21、Flink 的table API与DataStream API 集成(1)- 介绍及入门示例、集成说明
Flink 系列文章
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接
13、Flink 的table api与sql的基本概念、通用api介绍及入门示例
14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性
15、Flink 的table api与sql之流式概念-详解的介绍了动态表、时间属性配置(如何处理更新结果)、时态表、流上的join、流上的确定性以及查询配置
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及FileSystem示例(1)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Elasticsearch示例(2)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Apache Kafka示例(3)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及JDBC示例(4)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Apache Hive示例(6)
17、Flink 之Table API: Table API 支持的操作(1)
17、Flink 之Table API: Table API 支持的操作(2)
18、Flink的SQL 支持的操作和语法
19、Flink 的Table API 和 SQL 中的内置函数及示例(1)
19、Flink 的Table API 和 SQL 中的自定义函数及示例(2)
19、Flink 的Table API 和 SQL 中的自定义函数及示例(3)
19、Flink 的Table API 和 SQL 中的自定义函数及示例(4)
20、Flink SQL之SQL Client: 不用编写代码就可以尝试 Flink SQL,可以直接提交 SQL 任务到集群上
21、Flink 的table API与DataStream API 集成(1)- 介绍及入门示例、集成说明
21、Flink 的table API与DataStream API 集成(2)- 批处理模式和inser-only流处理
21、Flink 的table API与DataStream API 集成(3)- changelog流处理、管道示例、类型转换和老版本转换示例
21、Flink 的table API与DataStream API 集成(完整版)
22、Flink 的table api与sql之创建表的DDL
24、Flink 的table api与sql之Catalogs(介绍、类型、java api和sql实现ddl、java api和sql操作catalog)-1
24、Flink 的table api与sql之Catalogs(java api操作数据库、表)-2
24、Flink 的table api与sql之Catalogs(java api操作视图)-3
24、Flink 的table api与sql之Catalogs(java api操作分区与函数)-4
25、Flink 的table api与sql之函数(自定义函数示例)
26、Flink 的SQL之概览与入门示例
27、Flink 的SQL之SELECT (select、where、distinct、order by、limit、集合操作和去重)介绍及详细示例(1)
27、Flink 的SQL之SELECT (SQL Hints 和 Joins)介绍及详细示例(2)
27、Flink 的SQL之SELECT (窗口函数)介绍及详细示例(3)
27、Flink 的SQL之SELECT (窗口聚合)介绍及详细示例(4)
27、Flink 的SQL之SELECT (Group Aggregation分组聚合、Over Aggregation Over聚合 和 Window Join 窗口关联)介绍及详细示例(5)
27、Flink 的SQL之SELECT (Top-N、Window Top-N 窗口 Top-N 和 Window Deduplication 窗口去重)介绍及详细示例(6)
27、Flink 的SQL之SELECT (Pattern Recognition 模式检测)介绍及详细示例(7)
28、Flink 的SQL之DROP 、ALTER 、INSERT 、ANALYZE 语句
29、Flink SQL之DESCRIBE、EXPLAIN、USE、SHOW、LOAD、UNLOAD、SET、RESET、JAR、JOB Statements、UPDATE、DELETE(1)
29、Flink SQL之DESCRIBE、EXPLAIN、USE、SHOW、LOAD、UNLOAD、SET、RESET、JAR、JOB Statements、UPDATE、DELETE(2)
30、Flink SQL之SQL 客户端(通过kafka和filesystem的例子介绍了配置文件使用-表、视图等)
32、Flink table api和SQL 之用户自定义 Sources & Sinks实现及详细示例
33、Flink 的Table API 和 SQL 中的时区
41、Flink之Hive 方言介绍及详细示例
42、Flink 的table api与sql之Hive Catalog
43、Flink之Hive 读写及详细验证示例
44、Flink之module模块介绍及使用示例和Flink SQL使用hive内置函数及自定义函数详细示例–网上有些说法好像是错误的
文章目录
- Flink 系列文章
- 一、Table API 与 DataStream API集成
- 1、概述
- 2、 DataStream 和 Table 相互转换示例
- 1)、示例1 - toDataStream
- 2)、示例2 - toChangelogStream
- 3)、示例3 - 通过仅切换标志来处理批处理和流数据
- 3、集成说明
- 1)、maven依赖
- 2)、import
- 3)、Configuration
- 4)、执行行为
- 1、DataStream API
- 2、Table API
本文是Flink table api 与 datastream api的集成的第一篇,主要介绍了集成的概述、table api 与 datastream api相互转换的三个示例以及其集成的说明(即maven依赖、import、配置以及执行行为),并以具体的示例进行说明。
本文依赖flink、kafka集群能正常使用。
本文分为3个部分,即集成概述、三个入门示例、集成说明。
本文的示例是在Flink 1.17版本中运行。
一、Table API 与 DataStream API集成
1、概述
在定义数据处理管道时,Table API和DataStream API同样重要。
DataStream API在一个相对低级的命令式编程API中提供流处理的原语(即时间、状态和数据流管理)。Table API抽象了许多内部构件,并提供了结构化和声明性API。
这两个API都可以处理有界和无界流。
在处理历史数据时,需要管理有界流。无界流发生在实时处理场景中,这些场景可能先使用历史数据进行初始化。
为了有效执行,这两个API都以优化的批处理执行模式提供处理有界流。然而,由于批处理只是流的一种特殊情况,因此也可以在常规流执行模式下运行有界流的管道。
一个API中的管道可以端到端定义,而不依赖于另一个API。然而,出于各种原因,混合这两种API可能是有用的:
- 在DataStream API中实现主管道(main pipeline)之前,使用表生态系统(table ecosystem)轻松访问目录(catalogs )或连接到外部系统。
- 在DataStream API中实现主管道之前,访问一些SQL函数以进行无状态数据规范化和清理。
- 如果table API中不存在更低级的操作(例如自定义计时器处理),则不时切换到DataStream API。
Flink提供了特殊的桥接功能,以使与DataStream API的集成尽可能顺利。
在DataStream 和Table API之间切换会增加一些转换开销。例如,部分处理二进制数据的表运行时(即RowData)的内部数据结构需要转换为更用户友好的数据结构(即Row)。通常,这个开销可以忽略。
- maven依赖
本篇文章,如果没有特殊说明,将使用如下maven依赖
<properties><encoding>UTF-8</encoding><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><maven.compiler.source>1.8</maven.compiler.source><maven.compiler.target>1.8</maven.compiler.target><java.version>1.8</java.version><scala.version>2.12</scala.version><flink.version>1.17.0</flink.version></properties><dependencies><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-common</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-api-java-bridge</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-sql-gateway</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-csv</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-json</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-table-planner --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-planner_2.12</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-table-api-java-uber --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-api-java-uber</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-runtime</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-jdbc</artifactId><version>3.1.0-1.17</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.38</version></dependency><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-connector-hive --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-hive_2.12</artifactId><version>1.17.0</version></dependency><dependency><groupId>org.apache.hive</groupId><artifactId>hive-exec</artifactId><version>3.1.2</version></dependency><!-- flink连接器 --><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-connector-kafka --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka</artifactId><version>${flink.version}</version></dependency><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-sql-connector-kafka --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-sql-connector-kafka</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><!-- https://mvnrepository.com/artifact/org.apache.commons/commons-compress --><dependency><groupId>org.apache.commons</groupId><artifactId>commons-compress</artifactId><version>1.24.0</version></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.2</version><!-- <scope>provided</scope> --></dependency></dependencies>
2、 DataStream 和 Table 相互转换示例
Flink提供了专门的StreamTableEnvironment,用于与DataStream API集成。这些环境使用其他方法扩展常规TableEnvironment,并将DataStream API中使用的StreamExecutionEnvironments作为参数。
1)、示例1 - toDataStream
下面的代码展示了如何在两个API之间来回切换的示例。表的列名和类型自动从DataStream的TypeInformation派生。由于DataStream API本机不支持变更日志处理,因此代码假设在流到表和表到流转换期间仅附加/仅插入语义。
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;/*** @author alanchan**/
public class ConvertingDataStreamAndTableDemo {/*** @param args* @throws Exception*/public static void main(String[] args) throws Exception {// 1、创建运行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();StreamTableEnvironment tenv = StreamTableEnvironment.create(env);// 2、创建输入流DataStream<String> dataStream = env.fromElements("alan", "alanchan", "alanchanchn");// 3、将datastream 转为 tableTable inputTable = tenv.fromDataStream(dataStream);// 4、创建视图,该步骤不是必须,将姓名转为大写tenv.createTemporaryView("InputTable", inputTable);Table resultTable = tenv.sqlQuery("SELECT UPPER(f0) FROM InputTable");// 5、将table转成datastream进行输出DataStream<Row> resultStream = tenv.toDataStream(resultTable);resultStream.print();env.execute();}}- 示例输出
12> +I[ALAN]
14> +I[ALANCHANCHN]
13> +I[ALANCHAN]
fromDataStream和toDataStream的完整语义可以在下面的部分中找到。特别是,本节讨论了如何使用更复杂的嵌套类型来影响模式派生。它还包括使用事件时间和水印。
根据查询的类型,在许多情况下,生成的动态表是一个管道,它不仅在将表转换为数据流时产生仅插入的更改,而且还产生收回和其他类型的更新。在表到流转换期间,这可能会导致类似于以下内容的异常
Table sink 'Unregistered_DataStream_Sink_1' doesn't support consuming update changes [...].
在这种情况下,需要再次修改查询或切换到ChangelogStream。
2)、示例2 - toChangelogStream
下面的示例显示如何转换更新表。
每个结果行表示更改日志中的一个条目,该条目具有更改标志,可以通过对其调用row.getKind()来查询。在本例中,alan的第二个分数在更改之前(-U)创建更新,在更改之后(+U)创建更新。
本示例仅仅以一个方法来展示,避免没有必要的代码,运行框架参考上述示例。
public static void test2() throws Exception {// 1、创建运行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();StreamTableEnvironment tenv = StreamTableEnvironment.create(env);// 2、创建输入流DataStream<Row> dataStream = env.fromElements(Row.of("alan", 18), Row.of("alanchan", 19), Row.of("alanchanchn", 20), Row.of("alan", 20));// 3、将datastream 转为 tableTable inputTable = tenv.fromDataStream(dataStream).as("name", "salary");// 4、创建视图,该步骤不是必须tenv.createTemporaryView("InputTable", inputTable);Table resultTable = tenv.sqlQuery("SELECT name, SUM(salary) FROM InputTable GROUP BY name");// 5、将table转成datastream进行输出DataStream<Row> resultStream = tenv.toChangelogStream(resultTable);resultStream.print();env.execute();}
- 运行结果
2> +I[alan, 18]
16> +I[alanchan, 19]
16> +I[alanchanchn, 20]
2> -U[alan, 18]
2> +U[alan, 38]
fromChangelogStream和toChangelogStream的完整语义可以在下面的部分中找到。特别是,本节讨论了如何使用更复杂的嵌套类型来影响模式派生。它包括使用事件时间和水印。它讨论了如何为输入和输出流声明主键和变更日志模式。
上面的示例显示了如何通过为每个传入记录连续发出逐行更新来增量计算最终结果。然而,在输入流有限(即有界)的情况下,通过利用批处理原理可以更有效地计算结果。
在批处理中,可以在连续的阶段中执行运算符,这些阶段在发出结果之前使用整个输入表。例如,连接操作符可以在执行实际连接之前对两个有界输入进行排序(即排序合并连接算法),或者在使用另一个输入之前从一个输入构建哈希表(即哈希连接算法的构建/探测阶段)。
DataStream API和Table API都提供专门的批处理运行时模式。
3)、示例3 - 通过仅切换标志来处理批处理和流数据
下面的示例说明了统一管道能够通过仅切换标志来处理批处理和流数据。
public static void test3() throws Exception {// 1、创建运行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setRuntimeMode(RuntimeExecutionMode.BATCH);StreamTableEnvironment tenv = StreamTableEnvironment.create(env);// 2、创建输入流DataStream<Row> dataStream = env.fromElements(Row.of("alan", 18), Row.of("alanchan", 19), Row.of("alanchanchn", 20), Row.of("alan", 20));// 3、将datastream 转为 tableTable inputTable = tenv.fromDataStream(dataStream).as("name", "salary");// 4、创建视图,该步骤不是必须tenv.createTemporaryView("InputTable", inputTable);Table resultTable = tenv.sqlQuery("SELECT name, SUM(salary) FROM InputTable GROUP BY name");// 5、将table转成datastream进行输出DataStream<Row> resultStream = tenv.toChangelogStream(resultTable);resultStream.print();env.execute();}
- 运行结果
注意比较和示例2的输出区别
+I[alanchan, 19]
+I[alan, 38]
+I[alanchanchn, 20]一旦将changelog 应用于外部系统(例如键值存储),可以看到两种模式都能够产生完全相同的输出表。通过在发出结果之前使用所有输入数据,批处理模式的更改日志仅由仅插入的更改组成。有关更多细节,请参阅下面的专用批处理模式部分。
3、集成说明
将Table API与DataStream API相结合的项目需要添加以下桥接模块之一。
它们包括对 flink-table-api-java或flink-table-api-scala的可传递依赖性,以及相应的特定于语言的DataStream api模块。
1)、maven依赖
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-api-java-bridge_2.12</artifactId><version>1.17.1</version><scope>provided</scope>
</dependency>
2)、import
使用DataStream API和Table API的Java或Scala版本声明公共管道需要以下导入。
// imports for Java DataStream API
import org.apache.flink.streaming.api.*;
import org.apache.flink.streaming.api.environment.*;// imports for Table API with bridging to Java DataStream API
import org.apache.flink.table.api.*;
import org.apache.flink.table.api.bridge.java.*;
3)、Configuration
TableEnvironment将采用传递的StreamExecutionEnvironment.中的所有配置选项。然而,不能保证对StreamExecutionEnvironment配置的进一步更改在实例化后传播到StreamTableEnvironment。在规划期间,将选项从Table API传播到DataStream API。
我们建议在切换到Table API之前尽早在DataStream API中设置所有配置选项。
import java.time.ZoneId;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;// create Java DataStream API
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// set various configuration earlyenv.setMaxParallelism(256);
env.getConfig().addDefaultKryoSerializer(MyCustomType.class, CustomKryoSerializer.class);
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);// then switch to Java Table API
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);// set configuration early
tableEnv.getConfig().setLocalTimeZone(ZoneId.of("Europe/Berlin"));// start defining your pipelines in both APIs...4)、执行行为
这两个API都提供了执行管道的方法。换句话说:如果被请求,它们将编译一个作业图( job graph),该作业图将提交到集群并触发以执行。结果将流式传输到声明的sinks。
通常,这两个API都在方法名称中使用术语“执行”来标记这种行为。然而,Table API和DataStream API之间的执行行为略有不同。
1、DataStream API
DataStream API的StreamExecutionEnvironment使用生成器模式(builder pattern)来构造复杂的管道。管道可能会拆分为多个分支,这些分支可能以sink结尾,也可能不以sink结尾。环境缓冲(environment buffers)所有这些定义的分支,直到提交作业。
StreamExecutionEnvironment.execute()提交整个构建的管道,然后清除构建器。换句话说:不再声明sources 和sinks ,并且可以向生成器中添加新的管道。因此,每个DataStream程序通常以对StreamExecutionEnvironment.execute()的调用结束。或者,DataStream.executeAndCollect()隐式定义了一个sink,用于将结果流式传输到本地客户端。
2、Table API
在Table API中,分支管道仅在StatementSet中受支持,其中每个分支必须声明一个最终sink。TableEnvironment和StreamTableEnvironment都不提供专用的通用execute()方法。相反,它们提供了提交单个source-to-sink管道或语句集的方法:
final static String sinkSQL = "CREATE TABLE OutputTable (\n" +" userId INT,\r\n" + " age INT,\r\n" + " balance DOUBLE,\r\n" + " userName STRING,\r\n" +" t_insert_time TIMESTAMP(3)\r\n" +") WITH (\n" +" 'connector' = 'print'\n" +")";final static String sinkSQL2 = "CREATE TABLE OutputTable2 (\n" +" userId INT,\r\n" + " age INT,\r\n" + " balance DOUBLE,\r\n" + " userName STRING,\r\n" +" t_insert_time TIMESTAMP(3)\r\n" +") WITH (\n" +" 'connector' = 'print'\n" +")";final static String sourceSQL = "CREATE TABLE InputTable (\r\n" + " userId INT,\r\n" + " age INT,\r\n" + " balance DOUBLE,\r\n" + " userName STRING,\r\n" + " t_insert_time AS localtimestamp,\r\n" + " WATERMARK FOR t_insert_time AS t_insert_time\r\n" + ") WITH (\r\n" + " 'connector' = 'datagen',\r\n" + " 'rows-per-second'='10',\r\n" + " 'fields.userId.kind'='sequence',\r\n" + " 'fields.userId.start'='1',\r\n" + " 'fields.userId.end'='20',\r\n" + " 'fields.balance.kind'='random',\r\n" + " 'fields.balance.min'='1',\r\n" + " 'fields.balance.max'='100',\r\n" + " 'fields.age.min'='1',\r\n" + " 'fields.age.max'='100',\r\n" + " 'fields.userName.length'='6'\r\n" + ");";public static void test4() throws Exception {// 1、创建运行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();StreamTableEnvironment tenv = StreamTableEnvironment.create(env);//sinkSQL//sourceSQL// 建表tenv.executeSql(sourceSQL);//tenv.executeSql(sinkSQL);tenv.executeSql(sinkSQL2);//插入表数据,方式一tenv.from("InputTable").insertInto("OutputTable").execute();tenv.executeSql("select * from OutputTable");tenv.from("InputTable").execute().print();//插入表数据,方式二tenv.executeSql("INSERT INTO OutputTable SELECT * FROM InputTable");tenv.executeSql("select * from OutputTable");//插入表数据,方式三tenv.createStatementSet().addInsertSql("INSERT INTO OutputTable SELECT * FROM InputTable").addInsertSql("INSERT INTO OutputTable2 SELECT * FROM InputTable").execute();// 输出tenv.from("InputTable").execute().print();tenv.executeSql("SELECT * FROM InputTable").print();env.execute();}- 输出结果
3> +I[3, 99, 36.20987556045243, d23888, 2023-11-13T14:49:58.812]
15> +I[15, 39, 68.30743253178122, 43bec8, 2023-11-13T14:49:58.812]
2> +I[2, 62, 47.280395949976885, 7bae4e, 2023-11-13T14:49:58.812]
16> +I[16, 52, 42.10205629532836, 6baf0e, 2023-11-13T14:49:58.812]
10> +I[10, 25, 58.008035887440094, d43dea, 2023-11-13T14:49:58.812]
13> +I[13, 36, 70.9215559827798, 01bb28, 2023-11-13T14:49:58.812]
12> +I[12, 38, 30.31004698340413, 322ba8, 2023-11-13T14:49:58.812]
6> +I[6, 17, 32.28909358733212, 13bf88, 2023-11-13T14:49:58.812]
9> +I[9, 49, 44.52802246768357, e8280c, 2023-11-13T14:49:58.812]
8> +I[8, 80, 18.03487847824154, 803b2a, 2023-11-13T14:49:58.812]
5> +I[5, 61, 54.43695775227862, 063f08, 2023-11-13T14:49:58.812]
7> +I[7, 64, 33.886576642098404, 443dea, 2023-11-13T14:49:58.812]
14> +I[14, 92, 63.71527772015468, 123848, 2023-11-13T14:49:58.812]
11> +I[11, 22, 30.745102844313315, e62848, 2023-11-13T14:49:58.812]
4> +I[4, 78, 88.60724929598506, 55bca8, 2023-11-13T14:49:58.812]
1> +I[1, 82, 62.50149215989057, 0bba0c, 2023-11-13T14:49:58.812]
3> +I[19, 67, 14.244993215937432, e6c911, 2023-11-13T14:49:59.806]
1> +I[17, 67, 91.05078612782468, 560b6c, 2023-11-13T14:49:59.807]
4> +I[20, 95, 82.12047947156385, 1ac5b2, 2023-11-13T14:49:59.807]
2> +I[18, 81, 25.384055001988084, fe98d1, 2023-11-13T14:49:59.806]
+----+-------------+-------------+--------------------------------+--------------------------------+-------------------------+
| op | userId | age | balance | userName | t_insert_time |
+----+-------------+-------------+--------------------------------+--------------------------------+-------------------------+
| +I | 1 | 91 | 22.629318048042723 | 923e08 | 2023-11-13 14:49:59.800 |
| +I | 2 | 67 | 75.26915785038814 | 342baa | 2023-11-13 14:49:59.803 |
| +I | 3 | 68 | 74.06076023217011 | 1dbbce | 2023-11-13 14:49:59.803 |
| +I | 4 | 26 | 79.47471729272772 | 083e2e | 2023-11-13 14:49:59.802 |
| +I | 5 | 97 | 82.56249330491859 | 4a3c6e | 2023-11-13 14:49:59.804 |
| +I | 6 | 32 | 81.74903214944425 | fdac4e | 2023-11-13 14:49:59.800 |
| +I | 7 | 67 | 94.80154136831771 | f7acea | 2023-11-13 14:49:59.800 |
| +I | 8 | 53 | 50.85073238739004 | cfbd0c | 2023-11-13 14:49:59.800 |
| +I | 9 | 69 | 93.64054547476522 | 7fa9ec | 2023-11-13 14:49:59.801 |
| +I | 10 | 66 | 61.92366658766452 | 05b86a | 2023-11-13 14:49:59.803 |
| +I | 11 | 81 | 95.61717698776191 | efa8ce | 2023-11-13 14:49:59.797 |
| +I | 12 | 8 | 63.573174957723076 | 0fbfec | 2023-11-13 14:49:59.802 |
| +I | 13 | 85 | 52.938510850778734 | 43bfa8 | 2023-11-13 14:49:59.803 |
| +I | 14 | 26 | 5.130287258770441 | 083c6c | 2023-11-13 14:49:59.797 |
| +I | 15 | 35 | 73.3318749510538 | 0e3b4c | 2023-11-13 14:49:59.802 |
| +I | 16 | 84 | 16.24326410122912 | ac2d6e | 2023-11-13 14:49:59.802 |
| +I | 18 | 41 | 32.38455189801736 | b07afb | 2023-11-13 14:50:00.804 |
| +I | 19 | 24 | 77.6947569111452 | 7f72ac | 2023-11-13 14:50:00.803 |
| +I | 20 | 92 | 82.53929937026987 | 051fb9 | 2023-11-13 14:50:00.802 |
| +I | 17 | 93 | 12.784194121509948 | bce5d9 | 2023-11-13 14:50:00.801 |
+----+-------------+-------------+--------------------------------+--------------------------------+-------------------------+
20 rows in set为了组合这两种执行行为,对StreamTableEnvironment.toDataStream或StreamTableEnviron.toChangelogStream的每次调用都将具体化(materialize )(即编译)Table API子管道(sub-pipeline),并将其插入DataStream API管道生成器(builder)中。这意味着之后必须调用StreamExecutionEnvironment.execute()或DataStream.executeAndCollect。Table API中的执行不会触发这些“外部部件(external parts)”。
// adds a branch with a printing sink to the StreamExecutionEnvironment
tableEnv.toDataStream(table).print();// (2)// executes a Table API end-to-end pipeline as a Flink job and prints locally,
// thus (1) has still not been executed
table.execute().print();// executes the DataStream API pipeline with the sink defined in (1) as a
// Flink job, (2) was already running before
env.execute();
上述示例中有具体应用。
以上,本文是Flink table api 与 datastream api的集成的第一篇,主要介绍了集成的概述、table api 与 datastream api相互转换的三个示例以及其集成的说明(即maven依赖、import、配置以及执行行为),并以具体的示例进行说明。
相关文章:
- 介绍及入门示例、集成说明)
21、Flink 的table API与DataStream API 集成(1)- 介绍及入门示例、集成说明
Flink 系列文章 1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接 13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…...

(免费领源码)Java#SpringBoot#mysql高校实验室资产管理系统85189-计算机毕业设计项目选题推荐
摘 要 随着计算机技术的发展,特别是计算机网络技术与数据库技术的发展,使人们的生活与工作方式发生了很大的改观。本课题研究的高校实验室资产管理系统,主要功能模块包括后台首页,轮播图,公告管理,资源管理…...

高效能人士的七个习惯
今天小编给大家推荐最近读的一本书,史蒂芬柯维的《高效能人士的七个习惯》,分别是积极主动、以始为终、要事第一、双赢思维、知己解彼、综合高效及不断更新。 一、个人领域:从依赖到独立 习惯一:积极主动——个人愿景的原则付诸行…...
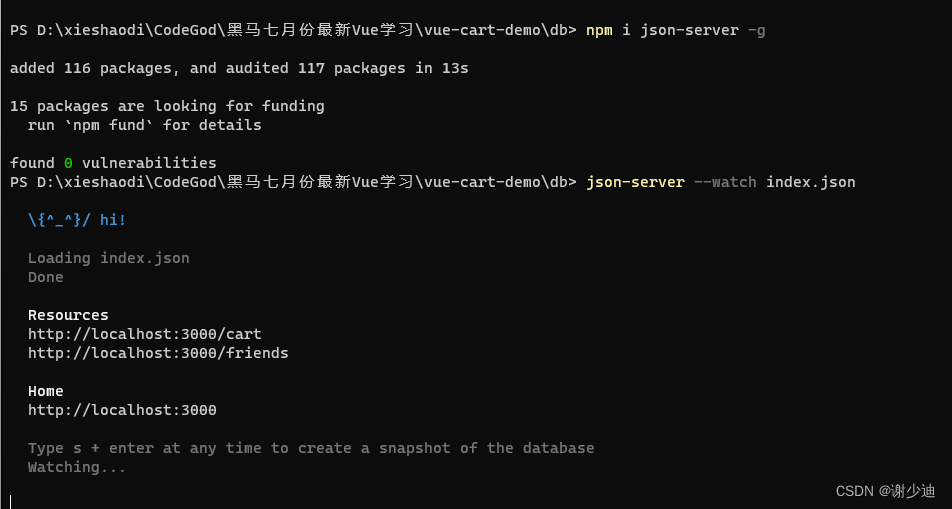
【前端】使用json-server报错
当我们使用json-server模仿后端接口时需要运行json-server --watch index.json这个命令生成增删改查接口但是可能会报这个错误,如图 这时我们运行 npm i json-server -g命令即可,然后再重新运行json-server --watch index.json就行了...

【Git企业开发】第七节.多人协作开发
文章目录 前言 一、多人协作开发 1.1 多人协作一 1.2 多人协作二 1.3 远程分支删除后,本地 git branch -a 依然能看到的解决办法 总结 前言 一、多人协作开发 1.1 多人协作一 目前,我们所完成的工作如下: 基本完成Git的所有本地库的相关操作࿰…...
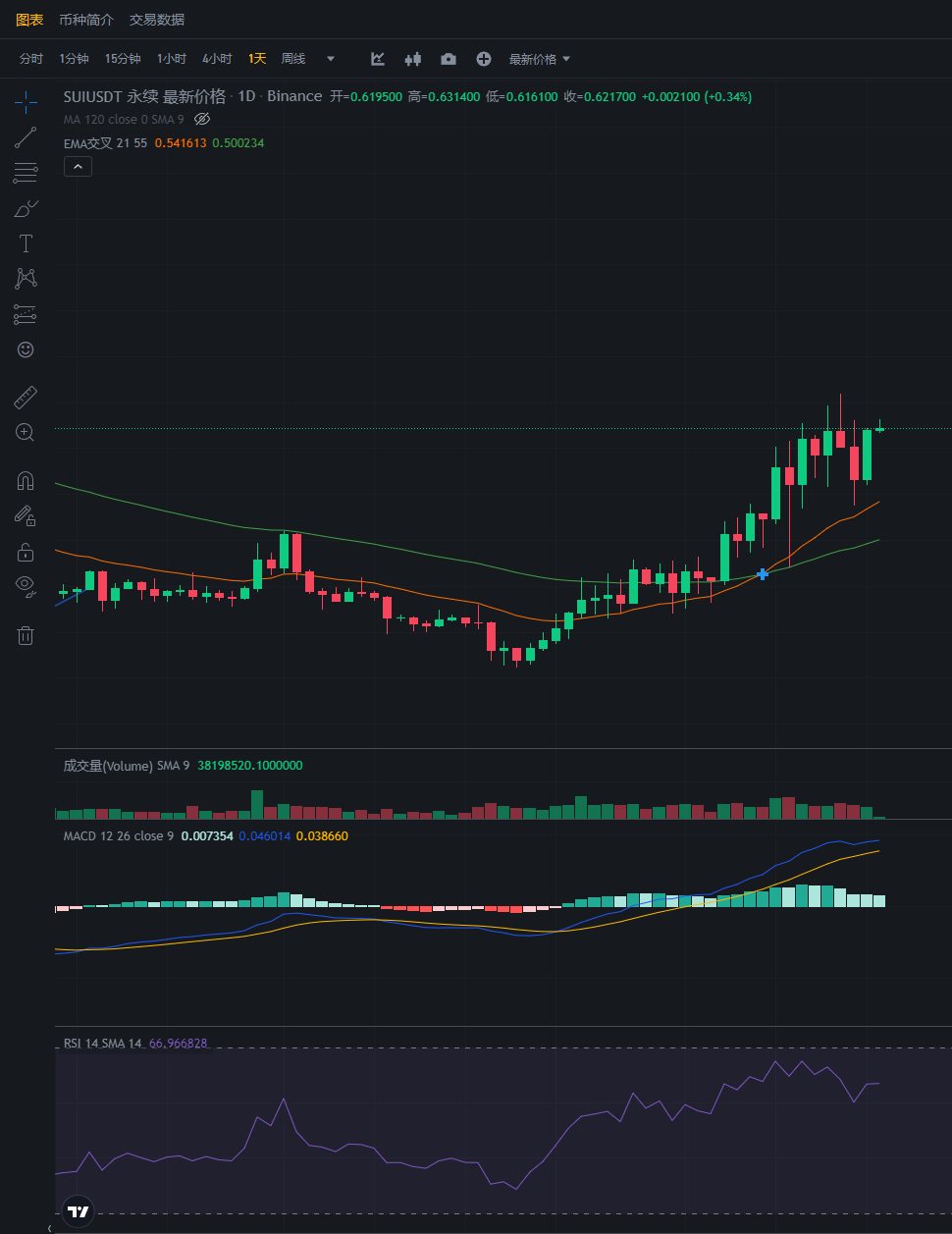
行情分析——加密货币市场大盘走势(11.16)
大饼昨日突然回调诱多上涨到38000附近,现在又重新跌回到37500,现在仓位小的可以加仓入场,而已经有仓位的不要动即可。 空单策略:入场37500附近 止盈34000-32000 止损39000 以太今日可以入场空单2060附近即可 策略:入…...
ICCV 23丨3D-VisTA:用于 3D 视觉和文本对齐的预训练Transformer
来源:投稿 作者:橡皮 编辑:学姐 论文链接:https://arxiv.org/abs/2308.04352 开源代码:http://3d-vista.github.io 摘要: 3D视觉语言标定(3D-VL)是一个新兴领域,旨在将…...

SFP-10G-SR光模块指南
SFP-10G-SR通常是思科(Cisco)使用的型号名。是一种用于非常短距离应用的最低成本、最低功耗的10G SFP模块。本文汇总了初学者在第一阶段关于10G SFP SR模块的常见问题。 SFP-10G-SR模块是否支持GE? 10GBASE-SR模块本身是可以支持GE速度的&am…...

使用Java实现一个简单的贪吃蛇小游戏
一. 准备工作 首先获取贪吃蛇小游戏所需要的头部、身体、食物以及贪吃蛇标题等图片。 然后,创建贪吃蛇游戏的Java项目命名为snake_game,并在这个项目里创建一个文件夹命名为images,将图片素材导入文件夹。 再在src文件下创建两个包࿰…...
智能运维监控告警6大优势
随着云计算和互联网的高速发展,大量应用需要横跨不同网络终端,并广泛接入第三方服务(如支付、登录、导航等),IT系统架构越来越复杂。 快速迭代的产品需求和良好的用户体验,需要IT运维管理者时刻保障核心业务稳定可用,…...

保姆级使用Vue-count-to
安装 npm install vue-count-to 直接使用 <template><div class"vue-count-to"><div class"count-to"><div><CountTo :startValstartVal :endValendVal :durationduration /></div><div><CountTo :startV…...

install YAPI MongoDB 备份mongo 安装yapi插件cross-request 笔记
登录容器 docker exec -it mongodb bash 登录mongo mongo -u root -p 123456 查看db show dbs 查看collection show collections 进入db use yapi 查看数据 db.<collection_name>.find() 带条件查看 db.<collection_name>.find({ <field>: <value>…...
WPA-hashcat渗透)
无线WiFi安全渗透与攻防(N.4)WPA-hashcat渗透
WPA-hashcat渗透 WPA-hashcat渗透1.hashcat介绍2.渗透姿势1.查看网卡2.开启监听模式3.扫描wifi4.抓包保存5.进行冲突模式攻击6.重新连接wifi7.生成hccap文件8.破解WPA-hashcat渗透 严重声明:cpu加速都是幌子,aricrack-ng也用cpu,不然用爱跑的? 1.hashcat介绍 Hashcat系列…...
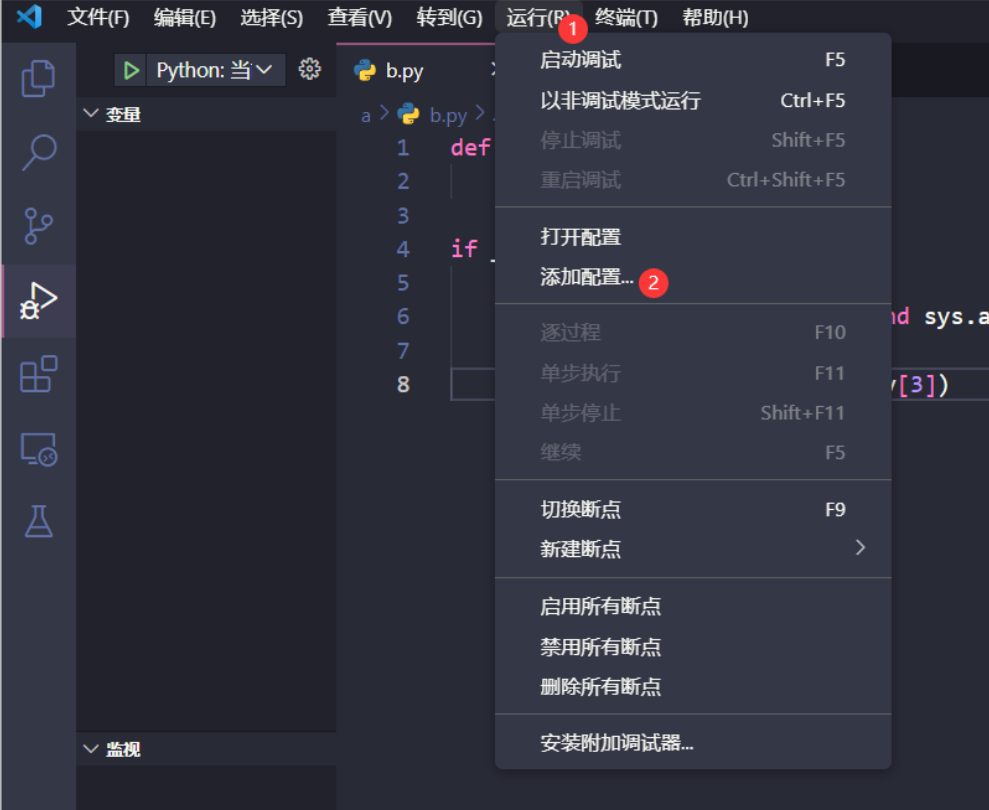
使用VSCode进行Python模块调试
使用VSCode进行Python模块调试 创建测试文件 创建文件test/a/b.py,且当前工作路径为test/ b.py文件内容: def cal(numa, numb):print(int(numa) int(numb))if __name__ "__main__":import sys# 判断系统参数长度是否为4且判断第2个参数是…...

【数据结构高阶】二叉搜索树
接下来我们来开始使用C来详细讲解数据结构的一些高阶的知识点 本期讲解的是二叉搜索树,对于初阶二叉树有所遗忘的同学可以看到这里: 【精选】【数据结构初阶】链式二叉树的解析及一些基本操作 讲解二叉搜索树主要是为了后面的map和set做铺垫ÿ…...
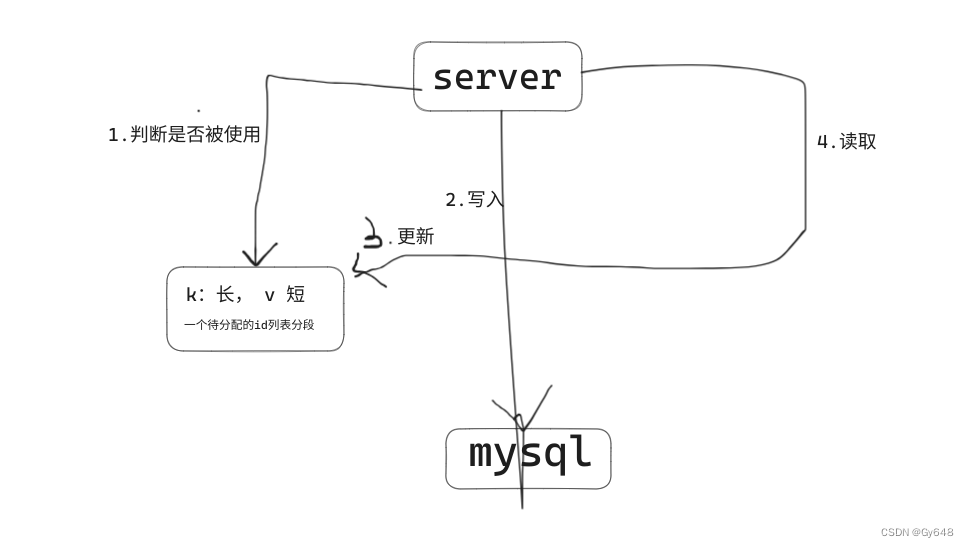
如何设计短域名系统
输入可能是 一个冗长的域名,过期时间和自定义的别名输出 自定义别名或者随机生成的短域名,在过期时间到来之前访问都可以被重定向到冗长的域名上约束条件 1.过期后就失效 2.短域名是唯一的 3.自定义短域名长度在7个字符(不包含域名长度&am…...
web缓存-----squid代理服务
squid相关知识 1 squid的概念 Squid服务器缓存频繁要求网页、媒体文件和其它加速回答时间并减少带宽堵塞的内容。 Squid代理服务器(Squid proxy server)一般和原始文件一起安装在单独服务器而不是网络服务器上。Squid通过追踪网络中的对象运用起作用。…...

nginx-location和proxy_pass的url拼接
在proxy_pass中端口号后面如果加入了"/",则location 匹配的内容全部去掉; Nginx中proxy_pass末尾带斜杠/和不带的区别 一、proxy_pass末尾有斜杠 location /api/ { proxy_pass http://127.0.0.1:8000/; } 请求地址:http://localhost/api/test 转发地…...

从零开始配置离线服务器
1.复制环境(包含torch包) 使用conda pack进行环境迁移(步骤很详细)_小舟%的博客-CSDN博客 注意:用pack的时候会默认把生成的tar.gz保存到当前目录,所以提前需要观测好在哪 注意:公用的环境必…...

Spring事务和事务的传播机制
目录 Spring中事务的实现 MySQL中的事务使用 Spring 编程式事务 TransactionTemplate 编程式事务 TransactionManager编程式事务 Spring声明式事务 Transactional 参数说明 事务因为程序异常捕获不会自动回滚的解决方案 Transactional 原理 Spring 事务隔离级别 Spring…...
)
Unity VFX Graph实战:从Compute Shader依赖看GPU粒子特效的性能与平台适配(以HDRP项目为例)
Unity VFX Graph深度解析:GPU粒子特效的性能优化与跨平台实战指南在游戏开发领域,粒子特效一直是营造沉浸感的关键要素。当传统CPU驱动的粒子系统遇到性能瓶颈时,Unity的Visual Effect Graph(VFX Graph)凭借其GPU加速能…...

别再死记硬背了!用‘重复局面’这道CSP真题,带你彻底搞懂C++中map容器的使用场景与底层逻辑
从国际象棋到红黑树:用CSP真题解锁C map的底层力量 国际象棋大师卡斯帕罗夫曾说:"棋局如同程序,每一步都是对数据结构的选择。"当我们面对CSP考试中那道看似简单的"重复局面"题时,表面上是考察字符串处理能力…...

MySQL 分区表实战:大表治理的利器与陷阱
开场白 分区表这个东西,我之前一直觉得就是个语法糖,直到有一次运维一张 2 亿行的日志表,查询慢到飞起,索引也建不动了,才认真研究分区表。结果发现分区表确实好用,但坑也不少——分区键选错了、分区裁剪没…...

Burp插件自动化渗透测试工作流:零基础入门与效率跃迁
1. 这不是“插件合集”,而是渗透测试工作流的底层操作系统重构 你有没有试过在Burp Suite里打开一个新目标,点开Proxy历史,看着几十个HTTP请求发呆——不知道该从哪条请求下手?右键菜单里密密麻麻的“Send to Repeater”“Send to…...

开源吉他谱编辑神器TuxGuitar:从新手到专业编曲的完整指南
开源吉他谱编辑神器TuxGuitar:从新手到专业编曲的完整指南 【免费下载链接】tuxguitar Open source guitar tablature editor 项目地址: https://gitcode.com/gh_mirrors/tu/tuxguitar 想要免费创作专业的吉他乐谱吗?TuxGuitar这款开源吉他谱编辑…...

Frida Spawn与Attach模式深度解析:Android加固对抗决策指南
1. 为什么刚学Frida的人总在Spawn和Attach之间反复横跳? “Frida Hook跑不起来”——这是我过去三年在安全技术社区、逆向学习群、CTF训练营里听到最多的一句抱怨。但真正拆开看,90%的问题根本不是代码写错了,也不是目标App加固太强ÿ…...

手把手拆解蓝牙Extended Advertising数据包:从HCI Command到空口PDU的完整流程
手把手拆解蓝牙Extended Advertising数据包:从HCI Command到空口PDU的完整流程 蓝牙技术演进到5.0版本后,Extended Advertising(扩展广播)机制的引入彻底改变了低功耗蓝牙的通信范式。这项技术突破不仅解决了传统广播模式的诸多限…...

深度解析:ctfileGet如何实现城通网盘直链解析的3大技术突破
深度解析:ctfileGet如何实现城通网盘直链解析的3大技术突破 【免费下载链接】ctfileGet 获取城通网盘一次性直连地址 项目地址: https://gitcode.com/gh_mirrors/ct/ctfileGet ctfileGet是一款专为城通网盘设计的开源直链解析工具,通过创新的技术…...

微信网页版终极解决方案:wechat-need-web 完整使用指南
微信网页版终极解决方案:wechat-need-web 完整使用指南 【免费下载链接】wechat-need-web 让微信网页版可用 / Allow the use of WeChat via webpage access 项目地址: https://gitcode.com/gh_mirrors/we/wechat-need-web 你是否曾经因为微信网页版限制而无…...

Keil µVision许可证失效问题解析与解决方案
1. 问题现象与背景解析最近遇到一个挺有意思的案例:一位工程师在安装了Windows Media Center后,突然发现Keil Vision IDE变成了评估版模式。这种情况其实在嵌入式开发领域并不罕见,但很多开发者第一次遇到时都会感到困惑。本质上,…...