【自然语言处理(NLP)实战】LSTM网络实现中文文本情感分析(手把手与教学超详细)
目录
引言:
1.所有文件展示:
1.中文停用词数据(hit_stopwords.txt)来源于:
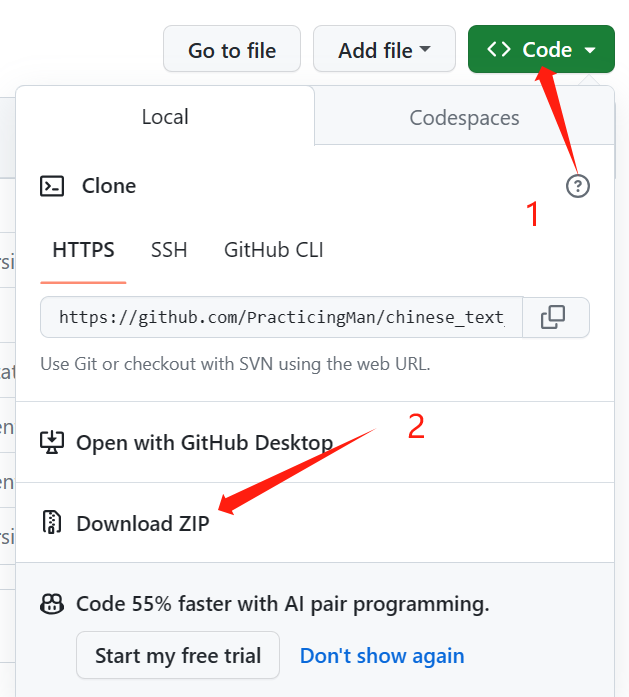
2.其中data数据集为chinese_text_cnn-master.zip提取出的文件。点击链接进入github,点击Code、Download ZIP即可下载。
2.安装依赖库:
3.数据预处理(data_set.py):
train.txt-去除停用词后的训练集文件:
test.txt -去除停用词后的测试集文件:
4. 模型训练以及保存(main.py)
1.LSTM模型搭建:
2.main.py代价展示 :
3.模型保存
4.训练结果
5.LSTM模型测试(test.py)
1.测试结果:
2.测试结果:
6.完整代码展示:
1.data_set.py
2.mian.py
3.test.py
引言:
在当今数字化时代,人们在社交媒体、评论平台以及各类在线交流中产生了海量的文本数据。这些数据蕴含着丰富的情感信息,从而成为了深入理解用户态度、市场趋势,甚至社会情绪的宝贵资源。自然语言处理(NLP)的发展为我们提供了强大的工具,使得对文本情感进行分析成为可能。在这个领域中,长短时记忆网络(LSTM)凭借其能够捕捉文本序列中长距离依赖关系的能力,成为了情感分析任务中的一项重要技术。
本篇博客将手把手地教你如何使用LSTM网络实现中文文本情感分析。我们将从数据预处理开始,逐步构建一个端到端的情感分析模型。通过详细的步骤和示例代码,深入了解如何处理中文文本数据、构建LSTM模型、进行训练和评估。
1.所有文件展示:

1.中文停用词数据(hit_stopwords.txt)来源于:
项目目录预览 - stopwords - GitCode
2.其中data数据集为chinese_text_cnn-master.zip提取出的文件。点击链接进入github,点击Code、Download ZIP即可下载。
2.安装依赖库:
pip install torch # 搭建LSTM模型
pip install gensim # 中文文本词向量转换
pip install numpy # 数据清洗、预处理
pip install pandas
3.数据预处理(data_set.py):
# -*- coding: utf-8 -*-
# @Time : 2023/11/15 10:52
# @Author :Muzi
# @File : data_set.py
# @Software: PyCharm
import pandas as pd
import jieba# 数据读取
def load_tsv(file_path):data = pd.read_csv(file_path, sep='\t')data_x = data.iloc[:, -1]data_y = data.iloc[:, 1]return data_x, data_ytrain_x, train_y = load_tsv("./data/train.tsv")
test_x, test_y = load_tsv("./data/test.tsv")
train_x=[list(jieba.cut(x)) for x in train_x]
test_x=[list(jieba.cut(x)) for x in test_x]with open('./hit_stopwords.txt','r',encoding='UTF8') as f:stop_words=[word.strip() for word in f.readlines()]print('Successfully')
def drop_stopword(datas):for data in datas:for word in data:if word in stop_words:data.remove(word)return datasdef save_data(datax,path):with open(path, 'w', encoding="UTF8") as f:for lines in datax:for i, line in enumerate(lines):f.write(str(line))# 如果不是最后一行,就添加一个逗号if i != len(lines) - 1:f.write(',')f.write('\n')if __name__ == '__main':train_x=drop_stopword(train_x)test_x=drop_stopword(test_x)save_data(train_x,'./train.txt')save_data(test_x,'./test.txt')print('Successfully')train.txt-去除停用词后的训练集文件:

test.txt -去除停用词后的测试集文件:

4. 模型训练以及保存(main.py)
1.LSTM模型搭建:
不同的数据集应该有不同的分类标准,我这里用到的数据模型属于二分类问题
# 定义LSTM模型
class LSTMModel(nn.Module):def __init__(self, input_size, hidden_size, output_size):super(LSTMModel, self).__init__()self.lstm = nn.LSTM(input_size, hidden_size, batch_first=True)self.fc = nn.Linear(hidden_size, output_size)def forward(self, x):lstm_out, _ = self.lstm(x)output = self.fc(lstm_out[:, -1, :]) # 取序列的最后一个输出return output# 定义模型
input_size = word2vec_model.vector_size
hidden_size = 50 # 你可以根据需要调整隐藏层大小
output_size = 2 # 输出的大小,根据你的任务而定model = LSTMModel(input_size, hidden_size, output_size)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss() # 交叉熵损失函数
optimizer = torch.optim.Adam(model.parameters(), lr=0.0002)2.main.py代价展示 :
# -*- coding: utf-8 -*-
# @Time : 2023/11/13 20:31
# @Author :Muzi
# @File : mian.py.py
# @Software: PyCharm
import pandas as pd
import torch
from torch import nn
import jieba
from gensim.models import Word2Vec
import numpy as np
from data_set import load_tsv
from torch.utils.data import DataLoader, TensorDataset# 数据读取
def load_txt(path):with open(path,'r',encoding='utf-8') as f:data=[[line.strip()] for line in f.readlines()]return datatrain_x=load_txt('train.txt')
test_x=load_txt('test.txt')
train=train_x+test_x
X_all=[i for x in train for i in x]_, train_y = load_tsv("./data/train.tsv")
_, test_y = load_tsv("./data/test.tsv")
# 训练Word2Vec模型
word2vec_model = Word2Vec(sentences=X_all, vector_size=100, window=5, min_count=1, workers=4)# 将文本转换为Word2Vec向量表示
def text_to_vector(text):vector = [word2vec_model.wv[word] for word in text if word in word2vec_model.wv]return sum(vector) / len(vector) if vector else [0] * word2vec_model.vector_sizeX_train_w2v = [[text_to_vector(text)] for line in train_x for text in line]
X_test_w2v = [[text_to_vector(text)] for line in test_x for text in line]# 将词向量转换为PyTorch张量
X_train_array = np.array(X_train_w2v, dtype=np.float32)
X_train_tensor = torch.Tensor(X_train_array)
X_test_array = np.array(X_test_w2v, dtype=np.float32)
X_test_tensor = torch.Tensor(X_test_array)
#使用DataLoader打包文件
train_dataset = TensorDataset(X_train_tensor, torch.LongTensor(train_y))
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_dataset = TensorDataset(X_test_tensor,torch.LongTensor(test_y))
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=True)
# 定义LSTM模型
class LSTMModel(nn.Module):def __init__(self, input_size, hidden_size, output_size):super(LSTMModel, self).__init__()self.lstm = nn.LSTM(input_size, hidden_size, batch_first=True)self.fc = nn.Linear(hidden_size, output_size)def forward(self, x):lstm_out, _ = self.lstm(x)output = self.fc(lstm_out[:, -1, :]) # 取序列的最后一个输出return output# 定义模型
input_size = word2vec_model.vector_size
hidden_size = 50 # 你可以根据需要调整隐藏层大小
output_size = 2 # 输出的大小,根据你的任务而定model = LSTMModel(input_size, hidden_size, output_size)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss() # 交叉熵损失函数
optimizer = torch.optim.Adam(model.parameters(), lr=0.0002)if __name__ == "__main__":# 训练模型num_epochs = 10log_interval = 100 # 每隔100个批次输出一次日志loss_min=100for epoch in range(num_epochs):model.train()for batch_idx, (data, target) in enumerate(train_loader):outputs = model(data)loss = criterion(outputs, target)optimizer.zero_grad()loss.backward()optimizer.step()if batch_idx % log_interval == 0:print('Epoch [{}/{}], Batch [{}/{}], Loss: {:.4f}'.format(epoch + 1, num_epochs, batch_idx, len(train_loader), loss.item()))# 保存最佳模型if loss.item()<loss_min:loss_min=loss.item()torch.save(model, 'model.pth')# 模型评估with torch.no_grad():model.eval()correct = 0total = 0for data, target in test_loader:outputs = model(data)_, predicted = torch.max(outputs.data, 1)total += target.size(0)correct += (predicted == target).sum().item()accuracy = correct / totalprint('Test Accuracy: {:.2%}'.format(accuracy))
3.模型保存
# 保存最佳模型if loss.item()<loss_min:loss_min=loss.item()torch.save(model, 'model.pth')4.训练结果

5.LSTM模型测试(test.py)
# -*- coding: utf-8 -*-
# @Time : 2023/11/15 15:53
# @Author :Muzi
# @File : test.py.py
# @Software: PyCharm
import torch
import jieba
from torch import nn
from gensim.models import Word2Vec
import numpy as npclass LSTMModel(nn.Module):def __init__(self, input_size, hidden_size, output_size):super(LSTMModel, self).__init__()self.lstm = nn.LSTM(input_size, hidden_size, batch_first=True)self.fc = nn.Linear(hidden_size, output_size)def forward(self, x):lstm_out, _ = self.lstm(x)output = self.fc(lstm_out[:, -1, :]) # 取序列的最后一个输出return output# 数据读取
def load_txt(path):with open(path,'r',encoding='utf-8') as f:data=[[line.strip()] for line in f.readlines()]return data#去停用词
def drop_stopword(datas):# 假设你有一个函数用于预处理文本数据with open('./hit_stopwords.txt', 'r', encoding='UTF8') as f:stop_words = [word.strip() for word in f.readlines()]datas=[x for x in datas if x not in stop_words]return datasdef preprocess_text(text):text=list(jieba.cut(text))text=drop_stopword(text)return text# 将文本转换为Word2Vec向量表示
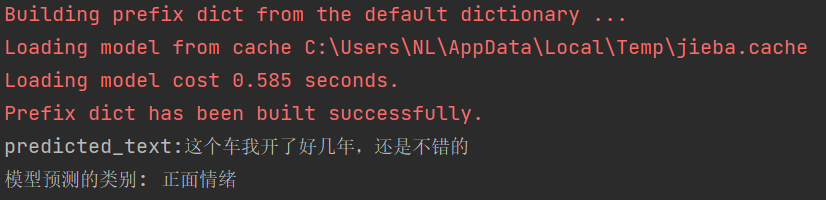
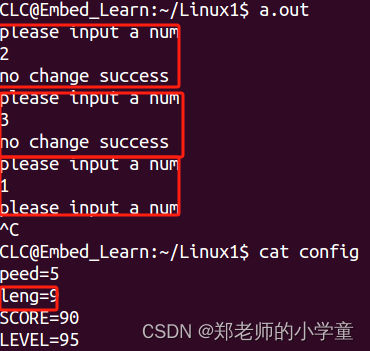
def text_to_vector(text):train_x = load_txt('train.txt')test_x = load_txt('test.txt')train = train_x + test_xX_all = [i for x in train for i in x]# 训练Word2Vec模型word2vec_model = Word2Vec(sentences=X_all, vector_size=100, window=5, min_count=1, workers=4)vector = [word2vec_model.wv[word] for word in text if word in word2vec_model.wv]return sum(vector) / len(vector) if vector else [0] * word2vec_model.vector_sizeif __name__ == '__main__':# input_text = "这个车完全就是垃圾,又热又耗油"input_text = "这个车我开了好几年,还是不错的"label = {1: "正面情绪", 0: "负面情绪"}model = torch.load('model.pth')# 预处理输入数据input_data = preprocess_text(input_text)# 确保输入词向量与模型维度和数据类型相同input_data=[[text_to_vector(input_data)]]input_arry= np.array(input_data, dtype=np.float32)input_tensor = torch.Tensor(input_arry)# 将输入数据传入模型with torch.no_grad():output = model(input_tensor)predicted_class = label[torch.argmax(output).item()]print(f"predicted_text:{input_text}")print(f"模型预测的类别: {predicted_class}")1.测试结果:
2.测试结果:

6.完整代码展示:
1.data_set.py
import pandas as pd
import jieba# 数据读取
def load_tsv(file_path):data = pd.read_csv(file_path, sep='\t')data_x = data.iloc[:, -1]data_y = data.iloc[:, 1]return data_x, data_ywith open('./hit_stopwords.txt','r',encoding='UTF8') as f:stop_words=[word.strip() for word in f.readlines()]print('Successfully')
def drop_stopword(datas):for data in datas:for word in data:if word in stop_words:data.remove(word)return datasdef save_data(datax,path):with open(path, 'w', encoding="UTF8") as f:for lines in datax:for i, line in enumerate(lines):f.write(str(line))# 如果不是最后一行,就添加一个逗号if i != len(lines) - 1:f.write(',')f.write('\n')if __name__ == '__main':train_x, train_y = load_tsv("./data/train.tsv")test_x, test_y = load_tsv("./data/test.tsv")train_x = [list(jieba.cut(x)) for x in train_x]test_x = [list(jieba.cut(x)) for x in test_x]train_x=drop_stopword(train_x)test_x=drop_stopword(test_x)save_data(train_x,'./train.txt')save_data(test_x,'./test.txt')print('Successfully')2.mian.py
import pandas as pd
import torch
from torch import nn
import jieba
from gensim.models import Word2Vec
import numpy as np
from data_set import load_tsv
from torch.utils.data import DataLoader, TensorDataset# 数据读取
def load_txt(path):with open(path,'r',encoding='utf-8') as f:data=[[line.strip()] for line in f.readlines()]return datatrain_x=load_txt('train.txt')
test_x=load_txt('test.txt')
train=train_x+test_x
X_all=[i for x in train for i in x]_, train_y = load_tsv("./data/train.tsv")
_, test_y = load_tsv("./data/test.tsv")
# 训练Word2Vec模型
word2vec_model = Word2Vec(sentences=X_all, vector_size=100, window=5, min_count=1, workers=4)# 将文本转换为Word2Vec向量表示
def text_to_vector(text):vector = [word2vec_model.wv[word] for word in text if word in word2vec_model.wv]return sum(vector) / len(vector) if vector else [0] * word2vec_model.vector_sizeX_train_w2v = [[text_to_vector(text)] for line in train_x for text in line]
X_test_w2v = [[text_to_vector(text)] for line in test_x for text in line]# 将词向量转换为PyTorch张量
X_train_array = np.array(X_train_w2v, dtype=np.float32)
X_train_tensor = torch.Tensor(X_train_array)
X_test_array = np.array(X_test_w2v, dtype=np.float32)
X_test_tensor = torch.Tensor(X_test_array)
#使用DataLoader打包文件
train_dataset = TensorDataset(X_train_tensor, torch.LongTensor(train_y))
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_dataset = TensorDataset(X_test_tensor,torch.LongTensor(test_y))
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=True)
# 定义LSTM模型
class LSTMModel(nn.Module):def __init__(self, input_size, hidden_size, output_size):super(LSTMModel, self).__init__()self.lstm = nn.LSTM(input_size, hidden_size, batch_first=True)self.fc = nn.Linear(hidden_size, output_size)def forward(self, x):lstm_out, _ = self.lstm(x)output = self.fc(lstm_out[:, -1, :]) # 取序列的最后一个输出return output# 定义模型
input_size = word2vec_model.vector_size
hidden_size = 50 # 你可以根据需要调整隐藏层大小
output_size = 2 # 输出的大小,根据你的任务而定model = LSTMModel(input_size, hidden_size, output_size)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss() # 交叉熵损失函数
optimizer = torch.optim.Adam(model.parameters(), lr=0.0002)if __name__ == "__main__":# 训练模型num_epochs = 10log_interval = 100 # 每隔100个批次输出一次日志loss_min=100for epoch in range(num_epochs):model.train()for batch_idx, (data, target) in enumerate(train_loader):outputs = model(data)loss = criterion(outputs, target)optimizer.zero_grad()loss.backward()optimizer.step()if batch_idx % log_interval == 0:print('Epoch [{}/{}], Batch [{}/{}], Loss: {:.4f}'.format(epoch + 1, num_epochs, batch_idx, len(train_loader), loss.item()))# 保存最佳模型if loss.item()<loss_min:loss_min=loss.item()torch.save(model, 'model.pth')# 模型评估with torch.no_grad():model.eval()correct = 0total = 0for data, target in test_loader:outputs = model(data)_, predicted = torch.max(outputs.data, 1)total += target.size(0)correct += (predicted == target).sum().item()accuracy = correct / totalprint('Test Accuracy: {:.2%}'.format(accuracy))3.test.py
import torch
import jieba
from torch import nn
from gensim.models import Word2Vec
import numpy as npclass LSTMModel(nn.Module):def __init__(self, input_size, hidden_size, output_size):super(LSTMModel, self).__init__()self.lstm = nn.LSTM(input_size, hidden_size, batch_first=True)self.fc = nn.Linear(hidden_size, output_size)def forward(self, x):lstm_out, _ = self.lstm(x)output = self.fc(lstm_out[:, -1, :]) # 取序列的最后一个输出return output# 数据读取
def load_txt(path):with open(path,'r',encoding='utf-8') as f:data=[[line.strip()] for line in f.readlines()]return data#去停用词
def drop_stopword(datas):# 假设你有一个函数用于预处理文本数据with open('./hit_stopwords.txt', 'r', encoding='UTF8') as f:stop_words = [word.strip() for word in f.readlines()]datas=[x for x in datas if x not in stop_words]return datasdef preprocess_text(text):text=list(jieba.cut(text))text=drop_stopword(text)return text# 将文本转换为Word2Vec向量表示
def text_to_vector(text):train_x = load_txt('train.txt')test_x = load_txt('test.txt')train = train_x + test_xX_all = [i for x in train for i in x]# 训练Word2Vec模型word2vec_model = Word2Vec(sentences=X_all, vector_size=100, window=5, min_count=1, workers=4)vector = [word2vec_model.wv[word] for word in text if word in word2vec_model.wv]return sum(vector) / len(vector) if vector else [0] * word2vec_model.vector_sizeif __name__ == '__main__':input_text = "这个车完全就是垃圾,又热又耗油"# input_text = "这个车我开了好几年,还是不错的"label = {1: "正面情绪", 0: "负面情绪"}model = torch.load('model.pth')# 预处理输入数据input_data = preprocess_text(input_text)# 确保输入词向量与模型维度和数据类型相同input_data=[[text_to_vector(input_data)]]input_arry= np.array(input_data, dtype=np.float32)input_tensor = torch.Tensor(input_arry)# 将输入数据传入模型with torch.no_grad():output = model(input_tensor)# 这里只一个简单的示例predicted_class = label[torch.argmax(output).item()]print(f"predicted_text:{input_text}")print(f"模型预测的类别: {predicted_class}")相关文章:
【自然语言处理(NLP)实战】LSTM网络实现中文文本情感分析(手把手与教学超详细)
目录 引言: 1.所有文件展示: 1.中文停用词数据(hit_stopwords.txt)来源于: 2.其中data数据集为chinese_text_cnn-master.zip提取出的文件。点击链接进入github,点击Code、Download ZIP即可下载。 2.安装依赖库&am…...

迭代新品 | 第四代可燃气体监测仪,守护燃气管网安全快人一步
城市地下市政基础设施是城市有序运行的生命线,事关城市安全、健康运行和高质量发展。近年来,我国燃气事故多发、频发。2020、2021、2022 年分别发生燃气事故668、1140 起、802 起,造成92、106、66 人死亡,560、763、487 人受伤。尤…...

【教3妹学编程-java基础6】详解父子类变量、代码块、构造函数执行顺序
-----------------第二天------------------------ 本文先论述父子类变量、代码块、构造函数执行顺序的结论, 然后通过举例论证,接着再扩展,彻底搞懂静态代码块、动态代码块、构造函数、父子类、类加载机制等知识体系。 温故而知新ÿ…...

深度学习中文汉字识别 计算机竞赛
文章目录 0 前言1 数据集合2 网络构建3 模型训练4 模型性能评估5 文字预测6 最后 0 前言 🔥 优质竞赛项目系列,今天要分享的是 🚩 深度学习中文汉字识别 该项目较为新颖,适合作为竞赛课题方向,学长非常推荐…...
从零开始 通义千问大模型本地化到阿里云通义千问API调用
从零开始 通义千问大模型本地化到阿里云通义千问API调用 一、通义千问大模型介绍 何为“通义千问”? “通义千问大模型”是阿里云推出的一个超大规模的语言模型,具有强大的归纳和理解能力,可以处理各种自然语言处理任务,包括但…...
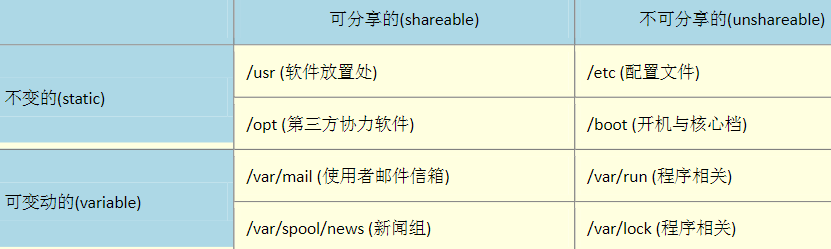
Linux(3):Linux 的文件权限与目录配置
把具有相同的账户放入到一个组里面,这个组就是这两个账户的 群组 。在访问资源(操作系统中计算机的资源)时,可以让这个组里面的所有用户都具有访问权限。 每个账号都可以有多个群组的支持。 在我们Liux 系统当中,默认的…...
Linux进程——exec族函数、exec族函数与fork函数的配合
exec族函数解析 作用 我们用fork函数创建新进程后,经常会在新进程中调用exec函数去执行另外一个程序。当进程调用exec函数时,该进程被完全替换为新程序。因为调用exec函数并不创建新进程,所以前后进程的ID并没有改变。 功能 在调用进程内部…...

客户端缓存技术
客户端缓存技术主要有以下几种: 内存缓存:客户端(如浏览器)会将请求到的资源(如HTML页面、图片文件等)存储在内存中,以便在再次访问相同资源时可以快速获取,减少向服务器的请求次数…...

Leetcode -2
Leetcode Leetcode -263.丑数Leetcode -268.丢失的数字 Leetcode -263.丑数 题目:丑数就是只包含质因数 2、3 和 5 的正整数。 给你一个整数 n ,请你判断 n 是否为 丑数 。如果是,返回 true ;否则,返回 false 。 示例…...
)
使用 DFS 轻松求解数独难题(C++ 的一个简单实现)
起因 都说懒惰是第一生产力,最近在玩数独游戏的时候,总会遇到拆解数独比较复杂的情况,就想着自己写个代码解题,解放双手。所以很快就写了一个简单的代码求解经典数独。拿来跑了几个最高难度的数独发现确实很爽!虽说是…...
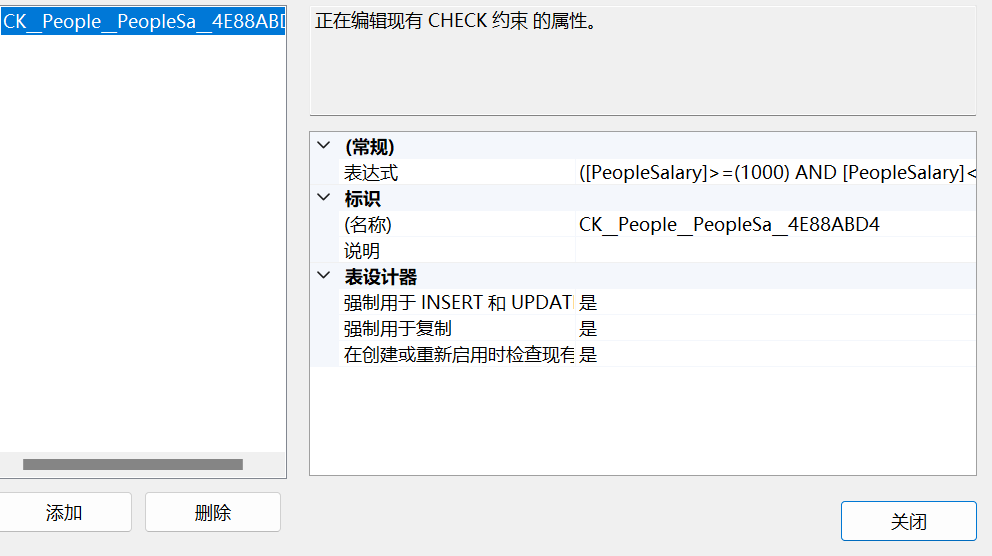
【SQL server】 表结构的约束和维护
表结构的约束和维护 修改表结构 (1)添加列 (2)删除列 (3)修改列alter table 表名 add 新列名 数据类型给员工表添加一列邮箱 alter table People add PeopleMail varchar(200)删除列 alter table People drop column PeopleMain修改列 alter table 表名 alter column 列名 数据…...

竞赛 题目:基于大数据的用户画像分析系统 数据分析 开题
文章目录 1 前言2 用户画像分析概述2.1 用户画像构建的相关技术2.2 标签体系2.3 标签优先级 3 实站 - 百货商场用户画像描述与价值分析3.1 数据格式3.2 数据预处理3.3 会员年龄构成3.4 订单占比 消费画像3.5 季度偏好画像3.6 会员用户画像与特征3.6.1 构建会员用户业务特征标签…...

Vue3-ref、reactive函数的watch
Vue3-ref、reactive函数的watch ref函数的watch 原理:监视某个属性的变化。当被监视的属性一旦发生改变时,执行某段代码。watch 属性中的数据需要具有响应式watch 属性可以使用箭头函数watch 属性可以监视一个或者多个响应式数据,并且可以配…...

【智能家居项目】FreeRTOS版本——多任务系统中使用DHT11 | 获取SNTP服务器时间 | 重新设计功能框架
🐱作者:一只大喵咪1201 🐱专栏:《智能家居项目》 🔥格言:你只管努力,剩下的交给时间! 目录 🍓多任务系统中使用DHT11🍅关闭调度器🍅使用中断 &am…...

鸿蒙APP外包开发需要注意的问题
在进行鸿蒙(HarmonyOS)应用开发时,开发者需要注意一些重要的问题,以确保应用的质量、性能和用户体验。以下是一些鸿蒙APP开发中需要特别关注的问题,希望对大家有所帮助。北京木奇移动技术有限公司,专业的软…...

Redis 19 事务
Redis通过MULTI、EXEC、WATCH等命令来实现事务(transaction)功能。事务提供了一种将多个命令请求打包,然后一次性、按顺序地执行多个命令的机制,并且在事务执行期间,服务器不会中断事务而改去执行其他客户端的命令请求…...

Fabric多机部署启动节点与合约部署
这是我搭建的fabric的网络拓扑 3 个 orderer 节点;组织 org1 , org1 下有两个 peer 节点, peer0 和 peer1; 组织 org2 , org2 下有两个 peer 节点, peer0 和 peer1; 以上是我的多机环境的网络拓扑,使用的是docker搭建的。我的网络…...
WordPress主题WoodMart v7.3.2 WooCommerce主题和谐汉化版下载
WordPress主题WoodMart v7.3.2 WooCommerce主题和谐汉化版下载 WoodMart是一款出色的WooCommerce商店主题,它不仅提供强大的电子商务功能,还与流行的Elementor页面编辑器插件完美兼容。 主题文件在WoodMart Theme/woodmart.7.3.2.zip,核心在P…...

Java 高等院校分析与推荐系统
1)项目简介 随着我国高等教育的大众化,高校毕业生就业碰到了前所未有的压力,高校学生就业问题开始进入相关研究者们的视野。在高校学生供给忽然急剧增加的同时,我国高校大学生的就业机制也在发生着深刻的变化,作为就业…...

Ubuntu服务器上配置KVM虚拟化环境:从零搭建Windows开发环境
1. 为什么要在Ubuntu服务器上跑Windows? 很多开发者可能都有这样的困惑:明明手头有性能强劲的Ubuntu服务器,但某些开发工具只能在Windows环境下运行。比如Visual Studio、SQL Server Management Studio这些微软系工具,或者某些行业…...

终极Hasklig字体完全指南:如何通过编程连字技术提升代码可读性
终极Hasklig字体完全指南:如何通过编程连字技术提升代码可读性 【免费下载链接】Hasklig Hasklig - a code font with monospaced ligatures 项目地址: https://gitcode.com/gh_mirrors/ha/Hasklig Hasklig是一款专为编程设计的等宽字体,通过创新…...

CTC语音唤醒模型在医疗语音录入系统中的应用案例
CTC语音唤醒模型在医疗语音录入系统中的应用案例 1. 引言 在医疗场景中,医生每天需要处理大量的病历记录工作。传统的手写或键盘输入方式不仅效率低下,还容易分散医生对患者的注意力。现在,通过CTC语音唤醒技术,医疗语音录入系统…...

CosyVoice3在CSDN星图一键部署:开箱即用,无需复杂配置
CosyVoice3在CSDN星图一键部署:开箱即用,无需复杂配置 1. 引言:语音克隆技术的新选择 你是否曾经想过,只需几秒钟的录音就能让AI完美复刻你的声音?或者为你的视频内容添加多种方言配音?CosyVoice3作为阿里…...

通义千问1.5-1.8B-Chat-GPTQ-Int4实战:构建智能软件测试用例生成器
通义千问1.5-1.8B-Chat-GPTQ-Int4实战:构建智能软件测试用例生成器 如果你是一名软件测试工程师,下面这个场景你一定不陌生:产品经理扔过来一份几十页的需求文档,或者开发同学更新了一个复杂的接口,而你需要在短时间内…...

别再手动飞了!用Python脚本一键操控AirSim无人机,实现自动巡航与悬停
用Python脚本全自动操控AirSim无人机:从基础巡航到复杂航线规划 在无人机仿真测试和算法开发中,手动控制不仅效率低下,更难以保证飞行动作的精确性和可重复性。想象一下,当你需要测试一个新型避障算法,或者采集特定飞行…...

为Jetson AGX添加自定义硬件:手把手编写设备树节点驱动LED与PPS
Jetson AGX硬件扩展实战:从设备树节点到LED与PPS驱动开发 在嵌入式开发领域,Jetson AGX Xavier凭借其强大的计算能力和丰富的接口资源,成为工业控制、机器人视觉等高性能场景的首选平台。但要让这块开发板真正发挥潜力,掌握自定义…...

OneMore图片编辑终极指南:无需外部工具裁剪旋转图像
OneMore图片编辑终极指南:无需外部工具裁剪旋转图像 【免费下载链接】OneMore A OneNote add-in with simple, yet powerful and useful features 项目地址: https://gitcode.com/gh_mirrors/on/OneMore OneMore是一款功能强大的OneNote插件,提供…...

Python内存暴涨突然崩溃?3个被90%开发者忽略的GC调优关键点揭秘
第一章:Python内存暴涨与崩溃的典型现象诊断当Python程序在运行中突然响应迟缓、频繁触发MemoryError,或进程被操作系统强制终止(如Linux下收到SIGKILL (9)),往往标志着内存使用已严重失控。这类问题通常不会立即暴露&…...

UE5 GAS调试技巧:巧用ASC的‘Attribute Test’面板,5分钟搞定角色属性配置与验证
UE5 GAS高效调试指南:利用Attribute Test面板快速验证角色属性配置 在虚幻引擎5的游戏开发中,Gameplay Ability System (GAS)作为构建复杂角色能力与属性的核心框架,其调试效率直接影响着RPG类项目的开发进度。本文将深入探讨如何利用Ability…...