在Spring Boot中使用进程内缓存和Cache注解
在Spring Boot中使用内缓存的时候需要预先知道什么是内缓存,使用内缓存的好处。
什么是内缓存
内缓存(也称为进程内缓存或本地缓存)是指将数据存储在应用程序的内存中,以便在需要时快速访问和检索数据,而无需每次都从外部数据源(如数据库或网络)获取数据。
内缓存通常用于提高应用程序的性能和响应速度,因为内存访问比磁盘或网络访问更快。通过将经常使用的数据存储在内存中,应用程序可以避免频繁地访问慢速的外部数据源,从而提高数据访问的效率。
内缓存可以用于各种场景,例如:
- 数据库查询结果缓存:将数据库查询的结果存储在内存中,以便在相同的查询被再次执行时,可以直接从缓存中获取结果,而无需再次查询数据库。
- API响应缓存:将API的响应结果存储在内存中,以便在相同的API请求被再次发起时,可以直接从缓存中获取响应结果,而无需再次调用外部API。
- 计算结果缓存:将复杂的计算结果存储在内存中,以便在相同的计算被再次触发时,可以直接从缓存中获取结果,而无需重新执行计算逻辑。
内缓存可以使用各种缓存框架或库来实现,如Caffeine、EhCache、Redis等。这些缓存框架提供了方便的API和配置选项,使开发人员能够轻松地在应用程序中使用内缓存。
需要注意的是,内缓存是存储在应用程序的内存中的,因此它的容量是有限的。过多地使用内缓存可能会导致内存占用过高,从而影响应用程序的性能。因此,在使用内缓存时,需要根据实际需求和可用内存来进行合理的配置和管理。
案例:
引入相关依赖:
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-jpa</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-cache</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-actuator</artifactId></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><scope>provided</scope></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency>
在配置文件中引入数据库相关属性:
spring.datasource.url=jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=utf-8&useSSL=true&serverTimezone=UTC
spring.datasource.username=root
spring.datasource.password=123456
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driverspring.jpa.show-sql=true
spring.jpa.hibernate.ddl-auto=create-drop
创建实体类对象,其中数据库对象和实体类对象一一对应,这里就不给出数据库SQL语句了:
@Entity
//@Data
//@NoArgsConstructor
public class User {@Id@GeneratedValueprivate Long id;private String name;private Integer age;public User(String name, Integer age) {this.name = name;this.age = age;}public Long getId() {return id;}public void setId(Long id) {this.id = id;}public String getName() {return name;}public void setName(String name) {this.name = name;}public Integer getAge() {return age;}public void setAge(Integer age) {this.age = age;}public User() {}
}
User实体的数据访问实现:
@CacheConfig(cacheNames = "users")
public interface UserRepository extends JpaRepository<User, Long> {@CacheableUser findByName(String name);User findByNameAndAge(String name, Integer age);@Query("from User u where u.name=:name")User findUser(@Param("name") String name);}
创建一个测试类:
@Slf4j
@RunWith(SpringRunner.class)
@SpringBootTest
public class ApplicationTests {@Autowiredprivate UserRepository userRepository;@Autowiredprivate CacheManager cacheManager;@Testpublic void test() throws Exception {// 创建1条记录userRepository.save(new User("AAA", 10));User u1 = userRepository.findByName("AAA");System.out.println("第一次查询:" + u1.getAge());User u2 = userRepository.findByName("AAA");System.out.println("第二次查询:" + u2.getAge());}}
需要在启动类中加入@EnableCaching注解:
@EnableCaching
@SpringBootApplication
public class Application {public static void main(String[] args) {SpringApplication.run(Application.class, args);}}
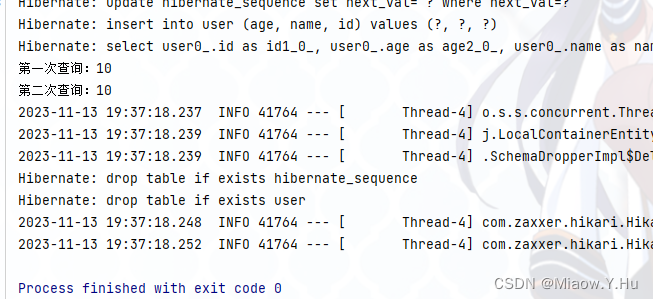
如图,我们可以看到在调用第二次的findByName的时候,并没有执行select语句,这样也就减少了对数据库的读取操作。
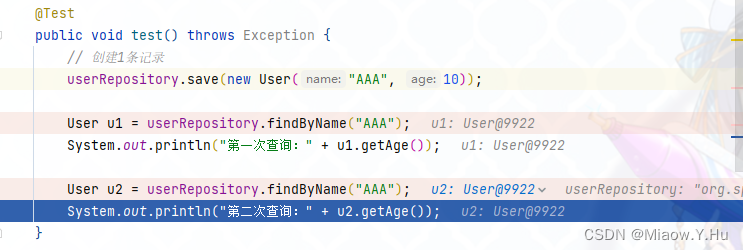
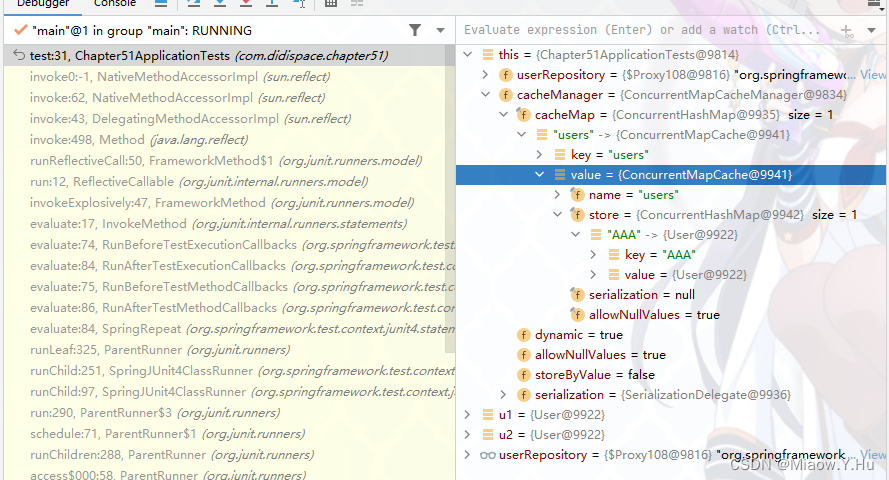
通过图片可以看到,在第一次调用findByName函数之后,CacheManager将这个查询结果保存下来,在第二次访问的时候,就可以匹配上而不需要再次访问数据库了。
@Cacheable:该注解用于标记方法的返回值应该被缓存。当调用带有@Cacheable注解的方法时,Spring Boot会首先检查缓存中是否存在对应的结果。如果存在,则直接返回缓存的结果;如果不存在,则执行方法体中的逻辑,并将结果存储到缓存中。该注解可以指定缓存的名称、缓存的键等参数。
@CachePut:该注解用于标记方法的返回值应该被更新到缓存中。与@Cacheable不同,@CachePut注解会每次都执行方法体中的逻辑,并将结果存储到缓存中。它通常用于更新缓存中的数据,以确保缓存的数据与实际数据保持同步。
@CacheEvict:该注解用于标记方法的返回值应该从缓存中移除。当调用带有@CacheEvict注解的方法时,Spring Boot会从缓存中移除对应的结果。该注解可以指定要移除的缓存名称、缓存的键等参数。它通常用于在数据发生变化时,清除缓存中的旧数据。
@Caching:该注解用于将多个缓存相关的注解组合在一起使用。通过@Caching注解,您可以在一个方法上同时使用多个缓存相关的注解,以实现更复杂的缓存操作。
关于更多的Cache配置,我们可以参照Spring Boot官方文档。
相关文章:
在Spring Boot中使用进程内缓存和Cache注解
在Spring Boot中使用内缓存的时候需要预先知道什么是内缓存,使用内缓存的好处。 什么是内缓存 内缓存(也称为进程内缓存或本地缓存)是指将数据存储在应用程序的内存中,以便在需要时快速访问和检索数据,而无需每次都从…...

YOLOv5项目实战(3)— 如何批量命名数据集中的图片
前言:Hello大家好,我是小哥谈。本节课就教大家如何去批量命名数据集中的图片,希望大家学习之后可以有所收获!~🌈 前期回顾: YOLOv5项目实战(1)— 如何去训练模型 YOLOv5项目实战(2...
输出到浏览器下载)
React + hooks + Ts 实现将后端响应的文件流(如Pdf)输出到浏览器下载
React 篇 一些关于react 学习与总结 这篇是记录开发中关于实现将后端响应的文件流(如Pdf)输出到浏览器下载,基于React Hooks Ts。 开发场景: 实现将后端响应的文件流(如Pdf)输出到浏览器下载,…...

大数据基础设施搭建 - JDK
一、创建目录 需要在root账号下操作,因为/目录下只能用root账号创建目录 1.1 创建目录 [roothadoop102 ~]# mkdir /opt/software/ [roothadoop102 ~]# mkdir /opt/module/1.2 修改权限 修改module、software文件夹的所有者和所属组均为hadoop用户,远程使…...

从0到0.01入门React | 010.精选 React 面试题
🤍 前端开发工程师(主业)、技术博主(副业)、已过CET6 🍨 阿珊和她的猫_CSDN个人主页 🕠 牛客高级专题作者、在牛客打造高质量专栏《前端面试必备》 🍚 蓝桥云课签约作者、已在蓝桥云课上架的前后端实战课程《Vue.js 和 Egg.js 开发企业级健康管理项目》、《带你从入…...
Docker启动SRS流媒体服务器
一、安装Docker 1.1、下载windows桌面版Windows 1.2、配置镜像 镜像加速器镜像加速器地址Docker 中国官方镜像https://registry.docker-cn.comDaoCloud 镜像站http://f1361db2.m.daocloud.ioAzure 中国镜像https://dockerhub.azk8s.cn科大镜像站https://docker.mirrors.ustc…...

php+MySQL防止sql注入
1、使用预处理语句(Prepared Statements):预处理语句能够防止攻击者利用用户输入来篡改SQL语句,同时也能提高执行效率。通过将用户的输入参数与SQL语句分离,确保参数以安全的方式传递给数据库引擎,避免拼接…...

git 删除远程非主分支
git删除远程分支问题及git批量删除已合并的远程分支 - joshua317的博客 git push origin --delete branch-name 本版本Gitlab没有设置按钮,所以不能在网页上删除项目。但是可以在本地使用上述命令来删除远程仓库中非主分支的分支。 测试过不论在哪个分支操作都可…...

【MySQL学习】C++外部调用
#include "mysql.h" MYSQL *mysql; MYSQL_RES *rec; MYSQL_ROW row; (1)连接 char *server "localhost"; char *user "root"; char *password "hello"; char *database "mysql"; mysql mysql_i…...
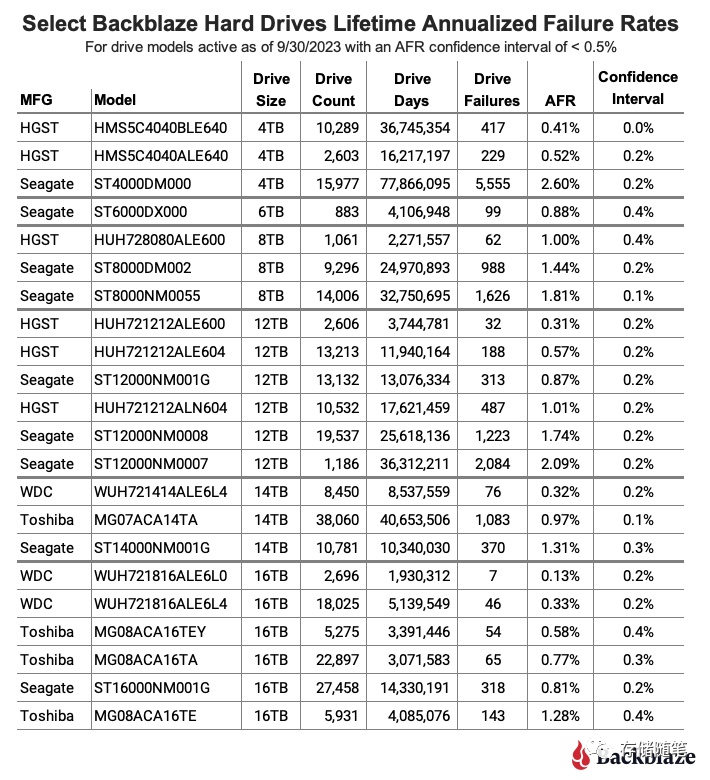
Backblaze 2023 Q3硬盘故障质量报告解读
作为一家在2021年在美国纳斯达克上市的云端备份公司,Backblaze一直保持着对外定期发布HDD和SSD的故障率稳定性质量报告,给大家提供了一份真实应用场景下的稳定性分析参考数据。2023年度之前发布的两次报告,请参考: Backblaze发布2…...

docker安装elasticsearch,elasticsearch-head
安装elasticsearch 1、执行命令:docker pull elasticsearch:8.11.1 2、执行命令:docker run --name elastic -p 9200:9200 -p 9300:9300 -e "discovery.typesingle-node" -d elasticsearch:8.11.1 3、执行命令:docker exec -it …...
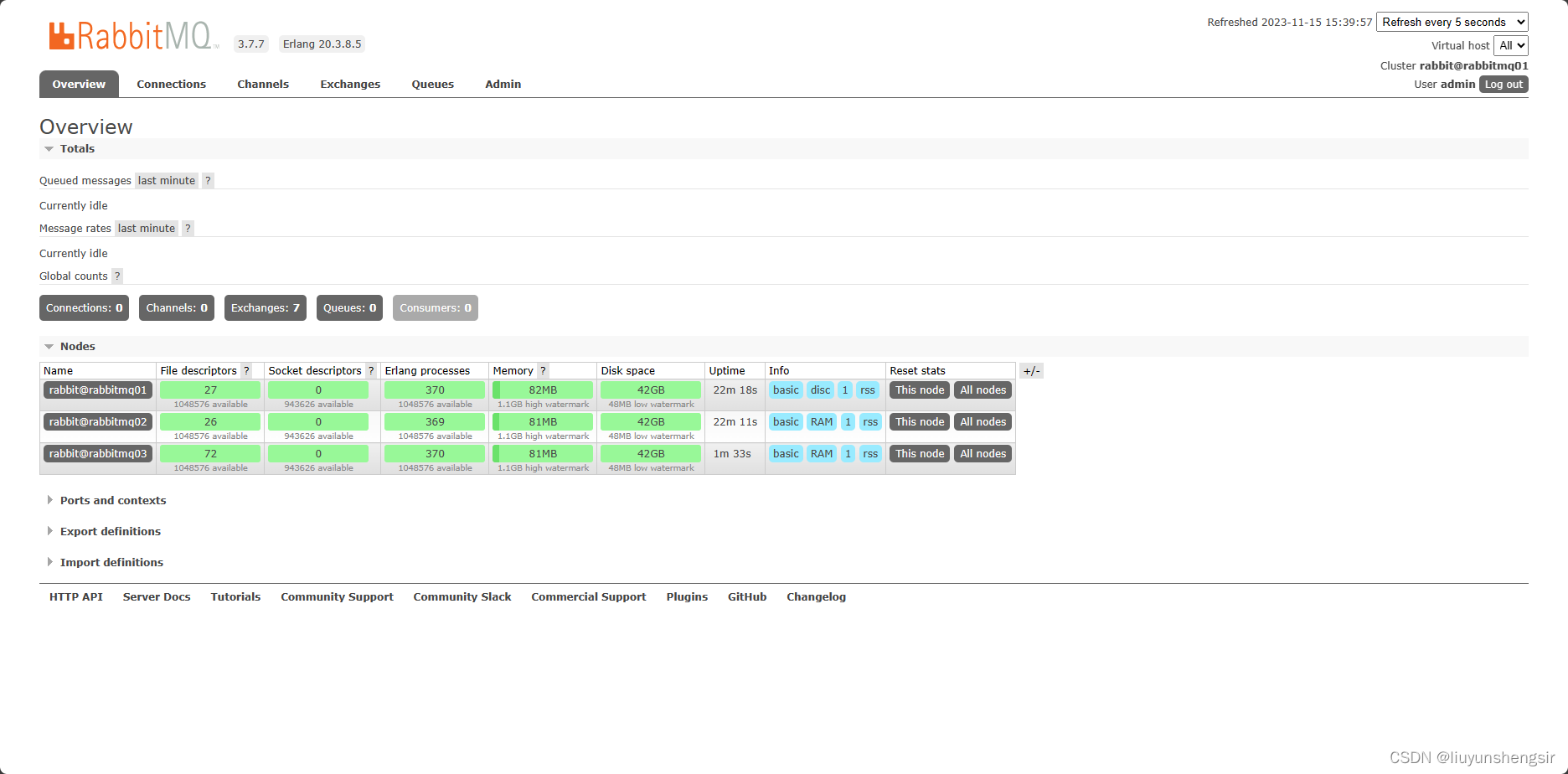
rabbitmq 集群搭建
RabbitMQ集群介绍 RabbitMQ集群是一组RabbitMQ节点(broker)的集合,它们一起工作以提供高可用性和可伸缩性服务。 RabbitMQ集群中的节点可以在同一物理服务器或不同的物理服务器上运行。 RabbitMQ集群的工作原理是,每个节点在一个…...

【云原生-Kurbernets篇】Kurbernets集群的调度策略
调度 一、Kurbernetes的list-watch机制1.1 list-watch机制简介1.2 创建pod的流程(结合list-watch机制) 二、Scheduler的调度策略2.1 简介2.2 预选策略(predicate)2.3 优选策略(priorities) 三、标签管理3.1…...
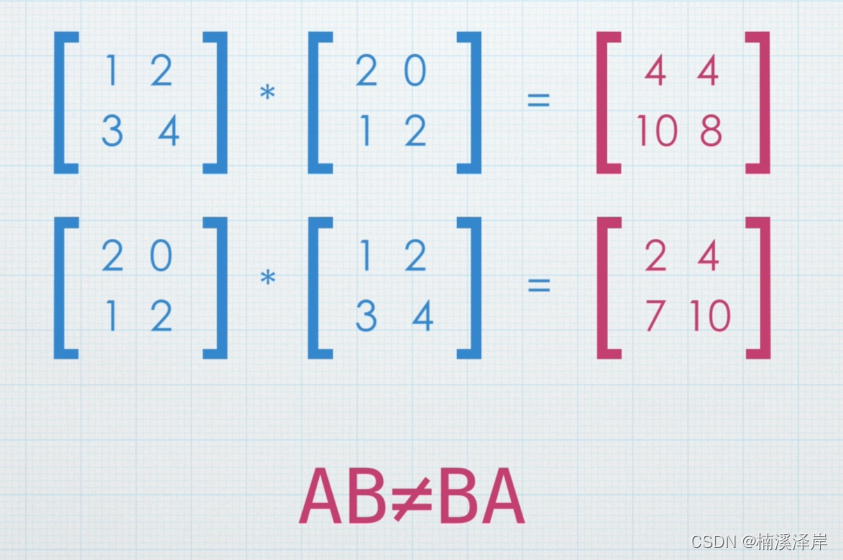
Unity中Shader矩阵的乘法
文章目录 前言一、矩阵乘以标量二、矩阵和矩阵相乘1、第一个矩阵的列数必须 与 第二个矩阵的行数相等,否则无法相乘!2、相乘的结果矩阵,行数由第一个矩阵的行数决定,列数由第二个矩阵的列数决定! 三、单位矩阵四、矩阵…...
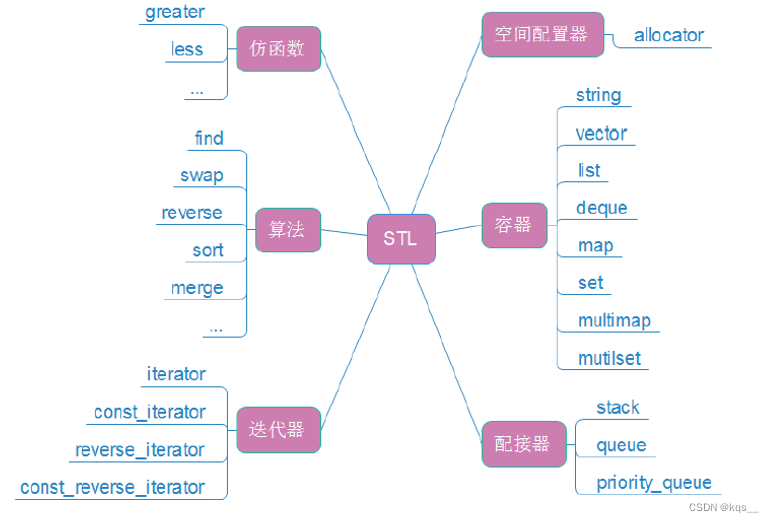
C++ STL简介
1. 什么是STL STL(standard template libaray-标准模板库):是C标准库的重要组成部分,不仅是一个可复用的组件库,而且是一个包罗数据结构与算法的软件框架。 2. STL的版本 原始版本 Alexander Stepanov、Meng Lee 在惠普实验室…...

如何优雅的使用contorller层
一个完整的后端请求由 4 部分组成: 接口地址(也就是 URL 地址)请求方式(一般就是 get、set,当然还有 put、delete)请求数据(request,有 head 跟 body)响应数据ÿ…...

发现区块链世界的新大门——AppBag.io DApp导航网站全面解析
随着区块链技术的飞速发展,分布式应用(DApp)个充满创新和可能性的领域里,appbag.io DApp导航网站应运而生,为您打开探索区块链世界的新大门。 区块链应用的集大成者 AppBag.io DApp导航网站不仅是一个DApp的集散地&a…...

C#多线程Thread、Task
在C#中,线程可以用于完成需要耗费较长时间的操作,而不会阻塞用户界面。一个程序可以有多个线程,每个线程可以并行执行代码。 在C#中,可以使用System.Threading.Thread类来创建和控制线程,使用System.Threading.Mutex类…...

Qt QWebSocket实现JS调用C++
目录 前言1、QWebChannel如何与网页通信2、QWebSocketQWebChannel与网页通信2.1 WebSocketTransport2.2 WebSocketClientWrapper2.3 初始化WebSocket服务器2.4 前端网页代码修改 总结 前言 本篇主要介绍实现JS调用C的另一种方式,即QWebSocketQWebChannel。与之前的…...

Android Matrix的使用详解(通过矩阵获取到图片缩放比例和角度)
网上查了好久相关的资料,都没有明确的答案。最终通过多次测试结果,结合安卓定义的矩阵含义,推算出来矩阵的数学含义以及相关的计算公式 1.获取Matrix矩阵: Matrix matrix new Matrix(); float[] matrixValues new float[9]; …...

终极解密:如何使用unluac工具实现Lua字节码逆向工程
终极解密:如何使用unluac工具实现Lua字节码逆向工程 【免费下载链接】unluac fork from http://hg.code.sf.net/p/unluac/hgcode 项目地址: https://gitcode.com/gh_mirrors/un/unluac unluac是一款专业的Lua 5.x字节码反编译工具,能够将编译后的…...

为OpenClaw配置Taotoken作为OpenAI兼容供应商的完整流程
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为OpenClaw配置Taotoken作为OpenAI兼容供应商的完整流程 OpenClaw是一款流行的AI智能体开发工具,它允许开发者便捷地接…...

科学机器学习入门指南:DeepXDE物理信息学习的完整教程
科学机器学习入门指南:DeepXDE物理信息学习的完整教程 【免费下载链接】deepxde A library for scientific machine learning and physics-informed learning 项目地址: https://gitcode.com/gh_mirrors/de/deepxde 你是否想要用深度学习解决复杂的物理方程&…...

终极指南:如何在VSCode中打造你的私人投资情报中心
终极指南:如何在VSCode中打造你的私人投资情报中心 【免费下载链接】leek-fund :chart_with_upwards_trend: 韭菜盒子VSCode插件,可以看股票、基金、期货等实时数据。 LeekFund turns your VS Code and Cursor into a real-time stock, fund, and future…...

如何快速集成AdvancedSessionsPlugin:终极多人游戏开发指南
如何快速集成AdvancedSessionsPlugin:终极多人游戏开发指南 【免费下载链接】AdvancedSessionsPlugin Advanced Sessions Plugin for UE4 项目地址: https://gitcode.com/gh_mirrors/ad/AdvancedSessionsPlugin 你是否正在为虚幻引擎4的多人游戏开发而烦恼&a…...

HS2-HF Patch:从新手到高手,一站式解决HoneySelect2的三大核心困扰
HS2-HF Patch:从新手到高手,一站式解决HoneySelect2的三大核心困扰 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch 如果你正在玩HoneySe…...

VisualGGPK2:流放之路游戏资源编辑器的完整使用指南
VisualGGPK2:流放之路游戏资源编辑器的完整使用指南 【免费下载链接】VisualGGPK2 Library for Content.ggpk of PathOfExile (Rewrite of libggpk) 项目地址: https://gitcode.com/gh_mirrors/vi/VisualGGPK2 VisualGGPK2是一款专为《流放之路》(Path of Ex…...

Windows网络性能测试神器:iperf3-win-builds完整使用指南
Windows网络性能测试神器:iperf3-win-builds完整使用指南 【免费下载链接】iperf3-win-builds iperf3 binaries for Windows. Benchmark your network limits. 项目地址: https://gitcode.com/gh_mirrors/ip/iperf3-win-builds iperf3-win-builds项目为Windo…...

保姆级教程:一步步教你排查并修复Windows上原神启动器的Qt平台插件错误
彻底解决Windows原神启动器Qt插件报错:零基础环境变量修改指南当你满心欢喜地双击原神启动器图标,准备开启提瓦特大陆的冒险时,屏幕上突然弹出的错误提示框瞬间浇灭了热情:"This application failed to start because no Qt …...

终极解决方案:如何用qmc-decoder快速解锁QQ音乐加密格式
终极解决方案:如何用qmc-decoder快速解锁QQ音乐加密格式 【免费下载链接】qmc-decoder Fastest & best convert qmc 2 mp3 | flac tools 项目地址: https://gitcode.com/gh_mirrors/qm/qmc-decoder 你是否曾经下载了QQ音乐,却发现那些.qmc3、…...