Flume学习笔记(3)—— Flume 自定义组件
前置知识:
Flume学习笔记(1)—— Flume入门-CSDN博客
Flume学习笔记(2)—— Flume进阶-CSDN博客
Flume 自定义组件
自定义 Interceptor
需求分析:使用 Flume 采集服务器本地日志,需要按照日志类型的不同,将不同种类的日志发往不同的分析系统
需要使用Flume 拓扑结构中的 Multiplexing 结构,Multiplexing的原理是,根据 event 中 Header 的某个 key 的值,将不同的 event 发送到不同的 Channel中,所以我们需要自定义一个 Interceptor,为不同类型的 event 的 Header 中的 key 赋予不同的值
实现流程:
代码
导入依赖:
<dependencies><dependency><groupId>org.apache.flume</groupId><artifactId>flume-ng-core</artifactId><version>1.9.0</version></dependency>
</dependencies>自定义拦截器的代码:
package com.why.interceptor;import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;import java.util.ArrayList;
import java.util.List;
import java.util.Map;public class TypeInterceptor implements Interceptor {//存放事件的集合private List<Event> addHeaderEvents;@Overridepublic void initialize() {//初始化集合addHeaderEvents = new ArrayList<>();}//单个事件拦截@Overridepublic Event intercept(Event event) {//获取头信息Map<String, String> headers = event.getHeaders();//获取body信息String body = new String(event.getBody());//根据数据中是否包含”why“来分组if(body.contains("why")){headers.put("type","first");}else {headers.put("type","second");}return event;}//批量事件拦截@Overridepublic List<Event> intercept(List<Event> events) {//清空集合addHeaderEvents.clear();//遍历eventsfor(Event event : events){//给每一个事件添加头信息addHeaderEvents.add(intercept(event));}return addHeaderEvents;}@Overridepublic void close() {}//构建生成器public static class TypeBuilder implements Interceptor.Builder{@Overridepublic Interceptor build() {return new TypeInterceptor();}@Overridepublic void configure(Context context) {}}}将代码打包放入flume安装路径下的lib文件夹中
配置文件
在job文件夹下创建group4目录,添加配置文件;
为 hadoop102 上的 Flume1 配置 1 个 netcat source,1 个 sink group(2 个 avro sink),并配置相应的 ChannelSelector 和 interceptor
# Name the components on this agent
a1.sources = r1
a1.sinks = k1 k2
a1.channels = c1 c2# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.why.interceptor.TypeInterceptor$TypeBuilder
a1.sources.r1.selector.type = multiplexing
a1.sources.r1.selector.header = type
a1.sources.r1.selector.mapping.first = c1
a1.sources.r1.selector.mapping.second = c2# Describe the sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = hadoop103
a1.sinks.k1.port = 4141
a1.sinks.k2.type=avro
a1.sinks.k2.hostname = hadoop104
a1.sinks.k2.port = 4242# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Use a channel which buffers events in memory
a1.channels.c2.type = memory
a1.channels.c2.capacity = 1000
a1.channels.c2.transactionCapacity = 100# Bind the source and sink to the channel
a1.sources.r1.channels = c1 c2
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c2hadoop103:配置一个 avro source 和一个 logger sink
a1.sources = r1
a1.sinks = k1
a1.channels = c1
a1.sources.r1.type = avro
a1.sources.r1.bind = hadoop103
a1.sources.r1.port = 4141
a1.sinks.k1.type = logger
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.sinks.k1.channel = c1
a1.sources.r1.channels = c1hadoop104:配置一个 avro source 和一个 logger sink
a1.sources = r1
a1.sinks = k1
a1.channels = c1
a1.sources.r1.type = avro
a1.sources.r1.bind = hadoop104
a1.sources.r1.port = 4242
a1.sinks.k1.type = logger
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.sinks.k1.channel = c1
a1.sources.r1.channels = c1执行指令
hadoop102:bin/flume-ng agent --conf conf/ --name a1 --conf-file job/group4/flume-interceptor-flume.conf
hadoop103:bin/flume-ng agent --conf conf/ --name a1 --conf-file job/group4/flume1-flume-logger.conf -Dflume.root.logger=INFO,console
hadoop104:bin/flume-ng agent --conf conf/ --name a1 --conf-file job/group4/flume2-flume-logger.conf -Dflume.root.logger=INFO,console
然后hadoop102通过nc连接44444端口,发送数据:
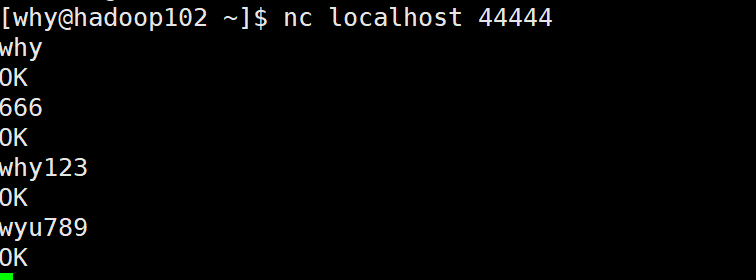
在hadoop103和104上分别接收到:


自定义 Source
官方提供的文档:Flume 1.11.0 Developer Guide — Apache Flume
给出的示例代码如下:
public class MySource extends AbstractSource implements Configurable, PollableSource {private String myProp;@Overridepublic void configure(Context context) {String myProp = context.getString("myProp", "defaultValue");// Process the myProp value (e.g. validation, convert to another type, ...)// Store myProp for later retrieval by process() methodthis.myProp = myProp;}@Overridepublic void start() {// Initialize the connection to the external client}@Overridepublic void stop () {// Disconnect from external client and do any additional cleanup// (e.g. releasing resources or nulling-out field values) ..}@Overridepublic Status process() throws EventDeliveryException {Status status = null;try {// This try clause includes whatever Channel/Event operations you want to do// Receive new dataEvent e = getSomeData();// Store the Event into this Source's associated Channel(s)getChannelProcessor().processEvent(e);status = Status.READY;} catch (Throwable t) {// Log exception, handle individual exceptions as neededstatus = Status.BACKOFF;// re-throw all Errorsif (t instanceof Error) {throw (Error)t;}} finally {txn.close();}return status;}
}需要继承AbstractSource,实现Configurable, PollableSource
实战需求分析
使用 flume 接收数据,并给每条数据添加前缀,输出到控制台。前缀可从 flume 配置文件中配置
代码
package com.why.source;import org.apache.flume.Context;
import org.apache.flume.EventDeliveryException;
import org.apache.flume.PollableSource;
import org.apache.flume.conf.Configurable;
import org.apache.flume.event.SimpleEvent;
import org.apache.flume.source.AbstractSource;import java.util.HashMap;
import java.util.concurrent.ConcurrentMap;public class MySource extends AbstractSource implements PollableSource, Configurable {//定义配置文件将来要读取的字段private Long delay;private String field;//获取数据封装成 event 并写入 channel,这个方法将被循环调用@Overridepublic Status process() throws EventDeliveryException {try {//事件头信息HashMap<String,String> headerMap = new HashMap<>();//创建事件SimpleEvent event = new SimpleEvent();//循环封装事件for (int i = 0; i < 5; i++) {//设置头信息event.setHeaders(headerMap);//设置事件内容event.setBody((field + i).getBytes());//将事件写入ChannelgetChannelProcessor().processEvent(event);Thread.sleep(delay);}}catch (InterruptedException e) {throw new RuntimeException(e);}return Status.READY;}//backoff 步长@Overridepublic long getBackOffSleepIncrement() {return 0;}//backoff 最长时间@Overridepublic long getMaxBackOffSleepInterval() {return 0;}//初始化 context(读取配置文件内容)@Overridepublic void configure(Context context) {delay = context.getLong("delay");field = context.getString("field","Hello");}}
打包放到flume安装路径下的lib文件夹中;
配置文件
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1# Describe/configure the source
a1.sources.r1.type = com.why.source.MySource
a1.sources.r1.delay = 1000
a1.sources.r1.field = why# Describe the sink
a1.sinks.k1.type = logger# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1执行指令
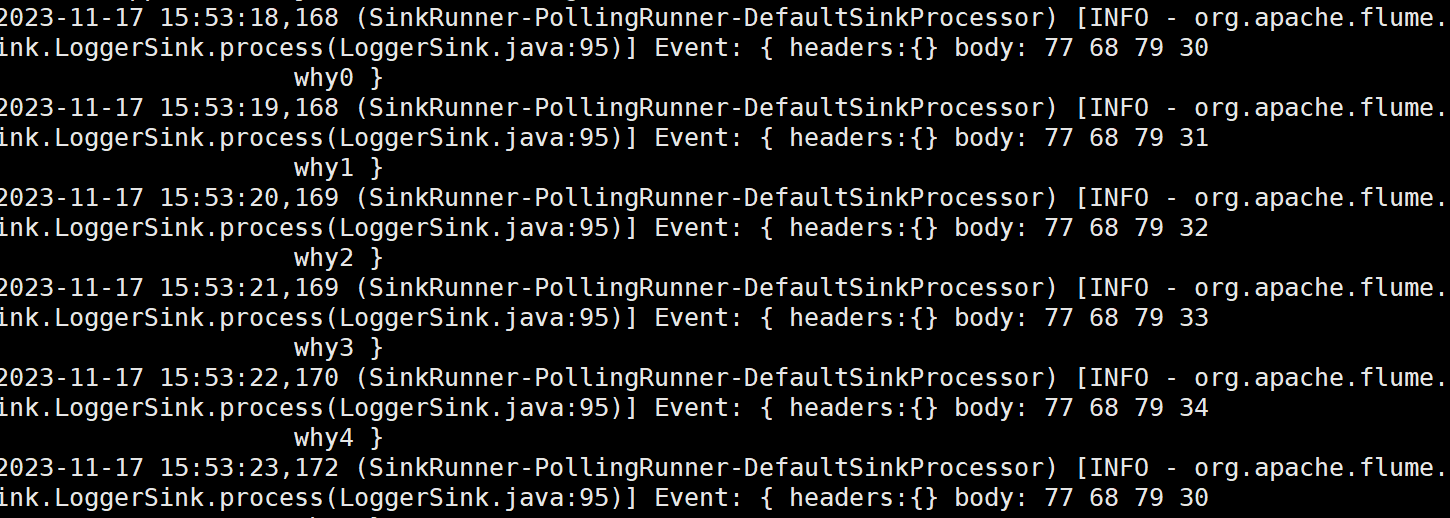
hadoop102上:bin/flume-ng agent --conf conf/ --name a1 --conf-file job/group5/mysource.conf -Dflume.root.logger=INFO,console
结果如下:
自定义 Sink
Sink 不断地轮询 Channel 中的事件且批量地移除它们,并将这些事件批量写入到存储或索引系统、或者被发送到另一个 Flume Agent。
Sink 是完全事务性的。在从 Channel 批量删除数据之前,每个 Sink 用 Channel 启动一个事务。批量事件一旦成功写出到存储系统或下一个 Flume Agent,Sink 就利用 Channel 提交事务。事务一旦被提交,该 Channel 从自己的内部缓冲区删除事件
官方文档:Flume 1.11.0 Developer Guide — Apache Flume
接口实例:
public class MySink extends AbstractSink implements Configurable {private String myProp;@Overridepublic void configure(Context context) {String myProp = context.getString("myProp", "defaultValue");// Process the myProp value (e.g. validation)// Store myProp for later retrieval by process() methodthis.myProp = myProp;}@Overridepublic void start() {// Initialize the connection to the external repository (e.g. HDFS) that// this Sink will forward Events to ..}@Overridepublic void stop () {// Disconnect from the external respository and do any// additional cleanup (e.g. releasing resources or nulling-out// field values) ..}@Overridepublic Status process() throws EventDeliveryException {Status status = null;// Start transactionChannel ch = getChannel();Transaction txn = ch.getTransaction();txn.begin();try {// This try clause includes whatever Channel operations you want to doEvent event = ch.take();// Send the Event to the external repository.// storeSomeData(e);txn.commit();status = Status.READY;} catch (Throwable t) {txn.rollback();// Log exception, handle individual exceptions as neededstatus = Status.BACKOFF;// re-throw all Errorsif (t instanceof Error) {throw (Error)t;}}return status;}
}自定义MySink 需要继承 AbstractSink 类并实现 Configurable 接口
实战需求分析
使用 flume 接收数据,并在 Sink 端给每条数据添加前缀和后缀,输出到控制台。前后缀可在 flume 任务配置文件中配置
代码
package com.why.sink;import org.apache.flume.*;
import org.apache.flume.conf.Configurable;
import org.apache.flume.sink.AbstractSink;import org.slf4j.Logger;
import org.slf4j.LoggerFactory;public class MySink extends AbstractSink implements Configurable {//创建 Logger 对象private static final Logger LOG = LoggerFactory.getLogger(AbstractSink.class);//前后缀private String prefix;private String suffix;@Overridepublic Status process() throws EventDeliveryException {//声明返回值状态信息Status status;//获取当前 Sink 绑定的 ChannelChannel ch = getChannel();//获取事务Transaction txn = ch.getTransaction();//声明事件Event event;//开启事务txn.begin();//读取 Channel 中的事件,直到读取到事件结束循环while (true) {event = ch.take();if (event != null) {break;}}try {//处理事件(打印)LOG.info(prefix + new String(event.getBody()) + suffix);//事务提交txn.commit();status = Status.READY;} catch (Exception e) {//遇到异常,事务回滚txn.rollback();status = Status.BACKOFF;} finally {//关闭事务txn.close();}return status;}@Overridepublic void configure(Context context) {prefix = context.getString("prefix", "hello");suffix = context.getString("suffix");}
}
打包放到flume安装路径下的lib文件夹中;
配置文件
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444# Describe the sink
a1.sinks.k1.type = com.why.sink.MySink
a1.sinks.k1.prefix = why:
a1.sinks.k1.suffix = :why# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1执行指令
hadoop102上:bin/flume-ng agent --conf conf/ --name a1 --conf-file job/group6/mysink.conf -Dflume.root.logger=INFO,console
结果如下:

相关文章:
Flume学习笔记(3)—— Flume 自定义组件
前置知识: Flume学习笔记(1)—— Flume入门-CSDN博客 Flume学习笔记(2)—— Flume进阶-CSDN博客 Flume 自定义组件 自定义 Interceptor 需求分析:使用 Flume 采集服务器本地日志,需要按照日志…...

go的字符切片和字符串互转
Go 1.21 // 返回一个Slice,它的底层数组自ptr开始,长度和容量都是len func Slice(ptr *ArbitraryType, len IntegerType) []ArbitraryType // 返回一个指针,指向底层的数组 func SliceData(slice []ArbitraryType) *ArbitraryType // 生成一…...

所见即所得的动画效果:Animate.css
我们可以在集成Animate.css来改善界面的用户体验,省掉大量手写css动画的时间。 官网:Animate.css 使用 1、安装依赖 npm install animate.css --save2、引入依赖 import animate.css;3、在项目中使用 在class类名上animate__animated是必须的&#x…...
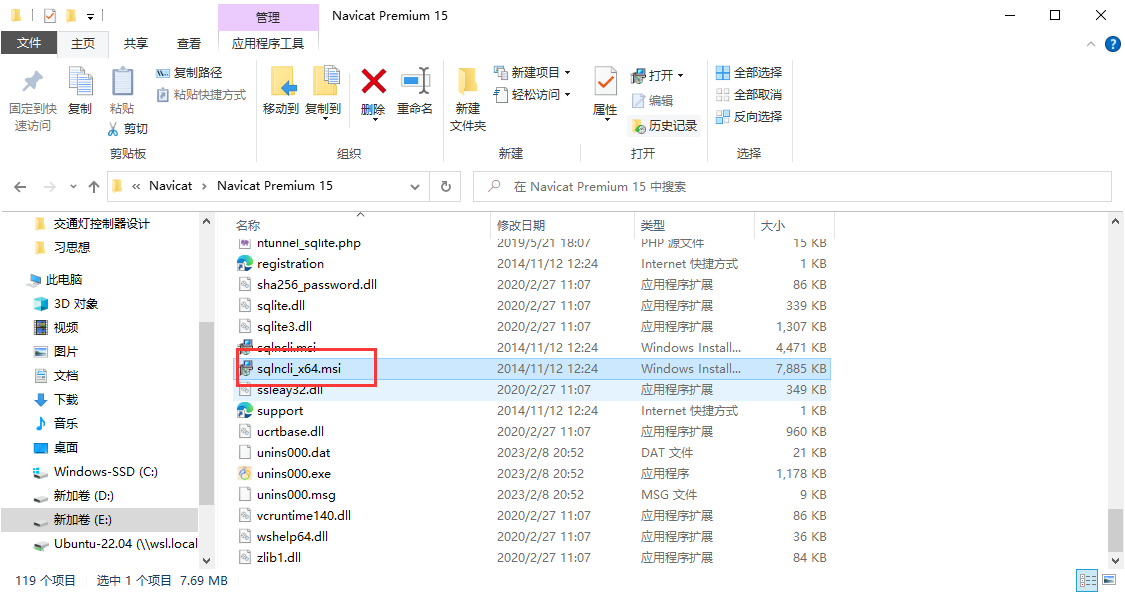
ERR:Navicat连接Sql Server报错
错误信息:报错:未发现数据源名称并且未指定默认驱动程序。 原因:Navicat没有安装Sqlserver驱动。 解决方案:在Navicat安装目录下找到sqlncli_x64.msi安装即可。 一键安装即可。 Navicat链接SQL Server配置 - MarchXD - 博客园 …...
python算法例10 整数转换为罗马数字
1. 问题描述 给定一个整数,将其转换为罗马数字,要求返回结果的取值范围为1~3999。 2. 问题示例 4→Ⅳ,12→Ⅻ,21→XⅪ,99→XCIX。 3. 代码实现 def int_to_roman(num):val [1000, 900, 500, 400,100, 90, 50, 40…...
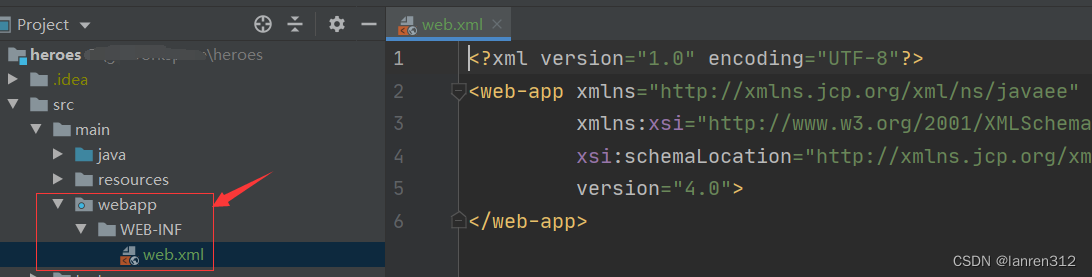
springboot引入第三方jar包放到项目目录中,添加web.xml
参考博客:https://www.cnblogs.com/mask-xiexie/p/16086612.html https://zhuanlan.zhihu.com/p/587605618 1、在resources目录下新建lib文件夹,将jar包放到lib文件夹中 2、修改pom.xml文件 <dependency><groupId>com.lanren312</grou…...
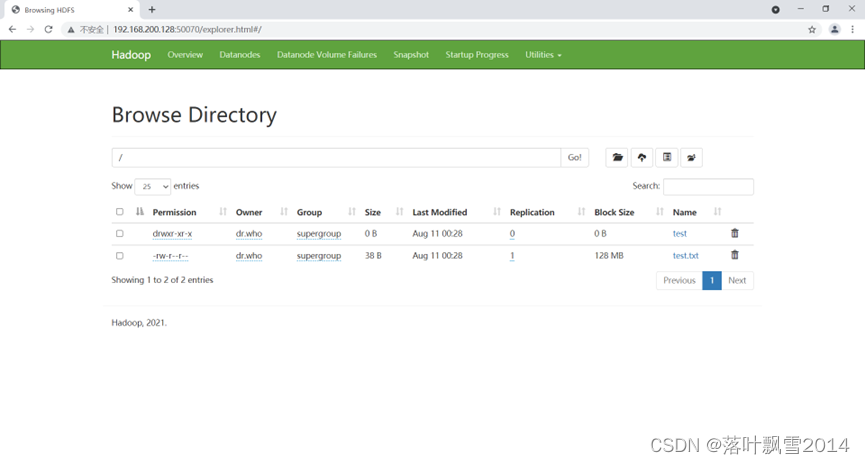
大数据研发工程师课前环境搭建
大数据研发工程师课前环境搭建 第一章 VMware Workstation 安装 在Windows的合适的目录来进行安装,如下图 1.1 双击打开 1.2 下一步,接受协议 1.3 选择安装位置 1.4 用户体验设置 1.5 快捷方式 已经准备好安装,点击安装 1.6 安装中 1.7 安装…...

Qt图形视图框架:QGraphicsItem详解
Qt图形视图框架:QGraphicsItem详解 Chapter1 Qt图形视图框架:QGraphicsItem详解Chapter2 自定义QGraphicsItem实现平移、改变尺寸和旋转1. 平移2. 改变尺寸3. 旋转完整代码如下:头文件源文件 Chapter1 Qt图形视图框架:QGraphicsIt…...

defer和async
如果两个属性浏览器都不兼容,推荐把<script>标签放到底部 一般情况下,浏览器在解析html源文件时,如果遇到外部的<script>标签,解析过程就会先暂停,这时会对script进行加载,执行两个过程&…...

数电实验-----实现74LS139芯片扩展为3-8译码器以及应用(Quartus II )
目录 一、74LS139芯片介绍 芯片管脚 芯片功能表 二、2-4译码器扩展为3-8译码器 1.扩展原理 2.电路图连接 3.仿真结果 三、3-8译码器的应用(基于74ls139芯片) 1.三变量表决器 2.奇偶校验电路 一、74LS139芯片介绍 74LS139芯片是属于2-4译码器…...

洋葱架构、三层架构及两者区别
前言 洋葱架构它的名称来源于洋葱的层次结构,即软件代码的各层次之间的关系。在这种架构中,应用程序的各个组件通过一系列层次结构被逐层包裹在一起,形成一个类似于洋葱的结构。 一、经典三层架构 三层架构是一种软件设计模式,…...
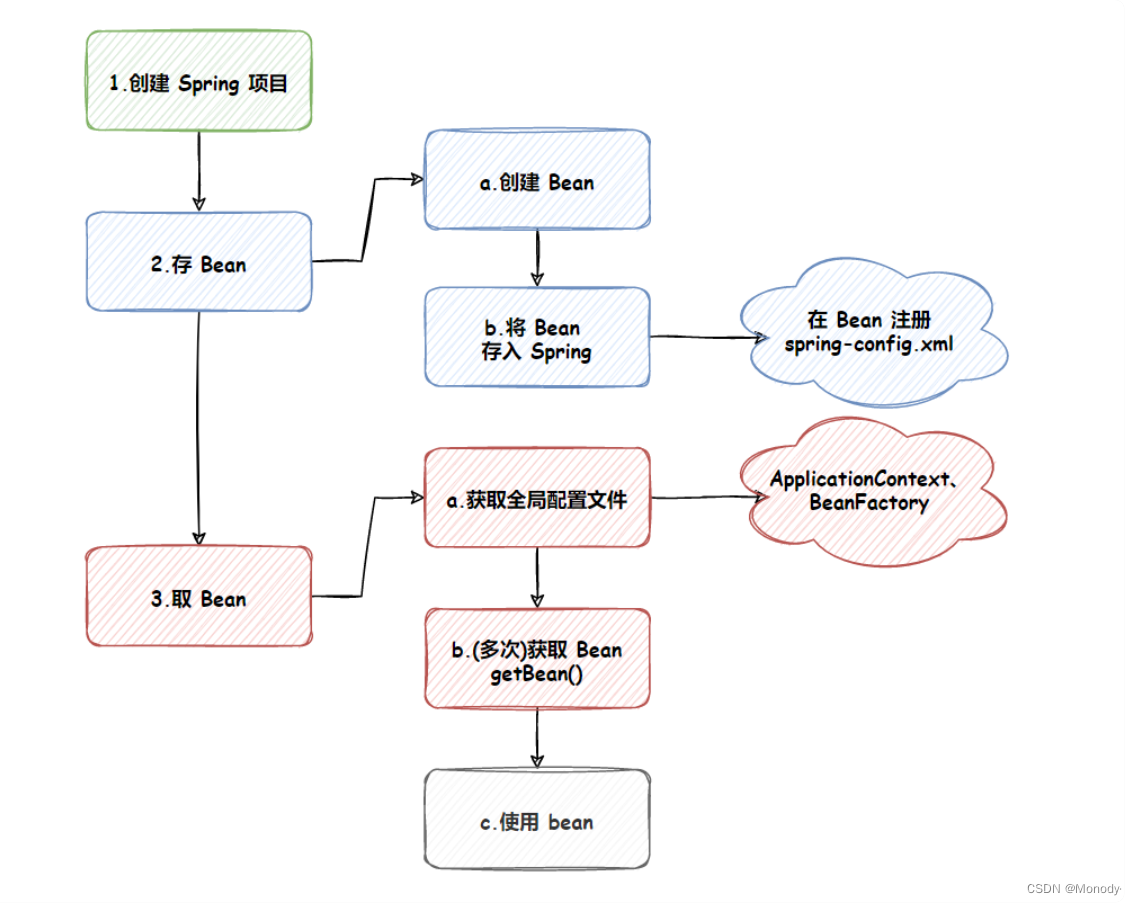
JavaEE进阶学习:Spring 的创建和使用
Spring 就是⼀个包含了众多工具方法的 IoC 容器。既然是容器那么它就具备两个最基本的功能: 将对象存储到容器(Spring)中从容器中将对象取出来 接下来使用 Maven 方式来创建一个 Spring 项目,创建 Spring 项目和 Servlet 类似&a…...
)
音视频项目—基于FFmpeg和SDL的音视频播放器解析(十四)
介绍 在本系列,我打算花大篇幅讲解我的 gitee 项目音视频播放器,在这个项目,您可以学到音视频解封装,解码,SDL渲染相关的知识。您对源代码感兴趣的话,请查看基于FFmpeg和SDL的音视频播放器 如果您不理解本…...
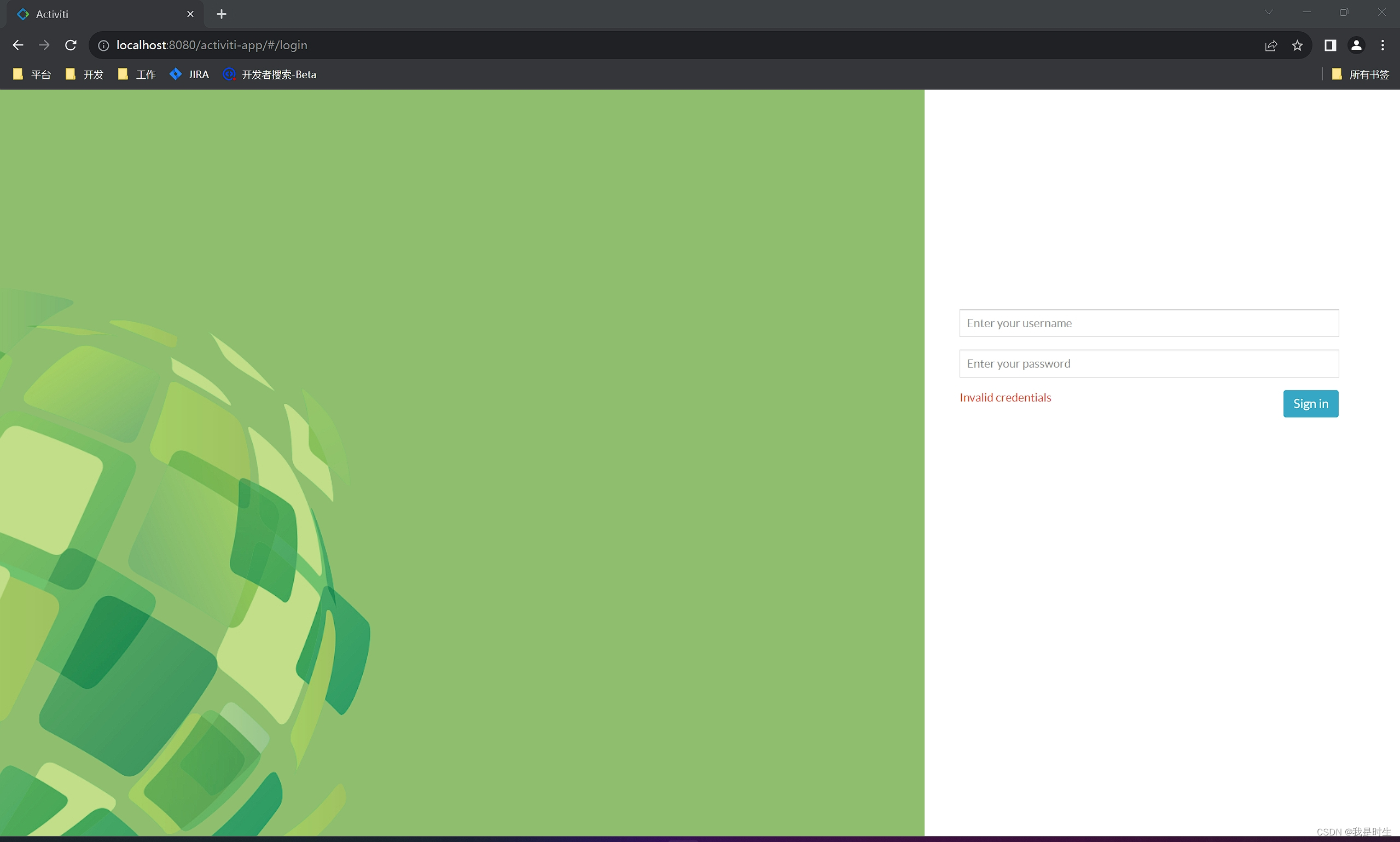
Tomcat无法映射到activiti-app导致activiti无法启动页面
原因之一:JDK版本与Tomcat版本不匹配,jdk8 yyds 我使用的是JDK11,Tomcat是9.0的,都是最新的,但还是不行,最后JDK改为8,tomcat的cmd后台没有报错,activiti-pp也可以正常访问了,很神奇…...

c语言常见的面试问题
在C语言编程中,面试官可能会询问你以下一些常见问题: 什么是C语言? C语言是一种通用的、过程式的计算机编程语言,由Dennis Ritchie在1972年创建。它是Unix操作系统的核心语言,也是许多其他编程语言(如Go、…...

image图片之间的间隙消除
多个图片排列展示,水平和垂直方向的间隔如何消除 垂直方向 vertical-align 原因: vertical-align属性主要用于改变行内元素的对齐方式,行内元素默认垂直对齐方式是基线对齐(baseline) 这是因为图片属于行内元素&…...
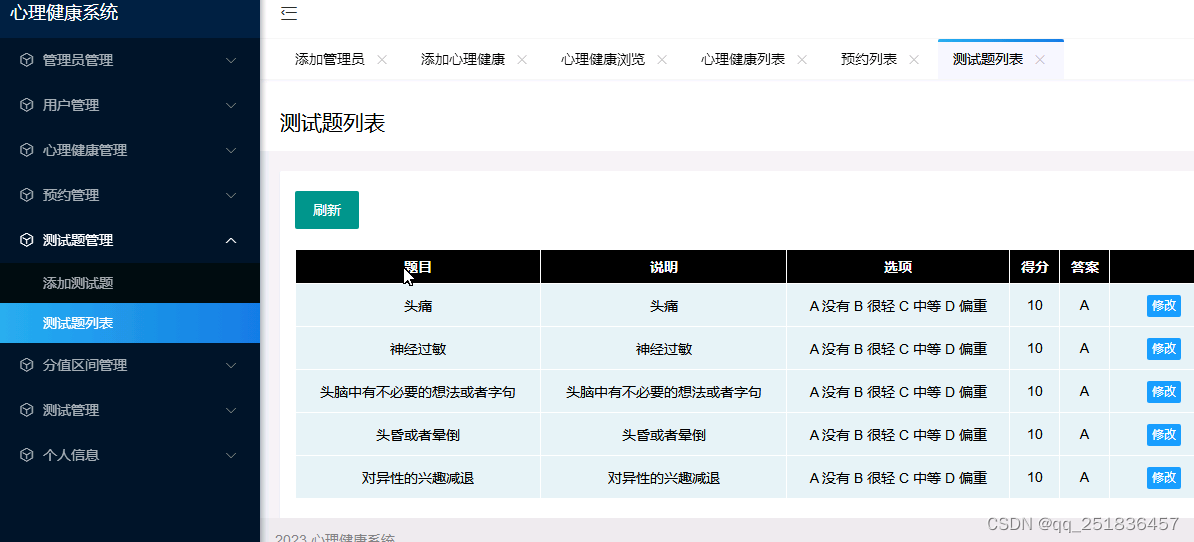
asp.net心理健康管理系统VS开发sqlserver数据库web结构c#编程计算机网页项目
一、源码特点 asp.net 心理健康管理系统 是一套完善的web设计管理系统,系统具有完整的源代码和数据库,系统主要采用B/S模式开发。 系统视频链接 https://www.bilibili.com/video/BV19w411H7P4/ 二、功能介绍 本系统使用Microsoft Visual Studio…...
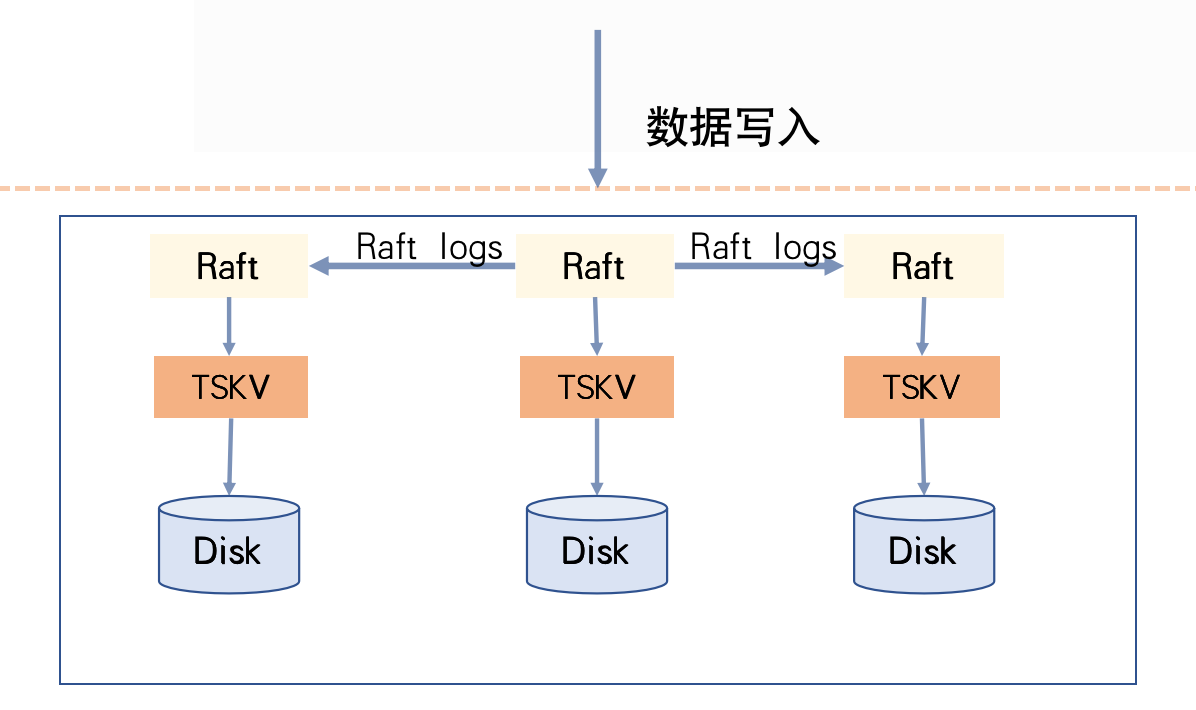
CnosDB有主复制演进历程
分布式存储系统的复杂性涉及数据容灾备份、一致性、高并发请求和大容量存储等问题。本文结合CnosDB在分布式环境下的演化历程,分享如何将分布式理论应用于实际生产,以及不同实现方式的优缺点和应用场景。 分布式系统架构模式 分布式存储系统下按照数据复…...
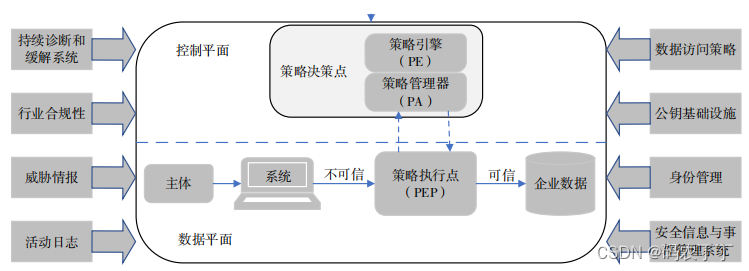
【前沿学习】美国零信任架构发展现状与趋势研究
转自:美国零信任架构发展现状与趋势研究 摘要 为了应对日趋严峻的网络安全威胁,美国不断加大对零信任架构的研究和应用。自 2022 年以来,美国发布了多个零信任战略和体系架构文件,开展了多项零信任应用项目。在介绍美国零信任战略…...
)
Toolformer论文阅读笔记(简略版)
文章目录 引言方法限制结论 引言 大语言模型在zero-shot和few-shot情况下,在很多下游任务中取得了很好的结果。大模型存在的限制:无法获取最新的信息、无法进行精确的数学计算、无法理解时间的推移等。这些限制可以通过扩大模型规模一定程度上解决&…...

【C++ AI 大模型接入 SDK】 - 项目介绍与 AI 知识科普
大家好,我是Halcyon.平安 欢迎文末添加好友交流,共同进步! 一、项目介绍核心功能二、AI 基础知识科普2.1 什么是大语言模型(LLM)2.2 API 调用方式2.3 全量响应 vs 流式响应2.4 SSE(Server-Sent Events&…...

Anthropic Claude Haiku 4.5 安全突破:勒索行为从96%降至0%
上一篇: Google I/O 2026前瞻:Gemini 4.0、Android XR与AI原生生态的全面突破 下一篇: Anthropic ARR突破440亿美元:Q1营收同比增长80倍深度分析 核心结论: Anthropic通过"困难建议数据集"和宪法训练方法,成功将Claude模型的勒索行…...

1394-AM75伺服驱动器
1394-AM75 是艾伦-布拉德LEY(Allen-Bradley)系列的一款伺服驱动器,控制精度高、响应迅速,适用于工业自动化中的精密运动控制。中间 15 条特点:结构紧凑,便于安装于控制柜内。支持宽电压输入范围,…...

PyQt5实战:从Designer拖拽到打包exe,手把手打造你的第一个多页面桌面应用
PyQt5实战:从Designer拖拽到打包exe,手把手打造你的第一个多页面桌面应用 在数字化浪潮席卷各行各业的今天,图形用户界面(GUI)开发已成为程序员必备技能之一。而PyQt5作为Python最强大的GUI框架,凭借其丰富…...

MediaCreationTool.bat:5大实用功能带你告别Windows安装烦恼
MediaCreationTool.bat:5大实用功能带你告别Windows安装烦恼 【免费下载链接】MediaCreationTool.bat Universal MCT wrapper script for all Windows 10/11 versions from 1507 to 21H2! 项目地址: https://gitcode.com/gh_mirrors/me/MediaCreationTool.bat …...

突破传统命令行限制:PortProxyGUI如何重塑Windows网络配置体验
突破传统命令行限制:PortProxyGUI如何重塑Windows网络配置体验 【免费下载链接】PortProxyGUI A manager of netsh interface portproxy which is to evaluate TCP/IP port redirect on windows. 项目地址: https://gitcode.com/gh_mirrors/po/PortProxyGUI …...

从零到一:手把手教你用LabelImg高效构建VOC与YOLO数据集
1. 为什么你需要掌握LabelImg标注工具 刚接触计算机视觉时,我最头疼的就是数据准备环节。记得第一次尝试训练目标检测模型,花了两周时间收集了上千张图片,却在标注环节卡住了——手动画框太慢,格式转换出错,反复返工差…...
)
HC32F460_ADC驱动(二)
2 ADC工作的核心要素2.1 采样保持一般来说采样保持电路(S/H)是ADC转换的前端电路。由于模拟信号是时刻连续变化的,若转换过程中输入电压持续波动会导致转换结果失真。采样保持电路的核心作用是在ADC启动转换后保持输入信号不变,保…...

Shoelace主题定制终极指南:掌握CSS变量覆盖与扩展技巧的10个秘诀
Shoelace主题定制终极指南:掌握CSS变量覆盖与扩展技巧的10个秘诀 【免费下载链接】shoelace Shoelace is now Web Awesome. Come see what’s new! 项目地址: https://gitcode.com/gh_mirrors/sh/shoelace Shoelace是一个功能强大的Web组件库,现已…...

img-2社区贡献指南:如何参与开源项目并提交你的第一个Pull Request
img-2社区贡献指南:如何参与开源项目并提交你的第一个Pull Request 【免费下载链接】img-2 Replace elements with to automatically pre-cache images and improve page performance.项目地址: https://gitcode.com/gh_mirrors/im/img-2 想要为优秀的图片懒加…...