LLM大模型 (chatgpt) 在搜索和推荐上的应用
目录
- 1 大模型在搜索的应用
- 1.1 召回
- 1.1.1 倒排索引
- 1.1.2 倒排索引存在的问题
- 1.1.3 大模型在搜索召回的应用 (实体倒排索引)
- 1.2 排序
- 1.2.1 大模型在搜索排序应用(融入LLM实体排序)
- 2 大模型在推荐的应用
- 2.1 学术界关于大模型在推荐的研究
- 2.2 推荐存在的一些问题
- 2.3 大模型在推荐的应用 (加强用户实时兴趣识别)
- 3 总结
1 大模型在搜索的应用
1.1 召回
我们知道在搜索中,item的召回主要还是基于关键词召回,但是用户表达与商家对item的描述存在差异导致一些长尾query可能召回很少或者召不回item,虽然现在有语义模型可以减少这种问题出现,但当数据稀疏,训练样本较少的情况下,基于语义向量召回效果也并不好。
那么大模型是不是可以提高召回的效果?答案是可以的,大模型的一个优势就是有多领域知识,可以更好的理解信息。接下来介绍用大模型做基础工作提升召回效果
1.1.1 倒排索引
基于关键词的召回,我们首先要清楚什么是倒排索引,如下图所示:
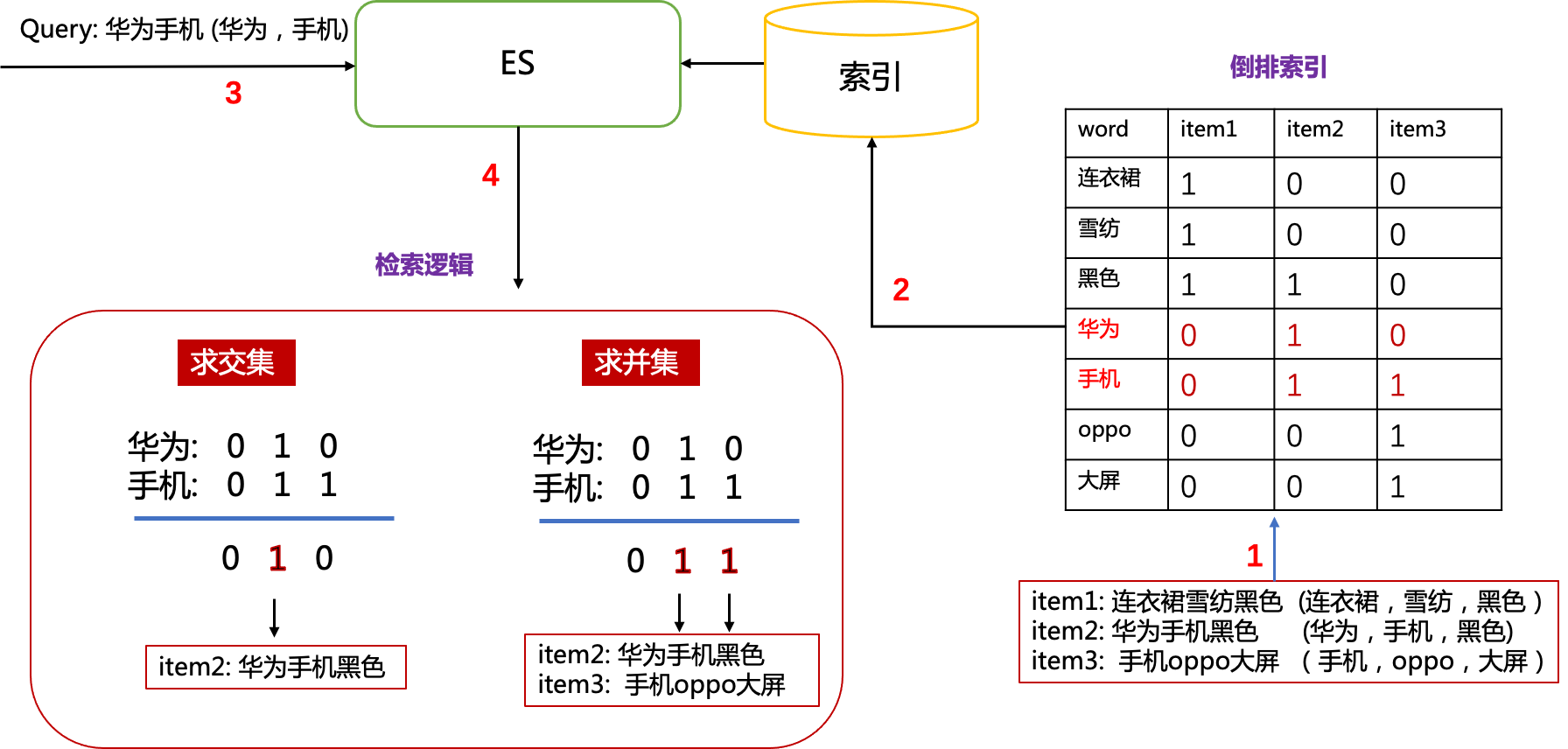
上述整个流程表示了倒排索引是如何建立的以及ES如何基于倒排索引进行检索。
1.1.2 倒排索引存在的问题
由于用户与商家存在表达差异以及数据噪声等问题,导致基于倒排索引进行召回存在一些问题,假设我们有如下倒排索引数据:
| 索引词 | 文档 |
|---|---|
| 挂面 | 福临门挂面500g*2袋 |
| 面 | 福临门挂面500g*2袋,佰草集白泥面膜组合 |
| 白 | 佰草集白泥面膜组合 |
| … | … |
当用户搜索query=‘白面’,通过切词,可以切分为:"白|面"两个term,从上面倒排索引表可以看出,同时命中“白"和"面“文本是:“佰草集白泥面膜组合”,反而和query相关的文本:“福临门挂面500g*2袋”没能够同时命中这两个term。主要原因是用户表达与商家描述存在差异,同时数据噪声加大了索引建立的复杂性通过语义向量进行召回减少了这种问题,但是需要大量的数据训练模型,才有较好的效果,当数据量不足的时候,效果并不佳。
1.1.3 大模型在搜索召回的应用 (实体倒排索引)
大模型的优势是基于庞大的多类型数据进行学习的,所以有很强的通用知识能力。我们可以基于大模型来优化倒排索引,提升召回的效果。通过大模型对文本生成标准的实体词,比如 {洗面奶,手机,苹果,牛奶,口红,馒头,香蕉,面, 面膜,蛋糕等},基于大模型的理解能力,将文本映射到标准的实体词中,同时对用户输入的query也映射到实体词,这样就可以将query与item的标准实体词建立关联。首先,我们构造好我们的promp,让chatgpt生成我们想要的结果,我们prompt模板可以这么写:
给定如下实体词和文本内容,给出每条文本内容对应的实体词
输出格式:{文本内容:实体词}
实体词:{洗面奶,手机,苹果,牛奶,口红,馒头,香蕉,面, 面膜,蛋糕}
文本内容: {白面, 平安质优 福临门挂面500g*2袋,佰草集白泥面膜组}
然后我们调用chatgpt进行预测,如下所示:
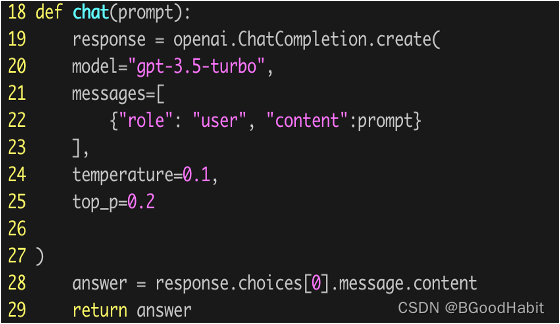
得到的结果如下:
{白面: 面, 平安质优 福临门挂面500g*2袋: 面, 佰草集白泥面膜组合: 面膜}
从测试来看,预测的还是比较准确的。这样,我们可以基于大模型建立标准化的实体索引,索引建立如下:
| 索引词 | 标准化实体索引 | 文档 |
|---|---|---|
| 挂面 | 面 | 福临门挂面500g*2袋 |
| 面 | 面 | 福临门挂面500g*2袋,佰草集白泥面膜组合 |
| 白 | 面膜 | 佰草集白泥面膜组合 |
| … | … | … |
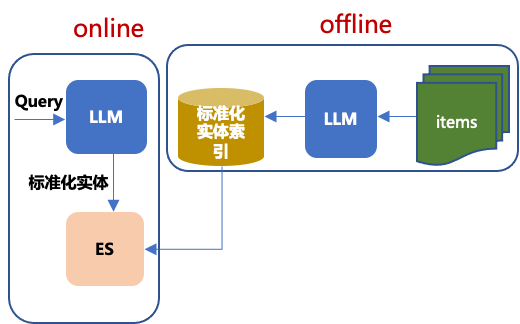
用chatgpt对query和item生成标准实体词,通过实体词建立索引关系,这种方式可以减少用户表达与item信息描述的差异导致召不回或者召不准的问题,索引建立流程图如下所示:
1.2 排序
在搜索中,影响语义排序算法主要有三个核心部分,我们基于双塔模型的结构来讲解,如下所示:
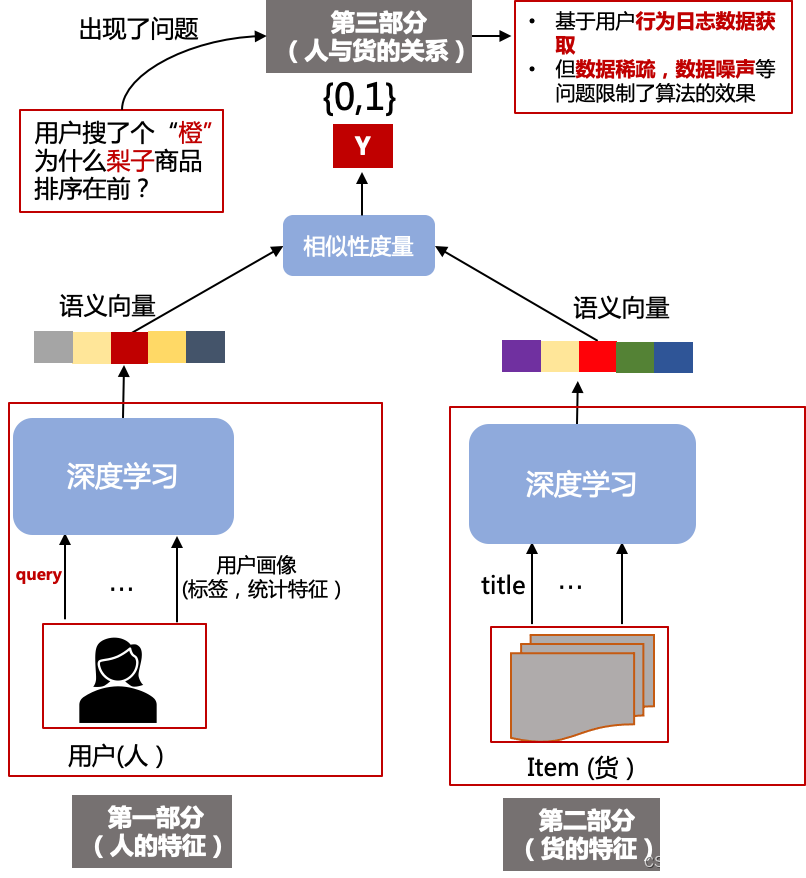
第一部分 (人的特征):在搜索里面,核心是用户搜索的query,还有用户历史行为以及画像等特征
第二部分 (货的特征):这里主要包括货(item)的标题,标签等特征
第三部分 (人与货的关系):主要基于用户行为比如:曝光,点击,转化等反馈数据中建立关系,这也是我们的模型训练样本主要来源。若用户点击了一个item,则这个用户与item的样本label我们就认为是正样本y=1,否则y=0。但是在现实场景中,数据稀疏,数据噪声等问题,导致模型对人与货的匹配学习存在较大的挑战,有可能会犯我们人看来很“低级“的错误,比如用户搜索一个“橙",模型反而将“梨子"相关的item给出的排序分比有“橙子"的item分还高。
1.2.1 大模型在搜索排序应用(融入LLM实体排序)
所以,顺着我们上述部分讲述的大模型在搜索召回层的应用,在排序层我们其实也可以利用大模型的通用知识理解能力,融入大模型的通用知识实体排序,如下图所示:
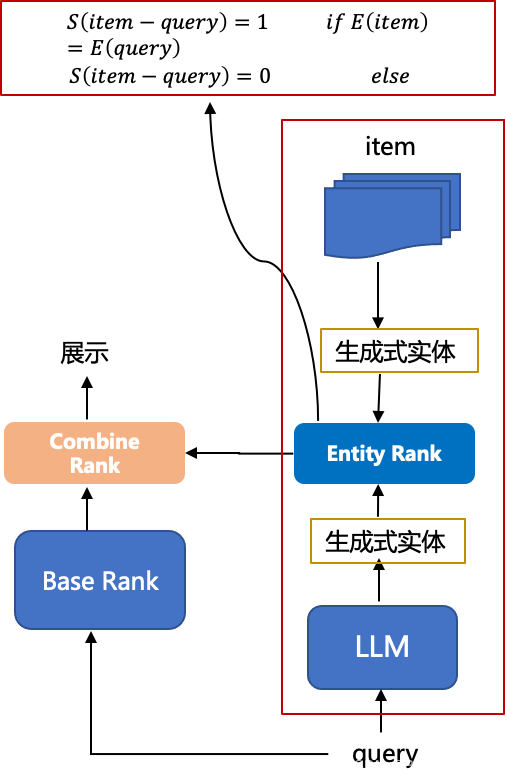
我们可以基于大模型对query与item生成的标准实体进行简单的匹配打分再融合到最终的排序的模型里,融合部分可以简单的进行加权求和得到最终的排序分也可以将大模型对query和item生成的标准实体作为基础排序模型特征输入等。
在这里也尝试了下用大模型生成向量,基于余弦值做相似度分计算,如下是调用chatgpt计算向量相似分代码:
def embedding(content):response = openai.Embedding.create(model="text-embedding-ada-002",input=content)embs = response.data[0].embeddingreturn embsif __name__=='__main__':query = '白面'content_1 ='福临门挂面500g*2袋'content_2 = '草集白泥面膜组合'q_emb = np.array(embedding(query))c1_emb = np.array(embedding(content_1))c2_emb = np.array(embedding(content_2))# cos simiqc1_cos = q_emb.dot(c1_emb) / (np.linalg.norm(q_emb) * np.linalg.norm(c1_emb))qc2_cos = q_emb.dot(c2_emb) / (np.linalg.norm(q_emb) * np.linalg.norm(c2_emb))print('query:%s\nitem:%s\n相似度为:%s' % (query, content_1, qc1_cos))print('query:%s\nitem:%s\n相似度为:%s' % (query, content_2, qc2_cos))
输出结果为:

从结果来看,query=‘白面’与item='草集白泥面膜组合’相似分更高😞😞😞😞😞😞😞😞
看来不理想,不过具体openai提供的抽取词向量模型model="text-embedding-ada-002"具体结构是怎样也不是很清楚。
2 大模型在推荐的应用
2.1 学术界关于大模型在推荐的研究
如下是一些大模型在推荐的研究论文:
- Is ChatGPT a Good Recommender? A Preliminary Study
- Uncovering ChatGPT’s Capabilities in Recommender Systems
- LKPNR: LLM and KG for Personalized News Recommendation Framework
- HeterogeneousKnowledgeFusion:ANovelApproachforPersonalized RecommendationviaLLM
- LLM-Rec:Personalized Recommendation via Prompting Large Language Models
- PALR:Personalization Aware LLMs for Recommendation
- …
从上面的一些paper关于大模型在推荐的应用,整体总结如下图所示:
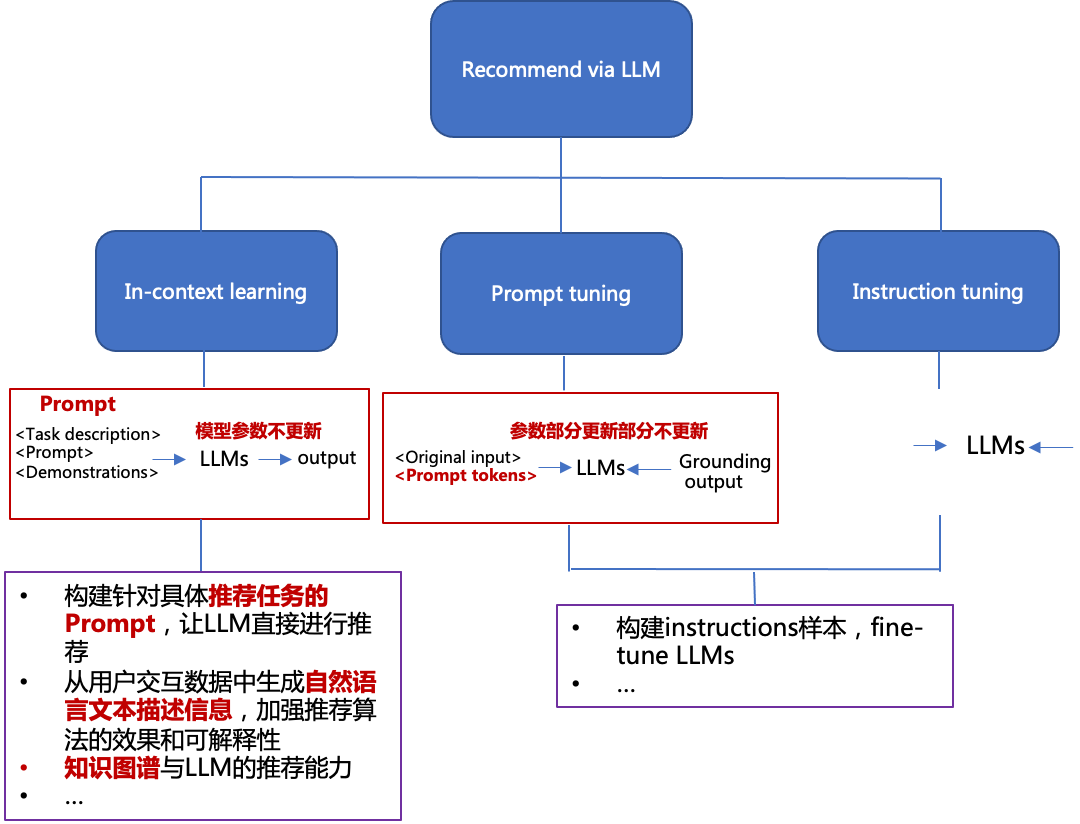
整体还是偏向In-context learning。通过构造 task-specific prompt让大模型进行推荐或者生成更丰富的信息内容提升base推荐模型的效果。
2.2 推荐存在的一些问题
当用户行为数据稀疏,数据量不足的时候,推荐系统存在的一些基础问题如下图所示:
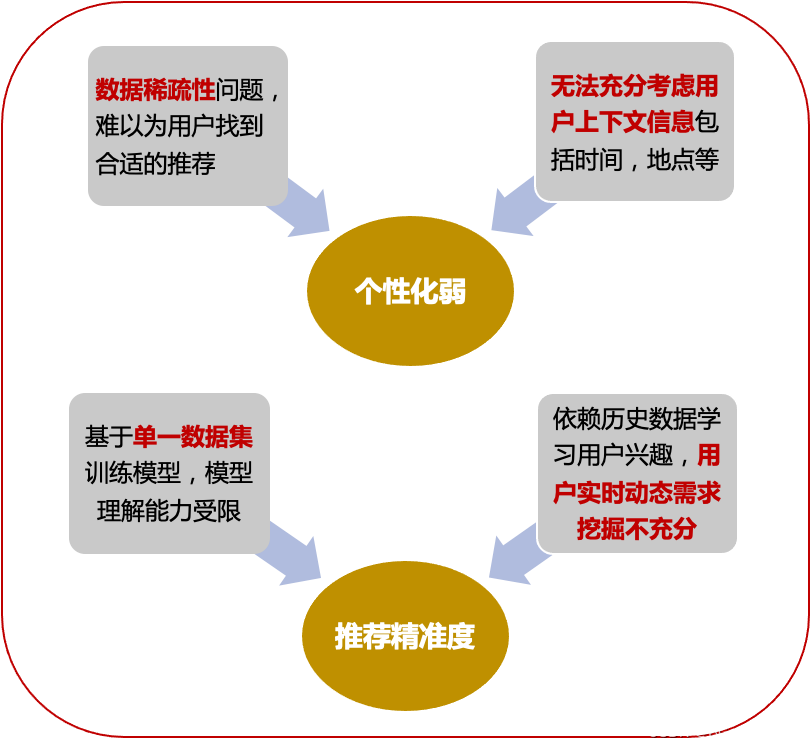
主要是两大类问题:个性化弱以及精准度问题。
2.3 大模型在推荐的应用 (加强用户实时兴趣识别)
我们可以利用大模型的强大推理以及通用知识能力,让大模型根据用户实时的行为以及场景信息进行用户实时兴趣识别,提升推荐的精准度。下面给出了一个基本方案的流程图:
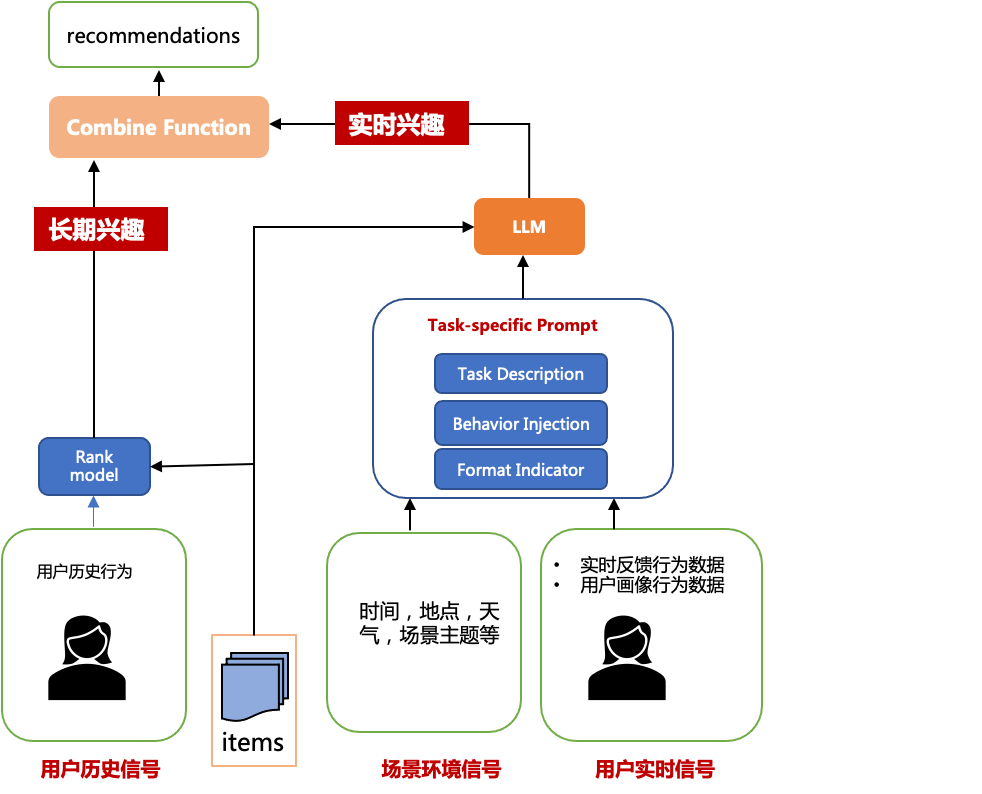
让我们给定一些场景信息测试下chatgpt对用户的实时场景兴趣的理解,我们的prompt构造如下:
Task Description:
基于如下用户的画像以及环境信息,针对给出的服务类型:[洗车,加油,代驾,保养,租车],推测出用户接下来在什么时间点做什么服务
Behavior Injection:
{“用户画像":[女,35岁,居住深圳],
“环境信息”:[晚上9点,在北京]
}
Format Indicator:
输出格式:{服务类型:理由:服务概率}
我们调用chatgpt api如下:
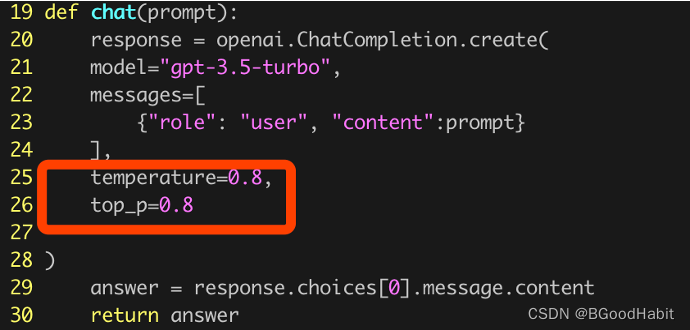
上面红色框的两个参数控制生成文本保守和确定性控制,值越低表示越保守。如下是chatgpt给出的结论:
{“服务类型”:“租车”,“理由”:“用户属性为女性,35岁,长住深圳,晚上9点位于北京,可能是因为需要在北京出差或旅行,所以最有可能需要租车服务。“服务概率”:0.8}
整体来说还是比较符合常规的,我们可以基于实时用户行为数据以及场景信息,借助大模型的强大推理以及通用知识能力进行用户实时意图的理解,让推荐算法更加智能,更好的理解用户的实时用兴趣和需求。
3 总结
本博文给出了大模型在搜索和推荐的一些基础应用,主要针对现有搜索和推荐存在的问题,借助大模型强大的推理能力以及通用知识能力进行一些优化。但大模型在搜索和推荐上的应用还有更多更好的方式,👏🏻欢迎有新兴趣的小伙伴能够一起交流和学习。
相关文章:
LLM大模型 (chatgpt) 在搜索和推荐上的应用
目录 1 大模型在搜索的应用1.1 召回1.1.1 倒排索引1.1.2 倒排索引存在的问题1.1.3 大模型在搜索召回的应用 (实体倒排索引) 1.2 排序1.2.1 大模型在搜索排序应用(融入LLM实体排序) 2 大模型在推荐的应用2.1 学术界关于大模型在推荐的研究2.2 …...

中国净初级生产力年度合成产品NPP(MYD17A3H.006)
中国净初级生产力年度合成产品NPP(MYD17A3H.006)由航天宏图实验室提供,根据NASA MODIS数据(MYD17A3H.006)通过航天宏图 Smoother计算得到的平滑后NPP产品,解决了影像云雾覆盖、像元异常值等问题。对处理后的…...
GitHub如何删除仓库
GitHub如何删除仓库 删除方法第一步第二步第三步 删除方法 第一步 在仓库的界面选择Settings 第二步 选择General,页面拉到最后。 第三步 删除仓库。...

漫谈广告机制设计 | 万剑归宗:聊聊广告机制设计与收入提升的秘密(3)
书接上文漫谈广告机制设计 | 万剑归宗:聊聊广告机制设计与收入提升的秘密(2),我们聊到囚徒困境是完全信息静态博弈,参与人存在占优策略,最终达到占优均衡,并且是对称占优均衡。接下来我们继续…...

安装系统时无raid驱动处理办法
场景描述 安装系统时可以进入安装界面,但是无法识别到硬盘,查看服务器硬件均无异常且从bios或者raid配置界面中能正常看到raid信息及硬盘信息,运行lspci 命令查看到服务器有raid卡,但是未加载驱动。 获取驱动程序模块 查看raid…...
ForkLift:macOS文件管理器/FTP客户端
ForkLift 是一款macOS下双窗口的文件管理器,可以代替本地的访达。ForkLift同时具备连接Ftp、SFtp、WebDav以及云服务器。 ForkLift还具备访达不具备的小功能,比如从文件夹位置打开终端,显示隐藏文件,制作替换等功能。ForkLift 是一…...

信息系统项目管理师 第四版 第20章 高级项目管理
1.项目集管理 1.1.项目集管理标准 1.2.项目集管理角色和职责 1.3.项目集管理绩效域 2.项目组合管理 2.1.项目组合管理标准 2.2.项目组合管理角色和职责 2.3.项目组合管理绩效域 3.组织级项目管理 3.1.组织级项目管理标准 3.2.业务价值与业务评估 3.3.OPM框架要素 3…...
Apache Pulsar 技术系列 - 基于 Pulsar 的海量 DB 数据采集和分拣
导语 Apache Pulsar 是一个多租户、高性能的服务间消息传输解决方案,支持多租户、低延时、读写分离、跨地域复制、快速扩容、灵活容错等特性。本文是 Pulsar 技术系列中的一篇,主要介绍 Pulsar 在海量DB Binlog 增量数据采集、分拣场景下的应用。 前言…...

HDFS、MapReduce原理--学习笔记
1.Hadoop框架 1.1框架与Hadoop架构简介 (1)广义解释 从广义上来说,随着大数据开发技术的快速发展与逐步成熟,在行业里,Hadoop可以泛指为:Hadoop生态圈。 也就是说,Hadoop指的是大数据生态圈整…...

PC端使子组件的弹框关闭
子组件 <template><el-dialog title"新增部门" :visible"showDialog" close"close"> </el-dialog> </template> <script> export default {props: {showDialog: {type: Boolean,default: false,},},data() {retu…...
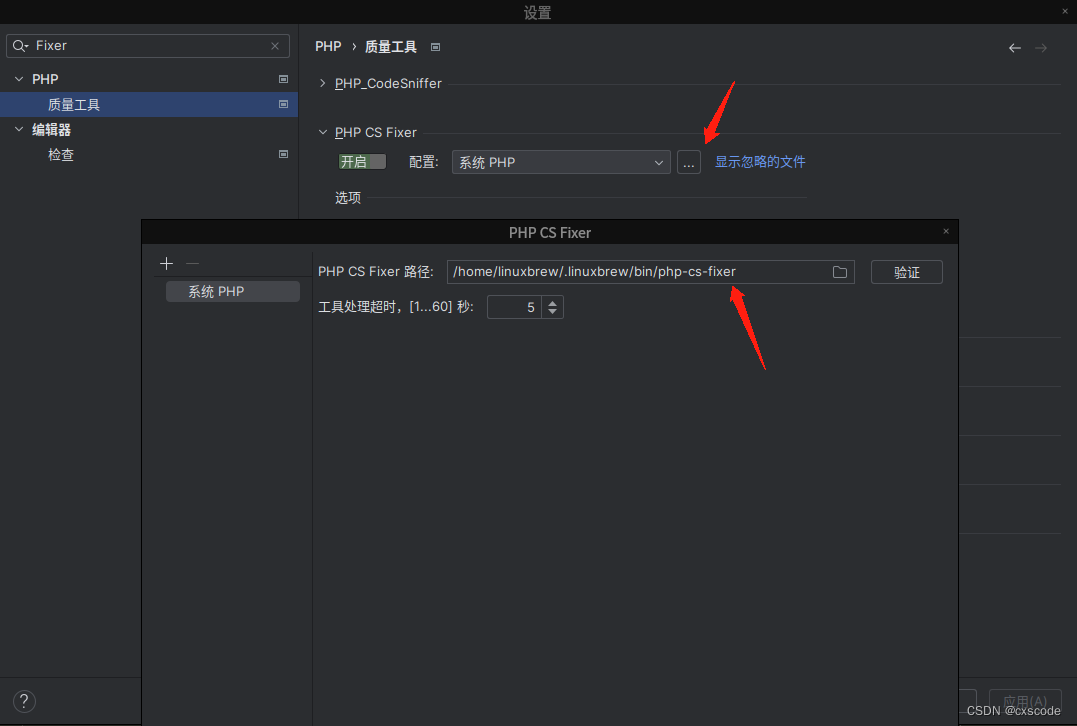
PHPStorm PHP-CS-Fixer
我用的是brew安装: brew install php-cs-fixer phpstorm配置: setting搜索fixer 指定安装php-cs-fixer的目录: https://github.com/PHP-CS-Fixer/PHP-CS-Fixer/blob/master/doc/installation.rst 图文详解PHPStorm实现自动执行代码格式化-…...

SpringBoot中日志的使用log4j
SpringBoot中日志的使用log4j 项目中日志系统是必不可少的,目前比较流行的日志框架有 log4j、logback 等,这两个框架的作者是同一个 人,Logback 旨在作为流行的 log4j 项目的后续版本,从而恢复 log4j 离开的位置。 另外 slf4j(…...

迭代器与生成器
章节目录: 一、迭代器1.1 相关概述1.2 基本使用1.3 自定义迭代器 二、生成器2.1 相关概述2.2 基本使用2.3 三种应用场景 三、yield 和 class 定义的迭代器对比四、结束语 一、迭代器 1.1 相关概述 迭代是 Python 最强大的功能之一,是访问集合元素的一种…...
适用于 Windows 的 10 个最佳视频转换器:快速转换高清视频
您是否遇到过由于格式不兼容而无法在您的设备上播放视频或电影的情况?您想随意播放从您的相机、GoPro 导入的视频,还是以最合适的格式将它们上传到媒体网站?您的房间里是否有一堆 DVD 光盘,想将它们转换为数字格式以便于播放&…...

分布式锁的概念、应用场景、实现方式和优缺点对比
一:什么是分布式锁 分布式锁是一种用于协调分布式系统中多个节点对共享资源的访问的机制。在分布式系统中,由于多个节点的并发执行,可能会导致对共享资源的竞争,而分布式锁的目的就是确保在任何时刻,只有一个节点能够持…...

Linux:常见指令
个人主页 : 个人主页 个人专栏 : 《数据结构》 《C语言》《C》 文章目录 前言一、常见指令ls指令pwd指令cd指令touch指令mkdir指令rmdir指令rm指令man指令cp指令mv指令cat指令tac指令echo指令more指令less指令head指令tail指令date显示Cal指令find指令gr…...

大数据基础设施搭建 - ZooKeeper
文章目录 一、上传压缩包二、解压压缩包三、本机安装3.1 修改配置文件3.1.1 创建ZooKeeper数据存储目录3.1.2 修改配置文件名3.1.2 修改配置文件内容 3.3 启动/停止服务端3.4 测试(1)启动客户端(2)测试客户端操作 四、集群安装4.1…...

网站优化工具Google Optimize
Google Optimize 是一款由Google提供的网站优化工具。Google Optimize旨在帮助网站管理员通过对网页内容、设计和布局进行测试和优化,来提升用户体验和网站的转化率。 Google Optimize 提供了 A/B 测试和多变量测试功能,使网站管理员能够比较和评估不同…...

PostgreSQL创建分区表,并插入大量数据
创建分区表,按日期范围分区 CREATE TABLE sales (id serial,sale_date DATE, amount NUMERIC, PRIMARY KEY(id, sale_date) ) PARTITION BY RANGE (sale_date); 创建分区 CREATE TABLE sales_2019 PARTITION OF sales FOR VALUES FROM (2019-0…...

NewStarCTF2023 Reverse Week3 EzDLL WP
分析 这里调用了z3h.dll中的encrypt函数。 用ida64载入z3h.dll 直接搜索encrypt 找到了一个XTEA加密。接着回去找key和密文。 发现key 这里用了个调试状态来判断是否正确,v71,要v7=1才会输出Right,即程序要处于飞调试状态。 可…...

render_async嵌套渲染:构建复杂异步界面的完整解决方案
render_async嵌套渲染:构建复杂异步界面的完整解决方案 【免费下载链接】render_async render_async lets you include pages asynchronously with AJAX 项目地址: https://gitcode.com/gh_mirrors/re/render_async 在现代Web开发中,页面加载速度…...

Go开发者必备:circuitbreaker API全解析与最佳实践指南 [特殊字符]
Go开发者必备:circuitbreaker API全解析与最佳实践指南 🚀 【免费下载链接】circuitbreaker Circuit Breakers in Go 项目地址: https://gitcode.com/gh_mirrors/circ/circuitbreaker 作为一名Go开发者,你是否经常遇到远程服务调用失败…...
)
别再纠结了!给激光焊接新手讲透单模和多模激光到底怎么选(附M²因子解读)
激光焊接设备选型指南:单模与多模激光的实战抉择 当你第一次站在激光焊接设备采购的十字路口,面对"单模"和"多模"这两个专业术语时,那种迷茫感我深有体会。五年前,我作为产线技术负责人,需要为汽车…...

开源三角洲机器人Delta-Robot One:从入门到精通的创客实践指南
1. 项目概述:一个为学习而生的开源三角洲机器人如果你对机器人感兴趣,但又觉得它高深莫测、无从下手,那么Delta-Robot One(我们亲切地称它为“One”)可能就是为你量身打造的入门项目。这不是一个遥不可及的工业设备&am…...

为什么你的霓虹总像“塑料灯带”?Midjourney光子散射模拟缺陷曝光:3个被官方隐瞒的--sref调参禁区
更多请点击: https://kaifayun.com 第一章:为什么你的霓虹总像“塑料灯带”? 霓虹效果在现代 UI 设计中无处不在——按钮悬停、加载指示器、焦点高亮……但多数实现却流于表面:生硬的 box-shadow、固定色值的渐变边框、缺乏物理感…...
)
【独家首发】Sora 2 AVI支持并非“开箱即用”:3层封装校验机制详解(RIFF→AVI→OpenCV Mat内存映射链路图解)
更多请点击: https://codechina.net 第一章:Sora 2 AVI支持并非“开箱即用”:核心矛盾与技术定位 Sora 2 的官方文档与发布说明中明确将 AVI 视为“实验性容器支持”,而非默认启用的输入格式。其底层解码栈基于 FFmpeg 5.1 构建&…...

红外信号逆向工程:破解电磁炉协议实现抽油烟机智能联动
1. 项目概述:当电磁炉与抽油烟机“对话”厨房里的自动化,听起来像是未来智能家居的专属,但其实很多乐趣和便利就藏在身边已有的设备里。我最近给家里的厨房换上了一台新的电磁炉,在翻阅说明书时,偶然发现了一个名为“h…...

第十五章:Agent产品的监控与可观测性:如何构建“看得见、管得住“的AI系统
导读 想象一下:你上线了一个客服Agent,第一个月运行平稳。第二个月开始,你陆续收到用户投诉说"答案不对"。但你的监控系统显示:请求量正常、延迟正常、错误率正常。你打开日志,发现Agent确实"成功"处理了每个请求——只是它给错了答案。 这不是监控…...

2026年新能源人才全球本地化策略
导读:报告基于领英行业洞察,聚焦 2026 年全球新能源行业发展格局、中国企业出海现状、人才供需痛点及全球化人才本地化落地策略,为新能源企业海外人才招聘、培养与组织管理提供完整解决方案。关注公众号:【互联互通社区】…...

机器学习预测关税冲击下的股市波动:随机森林、SVR、kNN与线性回归实战对比
1. 项目概述与核心问题拆解做量化研究的朋友们,尤其是关注宏观事件对市场冲击的,应该都对“黑天鹅”事件不陌生。政策变动,特别是像关税这种直接影响国际贸易成本和公司利润的宏观变量,往往会在短期内引发市场剧烈波动。传统的做法…...