python爬虫概述及简单实践:获取豆瓣电影排行榜
目录
前言
Python爬虫概述
简单实践 - 获取豆瓣电影排行榜
1. 分析目标网页
2. 获取页面内容
3. 解析页面
4. 数据存储
5. 使用代理IP
总结
前言
Python爬虫是指通过程序自动化地对互联网上的信息进行抓取和分析的一种技术。Python作为一门易于学习且强大的编程语言,因其拥有丰富的第三方库和强大的数据处理能力,使得它成为了爬虫开发中的最佳选择。本文将简单介绍Python爬虫的概述,并提供一个简单的实践案例,同时会使用代理IP来提高爬虫的效率。

Python爬虫概述
Python爬虫由三个部分组成:网页下载、网页解析、数据存储。
- 网页下载:从互联网上获取需要的数据,通常使用requests库或urllib库来实现
- 网页解析:将下载下来的网页进行处理,提取出需要的信息,常见的解析库有BeautifulSoup和xpath等
- 数据存储:将获取到的数据存储到文件、数据库等中,通常使用sqlite、MySQL等数据库或者csv、json等文件格式
简单实践 - 获取豆瓣电影排行榜
下面将通过一个简单的实践来讲解Python爬虫的应用。
1. 分析目标网页
首先打开浏览器,访问[豆瓣电影排行榜](https://movie.douban.com/chart),观察页面,我们会发现电影排行榜的信息都在HTML的table标签中,并且每个电影信息都是一个tr标签。每个电影信息包括电影名称、评分、导演、演员、链接等等。因此,我们需要使用Python程序来获取这些电影的信息。
2. 获取页面内容
网页下载是爬虫的第一步,我们使用Python的requests库来获取目标网页的HTML代码。代码如下:
import requestsurl = 'https://movie.douban.com/chart'
user_agent = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
headers = {'User-Agent': user_agent}r = requests.get(url, headers=headers)
if r.status_code == 200:html = r.text这里我们设置了请求头,模拟浏览器的请求,以免被目标网站认为是爬虫而禁止访问。
3. 解析页面
我们使用Python的BeautifulSoup库来解析页面。该库提供了一种非常方便的方式来操作HTML和XML文档,能够方便地获取特定元素、属性和文本等信息。我们首先使用lxml解析器将HTML代码转换成BeautifulSoup对象,然后根据标签和属性的CSS选择器来遍历HTML文档并提取需要的内容。代码如下:
from bs4 import BeautifulSoupsoup = BeautifulSoup(html, features="lxml")
table = soup.find("table", {"class": "ranking-list"})
tbody = table.find("tbody")
trs = tbody.findAll("tr")movies = []
for tr in trs:td_name = tr.find("td", {"class": "titleColumn"})name = td_name.find("a").textrating = tr.find("span", {"class": "rating_num"}).textdirector = td_name.find("div", {"class": "bd"}).find_all("p")[0].textactors = td_name.find("div", {"class": "bd"}).find_all("p")[1].textlink = td_name.find("a")["href"]movie = {"name": name, "rating": rating, "director": director, "actors": actors, "link": link}movies.append(movie)for movie in movies:print(movie)这里我们使用find()方法来查找特定的标签和属性,并使用text属性来获取标签中的文本。需要注意的是,如果标签不存在或者不存在某个属性,那么会返回None,因此需要进行一定的判断和处理。
4. 数据存储
最后,我们将获取到的电影信息保存到CSV文件中。代码如下:
import csvfilename = 'movies.csv'
with open(filename, 'w', newline='', encoding='utf-8') as f:writer = csv.writer(f)writer.writerow(['电影名', '评分', '导演', '演员', '链接'])for movie in movies:writer.writerow([movie['name'], movie['rating'], movie['director'], movie['actors'], movie['link']])使用csv库的writerow()方法将电影信息逐行写入CSV文件中。
5. 使用代理IP
有些网站会对爬虫程序进行限制,例如设置访问频率限制、封禁IP等操作。因此,我们需要使用代理IP来解决这一问题。代理IP可以让我们通过代理服务器来访问目标网站,从而提高访问速度和安全性。
我们可以通过一些免费的代理IP网站来获取代理IP,例如站大爷代理ip、开心代理等。代码如下:
import requestsurl = 'https://movie.douban.com/chart'
user_agent = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
headers = {'User-Agent': user_agent}proxy_url = 'https://www.zdaye.com//'
proxy_headers = {'User-Agent': user_agent}proxies = []
r = requests.get(proxy_url, headers=proxy_headers)
if r.status_code == 200:soup = BeautifulSoup(r.text, features="lxml")table = soup.find("table", {"id": "ip_list"})tbody = table.find("tbody")trs = tbody.findAll("tr")for tr in trs:tds = tr.find_all('td')if len(tds) > 6 and tds[5].text == 'HTTP':ip = tds[1].text + ':' + tds[2].textproxies.append(ip)for proxy in proxies:try:print('Using proxy:', proxy)proxy_dict = {'http': 'http://' + proxy, 'https': 'https://' + proxy}r = requests.get(url, headers=headers, proxies=proxy_dict, timeout=5)if r.status_code == 200:html = r.textbreakexcept:continue这里我们定义一个proxies列表来保存获取到的代理IP,然后遍历该列表中的每个代理IP进行访问。如果某个代理IP无法访问,则使用下一个代理IP进行访问,直到访问到目标网页为止。需要注意的是,如果代理IP无法使用或者响应时间过长,需要考虑使用其他IP或者增加超时时间。
总结
Python爬虫是一种非常有用的技术,通过Python程序自动化地获取互联网上的数据,为我们带来了许多便利。在实践中,我们需要注意遵守法律法规和爬虫道德规范,以避免产生不良后果。
相关文章:
python爬虫概述及简单实践:获取豆瓣电影排行榜
目录 前言 Python爬虫概述 简单实践 - 获取豆瓣电影排行榜 1. 分析目标网页 2. 获取页面内容 3. 解析页面 4. 数据存储 5. 使用代理IP 总结 前言 Python爬虫是指通过程序自动化地对互联网上的信息进行抓取和分析的一种技术。Python作为一门易于学习且强大的编程语言&…...
)
ts视频文件转为mp4(FFmpeg)
有些视频资源下载下来之后发现是.ts的文件,除了用下载它时用的工具或是浏览器才能看,那有没有将ts文件转换成更加通用视频格式的方法。 几乎万能的音视频工具--ffmpeg登场 安装和环境配置可看这篇博客:FFmpeg指令行打开usb摄像头࿰…...
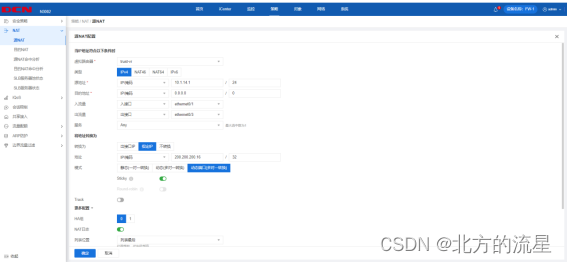
2023年咸阳市《网络建设与运维》赛题解析------四、安全配置
安全配置 说明:IP地址按照题目给定的顺序用“ip/mask”表示,IPv4 any地址用0.0.0.0/0,IPv6 any地址用::/0,禁止用地址条目,否则按零分处理。 1.FW1配置IPv4 nat,实现集团产品1段IPv4访问Internet IPv4,转换ip/mask为200.200.200.16/28,保证每一个源IP产生的所有会话将…...

什么是java枚举?为什么要用java枚举?
什么是java枚举? 原始的接口定义常量 public interface IConstants {String MON "Mon";String TUE "Tue";String WED "Wed";String THU "Thu";String FRI "Fri";String SAT "Sat";String SUN …...
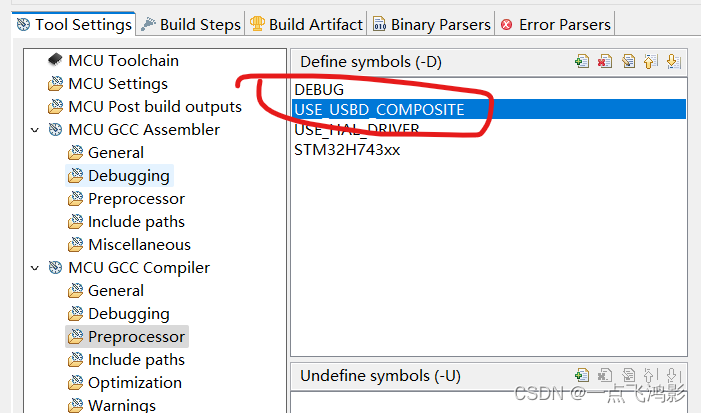
USB复合设备构建CDC+HID鼠标键盘套装
最近需要做一个小工具,要用到USB CDCHID设备。又重新研究了一下USB协议和STM32的USB驱动库,也踩了不少坑,因此把代码修改过程记录一下。 开发环境: ST-LINK v2 STM32H743开发板 PC windows 11 cubeMX v6.9.2 cubeIDE v1.13.2 cub…...
HTTP 基本原理)
准备篇(四)HTTP 基本原理
URI 和 URLURIURLURI vs URLHTTP 和 HTTPS超文本HTTPHTTP 请求与响应HTTPS你是否想过,在浏览器中敲入 URL 到 获取网页内容 之间发生了什么? 了解这些,有助于进一步了解爬虫的基本原理。 URI 和 URL URI(Uniform Resource Identifier),即统一资源标识符;URL(Universa…...

模板初阶笔记分享
有道云笔记...
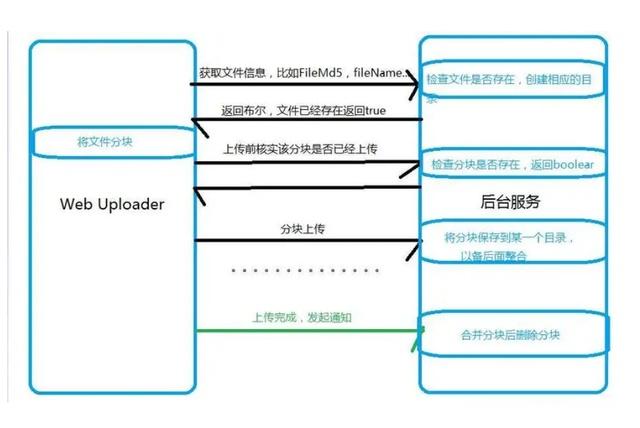
使用Spring Boot实现大文件断点续传及文件校验
一、简介 随着互联网的快速发展,大文件的传输成为了互联网应用的重要组成部分。然而,由于网络不稳定等因素的影响,大文件的传输经常会出现中断的情况,这时需要重新传输,导致传输效率低下。 为了解决这个问题ÿ…...

读取PDF中指定数据写入EXCEL文件
使用Java读取文件夹中的PDF文件,再读取文件中的指定的字体内容,然后将内容写入到Excel文件中,其中包含一些正则判断,可以忽略,字体以Corbel字体为例。 所需要的maven依赖为: <dependency><groupId>com.alibaba</groupId><artifactId>easyexcel…...
[黑马程序员SpringBoot2]——开发实用篇1
目录: 手工启动热部署自动启动热部署热部署范围配置关闭热部署功能第三方bean属性绑定松散绑定常用计量单位应用bean属性校验进制数据转换规则加载测试专用属性加载测试专用配置测试类中启动web环境发送虚拟请求匹配响应执行状态匹配响应体匹配响应体(json)匹配响应…...
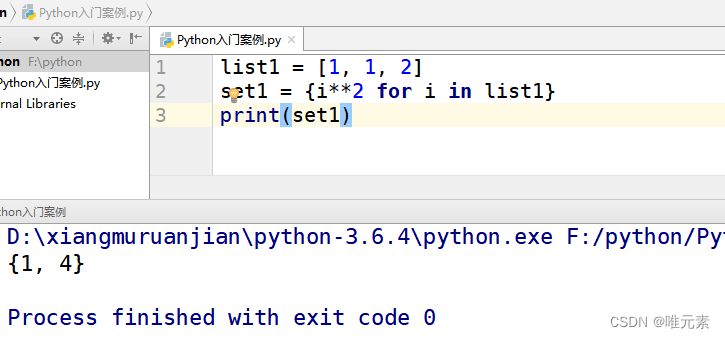
Python------列表 集合 字典 推导式(本文以 集合为主)
推导式: 推导式comprehensions(又称解析式),是Python的一种独有特性。推导式是可以从一个数据序列 构建 另一个 新的数据序列(一个有规律的列表或控制一个有规律列表)的结构体。 共有三种推导ÿ…...

网工内推 | Linux运维,六险二金,最高30K,IE认证优先
01 上海域起 招聘岗位:Linux运维工程师 职责描述: 1.负责游戏产品运维相关的工作,流程文档、技术文档、功能脚本的编写整理 2.负责分析并排除系统、数据库、网络、应用等游戏产品运维中出现的故障及错误 3.负责对游戏产品项目进行线上部署、…...
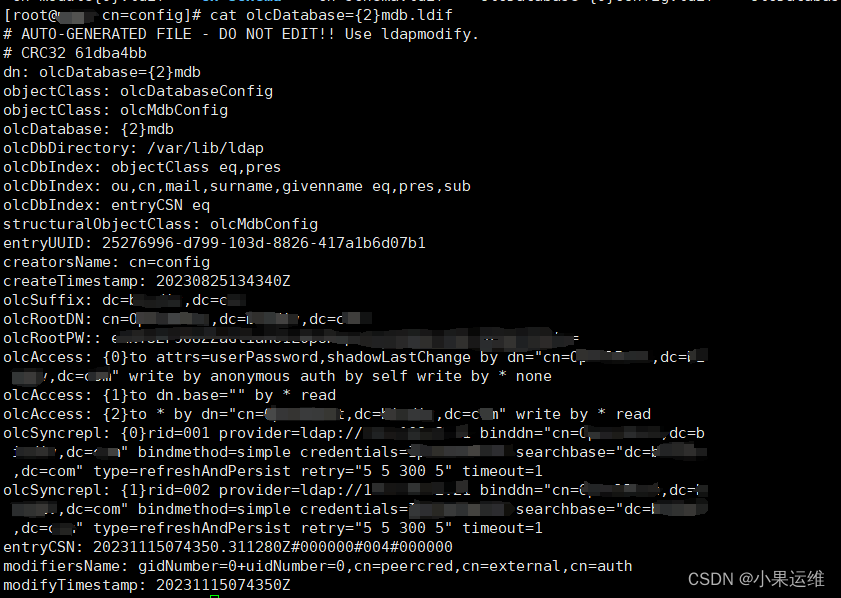
服务器集群配置LDAP统一认证高可用集群(配置tsl安全链接)-centos9stream-openldap2.6.2
写在前面 因之前集群为centos6,已经很久没升级了,所以这次配置统一用户认证也是伴随系统升级到centos9时一起做的配套升级。新版的openldap配置大致与老版本比较相似,但有些地方配置还是有变化,另外,铺天盖地的帮助文…...

12-1- GAN -简单网络-线性网络
功能 随机噪声→生成器→MINIST图像。 训练方法 0 损失函数:gan的优化目标是一个对抗损失,是二分类问题,用BCELoss 1 判别器的训练,首先固定生成器参数不变,其次判别器应当将真实图像判别为1,生成图像判别为0 loss=loss(real_out, 1)+loss(fake_out, 0) 2 生成器的…...
Antv/G2 分组柱状图+折线图双轴图表
<!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width,heightdevice-height"><title>分组柱状图折线图双轴图表</title><styl…...
springboot323基于Java的美妆购物网站的设计与实现
交流学习: 更多项目: 全网最全的Java成品项目列表 https://docs.qq.com/doc/DUXdsVlhIdVlsemdX 演示 项目功能演示: ————————————————...
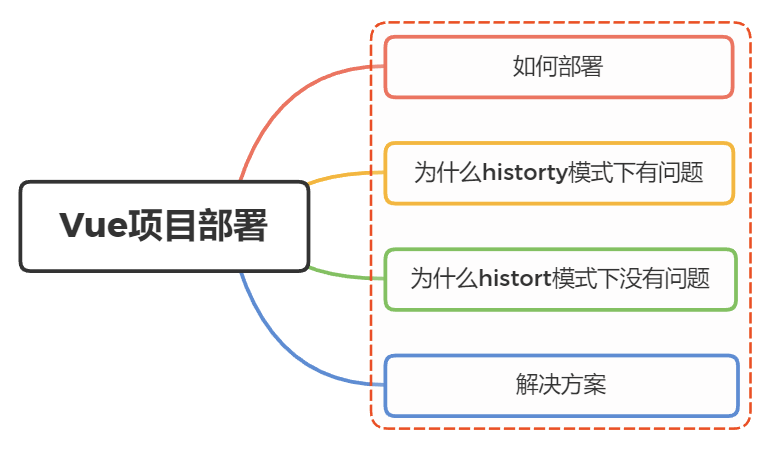
vue项目本地开发完成后部署到服务器后报404
vue项目本地开发完成后部署到服务器后报404是什么原因呢? 一、如何部署 前后端分离开发模式下,前后端是独立布署的,前端只需要将最后的构建物上传至目标服务器的web容器指定的静态目录下即可 我们知道vue项目在构建后,是生成一系…...
Android设计模式--状态模式
真知即所以为行,不行不足谓之知 一,定义 当一个对象的内在状态改变时,允许改变其行为,这个对象看起来像是改变了其类。 这么说可能很难理解,通俗来讲就是当一个对象它有多种状态的时候,把每一种状态的行为…...

C++关系运算符重载
#include<iostream> using namespace std;class Person { public:string name;int age;Person(string n, int a){name n;age a;}//friend bool operator(Person& p1, Person& p2); 使用友元//成员函数实现函数关系符重载bool operator(Person& p) {if (na…...
HLS基础issue
hls 是一个用C/c 来开发PL ,产生rtl的工具 hls是按照rtl code来运行的 , 但是rtl会在不同器件调用不同的源语; 可能产生的ip使用在vivado另外一个器件的话 会存在问题; Hls : vivado ip , vitis kernel 是…...
到底怎么配?)
别再搞混了!SAP物料主数据、BOM、工艺路线里的三种损耗率(Scrap)到底怎么配?
SAP三大损耗率配置实战指南:从物料主数据到工艺路线的精准决策 在SAP PP模块实施过程中,物料损耗率的配置往往成为顾问团队争论的焦点。我曾参与过一个汽车零部件制造项目,由于初期对三种损耗率的理解偏差,导致MRP运算结果与实际情…...

终极AI自瞄系统:5分钟搭建你的智能游戏瞄准助手
终极AI自瞄系统:5分钟搭建你的智能游戏瞄准助手 【免费下载链接】RookieAI_yolov8 基于yolov8实现的AI自瞄项目 AI self-aiming project based on yolov8 项目地址: https://gitcode.com/gh_mirrors/ro/RookieAI_yolov8 还在为游戏中的精准瞄准而烦恼吗&…...

手把手教你定制专属标注工具:基于Python3+Tkinter打造你的实体关系标注器
从零构建领域专用标注工具:Python3Tkinter实战指南 在自然语言处理项目中,高质量标注数据是模型效果的基石。当面对法律条文、医疗报告等专业领域时,通用标注工具往往难以满足特定实体关系和输出格式需求。本文将带你深入开发一个完全可控的实…...

紧急更新!Perplexity v3.2作家索引逻辑变更后,3小时内必须掌握的4项适配策略
更多请点击: https://kaifayun.com 第一章:Perplexity作家信息搜索 Perplexity 是一款以实时网络检索与引用溯源为特色的 AI 搜索工具,其“作家信息搜索”能力并非依赖静态数据库,而是通过动态解析权威出版平台(如 Su…...

AUTOSAR Ea模块深度剖析:从原理到实战的EEPROM抽象层配置与优化
1. 项目概述:为什么我们需要深入理解Ea模块?在AUTOSAR的软件架构里,NVRAM管理器(NvM)负责非易失性数据的抽象管理,而Ea(EEPROM Abstraction,EEPROM抽象)模块,…...

Agentic RAG的实现方式?
文档智能体开发正迎来“低门槛时代”。基于PaddleOCR与LangChain社区的集成合作,文心飞桨开发者进一步搭建了可视化管理工具ClawMaster——让开发者无需从零部署模型或编写复杂调用逻辑,10分钟即可跑通文档智能体工作流。与此同时,X-AnyLabel…...
)
从74LS00与非门到74LS86异或门:手把手教你用面包板搭建数字电路基础实验(附波形分析)
从74LS00与非门到74LS86异或门:面包板上的数字电路实战指南 在电子技术的浩瀚海洋中,数字电路犹如一座连接现实与虚拟的桥梁。对于初学者而言,从理论到实践的跨越往往充满挑战——实验室里昂贵的设备、复杂的接线、固定的实验流程,…...

UVM验证效率提升:利用仿真器保存恢复机制消除冗余配置周期
1. 验证环境中的冗余周期之痛:一个普遍存在的效率瓶颈在芯片验证领域,尤其是使用UVM(Universal Verification Methodology)构建的复杂验证环境中,我们常常会面临一个看似不起眼、实则消耗巨大的问题:冗余的…...
)
Midjourney年度订阅最后上车机会:官方邮件暗藏“早鸟密钥”,输入即解锁终身$129→$79(已验证有效期至2024-12-15)
更多请点击: https://kaifayun.com 第一章:Midjourney年度订阅优惠的官方政策与背景解析 Midjourney自2023年起正式将年度订阅(Annual Plan)纳入其核心付费体系,旨在为长期用户降低平均月成本并强化服务稳定性。该政策…...

射频电路自动化设计:用MATLAB脚本批量修改ADS S参数,提升仿真效率
射频电路自动化设计:用MATLAB脚本批量修改ADS S参数,提升仿真效率 在射频电路设计中,工程师经常需要面对复杂的S参数矩阵调整和大量仿真任务。传统的手动修改方式不仅效率低下,还容易引入人为错误。本文将介绍如何利用MATLAB脚本实…...