Kafka学习笔记(三)
目录
- 第5章 Kafka监控(Kafka Eagle)
- 5.2 修改kafka启动命令
- 5.2 上传压缩包
- 5.3 解压到本地
- 5.4 进入刚才解压的目录
- 5.5 将kafka-eagle-web-1.3.7-bin.tar.gz解压至/opt/module
- 5.6 修改名称
- 5.7 给启动文件执行权限
- 5.8 修改配置文件
- 5.9 添加环境变量
- 5.10 启动
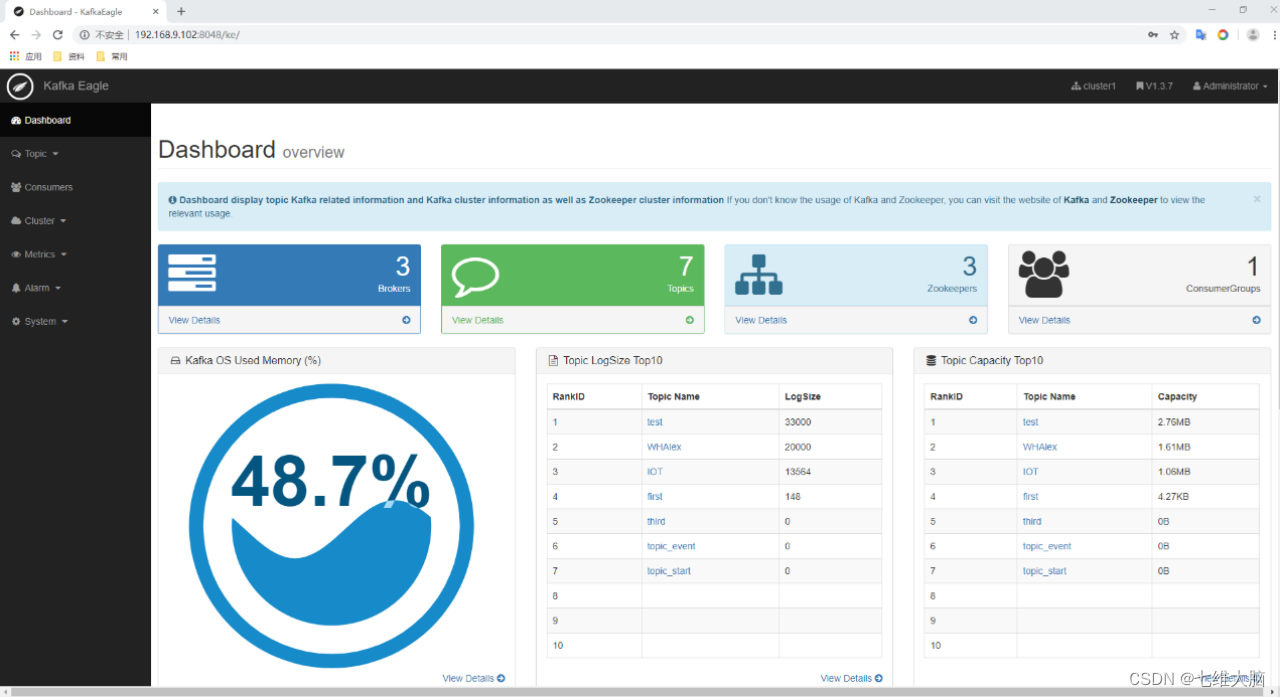
- 5.11 登录页面查看监控数据
- 第6章 Kafka面试题
- 6.1 面试问题
第5章 Kafka监控(Kafka Eagle)
5.2 修改kafka启动命令
修改kafka-server-start.sh命令中
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; thenexport KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"
fi
为
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; thenexport KAFKA_HEAP_OPTS="-server -Xms2G -Xmx2G -XX:PermSize=128m -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:ParallelGCThreads=8 -XX:ConcGCThreads=5 -XX:InitiatingHeapOccupancyPercent=70"export JMX_PORT="9999"#export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"
fi
注意:修改之后在启动Kafka之前要分发之其他节点
5.2 上传压缩包
上传压缩包kafka-eagle-bin-1.3.7.tar.gz到集群/opt/software目录
5.3 解压到本地
[atguigu@hadoop102 software]$ tar -zxvf kafka-eagle-bin-1.3.7.tar.gz
5.4 进入刚才解压的目录
[atguigu@hadoop102 kafka-eagle-bin-1.3.7]$ ll
总用量 82932
-rw-rw-r--. 1 atguigu atguigu 84920710 8月 13 23:00 kafka-eagle-web-1.3.7-bin.tar.gz
5.5 将kafka-eagle-web-1.3.7-bin.tar.gz解压至/opt/module
[atguigu@hadoop102 kafka-eagle-bin-1.3.7]$ tar -zxvf kafka-eagle-web-1.3.7-bin.tar.gz -C /opt/module/
5.6 修改名称
[atguigu@hadoop102 module]$ mv kafka-eagle-web-1.3.7/ eagle
5.7 给启动文件执行权限
[atguigu@hadoop102 eagle]$ cd bin/
[atguigu@hadoop102 bin]$ ll
总用量 12
-rw-r--r--. 1 atguigu atguigu 1848 8月 22 2017 ke.bat
-rw-r--r--. 1 atguigu atguigu 7190 7月 30 20:12 ke.sh
[atguigu@hadoop102 bin]$ chmod 777 ke.sh
5.8 修改配置文件
######################################
# multi zookeeper&kafka cluster list
######################################
kafka.eagle.zk.cluster.alias=cluster1
cluster1.zk.list=hadoop102:2181,hadoop103:2181,hadoop104:2181######################################
# kafka offset storage
######################################
cluster1.kafka.eagle.offset.storage=kafka######################################
# enable kafka metrics
######################################
kafka.eagle.metrics.charts=true
kafka.eagle.sql.fix.error=false######################################
# kafka jdbc driver address
######################################
kafka.eagle.driver=com.mysql.jdbc.Driver
kafka.eagle.url=jdbc:mysql://hadoop102:3306/ke?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull
kafka.eagle.username=root
5.9 添加环境变量
export KE_HOME=/opt/module/eagle
export PATH=$PATH:$KE_HOME/bin
注意:source /etc/profile
5.10 启动
[atguigu@hadoop102 eagle]$ bin/ke.sh start
... ...
... ...
*******************************************************************
* Kafka Eagle Service has started success.
* Welcome, Now you can visit 'http://192.168.9.102:8048/ke'
* Account:admin ,Password:123456
*******************************************************************
* <Usage> ke.sh [start|status|stop|restart|stats] </Usage>
* <Usage> https://www.kafka-eagle.org/ </Usage>
*******************************************************************
[atguigu@hadoop102 eagle]$
注意:启动之前需要先启动ZK以及KAFKA
5.11 登录页面查看监控数据
http://192.168.9.102:8048/ke
第6章 Kafka面试题
6.1 面试问题
-
Kafka中的ISR、AR又代表什么?
ISR:与leader保持同步的follower集合
AR:分区的所有副本 -
Kafka中的HW、LEO等分别代表什么?
LEO:没个副本的最后条消息的offset
HW:一个分区中所有副本最小的offset -
Kafka中是怎么体现消息顺序性的?
每个分区内,每条消息都有一个offset,故只能保证分区内有序。
-
Kafka中的分区器、序列化器、拦截器是否了解?它们之间的处理顺序是什么?
拦截器 -> 序列化器 -> 分区器
-
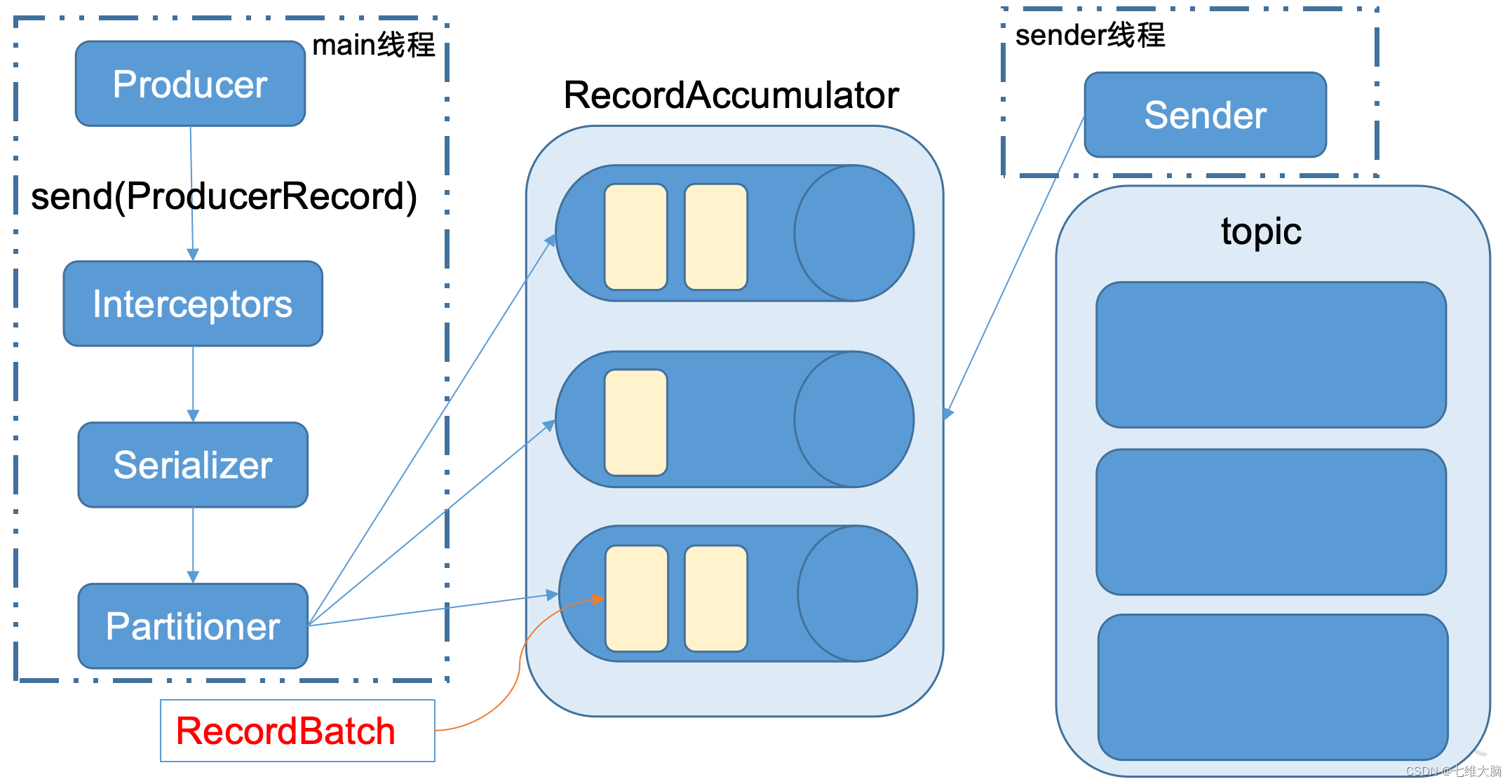
Kafka生产者客户端的整体结构是什么样子的?使用了几个线程来处理?分别是什么?
KafkaProducer 发送消息流程
-
“消费组中的消费者个数如果超过topic的分区,那么就会有消费者消费不到数据”这句话是否正确?
正确 -
消费者提交消费位移时提交的是当前消费到的最新消息的offset还是offset+1?
offset+1 -
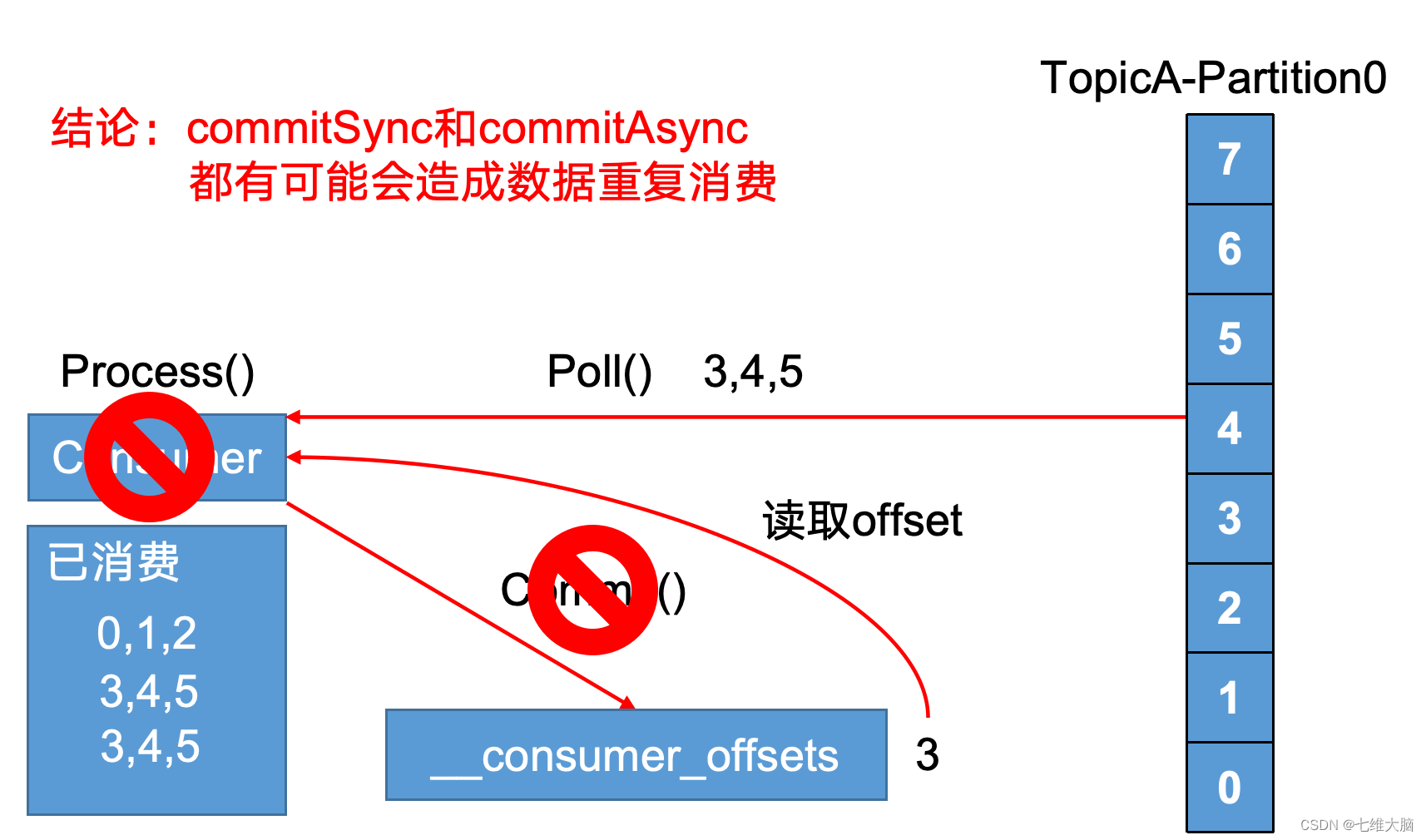
有哪些情形会造成重复消费?
-
那些情景会造成消息漏消费?
先提交offset,后消费,有可能造成数据的重复 -
当你使用kafka-topics.sh创建(删除)了一个topic之后,Kafka背后会执行什么逻辑?
- 会在zookeeper中的/brokers/topics节点下创建一个新的topic节点,如:/brokers/topics/first
- 触发Controller的监听程序
- kafka Controller 负责topic的创建工作,并更新metadata cache
-
topic的分区数可不可以增加?如果可以怎么增加?如果不可以,那又是为什么?
可以增加
bin/kafka-topics.sh --zookeeper localhost:2181/kafka --alter --topic topic-config --partitions 3 -
topic的分区数可不可以减少?如果可以怎么减少?如果不可以,那又是为什么?
不可以减少,被删除的分区数据难以处理。 -
Kafka有内部的topic吗?如果有是什么?有什么所用?
__consumer_offsets,保存消费者offset -
Kafka分区分配的概念?
一个topic多个分区,一个消费者组多个消费者,故需要将分区分配个消费者(roundrobin、range) -
简述Kafka的日志目录结构?
每个分区对应一个文件夹,文件夹的命名为topic-0,topic-1,内部为.log和.index文件 -
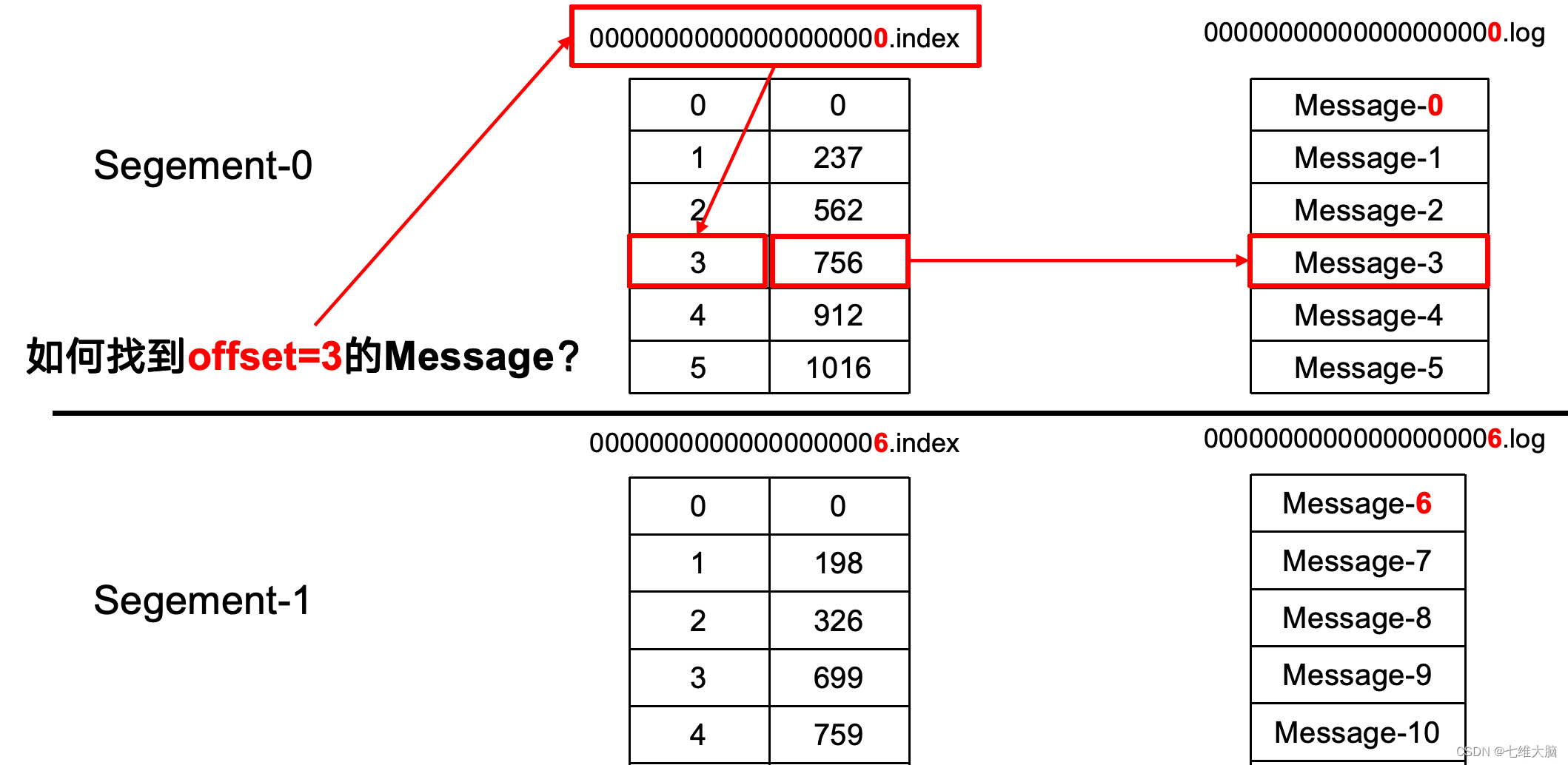
如果我指定了一个offset,Kafka Controller怎么查找到对应的消息?
-
聊一聊Kafka Controller的作用?
负责管理集群broker的上下线,所有topic的分区副本分配和leader选举等工作。 -
Kafka中有那些地方需要选举?这些地方的选举策略又有哪些?
partition leader(ISR),controller(先到先得) -
失效副本是指什么?有那些应对措施?
不能及时与leader同步,暂时踢出ISR,等其追上leader之后再重新加入 -
Kafka的那些设计让它有如此高的性能?
分区,顺序写磁盘,0-copy
相关文章:
Kafka学习笔记(三)
目录 第5章 Kafka监控(Kafka Eagle)5.2 修改kafka启动命令5.2 上传压缩包5.3 解压到本地5.4 进入刚才解压的目录5.5 将kafka-eagle-web-1.3.7-bin.tar.gz解压至/opt/module5.6 修改名称5.7 给启动文件执行权限5.8 修改配置文件5.9 添加环境变量5.10 启动…...
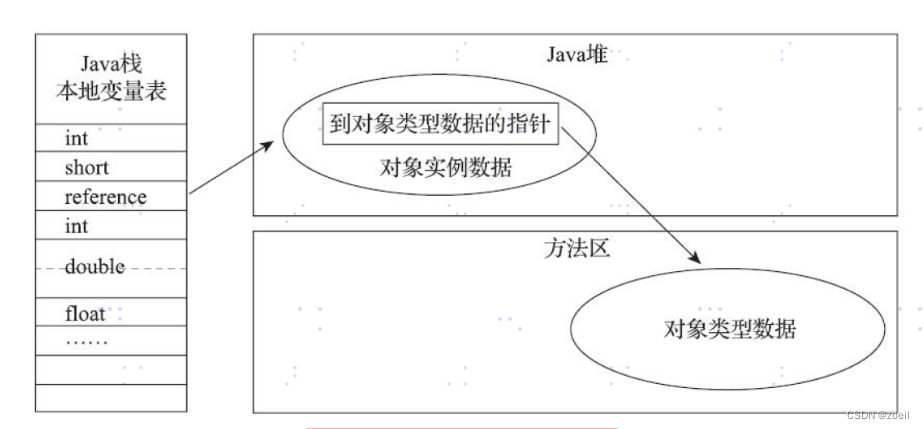
JVM-HotSpot虚拟机对象探秘
目录 一、对象的实例化 (一)创建对象的方式 (二)创建对象的步骤 二、对象的内存布局 (一)对象头 (二)实例数据 (三)对齐填充 三、 对象的访问定位 &…...

大模型技术的发展:开源和闭源,究竟谁强谁弱又该何去何从?
一、开源和闭源的优劣势比较 开源和闭源软件都有各自的优劣势,具体比较如下: 安全性:闭源软件的安全性相对较高,因为其源代码不公开,攻击者难以找到漏洞进行攻击。而开源软件由于源代码公开,容易被攻击者发…...

Python学习笔记--自定义元类
四、自定义元类 到现在,我们已经知道元类是什么鬼东西了。 那么,从始至终我们还不知道元类到底有啥用。 只是了解了一下元类。 在了解它有啥用的时候,我们先来了解下怎么自定义元类。 因为只有了解了怎么自定义才能更好的理解它的作用。…...
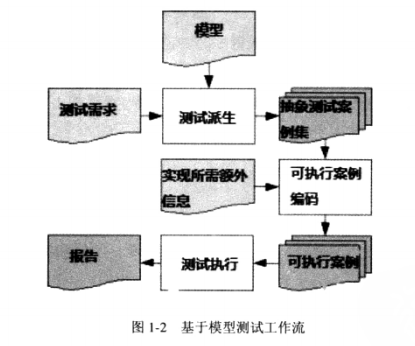
软件测试 —— 常见的自动化测试架构!
一个自动化测试架构就是一个集成体系,其中定义了一个特殊软件产品的自动化测试规则。这一体系中包含测试功能函数库、测试数据源、测试对象识别标准,以及各种可重用的模块。这些组件作为小的构建模块,被组合起来代表某种商业流程。自动化测试…...
 装饰器)
Python 的 @lru_cache() 装饰器
在 Python 标准库的 functools 模块中,有个 lru_cache 装饰器,用于为一个函数添加缓存系统: 存储函数的输入和对应的输出当函数被调用,并且给出了已经缓存过的输入,那么函数不会再运行,而是直接从缓存中获…...
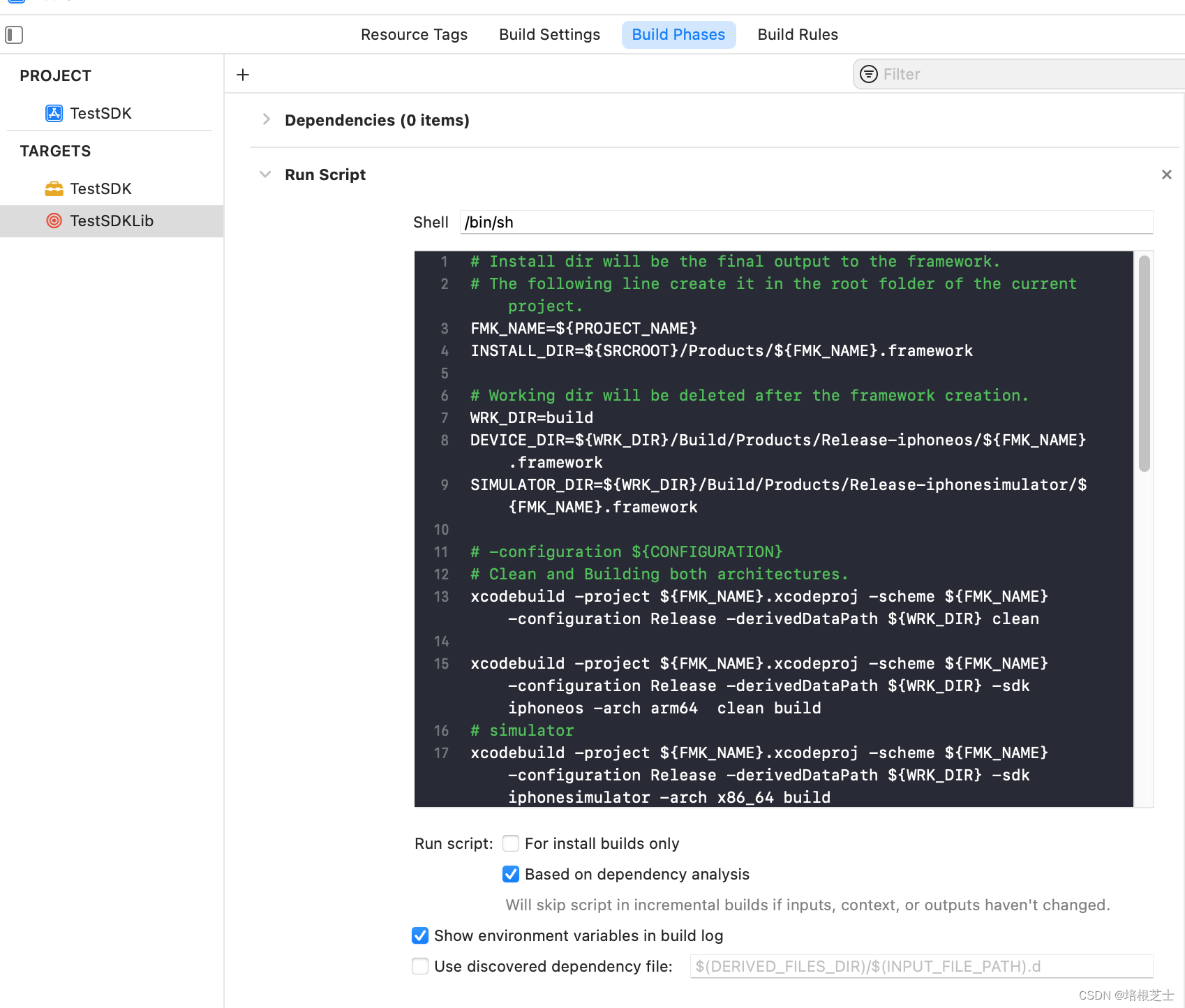
Swift制作打包framework
新建framework项目 设置生成fat包,包括模拟器x86_64和arm64 Buliding Settings -> Architectures -> Build Active Architecture Only 设置为NO 设置打包环境,选择release edit Scheme -> run -> Build configuration 设置为 Release 设置…...
WPA渗透-使用airolib-ng创建彩虹表加速)
无线WiFi安全渗透与攻防(N.2)WPA渗透-使用airolib-ng创建彩虹表加速
WPA渗透-使用airolib-ng创建彩虹表加速 WPA渗透-使用airolib-ng创建彩虹表加速1.什么是彩虹表?2.渗透wifi1.创建数据库名2.将字典导入数据库3.生成渗透wifi密码的PMK4.生成需要渗透wifi的彩虹表5.渗透wifiWPA渗透-使用airolib-ng创建彩虹表加速 1.什么是彩虹表? 彩虹表是一…...
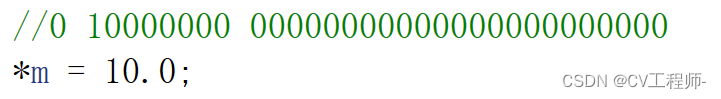
整形数据和浮点型数据在内存中的存储差别
愿所有美好如期而遇 我们先来看代码,猜猜结果是什么呢? int main() {//以整型数据的方式存储int n 10;float* m (float*)&n;//以整型数据的方式读取printf("%d\n", n);//以浮点型数据的方式2读取printf("%f\n", *m);printf(&…...
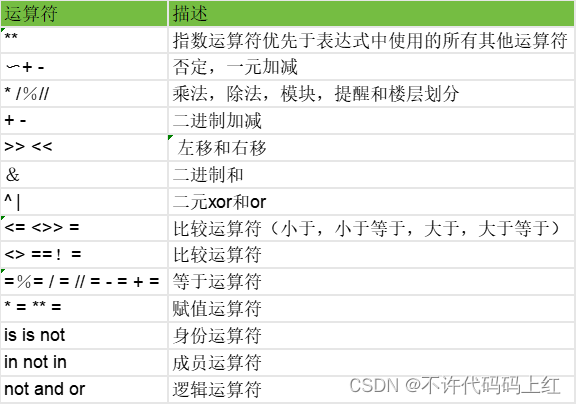
【Python基础篇】运算符
博主:👍不许代码码上红 欢迎:🐋点赞、收藏、关注、评论。 格言: 大鹏一日同风起,扶摇直上九万里。 文章目录 一 Python中的运算符二 算术运算符1 Python所有算术运算符的说明2 Python算术运算符的所有操作…...

开启数据库审计 db,extended级别或os级别)并将审计文件存放到/opt/oracle/audit/下
文章目录 1、登录到数据库2、查看审计状态3、创建审计目录4、启用审计5、设置审计文件路径6、再次查看结果 1、登录到数据库 使用SQL*Plus或者其他Oracle数据库客户端登录到数据库。 sqlplus / as sysdba;2、查看审计状态 show parameter audit;目前是DB状态,并且…...

02.webpack中多文件打包
1.module,chunk,bundle的区别 moudle - 各个源码文件,webpack中一切皆是模块chunk - 多模块合并成的,如entry, import(), splitChunkbundle - 最终的输出文件 2.多文件打包配置 2.1 webpack.common.js const path require(path) const HtmlWebpackPl…...

IEEE Standard for SystemVerilog Chapter 22. Compiler directives
22.1 General 此子句描述以下编译器指令(按字母顺序列出): __FILE__ [22.13] __LINE__ [22.13] begin_keywords [22.14] celldefine [22.10] default_net…...
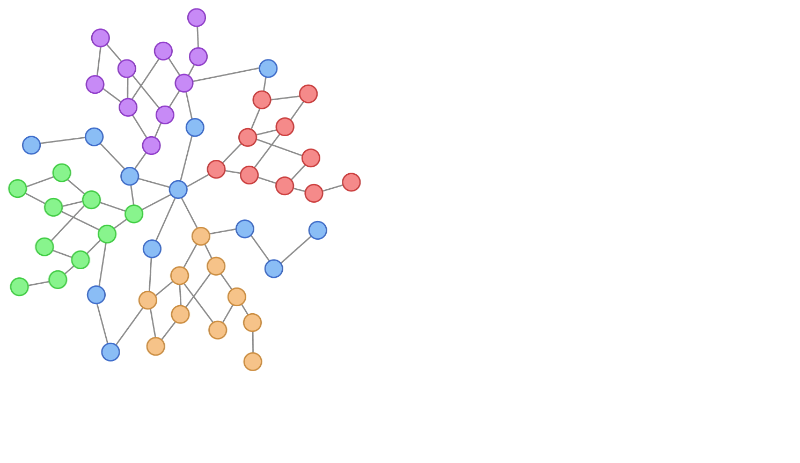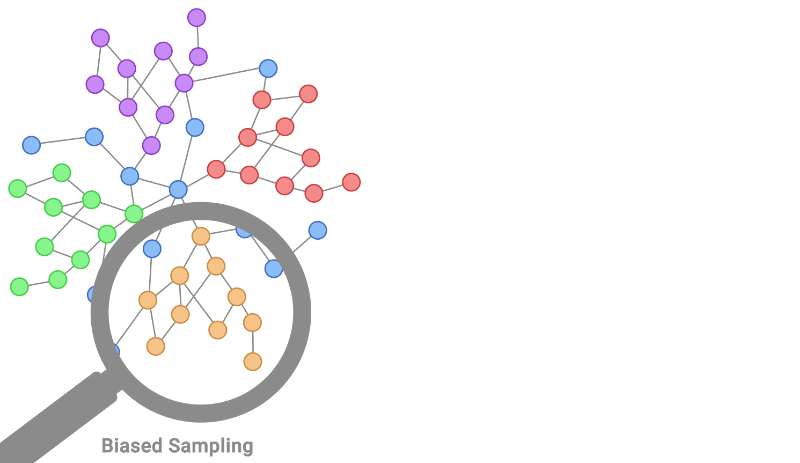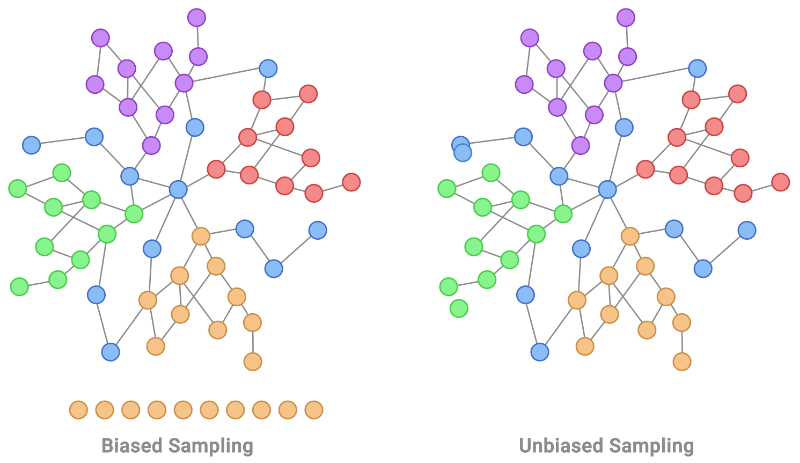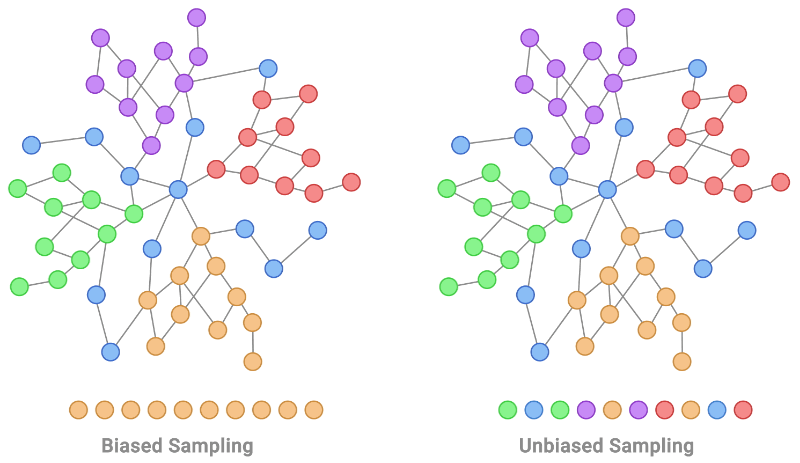
机器学习中的独立和同分布 (IID):假设和影响
一、介绍 在机器学习中,独立和同分布 (IID) 的概念在数据分析、模型训练和评估的各个方面都起着至关重要的作用。IID 假设是确保许多机器学习算法和统计技术的可靠性和有效性的基础。本文探讨了 IID 在机器学习中的重要性、其假设及其对模型开…...

PTP软硬件时间戳
软硬件时间戳 抄袭来源:http://www.bdtime.com.cn/pinlv/4296.html PTP 是一种网络协议,用于在计算机网络中进行时钟校准和时间同步。硬件时间戳和软件时间戳是在实现 PTP 时常见的两种方式,它们在精度、可靠性、实时性以及资源消耗等方面存…...
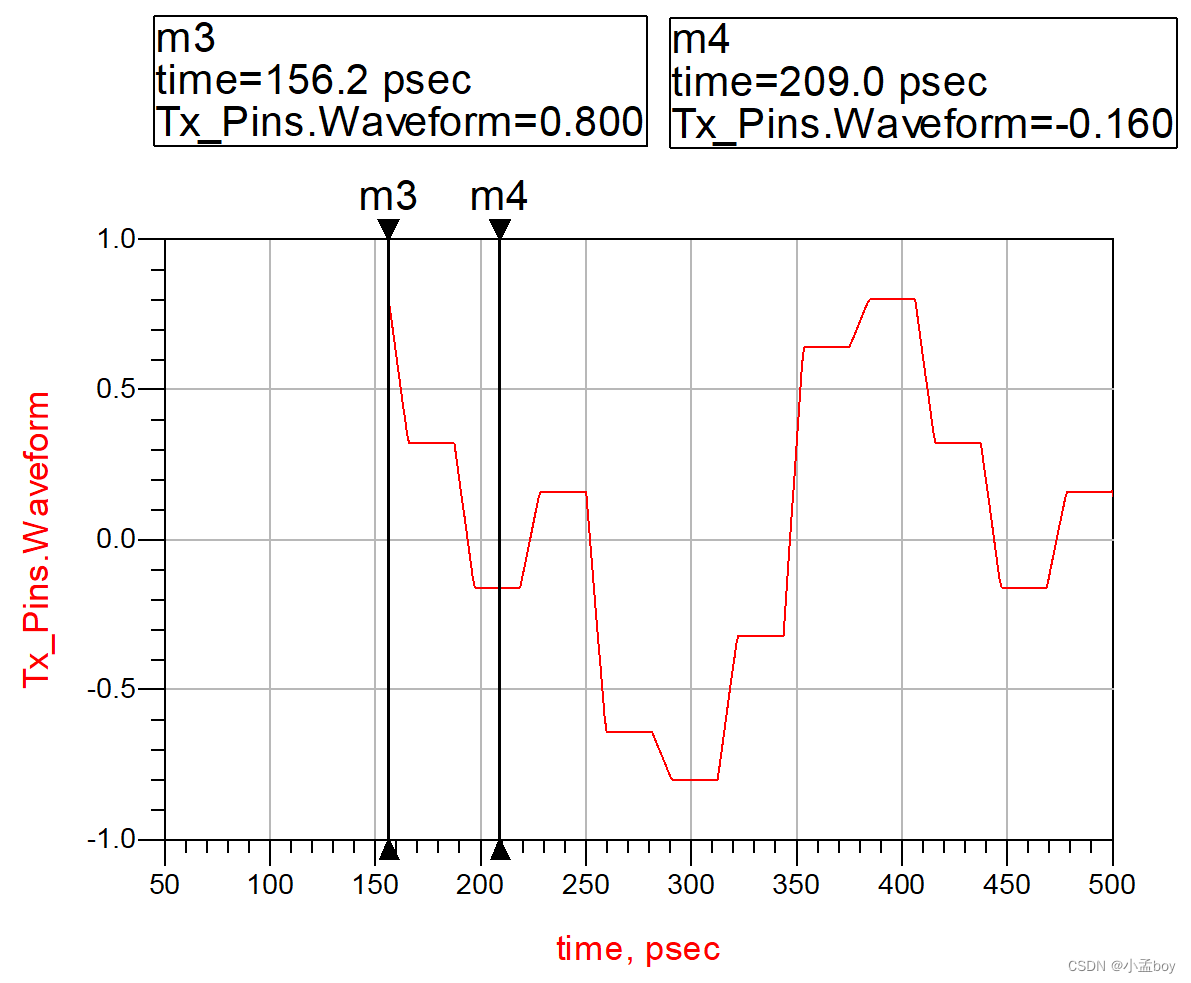
使用ADS进行serdes仿真时,Tx_Diff中EQ的设置对发送端波形的影响。
研究并记录一下ADS仿真中Tx_Diff的EQ设置。原理图如下: 最上面是选择均衡方法Choose equalization method:Specify FIR taps,Specify de-emphasis和none。 当选择Specify de-emphasis选项时,下方可以输入去加重具体的dB值&#x…...
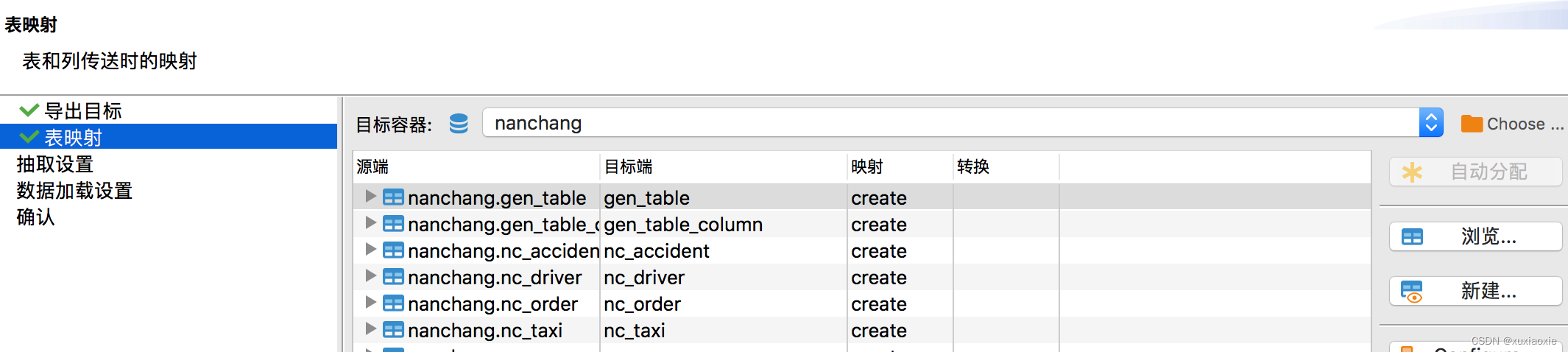
数据库迁移(DBeaver版本)
最近需要做一个数据库迁移, 测试环境开发的差不多了,需要将脚本迁移到生产。 中间了试了一些工具,比如Jetbrain出品的datagrip,这个数据库工具平时还是很好用的,但是数据迁移感觉不是那么好用,所以还是用到…...

【c++STL常见排序算法sort,merge,random_shuffle,reverse】
文章目录 C STL 常见排序算法详解1. sort 算法2. merge 算法3. random_shuffle 算法4. reverse 算法 C STL 常见排序算法详解 1. sort 算法 功能:sort 用于对容器内的元素进行升序排序。示例代码:#include <iostream> #include <algorithm>…...

STM32/N32G455国民科技芯片驱动DS1302时钟---笔记
这次来分享一下DS1302时钟IC,之前听说过这个IC,但是一直没搞过,用了半天时间就明白了原理和驱动,说明还是很简单的。 注:首先来区分一下DS1302和RTC时钟有什么不同,为什么不直接用RTC呢? RTC不…...
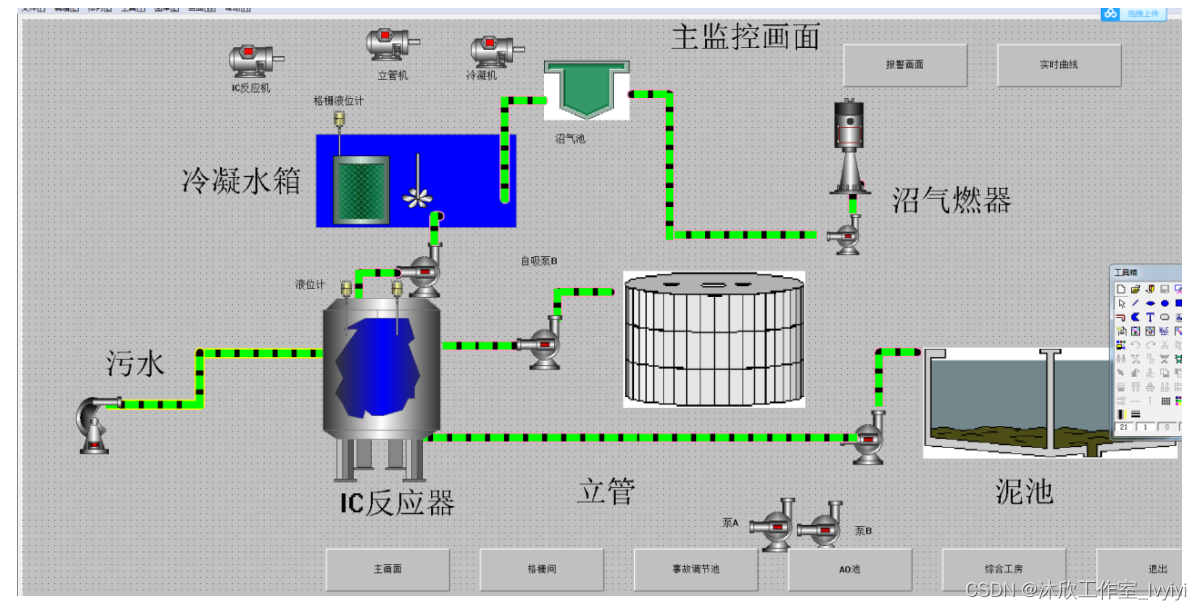
基于PLC的污水厌氧处理控制系统(论文+源码)
1. 系统设计 污水厌氧由进水系统通过粗格栅和清污机进行初步排除大块杂质物体以及漂浮物等,到达除砂池中。在除砂池系统中细格栅进一步净化污水厌氧中的细小颗粒物体,将污水厌氧中的细小沙粒滤除后进入氧化沟反应池。在该氧化沟系统中进行生化处理&…...

如何快速完成Windows系统部署:高效自动化工具完整指南
如何快速完成Windows系统部署:高效自动化工具完整指南 【免费下载链接】MediaCreationTool.bat Universal MCT wrapper script for all Windows 10/11 versions from 1507 to 21H2! 项目地址: https://gitcode.com/gh_mirrors/me/MediaCreationTool.bat Wind…...

终极指南:CodeGuide数据备份与恢复策略,保障Java开发项目安全无忧
终极指南:CodeGuide数据备份与恢复策略,保障Java开发项目安全无忧 【免费下载链接】CodeGuide :books: 本代码库是作者小傅哥多年从事一线互联网 Java 开发的学习历程技术汇总,旨在为大家提供一个清晰详细的学习教程,侧重点更倾向…...

终极营销自动化工作流设计:工程师如何构建高效营销流程
终极营销自动化工作流设计:工程师如何构建高效营销流程 【免费下载链接】Marketing-for-Engineers A curated collection of marketing articles & tools to grow your product. 项目地址: https://gitcode.com/gh_mirrors/ma/Marketing-for-Engineers …...

嵌入式Python库CI/CD实战:Travis CI自动化测试与发布
1. 项目概述与核心价值 如果你正在维护一个开源项目,或者在一个小团队里负责核心模块的开发,那么你一定对“这次改动会不会把别人的代码搞坏”这个问题感到头疼。尤其是在嵌入式开发领域,比如我们常用的CircuitPython库,代码最终要…...
pc手机通用)
堕落千金—黑蔷薇与欲望之火 2026最新版免费下载 (看到请立即转存 资源随时失效)pc手机通用
下载链接 Build.6769958|整合DLC|容量1.1GB|官方简体中文|支持键盘.鼠标 在互动叙事与成人向角色扮演游戏(RPG)的市场中,《堕落千金—黑蔷薇与欲望之火》(以下简称《黑蔷薇》)自发布以来便凭借其精致的美术风格与沉浸…...

为什么你的DeepSeek JSON总是parse error?资深架构师用AST语法树对比揭示4种LLM输出结构幻觉根源
更多请点击: https://intelliparadigm.com 第一章:JSON解析失败的表象与系统性归因 JSON解析失败在现代Web服务、微服务通信及前端数据消费中极为常见,其表象往往表现为程序崩溃、空值传播、或静默丢弃数据,而非明确的错误提示。…...

如何用BilibiliDown实现跨平台B站视频高效下载?3个核心优势解析
如何用BilibiliDown实现跨平台B站视频高效下载?3个核心优势解析 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_…...

RK3588平台IMX415摄像头驱动调试全流程与实战指南
1. 项目概述与核心挑战最近在基于瑞芯微RK3588平台调试索尼IMX415摄像头,整个过程可以说是既典型又充满细节。对于嵌入式Linux开发,尤其是多媒体应用,摄像头驱动调试往往是硬件适配中最关键也最磨人的一环。RK3588作为一款高性能的AIoT SoC&a…...
)
别再让延迟搞砸你的PID控制!手把手教你用Matlab Simulink搭建Smith预估器(附完整模型)
从PID震荡到稳定控制:Matlab Simulink中Smith预估器的实战集成指南 当你精心设计的PID控制器在仿真中突然开始疯狂振荡,屏幕上那条曲线像喝醉了一样左右摇摆时,延迟问题很可能就是罪魁祸首。这不是算法本身的问题,而是现实世界中执…...

基于OpenClaw构建AI智能体:从RAG到自动化工作流的实战指南
1. 项目概述:一个开源AI应用案例的“藏宝图”最近在GitHub上闲逛,发现了一个挺有意思的仓库,叫awesome-openclaw-usecases-zh。光看名字,就能拆解出几个关键信息:“awesome”系列(意味着是精选合集…...