MySQL InnoDB 引擎底层解析(一)
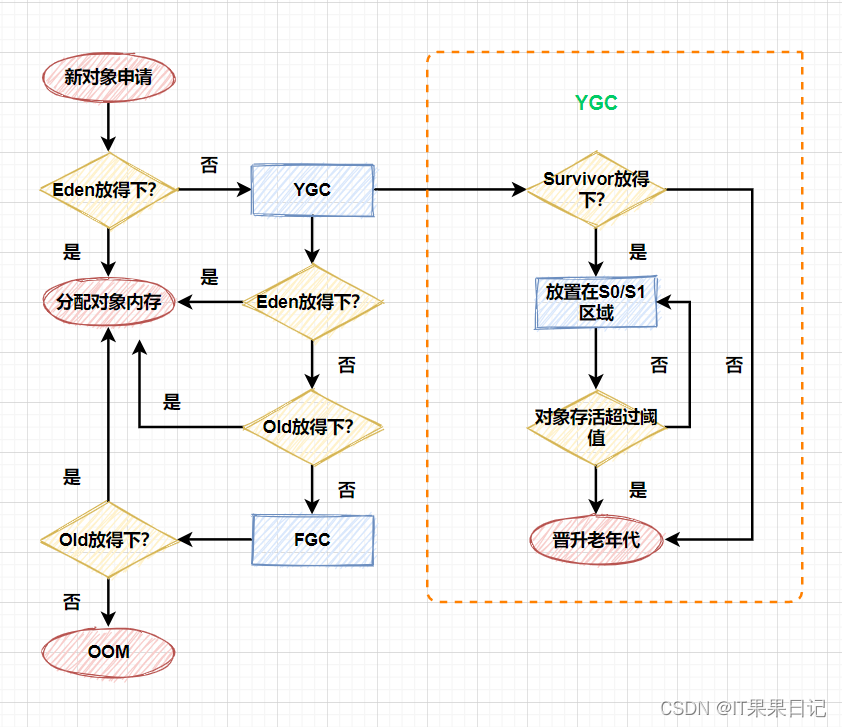
6. InnoDB 引擎底层解析
MySQL 对于我们来说还是一个黑盒,我们只负责使用客户端发送请求并等待服务器返回结果,表中的数据到底存到了哪里?以什么格式存放的?MySQL 是以什么方式来访问的这些数据?这些问题我们统统不知道。要搞明白查询优化背后的原理,就必须深入 MySQL 的底层去一探究竟,而且事务、锁等的原理也要求我们必须深入底层。
6.1. InnoDB 记录存储结构和索引页结构
InnoDB 是一个将表中的数据存储到磁盘上的存储引擎,所以即使关机后重启我们的数据还是存在的。而真正处理数据的过程是发生在内存中的,所以需要把磁盘中的数据加载到内存中,如果是处理写入或修改请求的话,还需要把内存中的内容刷新到磁盘上。而我们知道读写磁盘的速度非常慢,和内存读写差了几个数量级,所以当我们想从表中获取某些记录时,InnoDB 存储引擎需要一条一条的把记录从磁盘上读出来么?
InnoDB 采取的方式是:将数据划分为若干个页,以页作为磁盘和内存之间交互的基本单位,InnoDB 中页的大小一般为 16 KB。也就是在一般情况下,一次最少从磁盘中读取 16KB 的内容到内存中,一次最少把内存中的 16KB 内容刷新到磁盘中。
我们平时是以记录为单位来向表中插入数据的,这些记录在磁盘上的存放方式也被称为行格式或者记录格式。InnoDB 存储引擎设计了 4 种不同类型的行格式,分别是 Compact、Redundant、Dynamic 和 Compressed 行格式。
6.1.1. 行格式
我们可以在创建或修改表的语句中指定行格式:
CREATE TABLE 表名 (列的信息) ROW_FORMAT=行格式名称
6.1.1.1. COMPACT

我们知道 MySQL 支持一些变长的数据类型,比如 VARCHAR(M)、
VARBINARY(M)、各种 TEXT 类型,各种 BLOB 类型,我们也可以把拥有这些数据类型的列称为变长字段,变长字段中存储多少字节的数据是不固定的,所以我们在存储真实数据的时候需要顺便把这些数据占用的字节数也存起来。如果该可变字段允许存储的最大字节数(M×W)超过 255 字节并且真实存储的字节数(L)超过 127 字节,则使用 2 个字节,否则使用 1 个字节。
表中的某些列可能存储 NULL 值,如果把这些 NULL 值都放到记录的真实数据中存储会很占地方,所以 Compact 行格式把这些值为 NULL 的列统一管理起来,存储到 NULL 值列表。每个允许存储 NULL 的列对应一个二进制位,二进制位的值为 1 时,代表该列的值为 NULL。二进制位的值为 0 时,代表该列的值不为 NULL。
还有一个用于描述记录的记录头信息,它是由固定的 5 个字节组成。5 个字节也就是 40 个二进制位,不同的位代表不同的意思。
预留位 1 1 没有使用
预留位 2 1 没有使用
- delete_mask 1 标记该记录是否被删除
- min_rec_mask 1 B+树的每层非叶子节点中的最小记录都会添加该标记
- n_owned 4 表示当前记录拥有的记录数
- heap_no 13 表示当前记录在页的位置信息
- record_type3 表示当前记录的类型,0 表示普通记录,1 表示 B+树非叶子节点记录,2 表示最小记录,3 表示最大记录
- next_record16 表示下一条记录的相对位置
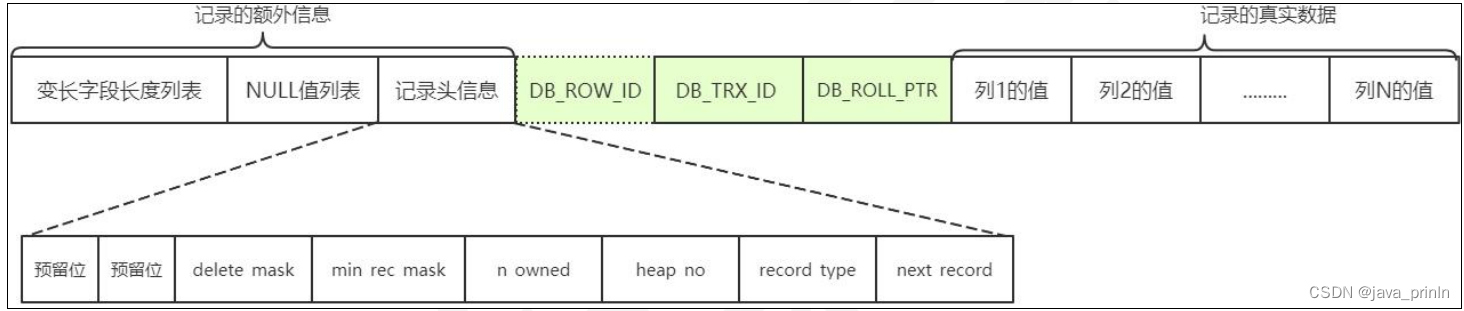
记录的真实数据除了我们自己定义的列的数据以外,MySQL 会为每个记录默认的添加一些列(也称为隐藏列),包括:
DB_ROW_ID(row_id):非必须,6 字节,表示行 ID,唯一标识一条记录
DB_TRX_ID:必须,6 字节,表示事务 ID
DB_ROLL_PTR:必须,7 字节,表示回滚指针
InnoDB 表对主键的生成策略是:优先使用用户自定义主键作为主键,如果用户没有定义主键,则选取一个 Unique 键作为主键,如果表中连 Unique 键都没有定义的话,则 InnoDB 会为表默认添加一个名为 row_id 的隐藏列作为主键。
DB_TRX_ID(也可以称为 trx_id) 和 DB_ROLL_PTR(也可以称为 roll_ptr) 这两个列是必有的,但是 row_id 是可选的(在没有自定义主键以及 Unique 键的情况下才会添加该列)。
其他的行格式和 Compact 行格式差别不大。
6.1.1.2. Redundant 行格式
Redundant 行格式是 MySQL5.0 之前用的一种行格式,不予深究。
6.1.1.3. Dynamic 和 Compressed 行格式
MySQL5.7 的默认行格式就是 Dynamic,Dynamic 和 Compressed 行格式和Compact 行格式挺像,只不过在处理行溢出数据时有所不同。Compressed 行格式和 Dynamic 不同的一点是,Compressed 行格式会采用压缩算法对页面进行压缩,以节省空间。
6.1.1.4. 数据溢出
如果我们定义一个表,表中只有一个 VARCHAR 字段,如下:
CREATE TABLE test_varchar( c VARCHAR(60000) )
然后往这个字段插入 60000 个字符,会发生什么?
前边说过,MySQL 中磁盘和内存交互的基本单位是页,也就是说 MySQL 是以页为基本单位来管理存储空间的,我们的记录都会被分配到某个页中存储。而一个页的大小一般是 16KB,也就是 16384 字节,而一个 VARCHAR(M)类型的列就最多可以存储 65532 个字节,这样就可能造成一个页存放不了一条记录的情况。
在 Compact 和 Redundant 行格式中,对于占用存储空间非常大的列,在记录的真实数据处只会存储该列的该列的前 768 个字节的数据,然后把剩余的数据分散存储在几个其他的页中,记录的真实数据处用 20 个字节存储指向这些页的地址。这个过程也叫做行溢出,存储超出 768 字节的那些页面也被称为溢出页。
Dynamic 和 Compressed 行格式,不会在记录的真实数据处存储字段真实数据的前 768 个字节,而是把所有的字节都存储到其他页面中,只在记录的真实数据处存储其他页面的地址。
那发生行溢出的临界点是什么呢?也就是说在列存储多少字节的数据时就
会发生行溢出?
MySQL 中规定一个页中至少存放两行记录,以上边的 test_varchar 表为例,它只有一个列 c,我们往这个表中插入两条记录,每条记录最少插入多少字节的=数据才会行溢出的现象呢?这得分析一下页中的空间都是如何利用的。
每个页除了存放我们的记录以外,也需要存储一些页本身的信息,加起来需要 132 个字节的空间,其他的空间都可以被用来存储记录。每个记录需要的额外信息是 27 字节。
假设一个列中存储的数据字节数为 n,MySQL 规定如果该列不发生溢出的现
象,就需要满足下边这个式子:
132 + 2×(27 + n) < 16384
求解这个式子得出的解是:n < 8099。也就是说如果一个列中存储的数据小于 8099 个字节,那么该列就不会成为溢出列,否则该列就需要成为溢出列。不过这个 8099 个字节的结论只是针对只有一个列的 test_varchar 表来说的,如果表中有多个列,那上边的式子和结论都需要改。所以重点就是:这个临界点具体值无关紧要,只要知道如果我们一条记录的某个列中存储的数据占用的字节数非常多时,该列就可能成为溢出列。
6.1.2. 索引页格式
前边我们简单提了一下页的概念,它是 InnoDB 管理存储空间的基本单位,一个页的大小一般是 16KB。
InnoDB 为了不同的目的而设计了许多种不同类型的页,存放我们表中记录的那种类型的页自然也是其中的一员,官方称这种存放记录的页为索引(INDEX)页,不过要理解成数据页也没问题,毕竟存在着聚簇索引这种索引和数据混合的东西。
6.1.2.1. 数据页结构
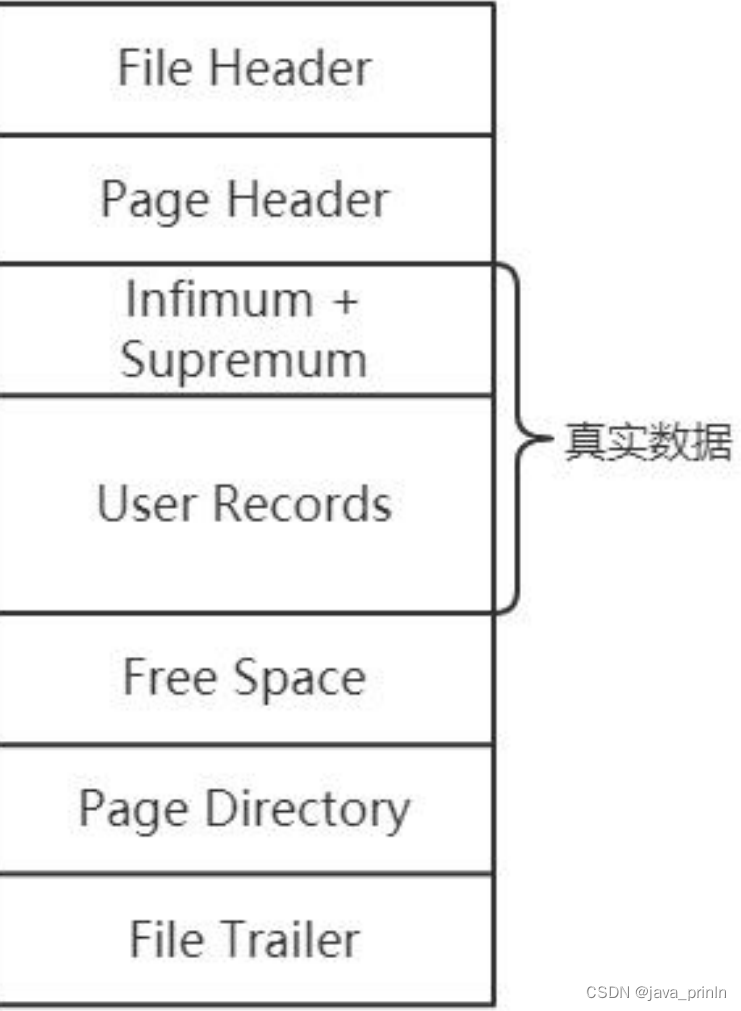
一个 InnoDB 数据页的存储空间大致被划分成了 7 个部分:
- File Header 文件头部 38 字节 页的一些通用信息
- Page Header 页面头部 56 字节 数据页专有的一些信息
- Infimum + Supremum 最小记录和最大记录 26 字节 两个虚拟的行记录
- User Records 用户记录 大小不确定 实际存储的行记录内容
- Free Space 空闲空间 大小不确定 页中尚未使用的空间
- Page Directory 页面目录 大小不确定 页中的某些记录的相对位置
- File Trailer 文件尾部 8 字节 校验页是否完整
User Records
我们自己存储的记录会按照我们指定的行格式存储到 User Records 部分。但是在一开始生成页的时候,其实并没有 User Records 这个部分,每当我们插入一条记录,都会从 Free Space 部分,也就是尚未使用的存储空间中申请一个记录大小的空间划分到 User Records 部分,当 Free Space 部分的空间全部被 User Records部分替代掉之后,也就意味着这个页使用完了,如果还有新的记录插入的话,就需要去申请新的页了。
当前记录被删除时,则会修改记录头信息中的 delete_mask 为 1,也就是说被删除的记录还在页中,还在真实的磁盘上。这些被删除的记录之所以不立即从磁盘上移除,是因为移除它们之后把其他的记录在磁盘上重新排列需要性能消耗。
所以只是打一个删除标记而已,所有被删除掉的记录都会组成一个所谓的垃圾链表,在这个链表中的记录占用的空间称之为所谓的可重用空间,之后如果有新记录插入到表中的话,可能把这些被删除的记录占用的存储空间覆盖掉。
同时我们插入的记录在会记录自己在本页中的位置,写入了记录头信息中heap_no 部分。heap_no 值为 0 和 1 的记录是 InnoDB 自动给每个页增加的两个记录,称为伪记录或者虚拟记录。这两个伪记录一个代表最小记录,一个代表最大记录,这两条存放在页的 User Records 部分,他们被单独放在一个称为 Infimum + Supremum 的部分。
记录头信息中 next_record 记录了从当前记录的真实数据到下一条记录的真实数据的地址偏移量。这其实是个链表,可以通过一条记录找到它的下一条记录。
但是需要注意注意再注意的一点是,下一条记录指得并不是按照我们插入顺序的下一条记录,而是按照主键值由小到大的顺序的下一条记录。而且规定 Infimum记录(也就是最小记录) 的下一条记录就是本页中主键值最小的用户记录,而本页中主键值最大的用户记录的下一条记录就是 Supremum 记录(也就是最大记录)。
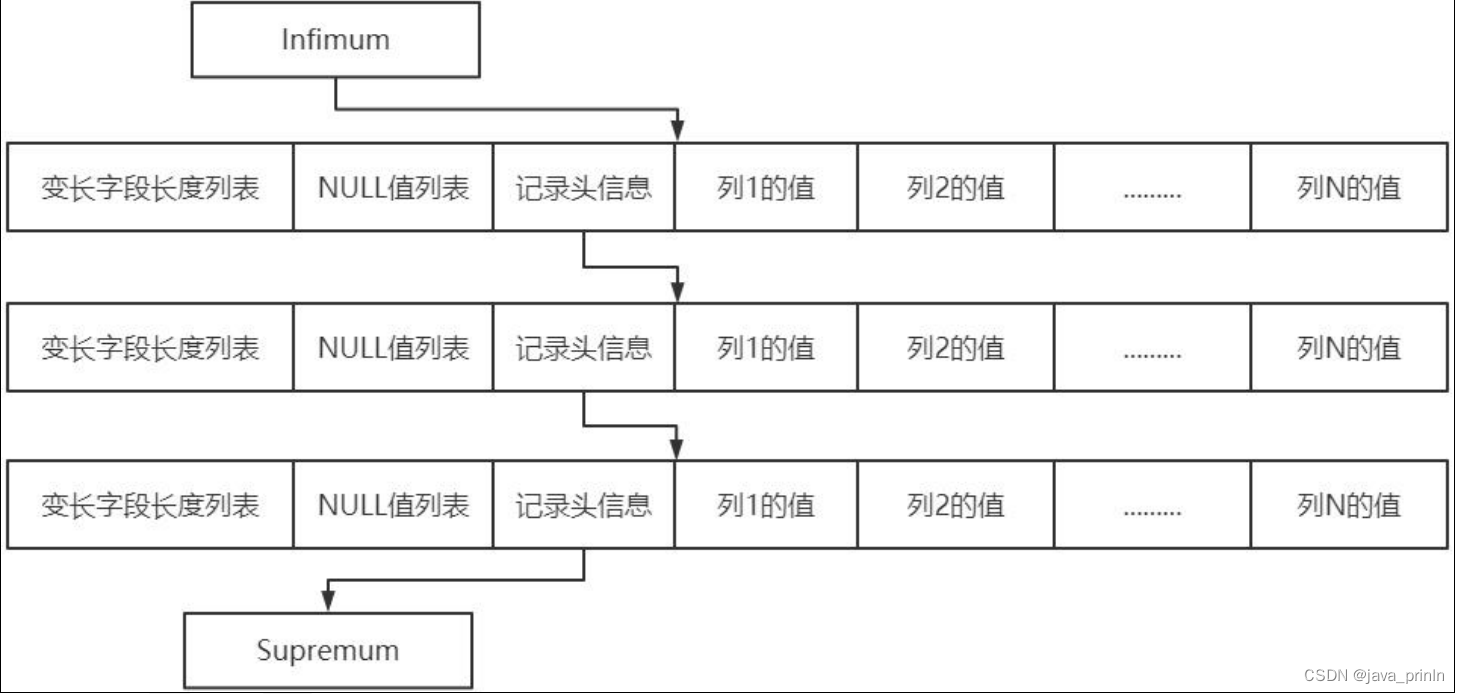
我们的记录按照主键从小到大的顺序形成了一个单链表,记录被删除,则从这个链表上摘除。
Page Directory
Page Directory 主要是解决记录链表的查找问题。如果我们想根据主键值查找页中的某条记录该咋办?按链表查找的办法:从 Infimum 记录(最小记录)开始,沿着链表一直往后找,总会找到或者找不到。
InnoDB 的改进是,为页中的记录再制作了一个目录,他们的制作过程是这样的:
1、将所有正常的记录(包括最大和最小记录,不包括标记为已删除的记录)划分为几个组。
2、每个组的最后一条记录(也就是组内最大的那条记录)的头信息中的n_owned 属性表示该记录拥有多少条记录,也就是该组内共有几条记录。
3、将每个组的最后一条记录的地址偏移量单独提取出来按顺序存储到靠近页的尾部的地方,这个地方就是所谓的 Page Directory,也就是页目录页面目录中的这些地址偏移量被称为槽(英文名:Slot),所以这个页面目录就是由槽组成的。
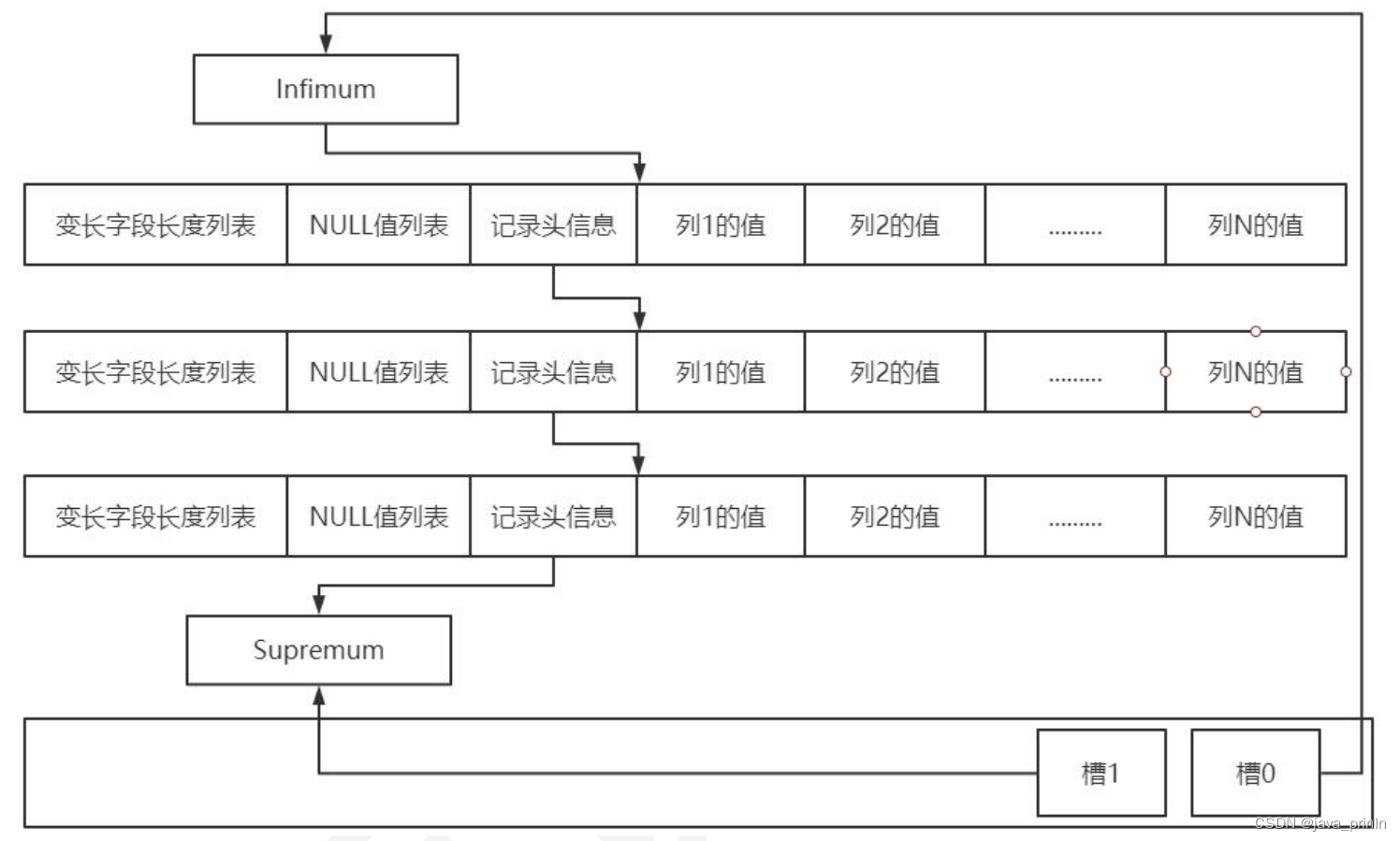
4、每个分组中的记录条数是有规定的:对于最小记录所在的分组只能有 1条记录,最大记录所在的分组拥有的记录条数只能在 1~8 条之间,剩下的分组中记录的条数范围只能在是 4~8 条之间。如下图:

这样,一个数据页中查找指定主键值的记录的过程分为两步:
通过二分法确定该记录所在的槽,并找到该槽所在分组中主键值最小的那条记录。
通过记录的 next_record 属性遍历该槽所在的组中的各个记录。
Page Header
InnoDB 为了能得到一个数据页中存储的记录的状态信息,比如本页中已经存储了多少条记录,第一条记录的地址是什么,页目录中存储了多少个槽等等,
特意在页中定义了一个叫 Page Header 的部分,它是页结构的第二部分,这个部分占用固定的 56 个字节,专门存储各种状态信息。
File Header
File Header 针对各种类型的页都通用,也就是说不同类型的页都会以 File Header 作为第一个组成部分,它描述了一些针对各种页都通用的一些信息,比方说页的类型,这个页的编号是多少,它的上一个页、下一个页是谁,页的校验和等等,这个部分占用固定的 38 个字节。
页的类型,包括 Undo 日志页、段信息节点、Insert Buffer 空闲列表、Insert Buffer 位图、系统页、事务系统数据、表空间头部信息、扩展描述页、溢出页、 索引页,有些页会在后面的课程看到。
同时通过上一个页、下一个页建立一个双向链表把许许多多的页就串联起来,而无需这些页在物理上真正连着。但是并不是所有类型的页都有上一个和下一个页的属性,数据页是有这两个属性的,所以所有的数据页其实是一个双向链表。
File Trailer
我们知道 InnoDB 存储引擎会把数据存储到磁盘上,但是磁盘速度太慢,需要以页为单位把数据加载到内存中处理,如果该页中的数据在内存中被修改了,
那么在修改后的某个时间需要把数据同步到磁盘中。但是在同步了一半的时候中断电了咋办?
为了检测一个页是否完整(也就是在同步的时候有没有发生只同步一半的尴尬情况),InnoDB 每个页的尾部都加了一个 File Trailer 部分,这个部分由 8 个字节组成,可以分成 2 个小部分:
前 4 个字节代表页的校验和
这个部分是和 File Header 中的校验和相对应的。每当一个页面在内存中修改了,在同步之前就要把它的校验和算出来,因为 File Header 在页面的前边,
所以校验和会被首先同步到磁盘,当完全写完时,校验和也会被写到页的尾部,如果完全同步成功,则页的首部和尾部的校验和应该是一致的。如果写了一半儿断电了,那么在 File Header 中的校验和就代表着已经修改过的页,而在 File Trailer 中的校验和代表着原先的页,二者不同则意味着同步中间出了错。
后 4 个字节代表页面被最后修改时对应的日志序列位置(LSN),这个也和校验页的完整性有关。
这个 File Trailer 与 File Header 类似,都是所有类型的页通用的
相关文章:
MySQL InnoDB 引擎底层解析(一)
6. InnoDB 引擎底层解析 MySQL 对于我们来说还是一个黑盒,我们只负责使用客户端发送请求并等待服务器返回结果,表中的数据到底存到了哪里?以什么格式存放的?MySQL 是以什么方式来访问的这些数据?这些问题我们统统不知…...
redis安装(Windows和linux)
如何实现Redis安装与使用的详细教程 Redis 简介 Redis是一个使用C语言编写的开源、高性能、非关系型的键值对存储数据库。它支持多种数据结构,包括字符串、列表、集合、有序集合、哈希表等。Redis的内存操作能力极强,其读写性能非常优秀,且…...
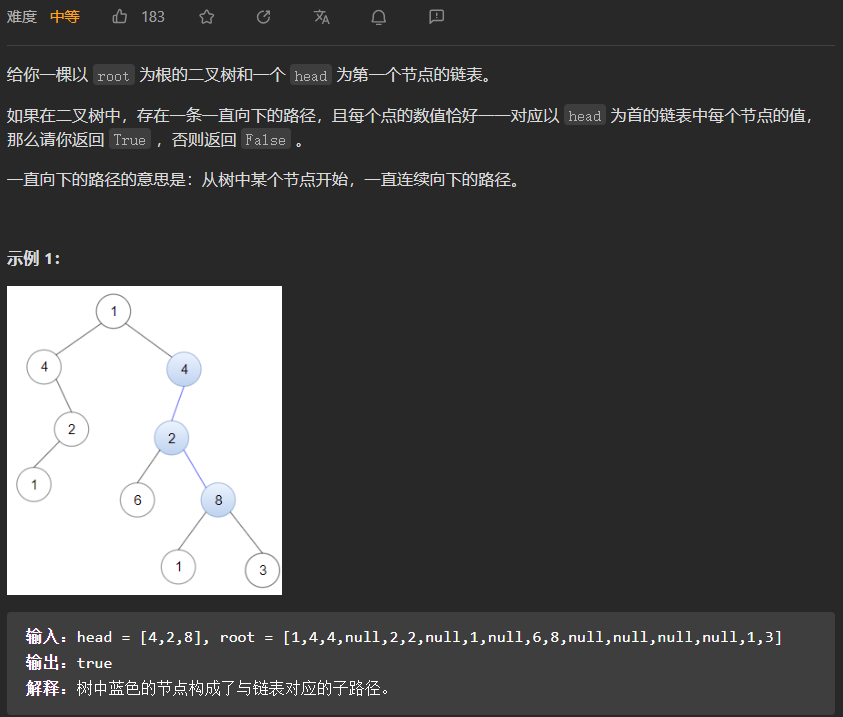
【LeetCode刷题-树】--1367.二叉树中的链表
1367.二叉树中的链表 方法:枚举 枚举二叉树中的每个节点为起点往下的路径是否与链表相匹配的路径,为了判断是否匹配设计了一个递归函数dfs(root,head),其中root表示当前匹配到的二叉树节点,head表示当前匹配到的链表节点,整个函数…...

【嵌入式 – GD32开发实战指南(ARM版本)】第2部分 外设篇 - 第3章 温度传感器DS18B20
1 理论分析 1.1 DS18B20概述 DS18B20 是 DALLAS 最新单线数字温度传感器,新的"一线器件"体积更小、适用电压更宽、更经济。Dallas 半导体公司的数字化温度传感器 DS1820 是世界上第一片支持 "一线总线"接口的温度传感器。 DS18B20采用的单总线协议,也…...

基于spring gateway 的静态资源缓存实现
由于子项目比较多,子项目都是通过嵌套的方式实现的。就会导致子页面加载比较慢,影响客户体验 实现思路(AI搜的--!): 1、通过spring boot缓存实现静态资源缓存 2、在gateway过滤器,对静态资源进行缓存 直接上代码&a…...

SDUT OJ《算法分析与设计》搜索算法
A - 子集和问题 Description 子集和问题的一个实例为〈S,t〉。其中,S{ x1 , x2 ,…,xn }是一个正整数的集合,c是一个正整数。子集和问题判定是否存在S的一个子集S1,使得: 。 试设计一个解子…...
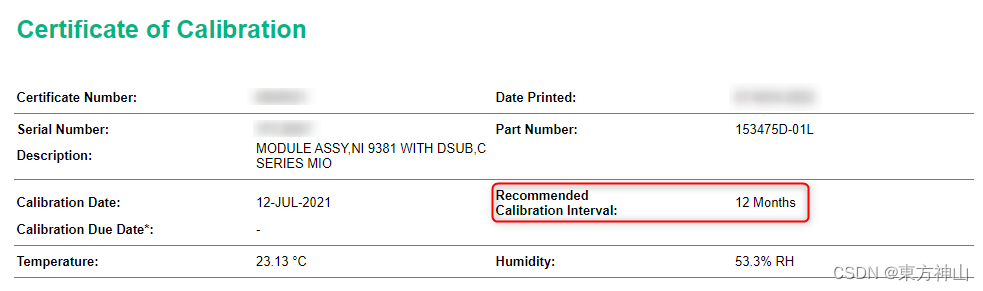
【NI-DAQmx入门】校准
1.设备定期校准的理由 随着时间的推移电子器件的特性会发生自然漂移,可能会导致测量结果的不准确性。防止出现良品和差品筛选出错的情况满足行业国际标准降低设备出现故障的风险使测量结果更具备参考性 2.查找NI设备的校准间隔。 定期校准会使DAQ设备的精度保持在…...

C语言链表
head.h typedef struct Node_s{int data; //数据域struct Node_s *pNext; //指针域 } Node_t, *pNode_t;void headInsert(pNode_t *ppHead, pNode_t *ppTail, int data); void print(pNode_t pHead); void tailInsert(pNode_t *ppHead, pNode_t *ppTail, int data); void sort…...
LabVIEW进行MQTT通信及数据解析
需求:一般通过串口的方式进行数据的解析,但有时候硬件的限制,没法预留串口,那么如何通过网络的方式特别是MQTT数据的通信及解析 解决方式: 1.MQTT通信控件: 参考开源的mqtt-LabVIEW https://github.com…...

基于DOTween插件实现金币飞行到指定位置功能
文章目录 前言一、DOTween是什么?二、使用步骤1.导入DOTween插件在Unity官方插件商店找到DOTween插件导入DOTween插件启用DOTween插件 2.代码逻辑金币飞行代码控制飞行效果代码 3.物体配置1.物体上装配CoinEffect脚本2.在金币预制体上装配FlyControl脚本 三、效果展…...

python-opencv 培训课程作业
python-opencv 培训课程作业 作业一: 第一步:读取 res 下面的 flower.jpg,读取彩图,并用 opencv 展示 第二步:彩图 -> 灰度图 第三步:反转图像:最大图像灰度值减去原图像,即可得…...

【Go入门】并发
【Go入门】并发 有人把Go比作21世纪的C语言,第一是因为Go语言设计简单,第二,21世纪最重要的就是并行程序设计,而Go从语言层面就支持了并行。 goroutine goroutine是Go并行设计的核心。goroutine说到底其实就是协程,…...
Java虚拟机运行时数据区结构详解
Java虚拟机运行时数据区结构如图所示 程序计数器 程序计数器(Program Counter Register)是一块较小的内存空间,它可以看作是当前线程所执行的字节码的行号指示器。 多线程切换时,为了能恢复到正确的执行位置,每条线程…...
)
华为OD机试 - 转盘寿司(Java JS Python C)
目录 题目描述 输入描述 输出描述 用例 题目解析 JS算法源码 Java算法源码...

【ATTCK】MITRE Caldera-emu插件
CALDERA是一个由python语言编写的红蓝对抗工具(攻击模拟工具)。它是MITRE公司发起的一个研究项目,该工具的攻击流程是建立在ATT&CK攻击行为模型和知识库之上的,能够较真实地APT攻击行为模式。 通过CALDERA工具,安全…...
23111709[含文档+PPT+源码等]计算机毕业设计基于Spring Boot智能无人仓库管理-进销存储
文章目录 **软件开发环境及开发工具:****功能介绍:****论文截图:****数据库:****实现:****代码片段:** 编程技术交流、源码分享、模板分享、网课教程 🐧裙:776871563 软件开发环境及…...

SDUT OJ《算法分析与设计》贪心算法
A - 汽车加油问题 Description 一辆汽车加满油后可行驶n公里。旅途中有若干个加油站。设计一个有效算法,指出应在哪些加油站停靠加油,使沿途加油次数最少。并证明算法能产生一个最优解。 对于给定的n和k个加油站位置,计算最少加油次数。 I…...
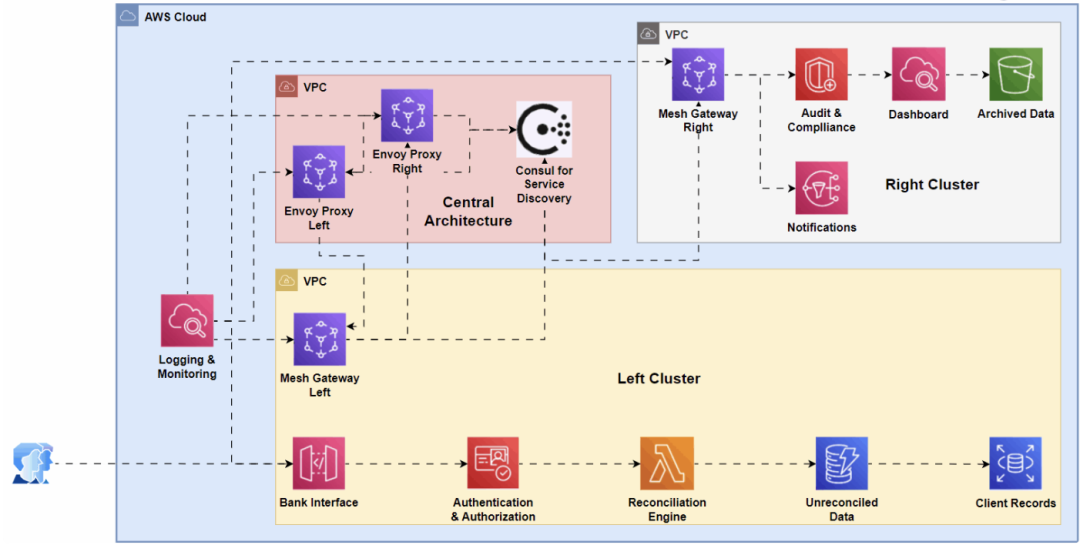
金融业务系统: Service Mesh用于安全微服务集成
随着云计算的不断演进,微服务架构变得日益复杂。为了有效地管理这种复杂性,人们开始采用服务网格。在本文中,我们将解释什么是Service Mesh,为什么它对现代云架构至关重要,以及它是如何解决开发人员今天面临的一些最紧…...

Linux下快速确定目标服务器支持哪些协议和密码套件
实现原理是利用TLS协议的特点和握手过程来进行测试和解析响应来确定目标服务器支持哪些TLS协议和密码套件。 在TLS握手过程中,客户端和服务器会协商并使用相同的TLS协议版本和密码套件来进行通信。通过发送特定的握手请求并分析响应,可以确定目标服务器…...

LeetCode100122. Separate Black and White Balls
文章目录 一、题目二、题解 一、题目 There are n balls on a table, each ball has a color black or white. You are given a 0-indexed binary string s of length n, where 1 and 0 represent black and white balls, respectively. In each step, you can choose two a…...

Wand-Enhancer终极指南:免费解锁WeMod专业版的完整教程
Wand-Enhancer终极指南:免费解锁WeMod专业版的完整教程 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 还在为WeMod专业版的高昂订阅费用而烦…...

哔哩漫游X:全面解锁B站功能的终极ReVanced增强模块
哔哩漫游X:全面解锁B站功能的终极ReVanced增强模块 【免费下载链接】BiliRoamingX-integrations BiliRoamingX integrations and patches powered by ReVanced. 项目地址: https://gitcode.com/gh_mirrors/bi/BiliRoamingX-integrations B站作为中国最大的视…...

Python学习第43天:索引——关系型数据库查询性能的核心秘密
文章目录 一、前言 二、B+ 树索引 2.1 B+ 树的结构 2.2 聚集索引与非聚集索引 三、索引实战演示 3.1 没有索引的情况 3.2 执行计划关键字段解读 3.3 创建索引后的效果 3.4 前缀索引 四、删除索引 4.1 使用 ALTER TABLE 删除索引 4.2 使用 DROP INDEX 删除索引 五、高级索引技巧…...

Windows用户必看!终极免费的PDF处理工具Poppler快速安装指南
Windows用户必看!终极免费的PDF处理工具Poppler快速安装指南 【免费下载链接】poppler-windows Download Poppler binaries packaged for Windows with dependencies 项目地址: https://gitcode.com/gh_mirrors/po/poppler-windows 还在为Windows系统上处理P…...

ComfyUI-Manager深度解析:AI工作流扩展管理系统的架构设计与性能优化
ComfyUI-Manager深度解析:AI工作流扩展管理系统的架构设计与性能优化 【免费下载链接】ComfyUI-Manager ComfyUI-Manager is an extension designed to enhance the usability of ComfyUI. It offers management functions to install, remove, disable, and enable…...

数据科学揭秘椭圆曲线秩分布:BSD参数空间的拓扑结构探索
1. 项目概述:当数论遇到数据科学如果你研究过椭圆曲线,尤其是涉足过同余数问题,那你一定对Mordell-Weil秩和BSD猜想这些概念不陌生。这些名词听起来高深,本质上是在追问一个古老而迷人的问题:一条椭圆曲线上有多少个有…...
)
手把手教你用CentOS 7搭建Fog Project网络克隆服务器(含DHCP/TFTP配置避坑指南)
CentOS 7实战:企业级Fog Project网络克隆系统部署全攻略当企业IT部门需要同时为数十台甚至上百台计算机部署操作系统时,传统的光盘或U盘安装方式显然效率低下。这正是Fog Project大显身手的场景——一个开源的网络克隆与系统部署解决方案。本文将带您从零…...

AutoCut视频剪辑神器:用文本编辑快速剪切视频的完整指南
AutoCut视频剪辑神器:用文本编辑快速剪切视频的完整指南 【免费下载链接】autocut 用文本编辑器剪视频 项目地址: https://gitcode.com/GitHub_Trending/au/autocut 还在为繁琐的视频剪辑过程烦恼吗?想要像编辑Word文档一样轻松剪切视频吗&#x…...

面向实时决策Agent的Harness微秒级调度
面向实时决策Agent的Harness微秒级调度:从原理到落地,打造低于10us延迟的智能决策系统 副标题:适配量化交易、自动驾驶、工业控制等高实时性场景,确定性延迟保障99.999%调度成功率 摘要/引言 你有没有遇到过这些场景:量化交易策略的决策逻辑晚了5us,原本可以盈利的订单…...

新手教程使用curl命令快速测试Taotoken的OpenAI兼容接口
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 新手教程:使用curl命令快速测试Taotoken的OpenAI兼容接口 基础教程类,面向刚注册Taotoken的开发者…...