c语言-数据结构-堆
目录
一、二叉树
1、二叉树的概念
2、完全二叉树和满二叉树
3、完全二叉树的顺序存储
二、堆
2、堆的概念与结构
3、堆的创建及初始化
4、堆的插入(小堆)
5、堆的删除
6、显示堆顶元素
7、显示堆里的元素个数
8、测试堆的各个功能
9、 实现堆排序
三、TOP-K的实现
结语:
前言:
堆是数据结构中是很重要的一个知识点,通常用于实现堆排序, 比如在生活中我们要算出考试成绩的前十名,或者游戏排名的前一百名,这种场景下就用到堆排序了。堆其实是相同类型元素的集合,通常用数组的形式表示一个堆,数组内的所有元素都按照完全二叉树的形式进行存储,这时候又引出了二叉树的概念,只要明白了完全二叉树的概念就明白了什么是堆,因此下面先介绍二叉树的基本概念。
一、二叉树
1、二叉树的概念
二叉树的根节点由一个左子树和一个右子树构成,也就是每一个结点可以少于两个孩子结点但是不能多于两个孩子结点,示意图如下:

如上图,D可以是A的孩子结点,同时D也可以是H的父母节点,D同时也是E的兄弟节点,一个结点可以拥有多重身份。如果一棵树中的任意一个结点有超过2个孩子结点那么该树就不是一个二叉树,二叉树的其他情况如下:
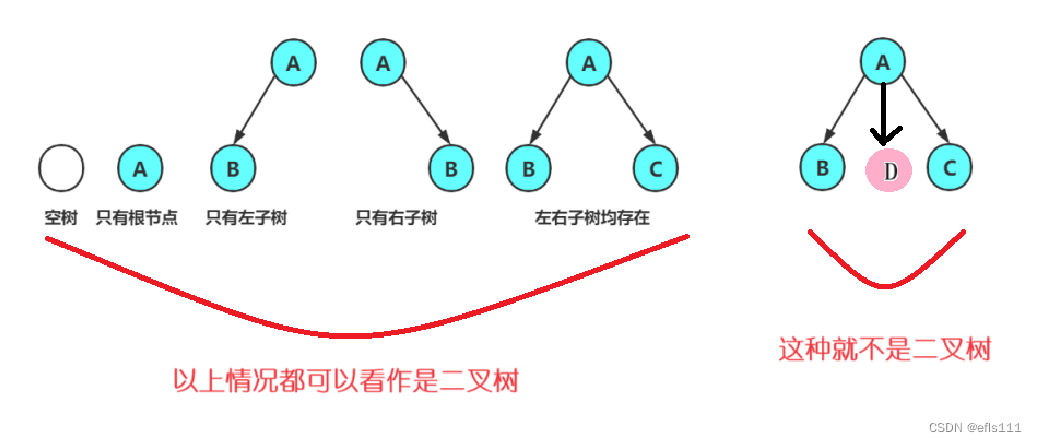
2、完全二叉树和满二叉树
一颗二叉树的每一层的结点都是满的,将该二叉树称为满二叉树,完全二叉树则是在满二叉树的概念上引申而来的,即满二叉树的最后一层的结点可以不是满的,但是二叉树中的所有结点从左到右必须是按照顺序排序的,示意图如下:
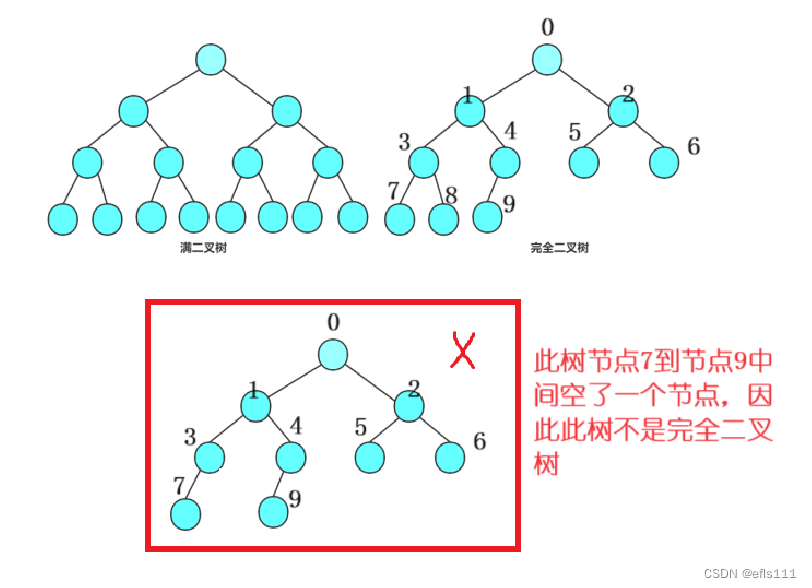
因此可以看出完全二叉树的一个特点:即每个节点必须是按照顺序进行存储的,即完全二叉树具有顺序性。
3、完全二叉树的顺序存储
我们知道数组是一块连续的空间,而且数组里的元素都是“紧挨着”的,即不存在第一个元素和第三个元素中间空了位置不存储任何数据,这么做不符合逻辑也很浪费空间。由此看来,数组和完全二叉树的特点非常相似。

因此一个完全二叉树可以用数组的形式表示出来,只要是一个数组就是一个完全二叉树。并且有了父母结点的下标就可以找到他的孩子结点,有了孩子的结点就能找到其父母结点的下标。
比如有了结点B的下标,可以找到他的左右两个孩子结点的下标:左孩子D的下标=B的下标*2+1,右孩子E的下标=B的下标*2+2。
B的父母结点A坐标=(B坐标-1)/2。
二、堆
2、堆的概念与结构
堆是一个完全二叉树,但是他在完全二叉树的基本要求上增加了以下条件:树里任意一个父母结点都大于等于(或小于等于)他们的孩子结点,因此堆分为两种情况:大堆和小堆。
大堆:从根节点开始,从上至下每个父亲结点必须大于他的两个孩子结点。
小堆:从根节点开始,从上至下每个父亲结点必须小于他的两个孩子结点。
示意图如下:
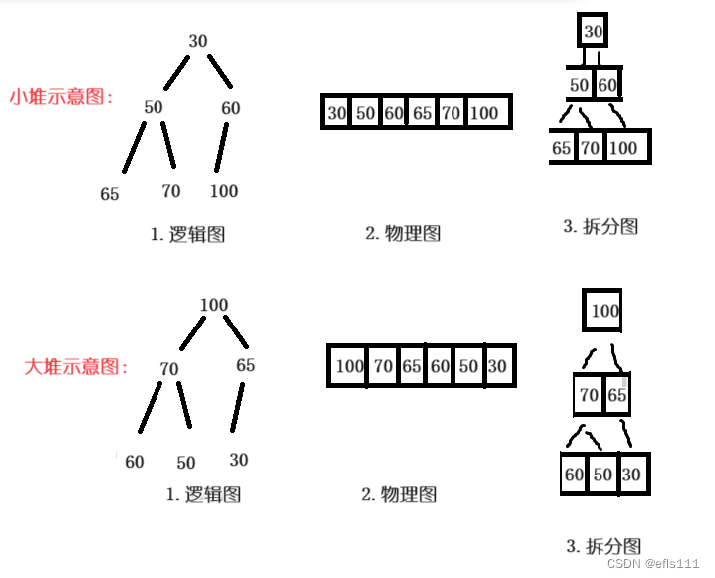
因此从以上的分析来看,可以得出以下结论:数组其实就可以看成是一个完全二叉树,但是不一定是堆,但是是堆就一定是完全二叉树。而且即使是小堆也不一定是升序,大堆也不一定是降序(这里只是偶然)。当然,有序的数组一定是堆。
接下来用代码建立一个小堆。
3、堆的创建及初始化
从以上得知,堆的本质是数组,因此堆的创建代码如下:
typedef int HeapDataType;//int类型重定义
typedef struct Heap
{HeapDataType* arr;//指针arr,即数组名表示数组的首地址int size;//数组的元素个数int capacity;//数组的容量
}Heap;堆初始化代码如下:
void HeapInit(Heap* php)//初始化
{assert(php);php->arr = NULL;//置为空php->size = 0;//刚开始没有元素因此为0php->capacity = 0;
}4、堆的插入(小堆)
原理就是把数据插入到数组中,所以在数组的末尾处添加数据即可,但是单单的插入数据并不能满足大堆和小堆的条件,因此每插入一个数据都要对数组进行调整,以便然数组满足小堆的条件。
然而从数组的末尾处插入元素,从完全二叉树的角度来看,就是从树的最后一个结点插入元素,因此对数组进行调整其实就是调整插入元素与其父母结点的一个大小关系。插入最后一个结点的时候进行对树的调整的,该调整法称为向上调整法。向上调整示意图如下:

建小堆和向上调整法代码如下:
void Swap(HeapDataType* p1, HeapDataType* p2)//交换函数
{int temp = *p1;*p1 = *p2;*p2 = temp;
}void AdjustUp(HeapDataType* arr, int child)//向上调整函数
{assert(arr);int parent = (child - 1) / 2;//求出父母结点下标while (child > 0)//等于0才结束循环说明是最坏情况与根交换{if (arr[child] < arr[parent])//如果孩子小则与父母交换{Swap(&arr[child], &arr[parent]);//让孩子结点和父母结点交换child = parent;//让原先的父母结点变成孩子结点继续调整parent = (child - 1) / 2;//找到原先父母结点的父母结点}else//表示没有达到最坏情况{break;}}
}void HeapPush(Heap* php, HeapDataType x)//入堆
{assert(php);if (php->size == php->capacity){int newcapacity = php->capacity == 0 ? 4 : php->capacity * 2;//三目法更新容量HeapDataType* temp = (HeapDataType*)realloc(php->arr, sizeof(HeapDataType) * newcapacity);//开辟以及扩容空间if (temp == NULL){perror("HeadFush");return;}php->arr = temp;//让arr指向新的空间php->capacity = newcapacity;//更新容量}php->arr[php->size] = x;//入堆php->size++;//更新sizeAdjustUp(php->arr, php->size - 1);//向上调整堆
}5、堆的删除
堆的删除一般是将堆顶的元素删除,堆顶的元素即是下标为0的元素,也就是数组的第一个元素,如果将堆顶的元素直接删除,堆肯定会发生变化,会导致该数组不再是堆了,因此进行堆的删除的同时要调整堆。因为是堆顶的元素发生了改变,所以从堆顶的位置往下调整,进行向下调整。向下调整堆的具体逻辑如下图:
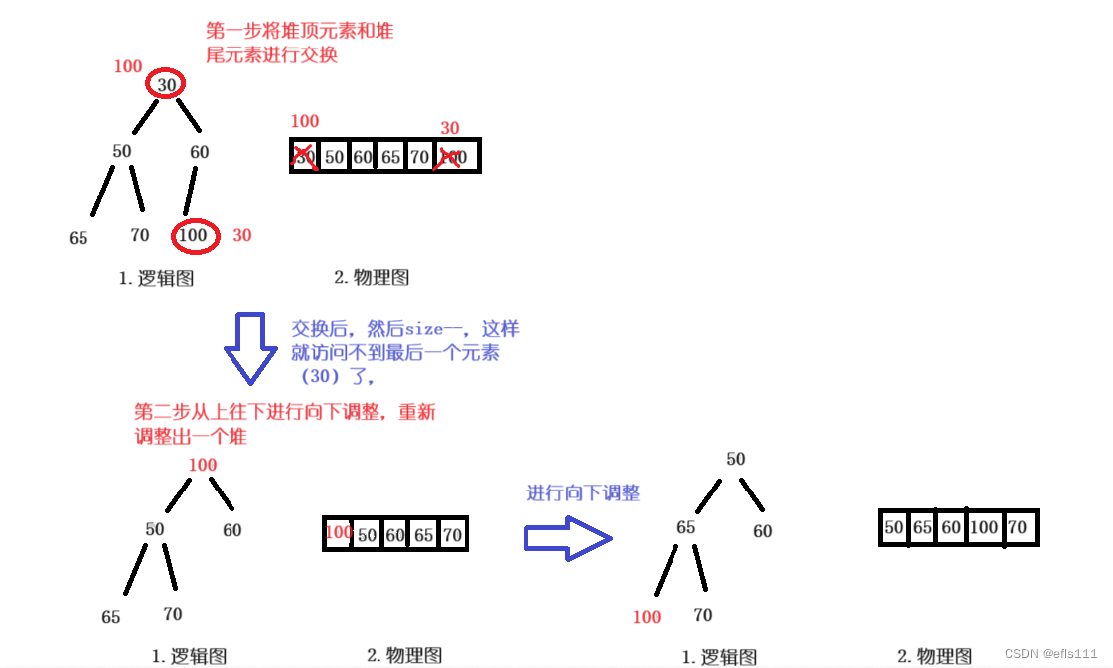
向下调整法思路:把堆顶元素和堆尾元素进行交换,然后从堆顶处开始向下调整,一直调整到元素30的前一个元素。让堆顶元素跟他的两个孩子中最小的孩子进行比较,如果他的孩子比他小则他们俩进行交换,如此循环往下比较,直到树的最后一层。注意:此时的元素30是不参与调整的。
堆的删除及向下调整法代码如下:
bool Empty(Heap* php)//判空函数
{assert(php);return php->size == 0;//为空即返回真
}void AdjustDown(HeapDataType* arr, int size, int parent)//向下调整堆
{assert(arr);int child = parent * 2 + 1;//找出其左孩子while (child < size)//若孩子的下标已经超出了数组元素个数,说明数组已经是堆{if ((child + 1 < size) && arr[child + 1] < arr[child])//此判断可以找出最小的孩子{child++;}if (arr[child] < arr[parent])//若孩子小于父母则交换{Swap(&arr[child], &arr[parent]);parent = child;//进行往下遍历child = parent * 2 + 1;}else{break;}}
}void HeapPop(Heap* php)//删除堆顶
{assert(php);assert(!Empty(php));//堆为空则Empty函数返回真,对其取非,则堆为空assert生效Swap(&php->arr[0], &php->arr[php->size - 1]);//交换函数php->size--;szie需要--因为此时的size是最后一个元素的后一个位置AdjustDown(php->arr, php->size, 0);//向下调整堆,从堆顶开始到堆尾结束
}6、显示堆顶元素
显示堆顶元素就很简单了,堆顶表示的是数组的首元素,首元素下标为0,显示堆顶代码如下:
HeapDataType HeapTop(Heap* php)//展示堆顶
{assert(php);return php->arr[0];
}7、显示堆里的元素个数
堆的大小就是size的值,因为每次赋值后size都会++,所以刚好可以用size表示元素个数,代码如下:
int HeapSize(Heap* php)//堆的元素的总数
{assert(php);return php->size;
}8、测试堆的各个功能
以上介绍了那么多的功能,现在对这些功能进行测试,代码如下:
void test1()
{Heap hp;//创建堆的结构体变量HeapInit(&hp);//初始化int a[] = { 7,8,3,5,1,9,4,5 };for (int i = 0; i < sizeof(a) / sizeof(int); i++){HeapPush(&hp, a[i]);//把数组a里的元素入进堆里}printf("size:%d\n", HeapSize(&hp));//打印堆里元素总数int i = 0;while (!Empty(&hp))//循环打印出堆里的所有元素{printf("%d ",HeapTop(&hp));//打印堆顶的元素HeapPop(&hp);//删除堆顶元素}HeapDestroy(&hp);//释放堆
}int main()
{test1();return 0;}运行结果:

可以看到打印出来的结果是一个有序的数组,原因是每次打印堆顶的元素然后就删除该堆顶元素并且进行了向下调整,调整完之后此时堆顶元素就是第二小的元素,所有才能打印出有序的序列。
9、 实现堆排序
以上的测试可以发现是在数组arr中进行的,但是原数组a并没有受到改变,若想实现排序,则必须在原数组内对原数组里的顺序进行排序。
堆排序代码如下:
void test2()//堆排序
{Heap hp;HeapInit(&hp);//初始化int arr[] = { 7,8,3,5,1,9,4,5 };//创建一个数组int k = sizeof(arr) / sizeof(int);//对原数组进行建堆for (int i = (k - 1 - 1) / 2; i >= 0; i--){AdjustDown(arr, k, i);//}//建完堆之后不一定是有序的数组,因此还需要对其进行调整int end = sizeof(arr) / sizeof(int) - 1;while (end > 0){Swap(&arr[0], &arr[end]);//堆顶元素与堆尾元素进行交换AdjustDown(arr, end, 0);//向下调整到堆尾的前一个元素end--;//堆尾下标--,准备下一次的交换}//打印for (int i = 0; i < k; i++){printf("%d ", arr[i]);}
}int main()
{test1();return 0;}首先在原数组a中进行建堆,建完堆之后不代表数组a就是有序的,因此还需要对其进行调整,我们可以保证的是数组在建完堆之后堆顶的元素是最小的,因此把堆顶元素跟堆里的最后一个元素进行交换(用end表示堆尾的下标),然后从堆顶开始向下调整到end的前一个位置结束调整,思路与堆的删除相似。
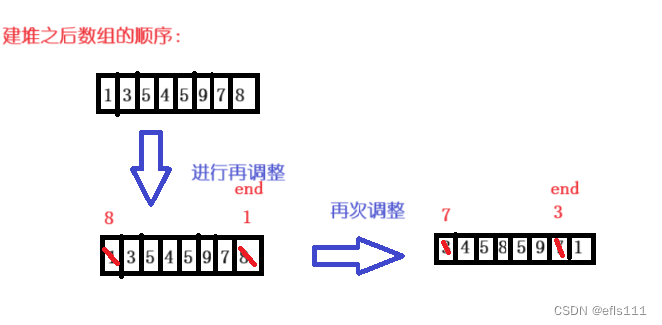
从上图分析来看,最后会得到一组降序的数组,因此得出结论建立小堆得到的是降序,而建立大堆得到的是升序。
三、TOP-K的实现
一般我们要查询某个专业的前十名,或者前世界500强的公司有哪些的时候都会用到TOP-K来解决,当要搜索的范围很大的时候,用正常的排序是难以解决的,比如从10亿个数中求出前五个最大的数,这时候如果把10亿个数排好序则要耗费大量的内存,很明显排序的办法不行。
这时候就需要堆来解决了,可以先建立一个5个数字的小堆,然后从这10个数中不断的取出数据跟堆顶元素进行比较,如果比堆顶元素大则替换堆顶元素然后再进行向下调整堆,最后堆里的5个元素就10亿中最大的5个元素。用堆解决的优势在于这10亿个数不需要全部拿到内存中,而是存在磁盘里的文件中就可以进行对比了,需要文件操作函数来实现。
这里我就用1000个数作为测试用例,TOP-K代码如下:
void CreatData()//创造数据
{int n = 1000;//这里我们只创建1000个数用来测试srand(time(0));//生成随机数FILE* fin = fopen("data.txt", "w");//以写的方式打开文件if (fin == NULL){perror("fopen error");return;}for (int i = 0; i < n; i++){int x = rand() % 10000;//生成10000以内的随机值fprintf(fin, "%d\n", x);//把这些值写进文件中}fclose(fin);//关闭文件fin = NULL;
}void TOP_K(int k)//选出5个最大的数
{FILE* fin = fopen("data.txt", "r");//以读的方式打开文件if (fin == NULL){perror("fopen error");return;}//创建数组int* arr = (int*)malloc(sizeof(int)*k);if (arr == NULL){perror("malloc error");return;}//倒数据for (int i = 0; i < k; i++){fscanf(fin, "%d", arr + i);//把文件里的前五个数给到数组arr,准备建堆}//建小堆for (int i = (k - 1 - 1) / 2; i >= 0; i--){AdjustDown(arr, k, i);//向下调整建立小堆}//TOP-Kint val = 0;//创建val变量while (!feof(fin))//遍历文件内容{fscanf(fin, "%d", &val);//把文件里的值以%d的形式给到val变量if (val > arr[0])//如果val的值大于堆顶元素{arr[0] = val;//将val的值赋给堆顶AdjustDown(arr, k, 0);//并且重新向下调整堆,保证数组是一个堆}}//打印数组for (int i = 0; i < k; i++){printf("%d ", arr[i]);}fclose(fin);//关闭文件fin = NULL;
}int main()
{CreatData();//创建数据TOP_K(5);//TOP-K实现return 0;}创建文件数据的结果:
运行结果:
![]()
从结果可以看到TOP-K确实帮助我们从1000个数中找出了最大的五个数。
结语:
以上就是关于堆的一系列的解析与延申,堆的重点在于对向上调整和向下调整的理解,这两个调整法才是创建堆的核心。希望本文可以带给你更多的收获,如果本文对你起到了帮助,希望可以动动小指头帮忙点赞👍+关注😎+收藏👌!如果有遗漏或者有误的地方欢迎大家在评论区补充~!!谢谢大家!!(❁´◡`❁)
相关文章:

c语言-数据结构-堆
目录 一、二叉树 1、二叉树的概念 2、完全二叉树和满二叉树 3、完全二叉树的顺序存储 二、堆 2、堆的概念与结构 3、堆的创建及初始化 4、堆的插入(小堆) 5、堆的删除 6、显示堆顶元素 7、显示堆里的元素个数 8、测试堆的各个功能 9、 实现堆…...

ROS基础—关于参数服务器的操作
1、rosparam list 获取参数服务器的所有参数。 2、rosparam get /run_id 获取参数的值...
Sql Server 2017主从配置之:事务日志传送
使用事务日志传送模式搭建Sql Server 2017主从同步,该模式有一定的延迟,是通过3个不同的定时任务,将主库的日志同步到从库进行恢复来实现数据库同步操作。 环境准备 两台服务器,配置都是8g2核,50g硬盘,操…...

每日OJ题_算法_双指针_力扣283. 移动零+力扣1089. 复写零
力扣283. 移动零 283. 移动零 - 力扣(LeetCode) 难度 简单 给定一个数组 nums,编写一个函数将所有 0 移动到数组的末尾,同时保持非零元素的相对顺序。 请注意 ,必须在不复制数组的情况下原地对数组进行操作。 示例…...
WebGl-Blender:建模 / 想象成形 / Blender概念词汇表 / 快捷键
一、理解Blender 欢迎来到Blender!Blender是一款免费开源的3D创作套件。 使用Blender,您可以创建3D可视化效果,例如建模、静态图像,3D动画,VFX(视觉特效)快照和视频编辑。它非常适合那些受益于…...

【C++】【Opencv】cv::warpAffine()仿射变换函数详解,实现平移、缩放和旋转等功能
仿射变换是一种二维变换,它可以将一个二维图形映射到另一个二维图形上,保持了图形的“形状”和“大小”不变,但可能会改变图形的方向和位置。仿射变换可以用一个线性变换矩阵来表示,该矩阵包含了六个参数,可以进行平移…...

WPF实现右键菜单
在WPF中,创建上下文菜单(通常称为“右键菜单”)是通过使用ContextMenu控件来实现的。你可以在XAML中声明上下文菜单,并将其关联到任何FrameworkElement。以下是如何在WPF中实现上下文菜单的基本步骤: 1. 在XAML中定义…...

Java智慧工地SaaS管理平台源码:AI/云计算/物联网
智慧工地是指运用信息化手段,围绕施工过程管理,建立互联协同、智能生产、科学管理的施工项目信息化生态圈,并将此数据在虚拟现实环境下与物联网采集到的工程信息进行数据挖掘分析,提供过程趋势预测及专家预案,实现工程…...
【漏洞复现】通达oa 前台sql注入
漏洞描述 通达OA(Office Automation)是一款企业级协同办公软件,旨在为企业提供高效、便捷、安全、可控的办公环境。它涵盖了企业日常办公所需的各项功能,包括人事管理、财务管理、采购管理、销售管理、库存管理、生产管理、办公自动化等。通达OA支持PC端和移动端使用,可以…...

机器学习笔记 - Ocr识别中的文本检测EAST网络概述
一、文本检测 文本检测简单来说就是找到图像中可以出现文本的区域。例如,请参见下图,其中在检测到的文本周围绘制了绿色边框。 在进行文本检测时,你可能会遇到两种情况 具有结构化文本的图像:这是指具有干净/均匀背景和常规字体的图像。文本大多密集,行结构正确,…...
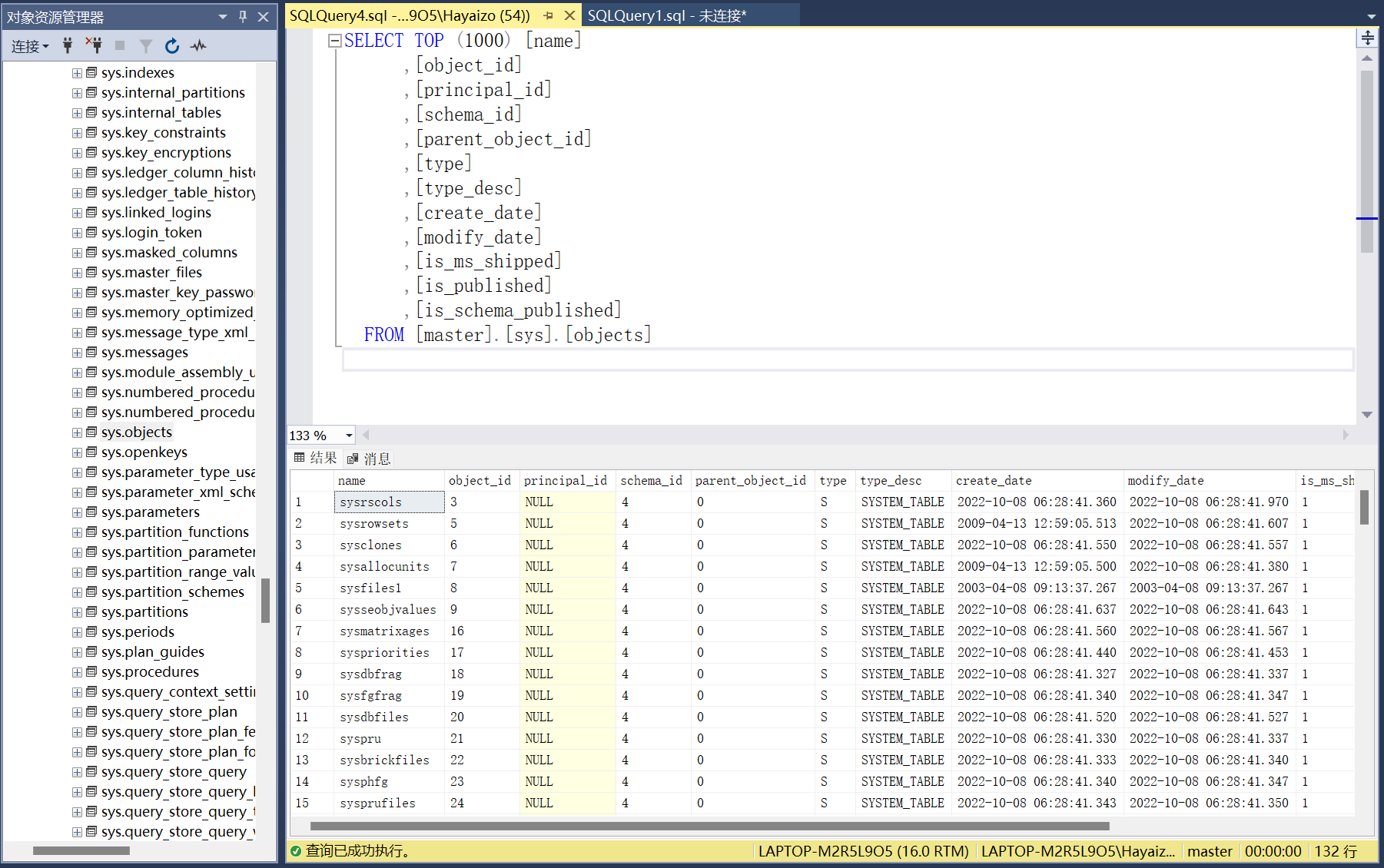
【SQL server】数据库、数据表的创建
创建数据库 --如果存在就删除 --所有的数据库都存在sys.databases当中 if exists(select * from sys.databases where name DBTEST)drop database DBTEST--创建数据库 else create database DBTEST on --数据文件 (nameDBTEST,--逻辑名称 字符串用单引号filenameD:\DATA\DBT…...

vue的生命周期分别是什么?
Vue的生命周期分为8个阶段,分别是: beforeCreate:实例初始化之后,数据观测 (data observer) 和 event/watcher 事件配置之前被调用。 created:实例已经创建完成后被调用,这时候实例已完成以下的配置&#…...

Java拼图游戏
运行出的游戏界面如下: 按住A不松开,显示完整图片;松开A显示随机打乱的图片。 User类 package domain;/*** ClassName: User* Author: Kox* Data: 2023/2/2* Sketch:*/ public class User {private String username;private String password…...

Vue框架的element组件table文字居中
1.直接上代码 <el-table max-height"500px" :data"datas.roles" style"width: 100%" border :header-cell-style"{textAlign: center}" :cell-style"{ textAlign: center }"><el-table-column prop"id" …...

科技创新 共铸典范 | 江西卫健办邓敏、飞图影像董事长洪诗诗一行到访拓世科技集团,提振公共卫生事业发展
2023年11月15日,拓世科技集团总部迎来了江西省卫健项目办项目负责人邓敏、江西飞图影像科技有限公司董事长洪诗诗一行的考察参观,集团董事长李火亮、集团高级副总裁方高强进行热情接待。此次多方交流,旨在共同探讨携手合作,激发科…...
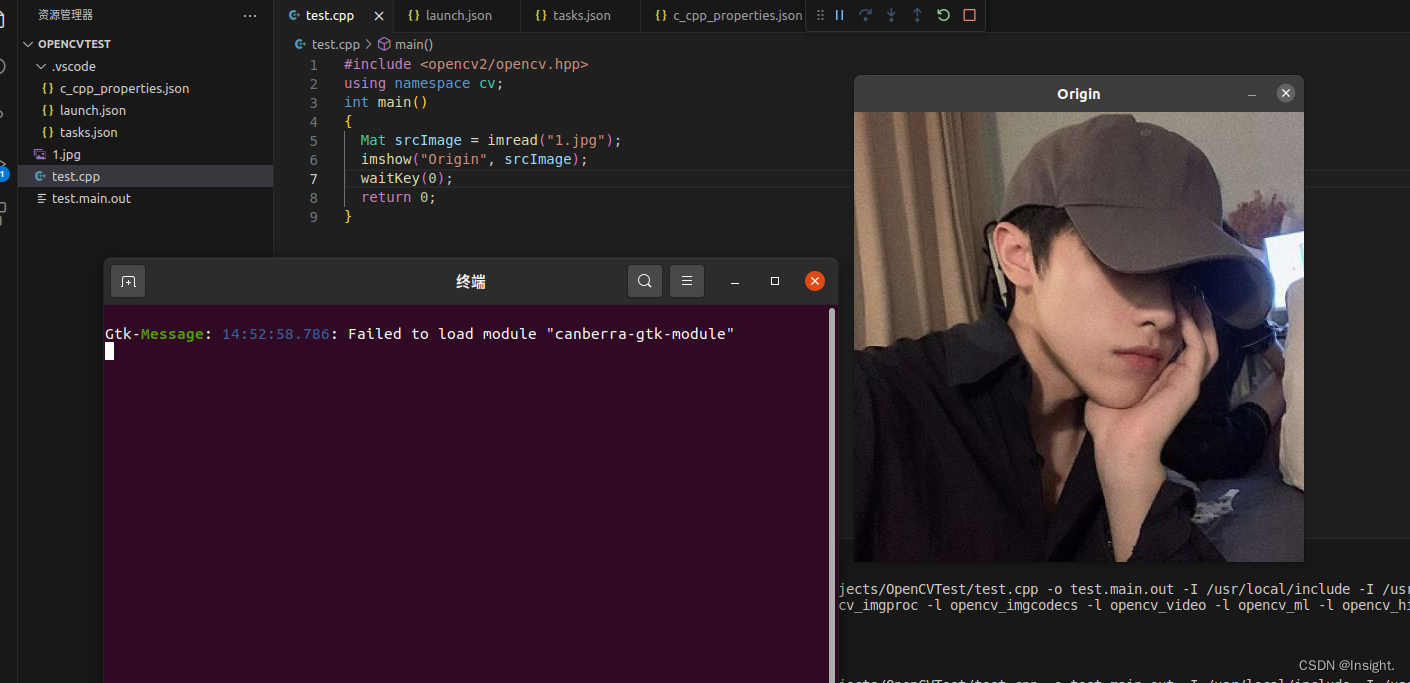
Linux安装OpenCV并配置VSCode环境
Linux安装OpenCV并配置VSCode环境 安装OpenCV环境安装必需工具下载并解压OpenCV库(Opencv Core Modules和opencv_contrib)创建构建目录,进行构建验证构建结果安装验证安装结果 配置VSCode环境创建项目文件修改配置信息执行程序 安装环境 Ubun…...
)
Django(ORM事务操作|ORM常见字段类型|ORM常见字段参数|关系字段|Meta元信息)
文章目录 ORM事务操作什么是事务?事务的产生事务的四大特征ORM中如何使用事务 ORM字段类型常用字段与不常用字段类型ORM还支持用户自定义字段类型 ORM字段参数关系字段ForeignKey外键on_delete参数设置的值 OneToOneField与ForeignKey的区别多对多关系建立的方式ORM…...

【mujoco】Ubuntu20.04配置mujoco210
【mujoco】Ubuntu20.04配置mujoco210 文章目录 【mujoco】Ubuntu20.04配置mujoco2101. 安装mujoco2102. 安装mujoco-py3.使用render时报错Reference 本文简要介绍一下如何在ubuntu20.04系统中配置mujoco210,用于强化学习。 1. 安装mujoco210 在官方资源里找到http…...
)
【洛谷 P3853】[TJOI2007] 路标设置 题解(二分答案+循环)
[TJOI2007] 路标设置 题目背景 B 市和 T 市之间有一条长长的高速公路,这条公路的某些地方设有路标,但是大家都感觉路标设得太少了,相邻两个路标之间往往隔着相当长的一段距离。为了便于研究这个问题,我们把公路上相邻路标的最大…...

蓝桥杯 vector
vector的定义和特性 注意:vector需要开C11标准 vector的常用函数 push_back():将元素添加到vector末尾 pop_back():删除vector末尾的元素 begin()和end():返回指向vector第一个元素和最后一个元素之后一个位置的迭代器。 示例 vector<int> vec{10,20,30};f…...

作为一名大二学生对于Vibe Coding的理解
🌈 个人主页: Hygge_Code 🔥 热门专栏:从0开始学习Java | Linux学习 | 计算机网络 💫 个人格言: “既然选择了远方,便不顾风雨兼程” 文章目录关于Vibe Coding前言什么是Vibe Coding(氛围感编程)? &#x…...

光子KANs:电信组件构建的光学神经网络革命
1. 光子KANs:电信组件构建的光学神经网络革命 在AI算力需求爆炸式增长的今天,传统电子计算架构正面临带宽瓶颈和能耗墙的严峻挑战。当我第一次在实验室用示波器测量光学神经网络的响应时间时,23纳秒的延迟让我震惊——这比最好的GPU还要快三个…...

开放标准如何重塑多媒体设备开发:从碎片化到模块化
1. 项目概述:为什么我们需要一个“开放标准”?如果你在消费电子、汽车座舱或者智能家居领域待过几年,一定会对“多媒体设备”这个词又爱又恨。爱的是,它代表了用户体验的核心——那块屏幕、那套音响、那个能看视频能听歌的交互界面…...

让音乐看得见:Lano Visualizer桌面音频可视化工具深度解析
让音乐看得见:Lano Visualizer桌面音频可视化工具深度解析 【免费下载链接】Lano-Visualizer A simple but highly configurable visualizer with rounded bars. 项目地址: https://gitcode.com/gh_mirrors/la/Lano-Visualizer 还在为单调的桌面音乐播放体验…...
)
从源码到桌面:手把手教你用Python搭建SimpleFOCStudio开发环境(Windows/Mac)
从源码到桌面:手把手教你用Python搭建SimpleFOCStudio开发环境(Windows/Mac) 在开源硬件和电机控制领域,SimpleFOCStudio已成为开发者调试无刷电机的利器。不同于直接下载可执行文件的"快餐式"使用,从源码构…...

3分钟学会在Windows电脑安装安卓应用:APK Installer完全指南
3分钟学会在Windows电脑安装安卓应用:APK Installer完全指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 还在为Windows电脑无法直接运行安卓应用而烦恼…...

el-tree 动态子节点注入:从点击事件到数据更新的完整实践
1. 理解动态子节点注入的核心需求 在实际开发中,我们经常会遇到需要动态加载树形数据的场景。比如一个文件管理系统,用户点击文件夹时才加载其中的内容;或者一个组织架构图,只有展开某个部门时才显示下属员工。这种按需加载的方式…...

告别单条弹窗!ABAP里用MESSAGES_SHOW函数批量展示多条消息的保姆级教程
ABAP批量消息展示实战:用MESSAGES_SHOW优化用户交互体验 在SAP系统的日常开发中,消息处理是每个ABAP开发者都无法回避的核心功能。传统的单条弹窗方式虽然简单直接,但在处理批量数据校验、复杂业务逻辑时,频繁弹出的消息窗口不仅打…...

星闪测距性能分析
环境HiSpark开发平台,两块BS21E丢包率1分钟内75次测距数据中,约有6次左右的数据是无效或者丢失,可以通过一些滤波算法过滤,完全可以满足小车定位的需要。测距精度目前使用的测距方案是RSSI信号强度与IQ信号结合,精度达…...

JIT只适合大厂?精益生产中小厂JIT落地技巧,不用大投入也能降库存!
提到精益生产JIT准时化生产,很多中小厂管理者都会陷入一个固有认知:JIT是大厂的专属工具,只有资金充足、供应链完善、管理规范的大厂,才能推行JIT;中小厂规模小、资金有限、供应链不稳定,推行JIT不仅需要大…...