下一代搜索引擎会什么?
现在是北京时间2023年11月18日。聊一聊搜索。
说到搜索,大家首先想到的肯定是谷歌,百度。我把这些定义成上一个时代的搜索引擎。ChatGPT已经火热了有一年的时间了,大家都认为Ai搜索是下一代的搜索。但是AI搜索,需要的是很大算力,需要很大存储空间。至今为止又有多少个公司能够真的去做AI搜索呢?普通的公司又能够做什么呢?
ChatGPT是大模型,它的数据总是停留在历史的某个时间点上,目前来看,它对新事物的了解还是很慢的,并不能时时刻刻把新的内容加入到知识库中。未来在更强大的算力进步下,或许会实现。但是我觉得下一代的搜索仍然需要和上一代的搜索结合。这会是一个漫长的过渡期。很显然,大家也都是这么玩的。它叫做搜索增强。
上一代传统搜索
上一代的搜索引擎的关键是关键词匹配。这里还是以elasticsearch为例,关键词匹配,BM25相关性算法,来决定数据的召回。这种基于关键词的匹配技术,是存在很多弊端的,它的召回能力,效果也有限。大家更喜欢AI搜索这种模式,通常AI搜索给的答案,更接近问题本身。而在传统的搜索模式下,通常就是问一个问题,然后返回你几条数据,然后再在这几条数据中,人工获取答案。悲伤的是,这几条数据里边未必有我们的结果。
传统搜索与大模型构造增强式搜索引擎
最简单的玩法就是,把召回的结果,给大模型,然后由大模型总结整理一个答案。其实这个过程就是省去了使用者思考的过程。为使用者带来很大的便利性。这正是被更多人追捧的原因。最典型的就是bing的搜索。它就是这么玩的,这样以来,弥补了大模型的知识停留在历史的某个阶段的问题。
传统搜索的未来
除了上述的搜索增强,我觉得下个时代的搜索,还是会有很大变化空间的。有的公司在说神经搜索,有的人在说语义检索,还有人在说跨模态检索。总之,大家都期望搜索能够有更强大的能力。推荐基于深度学习的神经语义搜索 - 智源社区 看看这篇文章,详细了解神经搜索(NLP模型 )。
其实上述的搜索目标,实现起来都是一种形式。大模型 + 向量,通过大模型将各种模态的数据,图片,文本,声音等等各种形式的内容,映射成向量。但是下个时代的到来,还有几个问题等待解决。第一个是算力问题,把文本或者图片,使用大模型转成向量,需要算力,这个过程是非常慢的。第二个是存储和检索问题,这些转完的向量如何存储,如何高效快速检索。因为通常文本内容,例如一篇文章,通常需要先进行分割,按照行或者按照段落做切分,然后再对切分后的内容使用模型转成向量。每个向量通常是一个512维度甚至更高维度的浮点型数组。这让原本的存储空间变得更大。所以存储是一个问题。除了存储的问题,在向量中做检索,通常是计算完成的。在海量数据中做检索已经很难了,在限量中做计算,需要的算力资源又是一个难题。我在一台128G内存96核心的服务器上使用elasticsearch做存储和检索,亿级数据的检索性能已经是一个比较大的问题了。在千万级向量中检索是毫秒级别。
未来的搜索如何玩
想要做起来很容易。选取适合自己的模型,可以在huggingFace上看一看。https://huggingface.co/models

首先先拿文本来说,需要做文本嵌入,寻找text-vex的模型,这里推荐一个 可以看看。https://huggingface.co/moka-ai/m3e-base
假如想做多模态搜索,又需要特定的模型。效果较好的例如Clip,https://huggingface.co/openai/clip-vit-base-patch32
然后把转好的向量使用向量库存起来。这里我是用的elasticsearch 8.X版本。因为我本来就是做es搜索的,对elasticsearch非常熟悉。其实也调研了非常多的向量数据库,在大规模数据下,es的读写性能都是非常出色的。至少单个节点去解决千万级别的向量数据的存储和检索还是很轻松的,优化万了以后,性能在毫秒级别。
跑起来总是很容易。想要有更好的效果却是不容易的。对于选模型来说,是一个问题,而且要经过大量的测试对比各个模型的效果才行。并且非常可能面临着模型不符合自己的使用场景的问题,可能又要对模型进行微调。在huggingFace上,模型非常多,但是多数都是用英文语料训练的模型。往往不能够满足我们的需求。此外数据向量化的工程问题,又要去写挺多的代码,跑起来速度又不行,又需要进行调优。关于数据转向量工程化的内容,推荐一下Jina AI · GitHub。
相关文章:
下一代搜索引擎会什么?
现在是北京时间2023年11月18日。聊一聊搜索。 说到搜索,大家首先想到的肯定是谷歌,百度。我把这些定义成上一个时代的搜索引擎。ChatGPT已经火热了有一年的时间了,大家都认为Ai搜索是下一代的搜索。但是AI搜索,需要的是很大算力&a…...

WPF中如何在MVVM模式下关闭窗口
完全来源于十月的寒流,感谢大佬讲解 使用Behaviors <Window x:Class"Test_03.MainWindow"xmlns"http://schemas.microsoft.com/winfx/2006/xaml/presentation"xmlns:b"http://schemas.microsoft.com/xaml/behaviors"xmlns:x&quo…...
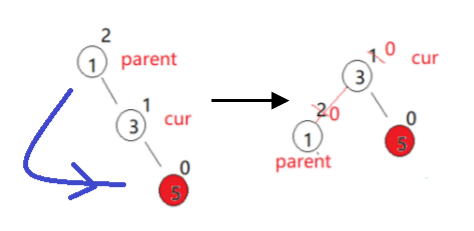
【数据结构&C++】二叉平衡搜索树-AVL树(25)
前言 大家好吖,欢迎来到 YY 滴C系列 ,热烈欢迎! 本章主要内容面向接触过C的老铁 主要内容含: 欢迎订阅 YY滴C专栏!更多干货持续更新!以下是传送门! 目录 一.AVL树的概念二.AVL树节点的定义(代码…...

Python算法——树的最大深度和最小深度
Python中的树的最大深度和最小深度算法详解 树的最大深度和最小深度是树结构中的两个关键指标,它们分别表示树的从根节点到最深叶子节点的最大路径长度和最小路径长度。在本文中,我们将深入讨论如何计算树的最大深度和最小深度,并提供Python…...

46.全排列-py
46.全排列 class Solution(object):def permute(self, nums):""":type nums: List[int]:rtype: List[List[int]]"""# 结果数组0ans[]nlen(nums)# 判断是否使用state_[False]*n# 临时状态数组dp_[]def dfs (index):# 终止条件if indexn:ans.appe…...
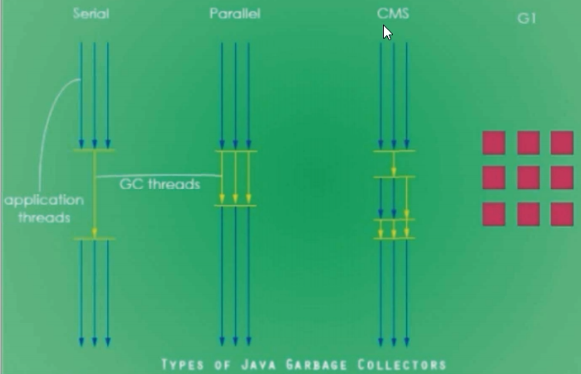
系列三、GC垃圾回收算法和垃圾收集器的关系?分别是什么请你谈谈
一、关系 GC算法(引用计数法、复制算法、标记清除算法、标记整理算法)是方法论,垃圾收集器是算法的落地实现。 二、4种主要垃圾收集器 4.1、串行垃圾收集器(Serial) 它为单线程环境设计,并且只使用一个线程…...
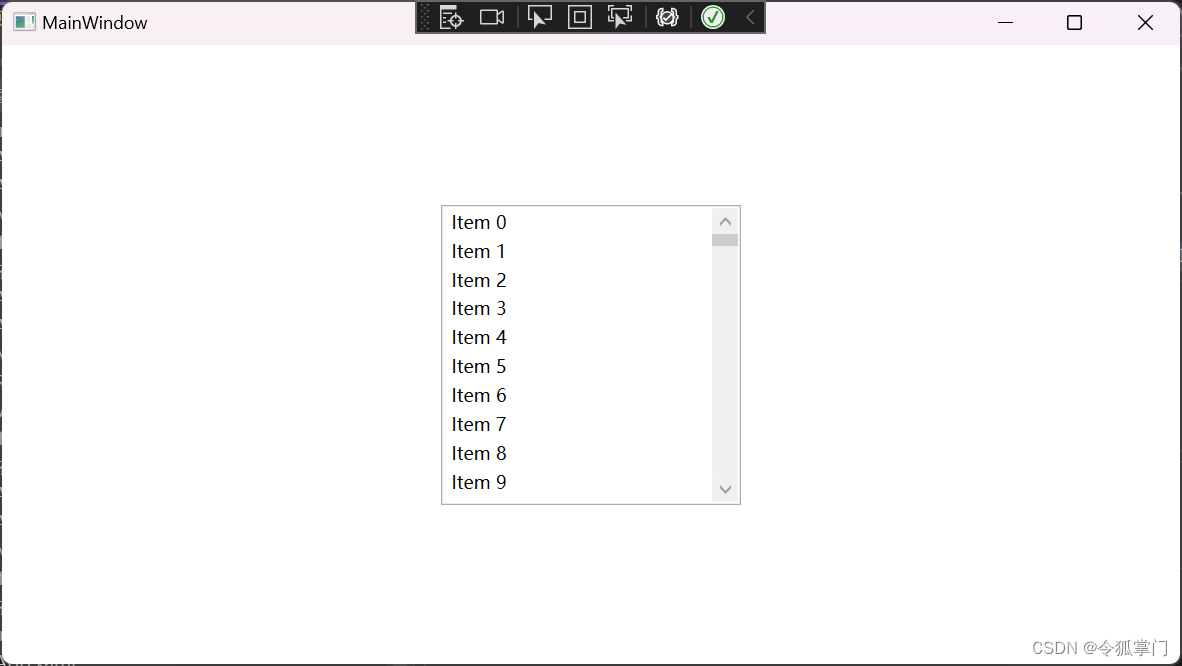
WPF中的虚拟化是什么
WPF(Windows Presentation Foundation)中的虚拟化是一种性能优化技术,它主要用于提高大量数据展示的效率。在WPF中,如果你有一个包含大量项的ItemsControl(例如ListBox、ListView或DataGrid等),…...

免费稳定几乎无门槛,我的ChartGPT助手免费分享给你
公众号「架构成长指南」,专注于生产实践、云原生、分布式系统、大数据技术分享。 概述 ChatGPT想必大家应该都不陌生了,大部分人或多或少都接触了,好多应该都是通过openAi的官方进行使用的,这个门槛对大部分人有点高,…...
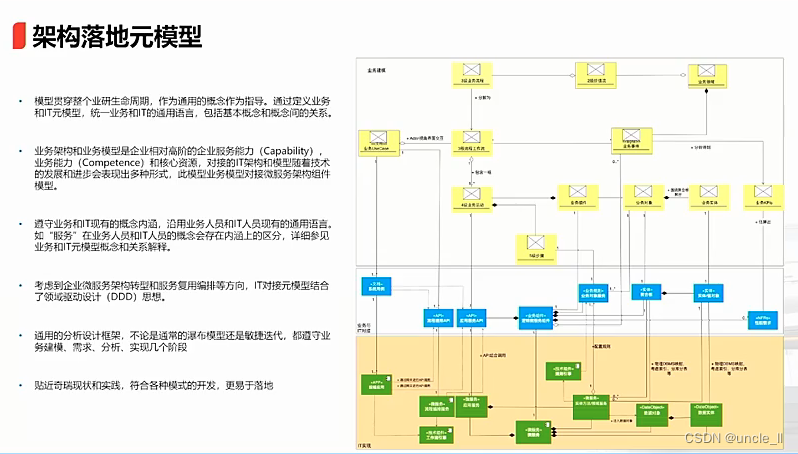
奇瑞金融:汽车金融行业架构设计
拆借联合贷款abs...

milvus数据库分区管理
一、创建分区 在创建集合时,会默认创建分区_default。 自己手动创建如下: from pymilvus import Collection collection Collection("book") # Get an existing collection. collection.create_partition("novel")二、检测分…...

pytorch.nn.Conv1d详解
通读了从论文中找的代码,终于找到这个痛点了! 以下详解nn.Conv1d方法 1 参数说明 in_channels(int) – 输入信号的通道。 out_channels(int) – 卷积产生的通道。 kernel_size(int or tuple) - 卷积核的尺寸,经测试后卷积核的大小应为in_cha…...
大数据HCIE成神之路之数学(2)——线性代数
线性代数 1.1 线性代数内容介绍1.1.1 线性代数介绍1.1.2 代码实现介绍 1.2 线性代数实现1.2.1 reshape运算1.2.2 转置实现1.2.3 矩阵乘法实现1.2.4 矩阵对应运算1.2.5 逆矩阵实现1.2.6 特征值与特征向量1.2.7 求行列式1.2.8 奇异值分解实现1.2.9 线性方程组求解 1.1 线性代数内…...
——使用ffmepg实现视音频解码)
音视频学习(十八)——使用ffmepg实现视音频解码
视频解码 初始化 视频常用的编解码器id定义(以h264和h265为例) // 定义在ffmpeg\include\libavcodec\avcodec.h AV_CODEC_ID_H264 AV_CODEC_ID_H265查找解码器:根据编解码id查看解码器 AVCodec* pCodecVideo avcodec_find_decoder(codec…...

nginx的GeoIP模块
使用场景 过滤指定地区/国家的IP,一般是国外IP禁止请求。 使用geoip模块实现不同国家的请求被转发到不同国家的nginx服务器,也就是根据国家负载均衡。 前置知识 GeoIP是什么? 官网地址 https://www.maxmind.com/en/home包含IP地址的地理位…...

mac控制台命令小技巧
shigen日更文章的博客写手,擅长Java、python、vue、shell等编程语言和各种应用程序、脚本的开发。记录成长,分享认知,留住感动。 hello伙伴们,作为忠实的mac骨灰级别的粉丝,它真的给我带来了很多效率上的提升。那作为接…...

Postman:API测试之Postman使用完全指南
Postman是一个可扩展的API开发和测试协同平台工具,可以快速集成到CI/CD管道中。旨在简化测试和开发中的API工作流。 Postman工具有Chrome扩展和独立客户端,推荐安装独立客户端。 Postman有个workspace的概念,workspace分personal和team类型…...

Flume学习笔记(3)—— Flume 自定义组件
前置知识: Flume学习笔记(1)—— Flume入门-CSDN博客 Flume学习笔记(2)—— Flume进阶-CSDN博客 Flume 自定义组件 自定义 Interceptor 需求分析:使用 Flume 采集服务器本地日志,需要按照日志…...

go的字符切片和字符串互转
Go 1.21 // 返回一个Slice,它的底层数组自ptr开始,长度和容量都是len func Slice(ptr *ArbitraryType, len IntegerType) []ArbitraryType // 返回一个指针,指向底层的数组 func SliceData(slice []ArbitraryType) *ArbitraryType // 生成一…...

所见即所得的动画效果:Animate.css
我们可以在集成Animate.css来改善界面的用户体验,省掉大量手写css动画的时间。 官网:Animate.css 使用 1、安装依赖 npm install animate.css --save2、引入依赖 import animate.css;3、在项目中使用 在class类名上animate__animated是必须的&#x…...
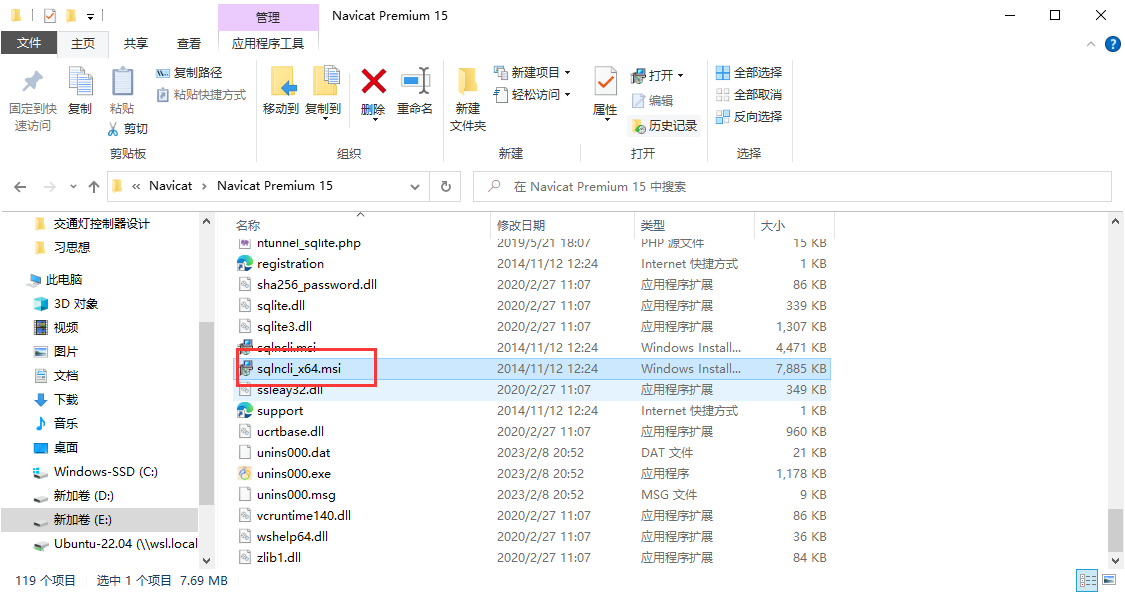
ERR:Navicat连接Sql Server报错
错误信息:报错:未发现数据源名称并且未指定默认驱动程序。 原因:Navicat没有安装Sqlserver驱动。 解决方案:在Navicat安装目录下找到sqlncli_x64.msi安装即可。 一键安装即可。 Navicat链接SQL Server配置 - MarchXD - 博客园 …...

CVE-2025-48976:Apache Commons FileUpload 协议解析层内存崩溃漏洞深度解析
1. 这个漏洞不是“上传文件被黑了”,而是整个解析逻辑崩了Apache Commons FileUpload 是 Java 生态里最老牌、最被信任的文件上传处理库之一,从 2003 年发布第一个稳定版起,它就稳稳地嵌在 Struts2、Spring MVC(早期)、…...

2026年上海AI Agent智能体开发公司全景解析:从技术底座到产业落地的能力坐标
引言:先把结论放在这里。2026年的上海,AI Agent智能体早已不是概念展厅里的抽象模型,而是直接进入业务流程、改写生产力公式的现实工具。面对“上海AI Agent智能体开发公司哪家好”或者“上海智能体软件开发公司推荐”这类问题,很…...

图自编码器在金融风控中的拓扑模式检测实践
1. 项目概述:当图机器学习遇上金融风控在金融科技领域摸爬滚打了十几年,我见过太多风控系统从“规则为王”到“数据驱动”的变迁。早期的反洗钱(AML)和反欺诈系统,本质上是一套复杂的“如果-那么”规则库:如…...

FPGA与机器学习协同加速量子点自动调谐:原理、实现与性能分析
1. 项目概述:当FPGA遇上机器学习,量子点调谐的“自动驾驶”时代在量子计算实验室里,调谐一个量子点器件进入单电子态,是每个实验物理学家都绕不开的“苦差事”。这活儿有多磨人?你得坐在仪器前,手动调节两个…...

如何快速为你的爱车添加自动驾驶:openpilot完整实战指南
如何快速为你的爱车添加自动驾驶:openpilot完整实战指南 【免费下载链接】openpilot openpilot is an operating system for robotics. Currently, it upgrades the driver assistance system on 300 supported cars. 项目地址: https://gitcode.com/GitHub_Trend…...

保姆级教程:用Python将EEG脑电信号转成图像,喂给VGG+LSTM做疲劳检测
从EEG信号到疲劳检测图像:Python实战全流程解析当脑电波遇见计算机视觉,会擦出怎样的火花?传统EEG分析往往局限于时频域特征提取,而本文将带你探索一种革命性的思路——将多通道脑电信号转化为彩色拓扑图像,让卷积神经…...

circuitbreaker常见问题解答:解决Go熔断器使用中的痛点
circuitbreaker常见问题解答:解决Go熔断器使用中的痛点 【免费下载链接】circuitbreaker Circuit Breakers in Go 项目地址: https://gitcode.com/gh_mirrors/circ/circuitbreaker Circuitbreaker是一个强大的Go语言熔断器库,它实现了熔断器模式&…...
)
鸿蒙数理体系创作说明 (鸿蒙数学一阶完结后更新说明)
本套鸿蒙数学体系,并非凭空独创,而是站在华夏千年古数根基之上,融合西方近代数理实证体系,双向重构、文明合一所诞生的全新本源数理框架。一、本体系继承、吸纳的【华夏传统古数核心本源】整套体系的底层大道骨架、思维范式、宇宙…...
)
告别.bash_profile:在macOS Ventura/Sonoma上为Maven配置环境变量的几种新方法(含Zsh教程)
macOS Ventura/Sonoma时代:Maven环境变量配置的现代实践指南如果你最近升级到了macOS Ventura或Sonoma,可能会发现那些教你修改.bash_profile来配置Maven环境变量的教程突然不灵了。这不是你的问题——而是macOS的Shell环境已经悄然进化。作为长期在macO…...
)
从原理到操作:彻底搞懂Linux服务器UEFI启动项管理(efibootmgr命令详解)
深入解析Linux服务器UEFI启动管理:efibootmgr命令全攻略当你在Linux服务器上执行efibootmgr命令时,是否曾被那些神秘的Boot000X条目搞得一头雾水?作为现代服务器的主流启动方式,UEFI远比传统的BIOS复杂得多。本文将带你从底层原理…...