客户端性能优化实践
背景
双十一大促时,客户客服那边反馈商品信息加载卡顿,在不断有订单咨询时,甚至出现了商品信息一直处于加载状态的情况,显然,在这种高峰期接待客户时,是没法进行正常的接待工作的。
起初,页面一直处于加载状态,初步认为是后端接口返回太慢导致,后经过后端日志排查,发现接口返回很快,根本不会造成页面一直处于加载状态,甚至出现卡死的状态。后经过不断排查,发现是客户端性能问题导致。
优化前
咨询订单时,只咨询一条订单,用时需要3秒左右,当连续咨询5、6条订单时,用时甚至达到了一分多钟,仅仅5、6条订单竟然用时这么久,那么在持续不断有订单咨询时,页面就会出现一直加载,甚至卡死的状态,明显存在很大的性能问题。
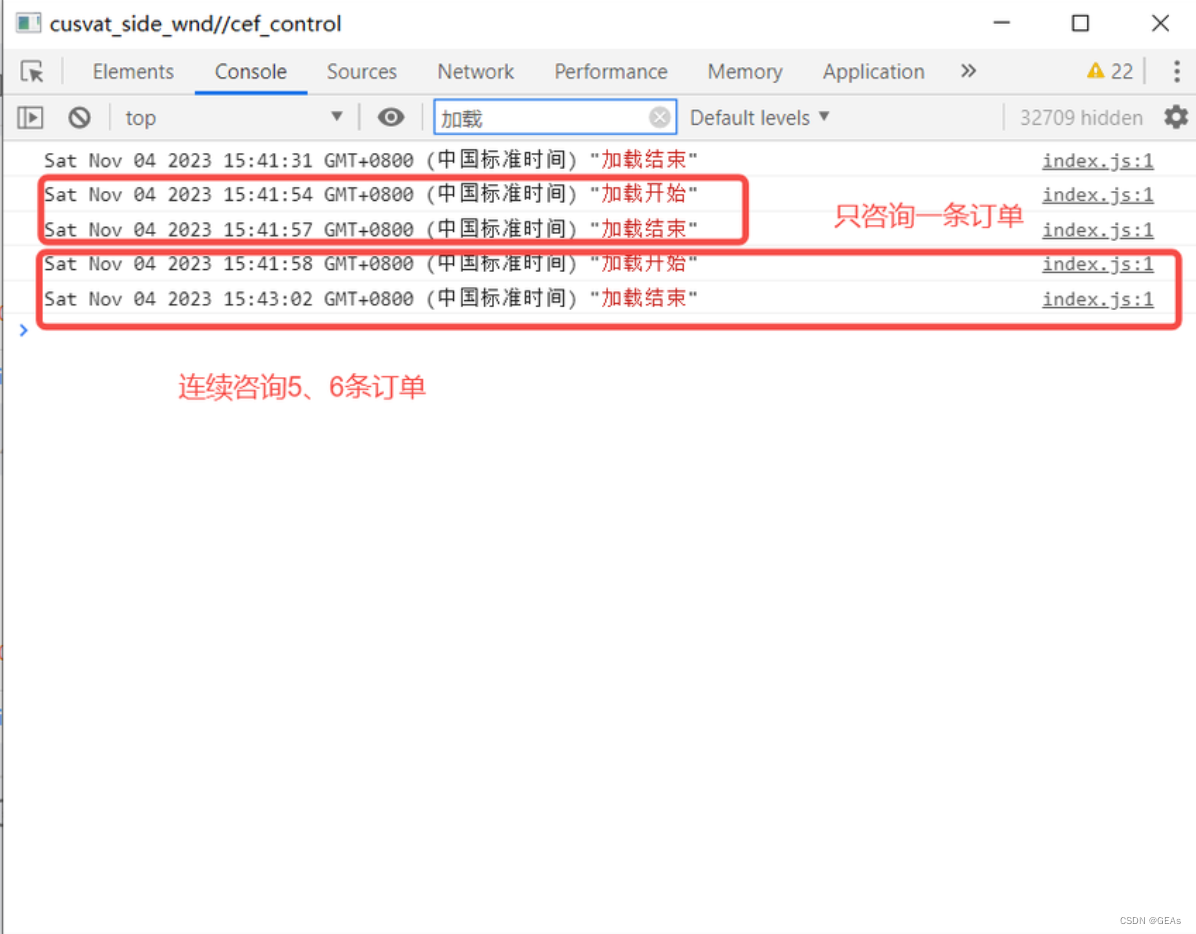

利用performance工具可以分析主线程的Event Loop,图中标出的Main就是主线程。
主线程是不断执行 Event Loop 的,可以看到有很多个 Task(宏任务),当主线程中的任务过多时,会导致主线程长时间被占用,无法及时响应用户的交互操作,从而影响用户体验。这种情况下,页面可能会出现卡顿、延迟响应等问题。
优化后
当只咨询一条订单时,用时需要1秒时间,连续咨询5、6条订单,用时优化到只需要3秒时间,并且页面流畅,对于用户体验上得到了明显的提升。
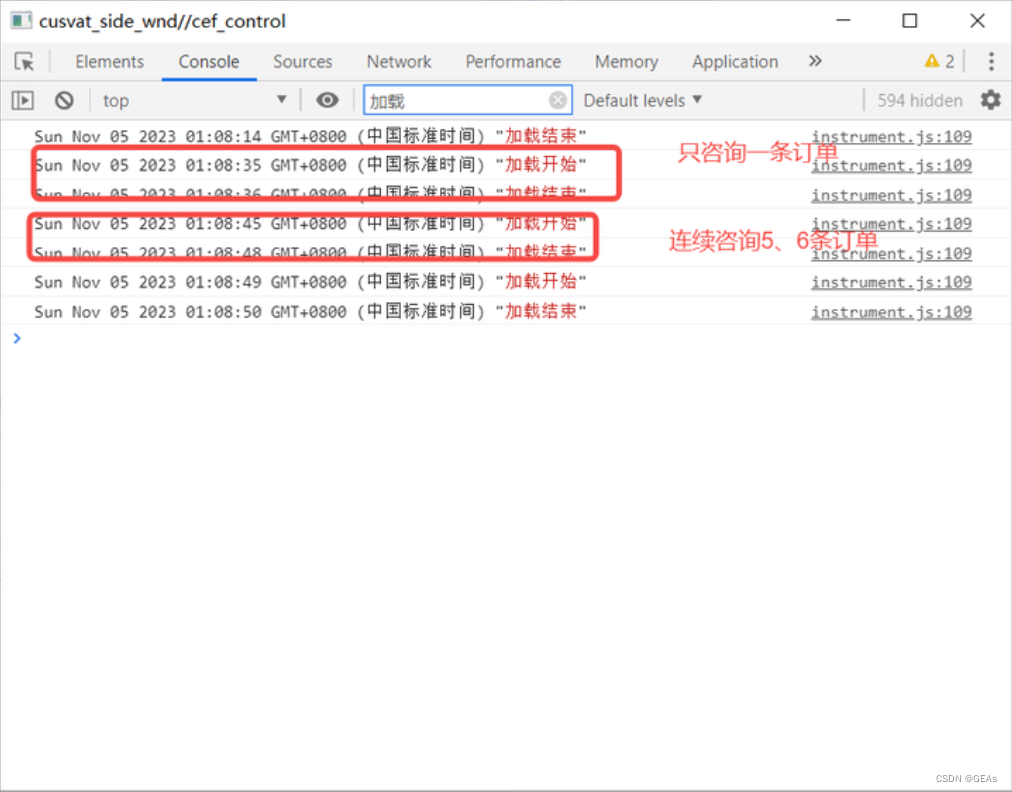
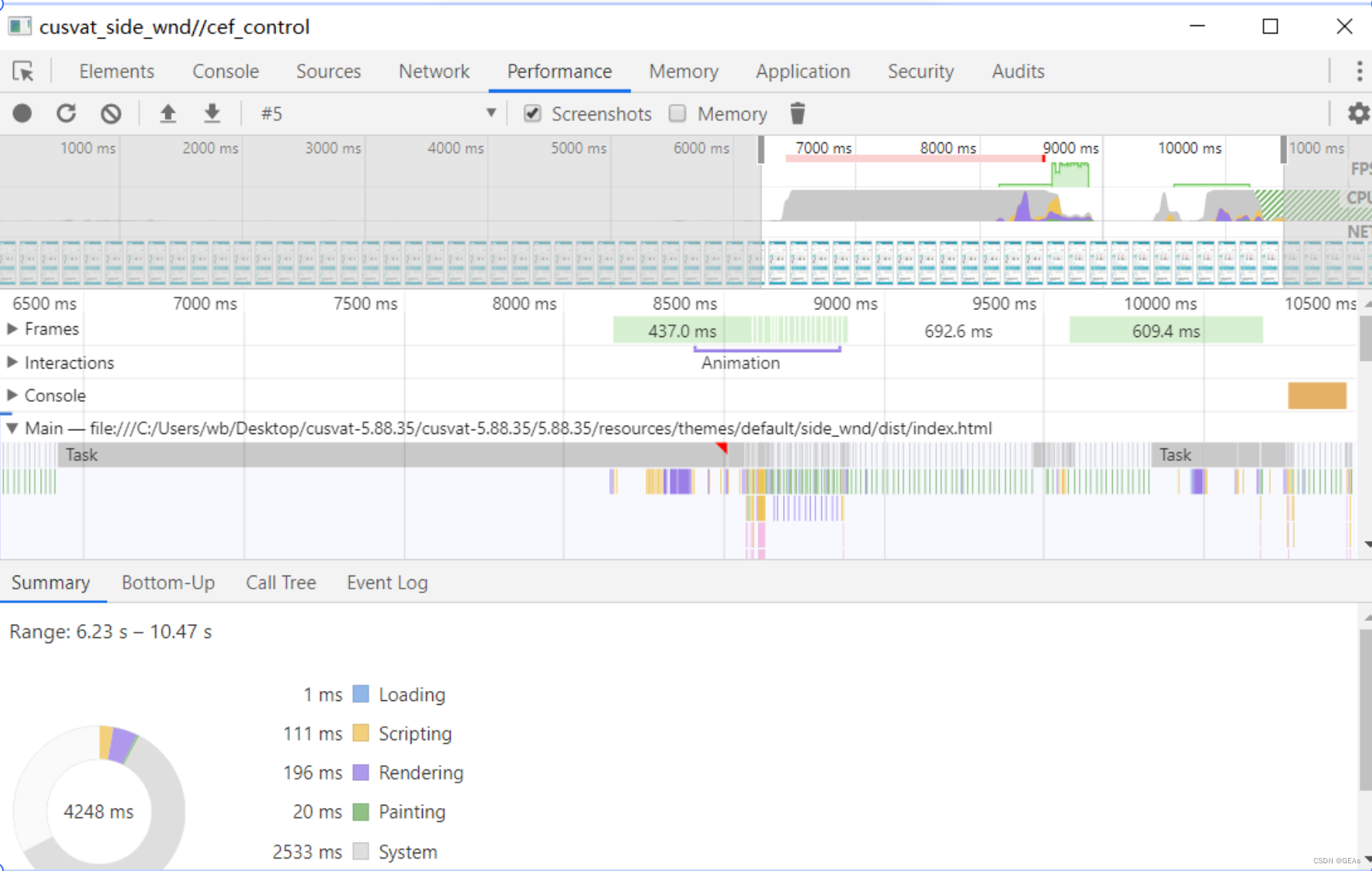
可以看出long task 减少了很多。
那么,如何来优化呢?请看下面的内容。
优化点
在合适的时机进行组件渲染
在排查代码的过程中发现,很多本不该当前状态渲染的组件,都渲染出来了,显然这是不合理的。过多的组件渲染会占用大量的内存,并且也会增加页面的渲染时间,自然,响应性能就会变得很差,用户与页面的交互就会变得迟缓。
而商品信息加载部分最常见的不必要的组件渲染表现在使用Modal弹窗时,我们都知道当visible为true时,会弹出弹窗相应的页面内容,但是当visible为false时,其实是不希望渲染Modal弹窗中的内容的,这会带来额外的性能开销。
下面是一些示例:
- ...
- <Modal
- ...
- visible={editVisible}
- ...>
- ...
- </Modal>
- ...
+ {editVisible && (
+ <GoodsAttributeModal
+ editVisible
+ ...
+ />
+ )}
// 把Modal弹窗作为一个单独组件提取出去,并且只有当editVisible为true时才渲染组件
第一段代码中,使用了visible={editVisible}来控制Modal组件的显示与隐藏。当editVisible为true时,Modal组件会被渲染出来,否则不会被渲染。
第二段代码中,使用了条件渲染的方式,即通过{editVisible && …}来判断是否渲染Modal组件。当editVisible为true时,Modal组件会被渲染出来,否则不会被渲染。
这两种方式的主要区别在于组件的渲染时机。在第一种方式中,Modal组件在每次渲染时都会被创建和销毁,而在第二种方式中,只有在editVisible为true时才会创建和渲染Modal组件。
使用条件渲染的方式可以提高性能,特别是在组件层级较深或渲染频繁的情况下。因为只有在需要显示Modal组件时才会进行渲染,避免了不必要的组件创建和销毁,减少了内存消耗和渲染时间。
总结起来,使用条件渲染的方式可以根据需要动态地控制组件的显示与隐藏,提高性能和用户体验。
使用useCallback、useMemo、React.memo提升性能
下面是一些示例:
useCallback
- renderContent = (content, searchKey) => {
- if(content) {
- const contentWithBr = content.replace(/\↵/g, '<br>').replace(/\n/g, '<br>')
- const regex = new RegExp(`(${searchKey})`, 'gi'); // 创建正则表达式,忽略大小写匹配
- const matches = content.match(regex) || []; // 匹配结果数组
- return (
- <React.Fragment>
- {contentWithBr.split('<br>').map((text, index) => (
- <React.Fragment key={index}>
- {index > 0 && <br />}
- {text.split(regex).map((subText, subIndex) => {
- // console.log('subText',subText,matches)
- return (
- <React.Fragment key={subIndex}>
- {matches.includes(subText) ? (
- <span style={{ color: '#FF8800' }}>{subText}</span>
- ) : (
- subText
- )}
- </React.Fragment>
- )
- })}
- </React.Fragment>
- ))}
- </React.Fragment>
- )
- } else {
- return '-'
- }
- }+ const renderContent = useCallback((content, searchKey) => {
+ if (content) {
+ const contentWithBr = content.replace(/\↵/g, '<br>').replace(/\n/g, '<br>')
+ const regex = new RegExp(`(${searchKey})`, 'gi') // 创建正则表达式,忽略大小写匹配
+ const matches = content.match(regex) || [] // 匹配结果数组
+ return (
+ <React.Fragment>
+ {contentWithBr.split('<br>').map((text, index) => (
+ <React.Fragment key={index}>
+ {index > 0 && <br />}
+ {text.split(regex).map((subText, subIndex) => {
+ //console.log('subText',subText,matches)
+ return (
+ <React.Fragment key={subIndex}>
+ {matches.includes(subText) ? (
+ <span style={{ color: '#FF8800' }}>{subText}</span>
+ ) : (
+ subText
+ )}
+ </React.Fragment>
+ )
+ })}
+ </React.Fragment>
+ ))}
+ </React.Fragment>
+ )
+ } else {
+ return '-'
+ }
+ }, [])
上面的代码使用了React的useCallback钩子函数来定义了一个名为renderContent的函数。useCallback的作用是用来缓存函数,以便在依赖项不变的情况下避免函数的重新创建。
使用useCallback的好处是可以优化性能,特别是在父组件重新渲染时,避免不必要的函数重新创建。当依赖项数组为空时,useCallback会在组件的初始渲染时创建函数,并在后续的渲染中重复使用同一个函数。
而没有使用useCallback的情况下,每次组件重新渲染时都会创建一个新的renderContent函数,即使函数的实现逻辑完全相同。这可能会导致性能问题,特别是在组件层级较深或渲染频繁的情况下。
因此,使用useCallback可以提高组件的性能,避免不必要的函数创建和内存消耗。但需要注意的是,只有在确实需要缓存函数并且依赖项不变的情况下才使用useCallback,否则可能会导致不必要的优化和错误。
useMemo
- const tooltip = (
- <div>
- <h2>
- <span className={styles.title}>{title}</span>
- {
- !window.isVisibleGoods && (
- <span>
- {renderKnowledgeModal({
- label: '编辑',
- record: item,
- platGoodsId: plat_goods_id,
- classification_id: classificationId,
- })}
- <a
- className={styles.delete}
- onClick={() => handleDeleteKnowledage(item, classificationId)}
- >
- 删除
- </a>
- </span>
- )
- }
- </h2>
- <div className={styles.img_block}>{images}</div>
- <div
- className={classnames(styles.context, styles.tooltipsContext)}
- dangerouslySetInnerHTML={{ __html: ParseBrow.parse(context) }}
- />
- </div>
- )
+ const tooltip = useMemo(
+ () => (
+ <div>
+ <h2>
+ <span className={styles.title}>{title}</span>
+ {!isVisibleGoods && (
+ <span>
+ {renderKnowledgeModal({
+ label: '编辑',
+ record: item,
+ platGoodsId: plat_goods_id,
+ classification_id: classificationId,
+ })}
+ <a
+ className={styles.delete}
+ onClick={() => handleDeleteKnowledage(item, classificationId)}
+ >
+ 删除
+ </a>
+ </span>
+ )}
+ </h2>
+ <div className={styles.img_block}>{images}</div>
+ <div
+ className={classnames(styles.context, styles.tooltipsContext)}
+ dangerouslySetInnerHTML={{ __html: ParseBrow.parse(context) }}
+ />
+ </div>
+ ),
+ [
+ title,
+ renderKnowledgeModal,
+ item,
+ plat_goods_id,
+ classificationId,
+ images,
+ context,
+ handleDeleteKnowledage,
+ isVisibleGoods,
+ ]
+ )
在上面的代码中,使用了useMemo来缓存了一个变量tooltip的计算结果。这个计算结果是一个React元素,包含了一些子元素和事件处理函数等。通过将tooltip作为依赖数组的一部分,当依赖数组中的值发生变化时,useMemo会重新计算tooltip的值;如果依赖数组中的值没有发生变化,则直接返回上一次缓存的tooltip的值。
这样做的好处是,当依赖数组中的值没有发生变化时,可以避免重复计算tooltip的值,提高组件的性能。而如果依赖数组中的值发生变化,useMemo会重新计算tooltip的值,确保tooltip的值是最新的。
相比之下,如果不使用useMemo,每次组件重新渲染时都会重新计算tooltip的值,即使依赖数组中的值没有发生变化,这样会造成不必要的性能损耗。
总结起来,使用useMemo可以优化组件的性能,避免不必要的计算。但是需要注意的是,只有在计算的成本比较高时才需要使用useMemo,否则可能会带来额外的开销
React.memo
- export default Item
+ import { isEqual } from 'lodash'
+ export default React.memo(Item, isEqual)
export default Item 直接导出组件,每次父组件重新渲染都会重新渲染 Item 组件;
而 export default React.memo(Item, isEqual) 使用 React.memo 进行包裹,并传入自定义的比较函数 isEqual,只有在 props 发生变化且通过 isEqual 函数比较不相等时才会重新渲染 Item 组件。
注意:自定义的比较函数 isEqual 用于比较两个 props 是否相等。如果不传入比较函数,则默认使用浅比较(即 Object.is)来比较 props。如果传入了比较函数,则会使用该函数来比较 props。
props解构变量时的默认值
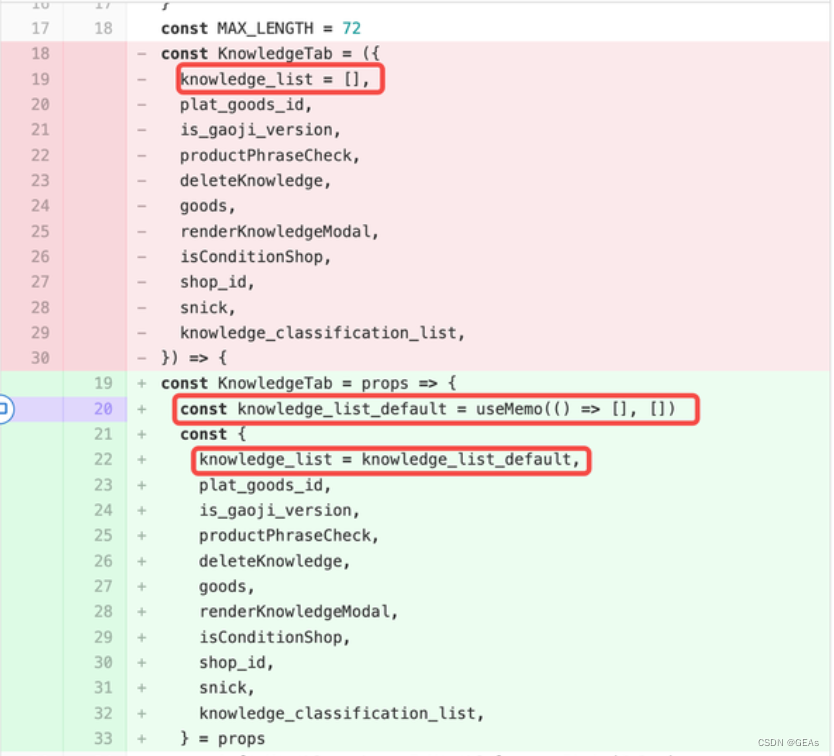
在这段代码中,KnowledgeTab是一个使用了React.memo进行优化的组件。React.memo是一个高阶组件,用于对组件进行浅层比较,以确定是否需要重新渲染组件。当组件的props没有发生变化时,React.memo会返回之前渲染的结果,从而避免不必要的重新渲染。
在KnowledgeTab组件中,knowledge_list是一个从props中解构出来的属性。而const knowledge_list_default = useMemo(() => [], [])是使用useMemo钩子函数创建的一个空数组。这样做的目的是为了在组件的初始渲染时,给knowledge_list一个默认值,以避免在解构时出现undefined的情况。
如果直接使用knowledge_list=[]来给knowledge_list赋值,会破坏React.memo的优化。因为每次父组件重新渲染时,knowledge_list都会被重新创建,即使它的值没有发生变化。这样会导致KnowledgeTab组件的props发生变化,从而触发不必要的重新渲染。
而使用useMemo创建一个空数组作为默认值,可以保证在父组件重新渲染时,knowledge_list_default的引用不会发生变化,从而避免不必要的重新渲染。这样就能够保持React.memo的优化效果,只有在knowledge_list的值真正发生变化时才会重新渲染KnowledgeTab组件。
所以,总结起来就是默认值如果传给子组件,父组件每一次更新都会导致子组件更新,导致子组件的React.memo失效
拆分为状态自治的独立组件
当一个组件的代码变得复杂或包含大量的子组件时,可以考虑将其中的一部分代码抽取为一个独立的子组件。这样做的好处是可以将复杂的逻辑拆分为多个小组件,提高代码的可读性和可维护性。
同时,抽取组件也可以配合使用React.memo进行优化。
下面是一个抽取独立组件的例子
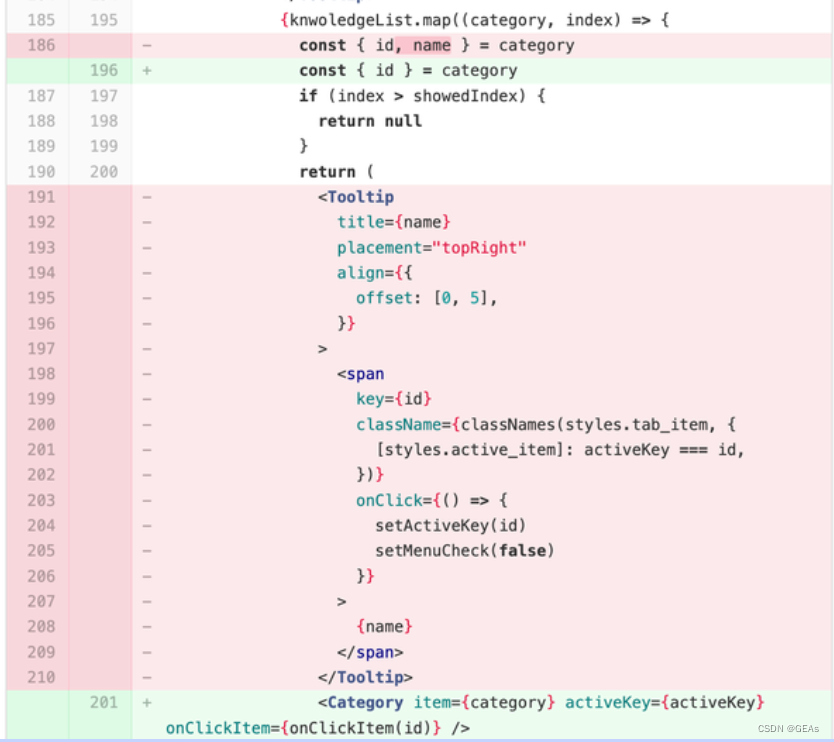
import React, { memo } from 'react'
import { Tooltip } from 'antd'
import classNames from 'classnames'
import Item from './item'
import styles from '../../index.less'interface Item {name: stringid: string
}
interface CategoryProps {item: ItemactiveKey: stringonClickItem: () => void
}
const Category: React.FC<CategoryProps> = props => {const { item, activeKey, onClickItem } = propsconst { name, id } = itemreturn (<Tooltiptitle={name}placement="topRight"align={{offset: [0, 5],}}><spankey={id}className={classNames(styles.tab_item, {[styles.active_item]: activeKey === id,})}onClick={onClickItem}>{name}</span></Tooltip>)
}export default memo(Category)
相关文章:
客户端性能优化实践
背景 双十一大促时,客户客服那边反馈商品信息加载卡顿,在不断有订单咨询时,甚至出现了商品信息一直处于加载状态的情况,显然,在这种高峰期接待客户时,是没法进行正常的接待工作的。 起初,页面一…...

mysql使用--表达式和函数
1.表达式 如:11,一般包含操作数,运算符。 _1.操作数 MYSQL中最常用的操作数有以下几种 (1).常数 (2).列名,针对某个具体的表,它的列名可被当作表达式的一部分 (3).函数调用 一个函数用于完成某个特定的功能。比如NOW()…...
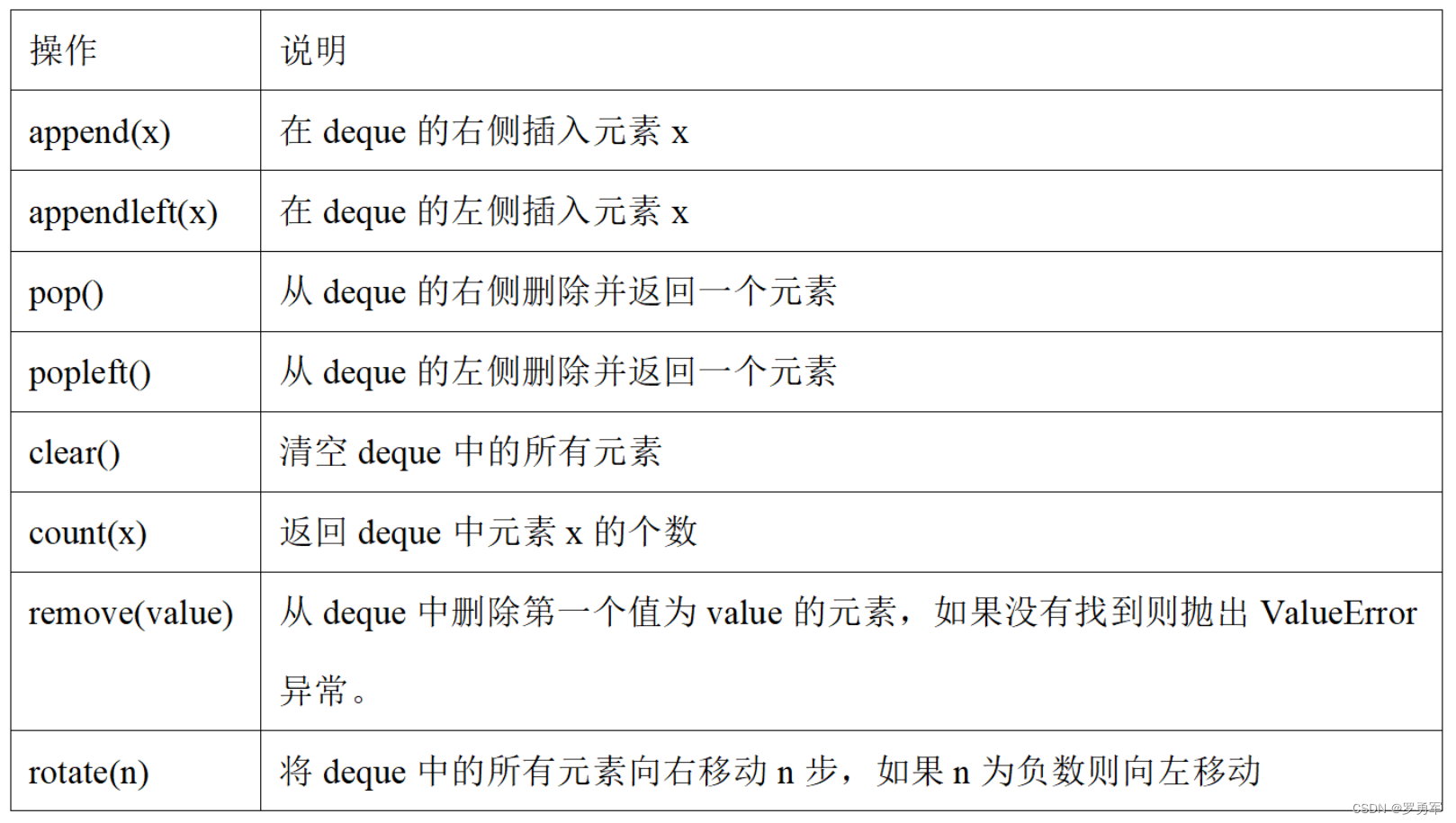
<蓝桥杯软件赛>零基础备赛20周--第6周--数组和队列
报名明年4月蓝桥杯软件赛的同学们,如果你是大一零基础,目前懵懂中,不知该怎么办,可以看看本博客系列:备赛20周合集 20周的完整安排请点击:20周计划 每周发1个博客,共20周(读者可以按…...

软件开发、网络空间安全、人工智能三个方向的就业和前景怎么样?哪个方向更值得学习?
软件开发、网络空间安全、人工智能这三个方向都是当前及未来的热门领域,每个领域都有各自的就业前景和价值,以下是对这三个方向的分析: 1、软件开发: 就业前景:随着信息化的加速,软件开发的需求日益增长。…...

新增文章分类
pojo.Category package com.lin.springboot01.pojo;import jakarta.validation.constraints.NotEmpty; import lombok.Data;import java.time.LocalDateTime;Data public class Category {private Integer id;//主键NotEmptyprivate String categoryName;//分类名称NotEmptypr…...

选硬币该用动态规划
选硬币: 现有面值分别为1角1分,5分,1分的硬币,请给出找1角5分钱的最佳方案。 #include <iostream> #include <vector>std::vector<int> findChange(int amount) {std::vector<int> coins {11, 5, 1}; /…...

LeetCode 2342. 数位和相等数对的最大和:哈希表
【LetMeFly】2342.数位和相等数对的最大和:哈希表 力扣题目链接:https://leetcode.cn/problems/max-sum-of-a-pair-with-equal-sum-of-digits/ 给你一个下标从 0 开始的数组 nums ,数组中的元素都是 正 整数。请你选出两个下标 i 和 j&…...
Vulkan渲染引擎开发教程 一、开发环境搭建
一 安装 Vulkan SDK Vulkan SDK 就是我们要搞的图形接口 首先到官网下载SDK并安装 https://vulkan.lunarg.com/sdk/home 二 安装 GLFW 窗口库 GLFW是个跨平台的小型窗口库,也就是显示窗口,图形的载体 去主页下载并安装,https://www.glfw.…...
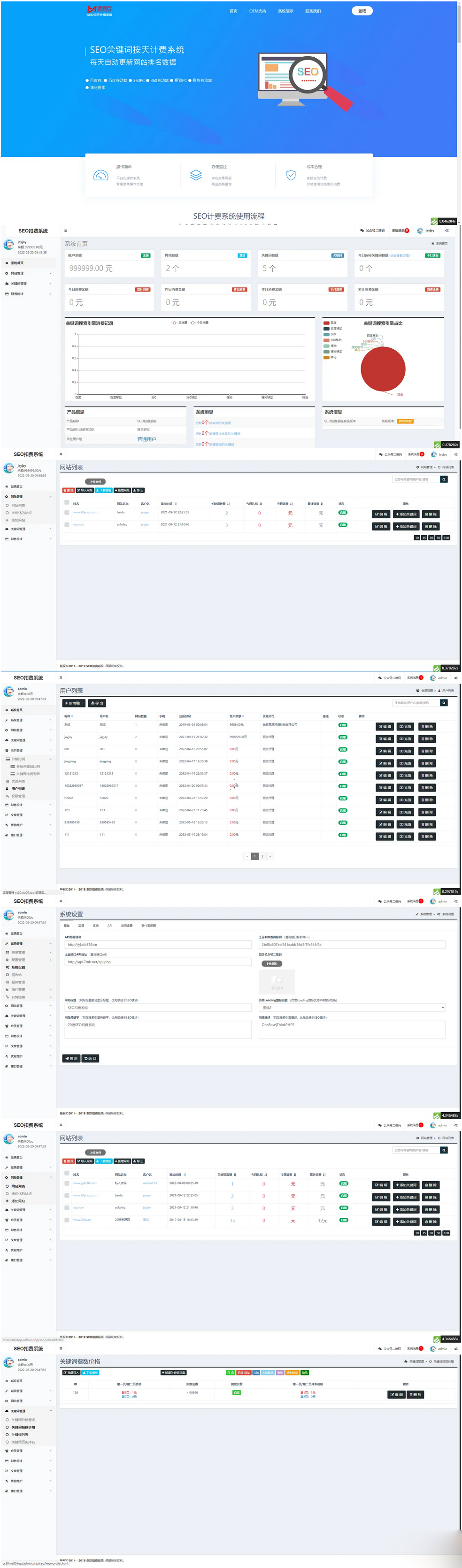
(带教程)商业版SEO关键词按天计费系统:关键词排名优化、代理服务、手机自适应及搭建教程
源码简介: 1、会员管理: 该系统分为三个级别的会员流程:总站管理员、代理与会员(会员有普通会员、中级会员和高级会员三个等级)。总站管理员可以添加代理用户并为其充值余额,代理用户可以为普通用户充值余…...
IDEA 快捷键汇总
目录 1、altinsert 2、ctrl/ 3、altenter 4、alt回车 5、ctrlD 6、ctrlaltL 7、ctrl点击 8、alt左键向下拉 9、ctrlaltv 10、ctrlaltwint 1、altinsert 快速创建代码,可以快速创建类中get set tostring等方法 2、ctrl/ 单行注释 3、altenter…...

目标检测YOLO实战应用案例100讲-基于机器视觉的水稻病虫害监测预警
目录 前言 国内外研究现状 国外研究现状 国内研究现状 2 相关理论与技术...

OrthoNets:正交信道注意网络
文章目录 摘要1、简介2、相关工作3、方法4、实验设置及结果5、论述6、结论摘要 链接:https://arxiv.org/pdf/2311.03071v2.pdf 设计有效的通道注意力机制要求人们找到一种有损压缩方法,以实现最佳特征表示。尽管该领域近年来取得了进展,但仍然存在一个未解决的问题。FcaNet…...
C_12练习题
一、单项选择题(本大题共20小题,每小题2分,共40分。在每小题给出的四个备选项中,选出一个正确的答案,并将所选项前的字母填写在答题纸的相应位置上。) C 风格的注释,也称块注释或多行注释,以()…...

导航守卫有哪三种?
导航守卫主要分为三种: 全局前置守卫:使用 router.beforeEach 注册,作用是在路由切换开始前进行拦截和处理,可以用来进行一些全局的权限校验、登录状态检查等操作。 全局解析守卫:使用 beforeResolve 注册,…...

强烈 推荐 13 个 Web前端在线代码IDE
codesandbox.io(国外,提供免费空间) 网址:https://codesandbox.io/ CodeSandbox 专注于构建完整的 Web 应用程序,支持多种流行的前端框架和库,例如 React、Vue 和 Angular。它提供了一系列增强的功能&…...

网络协议 WebSocket
一、介绍 WebSocket 是基于 TCP 的一种新的网络协议。它实现了浏览器与服务器全双工通信——浏览器和服务器只需要完成一次握手,两者之间就可以创建持久性的连接, 并进行双向数据传输 1、HTTP协议和WebSocket协议对比 HTTP 是短连接WebSocket 是长连接H…...

路径操作 合法路径名
python中路径的三种合法表示:在路径前面加上r、分隔符使用/。 在路径前面加上r python中在前面加上r,是防止字符转义。 例如:这样一个路径: \Undergraduate\School\Programme\Python_Learnpython会将这个字符串的**\和\后面的…...

JavaEE初阶 01 计算机是如何工作的
前言 今天开始进行对JavaEE的一些基本总结,希望大家能在阅读中有所收获,如有错误还望多多指正. 1.冯诺依曼体系结构 这个体系结构相信学计算机的同学都不陌生,但是你真的知道这个体系结构说的是什么嘛?请听我娓娓道来.首先我先给出一张冯诺依曼体系结构的简图 你可以理解为当前…...

【shell 常用脚本30例】
先了解下编写Shell过程中注意事项 开头加解释器:#!/bin/bash语法缩进,使用四个空格;多加注释说明。命名建议规则:全局变量名大写、局部变量小写,函数名小写,名字体现出实际作用。默认变量是全局的…...

【我和Python算法的初相遇】——体验递归的可视化篇
🌈个人主页: Aileen_0v0 🔥系列专栏:PYTHON数据结构与算法学习系列专栏💫"没有罗马,那就自己创造罗马~" 目录 递归的起源 什么是递归? 利用递归解决列表求和问题 递归三定律 递归应用-整数转换为任意进制数 递归可视化 画…...

AI原生应用中的个性化推荐算法实战解析
AI原生应用中的个性化推荐算法实战解析 关键词:AI原生应用、个性化推荐、协同过滤、深度学习推荐模型、冷启动问题 摘要:在AI技术深度渗透的今天,“AI原生应用”(AI Native Apps)已从概念走向落地。这类应用的核心特征…...

如何高效使用开源OCR工具:Umi-OCR专业部署与实战应用指南
如何高效使用开源OCR工具:Umi-OCR专业部署与实战应用指南 【免费下载链接】Umi-OCR Umi-OCR: 这是一个免费、开源、可批量处理的离线OCR软件,适用于Windows系统,支持截图OCR、批量OCR、二维码识别等功能。 项目地址: https://gitcode.com/G…...

Nano语法高亮配置最佳实践:基于nanorc项目的经验分享
Nano语法高亮配置最佳实践:基于nanorc项目的经验分享 【免费下载链接】nanorc Improved Nano Syntax Highlighting Files 项目地址: https://gitcode.com/gh_mirrors/na/nanorc Nano语法高亮配置是提升命令行文本编辑体验的关键技巧。如果你经常使用Nano编辑…...

终极指南:如何自定义 rust-analyzer 扩展功能与插件开发
终极指南:如何自定义 rust-analyzer 扩展功能与插件开发 【免费下载链接】rust-analyzer A Rust compiler front-end for IDEs 项目地址: https://gitcode.com/gh_mirrors/ru/rust-analyzer rust-analyzer 是一款强大的 Rust 编译器前端工具,专为…...

5大空间回收功能解决存储焦虑:Czkawka的极速扫描技术革命
5大空间回收功能解决存储焦虑:Czkawka的极速扫描技术革命 【免费下载链接】czkawka 一款跨平台的重复文件查找工具,可用于清理硬盘中的重复文件、相似图片、零字节文件等。它以高效、易用为特点,帮助用户释放存储空间。 项目地址: https://…...

正铲单斗液压挖掘机工作装置设计【课程设计说明书+CAD图纸+Creo三维】
正铲单斗液压挖掘机工作装置是土方工程中的核心执行部件,其设计质量直接影响挖掘效率、作业稳定性及设备寿命。该装置主要由动臂、斗杆、铲斗及液压缸等关键零件构成,通过液压系统驱动实现挖掘、提升、卸料等动作。设计过程中需重点考虑力学性能优化、结…...
)
手把手解决Simulink与贝加莱Automation Studio联调的5个典型报错(附详细截图)
手把手解决Simulink与贝加莱Automation Studio联调的5个典型报错(附详细截图) 在工业自动化领域,Simulink与贝加莱PLC的联合开发已经成为复杂控制系统设计的黄金组合。但当你满怀期待地将精心设计的Simulink模型转换为Automation Studio可执行…...

如何用铜钟音乐打造纯粹听歌体验?5个让你告别广告干扰的核心优势
如何用铜钟音乐打造纯粹听歌体验?5个让你告别广告干扰的核心优势 【免费下载链接】tonzhon-music 铜钟 (Tonzhon.com): 免费听歌; 没有直播, 社交, 广告, 干扰; 简洁纯粹, 资源丰富, 体验独特!(密码重置功能已回归) 项目地址: https://gitcode.com/Git…...

DDrawCompat:现代Windows系统下的经典图形API兼容解决方案
DDrawCompat:现代Windows系统下的经典图形API兼容解决方案 【免费下载链接】DDrawCompat DirectDraw and Direct3D 1-7 compatibility, performance and visual enhancements for Windows Vista, 7, 8, 10 and 11 项目地址: https://gitcode.com/gh_mirrors/dd/DD…...

Verilog新手避坑指南:从HDLBits的Getting Started到Vectors,我踩过的那些坑
Verilog新手避坑指南:从HDLBits的Getting Started到Vectors,我踩过的那些坑 第一次接触Verilog时,我像大多数初学者一样,被它既像C语言又不像C语言的语法搞得晕头转向。HDLBits这个在线练习平台确实是个好帮手,但当我从…...