C++编写的多线程自动爬虫程序
目录
引言
一、程序的设计
二、程序的实现
三、程序的测试
四、优化与改进
五、代码示例
总结
引言
随着互联网的快速发展,网络爬虫程序已经成为数据采集、信息处理的重要工具。C++作为一种高效的编程语言,具有高效的并发处理能力和丰富的网络编程库,因此非常适合用于编写多线程自动爬虫程序。本文将介绍如何使用C++编写一个多线程自动爬虫程序,包括程序的设计、实现和测试等方面。

一、程序的设计
- 确定目标网站
在编写爬虫程序之前,需要确定要爬取的目标网站。目标网站应该具有结构化良好、数据更新频繁等特点,以便于数据的采集和处理。 - 确定数据采集策略
根据目标网站的结构和数据更新频率,确定数据采集的策略。常用的策略包括:按需采集、定时采集等。 - 确定爬虫框架
爬虫框架是爬虫程序的基础,可以帮助开发人员快速搭建爬虫程序。常用的C++爬虫框架包括:Scrapy、Crawley等。 - 确定多线程策略
多线程可以提高爬虫程序的并发处理能力,缩短数据采集的时间。常用的多线程策略包括:每个线程处理一个页面、每个线程处理一个IP等。
二、程序的实现
- 安装C++爬虫框架
选择一个合适的C++爬虫框架,并按照说明进行安装和配置。本例中,我们使用Scrapy框架进行实现。 - 创建爬虫项目
使用Scrapy框架创建一个新的爬虫项目,并配置相应的参数和目录结构。 - 编写爬虫代码
在Scrapy框架中,需要编写Spider类来实现数据采集功能。Spider类需要定义起始URL、解析URL、提取数据等方法。在本例中,我们编写一个简单的Spider类,从目标网站中提取需要的数据。 - 实现多线程功能
在Scrapy框架中,可以使用Scrapy引擎和Scheduler来实现多线程功能。通过设置Scrapy引擎的settings属性,可以控制线程数量和请求频率等参数。通过调用Scheduler的add_request方法,可以添加需要采集的URL请求。 - 实现自动调度功能
为了实现自动调度功能,我们可以编写一个定时任务脚本,定时调用Scheduler的add_request方法,添加需要采集的URL请求。在Linux系统中,可以使用cron工具来实现定时任务。
三、程序的测试
- 测试数据采集功能
通过运行爬虫程序,测试数据采集功能是否正常。可以使用Scrapy框架提供的命令行工具来查看爬取的数据结果。 - 测试多线程功能
通过设置不同的线程数量和请求频率等参数,测试多线程功能是否正常。可以使用Scrapy框架提供的命令行工具来查看爬取的数据结果和性能指标。 - 测试自动调度功能
通过设置定时任务脚本,测试自动调度功能是否正常。可以使用Linux系统提供的cron工具来查看定时任务是否按计划执行。 - 测试数据清洗和处理功能
根据实际需求,测试数据清洗和处理功能是否正常。可以使用Python等编程语言编写数据处理脚本,对爬取的数据进行处理和清洗。 - 安全性测试
为了确保爬虫程序的正常运行和避免对目标网站造成影响,需要进行安全性测试。安全性测试包括:模拟请求被拒绝、模拟登录失败等情况,以确保程序能够正确处理异常情况。同时需要对爬虫程序进行压力测试以确保其能够在高负载情况下正常运行。压力测试可以通过不断增加请求数量或请求频率来进行模拟以检验程序的性能和稳定性。在安全性测试和压力测试过程中可以使用一些测试工具来辅助测试例如Wireshark可以帮助抓包分析请求是否被目标网站识别为爬虫请求;Jmeter可以帮助模拟高负载请求以检验程序的性能和稳定性等。
四、优化与改进
1、优化爬虫效率
针对爬虫程序的效率进行优化,可以采取以下措施:
使用更高效的爬虫库,例如libcurl、requests等,以提高请求速度和响应时间。
优化网络请求的并发数量和频率,以避免被封禁和减少请求延迟。
优化数据清洗和处理流程,以减少处理时间和提高数据质量。
2、改进多线程功能
针对多线程功能进行改进,可以采取以下措施:
使用线程池技术,以避免频繁创建和销毁线程,提高程序性能。
实现线程同步和互斥机制,以避免数据竞争和死锁等问题。
优化线程调度算法,以提高多线程的并发处理能力和效率。
3、加强安全性保障
针对爬虫程序的安全性进行保障,可以采取以下措施:
使用代理服务器和随机IP等技术,以避免被目标网站识别和封禁。
加强用户认证和授权机制,以确保只有授权用户可以访问目标网站。
实现异常处理机制,以避免程序崩溃和数据丢失等问题。
定期更新程序和库版本,以修复漏洞和提高安全性。
4、实现动态调度功能
为了更好地适应目标网站的数据更新频率和结构变化,可以实现在线动态调度功能。通过实时监 测目标网站的数据更新情况和结构变化,动态调整爬虫程序的采集策略和调度计划,以提高数据采集的准确性和效率。
5、集成报警系统
为了及时发现程序异常和错误,可以集成一个报警系统。当程序出现异常情况时,可以通过邮件、短信等方式向管理员发送报警信息,以便及时发现和处理问题。同时也可以通过报警系统对程序的性能指标进行监控和分析,以便更好地优化和改进程序。
五、代码示例
#include <iostream>
#include <string>
#include <thread>
#include <vector>
#include <wget.h> // 使用libcurl库进行网络请求 #include "scrapy/Spider.h"
#include "scrapy/Scheduler.h" using namespace std;
using namespace Scrapy; // 自定义一个爬虫类,继承自Spider类
class MySpider : public Spider {
public: void start_request() override { // 设置起始URL和其他参数 string url = "http://example.com"; string referer = "http://example.com"; string user_agent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3"; // 发起网络请求 wget::init(); // 初始化libcurl库 wget::set_url(url); wget::set_referer(referer); wget::set_user_agent(user_agent); wget::set_output_to_string(true); // 将响应内容保存到字符串中 wget::set_timeout(10); // 设置超时时间(单位:秒) wget::execute(); // 发起请求并获取响应内容 wget::cleanup(); // 清理libcurl库的资源 } bool parse_response(const string& response) override { // 从响应内容中提取所需数据 // ... return true; // 返回true表示继续爬取下一个URL,返回false表示停止爬虫程序 }
}; int main() { // 创建Scheduler对象,用于管理URL请求队列 Scheduler scheduler; // 创建MySpider对象,设置起始URL和其他参数 MySpider spider("http://example.com"); spider.set_scheduler(&scheduler); // 将Spider对象绑定到Scheduler对象上 // 启动多个线程进行数据采集和处理,每个线程处理一个页面 for (int i = 0; i < 10; i++) { // 假设有10个线程可用 thread t(&MySpider::start, &spider); // 启动线程执行start方法 t.detach(); // 将线程分离,使其在后台运行 } // 在主线程中等待所有数据采集和处理完成 while (!scheduler.is_empty()) { // 当Scheduler对象中还有未处理的URL请求时,继续等待 this_thread::sleep_for(chrono::seconds(1)); // 主线程休眠1秒钟,等待其他线程处理完所有请求并返回结果 } return 0;
}总结
本文介绍了一个使用C++编写的多线程自动爬虫程序的实现过程和测试方法。通过设计合理的爬虫框架和多线程策略,实现了高效的数据采集和处理功能。同时通过安全性测试和压力测试等措施,确保了程序的正常运行和高性能表现。在未来的工作中,可以对程序进行优化和改进以提高效率和安全性保障等方面的表现。同时也可以探索更加智能的数据清洗和处理方法以及更加灵活的调度策略等方向的研究和应用。
相关文章:
C++编写的多线程自动爬虫程序
目录 引言 一、程序的设计 二、程序的实现 三、程序的测试 四、优化与改进 五、代码示例 总结 引言 随着互联网的快速发展,网络爬虫程序已经成为数据采集、信息处理的重要工具。C作为一种高效的编程语言,具有高效的并发处理能力和丰富的网络编程…...

SMB信息泄露的利用
一、背景 今天分享SMB信息泄露,SMB(Server Message Block)网络通信协议,早些时候被用于Web链接和客户端与服务器之间的信息通信,现在大部分Web页面使用HTTP协议,在web领域应用较少。另一方面SMB协议还是被…...
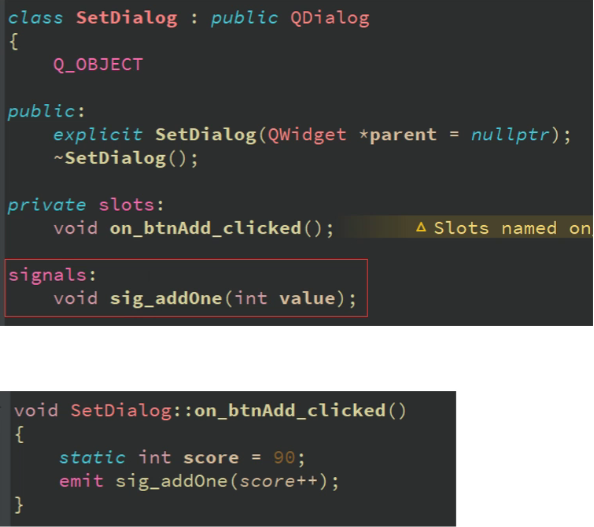
QT自定义信号,信号emit,信号参数注册
qt如何自定义信号 使用signals声明返回值是void在需要发送信号的地方使用 emit 信号名字(参数)进行发送 在需要链接的地方使用connect进行链接 ct进行链接...

06.webpack性能优化--构建速度
优化babel-loaderhappyPackIgnorePluginparalleUglifyPluginnoParse自动刷新 1 happypack多进程打包 js单线程,开启多进程打包提高构建速度(特别是多核CPU) const HappyPack require(happypack)module.exports smart(webpackCommonConf,…...

11-15 周三 softmax 回归学习
11-15 周三 softmax 回归学习 时间版本修改人描述2023年11月15日11:17:27V0.1宋全恒新建文档 简介 softmax分享可以参考什么是softmax 回归估计一个连续值,分类预测一个离散类别。 恶意软件的判断 回归和分类 分类可以认为从回归的单输出变成多输出 B站学习 softm…...

React新手必懂的知识点
react思想:组件化开发 React 的核心概念是组件化开发,将用户界面拆分成独立的可复用组件。学习如何创建和使用 React 组件,以及组件之间的数据传递和通信是非常重要的。 React的思想就是拆分组件与使用组件。 import React from react;// 定…...

es为什么这么快
es为什么这么快的方式 es的基于Lucene开源搜索引擎,负责文件存储和搜索,支持http请求,以json形式展示 这样介绍你有可能有点迷糊我们详细解释 es 使用的倒排索引的方式,进行数据存储方式,给每一个字段创建索引&…...
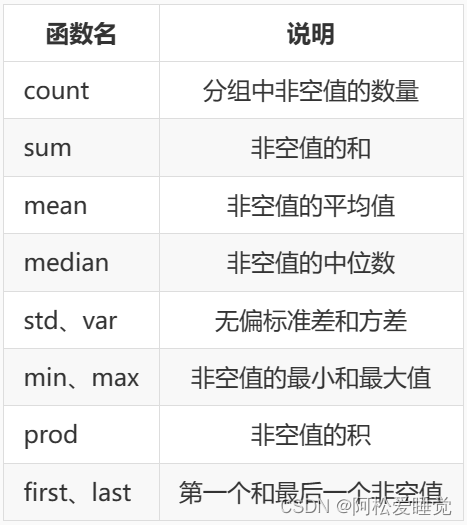
Pandas分组聚合_Python数据分析与可视化
Pandas分组聚合 分组单列和多列分组Series 系列分组通过数据类型或者字典分组获取单个分组对分组进行迭代 聚合应用单个聚合函数应用多个聚合函数自定义函数传入 agg() 中对不同的列使用不同的聚合函数 分组聚合的流程主要有三步: 分割步骤将 DataFrame 按照指定的…...
VMware17虚拟机Linux安装教程(详解附图,带VMware Workstation 17 Pro安装)
一、安装 VMware 附官方下载链接(VM 17 pro):https://download3.vmware.com/software/WKST-1701-WIN/VMware-workstation-full-17.0.1-21139696.exe 打开下载好的VMware Workstation 17 Pro安装包; 点击下一步; 勾选我…...
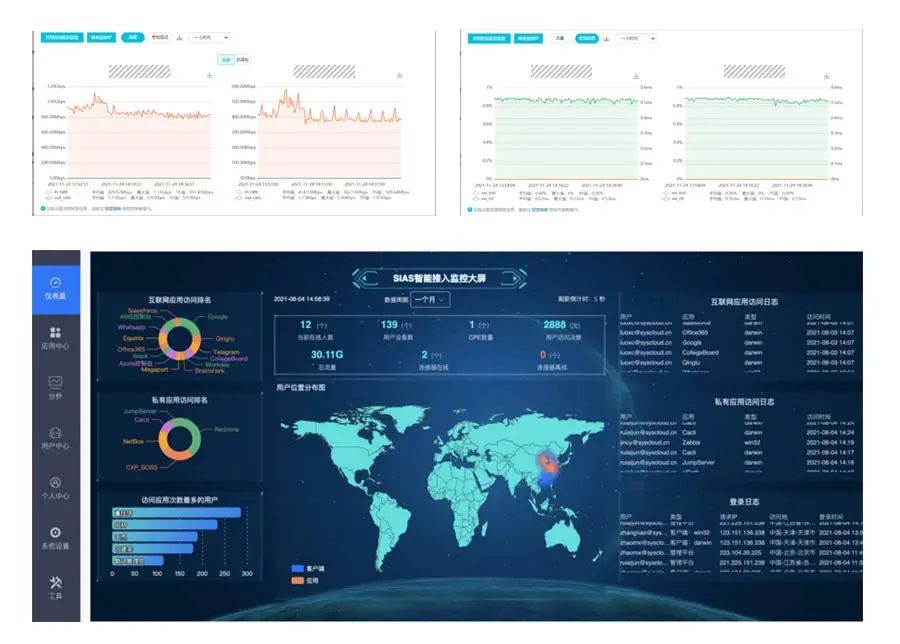
基于SDN技术构建多平面业务承载网络
随着企业数字化的浪潮席卷各个行业,传统网络架构面临着更为复杂和多样化的挑战。企业正在寻找一种全面适应数字化需求的网络解决方案。随着软件定义网络(SDN)的发展,“多业务SDN一张网”解决方案为企业提供了一种全新的网络架构&a…...
关于卓越服务的调研报告
NetSuite知识会发起的本次调研从2023年11月2日开始,到11月12日结束。16日已向参与调研的朋友邮件回复,感谢您的付出!今朝分享此报告,各位同学参考。 调研问题与反馈总结 问题1:您能想到哪些服务组织能够提供高满意度&…...

ubuntu22.04换源
1、系统信息 lsb_release -a No LSB modules are available. Distributor ID: Ubuntu Description: Ubuntu 22.04.3 LTS Release: 22.04 Codename: jammy2、进入 /etc/apt/ 目录: cd /etc/apt/ 3、备份默认源文件 sudo cp sources.list sources.list_bak 4、编…...
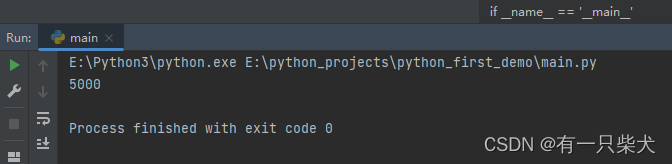
03. Python中的语句
1、前言 在《Python基础数据类型》一文中,我们了解了Python中的基础数据类型,今天我们继续了解下Python中的语句和函数。 2、语句 在Python中常用的语句可以大致分为两类:条件语句、循环语句。 2.1、条件语句 条件语句就是我们编码时常见…...
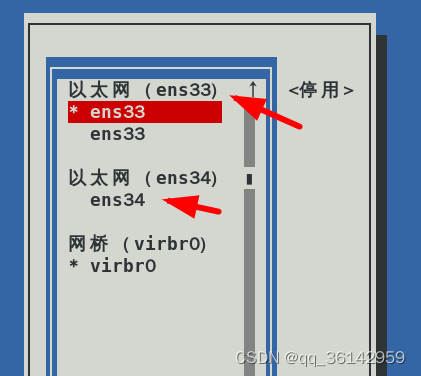
Linux CentOS7 添加网卡
一台主机中安装多块网卡,有许多优势。可以实现多项功能。 为了学习网卡参数的设置,可以为主机添加多块网卡。与添加磁盘一样,要在VMware中设置。利用图形化方式或命令行查看或设置网卡。本文仅初步讨论添加、查看与删除网卡,有关…...

2311rust,到54版本更新
1.50.0稳定版 常量泛型数组索引 继续向稳定的常量泛型迈进,此版本为[T;N]数组,添加了ops::Index和IndexMut的实现. fn second<C>(container: &C) -> &C::Output whereC: std::ops::Index<usize> ?Sized, {&container[1] } fn main() {let arra…...
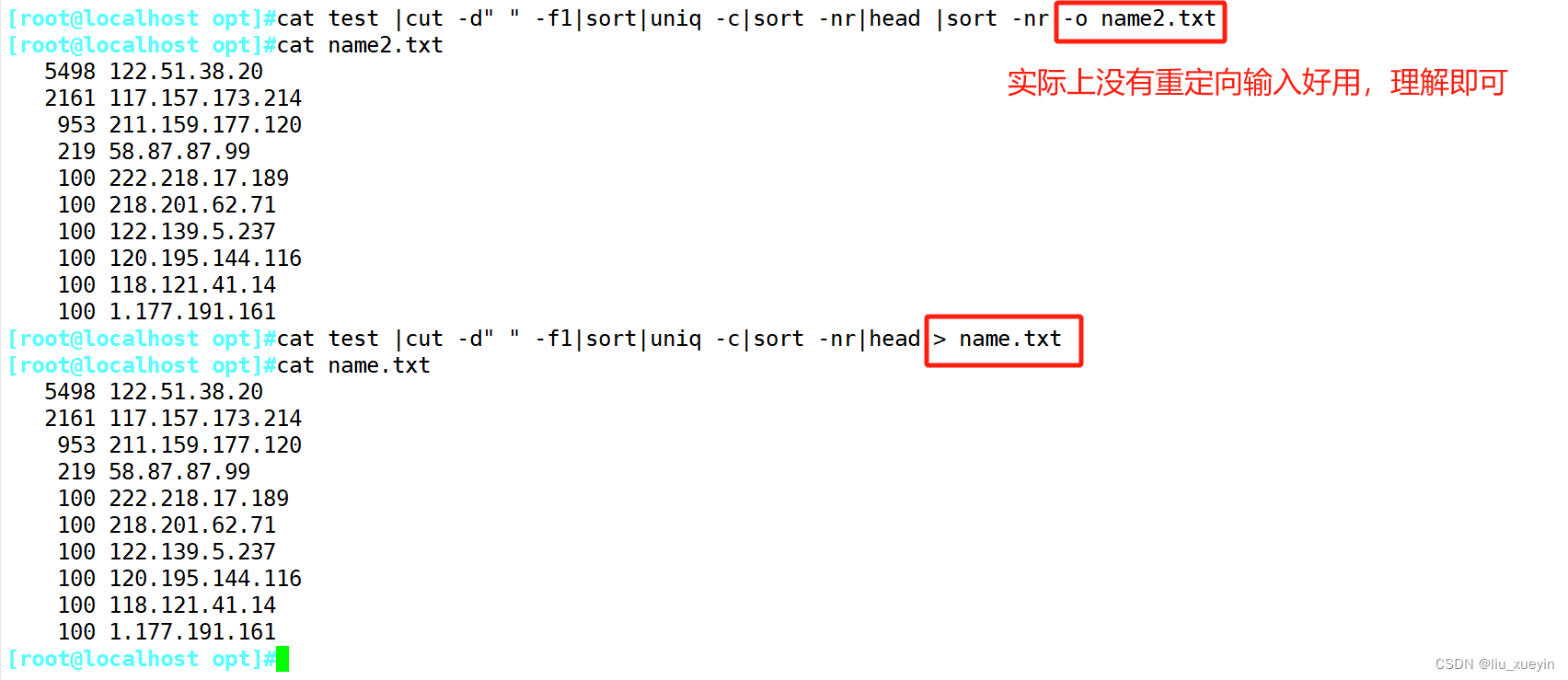
【linux】补充:高效处理文本的命令学习(tr、uniq、sort、cut)
目录 一、tr——转换、压缩、删除 1、tr -s “分隔符” (指定压缩连续的内容) 2、tr -d 想要删除的东西 编辑 3、tr -t 内容1 内容2 将内容1全部转换为内容2(字符数需要一一对应) 二、cut——快速剪裁命令 三、uniq——去…...

Redis篇---第七篇
系列文章目录 文章目录 系列文章目录前言一、是否使用过 Redis Cluster 集群,集群的原理是什么?二、 Redis Cluster 集群方案什么情况下会导致整个集群不可用?三、Redis 集群架构模式有哪几种?前言 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分…...
Shell脚本:Linux Shell脚本学习指南(第一部分Shell基础)一
你好,欢迎来到「Linux Shell脚本」学习专题,你将享受到免费的 Shell 编程资料,以及很棒的浏览体验。 这套 Shell 脚本学习指南针对初学者编写,它通俗易懂,深入浅出,不仅讲解了基本知识,还深入底…...

长短期记忆(LSTM)与RNN的比较:突破性的序列训练技术
长短期记忆(Long short-term memory, LSTM)是一种特殊的RNN,主要是为了解决长序列训练过程中的梯度消失和梯度爆炸问题。简单来说,就是相比普通的RNN,LSTM能够在更长的序列中有更好的表现。 Why LSTM提出的动机是为了解…...

Swift 如何打造兼容新老系统的字符串分割(split)方法
0. 概览 在 Swift 的开发中,我们经常要与字符串打交道。其中一个常见的操作就是用特定的“分隔符”来分割字符串,这里分隔符可能不仅仅是字符,而是多字符组成的字符串。 从 iOS 16 开始, 新增了对应的方法来专注此事。不过&am…...

机器学习核心术语全解析:从评估指标到TensorFlow实战避坑指南
1. 项目概述与核心价值刚接触机器学习,尤其是像TensorFlow这样庞大框架的朋友,最头疼的莫过于满屏的英文术语。什么“Backpropagation”、“Softmax”、“Embedding”,每个词都认识,但组合在一起就让人云里雾里。更别提那些缩写&a…...

百考通AI让开题报告成为研究助力,而非负担
开题报告是毕业论文或学位研究的“第一块基石”,它不仅决定你的选题能否通过,更直接影响后续研究的深度、逻辑与可行性。然而,许多学生在撰写时常常陷入困境:问题意识模糊、文献综述堆砌无主线、研究方法描述空泛、结构松散不规范…...

STM32MP25x嵌入式Linux平台:集成XFCE、VNC、TSN的工业边缘计算解决方案
1. 项目概述:一个面向工业边缘的“瑞士军刀”级嵌入式平台最近,我们团队基于STM32MP25x系列核心板,成功构建并发布了一套完整的Debian系统镜像。这个项目的目标非常明确:打造一个开箱即用、功能全面、且能无缝覆盖从传统工业控制到…...

如何为多个并行项目设置Taotoken Token Plan以优化成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 如何为多个并行项目设置Taotoken Token Plan以优化成本 应用场景类,同时进行多个AI应用实验或开发的个人或团队&#x…...
)
保姆级教程:用Python+OpenCV高效切割Potsdam语义分割数据集(附完整代码)
PythonOpenCV实战:Potsdam语义分割数据集高效切割全流程解析 第一次接触Potsdam数据集时,面对那些6000x6000像素的巨幅航拍图像,我的GPU在训练时直接报显存不足的错误。这让我意识到,高分辨率图像的切割预处理不是可选项…...

Taotoken API Key管理功能实现团队权限与访问控制
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken API Key管理功能实现团队权限与访问控制 在团队协作开发或项目管理中,如何安全、可控地分发大模型调用资源是…...

AWorks硬件抽象层:嵌入式开发中UART、I2C、SPI、ADC接口的统一编程实践
1. 项目概述:当嵌入式开发遇上“万能插座”在嵌入式系统开发中,我们常常面临一个经典难题:硬件平台的碎片化。今天,你可能在为一块基于ARM Cortex-M4的MCU编写SPI驱动,用来连接一块TFT屏幕;明天,…...

从零开始:YY3568开发板刷写原生Linux系统全流程指南
1. 项目概述与核心价值 最近拿到了一块YY3568开发板,这是一款基于瑞芯微RK3568芯片的嵌入式开发平台,性能相当不错。很多朋友拿到开发板后,第一反应就是跟着官方文档跑个Demo,或者直接用板子预装的Android系统。但如果你和我一样&…...

MaterialSkin 2.0终极指南:3步解锁现代化WinForms界面设计
MaterialSkin 2.0终极指南:3步解锁现代化WinForms界面设计 【免费下载链接】MaterialSkin Theming .NET WinForms, C# or VB.Net, to Googles Material Design Principles. 项目地址: https://gitcode.com/gh_mirrors/mat/MaterialSkin 还在为传统WinForms应…...

当金属学会“作画”——优之彩蚀刻不锈钢蜂窝板的空间艺术
让一块坚硬的金属表面呈现出山水画的意境、书法作品的笔意,或是品牌Logo的精致线条——这不是魔法,而是优之彩蚀刻不锈钢蜂窝板正在做的事。触得到的艺术,看得见的高级优之彩不锈钢蚀刻蜂窝板的最大魅力,在于它将“平面”变成了“…...