Pytorch多GPU并行训练: DistributedDataParallel
1 模型并行化训练
1.1 为什么要并行训练
在训练大型数据集或者很大的模型时一块GPU很难放下,例如最初的AlexNet就是在两块GPU上计算的。并行计算一般采取两个策略:一个是模型并行,一个是数据并行。左图中是将模型的不同部分放在不同GPU上进行训练,最后汇总计算。而右图中是将数据放在不同GPU上进行训练,最后汇总计算,不仅能增大BatchSize,还能加快计算速度,提高计算精度
1.2 并行化训练策略
并行化深度学习模型有两种流行的方式:模型并行和数据并行
-
模型并行
模型并行性是指模型在逻辑上分为几个部分(即,一个部分中的某些层,而另一部分中的某些层),然后将其放置在不同的硬件/设备上。尽管将零件放在不同的设备上确实在执行时间(数据的异步处理)方面有很多好处,但通常可以采用它来避免内存限制。具有大量参数的模型由于这种类型的策略而受益,这些模型由于内存占用量大而难以放入单个系统中。
-
数据并行
另一方面,数据并行性是指通过位于不同硬件/设备上的同一网络的多个副本来处理多段数据(技术上为批次)。与模型并行性不同,每个副本可能是整个网络,而不仅仅是一部分。这种策略可以随着数据量的增加而很好地扩展。但是,由于整个网络必须驻留在单个设备上,因此无法帮助占用大量内存的模型。

1.3 单机多卡与多级多卡
在深度学习和其他高性能计算任务中,"单机多卡"(Single-Node Multi-GPU)和"多机多卡"(Multi-Node Multi-GPU)是两种常见的硬件配置,它们涉及使用多个图形处理单元(GPUs)来加速计算。单机多卡配置通常更容易管理和维护,而多机多卡配置提供了更高的计算能力和扩展性,但也带来了更高的复杂度和成本。
2.1.1 单机多卡 (Single-Node Multi-GPU)
-
定义:所有的 GPU 都安装在同一台机器上。
-
通信:GPU之间通过PCIe总线或者更高带宽的NVLink进行通信。
-
适用性:适合中等规模的数据集和模型,通常用于实验室环境或小规模的商业应用。
-
设置复杂度:相对简单,因为所有的通信都在一个节点内部进行。
-
扩展性:受限于单个节点能够支持的最大GPU数量。
-
示例场景:在一个数据中心的单个服务器上训练深度学习模型。
2.1.2 多机多卡 (Multi-Node Multi-GPU)
-
定义:GPU 分布在多台机器上,这些机器通过网络连接。
-
通信:机器之间的通信通过高速网络(例如InfiniBand)进行,但比单节点内部的通信要慢。
-
适用性:适合大规模数据集和模型,通常用于大型数据中心或复杂的机器学习任务。
-
设置复杂度:更复杂,需要管理节点间的网络通信和同步。
-
扩展性:理论上可以通过增加更多节点来无限扩展。
-
示例场景:在多个数据中心分布的服务器上训练大型深度学习模型,如训练大型语言模型或复杂的科学计算任务。
2 使用DistributedDataParallel实现模型并行化训练
2.1 基本概念
DistributedDataParallel中的关键概念


训练过程示意如下:
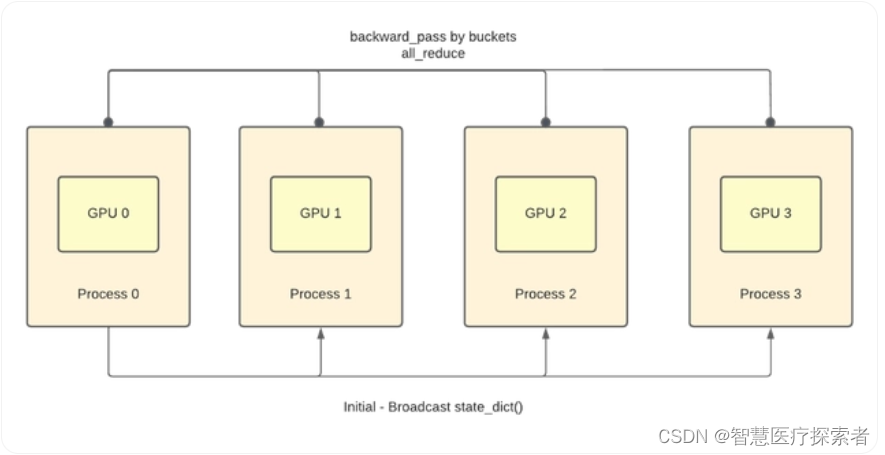
分布式训练的启动有两种方法,一种是torch.multiprocessing,还有一种是torch.distributed
- 第一种在启动程序时不需要在命令行输入额外的参数,写起来也比较容易,但是调试较麻烦,比如MAE;
- 第二种必须要用命令行启动,写起来略微复杂,但是调试较方便。
2.2 torch.distributed分布式训练步骤
2.2.1 导入分布式模块
其中distributed中必须导入的是以下模块
import torch.distributed as dist2.2.2 用argparse编写模型的个性化参数
parser = argparse.ArgumentParser()''' ...your params '''
''' ...distributed params'''# 开启的进程数,不用设置该参数,会根据nproc_per_node自动设置
parser.add_argument('--world-size', default=4, type=int, help='number of distributed processes')
parser.add_argument('--local_rank', type=int, help='rank of distributed processes')
opt = parser.parse_args()
注意这里如果使用了argparse方法的话,必须传入local_rank参数,系统会自动给他进行赋值,如果不传入会报错!
2.2.3 初始化distributed
初始化过程如下:假设我们的world_size=8,那么我们有8张GPU初始化,初始化有快有慢,快的GPU初始化会在dist.barrier()处停下来等待,当所有的GPU都到达这个函数时,才会继续运行之后的代码。
# 初始化各进程环境
if 'RANK' in os.environ and 'WORLD_SIZE' in os.environ:args.rank = int(os.environ["RANK"])args.world_size = int(os.environ['WORLD_SIZE'])args.gpu = int(os.environ['LOCAL_RANK'])
else:print('Not using distributed mode')return# 设置当前程序使用的GPU。根据python的机制,在单卡训练时本质上程序只使用一个CPU核心,而DataParallel
# 不管用了几张GPU,依然只用一个CPU核心,在分布式训练中,每一张卡分别对应一个CPU核心,即几个GPU几个CPU核心
torch.cuda.set_device(args.gpu)# 分布式初始化
args.dist_url = 'env://' # 设置url
args.dist_backend = 'nccl' # 通信后端,nvidia GPU推荐使用NCCL
print('| distributed init (rank {}): {}'.format(args.rank, args.dist_url), flush=True)
dist.init_process_group(backend=args.dist_backend, init_method=args.dist_url, world_size=args.world_size, rank=args.rank)
dist.barrier() # 等待所有进程都初始化完毕,即所有GPU都要运行到这一步以后在继续'''
| distributed init (rank 1): env://
| distributed init (rank 2): env://
| distributed init (rank 0): env://
| distributed init (rank 3): env://
''' torch.distributed.init_process_group 是PyTorch中的一个函数,它用于初始化默认的分布式进程组,从而允许进行跨多个进程的通信。这个函数在使用 PyTorch 的分布式功能时非常重要,特别是在使用 DistributedDataParallel (DDP) 进行多GPU或多节点训练时。真正意义上来讲,分布式的初始化就只有dist.init_process_group这一句。
从上面我们print的输出可以得到不同GPUs初始化的速度是不同的,这也正是因为每个GPU都分配了一个CPU核心,他们的速度有快有慢,比如本次实验初始化顺序为1,2,0,3
关于环境变量,有一下几点需要注意
- local_rank是被自动赋值的,在单机多卡中他和rank的值相同
- os.environ[“RANK”]是没有值的,运行时在命令行上输入python -m torch.distributed.launch --nproc_per_node=4 --use_env train.py他才被赋予了值
- –nproc_per_node=4这条指令可以将os.environ[“WORLD_SIZE”]赋值为4
- 如果用argparse这个库,就必须加上local_rank变量,如果忘记加了,在命令行启动时就需要加上–use_env参数,–use_env 表示 Local Rank 用 LOCAL_RANK 这个环境变量传参
2.2.4 设置数据集分布式的数据集加载
设置数据集分布式的数据集加载不同于之前的单卡,这里需要将数据集分为N部分,N为卡的数量。单卡时只需要设置Datasets→DataLoader即可,但是分布式中需要对每一块GPU分配不重复的数据,分配方式也不难,分配方式变为:Datasets→DistributedSampler→BatchSampler→DataLoader(BatchSampler可以省略)
DistributedSampler将数据集N等分,BatchSamper将每一等分后的数据内部进行batch的划分。BatchSampler的作用就是分配batchsize,这一步可以再DataLoader中分配,因此也可以将BatchSampler省略。下图展示了数据集的分配过程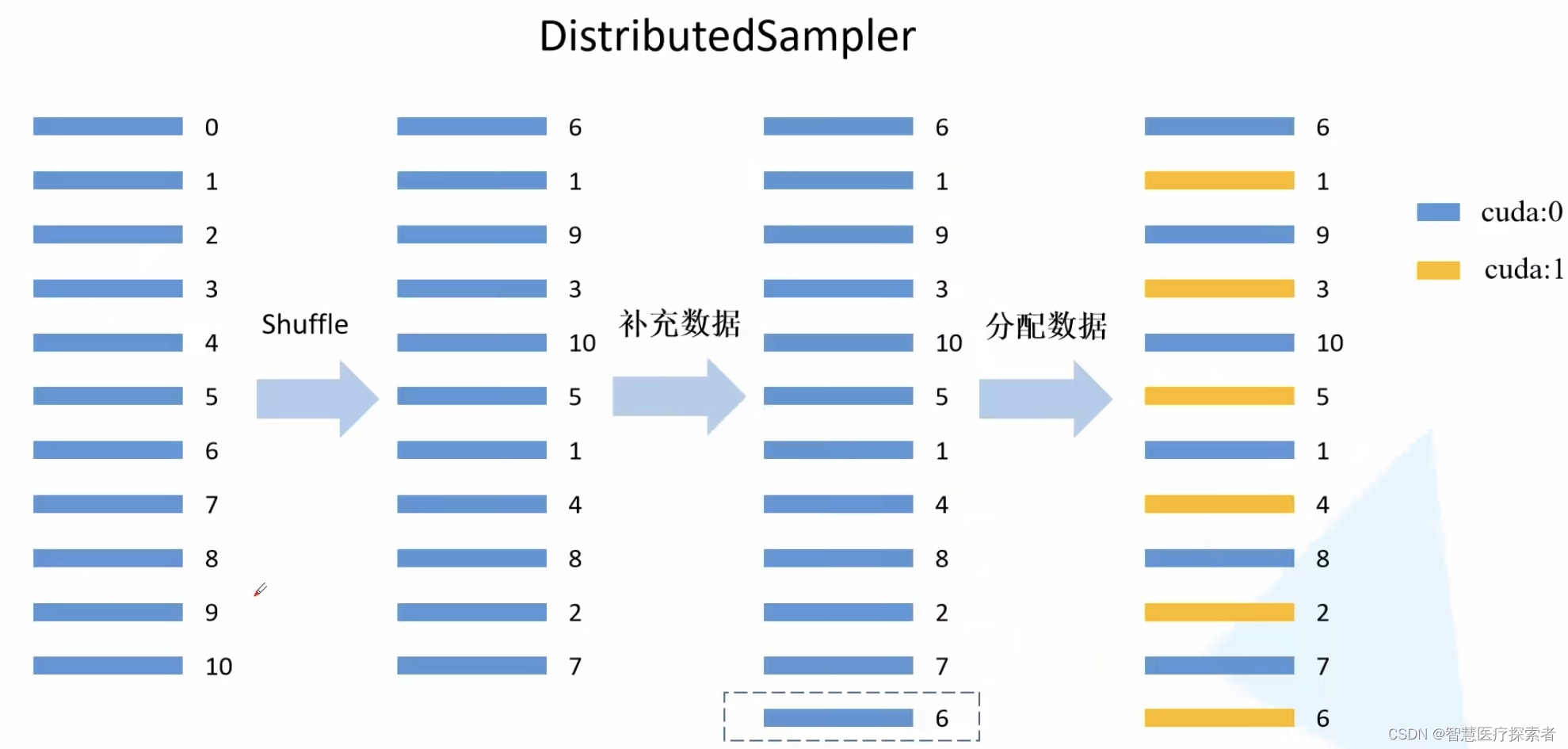
# 1. datasets
train_datasets = MyDataSet(xxx)
val_datasets = MyDataSet(xxx)# 2. DistributedSampler
# 给每个rank对应的进程分配训练的样本索引,比如一共800样本8张卡,那么每张卡对应分配100个样本
train_sampler = torch.utils.data.distributed.DistributedSampler(train_datasets)
val_sampler = torch.utils.data.distributed.DistributedSampler(val_datasets)# 3. BatchSampler
# 刚才每张卡分了100个样本,假设BatchSize=16,那么能分成100/16=6...4,即多出4个样本
# 下面的drop_last=True表示舍弃这四个样本,False将剩余4个样本为一组(注意最后就不是6个一组了)
train_batch_sampler = torch.utils.data.BatchSampler(train_sampler, batch_size, drop_last=True)# 4. DataLoader
# 验证集没有采用batchsampler,因此在dataloader中使用batch_size参数即可
train_dataloader = torch.utils.data.DataLoader(train_datasets,batch_sampler=train_batch_sampler, pin_memory=True, num_workers=nw)
val_dataloader = torch.utils.data.DataLoader(val_datasets,batch_size=batch_size, sampler=val_sampler, pin_memory=True, num_workers=nw)2.2.5 加载模型到所有GPUs上
在训练时,因为我们用到了DistributedSampler,所以需要每一个epoch都将原数据打乱一下,其他剩下的过程和单卡相同
model = UNet().cuda()
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[rank])
...for epoch in range(start_epoch, n_epochs):if is_distributed:train_sampler.set_epoch(epoch)...2.2.6 启动分布式训练
python -m torch.distributed.launch --nproc_per_node=4 --master_port=2424 --use_env main.py (your_argparse_params)在pytorch新版中将python -m torch.distributed.launch替换为了torchrun,在训练时我们需要指定通讯端口master_port,也可以让程序自动寻找,即将--master_port=xxxx替换为--rdzv_backend c10d --master_port=0
2.3 torch.multiprocessing分部署训练步骤
通过核心函数spawn函数调用GPU并行,函数的参数如下:
torch.multiprocessing.spawn(fn, args=(), nprocs=1, join=True, daemon=False, start_method='spawn')
- fn:这个就是我们要分布式运行的函数,一般来说是main函数,main(rank, *args),其中rank为必须,单机多卡中可以理解为第几个GPU,args为函数传入的参数,类型tuple,在spawn(…args)的args参数中定义
- args:传入fn的参数,tuple
- nprocs:进程数,即几张卡
- join: 默认为True即可
- daemon: 默认为False即可
# 调用
mp.spawn(main, args=(opt, ), nprocs=opt.world_size, join=True)与distributed大同小异,完整的训练代码如下:
# 单机多卡并行计算示例
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "6, 7"import torch
import torch.distributed as dist
import torch.multiprocessing as mp
import torch.nn as nn
import torch.optim as optim
from torch.nn.parallel import DistributedDataParallel as DDPdef example(rank, world_size):# create default process groupdist.init_process_group("gloo", init_method='tcp://127.0.0.1:6666', rank=rank, world_size=world_size)# create local modelmodel = nn.Linear(10, 10).to(rank)# construct DDP modelddp_model = DDP(model, device_ids=[rank])# define loss function and optimizerloss_fn = nn.MSELoss()optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)# forward passoutputs = ddp_model(torch.randn(20, 10).to(rank))labels = torch.randn(20, 10).to(rank)# backward passloss_fn(outputs, labels).backward()# update parametersoptimizer.step()print("finished rank: {}".format(rank))def main():world_size = torch.cuda.device_count()mp.spawn(example,args=(world_size,),nprocs=world_size,join=True)if __name__=="__main__":main()2.4 dist.barrier()函数
单机多卡环境下使用分布式训练具有更快的速度。PyTorch在分布式训练过程中,对于数据的读取是采用主进程预读取并缓存,然后其它进程从缓存中读取,不同进程之间的数据同步具体通过torch.distributed.barrier()实现,示例如下:
if args.local_rank not in [-1, 0]:torch.distributed.barrier() # Make sure only the first process in distributed training will download model & vocab... (loads the model and the vocabulary)if args.local_rank == 0:torch.distributed.barrier() # Make sure only the first process in distributed training will download model & vocab假设我们有4张卡[0, 1, 2, 3],其中[0]卡是first process或者base process,有些操作不需要所有的卡同时进行,比如在预处理的时候只用base process即可。
在上述代码中,第一个if是说除了主卡之外的卡运行到此处会被barrier,也就是说运行到这里就停止了,而base process不会停止,会继续运行,执行预加载模型等操作,当主卡运行到第二个if时,他也会进入到barrier,就是说他已经预加载完了,现在他也需要被barrier了。
此时所有的卡都进入到了barrier,意味着所有的卡可以继续运行(主卡已经加载完了,这个数据所有的卡都可以使用),此后,所有的卡从barrier撤出,开始执行训练。
a process is blocked by a barrier until all processes have encountered a barrier, upon which the barrier is lifted for all processes
3 一个完整的例子
3.1 初始化进程组
import os
from torch import distributedtry:world_size = int(os.environ["WORLD_SIZE"]) # 全局进程个数rank = int(os.environ["RANK"]) # 当前进程编号(全局)local_rank = int(os.environ["LOCAL_RANK"]) # 每台机器上的进程编号(局部)distributed.init_process_group("nccl") # 初始化进程, 使用nccl后端
except KeyError:world_size = 1rank = 0local_rank = 0distributed.init_process_group(backend="nccl",init_method="tcp://127.0.0.1:12584",rank=rank,world_size=world_size,)3.2 使用DistributedSampler划分数据集
与nn.DataParrallel不同的是,分布式训练中的batch_size为单卡的输入样本数,因为它代表的是当前rank下对应的partition,总batch_size是这里的batch_size再乘以并行数。举个例子,假设使用8张卡训练模型,nn.DataParrallel中的batch_size为3200,nn.DistributedDataParallel中的batch_size则为400。
from dataloader.distributed_sampler import DistributedSamplertrain_sampler = DistributedSampler(train_set, num_replicas=world_size, rank=rank, shuffle=True, seed=seed)
trainloader = DataLoader(dataset=train_set,pin_memory=true,batch_size=batch_size,num_workers=num_workers,sampler=train_sampler
) # pin_memory: 是否提前申请CUDA内存. 创建DataLoader时,设置pin_memory=True,则意味着生成的Tensor数据最开始是属于内存中的锁页内存,这样将内存的Tensor转义到GPU的显存就会更快一些.3.3 使用DistributedDataParallel封装模型
DistributedDataParallel能够为不同GPU上求得的梯度进行all reduce(即汇总不同GPU计算所得的梯度,并同步计算结果)。all reduce后不同GPU中模型的梯度均为all reduce之前各GPU梯度的均值。
backbone = get_model(cfg.network, dropout=0.0, fp16=cfg.fp16, num_features=cfg.embedding_size).cuda()backbone = torch.nn.parallel.DistributedDataParallel(module=backbone, broadcast_buffers=False, device_ids=[local_rank], bucket_cap_mb=16,find_unused_parameters=True)3.4 训练模型
把输入图片、标签及模型加载到当前进程使用的GPU中,
for epoch in range(start_epoch, cfg.num_epoch):if isinstance(train_loader, DataLoader):# 设置train_loader中的sampler的epoch,DistributedSampler需要这个参数来维持各个进程之间的相同随机数种子train_loader.sampler.set_epoch(epoch)for _, (img, local_labels) in enumerate(train_loader):global_step += 1local_embeddings = backbone(img)loss: torch.Tensor = module_partial_fc(local_embeddings, local_labels, opt)loss.backward()torch.nn.utils.clip_grad_norm_(backbone.parameters(), 5)opt.step()opt.zero_grad()lr_scheduler.step()3.5 计算损失
distributed.all_gather(tensor_list,input_tensor):从所有设备收集指定的input_tensor并将其放置在所有设备上的tensor_list变量中,
from torch import distributeddistributed.all_gather(_gather_embeddings, local_embeddings)
distributed.all_gather(_gather_labels, local_labels)distributed.all_reduce(loss, distributed.ReduceOp.SUM)3.6 保存模型
if rank == 0:path_module = os.path.join(cfg.output, "model_final.pt")torch.save(backbone.module.state_dict(), path_module)3.7 启动并行程序
(1) 使用torch.distributed.launch
该指令会使脚本并行地运行n次(n为使用的GPU个数),
python -m torch.distributed.launch --nproc_per_node=8 train.py configs/ms1mv3_r50(2) 使用torch.multiprocessing
torch.multiprocessing会自动创建进程,绕开torch.distributed.launch开启和退出进程的一些小毛病,
def main(rank):passtorch.multiprocessing.spawn(main, nprocs, args)3.8 完整代码
import argparse
import logging
import os
from datetime import datetimeimport numpy as np
import torch
from backbones import get_model
from dataset import get_dataloader
from losses import CombinedMarginLoss
from lr_scheduler import PolyScheduler
from partial_fc import PartialFC, PartialFCAdamW
from torch import distributed
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from utils.utils_callbacks import CallBackLogging, CallBackVerification
from utils.utils_config import get_config
from utils.utils_distributed_sampler import setup_seed
from utils.utils_logging import AverageMeter, init_loggingassert torch.__version__ >= "1.12.0", "In order to enjoy the features of the new torch, \
we have upgraded the torch to 1.12.0. torch before than 1.12.0 may not work in the future."try:rank = int(os.environ["RANK"])local_rank = int(os.environ["LOCAL_RANK"])world_size = int(os.environ["WORLD_SIZE"])distributed.init_process_group("nccl")
except KeyError:rank = 0local_rank = 0world_size = 1distributed.init_process_group(backend="nccl",init_method="tcp://127.0.0.1:12584",rank=rank,world_size=world_size,)def main(args):# get configcfg = get_config(args.config)# global control random seedsetup_seed(seed=cfg.seed, cuda_deterministic=False)torch.cuda.set_device(local_rank)os.makedirs(cfg.output, exist_ok=True)init_logging(rank, cfg.output)summary_writer = (SummaryWriter(log_dir=os.path.join(cfg.output, "tensorboard"))if rank == 0else None)wandb_logger = Noneif cfg.using_wandb:import wandb# Sign in to wandbtry:wandb.login(key=cfg.wandb_key)except Exception as e:print("WandB Key must be provided in config file (base.py).")print(f"Config Error: {e}")# Initialize wandbrun_name = datetime.now().strftime("%y%m%d_%H%M") + f"_GPU{rank}"run_name = run_name if cfg.suffix_run_name is None else run_name + f"_{cfg.suffix_run_name}"try:wandb_logger = wandb.init(entity = cfg.wandb_entity, project = cfg.wandb_project, sync_tensorboard = True,resume=cfg.wandb_resume,name = run_name, notes = cfg.notes) if rank == 0 or cfg.wandb_log_all else Noneif wandb_logger:wandb_logger.config.update(cfg)except Exception as e:print("WandB Data (Entity and Project name) must be provided in config file (base.py).")print(f"Config Error: {e}")train_loader = get_dataloader(cfg.rec,local_rank,cfg.batch_size,cfg.dali,cfg.seed,cfg.num_workers)backbone = get_model(cfg.network, dropout=0.0, fp16=cfg.fp16, num_features=cfg.embedding_size).cuda()backbone = torch.nn.parallel.DistributedDataParallel(module=backbone, broadcast_buffers=False, device_ids=[local_rank], bucket_cap_mb=16,find_unused_parameters=True)backbone.train()# FIXME using gradient checkpoint if there are some unused parameters will cause errorbackbone._set_static_graph()margin_loss = CombinedMarginLoss(64,cfg.margin_list[0],cfg.margin_list[1],cfg.margin_list[2],cfg.interclass_filtering_threshold)if cfg.optimizer == "sgd":module_partial_fc = PartialFC(margin_loss, cfg.embedding_size, cfg.num_classes,cfg.sample_rate, cfg.fp16)module_partial_fc.train().cuda()# TODO the params of partial fc must be last in the params listopt = torch.optim.SGD(params=[{"params": backbone.parameters()}, {"params": module_partial_fc.parameters()}],lr=cfg.lr, momentum=0.9, weight_decay=cfg.weight_decay)elif cfg.optimizer == "adamw":module_partial_fc = PartialFCAdamW(margin_loss, cfg.embedding_size, cfg.num_classes,cfg.sample_rate, cfg.fp16)module_partial_fc.train().cuda()opt = torch.optim.AdamW(params=[{"params": backbone.parameters()}, {"params": module_partial_fc.parameters()}],lr=cfg.lr, weight_decay=cfg.weight_decay)else:raisecfg.total_batch_size = cfg.batch_size * world_sizecfg.warmup_step = cfg.num_image // cfg.total_batch_size * cfg.warmup_epochcfg.total_step = cfg.num_image // cfg.total_batch_size * cfg.num_epochlr_scheduler = PolyScheduler(optimizer=opt,base_lr=cfg.lr,max_steps=cfg.total_step,warmup_steps=cfg.warmup_step,last_epoch=-1)start_epoch = 0global_step = 0if cfg.resume:dict_checkpoint = torch.load(os.path.join(cfg.output, f"checkpoint_gpu_{rank}.pt"))start_epoch = dict_checkpoint["epoch"]global_step = dict_checkpoint["global_step"]backbone.module.load_state_dict(dict_checkpoint["state_dict_backbone"])module_partial_fc.load_state_dict(dict_checkpoint["state_dict_softmax_fc"])opt.load_state_dict(dict_checkpoint["state_optimizer"])lr_scheduler.load_state_dict(dict_checkpoint["state_lr_scheduler"])del dict_checkpointfor key, value in cfg.items():num_space = 25 - len(key)logging.info(": " + key + " " * num_space + str(value))callback_verification = CallBackVerification(val_targets=cfg.val_targets, rec_prefix=cfg.rec, summary_writer=summary_writer, wandb_logger = wandb_logger)callback_logging = CallBackLogging(frequent=cfg.frequent,total_step=cfg.total_step,batch_size=cfg.batch_size,start_step = global_step,writer=summary_writer)loss_am = AverageMeter()amp = torch.cuda.amp.grad_scaler.GradScaler(growth_interval=100)for epoch in range(start_epoch, cfg.num_epoch):if isinstance(train_loader, DataLoader):train_loader.sampler.set_epoch(epoch)for _, (img, local_labels) in enumerate(train_loader):global_step += 1local_embeddings = backbone(img)loss: torch.Tensor = module_partial_fc(local_embeddings, local_labels, opt)if cfg.fp16:amp.scale(loss).backward()amp.unscale_(opt)torch.nn.utils.clip_grad_norm_(backbone.parameters(), 5)amp.step(opt)amp.update()else:loss.backward()torch.nn.utils.clip_grad_norm_(backbone.parameters(), 5)opt.step()opt.zero_grad()lr_scheduler.step()with torch.no_grad():if wandb_logger:wandb_logger.log({'Loss/Step Loss': loss.item(),'Loss/Train Loss': loss_am.avg,'Process/Step': global_step,'Process/Epoch': epoch})loss_am.update(loss.item(), 1)callback_logging(global_step, loss_am, epoch, cfg.fp16, lr_scheduler.get_last_lr()[0], amp)if global_step % cfg.verbose == 0 and global_step > 0:callback_verification(global_step, backbone)if cfg.save_all_states:checkpoint = {"epoch": epoch + 1,"global_step": global_step,"state_dict_backbone": backbone.module.state_dict(),"state_dict_softmax_fc": module_partial_fc.state_dict(),"state_optimizer": opt.state_dict(),"state_lr_scheduler": lr_scheduler.state_dict()}torch.save(checkpoint, os.path.join(cfg.output, f"checkpoint_gpu_{rank}.pt"))if rank == 0:path_module = os.path.join(cfg.output, "model.pt")torch.save(backbone.module.state_dict(), path_module)if wandb_logger and cfg.save_artifacts:artifact_name = f"{run_name}_E{epoch}"model = wandb.Artifact(artifact_name, type='model')model.add_file(path_module)wandb_logger.log_artifact(model)if cfg.dali:train_loader.reset()if rank == 0:path_module = os.path.join(cfg.output, "model.pt")torch.save(backbone.module.state_dict(), path_module)from torch2onnx import convert_onnxconvert_onnx(backbone.module.cpu().eval(), path_module, os.path.join(cfg.output, "model.onnx"))if wandb_logger and cfg.save_artifacts:artifact_name = f"{run_name}_Final"model = wandb.Artifact(artifact_name, type='model')model.add_file(path_module)wandb_logger.log_artifact(model)distributed.destroy_process_group()if __name__ == "__main__":torch.backends.cudnn.benchmark = Trueparser = argparse.ArgumentParser(description="Distributed Arcface Training in Pytorch")parser.add_argument("config", type=str, help="py config file")main(parser.parse_args())4 分布式训练可能遇到的问题
4.1 runtimeerror: address already in use
这种情况是端口被占用了,可能是由于你上次调试之后端口依旧占用的缘故,假设88889端口被占用了,用以下命令查询其PID,然后杀掉即可。第二种方法是将当前终端关闭,重新开一个他会自动解除占用
4.2 调试时可能会出现的问题
- 显存未释放:nvidia-smi看一下显存是否释放,如果没有释放使用kill -9 PID命令进行释放。如果kill也无法释放显存,直接将terminal关闭重新开一个即可
- 端口被占用:如果第一次调试后进行第二次调试时提示xx端口被占用了,这里最快的解决方法时将当前terminal关闭,然后重新开一个即可,或者参考第一个问题,kill掉相应的PID
相关文章:
Pytorch多GPU并行训练: DistributedDataParallel
1 模型并行化训练 1.1 为什么要并行训练 在训练大型数据集或者很大的模型时一块GPU很难放下,例如最初的AlexNet就是在两块GPU上计算的。并行计算一般采取两个策略:一个是模型并行,一个是数据并行。左图中是将模型的不同部分放在不同GPU上进…...
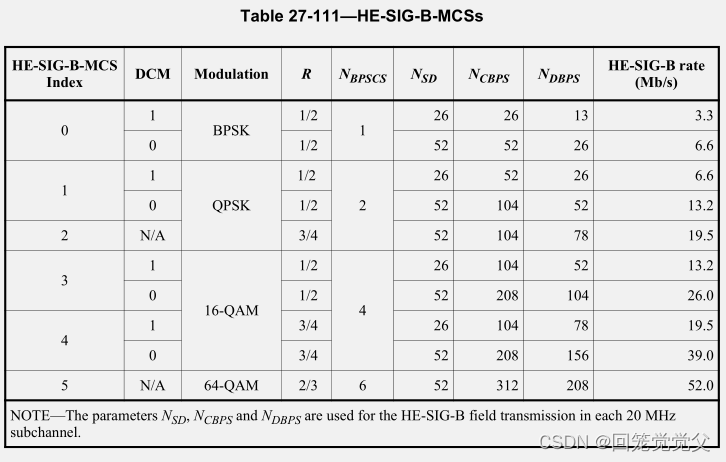
802.11ax-2021协议学习__$27-HE-PHY__$27.5-Parameters-for-HE-MCSs
802.11ax-2021协议学习__$27-HE-PHY__$27.5-Parameters-for-HE-MCSs 27.3.7 Modulation and coding scheme (HE-MCSs)27.3.8 HE-SIG-B modulation and coding schemes (HE-SIG-B-MCSs)27.5 Parameters for HE-MCSs27.5.1 General27.5.2 HE-MCSs for 26-tone RU27.5.3 HE-MCSs f…...

假如我是AI Agent专家,你会问什么来测试我的水平
1. 假如我是AI Agent专家,你会问什么来测试我的水平 作为AI Agent专家,您可能需要回答一系列关于AI代理的设计、实现和优化方面的问题。以下是一些可能的问题: AI代理的基本原理:AI代理的基本工作原理是什么?它们如何…...
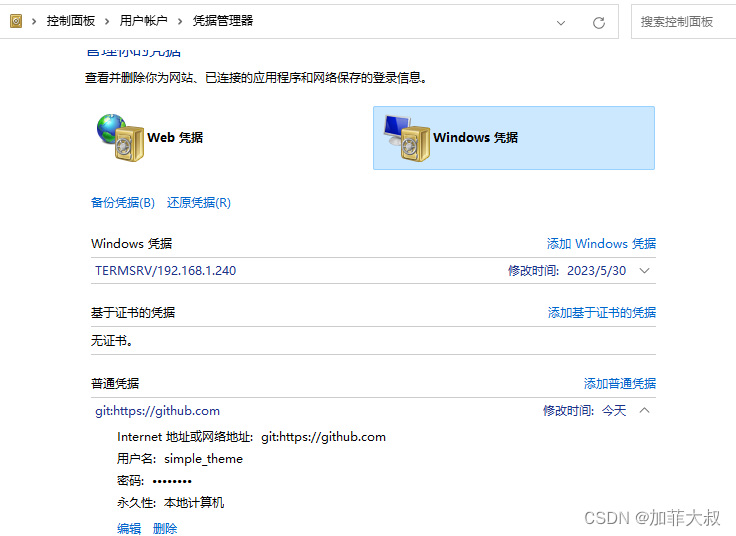
github 私人仓库clone的问题
github 私人仓库clone的问题 公共仓库直接克隆就可以,私人仓库需要权限验证,要先申请token 1、登录到github,点击setting 打开的页面最底下,有一个developer setting 这里申请到token之后,注意要保存起来ÿ…...

基于 React 的 HT for Web ,由厦门图扑团队开发和维护 - 用于 2D/3D 图形渲染和交互
本心、输入输出、结果 文章目录 基于 React 的 HT for Web ,由厦门图扑团队开发和维护 - 用于 2D/3D 图形渲染和交互前言什么是 HT for WebHT for Web 的特点如何使用 HT for Web相关链接弘扬爱国精神 基于 React 的 HT for Web ,由厦门图扑团队开发和维…...
我把微信群聊机器人项目开源
▍PART 序 开源项目地址》InsCode - 让你的灵感立刻落地 目前支持的回复 ["抽签", "天气", "讲笑话", "讲情话", "梦到", "解第", "动漫图", "去水印-", "历史今天", "星座-…...

数据可视化在监控易中的艺术与实践
在数字化运维管理中,数据可视化成为一种日益重要的工具,它将复杂的数据通过图形化的方式呈现,帮助运维团队更加直观和快速地理解系统的运行状况。监控易(MeiXin Era)将数据可视化引入到运维监控中,通过科学…...
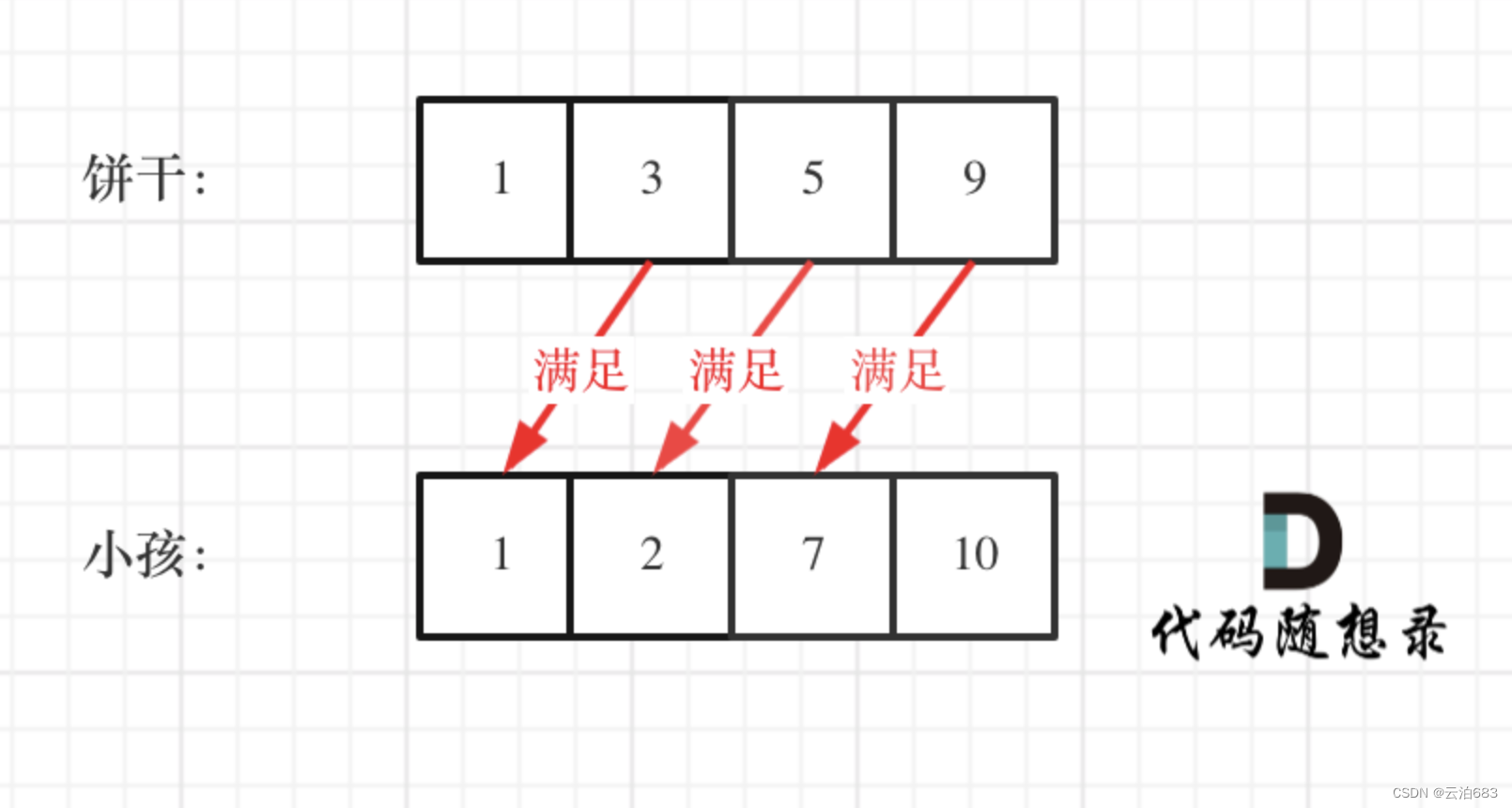
贪心 455.分发饼干
455.分发饼干 题目: 小朋友胃口值数组g[i],饼干尺寸数组 s[j],当饼干尺寸s[j]大于等于g[i]的时候,对应小朋友被满足,小朋友每一个最多一块饼干 ,求给定条件下最多被满足的小朋友数量。 思路:…...

前后端分离项目在Linux的部署方法、一台Nginx如何部署多个Web应用
需求场景:目前有三个前后端分离项目(vue+springboot),Linux服务器一台,nginx一个,比如服务器地址为www.xxxxxxx.com 我想通过80端口访问服务①(即访问www.xxxxxxx.com);通过81端口访问服务②(即www.xxxxxxx.com:81);通过82端口访问服务③(即www.xxxxxxx.com:82) ①部…...
python之 flask 框架(2)项目拆分的 执行逻辑
项目的结构图 app.py # 导入__init__.py 比较特殊 from APP import create_appapp create_app() if __name__ __main__:app.run(debugTrue)init.py # __inti__.py # 初始化文件,创建Flask应用 from flask import Flask from .views import bluedef create_ap…...
)
Angular 模块介绍及使用(二)
Angular 模块概念 Angular 模块是一个重要的概念。模块提供了一种组织和封装组件、指令、管道和服务的方式,以及在应用程序中定义和配置这些功能。 下面是一些常见的 Angular 模块概念的介绍: 根模块:根模块是 Angular 应用程序的入口模块…...

Google云的平台工程
GCP(Google Cloud Platform)是Google云,为其内部(Google search、Gmail、YouTube等)和外部客户提供IaaS、PaaS以及Serverless computing等云服务的平台。 本文将带领你走进GCP,并深入体验其产品功能&#x…...

【Android】画面卡顿优化列表流畅度五之下拉刷新上拉加载更多组件RefreshLayout修改
之前也写过类似组件的介绍: 地址:下拉刷新&上拉加载更多组件SmartRefreshLayout 本来打算用这个替换的,但在进行仔细研究发现不太合适。功能都很好,但嵌入不了当前的工程体系里。原因就是那啥体制懂的都懂。这样的组件需要改…...

【Android】导入三方jar包/系统的framework.jar
1.Android.mk导包 1).jar包位置 与res和src同一级的libs中(没有就新建) 2).Android.mk文件 LOCAL_STATIC_ANDROID_LIBRARIES:android静态库,经常用于一些support的导包 LOCAL_JAVA_LIBRARIES:依赖的java库,一般为系统的jar…...

在线升级 redis 到7.2.2
1. 操作环境与升级思路 先安装新的版本新版本设置主从备份,将老版本与新版本的数据进行同步新启动一个服务,连接新版本redis,切换到新服务,关闭主从备份kill 老服务, 卸载老版本redis 因为我需要 RedisSearch 所以直接安装 Redi…...

社区新零售:改变生活方式的创新商业模式
社区新零售:改变生活方式的创新商业模式 社区新零售,顾名思义,以社区为核心,利用互联网、大数据、人工智能等先进技术,将线上购物和线下体验有机结合,形成一种全新的零售模式。它特别强调地理位置的便利性&…...
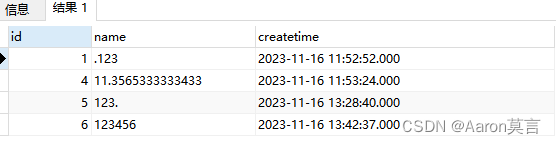
MySQL/SQLServer判断字符是纯数字或者是其它字符
如下是MySQL表结构设计(演示所用): MySQL表关联数据如下所示: 【场景:查询所有数字,包含小数点】,SQL如下所示: SELECT * FROM data WHERE message not REGEXP [^0-9].[^0-9] My…...
Threejs_02 父子位移+缩放改变
threejs中如何做出一堆父子来呢? 父子制作 1.做一个父元素 想要做一个元素 需要材质和模型,然后使用threejs的方法THREE.Mesh就可以制作出来 // 创建一个集合体 (立方体) const geometry new THREE.BoxGeometry(1, 1, 1); // 创建材质 (16进制颜色…...
--nimble - 蓝牙BLE库(nimble版))
LuatOS-SOC接口文档(air780E)--nimble - 蓝牙BLE库(nimble版)
示例 -- 本库当前支持Air101/Air103/ESP32/ESP32C3/ESP32S3 -- 用法请查阅demo, API函数会归于指定的模式-- 名称解释: -- peripheral 外设模式, 或者成为从机模式, 是被连接的设备 -- central 中心模式, 或者成为主机模式, 是扫描并连接其他设备 -- ibeacon 周期性的be…...
医疗器械展示预约小程序的效果如何
医疗器械行业涵盖的内容非常广,市场中大小从业的品牌/门店也很多,比如我们常见的轮椅、康复器械、拐杖、血压仪等产品市场需求都非常高,当然还有医院里用的器械等。 医疗器械市场呈现多品牌、多门店的发展趋势,虽然这些东西不是必…...
)
Lovable后端集成方案深度拆解(含Spring Boot 3.2+GraalVM+OpenTelemetry完整Demo)
更多请点击: https://kaifayun.com 第一章:Lovable后端集成方案全景概览 Lovable 是一个面向现代 Web 应用的轻量级后端协作框架,其核心设计理念是“可组合、可观测、可演进”。它不绑定特定语言或运行时,而是通过标准化协议与契…...

修复 PowerShell 7 下 conda activate 报错的指南
修复 PowerShell 7 下 conda activate 报错的指南 适用场景:升级到 PowerShell 7.x 后,conda activate 突然报错,但 Windows PowerShell 5.1 正常。 发布日期:2026-05-24 适用版本:conda 23.x PowerShell 7.x 一、问题…...

西安旅行社哪个靠谱
西安,这座承载着十三朝古都历史的城市,每年吸引着数千万游客。但面对市面上琳琅满目的旅行社,如何避开“购物团”“低价陷阱”“服务缩水”等坑?作为扎根西安8年的本地人,我结合陕西悠游天下国际旅行社有限公司&#x…...

崩坏星穹铁道自动化终极指南:3分钟学会解放双手的游戏助手
崩坏星穹铁道自动化终极指南:3分钟学会解放双手的游戏助手 【免费下载链接】StarRailAssistant 崩坏:星穹铁道自动化 | 崩坏:星穹铁道自动锄大地 | 崩坏:星穹铁道锄大地 | 自动锄大地 | 基于模拟按键 项目地址: https://gitcode…...

ParsecVDisplay:为Windows创建16个虚拟显示器的终极解决方案
ParsecVDisplay:为Windows创建16个虚拟显示器的终极解决方案 【免费下载链接】parsec-vdd ✨ Perfect virtual display for game streaming 项目地址: https://gitcode.com/gh_mirrors/pa/parsec-vdd 你是否曾经因为物理显示器的限制而感到束手束脚ÿ…...

观察taotoken在流量高峰时段api调用的成功率和响应延迟表现
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察 Taotoken 在流量高峰时段 API 调用的成功率和响应延迟表现 对于依赖大模型 API 进行开发的团队而言,服务的稳定性…...

IwaraDownloadTool:3种突破性技术实现的专业级Iwara视频批量下载方案
IwaraDownloadTool:3种突破性技术实现的专业级Iwara视频批量下载方案 【免费下载链接】IwaraDownloadTool Iwara 下载工具 | Iwara Downloader 项目地址: https://gitcode.com/gh_mirrors/iw/IwaraDownloadTool 在数字内容创作日益丰富的今天,Iwa…...

3个实用技巧:用SMUDebugTool解决AMD Ryzen常见硬件问题
3个实用技巧:用SMUDebugTool解决AMD Ryzen常见硬件问题 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https://g…...

终极指南:免费掌控AMD Ryzen处理器的SMUDebugTool调试工具
终极指南:免费掌控AMD Ryzen处理器的SMUDebugTool调试工具 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https:…...

我的数字孪生项目踩坑记:UE5里嵌入Web页面,从插件安装到交互调试的全流程
我的数字孪生项目踩坑记:UE5里嵌入Web页面,从插件安装到交互调试的全流程记得第一次在UE5项目中尝试嵌入Web页面时,我天真地以为这不过是个简单的"拖拽-配置-运行"过程。直到连续三个通宵与各种报错搏斗后,才真正理解为…...