Kafka-4.1-工作原理综述

1 Kafka工作原理详解

1.1 工作流程
Kafka集群将 Record 流存储在称为 Topic 的类中,每个记录由⼀个键、⼀个值和⼀个时间戳组成。
Kafka 中消息是以 Topic 进⾏分类的,⽣产者⽣产消息,消费者消费消息,⾯向的都是同⼀个Topic。Topic 是逻辑上的概念,⽽ Partition 是物理上的概念,每个 Partition 对应于⼀个 log ⽂件,该log ⽂件中存储的就是 Producer ⽣产的数据。Producer ⽣产的数据会不断追加到该 log ⽂件末端,且每条数据都有⾃⼰的 Offset。消费者组中的每个消费者,都会实时记录⾃⼰消费到了哪个 Offset,以便出错恢复时,从上次的位置继续消费。
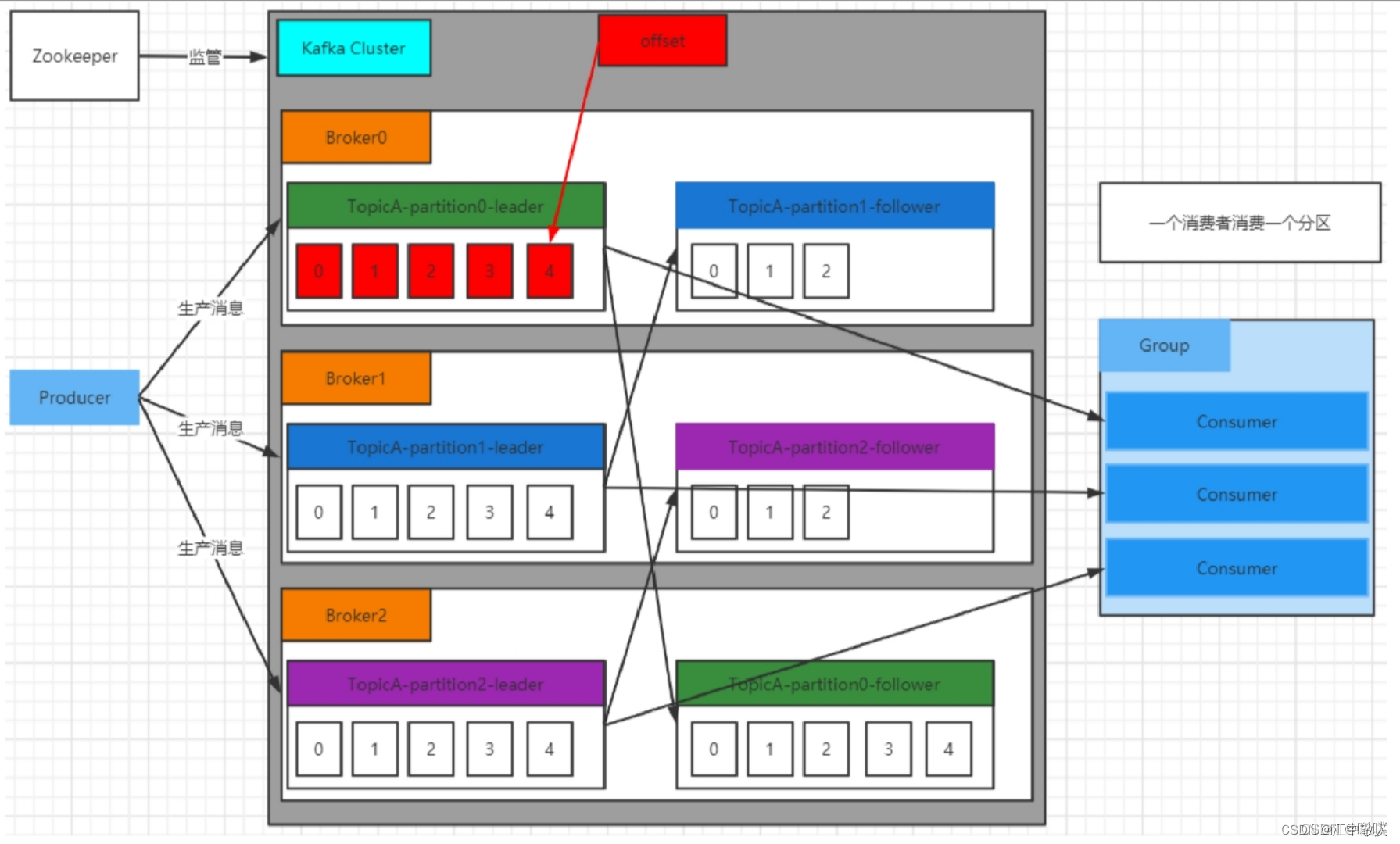
1.2 存储机制
由于⽣产者⽣产的消息会不断追加到 log ⽂件末尾,为防⽌ log ⽂件过⼤导致数据定位效率低下,Kafka 采取了分⽚和索引机制。它将每个 Partition 分为多个 Segment,每个 Segment 对应两个⽂件:“.index” 索引⽂件和“.log” 数据⽂件。这种索引思想值得我们学习应用到平时的开发中。

这些⽂件位于同⼀⽂件下,该⽂件夹的命名规则为:topic 名-分区号。例如,test这个 topic 有三个分区,则其对应的⽂件夹为 test-0,test-1,test-2。
$ ls /tmp/kafka-logs/test-1
00000000000000009014.index
00000000000000009014.log
00000000000000009014.timeindex
leader-epoch-checkpointindex 和 log ⽂件以当前 Segment 的第⼀条消息的 Offset 命名。下图为 index ⽂件和 log ⽂件的结构示意图。

“.index” ⽂件存储⼤量的索引信息,“.log” ⽂件存储⼤量的数据,索引⽂件中的元数据指向对应数据⽂件中 Message 的物理偏移量。
使用shell命令查看索引:
./kafka-dump-log.sh --files /tmp/kafka-logs/test-1/00000000000000000000.index1.3 分区机制
分区原因:
- ⽅便在集群中扩展,每个 Partition 可以通过调整以适应它所在的机器,⽽⼀个 Topic ⼜可以有多个 Partition 组成,因此可以以 Partition 为单位读写了。
- 可以提⾼并发,避免两个分区持久化的时候争夺资源。
- 备份的问题。防止一台机器宕机后数据丢失的问题。
分区原则:我们需要将 Producer 发送的数据封装成⼀个 ProducerRecord 对象。该对象需要指定⼀些参数:
- topic:string 类型,NotNull。
- partition:int 类型,可选。
- timestamp:long 类型,可选。
- key:string 类型,可选。
- value:string 类型,可选。
- headers:array 类型,Nullable。
指明 Partition 的情况下,直接将给定的 Value 作为 Partition 的值;没有指明 Partition 但有 Key 的情况下,将 Key 的 Hash 值与分区数取余得到 Partition 值;既没有 Partition 又没有 Key 的情况下,第⼀次调⽤时随机⽣成⼀个整数(后⾯每次调⽤都在这个整数上⾃增),将这个值与可⽤的分区数取余,得到 Partition 值,也就是常说的 Round-Robin轮询算法。
1.4 生产者
Producer⽣产者,是数据的⼊⼝。Producer在写⼊数据的时候永远的找leader,不会直接将数据写⼊follower。下图很好地阐释了生产者的工作流程。这里获取分区信息,是从zookeeper中获取的。生产者不会每个消息都调用一次send(),这样效率太低,默认是数据攒到16K或是超时(如10ms)会send()一次。注意这里发消息是异步操作。

1.5 ack机制
producer端设置request.required.acks=0;只要请求已发送出去,就算是发送完了,不关心有没有写成功。性能很好,如果是对一些日志进行分析,可以承受丢数据的情况,用这个参数,性能会很好。
- request.required.acks=1;发送一条消息,当leader partition写入成功以后,才算写入成功。不过这种方式也有丢数据的可能。
- request.required.acks=-1;需要ISR列表里面,所有副本都写完以后,这条消息才算写入成功。
设计一个不丢数据的方案:数据不丢失的方案:1)分区副本 >=2 2)acks = -1 3)min.insync.replicas >=2。
下面给出此时leader出现故障的情况,可以看出,此时数据可能重复。
解释上面出现的几个名词。Leader维护了⼀个动态的 in-sync replica set(ISR):和 Leader 保持同步的 Follower 集合。当 ISR 集合中的 Follower 完成数据的同步之后,Leader 就会给 Follower 发送 ACK。如果 Follower ⻓时间未向 Leader 同步数据,则该 Follower 将被踢出 ISR 集合,该时间阈值由replica.lag.time.max.ms 参数设定。Leader 发⽣故障后,就会从 ISR 中选举出新的 Leader。
kafka服务端中min.insync.replicas。 如果我们不设置的话,默认这个值是1。一个leader partition会维护一个ISR列表,这个值就是限制ISR列表里面至少得有几个副本,比如这个值是2,那么当ISR列表里面只有一个副本的时候,往这个分区插入数据的时候会报错。

1.6 消费者
Consumer 采⽤ Pull(拉取)模式从 Broker 中读取数据。Pull 模式则可以根据 Consumer 的消费能⼒以适当的速率消费消息。Pull 模式不⾜之处是,如果Kafka 没有数据,消费者可能会陷⼊循环中,⼀直返回空数据。因为消费者从 Broker 主动拉取数据,需要维护⼀个⻓轮询,针对这⼀点, Kafka 的消费者在消费数据时会传⼊⼀个时⻓参数 timeout。如果当前没有数据可供消费,Consumer 会等待⼀段时间之后再返回,这段时⻓即为 timeout。
1.6.1 分区分配策略
⼀个Consumer Group中有多个Consumer,⼀个Topic有多个Partition。不同组间的消费者是相互独立的,相同组内的消费者才会协作,这就必然会涉及到Partition的分配问题,即确定哪个Partition由哪个Consumer来消费。
Kafka 有三种分配策略:
- RoundRobin
- Range,默认为Range
- Sticky
当消费者组内消费者发⽣变化时,会触发分区分配策略(⽅法重新分配),在分配完成前,kafka会暂停对外服务。注意为了尽量确保消息的有序执行,一个分区只能对应一个消费者,这也说明消费者的数量不能超过分区的数量。
1.6.1.1 range方式
Range ⽅式是按照主题来分的,不会产⽣轮询⽅式的消费混乱问题,但是也有不足。
注意图文不符,图片是一个例子,文字再给一个例子,以便理解。假设我们有10个分区,3个消费者,排完序的分区将会是0,1,2,3,4,5,6,7,8,9;消费者线程排完序将会是C1-0,C2-0,C3-0。然后将partitions的个数除以消费者线程的总数来决定每个消费者线程消费⼏个分区。如果除不尽,那么前⾯⼏个消费者线程将会多消费⼀个分区。
在我们的例⼦⾥⾯,我们有10个分区,3个消费者线程, 10/3 = 3,⽽且除不尽,那么消费者线程 C1-0将会多消费⼀个分区:C1-0 将消费 0, 1, 2, 3 分区;C2-0将消费 4,5,6分区;C3-0将消费 7,8,9分区。
假如我们有11个分区,那么最后分区分配的结果看起来是这样的:
- C1-0将消费 0,1,2,3分区;
- C2-0将消费 4,5,6,7分区;
- C3-0 将消费 8, 9, 10 分区。
假如我们有2个主题(T1和T2),分别有10个分区,那么最后分区分配的结果看起来是这样的:
- C1-0 将消费 T1主题的 0, 1, 2, 3 分区以及 T2主题的 0, 1, 2, 3分区
- C2-0将消费 T1主题的 4,5,6分区以及 T2主题的 4,5,6分区
- C3-0将消费 T1主题的 7,8,9分区以及 T2主题的 7,8,9分区

这就可以看出,C1-0 消费者线程⽐其他消费者线程多消费了2个分区,这就是Range strategy的⼀个很明显的弊端。如下图所示,Consumer0、Consumer1 同时订阅了主题 A 和 B,可能造成消息分配不对等问题,当消费者组内订阅的主题越多,分区分配可能越不均衡。
1.6.1.2 RoundRobin
RoundRobin 轮询⽅式将所有分区作为⼀个整体进⾏ Hash 排序,消费者组内分配分区个数最⼤差别为 1,是按照组来分的,可以解决多个消费者消费数据不均衡的问题。
轮询分区策略是把所有partition和所有consumer线程都列出来,然后按照hashcode进⾏排序。最后通过轮询算法分配partition给消费线程。如果所有consumer实例的订阅是相同的,那么partition会均匀分布。
在上面的例⼦⾥⾯,假如按照 hashCode排序完的topic-partitions组依次为T1-5,T1-3,T1-0,T1-8,T1-2,T1-1,T1-4,T1-7,T1-6,T1-9,我们的消费者线程排序为C1-0,C1-1,C2-0,C2-1,最后分区分配的结果为:
- C1-0将消费 T1-5,T1-2,T1-6分区;
- C1-1将消费 T1-3,T1-1,T1-9分区;
- C2-0将消费 T1-0,T1-4分区;
- C2-1将消费 T1-8,T1-7分区。
图文不符。
但是,当消费者组内订阅不同主题时,可能造成消费混乱,如下图所示,Consumer0 订阅主题A,Consumer1 订阅主题 B。
将 A、B 主题的分区排序后分配给消费者组,TopicB 分区中的数据可能分配到 Consumer0 中。
因此,使⽤轮询分区策略必须满⾜两个条件:

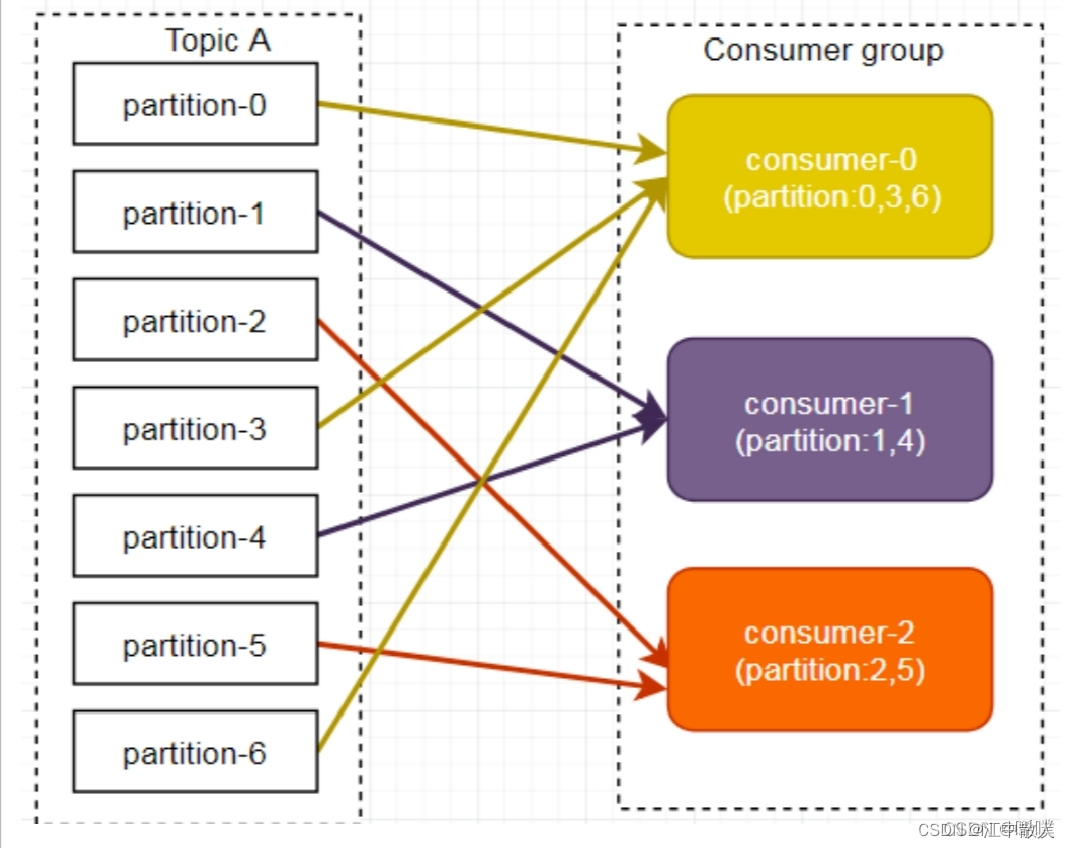
- 每个主题的消费者实例具有相同数量的流;
- 每个消费者订阅的主题必须是相同的。
注意,其实对于生产者而言,可以自定义push但哪个分区中,也可以使用如hash等方法。
1.6.1.3 Sticky
前两种rebalance方式需要重新映射,代价较大,特别是由于rebalance期间会暂停服务,这就要求该过程尽量短。Sticky在没有rebalance时采用轮询方式,发生rebalance时,尽量保持原映射关系,只是改变与宕机相关的映射,依然采用轮询的方式。
1.6.2 可靠性保证
在前面ack保障消息到了broker之后,消费者也需要有⼀定的保证,因为消费者也可能出现某些问题导致消息没有消费到。
这里介绍一下偏移量。每个consumer内存里数据结构保存对每个topic的每个分区的消费offset,定期会提交offset,0.9版本以后,提交offset发送给kafka内部额外生成的一个topic:__consumer_offsets,提交过去的时候, key是group.id+topic+分区号,value就是当前offset的值,每隔一段时间,kafka内部会对这个topic进行compact(合并),也就是每个group.id+topic+分区号就保留最新数据。
这里引入enable.auto.commit,默认为true,也就是⾃动提交offset,⾃动提交是批量执⾏的,有⼀个时间窗⼝,这种⽅式会带来重复提交或者消息丢失的问题,所以对于⾼可靠性要求的程序,要使⽤⼿动提交。对于⾼可靠要求的应⽤来说,宁愿重复消费也不应该因为消费异常⽽导致消息丢失。当然,我们也可以使用策略来避免消息的重复消费与丢失,比如使用事务,将offset与消息执行放在同一数据库中。
最后再简单介绍一个应用。kafka可以用在分布式延时队列中。创建一个额外的主题和一个定时进程,检测这个主题中是否有消息过期,过期后放在常规的消息队列中,消费者从这个常规的队列中获取消息来消费。
1.7 Kafka配额限速机制(Quotas)
生产者和消费者以极高的速度生产/消费大量数据或产生请求,从而占用broker上的全部资源,造成网络IO饱和。有了配额(Quotas)就可以避免这些问题。Kafka支持配额管理,从而可以对Producer和Consumer的produce&fetch操作进行流量限制,防止个别业务压爆服务器。
- 配额限速
- 可以限制Producer、Consumer的速率
- 防止Kafka的速度过快,占用整个服务器(broker)的所有IO资源
1.7.1 限制producer端速率
为所有client id设置默认值,以下为所有producer程序设置其TPS不超过1MB/s,即1048576/s,命令如下:
bin/kafka-configs.sh --zookeeper bigdata-pro-m07:2181 --alter --add-config 'producer_byte_rate=1048576' --entity-type clients --entity-default运行基准测试,观察生产消息的速率
bin/kafka-producer-perf-test.sh --topic test --num-records 500000 --throughput -1 --record-size 1000 --producer-props bootstrap.servers=bigdata-pro-m07:9092,bigdata-pro-m08:9092,bigdata-pro-m09:9092 acks=1结果:
50000 records sent, 1108.156028 records/sec (1.06 MB/sec)1.7.2 限制consumer端速率
对consumer限速与producer类似,只不过参数名不一样。
为指定的topic进行限速,以下为所有consumer程序设置topic速率不超过1MB/s,即1048576/s。命令如下:
bin/kafka-configs.sh --zookeeper bigdata-pro-m07:2181 --alter --add-config 'consumer_byte_rate=1048576' --entity-type clients --entity-default运行基准测试:
bin/kafka-consumer-perf-test.sh --broker-list bigdata-pro-m07:9092,bigdata-pro-m08:9092,bigdata-pro-m09:9092 --topic test --fetch-size 1048576 --messages 500000结果为:
MB.sec:1.07431.7.3 取消Kafka的Quota配置
使用以下命令,删除Kafka的Quota配置
bin/kafka-configs.sh --zookeeper bigdata-pro-m07:2181 --alter --delete-config 'producer_byte_rate' --entity-type clients --entity-default bin/kafka-configs.sh --zookeeper bigdata-pro-m07:2181 --alter --delete-config 'consumer_byte_rate' --entity-type clients --entity-default参考链接
Kafka超全精讲(一)_kafka精析_<一蓑烟雨任平生>的博客-CSDN博客
Kafka超全精讲(二)_kafka 函数库-CSDN博客
【精选】Kafka基本原理详解_昙花逐月的博客-CSDN博客
这是最详细的Kafka应用教程了 - 掘金
Kafka : Kafka入门教程和JAVA客户端使用-CSDN博客
简易教程 | Kafka从搭建到使用 - 知乎
【精选】kafka简介_唏噗的博客-CSDN博客
Kafka 架构及基本原理简析
kafka详解(一)--kafka是什么及怎么用
再过半小时,你就能明白kafka的工作原理了
Kafka 设计与原理详解
Kafka【入门】就这一篇! - 知乎
kafka简介_kafka_唏噗-华为云开发者联盟
kafka详解
kafka 学习 非常详细的经典教程-CSDN博客
相关文章:
Kafka-4.1-工作原理综述
1 Kafka工作原理详解 1.1 工作流程 Kafka集群将 Record 流存储在称为 Topic 的类中,每个记录由⼀个键、⼀个值和⼀个时间戳组成。 Kafka 中消息是以 Topic 进⾏分类的,⽣产者⽣产消息,消费者消费消息,⾯向的都是同⼀个Topic。Topi…...

Linux八股文
Linux八股文 第一章 Linux简介 Linux是一种多用户、多任务,支持多线程和多CPU的操作系统,具有免费、稳定、高效的优点,一般运行在大型服务器上。 1.1 常用目录 目录说明/根目录,有且仅有一个,一般只存放目录/home家目…...
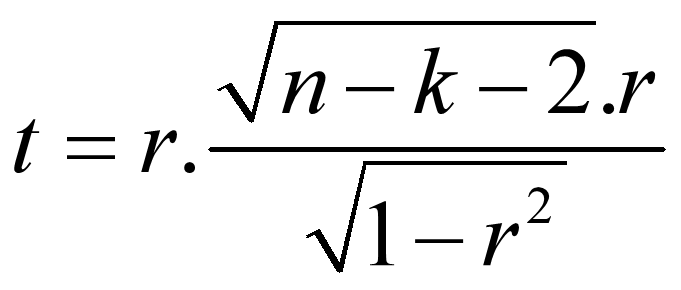
SPASS-偏相关分析
基本概念 偏相关分析的任务就是在研究两个变量之间的线性相关关系时控制可能对其产生影响的变量,这种相关系数称为偏相关系数。偏相关系数的数值和简单相关系数的数值常常是不同的,在计算简单相关系数时,所有其他自变量不予考虑。 统计原理 控制一个变量和控制两个变量的偏…...
第二证券:今日投资前瞻:小米汽车引关注 全球风光有望持续高速发展
昨日,两市股指盘中轰动上扬,深成指、创业板指一度涨超1%。到收盘,沪指涨0.55%报3072.83点,深成指涨0.72%报10077.96点,创业板指涨0.53%报2015.36点,北证50指数涨2.64%;两市算计成交9900亿元&…...
Docker中的RabbitMQ已经启动运行,但是管理界面打不开
文章目录 前言一、解决方法方法一方法二 总结 前言 肯定有好多小伙伴在学习RabbitMQ的过程中,发现镜像运行,但是我的管理界面怎么进不去,或者说我第一天可以进去,怎么第二天进不去了,为什么每次重新打开虚拟机都进不去…...

自动化网络图软件
由于 IT 系统的发展、最近向混合劳动力的转变、不断变化的客户需求以及其他原因,网络监控变得更加复杂。IT 管理员需要毫不费力地可视化整个网络基础设施,通过获得对网络的可见性,可以轻松发现模式、主动排除故障、确保关键设备可用性等。 为…...
如何基于亚马逊云科技打造高性能的 SQL 向量数据库 MyScale
MyScale 是一款完全托管于亚马逊云科技,支持 SQL 的高效向量数据库。MyScale 的优势在于,它在提供与专用向量数据库相匹敌甚至优于的性能的同时,还支持完整的 SQL 语法。在这篇文章中,我们将阐述 MyScale 是如何借助亚马逊云科技的…...
《轻松入门!快速安装PyCharm,打造高效Python编程环境》
「Pycharm安装包和相关插件(Windows 64位)」https://www.aliyundrive.com/s/jByv6vjShVz 提取码: 1234 视频教程:https://www.douyin.com/video/7303106933521763596?previous_pageapp_code_link 第一步:找到一起下载的Pycharm安…...

Golang环境搭建Win10(简洁版)
Golang环境搭建Win10 Golang环境搭建(Win10)一、前言二、Golang下载三、配置环境变量3.1、配置GOROOT3.2、配置GOPATH3.3、配置GOPROXY代理 Golang环境搭建(Win10) 一、前言 Go(又称 Golang)是 Google 的 Robert Griesemer,Rob Pike 及 Ken…...
【算法每日一练]-分块(保姆级教程 篇1)POJ3648
插讲一下分块 题目:(POJ 3648) 一个简单的整数问题 前缀和往往用于静态的不会修改的区间和。遇到经常修改的区间问题,就要用分块或线段树来维护了。 分块算法是优化后的暴力,分块算法有时可以维护一些线段树维护不了的…...

【华为OD题库-026】通过软盘拷贝文件-java
题目 有一名科学家想要从一台古董电脑中拷贝文件到自己的电脑中加以研究。但此电脑除了有一个3.5寸软盘驱动器以外,没有任何手段可以将文件拷贝出来,而且只有一张软盘可以使用。因此这一张软盘是唯一可以用来拷贝文件的载体。科学家想要尽可能多地将计算…...

定量数据和定性数据
定量数据本质上是数值,应该是衡量某样东西的数量。 定性数据本质上是类别,应该是描述某样东西的性质。 全部的数据列如下,其中既有定性列也有定量列; import pandas as pdpd.options.display.max_columns None pd.set_option(e…...
【Linux】:体系结构与进程概念
朋友们、伙计们,我们又见面了,本期来给大家解读一下有关Linux体系结构和进程的知识点,如果看完之后对你有一定的启发,那么请留下你的三连,祝大家心想事成! C 语 言 专 栏:C语言:从入…...

react-router-dom 版本6.18.0中NavLink的api和属性介绍
React Router 是一个基于 React 的路由库,它可以帮助我们在 React 应用中实现页面的切换和路由的管理。而 NavLink 则是 React Router 中的一个组件,它可以帮助我们实现导航栏的样式设置和路由跳转。 在 React Router 版本6.18.0 中,NavLink…...
和KD树区别?2d tree与3d tree区别?)
八叉树(Octree)和KD树区别?2d tree与3d tree区别?
一、八叉树(Octree)和KD树 八叉树(Octree) 结构:八叉树是一种用于三维空间数据的树状结构,每个分支节点恰好有八个子节点。每个节点代表空间中的一个立方体区域,这个立方体区域被均匀地分割成…...
)
Union(联合体、共用体)
结构体和共用体的区别在于:结构体的各个成员会占用不同的内存,互相之间没有影响;而共用体的所有成员占用同一段内存,修改一个成员会影响其余所有成员。 结构体占用的内存大于等于所有成员占用的内存的总和(成员之间可能…...

C++11的互斥包装器
文章目录 1. 为何要引入互斥包装器?2. lock_guard3. unique_lock4. 两者之间的不同5. 总结 1. 为何要引入互斥包装器? 在C多线程中会经常用到mutex,在使用的时候lock后,有时候会忘记使用unlock进行解锁造成死锁,或者在…...
HR应用在线人才测评,给企业招聘带来的好处
一、什么是人才测评? 人才测评是指运用一系列的科学方法,对人的基本素质,专业能力,心理健康,性格进行选拔,评价及发展人才的一种科学方法。近十多年,它被广泛运用于国有大型企业的人才招聘和人…...

深入了解百度爬虫工作原理
在当今数字化时代,互联网已经成为人们获取信息的主要渠道之一。而搜索引擎作为互联网上最重要的工具之一,扮演着连接用户与海量信息的桥梁角色。然而,我们是否曾经好奇过当我们在搜索引擎中输入关键词并点击搜索按钮后,究竟是如何…...

【C语言基础】分享近期学习到的volatile关键字、__NOP__()函数以及# #if 1 #endif
📢:如果你也对机器人、人工智能感兴趣,看来我们志同道合✨ 📢:不妨浏览一下我的博客主页【https://blog.csdn.net/weixin_51244852】 📢:文章若有幸对你有帮助,可点赞 👍…...

终极Node.js Mock工具:Mockery入门到精通实战教程
终极Node.js Mock工具:Mockery入门到精通实战教程 【免费下载链接】mockery Simplifying the use of mocks with Node.js 项目地址: https://gitcode.com/gh_mirrors/mock/mockery Mockery是Node.js生态中简化Mock使用的终极工具,它为开发者提供了…...

独立开发者如何利用Taotoken Token Plan,以更低成本启动AI项目
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何利用Taotoken Token Plan,以更低成本启动AI项目 对于独立开发者或小型团队而言,启动一个集成…...

十年以上经验的建站公司推荐|策划强、落地稳的网站制作公司盘点
互联网时代,企业官网已从单纯的信息展示窗口升级为集品牌价值传递、用户体验连接与业务高效转化于一体的核心数字阵地。行业报告显示,优质官网可帮助企业线上转化率提升35%-60%,而低效官网则可能导致潜在客户大量流失。面对市场上众多的网站建…...

约束感知图缩减算法在量子优化中的应用
1. 约束感知图缩减算法概述在量子计算领域,资源受限一直是制约算法实际应用的主要瓶颈。以当前主流的超导量子计算机为例,其量子比特数通常在50-100个之间,且存在显著的噪声干扰。这种硬件限制使得许多经典优化问题难以直接映射到量子设备上求…...

如何在5分钟内使用CrewAI Studio快速搭建AI工作流:零代码AI智能体开发终极指南
如何在5分钟内使用CrewAI Studio快速搭建AI工作流:零代码AI智能体开发终极指南 【免费下载链接】CrewAI-Studio A user-friendly, multi-platform GUI for managing and running CrewAI agents and tasks. Supports Conda and virtual environments, no coding need…...

猫抓浏览器扩展终极指南:5分钟掌握全网视频资源下载技巧
猫抓浏览器扩展终极指南:5分钟掌握全网视频资源下载技巧 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 你是否经常遇到心仪的视频无法…...

Claude Agent SDK 从 0 到 1 快速上手教程
Claude Agent SDK 从 0 到 1 快速上手教程 什么是 Claude Agent SDK? Claude Agent SDK 是 Anthropic 官方推出的用于构建 AI 智能体的开发工具包。它基于 Claude Code 构建,让开发者能够以编程方式创建、扩展和定制由 Claude 驱动的应用程序。与简单的聊天机器人不同,基于…...

你的差异基因结果可靠吗?用MetaVolcanoR给多个GEO数据集做一次‘交叉验证’吧
你的差异基因结果可靠吗?用MetaVolcanoR给多个GEO数据集做一次"交叉验证"当你在GEO数据库中下载了三个肺癌研究的差异表达结果,却发现三个DEG列表的重叠基因不到20%——这种令人沮丧的场景每天都在全球实验室上演。单项研究的差异分析结果就像…...

ComfyUI-WD14-Tagger:AI智能图像标签提取的终极完整指南
ComfyUI-WD14-Tagger:AI智能图像标签提取的终极完整指南 【免费下载链接】ComfyUI-WD14-Tagger A ComfyUI extension allowing for the interrogation of booru tags from images. 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI-WD14-Tagger 在AI图像…...

在多模型聚合场景下利用Taotoken实现API调用的自动降级与容灾
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在多模型聚合场景下利用Taotoken实现API调用的自动降级与容灾 对于依赖大模型API的生产系统而言,服务的连续性与稳定性…...