实战:给docusaurus文档网站配置Algolia 实现全站内容搜索功能-2023.11.16(已解决)
更新于:2023年11月16日
次文档已全部脱敏!
实战:给docusaurus文档网站配置Algolia 实现全站内容搜索功能-2023.11.16==(已解决)==
目录

前提条件
🍀
前提条件
具备docker环境
具有自己的网站
🍀
实验软件(包含在此文档里)
🍀
实验环境
docusaurus 3.0.0
node v18.18.0
npm 9.1.2
win10
前言
什么是Algolia
这个配置过程挺简单的,按文档操作,就OK的。
docusaurus搭建的静态网站,默认是不具有全站内容搜索功能的,因此这里配置Algolia 实现内容搜索。
Algolia 是一个搜索、推荐服务平台,可以通过简单的配置来为站点添加全文检索功能。
基本原理:
通过爬虫对目标网站的内容创建 Records (记录), 在用户搜索时调用接口返回相关内容。
为网站添加 实时搜索, 采用 Docusaurus2 官方支持的 Algolia DocSearch
Docsearch 每周一次爬取网站 (可在网页界面上配置具体时间), 并将所有内容汇总到一个 Algolia 索引中
随后,前端页面会调用 Algolia API 来直接查询这些内容。
1、Docsearch 官网申请
一定要先向Docsearch 官网申请成功后,再创建自己的数据源才行,不然可能会测试失败的。
前置条件:
- 准备好自己的域名地址 - 本案例: https://onedayxyy.cn/
这个是自己的docusaurus文档网站。
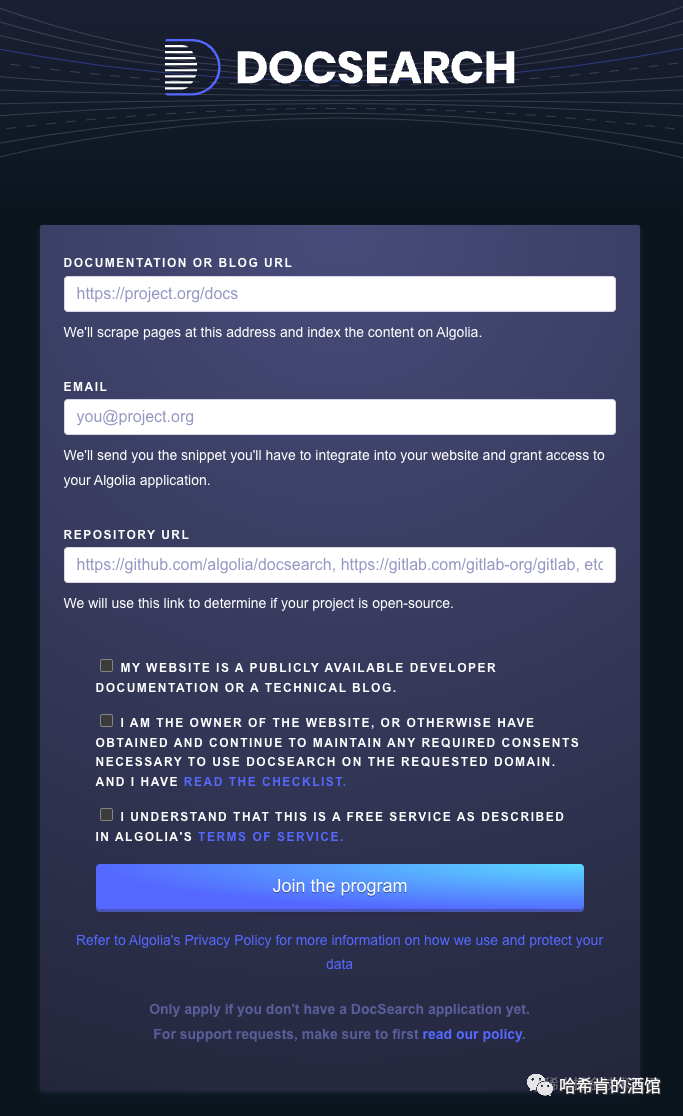
- 前置条件准备完成后, 就可到 Docsearch 注册
https://docsearch.algolia.com/apply/
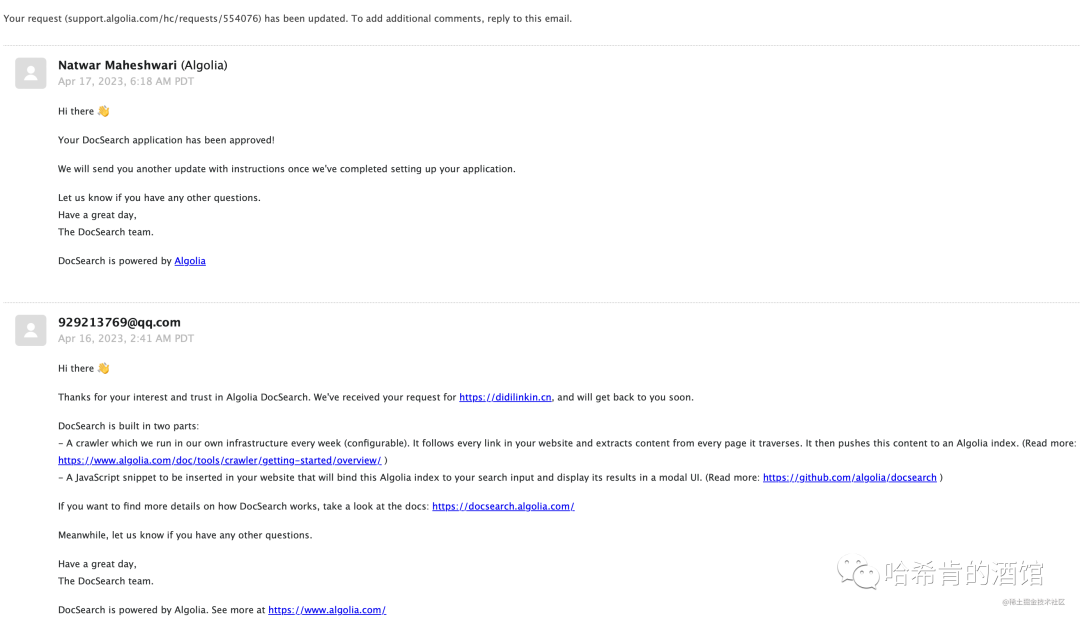
提交后大约 2 天内会收到 反馈邮件, 通知注册成功:
自己的测试过程如下:
https://docsearch.algolia.com/apply/
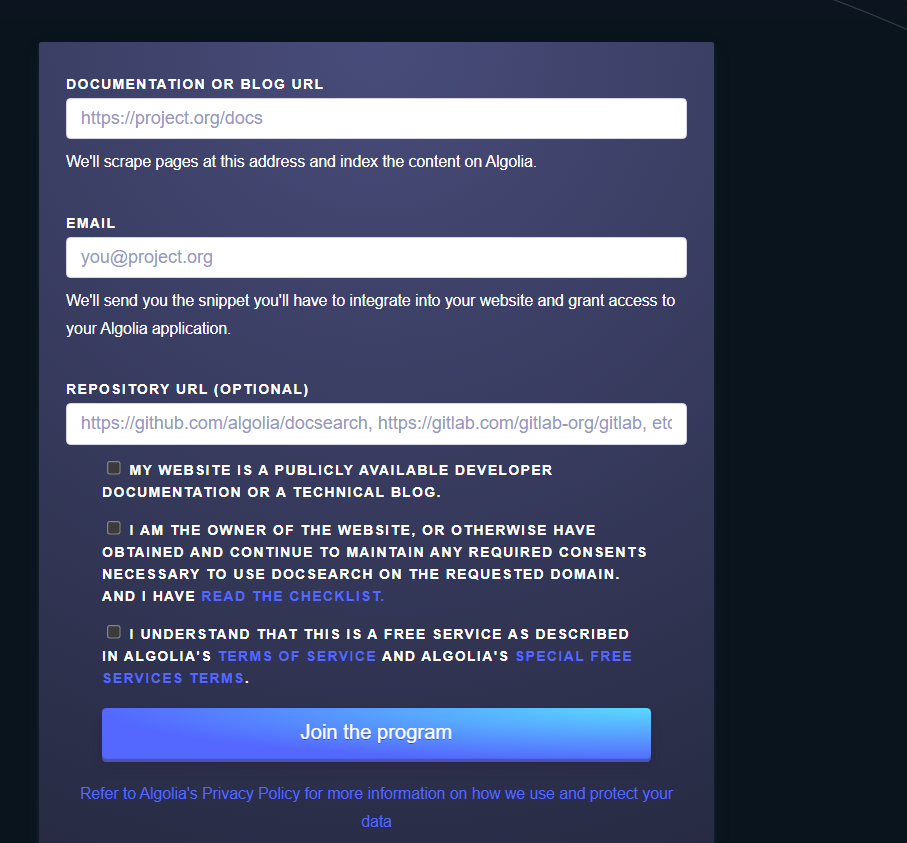
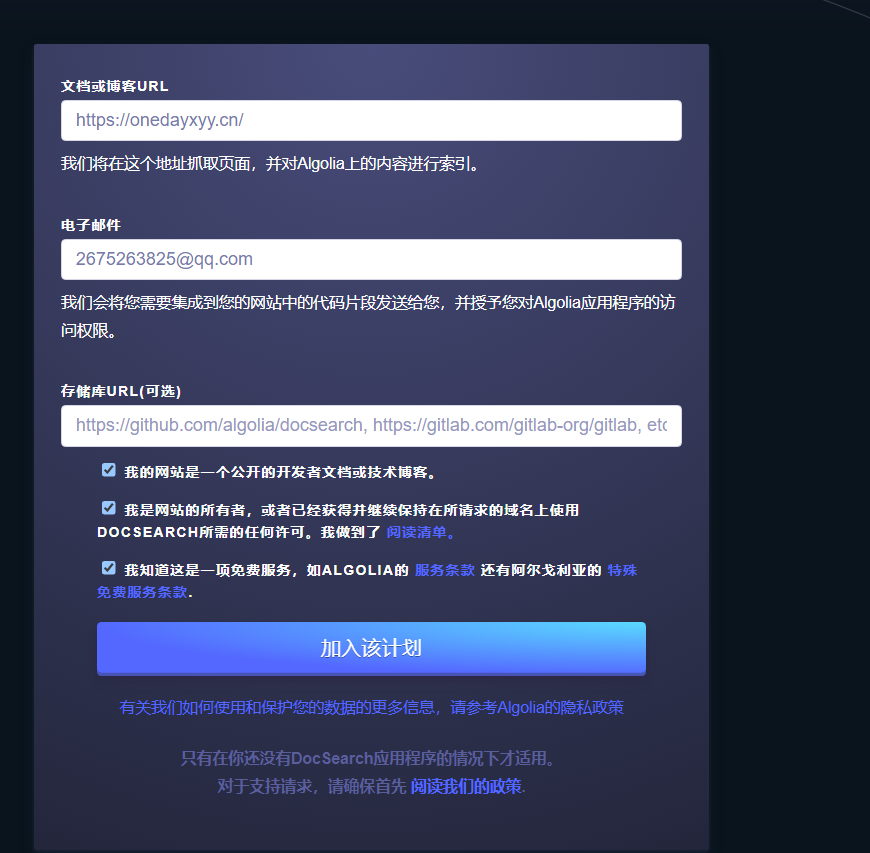
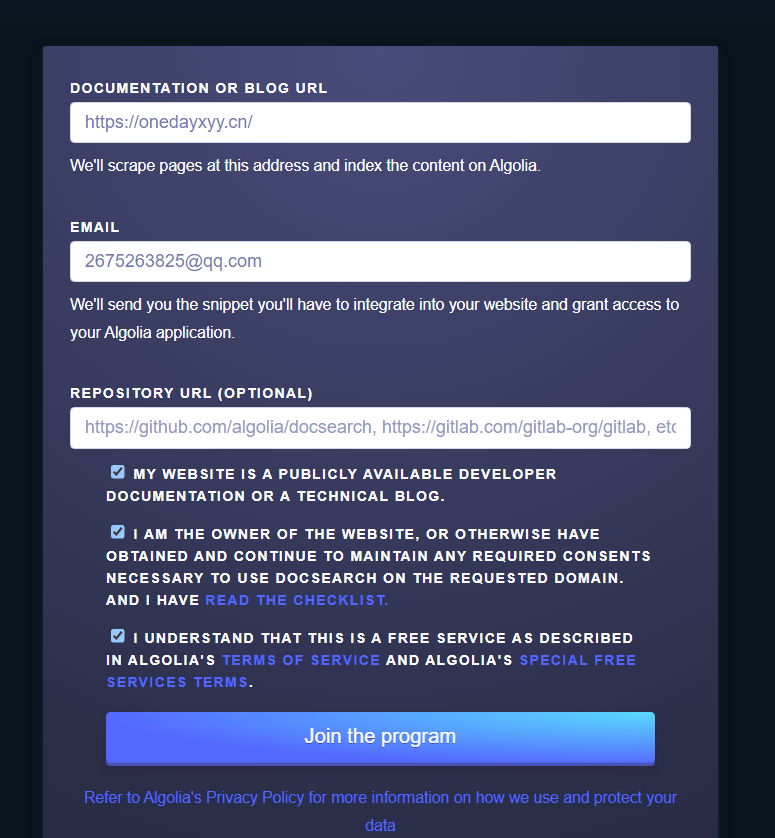
点击Join后,怎么没有反应呢?奇怪。。。(点击后,就自动提交了,我们只需要耐心等待即可)
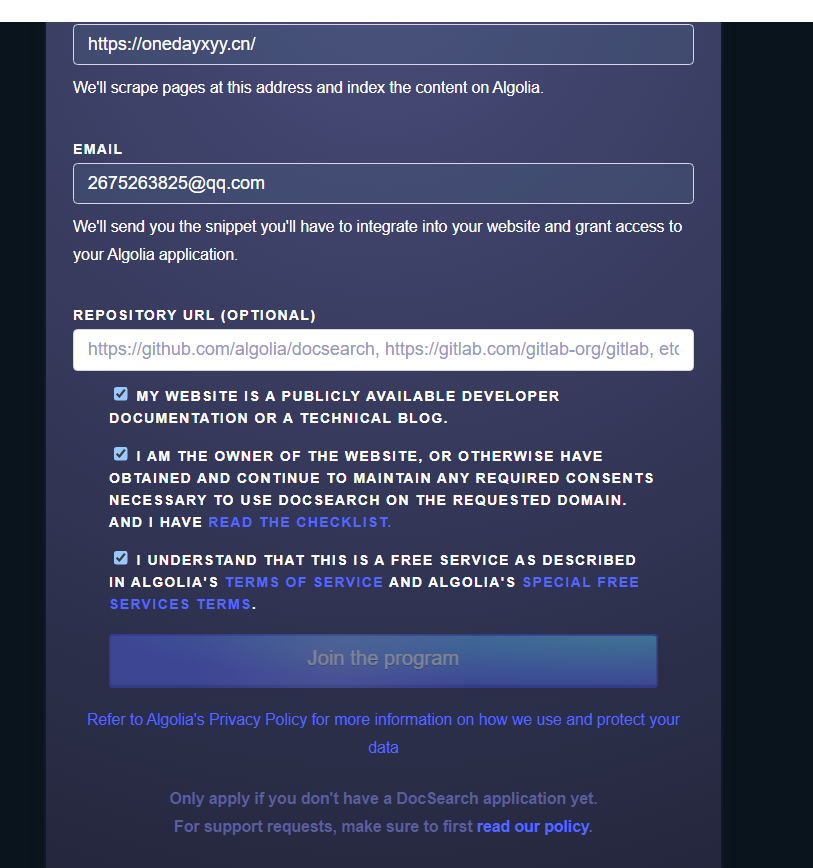
看下后续是否会收到邮件吧?
当前操作时间为:2023年11月15日14:25:55
- 哦,后面收到邮件了
(几个小时就会得到回复了)


注意:等到官方回复后,这里点击import your data后,就到了具体的配置步骤,我们不用管,按我的文档往下走即可。
https://info.algolia.com/NzQ2LVJPVS0zNjEAAAGPctQLIfgrI3cY5lI2PlJRPBj5GdQRSoaEu03a3Yb65nWoUcB1tBCmT1mdaASw-mRRgUgSo0A=
2、注册账号&创建 Application
获取 Application ID & API Keys
首先需要去 algolia 官网注册自己的账号,可以直接使用 Github 注册登陆即可。
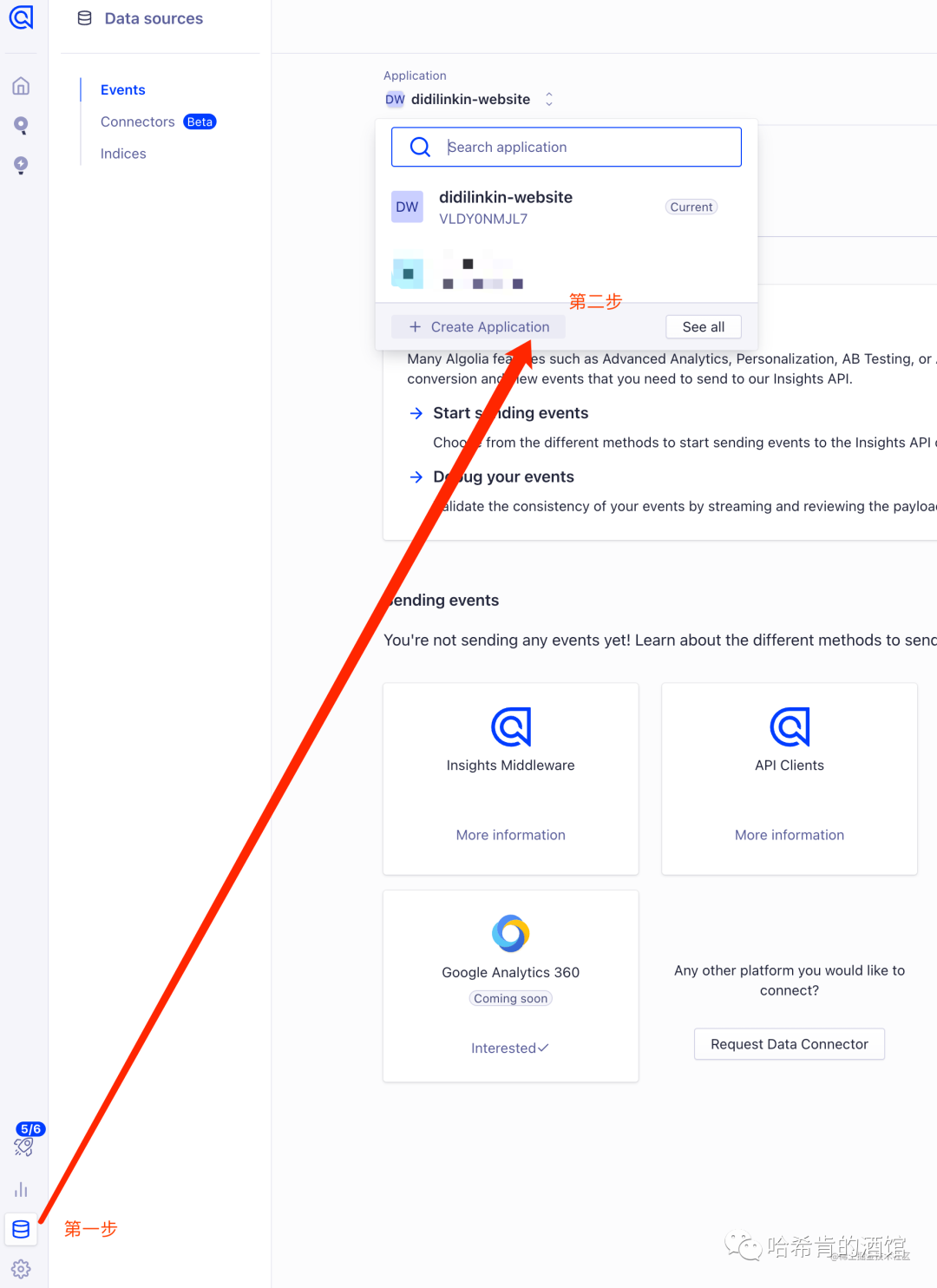
注册完后,创建数据源 DB:
- 前往 Algolia 官网, 登录账户 创建 Application
https://dashboard.algolia.com/apps/EW7M8KMAOC/dashboard
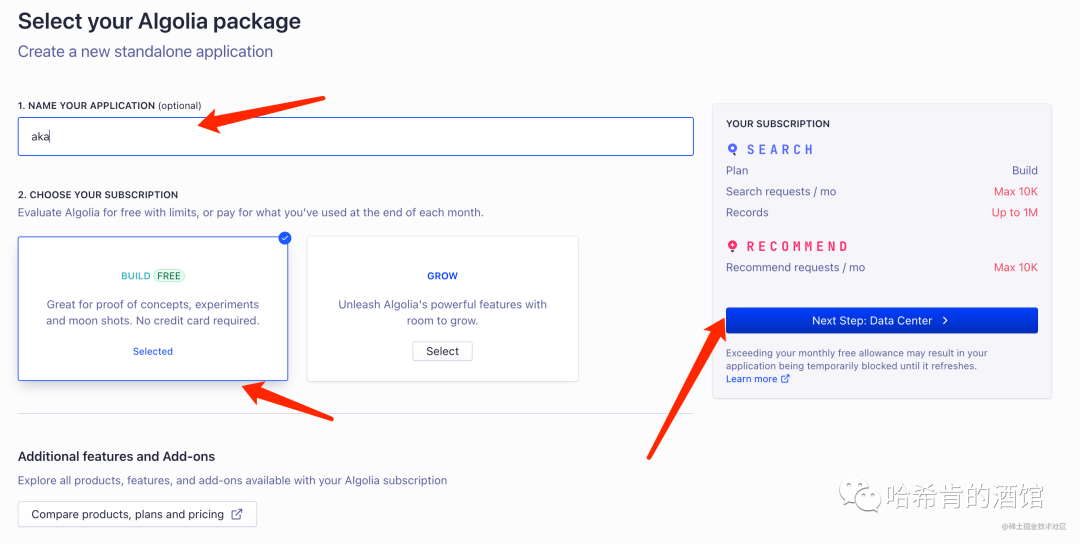
设置 Application 名称, 选择免费计划
最后选择响应速度快的服务后, 创建成功✅
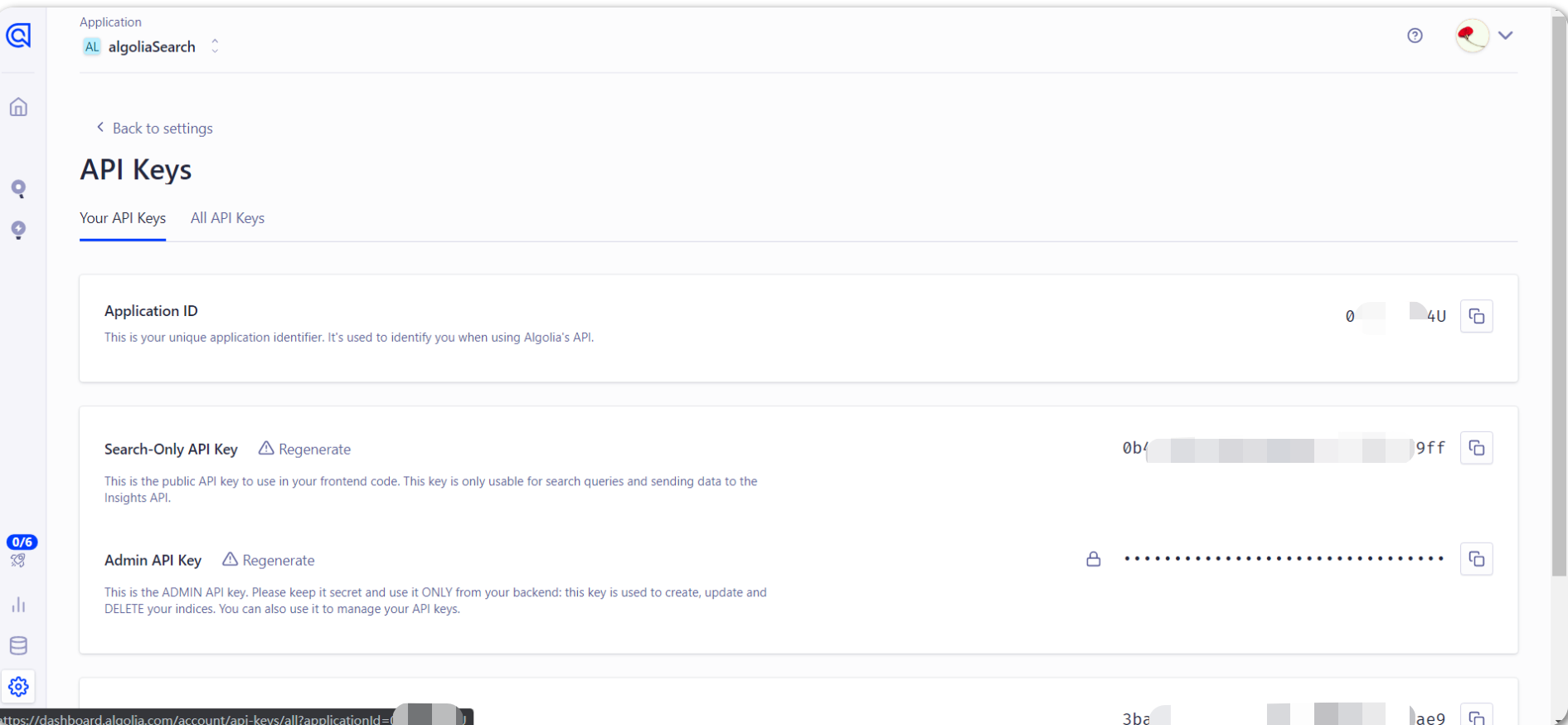
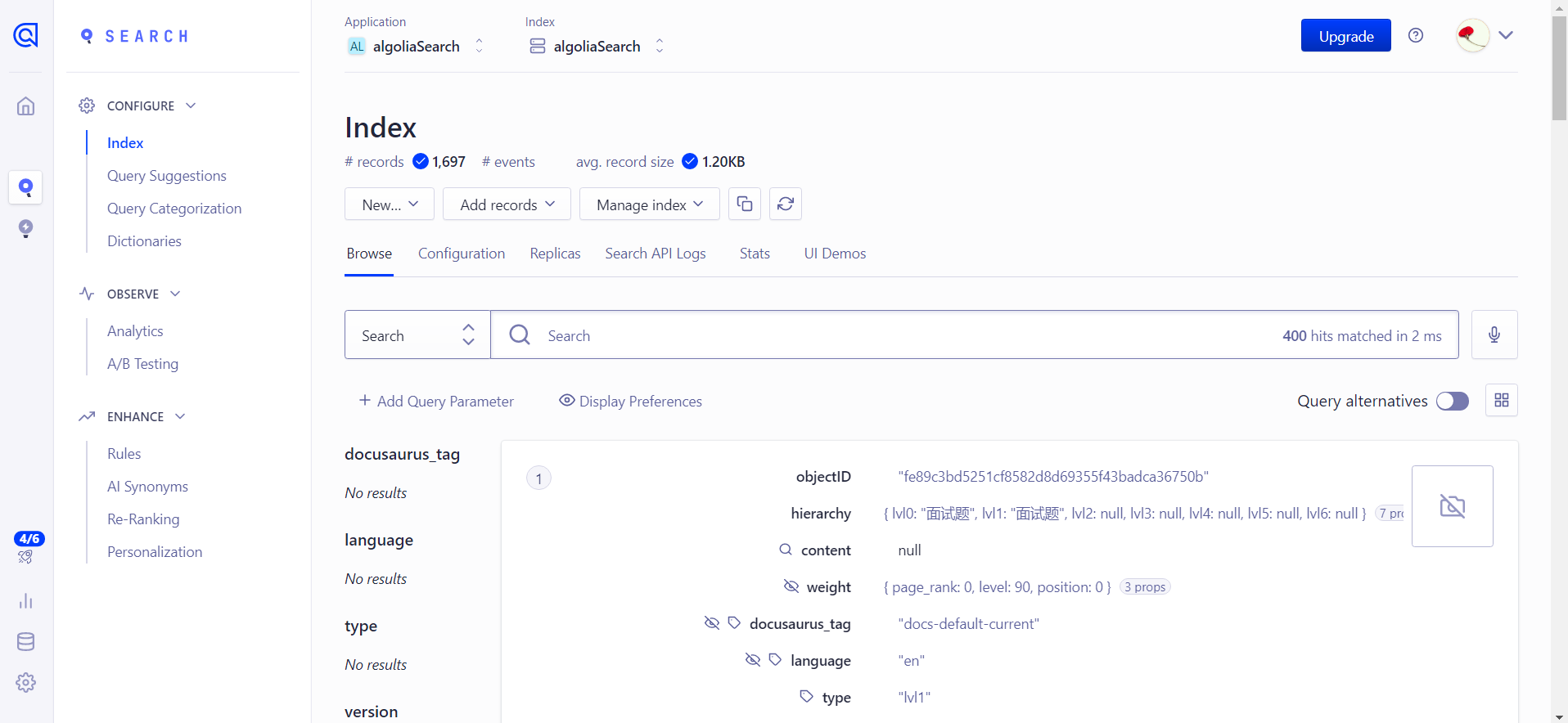
控制台打开 设置页面,点击 API keys
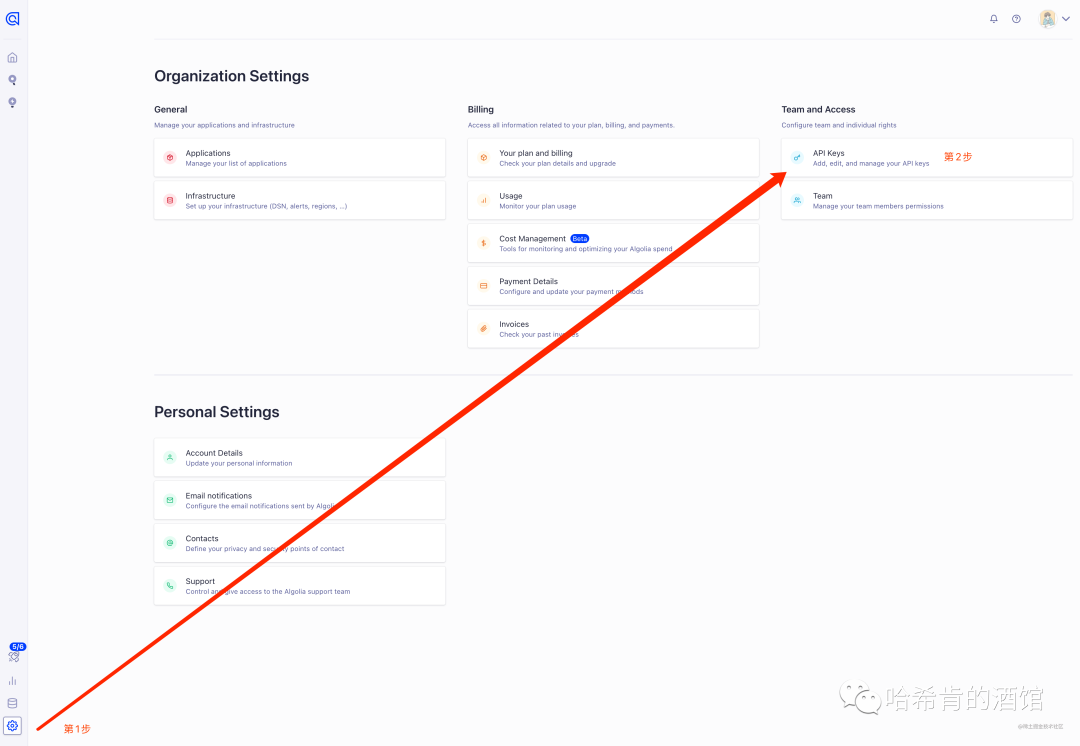
找到 接下来本地配置需要的数据
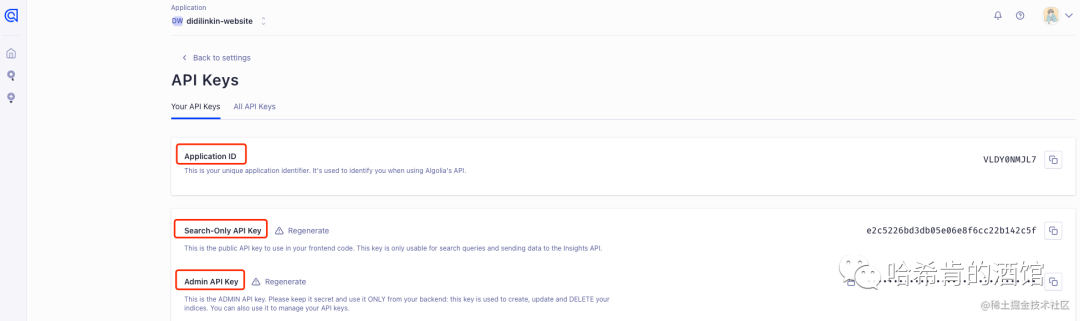
这里记录好需要用到的数据。
3、Docusaurus 项目中配置 algolia
Docusaurus 官方已经支持了 algolia 搜索,直接去 docusaurus.config.js 文件配置即可:
来到自己Docusaurus项目仓库,配置docusaurus.config.js文件:
themeConfig: {// ...algolia: {apiKey: "Admin API Key",indexName: "刚才创建索引的 name,不是数据源的 name",appId: "Application ID",},
}
algolia: {apiKey: "0b438cb1xxxxx84d79ff",indexName: "algoliaSearch",appId: "0Rxxxxxxxx4U",},
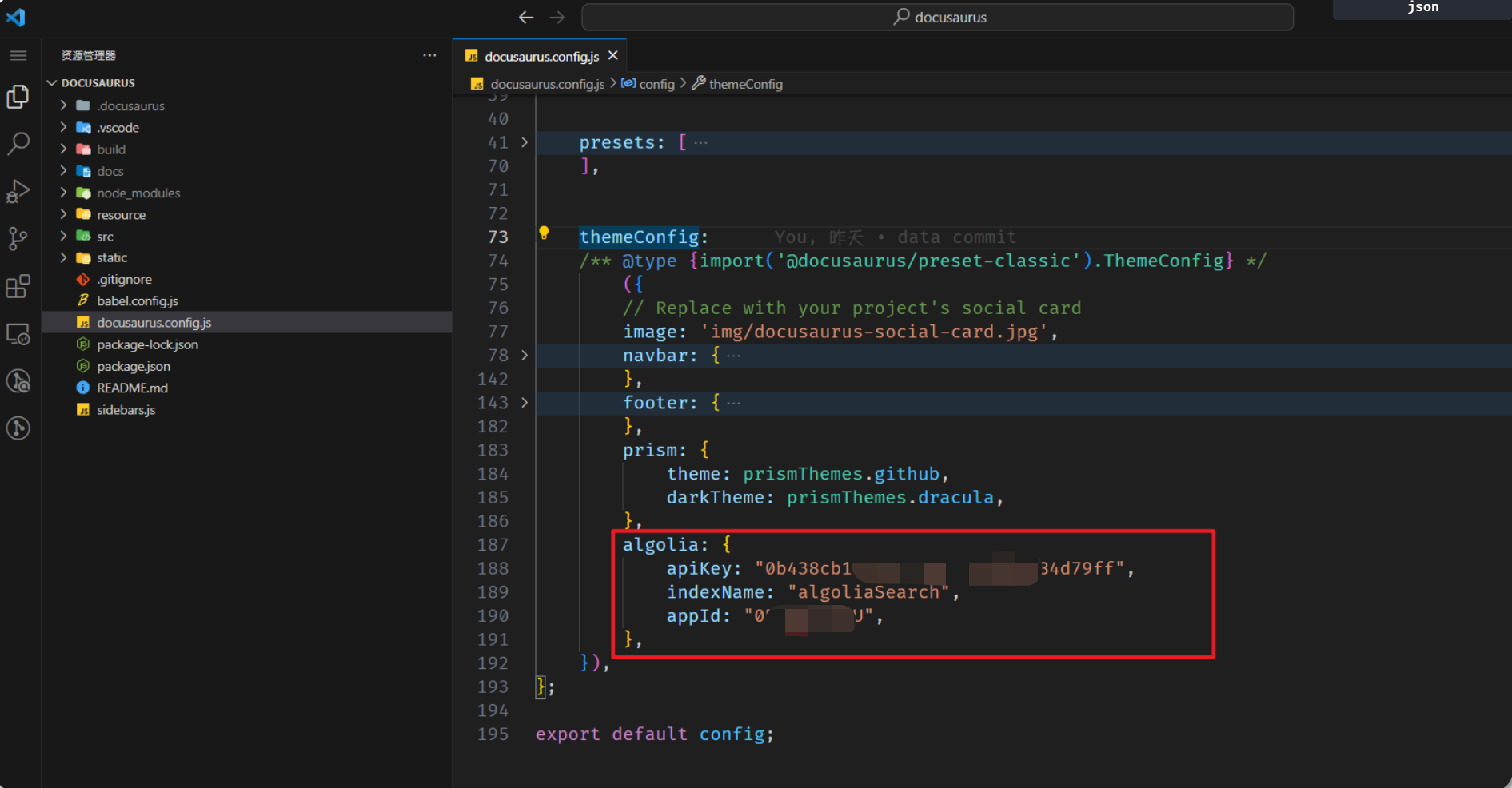
如果是用其他搭建的比如 Hexo,VuePress/ VitePres,也类似,在对应在 config 文件配置就好。
上面 apiKey、appId 可以在 API Keys 里面查看:
运行项目,就可以看到出现搜索功能,这时候还不能用,因为 algolia 还没有爬取自己网站的内容。
提交docusaurus本地数据到服务器端。
4、执行爬虫程序 - docsearch-scraper
_以下两种 爬虫方式任选其一即可 (推荐使用 GitHub Actions)
_
1. Docker 爬取本地内容推送到 Algolia
自己本次选择的方式。
由于 Algolia 限制开源项目才可以免费试用爬虫,所以我们要自己推送数据。需要如下环境:
- Docker(我的是 mac ,下载安装即可)
- jq(
brew install jq)—— 解析 json 文件用
yum install -y epel-release
yum install -y jq
爬取环境创建后,完成以下步骤
创建如下2个配置文件
(1)创建 .env 文件存放环境变量
.env
ALGOLIA_APP_ID=0xxxxxxU
ALGOLIA_API_KEY=a5xxxxxxxxxxxxxxx01 ## 务必确认, 这是坑点 不要用 'Write API Key' 或者 'Search API Key',一定要用Admin API Key才行。
(2)创建一个docsearch.json文件
docsearch.json
-
docsearch-config.json (爬虫配置文件)
需修改 3 处:
-
index_name
-
start_urls
-
sitemap_urls
参考文章:
{// 修改部分 修改1:"index_name": "对应上config文件里面的indexName,也是创建的索引名","start_urls": ["https://www.website.com/"], // 自己的域名网站地址 修改2:// 更换自己的域名地址,Docusaurus 官方会有配置生成 sitemap.xml 的方式 修改3:"sitemap_urls": ["https://www.website.com/sitemap.xml"],// end"stop_urls": ["/search"], // 排除不需要爬取页面的路由地址"selectors": {"lvl0": {"selector": "(//ul[contains(@class,'menu__list')]//a[contains(@class, 'menu__link menu__link--sublist menu__link--active')]/text() | //nav[contains(@class, 'navbar')]//a[contains(@class, 'navbar__link--active')]/text())[last()]","type": "xpath","global": true,"default_value": "Documentation"},"lvl1": "header h1, article h1","lvl2": "article h2","lvl3": "article h3","lvl4": "article h4","lvl5": "article h5, article td:first-child","lvl6": "article h6","text": "article p, article li, article td:last-child"},"custom_settings": {"attributesForFaceting": ["type","lang","language","version","docusaurus_tag"],"attributesToRetrieve": ["hierarchy","content","anchor","url","url_without_anchor","type"],"attributesToHighlight": ["hierarchy", "content"],"attributesToSnippet": ["content:10"],"camelCaseAttributes": ["hierarchy", "content"],"searchableAttributes": ["unordered(hierarchy.lvl0)","unordered(hierarchy.lvl1)","unordered(hierarchy.lvl2)","unordered(hierarchy.lvl3)","unordered(hierarchy.lvl4)","unordered(hierarchy.lvl5)","unordered(hierarchy.lvl6)","content"],"distinct": true,"attributeForDistinct": "url","customRanking": ["desc(weight.pageRank)","desc(weight.level)","asc(weight.position)"],"ranking": ["words","filters","typo","attribute","proximity","exact","custom"],"highlightPreTag": "<span class='algolia-docsearch-suggestion--highlight'>","highlightPostTag": "</span>","minWordSizefor1Typo": 3,"minWordSizefor2Typos": 7,"allowTyposOnNumericTokens": false,"minProximity": 1,"ignorePlurals": true,"advancedSyntax": true,"attributeCriteriaComputedByMinProximity": true,"removeWordsIfNoResults": "allOptional","separatorsToIndex": "_","synonyms": [["js", "javascript"],["ts", "typescript"]]}
}
自己本次最终版:
{"index_name": "algoliaSearch","start_urls": ["https://www.onedayxyy.cn/"], "sitemap_urls": ["https://www.onedayxyy.cn/sitemap.xml"],"stop_urls": ["/search"], "selectors": {"lvl0": {"selector": "(//ul[contains(@class,'menu__list')]//a[contains(@class, 'menu__link menu__link--sublist menu__link--active')]/text() | //nav[contains(@class, 'navbar')]//a[contains(@class, 'navbar__link--active')]/text())[last()]","type": "xpath","global": true,"default_value": "Documentation"},"lvl1": "header h1, article h1","lvl2": "article h2","lvl3": "article h3","lvl4": "article h4","lvl5": "article h5, article td:first-child","lvl6": "article h6","text": "article p, article li, article td:last-child"},"custom_settings": {"attributesForFaceting": ["type","lang","language","version","docusaurus_tag"],"attributesToRetrieve": ["hierarchy","content","anchor","url","url_without_anchor","type"],"attributesToHighlight": ["hierarchy", "content"],"attributesToSnippet": ["content:10"],"camelCaseAttributes": ["hierarchy", "content"],"searchableAttributes": ["unordered(hierarchy.lvl0)","unordered(hierarchy.lvl1)","unordered(hierarchy.lvl2)","unordered(hierarchy.lvl3)","unordered(hierarchy.lvl4)","unordered(hierarchy.lvl5)","unordered(hierarchy.lvl6)","content"],"distinct": true,"attributeForDistinct": "url","customRanking": ["desc(weight.pageRank)","desc(weight.level)","asc(weight.position)"],"ranking": ["words","filters","typo","attribute","proximity","exact","custom"],"highlightPreTag": "<span class='algolia-docsearch-suggestion--highlight'>","highlightPostTag": "</span>","minWordSizefor1Typo": 3,"minWordSizefor2Typos": 7,"allowTyposOnNumericTokens": false,"minProximity": 1,"ignorePlurals": true,"advancedSyntax": true,"attributeCriteriaComputedByMinProximity": true,"removeWordsIfNoResults": "allOptional","separatorsToIndex": "_","synonyms": [["js", "javascript"],["ts", "typescript"]]}
}
- jq 安装完成后, 在命令行执行 爬虫脚本
控制台执行 docker 爬去推送命令:
docker run -it --env-file=.env -e "CONFIG=$(cat docsearch.json | jq -r tostring)" algolia/docsearch-scraper
- 等待 容器运行完成, 如下即可
接下来就是等待阶段,这里需要点时间 download docker 内置的东西。
最后控制台出现:
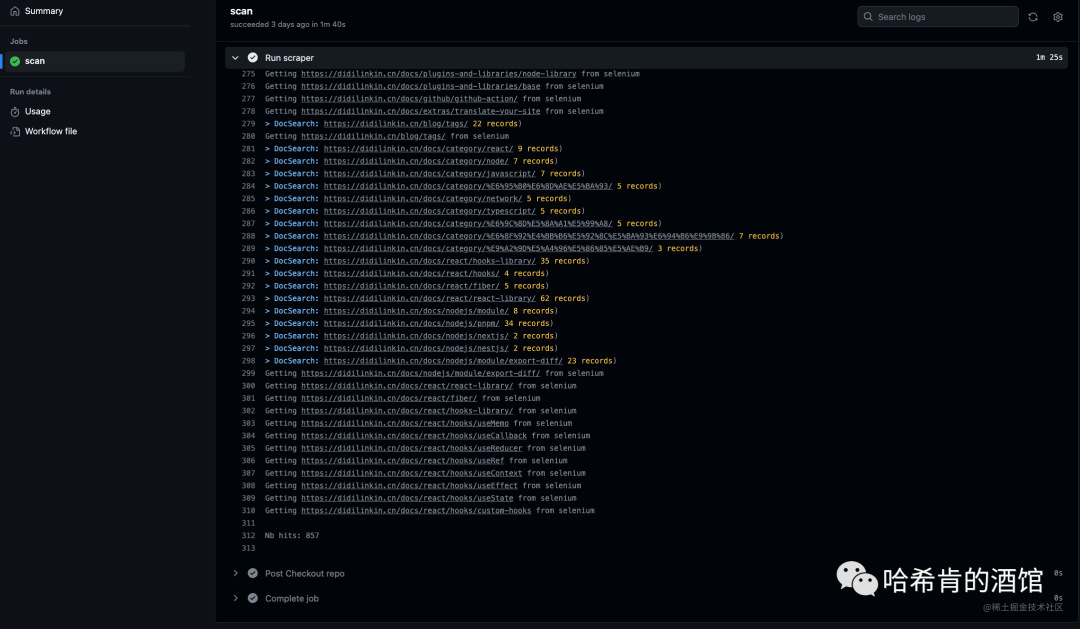
...
Getting https://didilinkin.cn/docs/react/hooks/custom-hooks from selenium
Getting https://didilinkin.cn/docs/react/hooks/useMemo from selenium
Getting https://didilinkin.cn/docs/react/hooks/useCallback from selenium
Getting https://didilinkin.cn/docs/javascript/versions/es-2016 from selenium
Getting https://didilinkin.cn/docs/javascript/versions/es-2015 from selenium
> DocSearch: https://didilinkin.cn/docs/plugins-and-libraries/big-screen/ 17 records)
> DocSearch: https://didilinkin.cn/docs/server/nginx/nginx-forward-proxy-vs-reverse-proxy/ 8 records)
> DocSearch: https://didilinkin.cn/docs/category/caddy/ 3 records)
> DocSearch: https://didilinkin.cn/docs/category/nginx/ 5 records)Nb hits: 1369自己执行后效果:
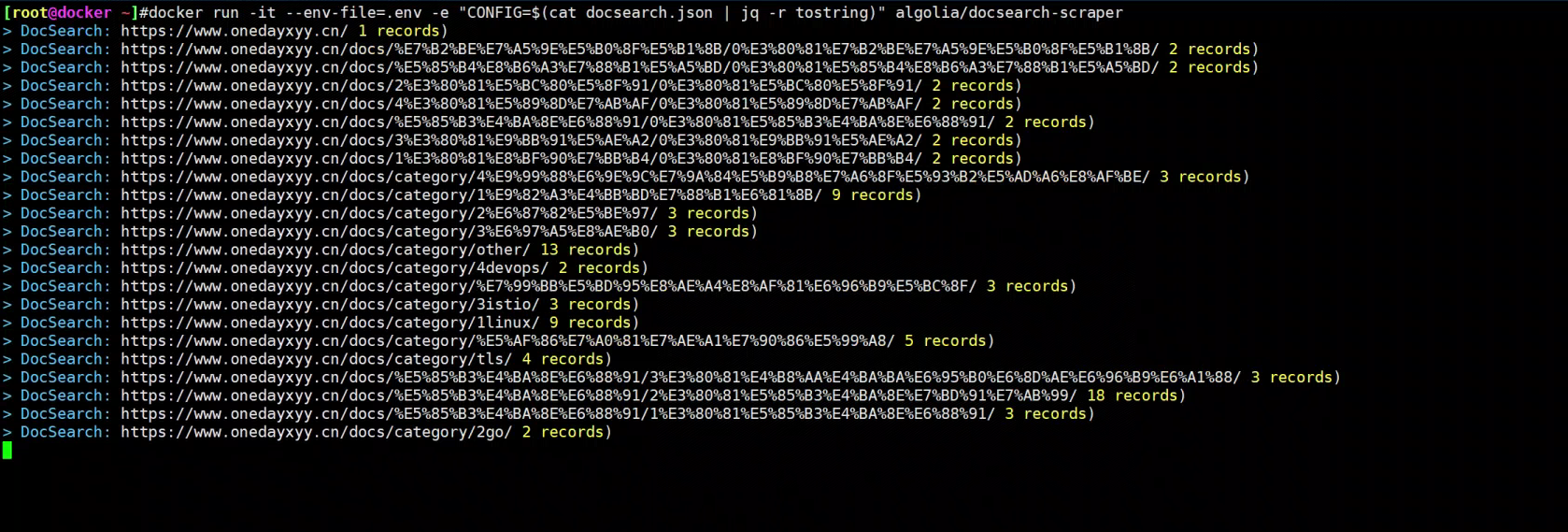
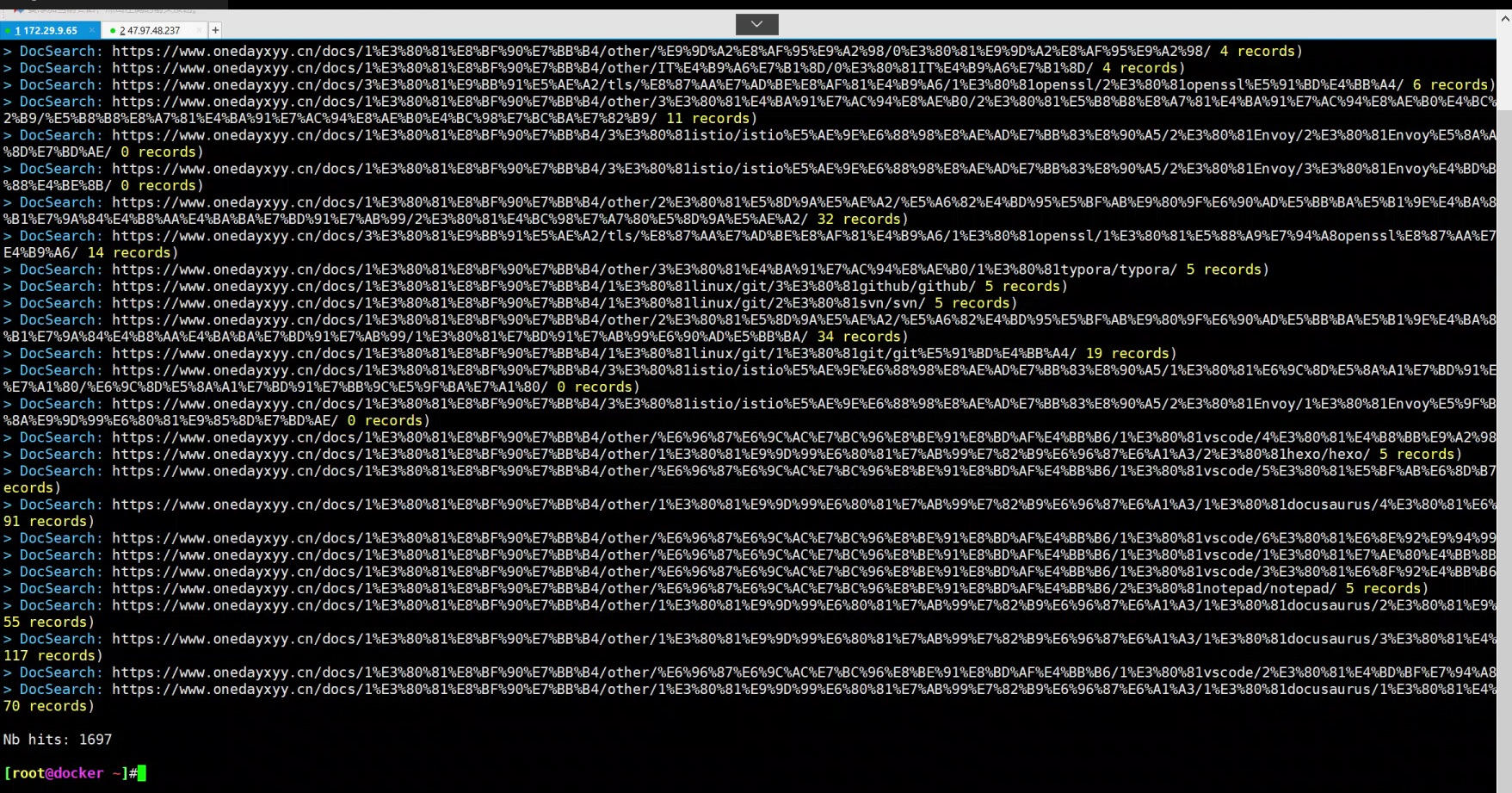
到自己的algolia账户下看下数据情况:
2. GitHub Actions 执行爬虫
仅做记录,待测试。
v1参考:
在 .github/workflows/ 文件夹下 创建 docsearch-scraper.yml, 用来定义 GitHub Actions 工作流
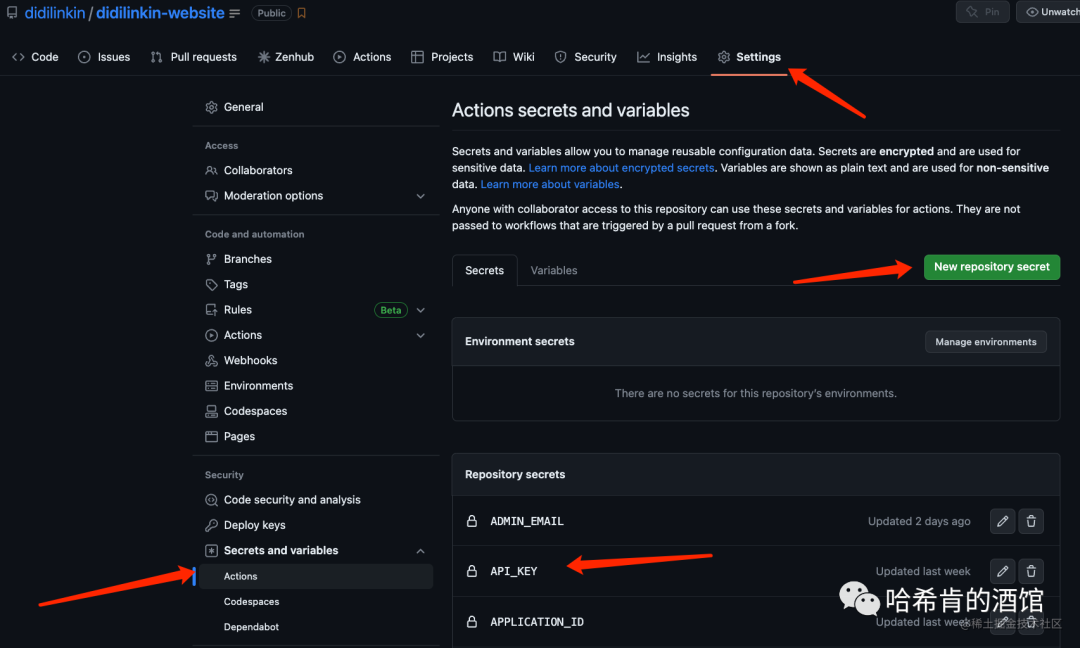
name: 索引爬虫 docsearch-scraperon:push:branches: [master]pull_request:branches: [master]jobs:scan:runs-on: ubuntu-lateststeps:- name: Sleep for 10 secondsrun: sleep 10sshell: bash- name: Checkout repouses: actions/checkout@v3- name: Run scraperenv:APPLICATION_ID: ${{ secrets.APPLICATION_ID }}API_KEY: ${{ secrets.API_KEY }}run: |CONFIG="$(cat docsearch-config.json)"docker run -i --rm \-e APPLICATION_ID=$APPLICATION_ID \-e API_KEY=$API_KEY \-e CONFIG="${CONFIG}" \algolia/docsearch-scraper然后在 GitHub 的 Secrets 创建
-
APPLICATION_ID
-
API_KEY — Admin API Key
当使用 Git 推送项目到 GitHub 时, Actions 就会自动执行 爬虫任务
v2 参考
可以利用 github 的 Action 帮我们跑这个阶段的内容,这个还是比较方便的。
项目根目录创建 .github/workflows/docsearch.yml 文件
内容:
name: docsearch
on: push: branches: - masterjobs: algolia: runs-on: ubuntu-latest steps: - uses: actions/checkout@v2- name: Get the content of docsearch.json as config id: algolia_config run: echo "::set-output name=config::$(cat docsearch.json | jq -r tostring)"- name: Run algolia/docsearch-scraper image env: ALGOLIA_APP_ID: ${{ secrets.ALGOLIA_APP_ID }} ALGOLIA_API_KEY: ${{ secrets.ALGOLIA_API_KEY }} CONFIG: ${{ steps.algolia_config.outputs.config }} run: | docker run \ --env APPLICATION_ID=${ALGOLIA_APP_ID} \ --env API_KEY=${ALGOLIA_API_KEY} \ --env "CONFIG=${CONFIG}" \ algolia/docsearch-scraper
Copy
这里说一下设置 github action 触发的条件
- 这个是 push 到 master 分支时触发。
on: push: branches: - master
Copy
- 发布成功后触发
on: deployment
Copy
- 定时触发
on: schedule: # 约每天早上8点触发(UTC时间0点) - cron: "0 0 * * *"
Copy
- 手动触发
on: workflow_dispatch:
Copy
⚠️ 注意:
需要注意的是:免费的创建的 algolia 限制文件 records 1000,如果超过的话,Github Action 会跑失败,所以也就是爬取推送不成功。导致搜索用不了。暂时还不知道怎么解决,所以我都是本地用 docker 的。
5、测试
可以看到,此时自己博客网站和本地测试DOI可以正常使用网站搜索功能的:(完美😘)
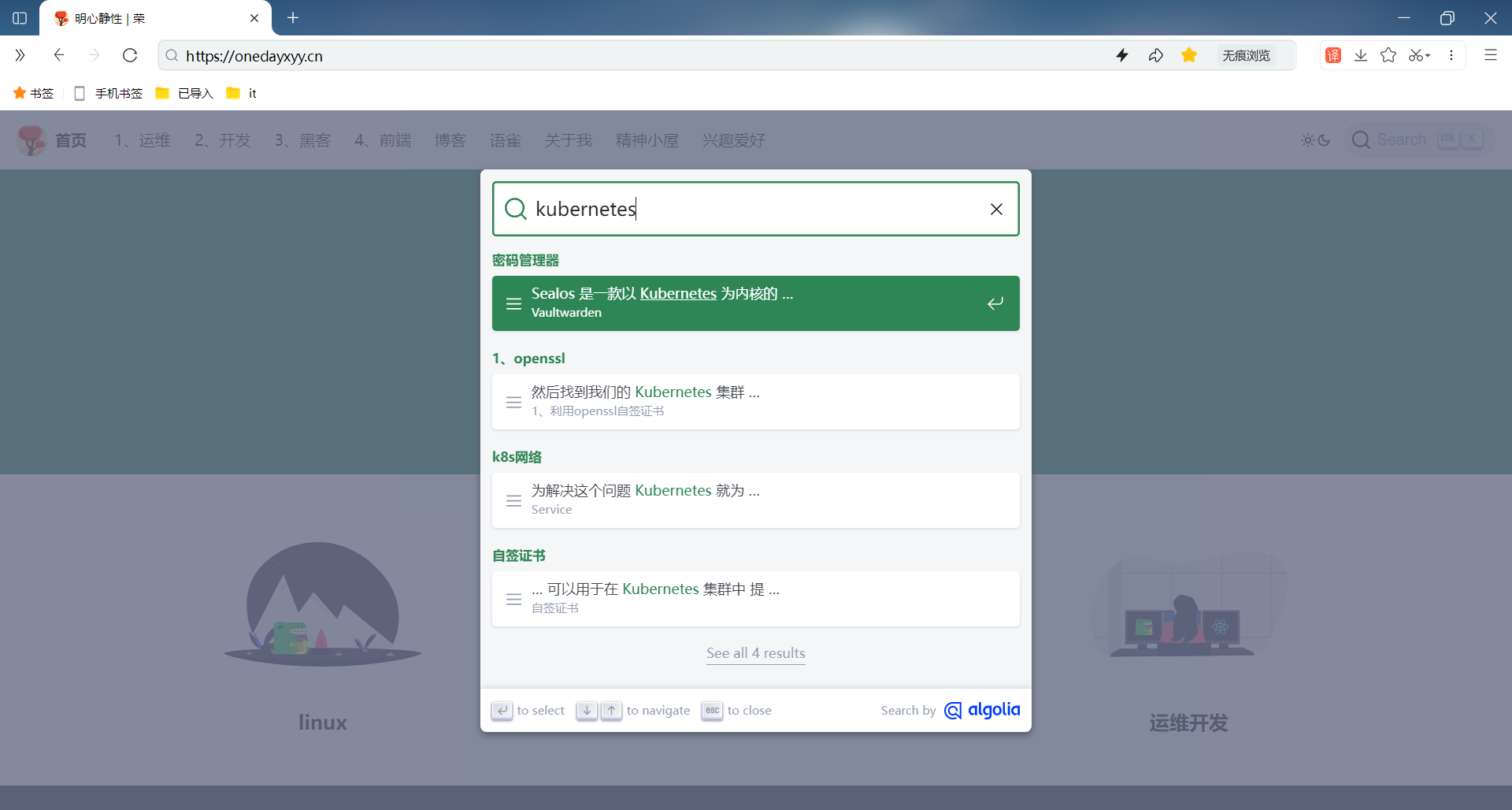
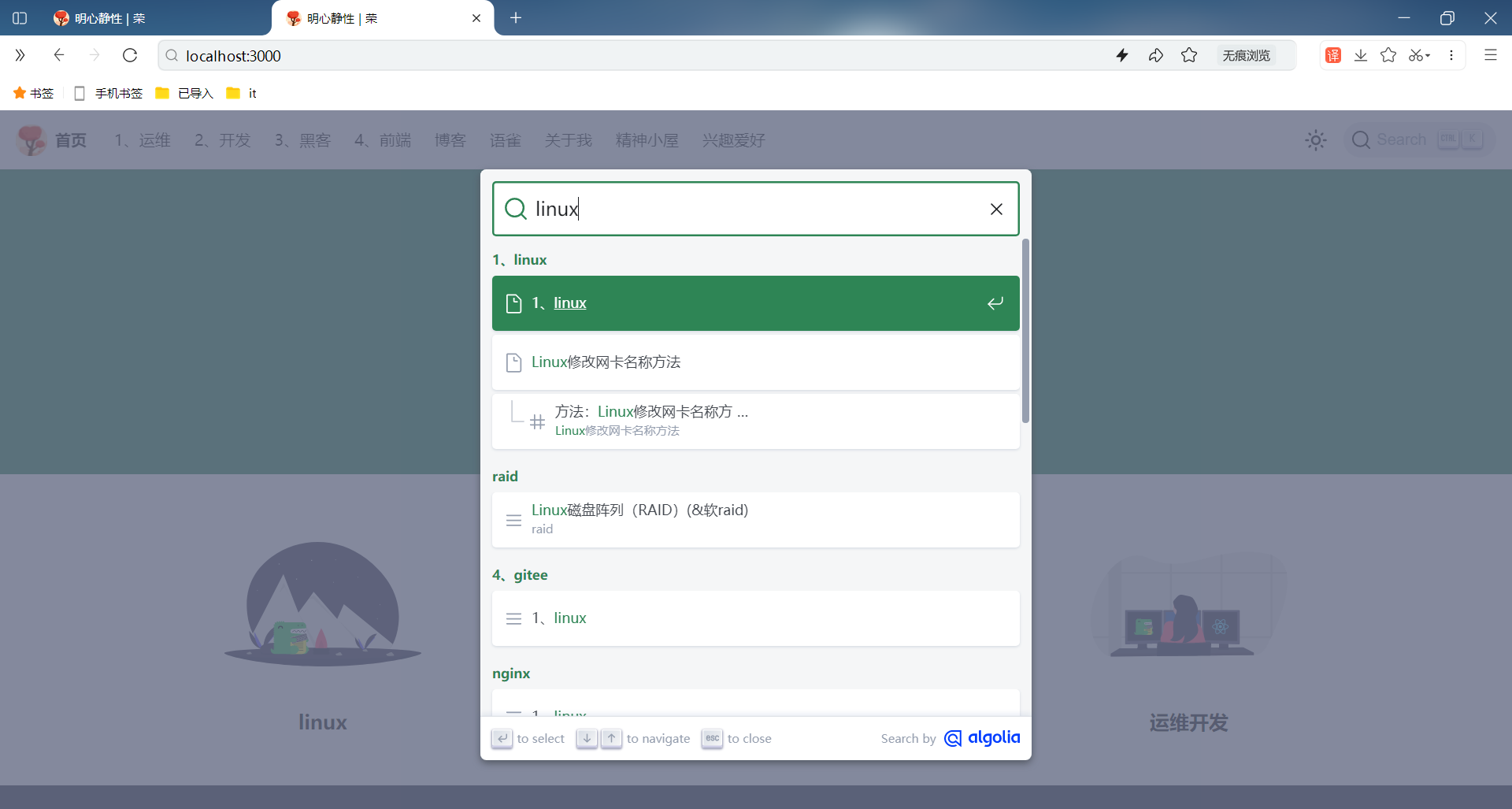
FAQ
官网其他搜索方案
https://www.docusaurus.cn/docs/search
参考链接
- 参考:别人docusarurus文章
自己本次主要参照的是这个文档,点赞作者。😘
https://ihoneys.github.io/docusaurus-algolia/
- 参考:知乎文章
https://zhuanlan.zhihu.com/p/625637978
微信文章地址:
https://mp.weixin.qq.com/s/PJZZ6fAqk_YguNmusvJ1Rg
- 参考
https://z.itpub.net/article/detail/DFA6C88B509015692FFBB1C4046EBC02
常见问题
🍀 这个问题自己遇到了,最后换成Admin API Key就能正常工作了。
-
algoliasearch.exceptions.RequestException: Method not allowed with this API key
这个错误通常表示您在使用 Algolia Search API 时使用了无效的 API 密钥或 API 密钥权限不允许使用该请求方法
-
分析: 使用的 key 不对 - 当前使用的也许是
Search-Only API Key -
解决方法: 改为使用
Admin API Key -
Error: Process completed with exit code 3.
由于尝试使用 Algolia Search API 更新对象时所使用的 API 密钥缺少必要的权限
确认您正在使用具有正确权限的 Algolia Search API 密钥来更新对象
-
分析: 使用的 key 权限不对 - 当前使用的也许是
Write API Key -
解决方法: 改为使用
Admin API Key
🍀
-
本地执行 爬虫脚本, 报错: Error: Cannot find module ‘winston’
使用 yarn 重新安装 winston
yarn global remove winstonyarn global add winston
🍀
- 本地执行 爬虫脚本, 报错:
Error: {cli} was removed in winston@3.0.0.
# 查看本地的 全局依赖是否存在 jqyarn global list --depth=0# 删除 jq依赖yarn global remove jq
- 本地执行 爬虫脚本, 报错: zsh: command not found: jq
确保本地 npm, yarn, pnpm 的全局依赖中没有 jq, 使用 brew 安装
# 安装最新版 jq
brew install --HEAD jq# 链接 最新版 jq
brew link jq
关于我
我的博客主旨:
- 排版美观,语言精炼;
- 文档即手册,步骤明细,拒绝埋坑,提供源码;
- 本人实战文档都是亲测成功的,各位小伙伴在实际操作过程中如有什么疑问,可随时联系本人帮您解决问题,让我们一起进步!
🍀 微信二维码
x2675263825 (舍得), qq:2675263825。

🍀 微信公众号
《云原生架构师实战》

🍀 个人博客站点
http://onedayxyy.cn/
🍀 语雀
https://www.yuque.com/xyy-onlyone
🍀 csdn
https://blog.csdn.net/weixin_39246554?spm=1010.2135.3001.5421
🍀 知乎
https://www.zhihu.com/people/foryouone
最后
好了,关于本次就到这里了,感谢大家阅读,最后祝大家生活快乐,每天都过的有意义哦,我们下期见!

相关文章:
实战:给docusaurus文档网站配置Algolia 实现全站内容搜索功能-2023.11.16(已解决)
更新于:2023年11月16日 次文档已全部脱敏! 实战:给docusaurus文档网站配置Algolia 实现全站内容搜索功能-2023.11.16(已解决) 目录 前提条件 🍀 前提条件 具备docker环境 具有自己的网站 🍀 实验软件(…...
Ubuntu18.04安装ROS系统+turtle测试
安装 1.设置安装源 sudo sh -c echo "deb http://packages.ros.org/ros/ubuntu $(lsb_release -sc) main" > /etc/apt/sources.list.d/ros-latest.list sudo sh -c . /etc/lsb-release && echo "deb http://mirrors.tuna.tsinghua.edu.cn/ros/ubun…...

UE基础篇五:动画
导语: 视频文档在文末 一、动画 1.1 物理资产可以用来做布娃娃系统 1.2 混合空间 调整这个值会在动画切换时有一个插值时间,表现为等一下再切 1.3 启用根运动 1.4 一些导入设置只有在导入时才有效, 1.5 动画图标可以预览调节数值<...
)
SELinux零知识学习十二、SELinux策略语言之客体类别和许可(6)
接前一篇文章:SELinux零知识学习十一、SELinux策略语言之客体类别和许可(5) 一、SELinux策略语言之客体类别和许可 3. 有效的客体类别 (3)System V IPC客体队列 与IPC有关的客体类别代表System V IPC资源。下表总结…...

vscode的git 工具使用
vscode的git 工具使用 目录概述需求: 设计思路实现思路分析1.git 工具的使用2.提交代码3.查看历史提交代码 参考资料和推荐阅读 Survive by day and develop by night. talk for import biz , show your perfect code,full busy,skip hardness,make a be…...
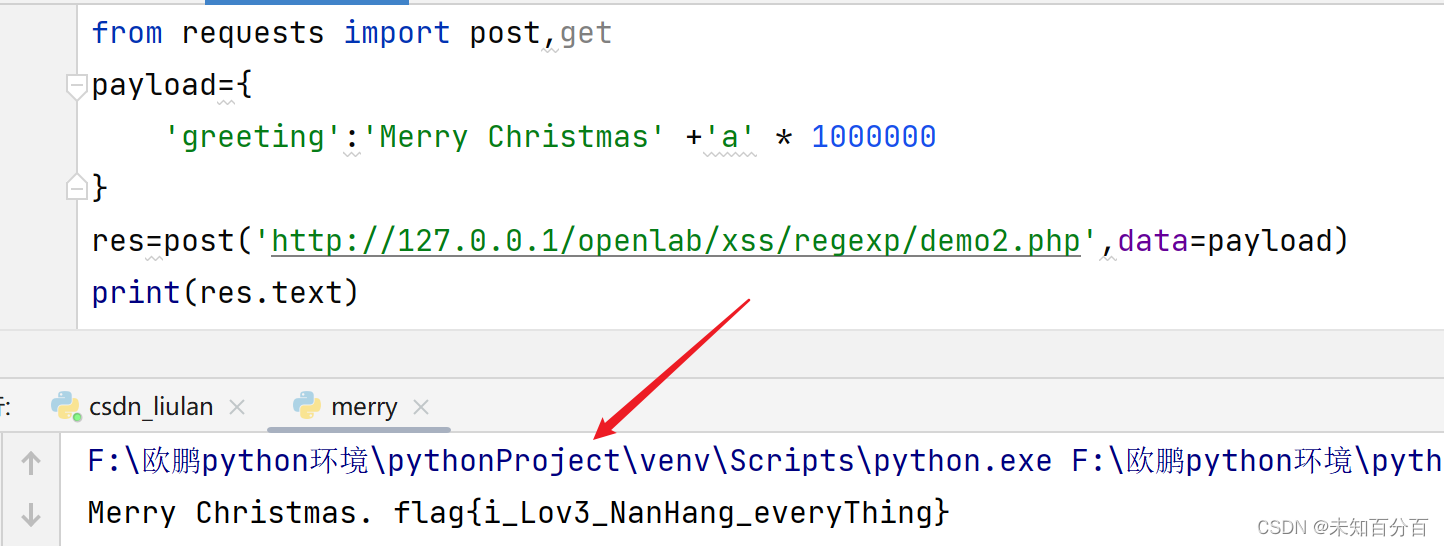
利用回溯绕过正则表达式
目录 利用strpos的特性拿到flag 利用回溯绕过正则表达式 利用回溯次数绕过正则表达式并且实现文件上传 使用回溯绕过正则表达式waf拿到flag 本篇会讲解三个实验来分别绕过正则表达式,python的正则表达式和Javascript的正则表达式大致相同如果有正则表达式不太懂…...

Flutter执行flutter doctor报错HTTP Host Availability
问题描述 [!] HTTP Host Availability✗ HTTP host https://maven.google.com/ is not reachable. Reason: An erroroccurred while checking the HTTP host: Operation timed out解决方案 将文件flutter/packages/flutter_tools/lib/src/http_host_validator.dart中的https:…...
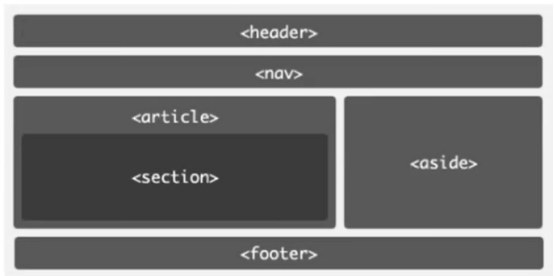
全栈工程师必须要掌握的前端Html技能
作为一名全栈工程师,在日常的工作中,可能更侧重于后端开发,如:C#,Java,SQL ,Python等,对前端的知识则不太精通。在一些比较完善的公司或者项目中,一般会搭配前端工程师&a…...
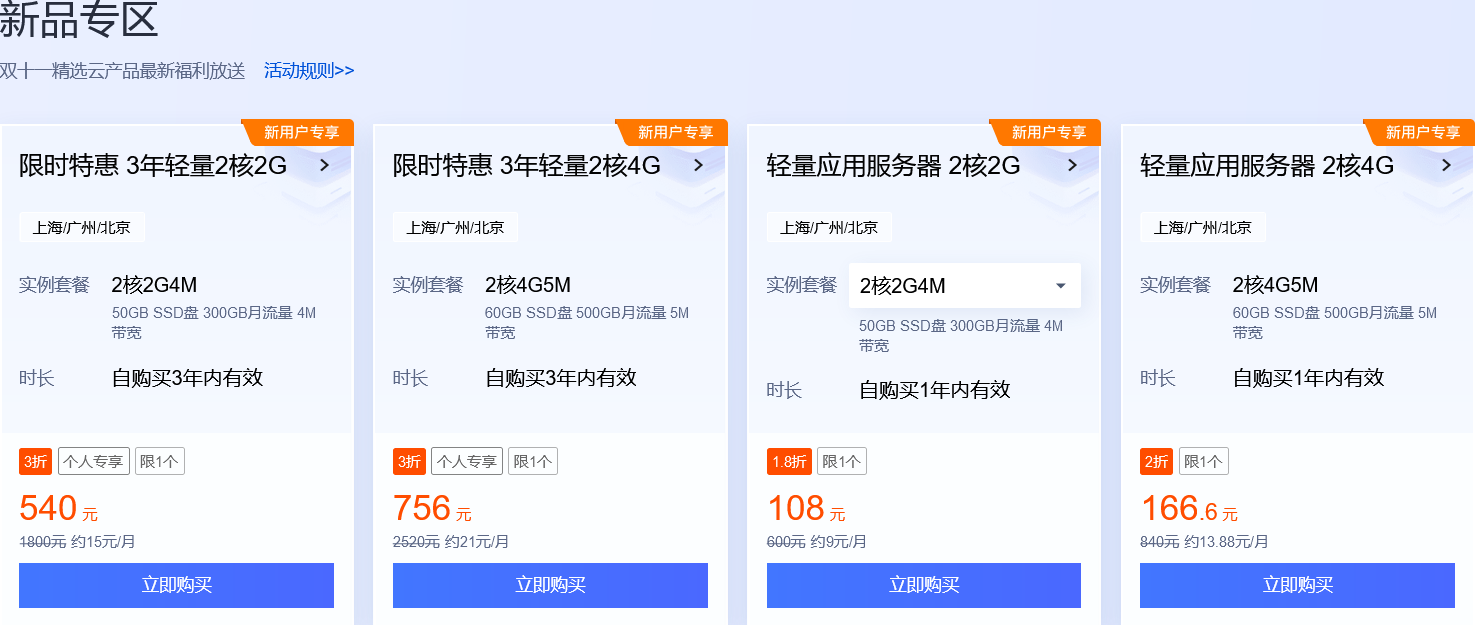
腾讯云服务器租用价格,腾讯云服务器租用价格多少钱一年?
腾讯云服务器租用价格,腾讯云服务器租用价格多少钱一年?腾讯云服务器有优惠活动,现在租用只需要88元/年!腾讯云服务器优惠购买入口:https://1111.mian100.cn 随着互联网的发展,越来越多的人开始选择将自己…...

QTableWidget 设置列宽行高大小的几种方式及其他常用属性设置
目录 效果: 1.列宽、行高自动分配 2.固定值 3.随内容分配列宽 随内容分配行高 4.水平方向标签拓展剩下的窗口部分,填满表格 5.列宽是自动分配的,但是第一列可手动调整宽度,而表格整体的列宽仍是自动分配的。第二、三列办法调…...

【AI视野·今日CV 计算机视觉论文速览 第277期】Fri, 27 Oct 2023
AI视野今日CS.CV 计算机视觉论文速览 Fri, 27 Oct 2023 Totally 93 papers 👉上期速览✈更多精彩请移步主页 Daily Computer Vision Papers A Coarse-to-Fine Pseudo-Labeling (C2FPL) Framework for Unsupervised Video Anomaly Detection Authors Anas Al lahham…...

【教3妹学编程-算法题】购买物品的最大开销
3妹:2哥,听说你今天发工资啦? 请我吃饭怎么样,嘿嘿 2哥 : 切,你上周还发工资了呢,也没见你请我吃饭。 3妹:哎呀, 我的工资都用来双11 shopping了, 双11过后我都吃了1周土…...

关于pandas dataframe数据转换为JSON格式存储在Redis后,读取数据时发生数据篡改的问题以及解决办法
问题:当时处理股票数据,获取到以dataframe数据结构的股票,由于Redis 是一个内存中的数据结构存储系统,但是不接受dataframe数据结构的数据,选择将其先转化为JSON格式,但发现再将JSON格式转化为原数据时&…...

Go 语言编译环境
1. 请简要介绍一下Go语言的特点。 Go语言是一种静态类型、编译型语言,由Google开发。它的主要特点包括: 简洁高效:Go语言的语法非常简洁,易于学习和使用。同时,Go语言的执行效率高,适合开发高性能的后端服…...
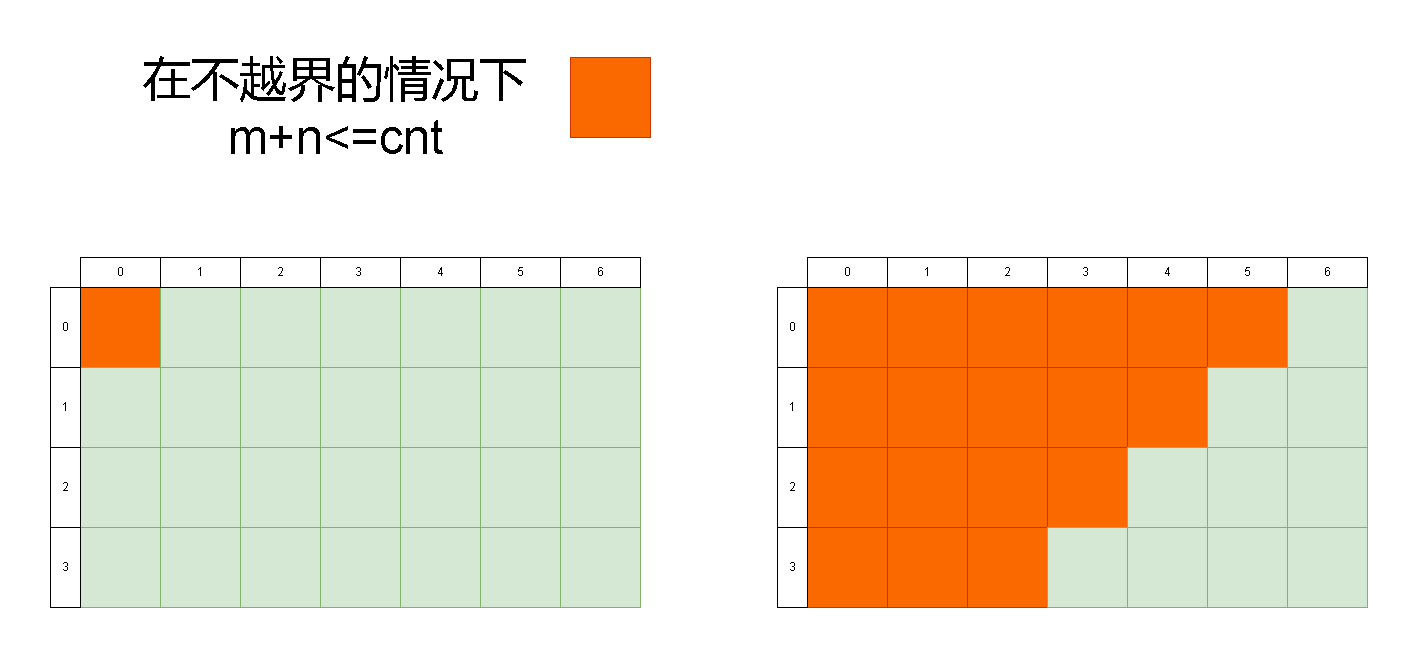
Leetcode刷题详解——衣橱整理
1. 题目链接:LCR 130. 衣橱整理 2. 题目描述: 家居整理师将待整理衣橱划分为 m x n 的二维矩阵 grid,其中 grid[i][j] 代表一个需要整理的格子。整理师自 grid[0][0] 开始 逐行逐列 地整理每个格子。 整理规则为:在整理过程中&am…...

短视频ai剪辑分发账号矩阵系统(招商oem)----源头技术开发
短视频ai剪辑分发账号矩阵系统 1. 视频剪辑工具——原创短视频一键生成,视频剪辑亮点分析 (1)多模式智能剪辑 包含智能混剪逻辑、智能组合、场景顺序、图片生成视频等多种模式。在视频创作上也做了简化,即使是没有剪辑能力的创…...

Ubuntu18.04安装Loam保姆级教程
系统环境:Ubuntu18.04.6 LTS 1.Loam的安装前要求: 1.1 ROS安装:参考我的另一篇博客 Ubuntu18.04安装ROS-melodic保姆级教程_灬杨三岁灬的博客-CSDN博客还是那句话,有时候加了这行也不好使,我是疯狂试了20次…...
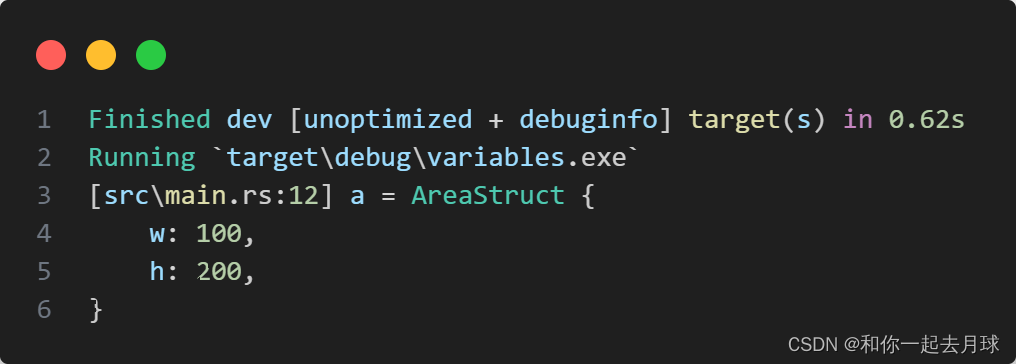
Rust 语言中的结构体
目录 1、结构体 2、结构体的定义和实例化 2.1 使用字段初始化简写语法 2.2 使用结构体更新语法从其他实例创建实例 2.3 没有命名字段的元组结构体 2.4 没有任何字段的类单元结构体 2.5 结构体示例程序 3、方法 3.1 关联函数 3.2 多个 impl 块 1、结构体 struct&…...
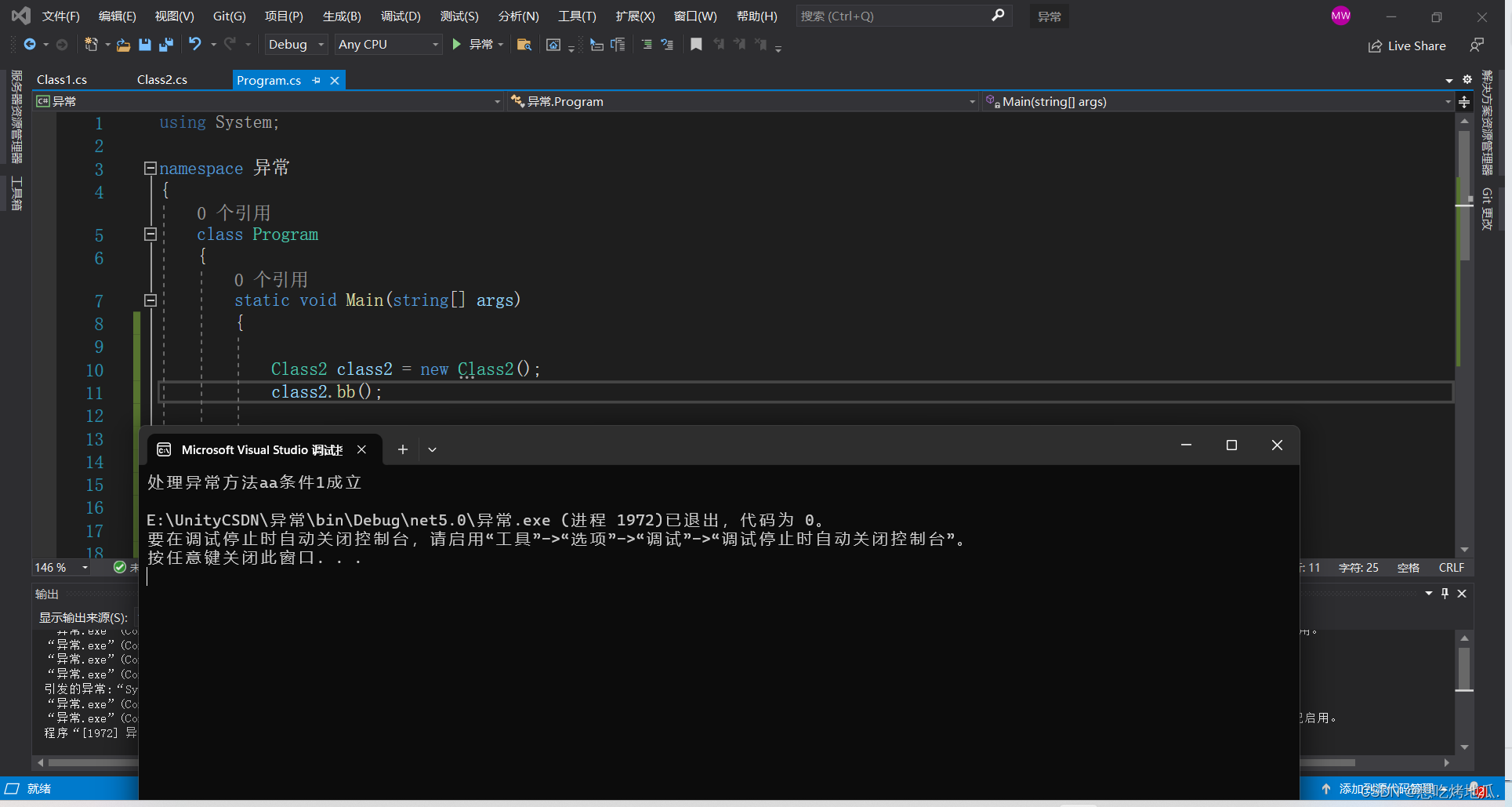
Unity开发之C#基础-异常处理(Try Catch)
前言 其实本来这章应该将栈和队列的 但是后来想想 栈和队列在实际应用很少跟多的是大家了解一下栈和队列的基本常识比如先进先出的是谁后进先出的是谁这种 csdn有很多介绍栈和队列的文章 我觉得都比我理解深刻所以大家可以去搜索参照一下 今天我们继续往下讲解 如何自己主动的…...

Epoxy:跨不同数据存储的 ACID 事务
Epoxy 利用 Postgres 事务数据库作为主数据库/协调数据库,并扩展多版本并发控制 (MVCC) 以实现跨数据存储隔离。它通过乐观并发控制 (OCC) 和两阶段提交 (2PC) 协议提供隔离性以及原子性和持久性。 环氧树脂被用作五种不同数据存储的接口层:Postgres, M…...

AI 安全生产管理平台:用数字技术筑牢企业安全防线
传统企业安全生产长期依赖“人工巡检、事后整改”的模式,人工排查存在疲劳漏检、响应滞后、标准不一等痛点,很难全天候守住生产安全底线。而 AI 安全生产管理平台依托人工智能、物联网、边缘计算、大数据等核心技术,彻底打破传统“人防”局限…...

KNN工程落地:从距离度量到FAISS索引的生产级实践
1. 这不是“调个sklearn参数”就能糊弄过去的事:KNN背后被严重低估的工程现实“K近邻算法(K-nearest Neighbors)”,四个字,教科书里三行公式就讲完,面试官常问“它是不是懒惰学习?有没有训练过程…...

中控考勤机MDB数据库逆向与安全审计实战
1. 为什么是中控考勤机MDB?——一个被低估的工业级数据入口你可能在工厂门禁旁、写字楼前台、甚至学校行政楼里见过那个灰黑色方盒子,屏幕不大,带个红外感应区,刷一下工卡,“滴”一声就完成打卡。它叫中控考勤机&#…...

为ClaudeCode配置Taotoken作为备用API解决访问限制
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为ClaudeCode配置Taotoken作为备用API解决访问限制 基础教程类,指导经常遇到ClaudeCode访问限制的开发者,如…...

Node.js后端服务如何集成多模型能力并管理API成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Node.js后端服务如何集成多模型能力并管理API成本 1. 场景与需求 在Node.js后端服务中集成AI对话功能,开发者通常面临…...

RAG大模型落地必杀技:解决幻觉、私有数据三大痛点,提升回答可信度!
本文深入解析了检索增强生成(RAG)技术,旨在解决大模型应用中的知识过时、幻觉和私有数据使用难题。文章详细阐述了RAG的三大核心模块——知识库、检索和生成,并系统讲解了索引、检索、生成的具体实施流程和优化策略。此外…...
)
AI Agent客服已过概念期——2024Q2行业渗透率突增至41.6%,但仅7.3%企业实现L3级自主决策闭环(附自评诊断表)
更多请点击: https://kaifayun.com 第一章:AI Agent客服已过概念期——2024Q2行业渗透率突增至41.6%,但仅7.3%企业实现L3级自主决策闭环(附自评诊断表) AI Agent客服正经历从技术验证到规模化落地的关键跃迁。据IDC联…...

利用 Taotoken 的模型广场为你的智能客服场景挑选合适模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用 Taotoken 的模型广场为你的智能客服场景挑选合适模型 构建智能客服或对话系统时,一个核心挑战是如何从众多大模型…...

网络资源嗅探与下载技术实践:res-downloader跨平台解决方案
网络资源嗅探与下载技术实践:res-downloader跨平台解决方案 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-downloader 在当今…...

企业内训系统集成Taotoken实现多模型AI助教与可控的交互成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业内训系统集成Taotoken实现多模型AI助教与可控的交互成本 对于现代企业而言,构建一个高效、智能的内训系统是提升员…...