【视觉SLAM十四讲学习笔记】第二讲——初识SLAM
专栏系列文章如下:
【视觉SLAM十四讲学习笔记】第一讲
一个机器人,如果想要探索某一块区域,它至少需要知道两件事:
- 我在什么地方——定位
- 周围环境是什么样——建图
一方面需要明白自身的状态(即位置),另一方面也要了解外在的环境(即地图)。这个时候就需要借助传感器了。
传感器分类
一类传感器是安装于环境中的,例如导轨、二维码标志等等。它们通常能够直接测量到机器人的位置信息,简单有效地解决定位问题。然而,由于它们必须在环境中设置,在一定程度上限制了机器人的使用范围。也就是说,这类传感器约束了外部环境。只有在这些约束满足时,基于它们的定位方案才能工作。虽然这类传感器简单可靠,但它们无法提供一个普遍的,通用的解决方案。
一类传感器是携带于机器人本体上的,比如激光传感器、相机、轮式编码器、惯性测量单元(Inertial Measurement Unit, IMU)等,它们测到的通常都是一些间接的物理量而不是直接的位置数据。例如,轮式编码器会测到轮子转动的角度、IMU测量运动的角速度和加速度,相机和激光则读取外部环境的某种观测数据。我们只能通过一些间接的手段,从这些数据推算自己的位置。明显的好处是,它没有对环境提出任何要求,使得这种定位方案可适用于未知环境。这和SLAM中所强调的不谋而合,因此使用携带式的传感器,比如相机,来完成SLAM是我们重点关心的问题。
按照相机的工作方式,我们把相机分为单目(Monocular)、双目(Stereo) 和 深度相机(RGB-D) 三个大类。直观看来,单目相机只有一个摄像头,双目有两个,而 RGB-D原理较复杂,除了能够采集到彩色图片之外,还能读出每个像素离相机的距离。此外,SLAM 中还有全景相机、Event 相机等。
单目相机
只使用一个摄像头进行SLAM的做法称为单目SLAM(Monocular SLAM)。

作为单目相机的数据,照片本质上是拍摄某个场景(Scene)在相机的成像平面上留下的一个投影。它以二维的形式记录了三维的世界。显然,这个过程丢掉了场景的一个维度,也就是所谓的深度(或距离)。在单目相机中,我们无法通过单个图片来计算场景中物体离我们的距离(远近)。同时由于单目相机只是三维空间的二维投影,所以如果我们想恢复三维结构,必须改变相机的视角。在单目SLAM中也是同样的原理。我们必须移动相机之后,才能估计它的运动(Motion),同时估计场景中物体的结构(Structure),即远近和大小。
那么,怎么估计这些运动和结构呢?一方面,如果相机往右移动,那么图像里的东西就会往左边移动——这就给我们推测运动带来了信息。另一方面,我们还知道近处的物体移动快,远处的物体则运动缓慢,极远处(无穷远处)的物体看上去是不动的。于是,当相机移动时,这些物体在图像上的运动形成了视差。通过视差,我们就能定量地判断哪些物体离得远,哪些物体离的近。
然而,即使我们知道了物体远近,它们仍然只是一个相对的值。如果把相机的运动和场景大小同时放大两倍,单目所看到的像是一样的。同样的,把这个大小乘以任意倍数,我们都将看到一样的景象。这说明了单目SLAM 估计的轨迹和地图,将与真实的轨迹、地图,相差一个因子,也就是所谓的尺度(Scale)。由于单目 SLAM 无法仅凭图像确定这个真实尺度,所以又称为尺度不确定性。
平移之后才能计算深度,以及无法确定真实尺度,这两件事情给单目SLAM 的应用造成了很大的麻烦。后面为了得到这个深度,开始使用双目和深度相机。使用这两种相机的目的是通过某种手段测量物体与相机之间的距离。一旦知道了距离,场景的三维结构就可以通过单个图像恢复,同时消除尺度不确定性。
双目相机

双目相机由两个单目相机组成,两个相机之间的距离(称为基线(Baseline))是已知的。我们通过这个基线来估计每个像素的空间位置。人类可以通过左右眼图像的差异判断物体的远近,在计算机上也是同样的道理。

计算机上的双目相机需要大量的计算才能估计每一个像素点的深度,相比于人类是非常的笨拙。双目相机测量到的深度范围与基线相关。基线距离越大,能够测量到的就越远。双目相机的距离估计是比较左右眼的图像获得的,并不依赖其他传感设备,所以它既可以应用在室内,也可应用于室外。双目或多目相机的缺点是配置与标定较为复杂,其深度量程和精度受双目的基线与分辨率限制,而且视差的计算非常消耗计算资源,需要使用 GPU 和 FPGA 设备加速后,才能实时输出整张图像的距离信息。
深度相机

深度相机又称RGB-D相机,可以通过红外结构光或 Time-of-Flight(ToF)原理,像激光传感器那样,通过主动向物体发射光并接收返回的光,测出物体离相机的距离。 不像双目那样通过软件计算来解决,而是通过物理的测量手段,可节省大量的计算量。不过,现在多数 RGB-D 相机还存在测量范围窄、噪声大、视野小、易受日光干扰、无法测量透射材质等诸多问题,在SLAM方面,主要用于室内。
综上,视觉SLAM的目标是通过一系列连续变化的图像,进行定位和地图构建。
经典视觉SLAM框架
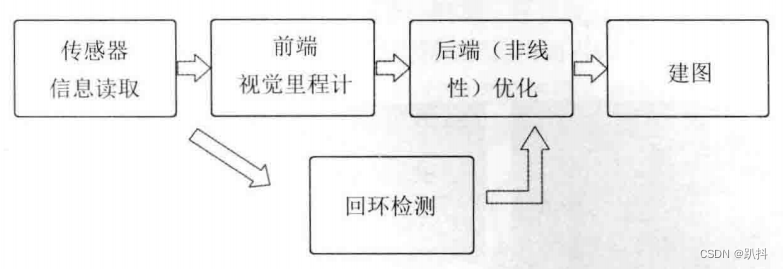
整个视觉SLAM流程包括以下步骤:
- 传感器信息读取。在视觉 SLAM 中主要为相机图像信息的读取和预处理。如果在机器人中,还可能有测速码盘、惯性传感器等信息的读取和同步。
- 前端视觉里程计(Visual Odometry, VO)。视觉里程计的任务是估算相邻图像间相机的运动,以及局部地图的样子。VO 又称为前端(Front End)。
- 后端(非线性)优化(Optimization)。后端接受不同时刻视觉里程计测量的相机位姿,以及回环检测的信息,对它们进行优化,得到全局一致的轨迹和地图。由于接在VO之后, 又称为后端(Back End)。
- 回环检测(Loop Closure Detection)。回环检测判断机器人是否到达过先前的位置。如果检测到回环,它会把信息提供给后端进行处理。
- 建图(Mapping)。它根据估计的轨迹,建立于任务要求对应的地图。
视觉里程计
视觉里程计关心相邻图像之间的相机运动,最简单的情况是两张图像之间的运动关系。图像在计算机里只是一个数值矩阵。这个矩阵里表达着什么东西,计算机毫无概念(这也正是现在机器学习要解决的问题)。而在视觉 SLAM 中,我们只能看到一个个像素,知道它们是某些空间点在相机的成像平面上投影的结果。所以,为了定量地估计相机运动,必须在了解相机与空间点的几何关系。
而视觉里程计能够通过相邻帧之间的图像估计相机运动,并恢复场景的空间结构。它和实际的里程计一样,只计算相邻时刻的运动,而和过去的信息没有关联。现在假定我们已经有了一个视觉里程计,估计了两张图像间的相机运动。那么一方面,只需要把相邻时刻的运动串起来,就构成了机器人的运动轨迹,从而解决了定位问题。另一方面,我们根据每个时刻的相机位置,计算出各像素对应的空间点的位置,就得到了地图。但是这并没有解决SLAM的问题。
仅通过视觉里程计来估计轨迹,将不可避免地出现累计漂移(Accumulating Drift)。这是由于视觉里程计在最简单的情况下只估计两个图像间的运动造成的。每次估计都有一定的误差,而由于里程计的工作方式,先前时刻的误差将会传递到下一时刻,经过一段时间的累计,估计的轨迹就不再准确。
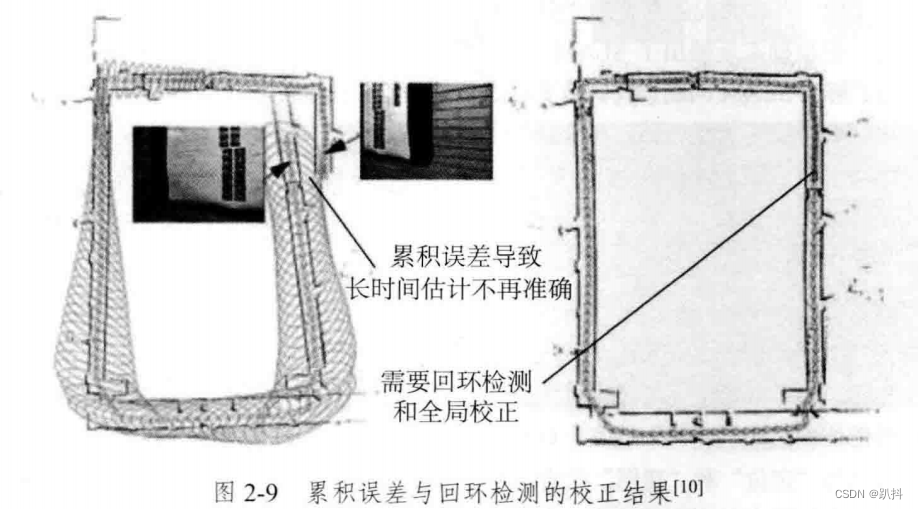
这就是所谓的漂移(Drift)。为了解决漂移问题,我们需要后端优化和回环检测。回环检测负责把“机器人回到原始位置”这件事检测出来,而后端优化则根据该信息,校正整个轨迹的形状。
后端优化
后端优化主要指处理SLAM过程中的噪声问题。即如何从这些带有噪声的数据中估计整个系统的状态(既包括机器人自身的轨迹,也包含地图),以及这个状态估计的不确定性有多大——这称为最大后验概率估计。
在SLAM框架中,前端给后端提供待优化的数据,以及这些数据的初始值。而后端负责整体的优化过程,它往往面对的只有数据,不必关心这些数据到底来自什么传感器。在视觉 SLAM 中,前端和计算机视觉研究领域更为相关,比如图像的特征提取与匹配等,后端则主要是滤波与非线性优化算法。
SLAM 问题的本质:对运动主体自身和周围环境空间不确定性的估计。为了解决SLAM,我们需要状态估计理论,把定位和建图的不确定性表达出来,然后采用滤波器或非线性优化,去估计状态的均值和不确定性(方差)。
回环检测
回环检测又称闭环检测(Loop Closure Detection),主要解决位置估计随时间漂移的问题。假设实际情况下,机器人经过一段时间运动后回到了原点,但是由于漂移,它的位置估计值却没有回到原点。如果有某种手段,让机器人知道回到了原点这件事,或者把原点识别出来,我们再把位置估计值拉过去,就可以消除漂移了。这就是所谓的回环检测。
为了实现回环检测,我们需要让机器人具有识别到过的场景的能力。同时我们更希望机器人能使用携带的传感器——也就是图像本身来完成这一任务。例如通过判断图像间的相似性来完成回环检测。如果回环检测成功,则可以显著地减小累计误差。所以,视觉回环检测实质上是一种计算图像数据相似性的算法。
在检测到回环之后,我们会把“A 与 B 是同一个点”这样的信息告诉后端优化算法。然后,后端根据这些新的信息,把轨迹和地图调整到符合回环检测结果的样子。这样,如果我们有充分而且正确的回环检测,就可以消除累积误差,得到全局一致的轨迹和地图。
建图
指构建地图的过程。地图是对环境的描述,但这个描述并不是固定的,需要视SLAM的应用而定。
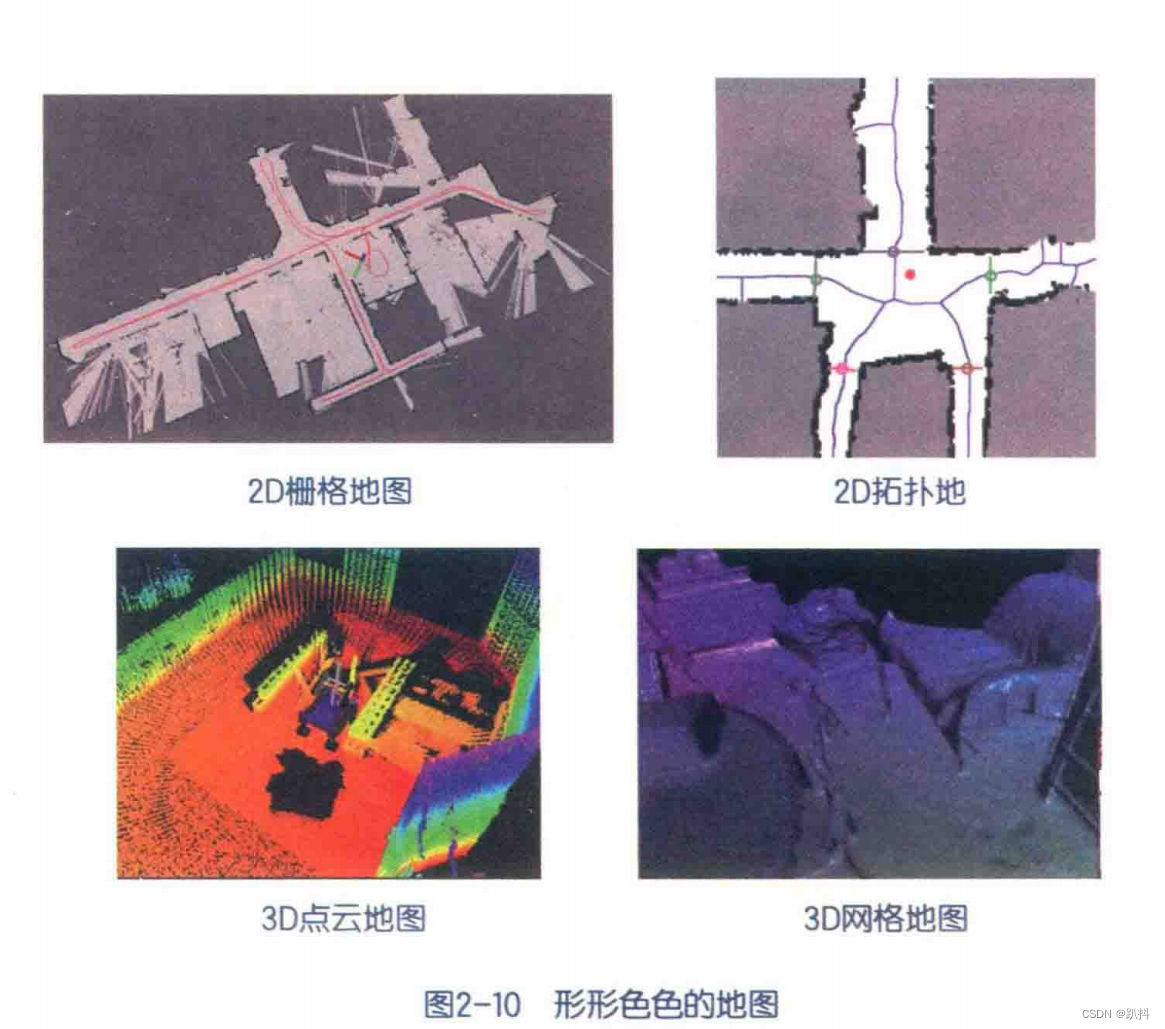
对于地图,我们有太多的想法和需求。因此。相比于前面提到的视觉里程计、后端优化和回环检测,建图并没有一个固定的形式和算法。大体上讲,可以分为度量地图和拓补地图两种。
度量地图(Metric Map)
度量地图强调精确地表示地图中物体的位置关系,通常我们用稀疏(Sparse)与稠密(Dense)对它们进行分类。
稀疏地图进行了一定程度的抽象,并不需要表达所有的物体。例如,我们选择一部分具有代表意义的东西,称之为路标(Landmark),那么一张稀疏地图就是由路标组成的地图,而不是路标的部分就可以忽略掉。
稠密地图着重于建模所有看到的东西。对于定位来说,稀疏路标地图就足够了。而用于导航时,我们往往需要稠密的地图。稠密地图通常按照某种分辨率,由许多个小块组成。二维度量地图是许多个小格子(Grid),三维则是许多小方块(Voxel)。一般地,一个小块含有占据、空闲、未知三种状态,以表达该格内是否有物体。当我们查询某个空间位置时,地图能够给出该位置是否可以通过的信息。这样的地图可以用于各种导航算法。
但是一方面,这种地图需要存储每一个格点的状态,耗费大量的存储空间,而且多数情况下地图的许多细节部分是无用的。另一方面,大规模度量地图有时会出现一致性问题。很小的一点转向误差,可能会导致两间屋子的墙出现重叠,使地图失效。
拓扑地图(Topological Map)
相比于度量地图的精确性,拓扑地图则更强调地图元素之间的关系。拓扑地图是一个图(Graph),由节点和边组成,只考虑节点间的连通性,例如只关注 A,B 点是连通的,而不考虑如何从A点到达B点的过程。它放松了地图对精确位置的需要,去掉地图的细节,是一种更为紧凑的表达方式。
但是拓扑地图不擅长表达具有复杂结构的地图。如何对地图进行分割形成结点与边,又如何使用拓扑地图进行导航与路径规划,仍是有待研究的问题。
SLAM的数学描述
现在假设有个机器人正携带某种传感器在未知环境里运动。由于相机通常是在某些时刻采集数据的,所以我们也只关心这些时刻的位置和地图。这就把一段连续时间的运动变成了离散时刻t=1,…,K当中发生的事情,用x表示位置,于是各时刻的位置就记为x1,…,xK,它们构成了机器人运动的轨迹。地图方面,假设地图是由许多个路标组成的,而每个时刻,传感器会测量到一部分路标点,得到它们的观测数据。设路标点一共有N个,用y1,…,yN来表示。
在如上设定中,机器人携带着传感器在环境中运动这件事,由如下两件事情描述:
-
什么是运动?要考察从k−1时刻到k时刻,机器人的位置x是如何变化的。
通常,机器人会携带一个测量自身运动的传感器,比如说码盘或惯性传感器。这个传感器可以测量有关运动的读数,但不一定直接是位置之差,还可能是加速度、角速度等信息。无论是什么传感器,我们都能使用一个通用的、抽象的数学模型:
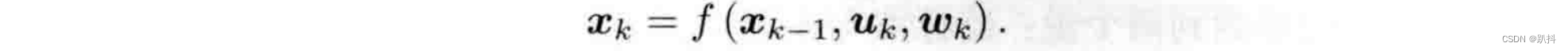 这里uk是运动传感器的输入,wk 为该过程中加入的噪声。这称为运动方程。噪声的存在使得这个模型变成了随机模型,每次运动过程中的噪声是随机的。如果不理会这个噪声,只根据指令来确定位置,可能与实际位置差的很多。
这里uk是运动传感器的输入,wk 为该过程中加入的噪声。这称为运动方程。噪声的存在使得这个模型变成了随机模型,每次运动过程中的噪声是随机的。如果不理会这个噪声,只根据指令来确定位置,可能与实际位置差的很多。 -
什么是观测?假设机器人在k时刻,于xk处探测到了某一个路标yj,要考虑这件事情是如何用数学语言来描述的。
与运动方程相对应,观测方程描述的是:当机器人在xk位置上看到某个路标点yj时,产生了一个观测数据z(k,j):
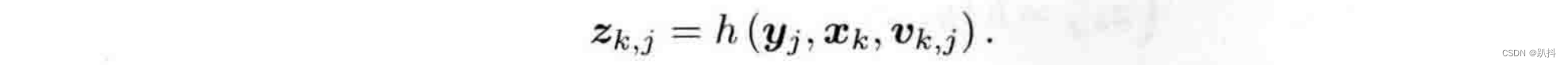
v(k,j)是这次观测里的噪声。
根据机器人的真实运动和传感器的种类,存在着若干种参数化方式(Parameterization)。
假设机器人在平面中运动,那么,它的位姿(位置和姿态)由两个位置和一个转角来描述,x1, x2 是两个轴上的位置而 θ 为转角,即
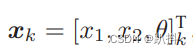
输入的指令是两个时间间隔位置和转角的变化量:
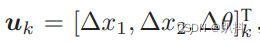
于是,此时运动方程可以化为:

并不是所有的输入指令都是位移和角度的变化量,比如“油门”或者 “控制杆”的输入就是速度或加速度量,存在着其他形式更加复杂的运动方程,我们需要进行动力学分析。
关于观测方程,以机器人携带着一个二维激光传感器为例。我们知道激光传感器观测一个2D路标点时,能够测到两个量:路标点与机器人本体之间的距离 r 和夹角 ϕ。
记路标点为
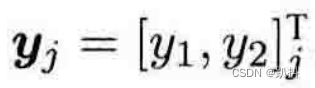
位姿为
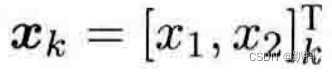
观测数据为
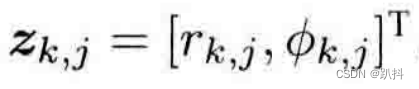
那么观测方程就写为:

其实就是一个勾股定理的事情。
考虑视觉 SLAM 时,传感器是相机,那么观测方程就是“对路标点拍摄后,得到了图像中的像素”的过程。 针对不同的传感器,这两个方程有不同的参数化形式。取成通用的抽象形式,SLAM过程可总结为两个基本方程:
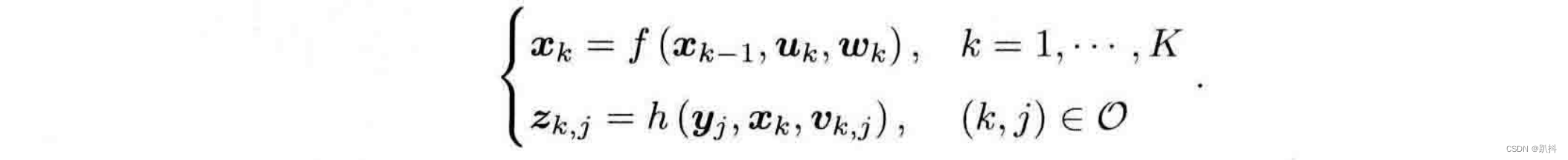
这两个方程描述了最基本的SLAM问题:当知道运动测量的读数u,以及传感器的读数z 时,如何求解定位问题(估计x)和建图问题(估计y)?这时,我们把 SLAM 问题建模成了一个状态估计问题:如何通过带有噪声的测量数据,估计内部的、隐藏着的状态变量?
状态估计问题的求解,与两个方程的具体形式,以及噪声服从哪种分布有关。
我们按照运动和观测方程是否为线性,噪声是否服从高斯分布进行分类,分为线性/非线性和高斯/非高斯系统。其中线性高斯系统(Linear Gaussian, LG 系统)是最简单的,它的无偏的最优估计可以由卡尔曼滤波器(Kalman Filter, KF)给出。而在复杂的非线性非高斯系统 (Non-Linear Non-Gaussian,NLNG 系统)中,我们会使用以扩展卡尔曼滤波器(Extended Kalman Filter, EKF)和非线性优化两大类方法去求解它。
直至21世纪早期,以 EKF 为主的滤波器方法占据了 SLAM 中的主导地位。我们会在在工作点处把系统线性化,并以预测——更新两大步骤进行求解。最早的实时视觉SLAM系统即是基于EKF开发的。随后,为了克服 EKF 的缺点(例如线性化误差和噪声高斯分布假设),人们开始使用粒子滤波器(Particle Filter)等其他滤波器,乃至使用非线性优化的方法。时至今日,主流视觉 SLAM 使用以图优化(Graph Optimization)为代表的优化技术进行状态估计。我们认为优化技术已经明显优于滤波器技术,只要计算资源允许,我们通常都偏向于使用优化方法。
机器人更多时候是一个三维空间里的机器人。三维空间的运动由3个轴构成,所以机器人的运动要由3个轴上的平移,以及绕着3个轴的旋转来描述,这一共有6个自由度。在视觉SLAM 中,对6自由度的位姿如何表达,优化,需要三维空间刚体运动以及李群李代数的知识。观测方程如何参数化,即空间中的路标点是如何投影到一张照片上的,这需要解释相机的成像模型。最后,怎么求解上述方程?这需要非线性优化的知识。
相关文章:
【视觉SLAM十四讲学习笔记】第二讲——初识SLAM
专栏系列文章如下: 【视觉SLAM十四讲学习笔记】第一讲 一个机器人,如果想要探索某一块区域,它至少需要知道两件事: 我在什么地方——定位周围环境是什么样——建图 一方面需要明白自身的状态(即位置)&#…...
Python交易-通过Financial Modeling Prep (FMP)选择行业
介绍 在您的交易旅程中,无论您是在寻找理想的股票、板块还是指标,做出明智的决策对于您的成功至关重要。然而,收集和分析所需的大量数据可能相当艰巨。财务建模准备 (FMP) API的...
AI创作系统ChatGPT网站源码+详细搭建部署教程+支持DALL-E3文生图/支持最新GPT-4-Turbo-With-Vision-128K多模态模型
一、AI创作系统 SparkAi创作系统是基于OpenAI很火的ChatGPT进行开发的Ai智能问答系统和Midjourney绘画系统,支持OpenAI-GPT全模型国内AI全模型。本期针对源码系统整体测试下来非常完美,可以说SparkAi是目前国内一款的ChatGPT对接OpenAI软件系统。那么如…...
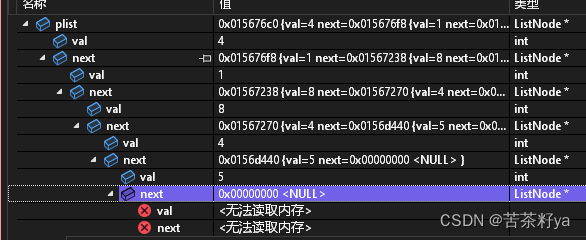
快速生成力扣链表题的链表,实现快速调试
关于力扣链表题需要本地调试创建链表的情况 我们在练习链表题,力扣官方需要会员,我们又不想开会员,想在本地调试给你们提供的代码 声明:本人也是参考的别人的代码,给你们提供不同语言生成链表 参考链接: 参…...
threejs(13)-着色器设置点材质
着色器材质内置变量 three.js着色器的内置变量,分别是 gl_PointSize:在点渲染模式中,控制方形点区域渲染像素大小(注意这里是像素大小,而不是three.js单位,因此在移动相机是,所看到该点在屏幕…...

计算机网络专栏 学习导航or使用说明
计算机网络各章笔记 计算机网络_第一章_计算机网络的概述 计算机网络_第二章_物理层 计算机网络_第三章_数据链路层 计算机网络_第四章网络层_网络层概述_网际协议IP 计算机网络各章习题 计算机网络第一章习题_网络概述 计算机网络第二章习题_物理层 计算机网络第三章习…...
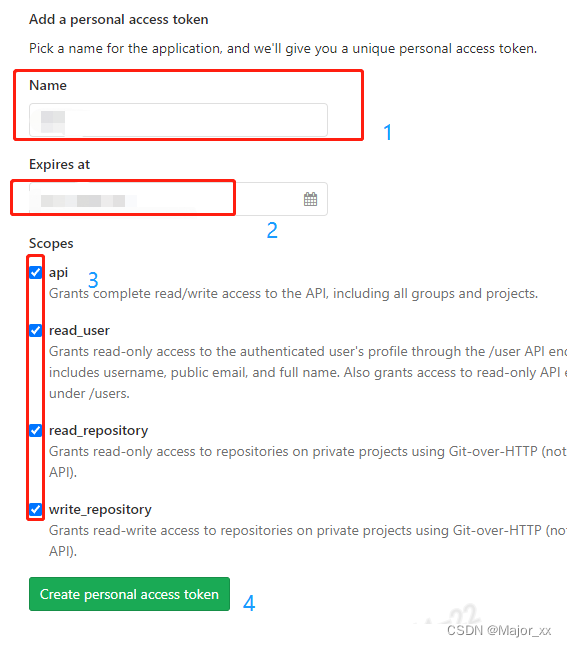
git clone:SSL: no alternative certificate subject name matches target host name
git clone 时的常见错误: fatal: unable to access ‘https://ip_or_domain/xx/xx.git/’: SSL: no alternative certificate subject name matches target host name ‘ip_or_domain’ 解决办法: disable ssl verify git config --global http.sslVe…...

代码随想录图论|130. 被围绕的区域 417太平洋大西洋水流问题
130. 被围绕的区域 **题目:**给你一个 m x n 的矩阵 board ,由若干字符 ‘X’ 和 ‘O’ ,找到所有被 ‘X’ 围绕的区域,并将这些区域里所有的 ‘O’ 用 ‘X’ 填充。 题目链接:130. 被围绕的区域 解题思路:…...

Outlook无法显示阅读窗格
Outlook无法显示阅读窗格 故障现象 Outlook主界面不显示阅读窗格 故障截图 故障原因 阅读窗格被关闭 解决方案 1、打开Outlook - 视图 – 阅读窗格 2、选择“靠右”或者“底部”,正常显示阅读窗格...
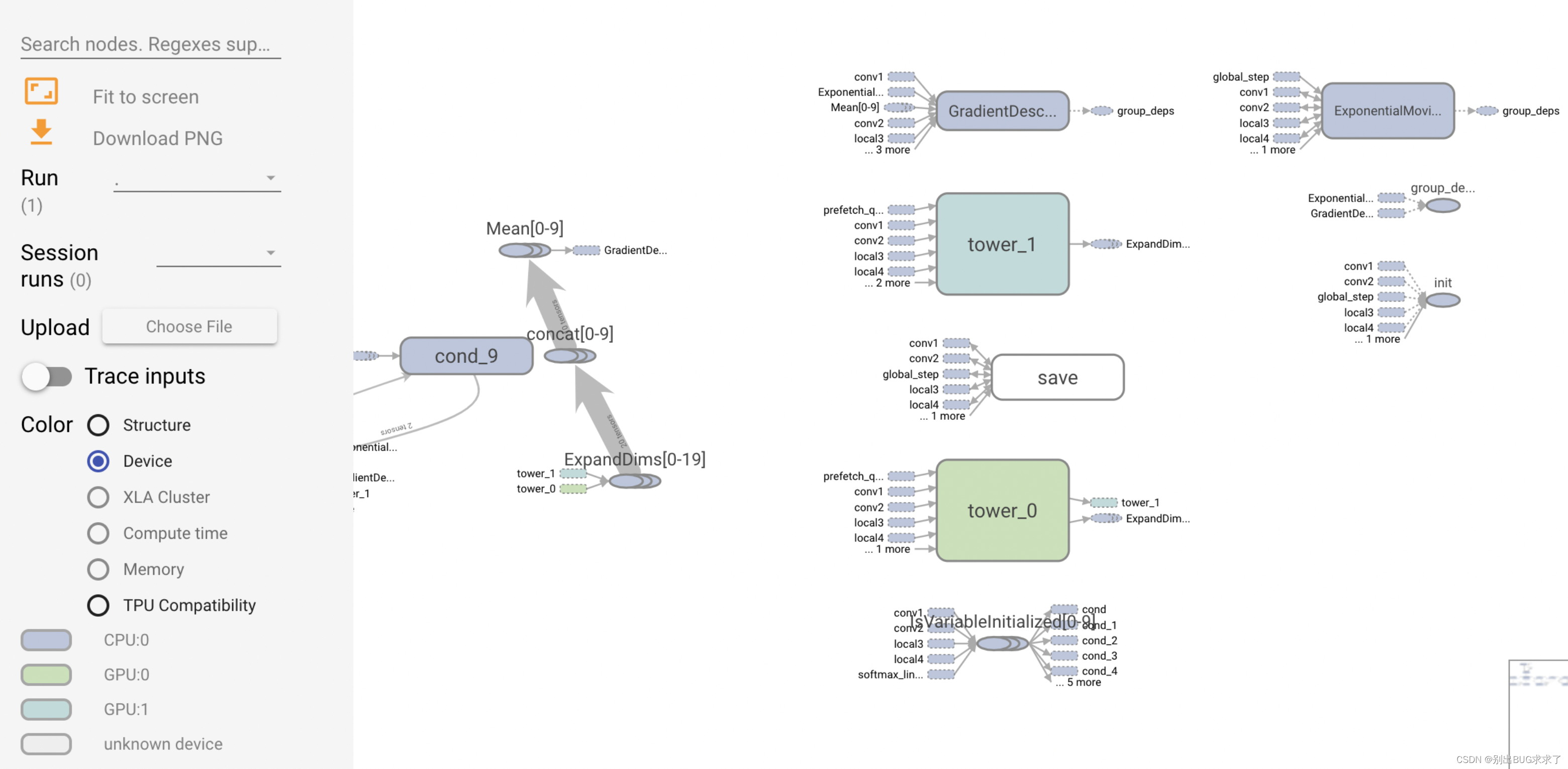
tensorflow 1.15 gpu docker环境搭建;Nvidia Docker容器基于TensorFlow1.15测试GPU;——全流程应用指南
前言: TensorFlow简介 TensorFlow 在新款 NVIDIA Pascal GPU 上的运行速度可提升高达 50%,并且能够顺利跨 GPU 进行扩展。 如今,训练模型的时间可以从几天缩短到几小时 TensorFlow 使用优化的 C 和 NVIDIA CUDA 工具包编写,使模型能够在训练…...
一个22届被裁前端思想上得转变
距离上篇文章已经过去了三个多月,这个三个月,经历了技术攻坚,然后裁员,退房,回老家,找工作。短短的几个月,就经历社会的一次次毒打,特别是找工作,虽然算上实习我也有两年…...
Python开源项目GPEN——人脸重建(Face Restoration),模糊清晰、划痕修复及黑白上色的实践
无论是自己、家人或是朋友、客户的照片,免不了有些是黑白的、被污损的、模糊的,总想着修复一下。作为一个程序员 或者 程序员的家属,当然都有责任满足他们的需求、实现他们的想法。除了这个,学习了本文的成果,或许你还…...

Android studio2022.3项目中,底部导航菜单数多于3个时,只有当前菜单显示文本,其他非选中菜单不显示文本
在Android Studio 2022.3 中,底部导航菜单通常使用 BottomNavigationView 实现。默认情况下,当底部导航菜单中的标签数量超过三个时,非选中的标签将不会显示文本,而只会显示图标。 这是 Android 设计规范的一部分,旨在…...
使用 Redis 构建轻量的向量数据库应用:图片搜索引擎(二)
本篇文章我们来继续聊聊轻量的向量数据库方案:Redis,如何完成整个图片搜索引擎功能。 写在前面 在上一篇文章《使用 Redis 构建轻量的向量数据库应用:图片搜索引擎(一)》中,我们聊过了构建图片搜索引擎的…...

Java-贪吃蛇游戏
前言 此实现较为简陋,如有错误请指正。 其次代码中的图片需要自行添加地址并修改。 主类 public class Main {public static void main(String[] args) {new myGame();} }游戏类 import javax.swing.*; import java.awt.event.KeyEvent; import java.awt.event.…...
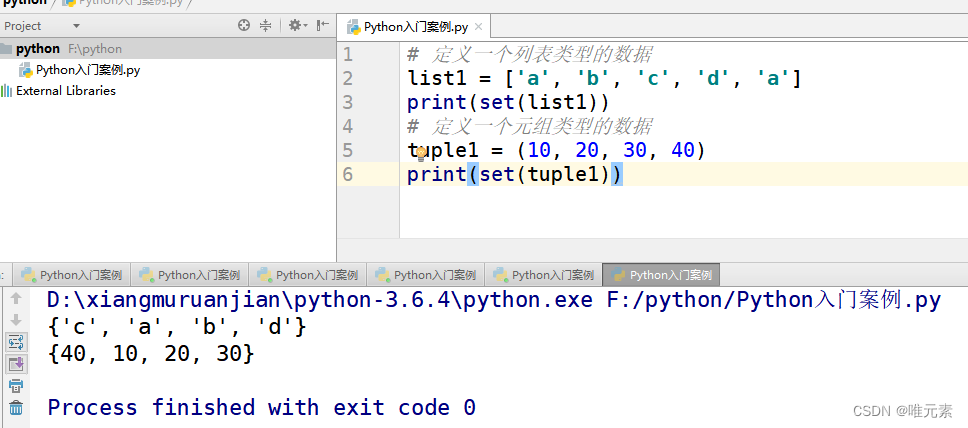
Python---数据序列类型之间的相互转换
list()方法:把某个序列类型的数据转化为列表 # 1、定义元组类型的序列 tuple1 (10, 20, 30) print(list(tuple1))# 2、定义一个集合类型的序列 set1 {a, b, c, d} print(list(set1))# 3、定义一个字典 dict1 {name:刘备, age:18, address:蜀中} print(list(dict1…...

gitlab 12.7恢复
一 摘要 本文主要介绍基于gitlab 备份包恢复gitlab 二 环境信息 科目老环境新环境操作系统centos7.3centos7.6docker19.0.319.0.3gitlab12.712.7 三 实施 主要有安装docker\docker-compose\gitlab 备份恢复三个文件 1.gitlab 配置文件gitlab.rb 2.gitlab 加密文件gitlab-s…...
将ECharts图表插入到Word文档中
文章目录 在后端调用JS代码准备ECharts库生成Word文档项目地址库封装本文示例 EChartsGen_DocTemplateTool_Sample 如何通过ECharts在后台生成图片,然后插入到Word文档中? 首先要解决一个问题:总所周知,ECharts是前端的一个图表库…...
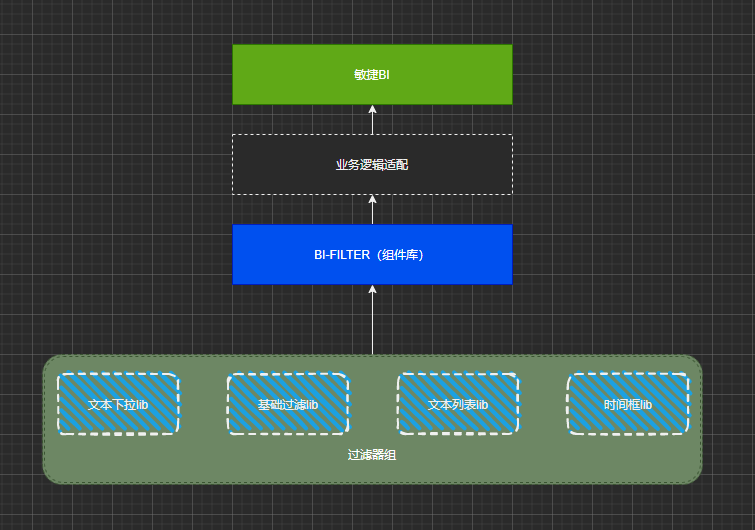
BI 数据可视化平台建设(2)—筛选器组件升级实践
作者:vivo 互联网大数据团队-Wang Lei 本文是vivo互联网大数据团队《BI数据可视化平台建设》系列文章第2篇 -筛选器组件。 本文主要介绍了BI数据可视化平台建设中比较核心的筛选器组件, 涉及组件分类、组件库开发等升级实践经验,通过分享一些…...
RabbitMQ 安装及配置
前言 当你准备构建一个分布式系统、微服务架构或者需要处理大量异步消息的应用程序时,消息队列就成为了一个不可或缺的组件。而RabbitMQ作为一个功能强大的开源消息代理软件,提供了可靠的消息传递机制和灵活的集成能力,因此备受开发人员和系…...

除了ulimit -c unlimited:深入理解Linux core dump机制与高级配置指南
深入Linux核心转储:从基础配置到生产环境实战指南当服务器上的关键应用突然崩溃时,系统管理员最需要的就是一份完整的"事故现场记录"。Linux的core dump机制正是为此而生,它能保存程序崩溃时的内存状态、寄存器值和调用堆栈&#x…...

基于Arduino与应变片传感器的高精度厨房电子秤DIY全攻略
1. 项目概述:用Arduino打造一台高精度厨房电子秤作为一个喜欢在厨房里折腾的硬件爱好者,我经常遇到需要精确称量食材的场合。市面上的电子秤要么精度不够,要么价格不菲,要么功能单一。于是,我萌生了自己动手做一台的想…...

BurpSuite 2025插件开发JDK版本兼容性实战指南
1. 为什么BurpSuite插件开发环境总在JDK版本上翻车?你是不是也经历过:下载好BurpSuite最新版2025.4,兴冲冲打开插件开发文档,照着官方示例写完第一个HelloWorld插件,一编译——java.lang.UnsupportedClassVersionError…...

终极艾尔登法环帧率解锁指南:轻松突破60FPS限制
终极艾尔登法环帧率解锁指南:轻松突破60FPS限制 【免费下载链接】EldenRingFpsUnlockAndMore A small utility to remove frame rate limit, change FOV, add widescreen support and more for Elden Ring 项目地址: https://gitcode.com/gh_mirrors/el/EldenRing…...

MAX78000移植Zephyr RTOS实战:从BSP创建到AI边缘设备开发
1. 项目概述与动机作为一名长期在嵌入式边缘AI和机器人领域摸爬滚打的开发者,我最近把目光投向了一块相当有潜力的板子:Maxim Integrated(现为ADI一部分)的MAX78000FTHR开发套件。这块板子的核心——MAX78000微控制器,…...

3步解锁网易云音乐NCM加密:让音乐真正属于你
3步解锁网易云音乐NCM加密:让音乐真正属于你 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 还在为下载的网易云音乐只能在特定客户端播放而烦恼吗?当你精心收藏的歌曲被NCM格式"锁"在单一平台时&a…...

荣耀出征官方网站下载正版手游 翅膀养成细节玩法全方位讲解
玩荣耀出征的玩家都清楚,翅膀不仅是角色的颜值象征,更是提升整体战力的核心途径。很多新手玩家只顾着升级、刷装备,完全忽略翅膀养成,导致等级很高但战力始终上不去。还有不少玩家胡乱合成、盲目进阶,浪费了大量稀有翅…...

Ubuntu经常安装软件
1、垃圾清理工具stacer sudo apt updatesudo apt install stacer apt cleanapt autocleanapt autoremove 2、类似与everything的工具Fsearcch 1sudo add-apt-repository ppa:christian-boxdoerfer/fsearch-stable 2sudo apt update 3sudo apt install fsearch (注…...

基于ISDN信令的来电语音播报系统:从原理到树莓派实现
1. 项目概述:一个基于ISDN的来电语音播报系统如果你家里或办公室里还有一台老式的ISDN路由器,别急着把它当电子垃圾处理掉。我最近就利用手头一台闲置的ISDN路由器,折腾出了一个挺有意思的小玩意儿:一个能自动识别来电号码&#x…...

AI 如何改变软件工程:Martin Fowler 视角 + 实战洞见
AI 如何改变软件工程:Martin Fowler 视角 实战洞见 AI(尤其是 LLM)是软件工程自高级语言(从汇编到 C/Fortran)以来最大的转变。它引入了非确定性(Non-deterministic)编程,改变了从编…...