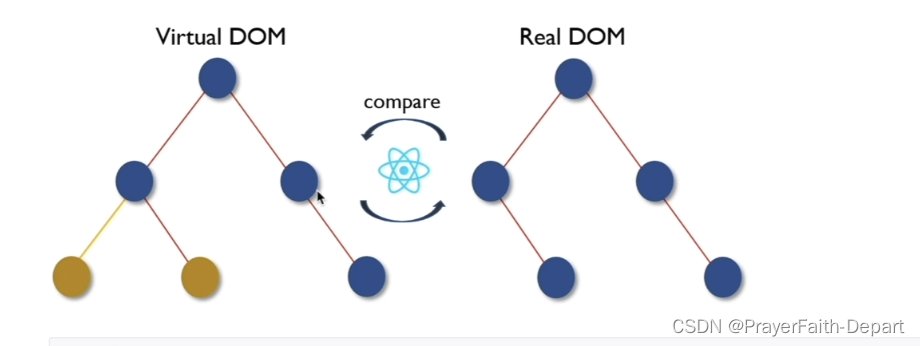
React Virtual DOM及Diff算法
JSX到底是什么 使用React就一定会写JSX,JSX到底是什么呢?它是一种JavaScript语法的扩展,React使用它来描述用户界面长成什么样子,虽然它看起来非常像HTML,但他确实是javaScript,在React代码执行之前&#…...

Spark通过三种方式创建DataFrame
通过toDF方法创建DataFrame 通过toDF的方法创建 集合rdd中元素类型是样例类的时候,转成DataFrame之后列名默认是属性名集合rdd中元素类型是元组的时候,转成DataFrame之后列名默认就是_N集合rdd中元素类型是元组/样例类的时候,转成DataFrame…...

【坑】idea终端下执行maven命令行报错:mvn clean install -Dspring.profiles.active=dev
直接看报错信息 解决方法 方法一 命令改为:mvn clean install -Dspring.profiles.activedev方法二 使用 cmd 进入命令行执行:mvn clean install -Dspring.profiles.activedev在新版本中的idea终端已经默认使用了类似windons10下的PowerShell窗口的风格…...

Linux下mysql安装配置教程
MySQL是一种常用的关系型数据库管理系统,安装配置MySQL需经历以下步骤: 1.下载MySQL 首先,你需要从MySQL官网下载MySQL的压缩包。在下载页面中,你需要选择正确的系统和版本(例如Windows或Linux,32位或64位…...
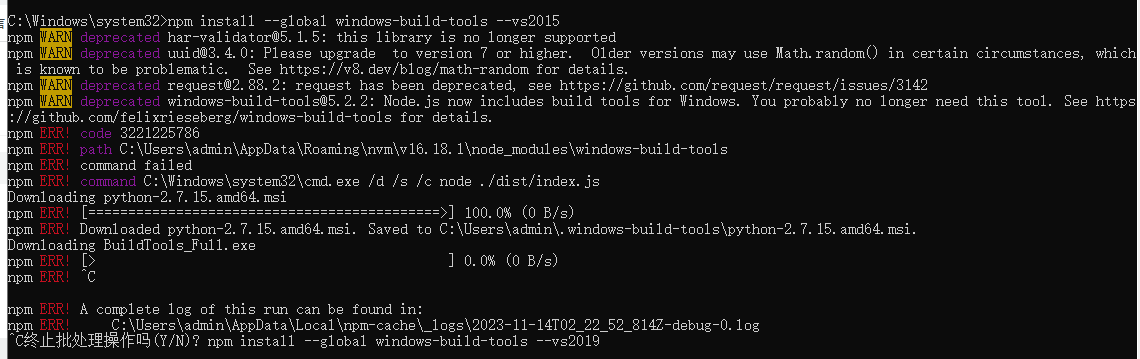
在 Electron上安装better-sqlite3出错
错误问题 一直卡npm install --global windows-build-tools --vs2015 这一步 解决 安装:pnpm install better-sqlite3 --save安装命令 pnpm i -D electron-rebuild 手动运行:node_modules/.bin/electron-rebuild -f -w better-sqlite3 我直接在packa…...

利用网络管理解决方案简化网络运维
当今的网络正朝着提高敏捷性和动态功能的方向发展,以支持高级网络要求和关键业务流程,这导致 IT 基础架构也跨越无线、虚拟和混合环境。但是,随着网络的快速发展,如果没有合适的解决方案,IT 管理员很难管理它们&#x…...
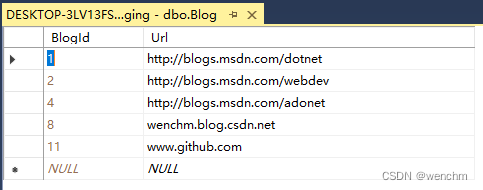
C#中.NET Framework4.8 Windows窗体应用通过EF访问数据库并对数据库追加、删除记录
目录 一、应用程序设计 二、应用程序源码 三、生成效果 前文作者发布了在.NET Framework4.8 控制台应用中通过EF访问已有数据库,事实上在.NET Framework4.8 Windows窗体应用中通过EF访问已有数据库也是一样的。操作方法基本一样,数据库EF模型和上下文…...
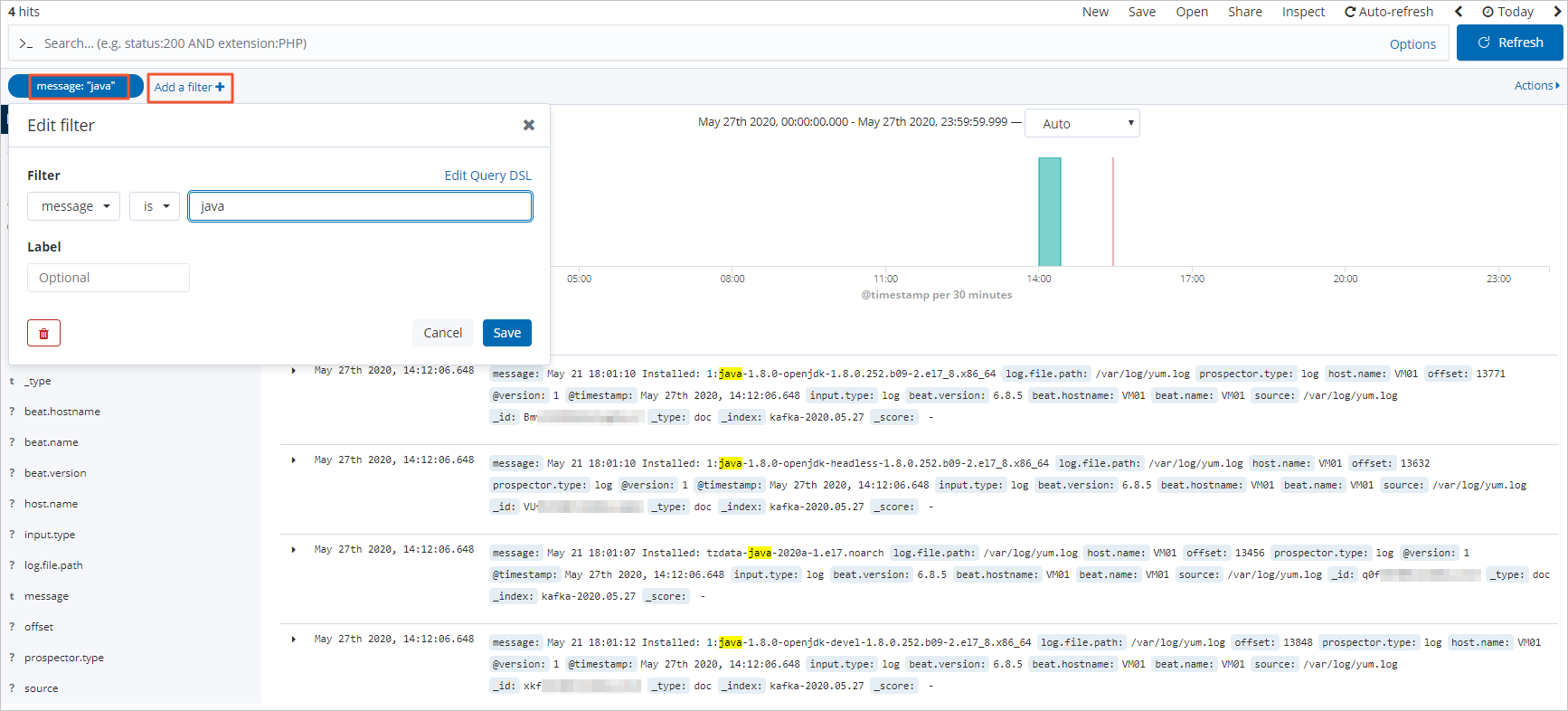
使用Filebeat+Kafka+Logstash+Elasticsearch构建日志分析系统
随着时间的积累,日志数据会越来越多,当您需要查看并分析庞杂的日志数据时,可通过FilebeatKafkaLogstashElasticsearch采集日志数据到Elasticsearch中,并通过Kibana进行可视化展示与分析。本文介绍具体的实现方法。 一、背景信息 …...
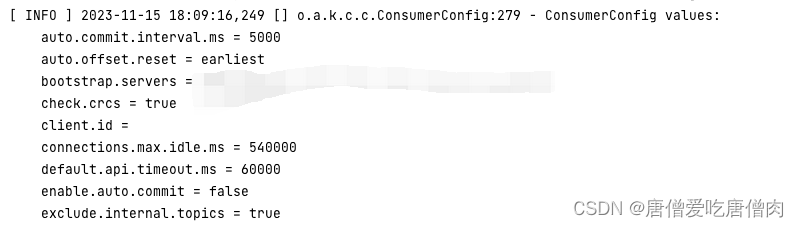
后端接口错误总结
今天后端错误总结: 1.ConditionalOnExpression(“${spring.kafka.exclusive-group.enable:false}”) 这个标签负责加载Bean,因此这个位置必须打开,如果这个标签不打开就会报错 问题解决:这里的配置在application.yml文件中 kaf…...

将scut-seg标签转化成通用coco标签
行人实例分割 import json import osdef calculate_bounding_rectangle(coordinates):# 提取x和y坐标的列表x_coords [coord[0] for coord in coordinates]y_coords [coord[1] for coord in coordinates]# 计算矩形的左上角坐标min_x min(x_coords)min_y min(y_coords)# 计…...

Jetson Orin Nano 升级jetpack5.1.2刷机过程记录
一.刷机起因 orin nano 接了个IMX477的摄像头,用 命令行DISPLAY:0.0 nvgstcapture-1.0 显示的画面有撕裂,让卖家查问题,卖家测试没有撕裂,对比环境,orin nano出厂默认的是jetpack5.1.1,卖家用的jetpack5.1.2版本,为了解决差异,要升级jetpack版本,前后搞了2天半,记录一下. 另外…...

AI时代程序员职业发展与个人创业可行性研究报告
一、行业宏观变革(2026核心趋势数据佐证) 1.1 开发范式已彻底重构(行业不可逆拐点) 2026年正式进入AI Agent智能体开发时代,传统CRUD编码价值持续崩塌。 核心权威数据: Gartner预测:2026年75%企…...

Wechat2RSS:微信公众号转RSS订阅工具
文章目录Wechat2RSS:微信公众号转RSS订阅工具Wechat2RSS:微信公众号转RSS订阅工具 ttttmr开源的Wechat2RSS项目,目前在GitHub上获得1409颗Star,项目地址为https://github.com/ttttmr/Wechat2RSS。该工具的核心作用是将微信公众号…...

对比 Token Plan 与按量计费在 Taotoken 平台上的成本体感差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比 Token Plan 与按量计费在 Taotoken 平台上的成本体感差异 对于个人开发者或项目管理者而言,在接入大模型服务时&a…...

告别鼠标手!5分钟上手开源鼠标连点器MouseClick,轻松实现自动化点击
告别鼠标手!5分钟上手开源鼠标连点器MouseClick,轻松实现自动化点击 【免费下载链接】MouseClick 🖱️ MouseClick 🖱️ 是一款功能强大的鼠标连点器和管理工具,采用 QT Widget 开发 ,具备跨平台兼容性 。软…...

【MySQL数据库 | 第一篇】 概述
数据库相关概念: 数据库(Database):数据库是指一组有组织的数据的集合,通过计算机程序进行管理和访问。数据库管理系统:操纵和管理数据库的大型软件SQL:操作关系型数据库的编程语言,定义了一套操作关系型数…...
)
37家金融客户紧急启用的DeepSeek扫描辅助加固包(含未公开API调用密钥策略)
更多请点击: https://kaifayun.com 第一章:DeepSeek漏洞扫描辅助的背景与战略价值 近年来,大模型在安全领域的应用正从辅助问答向深度协同防御演进。DeepSeek系列模型凭借其开源、高推理精度及强代码理解能力,成为构建智能化漏洞…...

3大实战秘籍:揭秘raylib如何让游戏开发像搭积木一样简单
3大实战秘籍:揭秘raylib如何让游戏开发像搭积木一样简单 【免费下载链接】raylib A simple and easy-to-use library to enjoy videogames programming 项目地址: https://gitcode.com/GitHub_Trending/ra/raylib 你是否曾经被复杂的游戏引擎配置搞得焦头烂额…...

多智能体谈判系统:Agent 如何通过博弈达成最优交易价格?
多智能体谈判系统:Agent 如何通过博弈达成最优交易价格?关键词 多智能体系统、自动谈判、博弈论、纳什均衡、帕累托最优、双边/多边谈判、强化学习谈判、动态定价 摘要 想象一个没有人类中介的世界:电商平台上的智能客服自动和批发商砍价、供…...

深度解析HS2-HF Patch:从技术框架到创作工具链的完整升级方案
深度解析HS2-HF Patch:从技术框架到创作工具链的完整升级方案 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch 你是否曾因Honey Select 2的原版体验受…...