大数据Hadoop之——部署hadoop+hive+Mysql环境(Linux)
目录
一、JDK的安装
1、安装jdk
2、配置Java环境变量
3、加载环境变量
4、进行校验
二、hadoop的集群搭建
1、hadoop的下载安装
2、配置文件设置
2.1. 配置 hadoop-env.sh
2.2. 配置 core-site.xml
2.3. 配置hdfs-site.xml
2.4. 配置 yarn-site.xml
2.5. 配置 mapred-site.xml
2.6. 配置 workers(伪分布式不配置)
2.7 配置sbin下启停命令
3、复制hadoop到其他节点(伪分布式不执行此步)
4、Hdfs格式化
5、启动hdfs分布式文件系统
三、msyql安装
1、卸载旧MySQL文件
2、下载mysql安装包
3、配置环境变量
4、删除用户组
5、创建用户和组
6、创建文件夹
7、更改权限
8、初始化
9、记住初始密码
10、配置文件
11 将mysql加入到服务中
12、设置开机启动并查看进程
13、 创建软连接
14、授权修改密码
四、HIve安装
1、下载安装
2、配置环境变量
3、配置文件
4、拷贝jar包
5、初始化
6、启动hive
一、JDK的安装
1、安装jdk
sudo yum search openjdk
yum install java-1.8.0-openjdk.x86_64
yum install java-1.8.0-openjdk-devel.x86_64
2、配置Java环境变量
vi ~/.bash_profile
export JAVA_HOME=/usr/local/jdk1.8.0_11
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
3、加载环境变量
source ~/.bash_profile
验证环境变量是否生效:
env | grep HOME
env | grep PATH
4、进行校验

二、hadoop的集群搭建
1、hadoop的下载安装
1.1. 下载
https://archive.apache.org/dist/hadoop/common/hadoop-3.3.4/
下载 hadoop-3.3.4.tar.gz 安装包1.2 上传
使用xshell上传到指定安装路径此处是安装路径是 /usr/local
1.3 解压重命名
tar -xzvf hadoop-3.3.4.tar.gz
mv hadoop-3.3.4 hadoop
1.4 配置环境变量
vi ~/.bash_profile
export JAVA_HOME=/usr/local/jdk1.8.0_11
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
1.5 加载环境变量
source ~/.bash_profile
验证环境变量是否生效:
env | grep HOME
env | grep PATH
1.6检验安装
hadoop version
出现下图说明安装成功




2、配置文件设置
2.1. 配置 hadoop-env.sh
hadoop伪分布式配置
export HADOOP_OS_TYPE=${HADOOP_OS_TYPE:-$(uname -s)}
export JAVA_HOME=/usr/local/jdk1.8.0_11hadoop集群配置(root指的是用户名)
export HADOOP_OS_TYPE=${HADOOP_OS_TYPE:-$(uname -s)}
export JAVA_HOME=/usr/local/jdk1.8.0_11export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
2.2. 配置 core-site.xml
<configuration>
<!-- 指定HDFS中NameNode的地址 默认 9000端口-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop001:9000</value>
<description>配置NameNode的URL</description>
</property><!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/data</value>
</property>分布式集群配置下面内容,伪分布式只需配置上面内容
<!--配置所有节点的root用户都可作为代理用户-->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property><!--配置root用户能够代理的用户组为任意组-->
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property><!--配置root用户能够代理的用户为任意用户-->
<property>
<name>hadoop.proxyuser.root.users</name>
<value>*</value>
</property>
</configuration>
2.3. 配置hdfs-site.xml
以下配置集群和伪分布式均可用
<configuration>
<!-- 数据的副本数量 -->
<property>
<name>dfs.replication</name>
<value>3</value> <!-- 伪分布式此时为1->
</property>
<!-- nn web端访问地址 默认也是9870-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop001:9870</value>
</property><!--设置权限为false-->
<property>
<name>dfs.permissions.enabled </name>
<value>false</value>
</property><!--设置元数据存储目录-->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///usr/local/hadoopdata/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///usr/local/hadoopdata/dfs/data</value>
</property>集群配置使用
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop003:9868</value>
</property>
<!-- 2nn web端访问地址 可以不配置-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:9868</value>
</property></configuration>
2.4. 配置 yarn-site.xml
<configuration>
<!-- NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行MR程序。-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>伪分布式以下无需配置
<!-- Site specific YARN configuration properties -->
<!-- yarn集群主角色RM运行机器。-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop002</value>
</property>
<!-- 每个容器请求的最小内存资源(以MB为单位)。-->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<!-- 每个容器请求的最大内存资源(以MB为单位)。-->
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>2048</value>
</property>
<!-- 容器虚拟内存与物理内存之间的比率。-->
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>4</value>
</property>
<!-- 关闭yarn内存检查 flink on hadoop 配置-->
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是 true -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property><!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是 true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
2.5. 配置 mapred-site.xml
<configuration>
<!-- mr程序默认运行方式。yarn集群模式 local本地模式-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>以下配置为集群配置使用
<!-- MR App Master环境变量。-->
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<!-- MR MapTask环境变量。-->
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<!-- MR ReduceTask环境变量。-->
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property><!-- 历史服务器端地址伪分布式和集群分布式都可以不配置 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop003:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop003:19888</value>
</property>
</configuration>
2.6. 配置 workers(伪分布式不配置)
配置三台主机名,在集群中使用。如果不是集群可以不用配置
hadoop102
hadoop103
hadoop104
2.7 配置sbin下启停命令
在 sbin下的start-dfs.sh和stop-dfs.sh中顶部配置
#!/usr/bin/env bash
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
在 sbin下的start-yarn.sh和stop-yarn.sh中顶部配置
#!/usr/bin/env bash
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
3、复制hadoop到其他节点(伪分布式不执行此步)
scp /usr/local/hadoop root@hadoop002:/usr/local/
4、Hdfs格式化
cd /usr/local/hadoop/
bin/hdfs namenode -format
find /usr/local/data/hadoop/
5、启动hdfs分布式文件系统
cd /usr/local/hadoop
./sbin/start-dfs.sh
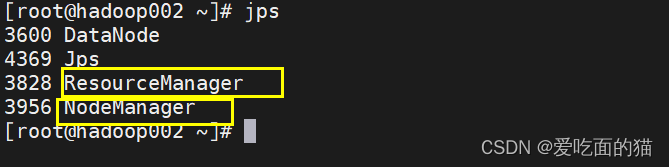
使用 jps 查看启动进程
访问hadoop分布式文件系统


6、启动yarn
cd /usr/local/hadoop
./sbin/start-yarn.sh
使用 jps 查看启动进程
访问hadoop分布式yarn页面

三、msyql安装
1、卸载旧MySQL文件
执行命令
# yum remove mysql mysql-server mysql-lib mysql-server
•再查看当前安装mysql的情况看卸载情况:
# rpm -qa|grep -i mysql
可以看到之前安装的包,然后执行删除命令,全部删除
# rpm -ev MySQL-devel--5.1.52-1.el6.i686 --nodeps
•查找之前老版本MySQL的目录,并删除老版本的MySQL的文件和库
# find / -name mysql
删除查找到的所有目录
#例如:rm -rf /run/lock/subsys/mysql
#例如: rm -rf /etc/selinux/targeted/active/modules/100/mysql # rm -rf /var/lib/mysql
•手动删除/etc/my.cnf
# rm -rf /etc/my.cnf
•再次查询如果无,则删除干净
# rpm -qa|grep -i mysql删除 mariadb
rpm -qa|grep mariadb
rpm -e --nodeps mariadb-libs
rpm -e --nodeps mysql-libs-5.1.52-1.el6_0.1.x86_64
2、Mysql下载安装
1.1 下载
官网网址:MySQL :: Download MySQL Community Server
在这里下载的是如下版本的mysql
https://cdn.mysql.com//Downloads/MySQL-5.7/mysql-5.7.26-linux-glibc2.12-x86_64.tar.gz1.2 上传
使用xshell上传到到linux服务器指定安装路径
此处是安装路径是 /usr/local
1.3 解压重命名
cd /usr/local/
tar -xzvf mysql-5.7.26-linux-glibc2.12-x86_64.tar.gz -C
# 如果是xz结尾压缩包用 tar -xvJf,如 tar -xvJf mysql-8.0.30-linux-glibc2.12-x86_64.tar.xz
重命令
mv mysql-5.7.26-linux-glibc2.12-x86_64 mysql
3、配置环境变量
vim /etc/profile
export MYSQL_HOME=/usr/local/mysql
export PATH=$PATH:$MYSQL_HOME/bin使环境生效
source /etc/profile
4、删除用户组
删除用户组
cat /etc/group|grep mysql
groupdel mysql
userdel mysql
5、创建用户和组
groupadd mysql
useradd -r -g mysql mysql
6、创建文件夹
mkdir /usr/local/mysql/data
7、更改权限
更改mysql目录下所有的目录及文件夹所属的用户组和用户,以及赋予可执行权限
chown -R mysql:mysql /usr/local/mysql/data/
chmod -R 755 /usr/local/mysql/data/
chown -R mysql:mysql /usr/local/mysql/
chmod -R 755 /usr/local/mysql/
8、初始化
安装依赖包
yum install libaio 或者下面的
yum install -y mariadb-server 安装mariadb-server 5.X版本使用
执行初始化
/usr/local/mysql/bin/mysqld --user=mysql --basedir=/usr/local/mysql/ --datadir=/usr/local/mysql/data/ --initialize
#说明
–initialize 初始化(真正开始干活)
–user=mysql 以mysql用户的身份初始化数据库,产生文件都是mysql作为拥有者
–basedir=xxx mysql其安装目录,非常重要
–lower_case_table_names=1 不区分大小写,如果初始化不指定,必须重装才能解决,非常重要
9、记住初始密码

10 将mysql加入到服务中
复制
cp /usr/local/mysql/support-files/mysql.server /etc/init.d/mysql#注意:默认情况下,GBLIC版本的数据库要求安装到/usr/local/mysql目录,其mysql.server脚本中对应的目录也是/usr/local/mysql,这会导致mysql无法启动。所以可以更改其basedir以及datadir两个变量,我们后面在 my.cnf中配置。
#赋予可执行权限
chmod +x /etc/init.d/mysql.cn
#添加服务
chkconfig --add mysql
#显示服务列表
chkconfig --list mysql

11、配置文件
5.x版本
vi /etc/my.cnf
[mysqld]
port=3306
user=mysql
basedir=/usr/local/mysql
datadir=/usr/local/mysql/data
socket=/tmp/mysql.sock
#character config
character_set_server=utf8mb4
explicit_defaults_for_timestamp=true
8.0版
注意:使用配置前一定要创建好目录
mkdir /usr/local/mysql/tmp
mkdir /usr/local/mysql/log
touch /usr/local/mysql/log/mysqld_safe.err
chown -R mysql:mysql /usr/local/mysql/tmp
chown -R mysql:mysql /usr/local/mysql/log
chown -R mysql:mysql /usr/local/mysql/log/mysqld_safe.err
简单配置(推荐)
vi /etc/my.cnf
[mysql]
user=mysql
default-character-set=utf8[mysqld]
basedir=/usr/local/mysql
datadir=/usr/local/mysql/data
socket=/usr/local/mysql/tmp/mysql.sock
user=mysql
log_timestamps=SYSTEM
collation-server = utf8_unicode_ci
character-set-server = utf8
default_authentication_plugin= mysql_native_password[mysqld_safe]
log-error=/usr/local/mysql/log/mysqld_safe.err
pid-file=/usr/local/mysql/tmp/mysqld.pid复杂配置
vi /etc/my.cnf
[mysql]
socket=/usr/local/mysql/tmp/mysql.sock
port=3306
user=mysql
default-character-set=utf8[mysqld]
basedir=/usr/local/mysql
datadir=/usr/local/mysql/data
socket=/usr/local/mysql/tmp/mysql.sock
port=3306
user=mysql
log_timestamps=SYSTEM
collation-server = utf8_unicode_ci
character-set-server = utf8
default_authentication_plugin= mysql_native_password[mysqld_safe]
log-error=/usr/local/mysql/log/mysqld_safe.err
pid-file=/usr/local/mysql/tmp/mysqld.pid
socket=/usr/local/mysql/tmp/mysql.sock[mysql.server]
basedir=/usr/local/mysql
datadir=/usr/local/mysql/data
socket=/usr/local/mysql/tmp/mysql.sock
port=3306
user=mysql
12、设置开机启动并查看进程
设置开机启动:chkconfig mysql on
启动mysql :service mysql start;
启动报错:
Starting MySQL.2023-06-25T04:58:08.333370Z mysqld_safe error: log-error set to ‘/usr/local/mysql/log/mysqld_safe.err’, however file don’t exists. Create writable for user ‘mysql’.
ERROR! The server quit without updating PID file (/usr/local/mysql/pid/mysqld.pid).解决方案
[root@mysql]# touch /usr/local/mysql/log/mysqld_safe.err
[root@mysql]# chown -R mysql:mysql /usr/local/mysql/log/mysqld_safe.err启动报错:
my_print_defaults: [Warning] World-writable config file ‘/usr/local/mysql/my.cnf’ is ignored.
Starting MySQL.my_print_defaults: [Warning] World-writable config file ‘/usr/local/mysql/my.cnf’ is ignored.
my_print_defaults: [Warning] World-writable config file ‘/usr/local/mysql/my.cnf’ is ignored.
ERROR! The server quit without updating PID file (/usr/local/mysql/data/localhost.localdomain.pid).解决方案
/usr/local/mysql/my.cnf’ 权限给的是 777,需要改成644,再次重新启动即可。
查看进程:ps -ef|grep mysql;
查看状态:service mysql status;
13、 创建软连接
ln -s /usr/local/mysql/bin/mysql /usr/bin
14、授权修改密码
mysql -uroot -p
输入密码(初始化时候的密码)
输入密码报错:
Can't connect to local MySQL server through socket '/tmp/mysql.sock' (2)
解决方案
创建软连接或者 修改配置文件my.cnf 中 socket = /usr/local/mysql/tmp/mysql.sock
8.0以下修改密码:
use mysql;
SET PASSWORD FOR 'root'@'localhost' = PASSWORD('newpassword');
flush privileges;
8.0以上修改密码
ALTER USER 'root'@'localhost' IDENTIFIED BY 'root';
ALTER USER 'root'@'%' IDENTIFIED BY 'root';
update user set user.Host='%' where user.User='root'
flush privileges;
alter user "root"@"%" identified by "root";
flush privileges;
8.0以下授权
grant all privileges on *.* to 'root'@'%' identified by '密码123456' with grant option;
flush privileges;8.0以上授权
use mysql;
#还原密码验证插件,将MySQL8的密码认证插件由caching_sha2_password更换成mysql_native_password
ALTER USER 'root'@'%' IDENTIFIED WITH mysql_native_password BY 'root';
#刷新权限
flush privileges;
四、HIve安装
1、下载安装
1.1下载
下载地址:http://archive.apache.org/dist/hive/
我们选择apache-hive-3.1.3-bin.tar.gz版本学习
1.2 上传
1.3 解压重命名
2、配置环境变量
vi ~/.bash_profile
export HIVE_HOME=/usr/local/hiveexport PATH=$PATH:$HIVE_HOME/bin
刷新配置
source ~/.bash_profile
3、配置文件
配置hive-env.sh
export HADOOP_HOME=/usr/local/hadoop
export HIVE_CONF_DIR=/usr/local/hive/conf
配置hive-site.xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true&useUnicode=true&characterEncoding=UTF-8&useSSL=false</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
</property>
</configuration>
4、拷贝jar包
4.1 拷贝mysql驱动
需要提前现在对应的驱动包,并解压
cp mysql-connector-java-5.1.49/mysql-connector-java-5.1.49-bin.jar /usr/local/hive/lib/
4.2 拷贝guava包
#hadoop和hive里面的guava包版本可能不一致,那么用hadoop里面的覆盖掉hive里面的
cp /usr/local/hadoop/share/hadoop/common/lib/guava-27.0-jre.jar /usr/local/hive/lib/#删除hive的旧依赖包
rm /opt/hive/lib/guava-19.0.jar
5、初始化
5.1 启动msyql
# 先查看mysql是否启动
service mysql status;
#未启动则进行启动
service mysql start
5.2 启动hadoop
#进入hadoop安装目录
cd /usr/local/hadoop/
#启动hadoop
sbin/start-all.sh
5.3 初始化hive
#进入hive安装目录
cd /usr/local/hive
#执行初始化命令,#初始化Hive
bin/schematool -dbType mysql -initSchema
6、启动hive
#进入hive安装目录
cd /usr/local/hive
#使用命令验证hive是否安装成功
bin/hive
#进入hive shell,使用show databases; 查看数据,说明安装成功!
相关文章:

大数据Hadoop之——部署hadoop+hive+Mysql环境(Linux)
目录 一、JDK的安装 1、安装jdk 2、配置Java环境变量 3、加载环境变量 4、进行校验 二、hadoop的集群搭建 1、hadoop的下载安装 2、配置文件设置 2.1. 配置 hadoop-env.sh 2.2. 配置 core-site.xml 2.3. 配置hdfs-site.xml 2.4. 配置 yarn-site.xml 2.5. 配置 ma…...
在地图文档中加入图层)
Python与ArcGIS系列(四)在地图文档中加入图层
目录 0 简述1 将图层添加到地图文档中2 将图层插入到地图文档0 简述 本篇介绍如何利用arcpy实现将图层添加到地图文档中,以及将图层插入到地图文档指定的位置。 1 将图层添加到地图文档中 arcpy的mapping模块提供的AddLayer()函数可以实现将图层添加到地图文档中。功能本质上…...
QT 程序异常崩溃
出现以下问题,大概率是你在修改代码时,在pro或者pri中增加了一些不存在的头文件或者cpp,使用BeyondCmp仔细对比,分享,希望帮助到你...

Ubuntu20.04 通过nmcli命令查看网卡状态为unmanaged
问题描述: 通过下述指令查看网卡状态为 "unmanaged" nmcli dev status 解决方法: cd /usr/lib/NetworkManager/conf.d/ sudo mv 10-globally-managed-devices.conf 10-globally-managed-devices.conf.bak sudo cp 10-globally-managed-devic…...

【R Error系列】r - fatal error : RcppEigen. h:没有这样的文件或目录
在头文件那要有 // [[Rcpp::depends(RcppEigen)]] 即: #include <Rcpp.h> #include <RcppEigen.h> using namespace Rcpp; using namespace Eigen;// [[Rcpp::depends(RcppEigen)]] // [[Rcpp::export]] 参考: r - fatal error: RcppEi…...

如何在聊天记录中实时查找大量的微信群二维码
10-5 如果你有需要从微信里收到的大量信息中实时找到别人发到群里的二维码,那本文非常适合你阅读,因为本文的教程,可以让你在海量的微信消息中,实时地把二维码自动挑出来,并且帮你分类保存。 如果你是做网推的&#…...

03-CSS基础选择器
3.1 CSS基础认知🍎 3.1.1 👁️🗨️CSS概念 CSS:层叠样式表(Cascading style sheets),为网页标签增加样式表现的 语法格式: 选择器{<!-- 属性设置 -->属性名:属性值; <!--每一个…...
:main函数及编译配置详解)
【ROS】RViz2源码分析(二):main函数及编译配置详解
【ROS】郭老二博文之:ROS目录 1、main函数 #include <memory> #include <string> #include <vector>#include <QApplication>...

Vue.js的生命周期钩子
聚沙成塔每天进步一点点 ⭐ 专栏简介 前端入门之旅:探索Web开发的奇妙世界 欢迎来到前端入门之旅!感兴趣的可以订阅本专栏哦!这个专栏是为那些对Web开发感兴趣、刚刚踏入前端领域的朋友们量身打造的。无论你是完全的新手还是有一些基础的开发…...
第3章:搜索与图论【AcWing】
文章目录 图的概念图的概念图的分类有向图和无向图 连通性连通块重边和自环稠密图和稀疏图参考资料 图的存储方式邻接表代码 邻接矩阵 DFS全排列问题题目描述思路回溯标记剪枝代码时间复杂度 [N 皇后问题](https://www.luogu.com.cn/problem/P1219)题目描述全排列思路 O ( n ! …...
:Qt 线程与并发)
C++ Qt 学习(七):Qt 线程与并发
1. Qt 创建线程的三种方法 1.1 方式一:派生于 QThread 派生于 QThread,这是 Qt 创建线程最常用的方法,重写虚函数 void QThread::run(),在 run() 写具体的内容,外部通过 start 调用,即可执行线程体 run() …...

Django框架之模板层
【一】Django模板系统 官方文档:官方文档 【二】常用语法 只需要记两种特殊符号: {{ }}和 {% %} 变量相关的用{逻辑相关的用{%%}。 【三】变量 在Django的模板语言中按此语法使用: {{ 变量名 }}。 当模版引擎遇到一个变量,它…...
【AI视野·今日Robot 机器人论文速览 第六十五期】Mon, 30 Oct 2023
AI视野今日CS.Robotics 机器人学论文速览 Mon, 30 Oct 2023 Totally 18 papers 👉上期速览✈更多精彩请移步主页 Daily Robotics Papers Gen2Sim: Scaling up Robot Learning in Simulation with Generative Models Authors Pushkal Katara, Zhou Xian, Katerina F…...
--otp - OTP操作库)
LuatOS-SOC接口文档(air780E)--otp - OTP操作库
otp.read(zone, offset, len)# 读取指定OTP区域读取数据 参数 传入值类型 解释 int 区域, 通常为0/1/2/3, 与具体硬件相关 int 偏移量 int 读取长度, 单位字节, 必须是4的倍数, 不能超过4096字节 返回值 返回值类型 解释 string 成功返回字符串, 否则返回nil 例…...
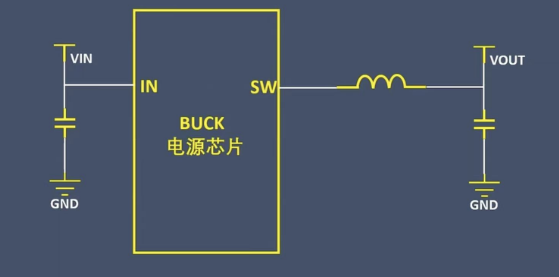
为什么LDO一般不用在大电流场景?
首先了解一下LDO是什么? LDO(low dropout regulator,低压差线性稳压器)或者低压降稳压器,它的典型特性就是压降。 那么什么是压降? 压降电压 VDO 是指为实现正常稳压,输入电压 VIN 必须高出 所…...

Adobe家里的“3D“建模工 | Dimension
今天,我们来谈谈一款在Adobe系列中比肩C4D的高级3D软件的存在—— Dimension。 Adobe Dimension ,其定位是一款与Photoshop以及Illustrator相搭配的3D绘图软件。 Adobe Dimensions与一般的3D绘图软件相较之下,在操作界面在功能上有点不大相同…...

MIB 6.1810实验Xv6 and Unix utilities(2)sleep
难度:easy Implement a user-level sleep program for xv6, along the lines of the UNIX sleep command. Your sleep should pause for a user-specified number of ticks. A tick is a notion of time defined by the xv6 kernel, namely the time between two interrupts f…...

修改 jar 包中的源码方式
在我们开发的过程中,我们有时候想要修改jar中的代码,方便我们调试或或者作为生产代码打包上线,但是在IDEA中,jar包中的文件都是read-only(只读模式)。那如何我们才能去修改jar包中的源码呢? 1.…...

Linux命令--重启系统的方法
原文网址:Linux命令--重启系统的方法_IT利刃出鞘的博客-CSDN博客 简介 本文介绍Linux重启系统的方法。 普通重启 reboot reboot的工作过程跟下边的halt差不多,不过它是引发主机重启,而halt是关机。它的参数与halt相差不多。 shutdown …...
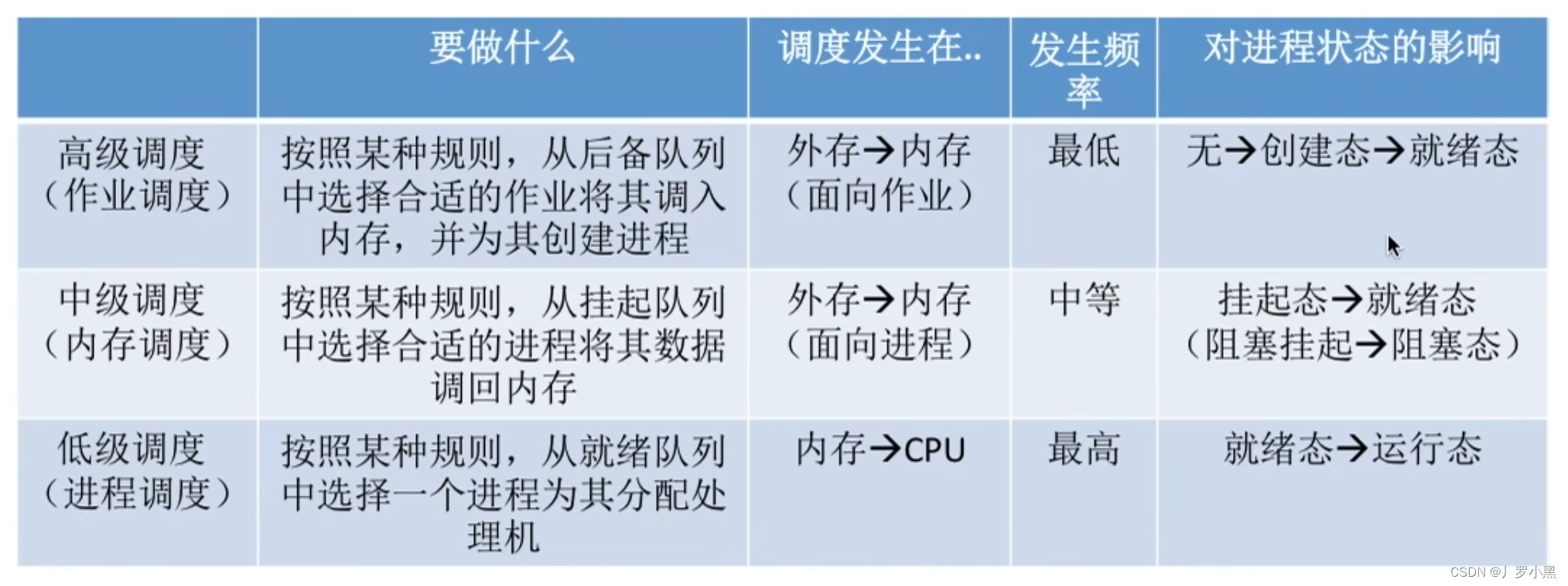
操作系统 day10(调度的概念、层次、七状态模型)
调度的概念 调度的层次 作业调度(高级调度) 进程调度(低级调度) 内存调度(中级调度) 挂起态与七状态模型 三层调度的联系和对比...
)
GitHub星标超50k的开源AI工具,为何大厂仍每年豪掷千万采购商业套件?(20年AI基建老兵深度复盘)
更多请点击: https://intelliparadigm.com 第一章:GitHub星标超50k的开源AI工具,为何大厂仍每年豪掷千万采购商业套件?(20年AI基建老兵深度复盘) 开源AI工具如LangChain、LlamaIndex、Ollama和Hugging Fac…...

ODM终极指南:5步快速上手免费开源无人机影像处理,生成专业三维模型与正射影像
ODM终极指南:5步快速上手免费开源无人机影像处理,生成专业三维模型与正射影像 【免费下载链接】ODM A command line toolkit to generate maps, point clouds, 3D models and DEMs from drone, balloon or kite images. 📷 项目地址: https…...

PotPlayer字幕翻译插件:5步实现免费自动化双语字幕体验
PotPlayer字幕翻译插件:5步实现免费自动化双语字幕体验 【免费下载链接】PotPlayer_Subtitle_Translate_Baidu PotPlayer 字幕在线翻译插件 - 百度平台 项目地址: https://gitcode.com/gh_mirrors/po/PotPlayer_Subtitle_Translate_Baidu 观看外语影视时&…...

床通道轨到轨CMOS运放:LMC6482AIM
简 介: 本文测试了TI公司LMC6482AIM双通道轨到轨CMOS运算放大器的基本特性。该芯片具有3V-15.5V宽工作电压范围、超低20fA输入偏置电流和轨到轨输入输出特性,适用于高阻抗传感器信号调理。测试发现其5V供电时工作电流仅0.8mA,15V时约1mA&…...

从零开始在个人项目中接入Taotoken并完成首次计费消费
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 从零开始在个人项目中接入Taotoken并完成首次计费消费 作为一名个人开发者,在尝试将大模型能力集成到自己的项目中时&a…...

Node.js 项目如何集成 Taotoken 实现稳定的大模型调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Node.js 项目如何集成 Taotoken 实现稳定的大模型调用 对于 Node.js 后端服务开发者而言,在项目中引入大模型能力正变得…...

如何快速配置游戏存档编辑器:面向玩家的完整指南
如何快速配置游戏存档编辑器:面向玩家的完整指南 【免费下载链接】SPT-AKI-Profile-Editor Программа для редактирования профиля игрока на сервере SPT-AKI 项目地址: https://gitcode.com/gh_mirrors/sp/SPT…...
)
从开发机到K8s集群,DeepSeek量化服务上线倒计时:48小时极速部署SOP(含CI/CD流水线脚本)
更多请点击: https://kaifayun.com 第一章:DeepSeek量化部署方案 DeepSeek系列大模型(如DeepSeek-V2、DeepSeek-Coder)在推理阶段对计算资源和显存占用要求较高,量化部署是实现低延迟、低成本服务的关键路径。本章聚焦…...

粒子滤波算法在非线性估计中的应用【附程序】
✨ 长期致力于非线性系统、参数估计、递归贝叶斯估计、粒子滤波算法、重采样、相关系数、谐波模型研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)基于…...

如何快速实现Windows硬件ID伪装:EASY-HWID-SPOOFER终极指南
如何快速实现Windows硬件ID伪装:EASY-HWID-SPOOFER终极指南 【免费下载链接】EASY-HWID-SPOOFER 基于内核模式的硬件信息欺骗工具 项目地址: https://gitcode.com/gh_mirrors/ea/EASY-HWID-SPOOFER 在当今数字隐私日益重要的时代,硬件指纹追踪已成…...